jtangming / blog Goto Github PK
View Code? Open in Web Editor NEWMy repository on GitHub.
License: Other
My repository on GitHub.
License: Other






















































1、React 16 之上:Time Slicing 与 Suspense API
本文介绍了 React 的新特性,Time-Slicing 将子组件切割为不同的块操作,并且能在不同的帧中异步执行; Suspense API 则允许 ReactJs 将界面的更新推迟到数据抓取完毕,是基于用户体验出发的编程模型。感兴趣的可以了解阅读。
文章力求把目前前端方向的 AR 技术都罗列一遍,细节不赘述,文章虽然是一两个月前的了,觉得能对 Web 前端工程师有一点的启发。
3、The React and React Native Event System Explained: A Harmonious Coexistence
通常情况下大部分开发者只是会用React’s event handling systemReact,对它们内部工作原理不是特别了解。本文作者阅读相关源代码后整理得到的理解,包括事件系统概览、事件接收与管理机制、EventPluginHub等。
4、http://mp.weixin.qq.com/s/MDRfdRnhJJ53611cG_Zb6g
我们常说的性能优化往往只是事后的想法,性能优化除了技术活,更多的是规划和指标。本文不是对雅虎14的的复述,而是更加详尽的阐述了文中所涉及的所有优化策略原理和来龙去脉,提供的这份快速、简洁的性能优化清单值得读者思考。
文章介绍了Android刘海屏的相关背景,“切割”状态栏的区域所面临的几种问题,最后从技术的角度来解决问题。在今后的开发中可能会遇见类似的适配,可推荐参考。
6、High Performance React: 3 New Tools to Speed Up Your Apps
在开发中,通常缓慢的组件挂载、过深的组件树以及不必要的渲染都有可能会削弱应用用户体验。文章详细地介绍了三个辅助工具及相关技术以提升应用性能,可以阅读参考。
7、How to escape async/await hell
说得有理有据的,有点危言耸听。其实没有那么严重,但可以作为优化手段,推荐一看。
8、那些好玩却尚未被 ECMAScript 2017 采纳的提案
文章先带你了解 ECMAScript 提案流程, 接着介绍了 ECMAScript 修订中几个重要的语法修改提案。了解相关的 ES 语法趋势和步伐,可以进一步打打基础。
9、WebAssembly 对比 JavaScript 及其使用场景
文章通过对比,你将更为清晰的理解V8 的运行机制,wasm 的内存模型、内存垃圾回收等以及其它特性和使用场景。
本文对VirtualDOM中的**与diff实现进行了详细介绍,有点炒旧饭嫌疑,不过值得我们持续关注与学习。
11、梳理前端开发使用 eslint 和 prettier 来检查和格式化代码问题 > 好代码同样的需要好工具,本文手把手教你撸一个使用 eslint 和 prettier 来检查和格式化代码问题
关于 React 组件开发,和通用的设计模式一样,同样的会有一些“经验法则”。推荐阅读一下,有套路傍身,开发起来更加稳妥。
文章是彭伟春在GMTC大会上的分享,是性能优化专题最为火爆的场,主要内容大致为:大前端时代前端监控新的变化、前端监控的最佳实践,最后是阿里云前端监控系统的实现
14、如何监控网页崩溃?
本文借 PWA 概念,使用 Service Worker 来实现网页崩溃的监控,实现了一套基于心跳检测的监控方案。
本文通过图文并茂的讲解,短短10分钟则了解了Event Loop 。
React16 的 fiber 架构下,内部会动态灵活的管理所有组件的渲染任务,本文可以帮助了解一下 React 到底是如何管理渲染任务的
17、React hooks:它不是一种魔法,只是一个数组——使用图表揭秘提案规则
近期有不少关于 React hooks 文章推荐,通过阅读本文,可以给大家建立了一个关于 Hooks 的更加清晰的思维模型,以此可以去思考新的 Hooks API 底层到底做了什么事情。
GraphQL 的 field resolve 如果按照 naive 的方式来写,每一个 field 都对数据库直接跑一个 query,会产生大量冗余 query,虽然网络层面的请求数被优化了,但数据库查询可能会成为性能瓶颈,这里面有很大的优化空间,但并不是那么容易做。FB 本身没有这个问题,因为他们内部数据库这一层也是抽象掉的,写 GraphQL 接口的人不需要顾虑 query 优化的问题。
GraphQL 的利好主要是在于前端的开发效率,但落地却需要服务端的全力配合。如果是小公司或者整个公司都是全栈,那可能可以做,但在很多前后端分工比较明确的团队里,要推动 GraphQL 还是会遇到各种协作上的阻力。
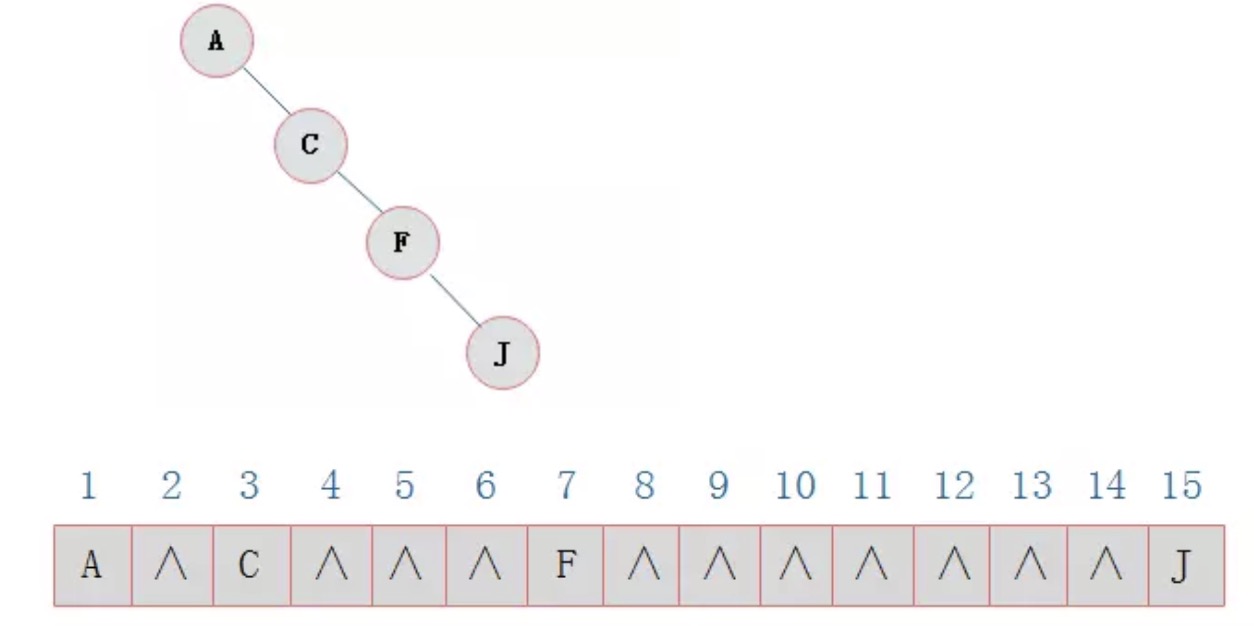
在一棵二叉树中,如果所有分支结点都存在左子树和右子树,并且所有叶子都在同一层上,则为满二叉树
对于具有 n 个节点的二叉树,对于任何一个编号 i (1 <= i <= n),如果与同层级的满二叉树中编号为 i 的节点完全相同,则是完全二叉树。
注:满二叉树一定是完全二叉树,但反过来不一定成立。
二叉树的顺序存储结构就是使用一维数组存储二叉树中的结点,并且结点的存储位置,就是数组的下标索引。
如一颗完全二叉树如下:

顺序存储方式如下:

极端情况采用顺序存储的方式是十分浪费空间的,如:
二叉链表将结点数据结构定义为一个数据和两个指针域,如:

快速记忆法:
前序就是父节点->左子树->右子树,中序是左子树->父节点->右子树,后序是左子树 -> 右子树 ->父节点
如这样一颗二叉树:
前序遍历输出为:ABDHIEJCFG
中序遍历输出为:HDIBJEAFCG
后序遍历输出为:HIDJEBFGCA
层次遍历结果为:ABCDEFGHIJ
参考原文:Private Variables in JavaScript
本文非直译,如有理解不对的地方,请指正。
近年来 Javascript 不断有新特性或语法加进来,不过还是始终保持一切皆对象的原则,基于运行时的概念,Javascript 并没有所谓的公共、私有属性的概念。
