Authors:
Motivation
TensorFlow users can run training jobs on Kubernetes with the support of this project: tensorflow/k8s, which is a CRD controller (or TensorFlow operator) for deploying distributed TensorFlow on Kubernetes.
Maybe it is not sustainable for TensorFlow users (e.g. data scientist or deep learning engineer
) to write a complex YAML file to deploy their TensorFlow Training and other related service (e.g. launch TensorFlow Serving and TensorBoard). And the users could not get the training status in the current design.
The KubeFlow project is dedicated to making a high-efficient, easy-to-use, cloud-native and scalable Machine Learning platform based on Kubernetes. Our goal is building an end-to-end system to manage the whole lifecycle of Machine Learning Jobs, which makes the TensorFlow to be kubernetes-friendly and user-friendly.
This doc describes a user-oriented distributed ML platform with:
- Defining a user spec to deploy TensorFlow Training/Serving/TensorBoard job
- Workflow from user side
- Components of the architecture
Use Cases
- I have no idea about Kubernetes and just want to focus on developing TensorFlow model.
- I don’t need to write YAML files for any kind of TensorFlow jobs, including training, serving and TensorBoard jobs.
- I can specify computing resources (e.g. GPUs) which will be used in TensorFlow training or serving.
- I can get the processing status and logs from KubeFlow API after triggering TensorFlow training jobs.
- I can launch TensorFlow model as a service to expose trained TensorFlow model.
- I can launch TensorBoard as a service which would track multiple experiments.
Goals
- Implement a server
- Accept training code files, e.g. python files as input, and run training jobs on Kubernetes, with no need for additional configs.
- watch job status running on Kubernetes and do some cleanup works on the cluster
- Implement a monitor, to get the job status from Kubernetes and report specific status to the KubeFlow server
- Update CRD specification and controller to fit the new design
- For scheduling (future work):
- For resource management (future work):
- Use device plugin (in Kubelet) and NVIDIA k8s-device-plugin with nvidia-docker v2 for NVIDIA GPU scheduling
- Implement Resource Class with CRD and Custom Scheduler for different type GPUs scheduling (on homogeneous nodes)
Workflow
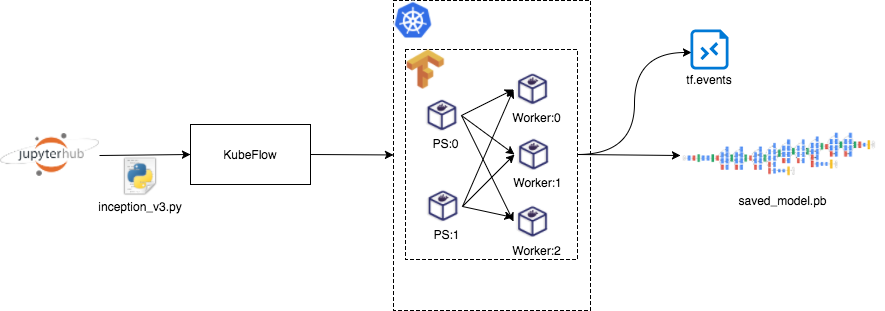
Fig 1 KubeFlow distributed training job
As shown in Fig 1, users develop some ML models in the JupyterHub. Then they send the TensorFlow Python script (e.g. inception_v3.py) into KubeFlow. When receiving the script, KubeFlow creates TensorFlow distributed training job based on Kubernetes. Finally, the TensorFlow training job would delivery sort of files, such as tf.events for TensorBoard visualization and saved_model.pb for TensorFlow Serving.

Fig 2 KubeFlow serving job
As shown in Fig 2, users send the saved_model.pb file into KubeFlow. Then KubeFlow creates a TensorFlow Serving job to provide a public service. With the number of requests increasing, KubeFlow would automatically scale out the job.

