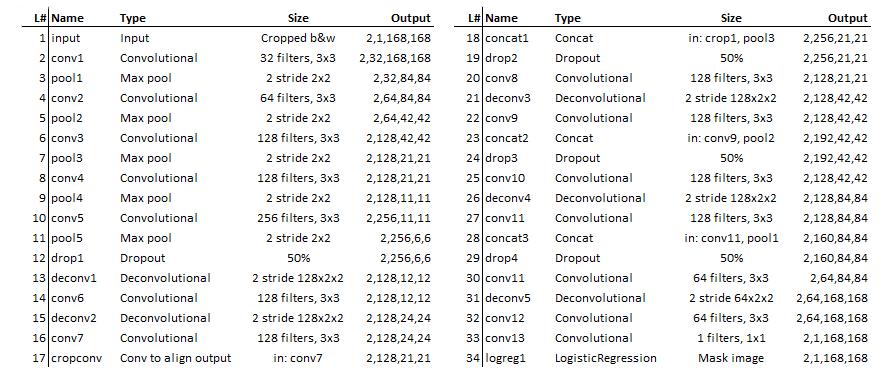
This is the source code for the 3rd place solution to the Second National Data Science Bowl hosted by Kaggle.com. For documenation about the approach look here
I used the anaconda default distribution with all the libraries that came with it. Next to this I used opencv(cv2), pydicom and MxNet (20151228 but later version will most probably be fine). For more detailed windows 64 installation instructions look here.
The dicom data needs to be downloaded from Kaggle and must be extracted in the data_kaggle/train /validate and /test folders.
In the settings.py you can adjust some parameters. The most important one is the special "quick mode". This makes training the model 5x faster at the expense of some datascience rigor. Instead of training different folds to calibrate upon to prevent overfitting we train only one fold. This overfits a bit in step 3 and 4 but still results in a solid 0.0105 score which is enough for a 3rd place on the LB. Not choosing quick mode takes much longer to train but will result in less overfit and gives 0.0101 on the LB. Which is almost 2nd place and maybe with some luck it is.
- python step0_preprocess.py
As a result the /data_preprocessed_images folder will contain ~329.000 preprocessed images and some extra csv files will be generated in the root folder. - python step1_train_segmenter.py
As a result you will have (a) trained model(s) in the root folder. Depending on the fold RMSE should be around 0.049 (train) and 0.052 (validate). - python step2_predict_volumes.py
As a result you will have a csv containing raw predictions for all 1140 patients. Also the data_patient_predictions will contain all generated overlays and csv data per patient for debugging. In the logs the average error in ml should be around 10ml. - python step3_calibrate.py
As a result you will have a csv file containing all the calibrated predictions. In the logs the average error in ML should go down with +/- 1ml. - python step4_submission.py
As a result the /data_submission_files folder will contain a submission file. In the logs the crps should be around 0.010.
The solution should be gentle on the GPU because of the small batchsize. Any recent GPU supported by MxNet should do the job I figure. The lowest card I tried (and that worked) was a GT740.