自 ES6 以后,虽然 Javascript 有了类,但不像 C、Java 那样有专门的修饰符来控制变量的访问权限,Javascript 所有的属性都需要在函数中定义。以下文章内容将介绍如何实现私有变量。
最简单粗暴的方式就是在团队中约定命名规范,通常是以下划线作为属性名称的前缀(e.g. _count)。其本质上并没有阻止变量的访问权限,仅仅是开发之间默认的规则,即不能乱引用和修改我的变量。
WeakMap 虽然不会阻止对数据的访问,但是它能将私有变量和用户的可操作对象分开,示例代码如下:
const map = new WeakMap();
// Create an object to store private values in per instance
const internal = obj => {
if (!map.has(obj)) {
map.set(obj, {});
}
return map.get(obj);
}
class Shape {
constructor(width, height) {
internal(this).width = width;
internal(this).height = height;
}
get area() {
return internal(this).width * internal(this).height;
}
}
const square = new Shape(10, 10);
console.log(square.area); // 100
console.log(map.get(square)); // { height: 100, width: 100 }以上代码中,将 WeakMap 的关键字设置为私有属性所属对象的实例,通过一个函数来管理返回值,如无则创建之,所有的属性将被存储在其中。在 Shape 实例中,遍历属性或者在执行 JSON.stringify 等都不会展示出实例的私有属性。
Symbol 的实现方式与 WeakMap 类似,不过这种实现方式需要为每个私有属性创建一个 Symbol,但是在类外还是可以访问该 Symbol,即还是可以拿到这个私有属性。示例代码如下:
const widthSymbol = Symbol('width');
const heightSymbol = Symbol('height');
class Shape {
constructor(width, height) {
this[widthSymbol] = width;
this[heightSymbol] = height;
}
get area() {
return this[widthSymbol] * this[heightSymbol];
}
}
const square = new Shape(10, 10);
console.log(square.area); // 100
console.log(square.widthSymbol); // undefined
console.log(square[widthSymbol]); // 10前面介绍的几种方式仍然允许从类外访问私有属性,闭包是将私有变量数据封装在调用时创建的函数作用域内,从内部返回函数的结果,从而使这一作用域无法从外部访问。闭包想必不用再介绍了吧,这里可以联想一下常出现的一到面试题:JavaScript 实现一个私有变量,每次调用一个函数自动加 1。
通俗的说 Proxy 在数据外层套了个壳,然后通过这层壳访问内部的数据,即在原对象的基础上进行了功能的衍生而又不影响原对象。理解如何使用 Proxy 实现私有变量,这里我们需要关注 set 和 get。
使用 Proxy 的方式是:let proxy = new Proxy(target, handler);,Proxy 构造函数中的两个参数具体是:
一个示例代码如下:
class Shape {
constructor(width, height) {
this._width = width;
this._height = height;
}
get area() {
return this._width * this._height;
}
}
const handler = {
get: function(target, key) {
if (key[0] === '_') {
throw new Error('Attempt to access private property');
}
return target[key];
},
set: function(target, key, value) {
if (key[0] === '_') {
throw new Error('Attempt to access private property');
}
target[key] = value;
}
}
const square = new Proxy(new Shape(10, 10), handler);
console.log(square.area); // 100
console.log(square instanceof Shape); // true
square._width = 200; // Error: Attempt to access private property如上代码,我们实例化了一个 Proxy,在 target 参数中引入了 Shape 对象,该类里边实现了两个变量,通过 square 是没法直接访问里边的 _width 和 _height 的,这就通过代理实现了私有变量的效果。
TypeScript 是 JavaScript 的超集,最终是编译为原生 JavaScript 用在生产环境。TS 支持指定私有、公共和受保护的属性,这里就不再像原文那样举例了。
需要提醒的是,使用 TypeScript 只有在编译时才能获知到这些类型,而私有、公共和受保护修饰符在编译时才起作用。所以,其实你可以使用 x.y 访问内部私有变量的,只不过 TypeScript 会在编译时给你报出一个错误,但不会停止它的编译。其实并不是真正意义上的私有变量,只是在开发编译的时候能够提醒到开发人员,间接达到实现私有变量的效果。
其实在 TC39 中已有提案引入 private fields,目前还在 Stage 3 阶段,它使用 # 符号表示它是私有的,# 的使用方式与以上提的命名约定方式非常类似,但对变量的实际访问权限提供了限制。
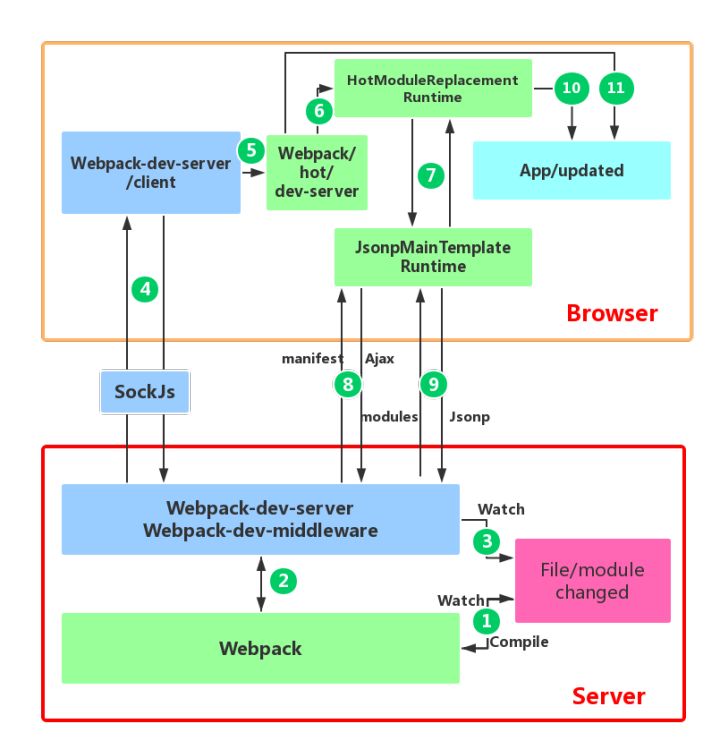
参考文章:Webpack HMR 原理解析
以下基于常见的攻击方式入手,对攻防方式和策略做一些总结。