Fig 3 KubeFlow TensorBoard job
As shown in Fig 3, users send the tf.events file into KubeFlow. Then KubeFlow creates a TensorBoard job to track multiple experiments.
Components
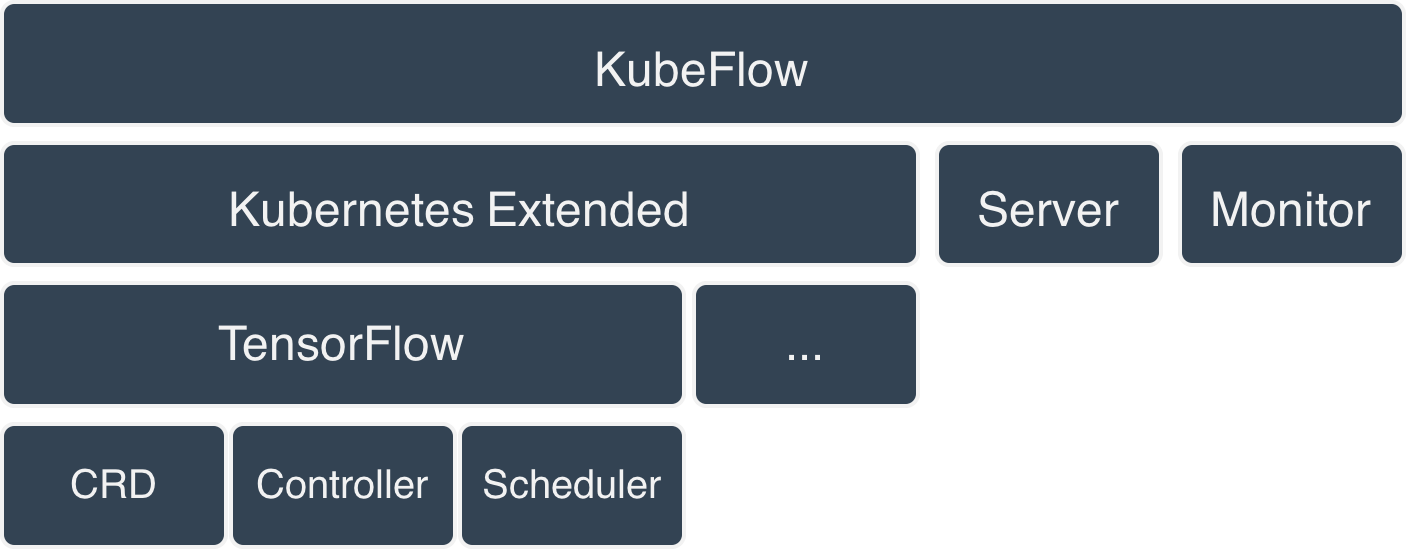
Fig 4 KubeFlow components
The design has several components:
- Kubernetes Extended (to better serve Machine Learning workload)
- TensorFlow CRD
- TensorFlow Controller
- TensorFlow Scheduler
- Server (to manage TensorFlow jobs and interact with the client)
- Monitor (to watch and report statuses of all TensorFlow jobs)
CRD
According to the use case and design goal, TensorFlow jobs are always divided into three types as below:
- Training Job
- Local Training Job
- Distributed Training Job
- Serving Job
- TensorBoard Job
TensorFlow distributed training job is most complicated and elusive among them. It adopts the classical PS-Worker distributed framework. PS (Parameter Server) is responsible for storing and updating the model's parameters. Worker is responsible for computing and applying gradients.
But, the native implementation of TensorFlow distributed framework is not perfect. For example, PS processes would join forever even though all Workers processes completed their computation works, which is a waste of resource. At the same time, Kubernetes has no idea of the TenforFlow job for lack of TensorFlow conceptions and semantics. So, it's difficult for native Kubernetes to make a realtime monitor watching the TenforFlow job status. In this case, KubeFlow aims to handle all problems above and fill in the gap between TensorFlow and Kubernetes.
The state-of-art implementation tensorflow/k8s generally works well and lots of works could be reused in the new CRD design. We have some changes based on tensorflow/k8s. We divides TensorFlow jobs into three types: training jobs, serving jobs and TensorBoard jobs.
In general, we always launch more than one TensorFlow training jobs with multiple kinds of hyper parameters combinations to get the best training results. At the same time, we can use one TensorBoard instance to visualize all of TensorFlow events outputted from training jobs. It is really a common case for data scientists and algorithm engineers. But, in the current design, the TensorBoard job is binding to one TensorFlow job.
In order to make above come true, we need to decouple the TensorFlow job and TensorBoard job. We can make some changes on the TenforFlow job CRD. At first, both jobs can share TFReplicaSpec. Moreover, we can use TFReplicaSpec to specify the TensorFlow Serving job. At the same time, we can add a type field to define the TensorFlow job type (one of Training, TensorBoard or Serving).
apiVersion: "tensorflow.org/v1alpha1"
kind: "TFJob"
metadata:
name: "training-job"
spec:
type: Training
tfReplicaSpec:
- replicas: 2
tfReplicaType: PS
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:1.4.0
command:
- "/workdir/tensorflow/launch_training.sh"
volumeMounts:
- name: workdir
mountPath: /workdir
volumes:
- name: workdir
glusterfs:
endpoints: <gluster-cluster>
path: <gluster_vol_subpath>
restartPolicy: OnFailure
tfReplicaSpec:
- replicas: 4
tfReplicaType: Worker
template:
spec:
containers:
- name: tensorflow
image: tensorflow/tensorflow:1.4.0
command:
- "/workdir/tensorflow/launch_training.sh"
args:
- "--data_dir=/workdir/data"
- "--train_dir=/workdir/train"
- "--model_dir=/workdir/model"
volumeMounts:
- name: workdir
mountPath: /workdir
volumes:
- name: workdir
glusterfs:
endpoints: <gluster-cluster>
path: <gluster_vol_subpath>
restartPolicy: OnFailure
Algo 1 YAML config for distributed training job
Related issues: tensorflow/k8s#209
Controller
tensorflow/k8s follows the CoreOS operator pattern to handle the events from Kubernetes, we aim to refactor the project to controller pattern which is similar to kubernetes/sample-controller to be extensible and robust.
But it has the same function as tensorflow/k8s: the controller watches the shared state of the cluster through the Kubernetes apiserver and makes changes attempting to move the current state towards the desired state for TensorFlow jobs on Kubernetes.
Server
Server is the most important component in KubeFlow, which are responsible for:
Setting up RESTful apiserver to listen for requests for creating TensorFlow jobs or requests from KubeFlow monitor for status updating.
Generating objects that can be accepted by Kubernetes apiserver to create TensorFlow jobs according to user requests.
Recording status of TensorFlow jobs in order to reschedule TensorFlow jobs when something goes wrong during training.
Monitor
KubeFlow controller allows users to create TensorFlow training jobs on Kubernetes, but the parameter servers are always running even after the training job finished. Besides this, users could not get the Tensorflow job's' status unless they access to Kubernetes.
Then we aim to implement a component which is called KubeFlow monitor, to watch the status of TensorFlow jobs on Kubernetes. And the monitor should report the status to KubeFlow server, then the server could move the current state towards the desired state.
Google Doc Version
For continuously and conveniently discuss the proposal and scope of KubeFlow, we created a gdoc of this proposal. Welcome for suggestion and comments! 🎉






![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")
































































































































































































