CSRF(Cross Site Request Forgery),即跨站请求伪造,是常见的 Web 攻击之一,攻击过程示例图如下:

CSRF 利用用户已登录的身份,在当前用户毫不知情的情况下完成非法操作,通过上图总结攻击原理如下:
举个例子方便理解,用户登陆某银行网站,以 Get 请求的方式完成转账,攻击者可构造另一危险链接 B,并把该链接通过一定方式诱骗受害者用户点击。受害者用户若在浏览器打开此链接,会将之前登陆后的 cookie 信息一起发送给银行网站,服务器在接收到该请求后,确认 cookie 信息无误则完成该请求操作,造成攻击行为完成。
攻击者可以构造 CGI 的每一个参数,伪造请求,这也是存在 CSRF 漏洞的最本质原因。
1、验证码,在一些关键的节点操作加上验证码,但是该种方式一定程度上会降低用户体验
2、Referer Check,通过 Http header 的 referer 鉴定请求来源。但在某些情况下如从 https 跳转到 http,浏览器基于安全考虑,不会发送 referer,服务器就无法进行 check,所以这种方式不是 CSRF 的主要防御手段。
3、SameSite,可以对 Cookie 设置 SameSite 属性,但并不是所有浏览器都支持的。
4、Anti CSRF Token,比较完善的解决方案是加入 Anti-CSRF-Token。即发送请求时在 Http 请求中加入 token,并在服务器建立一个拦截器来验证 token。服务器读取浏览器当前域 cookie 中的 token 值,然后进行校验,即该请求中的 token 和 cookie 中的 token 值是否都存在且相等,才认为这是合法的请求,否则拒绝该次服务。
总结一下就是:
XSS(Cross Site Scripting),跨站脚本攻击。恶意攻击者往 Web 页面里注入恶意 Script 代码,当用户浏览这些网页时,就会执行其中的恶意代码,可造成对用户 cookie 信息盗取、会话劫持等各种攻击。
XSS 的攻击原理是往 Web 页面里插入可执行网页脚本代码,当用户浏览该页之时,嵌入其中的脚本代码会被执行,从而可以达到盗取用户信息或其他侵犯用户安全隐私的目的。有可能造成以下影响:
非持久型 XSS 漏洞,一般是通过给在 URL 参数中添加恶意脚本,当 URL 链接被打开后,特有的恶意代码参数被 HTML 解析、执行。
非持久型 XSS 漏洞攻击有以下几点特征:
预防非持久型 XSS 攻击,可以采取如下措施:
该种攻击一般存在于 Form 表单交互的提交,如文章留言,提交文本信息等。即将内容经正常功能提交进入数据库持久保存,当前端页面获得后端从数据库中读出的注入代码时,恰好将其渲染执行。
与 1 中非持久型注入不一样,其来源是之前非法提交的存储在数据库中的数据,持久型 XSS 攻击不需要诱骗点击,黑客只需要在提交表单的地方完成注入即可。
防御手段如下:
SQL 注入即攻击者利用这个漏洞,可以访问或修改数据,或者利用潜在的数据库漏洞进行攻击。
攻击者将 SQL 命令插入到 Web 表单提交或在表单输入特殊字符,最终达到欺骗服务器执行恶意的 SQL命令。一次 SQL 攻击大致过程是:获取用户请求参数,拼接到代码当中,SQL语句按照我们构造参数的语义执行成功。SQL 注入可能是因为:
select * from users where userid=123; DROP TABLE users; 直接导致 users 表被删除DoS(Denial of Service),即拒绝服务,造成远程服务器拒绝服务的行为被称为 DoS 攻击。其目的是使计算机或网络无法提供正常的服务,最常见的 DoS 攻击有计算机网络带宽攻击和连通性攻击。
为了进一步认识 DoS 攻击,需要了解 TCP 三次握手及数据段互换的过程,具体参考下图:

在 DoS 攻击中,攻击者通过伪造 ACK 数据包,希望 Server 重传某些数据包,Server 根据 TCP 重传机制,进行数据重传。攻击者通过发送大量的半连接请求,耗费 CPU 和内存资源,实现方式如下图:

Web 服务器在未收到客户端的确认包时,会重发请求包一直到链接超时,才将此条目从未连接队列删除。攻击者再配合IP欺骗,SYN 攻击会达到很好的效果。通常攻击者在短时间内伪造大量不存在的 IP 地址,向服务器不断地发送 SYN 包,服务器回复确认包,并等待客户的确认,由于源地址是不存在的,服务器需要不断的重发直至超时,这些伪造的 SYN 包将长时间占用未连接队列,正常的 SYN 请求被丢弃,目标系统运行缓慢,严重者引起网络堵塞甚至系统瘫痪。
SYN 攻击的问题就出在 TCP 连接的三次握手中,假设一个用户向服务器发送了 SYN 报文后突然死机或掉线,那么服务器在发出 SYN+ACK 应答报文后是无法收到客户端的 ACK 报文的,从而导致第三次握手无法完成。在这种情况下服务器端一般会重试,即再次发送 SYN+ACK给 客户端,并等待一段时间后丢弃这个未完成的连接。这段时间的长度我们称为 SYN Timeout,一般来说这个时间是分钟的数量级,大约为30秒到2分钟。但如果有一个恶意的攻击者大量模拟这种情况,服务器端将为了维护一个非常大的半连接列表而消耗非常多的资源,即数以万计的半连接,将会对服务器的CPU和内存造成极大的消耗。
对于该类问题,可以做如下防范:
一般来说,第三种方法在防范该类问题上表现更佳。同时可以在Web服务器端采用分布式组网、负载均衡、提升系统容量等可靠性措施,增强总体服务能力。
每当收到候选人简历中有 VUE 的免不了提问“如何实现数据的双向绑定”,往往很多人都是浅尝辄止,简单来说,就是通过以下步骤实现双向绑定:
所以 VUE 双向绑定关键的一环就是数据劫持(Vue 2.x 使用的是 Object.defineProperty(),而 Vue 在 3.x 版本之后改用 Proxy 进行实现),数据劫持即在访问或修改对象的某个属性时,通过一段代码拦截这个行为,进行额外的操作如修改返回结果,以下专门梳理一下 Javascript 的数据劫持。
通过 Object.defineProperty() 来劫持对象属性的 setter 和 getter 操作,在数据变动时做你想要做的事情,示例代码如下:
Object.defineProperty(obj, key, {
get() {
// 相关操作,最终 return
},
set(newVal) {
// 一些 handle 操作
}
})Object.defineProperty 有它存在的问题,比如不能监听数组的变化,对 object 劫持必须遍历每个属性,可能存在深层次的嵌套遍历。那还有没有比 Object.defineProperty 更好的实现方式呢?
在上一篇文章中已经有提及到 Proxy。
Proxy 的构造函数能够使用代理模式,即 let proxy = new Proxy(target, handler);,Proxy 构造函数中的两个参数具体是:
Proxy 其内部功能十分强大的,有13种数据劫持的操作,如get、set、has、ownKey(获取目标对象的所有 key)、deleteProperty等,下面主要梳理 set、get。
get 即在获取到某个对象属性值的时候做预处理的方法,其有两个参数:target、key,示例代码如下:
let Obj = {};
let proxyObj = new Proxy(Obj, {
get: function(target, key) {
// 如通过 target 判断某个属性是否符合预期
if (target[‘xx’] > 80) {return “该考生优秀!”}
else if (!/^[0-9]+$/.test(key)) {return “学号格式不对!”}
return Reflect.get(target, name, receiver); // Reflect 见文章最后的总结
}
});set 即用来拦截某个属性赋值操作的方法,可以接受四个参数:
还是沿用上面的例子,比如一个考试成绩录入的校验,代码如下:
let validator = {
set: function(target, key, value) {
if (key === 'score') {
if (!/^[0-9]+$/.test(value)) {
throw new TypeError(‘分数必须为整数');
}
if (value > 100) {
throw new TypeError(‘成绩满分为 100');
}
}
// 对于满足条件的属性直接写入
target[key] = value;
}
};
let proxy = new Proxy(obj, handler);
// ...Proxy 相对 Object.defineProperty,它支持对数组的数据对象的劫持,不用像 VUE 那样要对数据劫持的话,需要进行重载 hack。对于以上提到的嵌套问题,Proxy 可以在 get 里面递归调用 Proxy 即返回下一个”代理“来完成递归嵌套,可以说 ES6 的 Proxy 就是对 Object.defineProperty 的改进和升级。关于嵌套举例如下:
let obj = {
0801080132: {
name: ‘Jason',
score: 99
},
// …
};
let handler = {
get (target, key, receiver) {
// 如果属性值不为空或者是一个对象,则继续递归
if (typeof target[key] === 'object' && target[key] !== null) {
return new Proxy(target[key], handler)
}
return xxx // 返回业务数据
}
}
let proxy = new Proxy(obj, handler)Proxy 本质上就是在数据层外加上代理,通过这个代理实例访问里边的数据,这就是 Proxy 实现数据劫持的方式。总结一下:
注,下文大致意译至 inside-browser-part2
上文理解了相关概念之后,本文我们将开始研究这些进程和线程之间发生了什么,如何显示一个网站内容。
我们从一个经典的面试题说起:在浏览器中输入 URL 并点回车后,浏览器内部究竟发生了什么?(also known as a navigation)
一切从浏览器进程开始
通过前文的知识我们知道,在浏览器 Tab 以外发生的操作都是由 browser process 控制的,浏览器进程常见的一些线程为:
当用户在导航栏输入信息的时候 UI 线程要进行一系列的解析,用来判定是将用户输入信息发送给搜索引擎还是直接请求你输入的站点资源。
当按下回车后,UI 线程将初始化网络请求并返回站点内容,此时 Tab 前的图标展示为加载中状态,然后网络进程进行一系列诸如 DNS 寻址,建立 TLS 连接等操作进行资源请求。这时如果收到服务器的 HTTP 301 重定向响应,它将会告知 UI 线程进行重定向然后它会再次发起一个新的网络请求。
一旦响应体开始响应返回,在必要的情况下它会先检查一下流的前几个字节,然后根据响应头中的 Content-Type 字段来确定响应主体的媒体类型(MIME Type),不过 Content-Type 有时候会缺失或者是错误的。
如果响应体是一个 HTML file,则将响应数据交给渲染进程来进行下一步的工作,如果是 zip 压缩文件或者其它类型的文件,这意味着是一个下载请求,则会把相关数据传输给下载管理器。
这也是浏览器会进行 SafeBrowsing 检查发生的地方,如果请求的域名和响应的内容匹配到某个已知的病毒站点,网络线程将给用户展示一个警告的页面。除此之外,网络线程还会做 Cross Origin Read Blocking(CORB)检查来确定那些敏感的跨站数据不会被发送至渲染进程。
一旦做完各种检查以后,网络线程确信浏览器可以导航到请求的站点,网络线程将告诉 UI 线程所有数据已经准备完毕,UI 线程接下来寻找一个渲染引擎来渲染页面。
网络请求是有耗时的,浏览器需要对查找渲染进程这一步骤进行优化。在第二步开始,浏览器已经知道要导航的站点,那么 UI 线程预加载一个渲染进程,如一切符合预期则直接用渲染引擎渲染页面即可,否则,如果遇到重定向,这个准备好的渲染进程也许就用不到了,它会被摒弃,这时将会重启一个渲染进程。
到这一步的时候,数据和渲染引擎都已经准备好了,浏览器进程通过 IPC 通知渲染进程去提交本次导航,除此之外,浏览器进程还会将刚刚接收到的响应数据流传递给对应的渲染进程让它继续接收到来的 HTML 数据,一旦浏览器进程监听到渲染引擎的导航已经被提交的消息,则导航这个过程就结束了,进入到文档的加载阶段。
到了这个时候,导航栏会被更新,安全指示符(地址前面的小锁)和站点设置 UI(site settings UI )会被更新,会话历史列表(history tab)也会被更新,这样即可以通过前进后退来切换该页面。
一旦导航(navigation)完成提交,渲染引擎开始着手加载资源以及渲染页面,后续的文章将继续介绍渲染细节。一旦渲染引擎完成渲染,它会通过 IPC 告知浏览器进程(页面及内部的 iframe 页面都触发了 onload 事件),到这个点,UI 线程将停止加载转圈。
额外的补充,慎用 beforeunload 事件,定义的监听函数会在页面被重新导航的时候执行到,因此这会增加重导航的时延。
欲了解更多,请关注或阅读 an overview of page lifecycle states 和 the Page Lifecycle API。
service worker 可以用来做网络代理或者缓存控制,目的在于给开发者更多的控制权限。
需要重点留意的是 service worker 只是一些跑在渲染进程里面的 JavaScript 代码。那么当有一个导航请求过来,浏览器进程是如何知道有一个 service worker 的呢?
当 service worker 在注册的时候,它的作用范围(scope)被当成一个实例被记录下来(欲了解更多,阅读 The Service Worker Lifecycle ),在导航开始的时候,网络线程会根据请求的域名在已经注册的 service worker 作用范围里面寻找有没有对应的 service worker 实例,如这个 URL 有注册过,UI 线程将寻找一个渲染引擎来执行它的代码,这样,service worker 可能使用之前缓存的数据,也可能发起新的网络请求。

网络线程在收到导航任务后查找 URL 对应的 service worker 实例
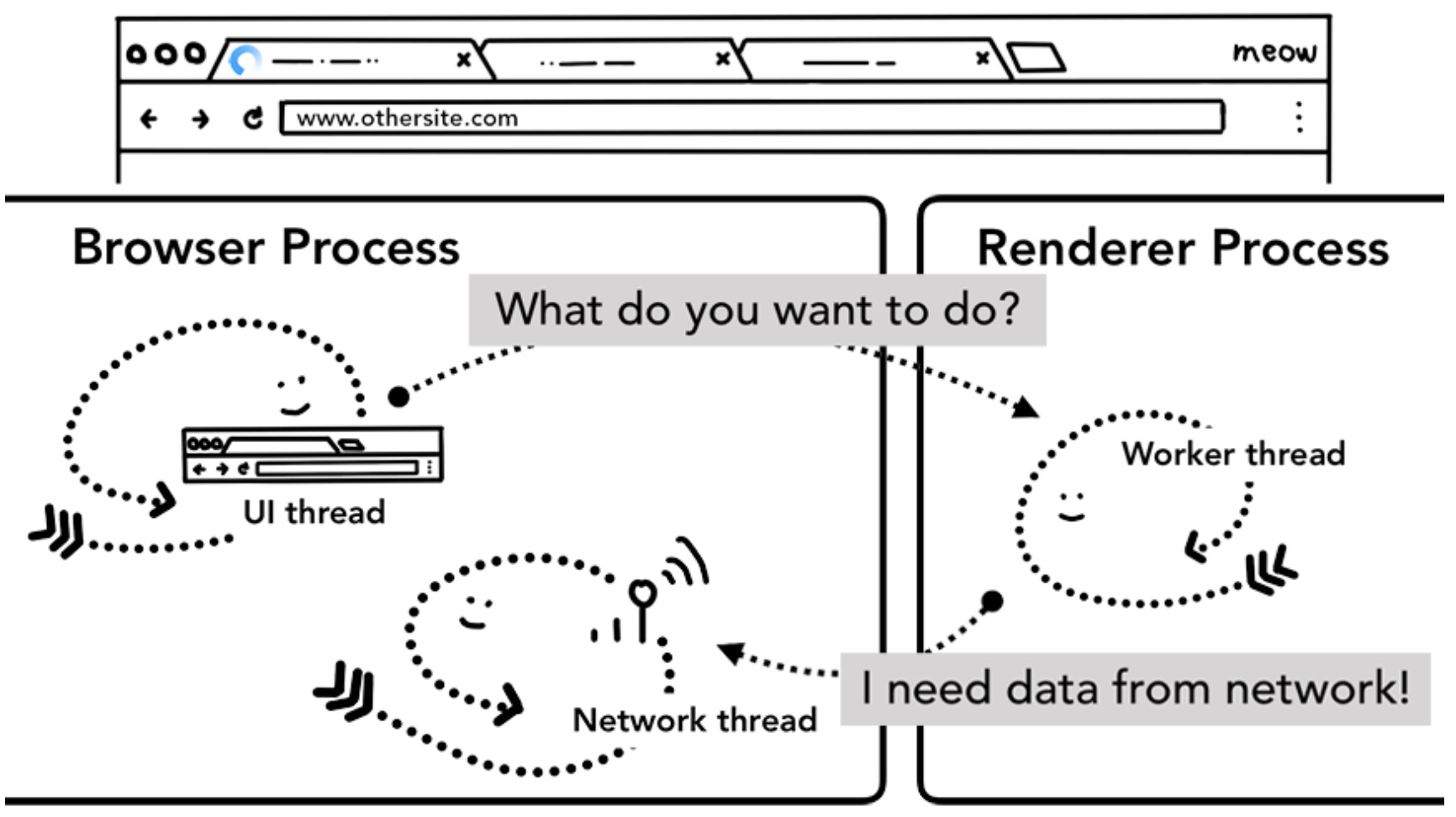
UI 线程会启动一个渲染进程来运行 URL 对应的 service worker 代码
本文讨论了导航具体都发生了哪些事情以及浏览器优化导航效率采取的一些技术方案,下文继续了解浏览器如何解析 HTML/CSS/JavaScript 并渲染页面的。
fiber 作为一种数据结构,用于代表某些 worker,换句话说,就是一个 work 单元,通过 Fiber 的架构,提供了一种跟踪,调度,暂停和中止工作的便捷方式。
异步渲染 Dan 提出的异步渲染的概念,异步渲染即在以异步的方式加载的同时给人以同步流程的体验,在老设备上,通过牺牲一些加载时间来获得一种流畅的体验。其实在 React@16 版本中,异步渲染默认是关闭的。
生命周期变更 在 react@16 版本中,虽然依旧支持之前的生命周期函数,但是官方已经说明在下个版本中会将废弃其中的部分,这么做的原因,主要是 reconciliation 的重写导致。在 render/reconciliation 的过程中,因为存在优先级和时间片的概念,一个任务很可能执行到一半就被其他优先级更高的任务所替代,或者因为时间原因而被终止。当再次执行这个任务时,是从头开始执行一遍,就会导致组件的某些 xxxwill 生命周期可能被多次调用而影响性能。
react@16 与其说是一个分水岭,不如说是一个过渡,react@17 才会是掀起风浪的那一个。
递归算法是一种直接或者间接调用自身函数或者方法的算法。
递归算法的实质是把问题分解成小规模的同类问题,这些同类问题作为子问题递归调用来表示问题的解。特点如下:
下面通过爬台阶问题来理解一下递归算法,问题描述:一个人爬楼梯,每次只能爬1个或2个台阶,假设有n个台阶,那么这个人有多少种不同的爬楼梯方法?
套用以上的递归特点,思考如下:【问题拆分】可以根据第一步的走法把所有走法分为两类:
所以 n 个台阶的走法就等于先走 1 阶后,n-1 个台阶的走法 ,然后加上先走 2 阶后,n-2 个台阶的走法。
用公式表示就是:
f(n) = f(n-1)+f(n-2)
有了递推公式,递归代码基本上就完成了一半。那么接下来考虑【递归终止条件】。
从以上公式得知,最终出口是f(2)、f(1)。当有一个台阶时,我们不需要再继续递归,就只有一种走法,即 f(1)=1。f(2) 表示走 2 个台阶,有两种走法,一步走完或者分两步来走,即 f(2)=2。
总结以上思路,递归条件基本如下:
f(1) = 1;
f(2) = 2;
f(n) = f(n-1)+f(n-2)
翻译成代码如下:
/**
* @param {number} n
* @return {number}
*/
var climbStairs = function(n) {
if (n == 1) return 1;
if (n == 2) return 2;
return climbStairs(n-1) + climbStairs(n-2);
};本文将深入理解一下渲染引擎在渲染页面的时候具体都发生了什么事情。
渲染引擎会触碰到 Web 性能的方方面面,欲了解更多请关注 the Performance section of Web Fundamentals。
渲染引擎负责 Tab 页面内发生的所有事情,主线程处理了大部分用户加载到的代码,如若使用了 web worker 或 service worker,与之相关的代码将会由 worker thread 处理。
渲染进程的主要任务是将 HTML,CSS,以及 JavaScript 转变为我们可以进程交互的网页内容。
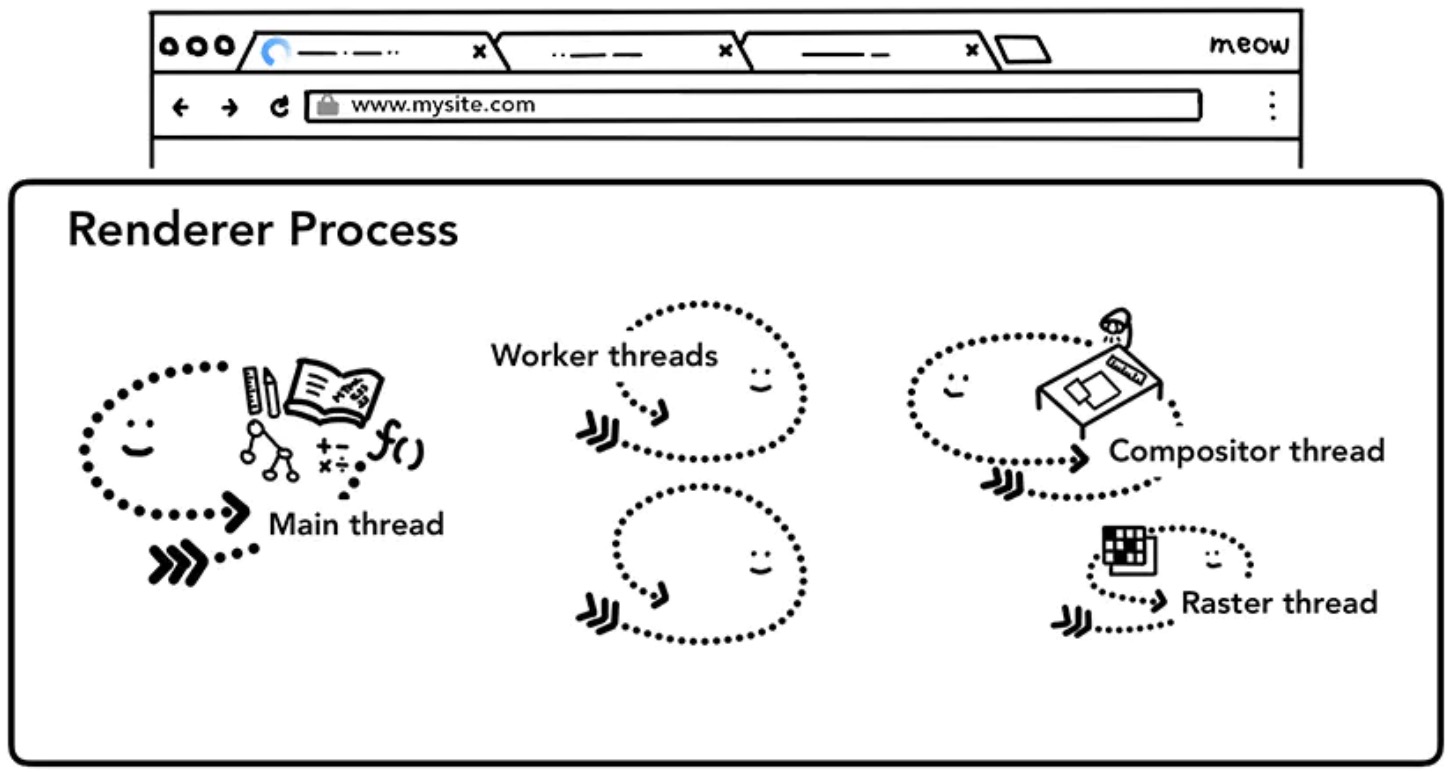
渲染进程中包含线程有:
blog issue 中已有类似的文章,这里不再原文翻译,具体请参考 浏览器渲染及性能优化
husky 安装后,可以很方便的在 package.json 配置 git hook 脚本。
"husky": {
"hooks": {
"pre-commit": "lint-staged",
"commit-msg": "commitlint -E HUSKY_GIT_PARAMS"
}
},
"lint-staged": {
"*.js": [
"eslint --fix",
"git add"
]
},
Feedly 的工程师 Andrey Okonetchnikov 开发的 lint-staged 就是基于这个想法,其中 staged 是 Git 里面的概念,指待提交区,使用 git commit -a,或者先 git add 然后 git commit 的时候,你的修改代码都会经过待提交区。那么就可以在这里做 lint 操作。
commit-msg 搭配 commitlint,它可以帮助我们 lint commit messages,如果我们提交的 log 不符合规范,直接拒绝提交。可以在 config 配置文件中优化相关信息。
module.exports = {
extends: ['@commitlint/config-conventional'],
rules: {
'scope-case': [2, 'always', ['lower-case', 'pascal-case', 'camel-case']],
'subject-case': [2, 'never', []]
}
};
目前我们的工作量和他们类似:
如我们项目中 package.json script 中{ "bump": "SKIP_TAG=true npm run release"},去执行5、6、7、8的操作。
React Hooks 是 React 16.7.0-alpha 版本推出的新特性,文章一下都简称 hooks。
hooks 与 Redux/mobx 解决的不是同一类问题,Redux/mobx 解决的状态共享问题:
hooks 其根本不是解决状态共享的问题,解决的问题是如何抽离、复用与状态相关的逻辑,是继 render-props 和 higher-order components 之后的第三种状态共享方案,不会产生如类组件 JSX 嵌套地狱问题。
hooks 的好处是:
在 hooks 之前,开发组件主要是类组件和函数组件,函数组件没有 state,只能简单的将 props 映射成 view。useState 让开发者能够在函数组件里面拥有 state 并能修改 state。一个简单的例子:
import React, { useState } from 'react';
function Example() {
// Declare a new state variable, which we'll call "count"
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}useEffect 是用于处理各种状态变化造成的副作用,也就是说只有在特定的时刻,才会执行的逻辑。
hooks 的特点是方便 connect 一切,包括通 HTTP 获取数据流、异步事件监听与派发等都可以使用之,利用 useEffect 也可以代替一些生命周期,如事件订阅与销毁。useEffect 就是用来处理这些功能可能产生的副作用的,以下通过 Http 获取数据填充模板来说明。
function App () {
const [data, setData] = useState({ xx: [] });
useEffect(async () => {
const result = await fetch(xxx);
setData(result.data);
}, []);
return (
<ul>
{data.xx.map(item => (
// ...
))}
</ul>
);
}通过 useEffect 来处理副作用,传递一个空数组作为 useEffect 的第二个参数,这样就能避免在组件更新执行 useEffect 而造成的死循环。
useEffect 的第二个参数可用于定义其依赖的所有变量。如果其中一个变量发生变化,则 useEffect 会再次运行。如果包含变量的数组为空,则在更新组件时 useEffect 不会再执行,因为它不会监听任何变量的变更。
利用 hooks 来创建一个 useReducer,代码如下:
function useReducer(reducer, initialState) {
const [state, setState] = useState(initialState);
function dispatch(action) {
const nextState = reducer(state, action);
setState(nextState);
}
return [state, dispatch];
}一个使用 useReducer 的例子:
function todosReducer(state: ImmutableType<State> = initialState, action: Action) {
switch (action.type) {
case XXX:
return nextState; // 伪代码
default:
return state;
}
}
// action useTodos
function useTodos() {
const [todos, dispatch] = useReducer(todosReducer, []);
return [todos, dispatch({ type: "add", text })];
}不过需要注意的是,每次使用 useReducer 都是局部的数据状态管理,不会像 redux 一样可以全局持久化,如果要维持一个全局状态,可以搭配 useContext 一起使用。一个比较好的最佳实践可以参考 redux-react-hook。
开发者需要遵循的两条规则:
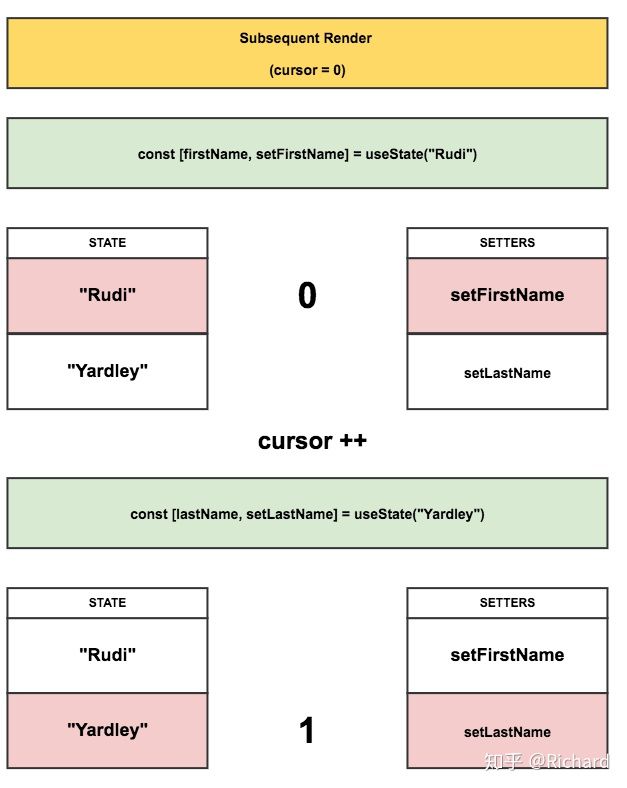
正如这篇博文 React hooks: not magic, just arrays 所描述的那样,hooks 就是通过一张类链表的关系来维持 state 和 setters 的关系,即初始化的时候,创建两个数组 state 和 setters,cursor 设置为 0,第一次调用 useState 的时候,会将 setXX 函数放入到 setters 数组中,把 useState 的初始化数据放入到 state 数组中。以此类推,需要注意的是,每一次重新渲染,cursor 都会重置为 0。
可以参考以上原文的 useState 对应数组变化的流程图:
有了以上的基础,我们更进一步,useState 本身是无状态的,那么它是如何获取前一次的 state 做 diff 的呢?
在执行函数组件的 useState 的时候,在对应的 Fiber 对象上 memoizedState 记录对应关系,返回 useState 执行的结果,而 next 指向的是下一次 useState 对应的 hook 对象,即:
hook1 => Fiber.memoizedState
state1 === hook1.memoizedState
hook1.next => hook2
state2 === hook2.memoizedState
hook2.next => hook3
state3 === hook2.memoizedState这也就能和以上流程对应起来了,确实是一个 just Array 的关系。现在看看开头标明的,hooks 不能使用嵌套,循环和条件判断中,正是因为 state 和 setters 的一一对应关系,如上三个 hooks 的例子,如果下次执行 useState 的时候,因为如某个判断条件导致某个 useState 没执行,那么这个一一对应关系就乱套了。
那么最后,执行 useState 后如何更新 state 并执行 render 呢,和前面提到的 setState 一样的,可以参考关于 React setState,你了解多少? 。
todos:
参考:
历史上,计算机语言分为两组:静态语言(例如,Fortran 和C,其中变量类型是在编译时静态指定的)和动态语言(例如,Smalltalk 和JavaScript,其中变量的类型可以在运行时改变),主要区别是变量类型的确定。
静态语言通常编译成目标机器的本地机器代码(或汇编代码)程序,该程序在运行时直接由硬件执行。动态语言由解释器执行,不产生机器语言代码。
后来,虚拟机(VM)的概念开始流行,它其实只是一个高级的解释器,虚拟机使语言移植到新的硬件平台更容易。因此,VM 的输入语言常常是中间语言。例如,一种编程语言(如 Java )被编译成中间语言(字节码),然后在VM( JVM )中执行。
另外,现在有即时(JIT)编译器。JIT 编译器在程序执行期间运行,即时编译代码。而原先在程序创建期间,运行时之前执行的编译器称为 AOT 编译器。
一般来说,静态语言才适合 AOT 编译为本地机器代码,因为机器语言通常需要知道数据的类型,而动态语言中的类型事先并不确定。因此,动态语言通常被解释或 JIT 编译。
在开发过程中,AOT 编译开发周期长(从更改程序到能够执行程序以查看更改结果的时间),总是很慢。但是 AOT 编译产生的程序可以更可预测地执行,并且运行时不需要停下来分析和编译。AOT 编译的程序也更快地开始执行(因为它们已经被编译)。
与此相反的是,JIT 编译提供了更快的开发周期,但可能导致执行速度较慢或时快时慢。特别是,JIT 编译器启动较慢,因为当程序开始运行时,JIT 编译器必须在代码执行之前进行分析和编译。
以上就是背景知识。
翻译的这篇文章中,我将深入探讨angular2的变化监测系统。
一个angular2应用是一个组件树。

一个angular2应用是一个反应系统,变化监测是它的核心。

每一个组件都会有一个负责检查其模板中定义的绑定的更改检测器,例如这样的绑定:{{todo.text}}和[todo]=”t”。变化监测是由根到叶的深度优先顺序来传播绑定的。
Angular2没有一种通用的机制来实现数据的双向绑定(不过你任然可以实现数据绑定行为和ng-model,阅读这里了解更多)。这就是为什么上图的变化监测图是一颗定向的树并且不是循环的(也就是说是一种树形图),这使得系统的性能变现更好,更重要的是,我们将保障系统更易于预测和调试。
那它到底有多快呢?
默认情况下,变化检测通过树的每一个节点来检查它是否改变了,并且在每一浏览器事件都实现了它。尽管它看起来非常的低效,但在几毫秒内,Angular2变化监测系统能通过成百上千次简单的检查(次数依赖于不同的平台)。
因为在JavaScript语言中不提供给我们对象的变化通知,所以Angular必须保守的要每一次运行所有的检测。但是我们可能知道我们的某些可确定性的属性,例如使用不可改变的或可观察的对象,以前angular不能利用这些,但是现在可以。
如果一个组件仅仅只依赖于它的输入属性,并且它是不可变的,那么当其绑定属性变化时该组件也会发生改变,因此我们可以跳过该组件的子树变化监测,直到这样的一个属性事件发生变化。当事件发生时,我们能立马监测子树,然后禁用它,直到下一次的变化(灰色的框框代表禁用了变化监测)。

如果我们使用不可变对象,一个大的变化检测树大部分时间都是被禁用的。

实施这个监测是微不足道的,仅仅是设置了一个变化监测策略到Onpush这个方法上。
@Component({changeDetection:ChangeDetectionStrategy.OnPush})
class ImmutableTodoCmp {
todo:Todo;
}
如果一个组件仅仅依赖于它的输入属性,并且它是可观测的,那么该组件会随着它的输入属性触发一个事件来改变。因此我们能跳过该组件变化监测树的子树直到这样一个事件被触发,当它发生改变,我们监测一次子树,并且禁用它直到下一次变化。
尽管表面上看它可能类似于不可变对象,但还是完全不同的。如果你有一个组件树使用不可变对象绑定,一个变化必须经历从根开始的所有组件检查,使用可观察对象则不会有这种情况。
让我举一个小例子演示这个问题
type ObservableTodo = Observable<todo>;
type ObservableTodos = Observable<array>>;
@Component({selector:'todos'})
class ObservableTodosCmp {
todos:ObservableTodos;
//...
}
ObservableTodosCmp模板为
<todo *ngFor="#t of todos" todo="t"></todo>
最后的ObservableTodosCmp为:
@Component({selector:'todo'})
class ObservableTodoCmp {
todo:ObservableTodo;
//...
}
正如你所看到的,这里Todos组件只引用到一个可观察的todo数组。所以在一个Todo中看不到变化。
当这个可监测的todo触发一个事件,该事件处理句柄将会从根的路径到那个改变的Todo组件来处理监测。
如我们仅仅使用了可观测对象,当我们启动它,Angular将会监测所有的对象。

所以第一遍监测过后的状态如下
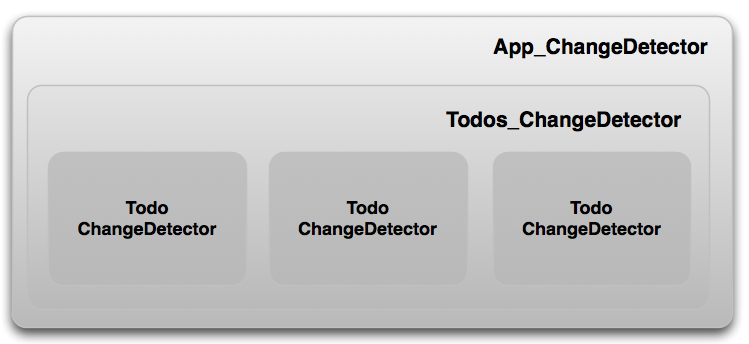
来看看第一个可变化的todo触发一个事件,该系统将会转换到下面的状态

在监测了App_ChangeDetector, Todos_ChangeDetector和第一个Todo_ChangeDetector后,它将变回这个状态
假设变化的发生很少并且是一颗平衡的组件数,使用可观察者对象的变化检查的复杂度从O(N)到O(logN),其中的N是绑定系统的数目。
这种能力不需要依赖于任何特殊的库,任何一个可观测的库的实现就是那么几行代码。
可观察到的对象有坏名声,因为它们会导致级联更新。任何有使用过依赖于可观测模块框架来构建大型应用的人都知道我在讲什么。一个可观测对象的更新能导致一串其它可观测对象触发更新,也在做同样的事情,沿途的视图也将会被更新,这样的系统是很难去debug的。
在Angular2中使用可观测的对象显然不会有这样的问题,一个可观测对象的事件触发仅仅是作为下次从当前目录到组件跟目录的监测,然后,通过节点树的深度优先的顺序启动正常的变化检测过程,因此更新的顺序不会因为你是否使用过可观测对象而改变,这是非常重要的。使用可观测对象成为了一种简单的性能优化但不会改变你对系统的认知。
答案是否定的,你没必要这么做。你可以使用到你应用的某一处(例如某处一张巨大的表),这块的性能将会受益,更有甚者,你可以构建不同的组件来使他们的性能最优,举个例子,一个“可观测的组件”可以包含一个“不可变属性的组件”,该“不可变属性组件”本身可以包含一个“可观测的组件”,即使在这样的情况下,变化检测系统将减少所需的传输的数量的变化。
对不可变属性和可观测对象的支持不需要(baked into)变化监测,这种类型的组件不需要用一种特殊的方式来处理,所以你可以使用一种智能方式的变化监测来写你的指令,举个例子,想象一下你的内容每N秒更新一次。
http://victorsavkin.com/post/110170125256/change-detection-in-angular-2
关于创建对象,最普通的办法就是工厂模式,工厂模式虽然解决了创建多个相似对象的问题,但却没有解决对象识别的问题(即怎样知道一个对象的类型)。
一个简单的构造函数如下:
function Person(name, age, job){
this.name = name;
this.age = age;
this.job = job;
this.sayName = function() {alert(this.name); };
}使用构造函数的主要问题,就是每个方法都要在每个实例上重新创建一遍,如上每个实例都有一个名为 sayName() 的方法,但那两个方法不是同一个 Function 的实例。解决办法是构造函数中的方法指向某个外部函数,这样做问题是多个方法没有封装性。
原型模式不必在构造函数中定义对象实例的信息,而是可以将这些信息直接添加到原型对象中,如下面的例子所示:
function Person(){}
Person.prototype.name = "Nicholas”;
Person.prototype.age = 29;
Person.prototype.job = "Software Engineer”;
Person.prototype.sayName = function(){ alert(this.name); };创建的每个函数都有一个 prototype(原型)属性,这个属性是一个指针,指向原型对象, 该对象是所有实例共享的属性和方法,简单说就是 prototype 是通过调用构造函数而创建的那个对象实例的原型对象。使用原型对象的好处是可以让所有对象实例共享它所包含的属性和方法,与构造函数模式不同的是,新对象的这些属性和方法是由所有实例共享的。
可以通过下图来理解上面的表述:
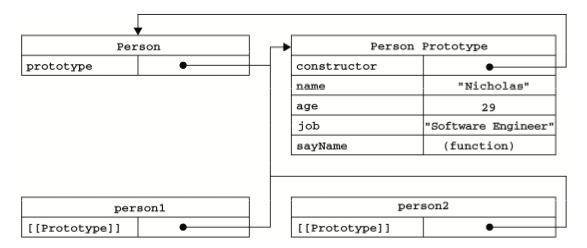
tips: 使用 hasOwnProperty() 方法可以检测一个属性是存在于实例中,还是存在于原型中;通过 isPrototypeOf() 方法来确定是否是对象实例。
更简单的原型语法是使用对象字面量来重写这个原型对象,但通过 constructor 已经无法确定对象的类型了,也可以使用如下方式操作。
function Person(){}
Person.prototype = {
constructor : Person,
// ...
};原型模式的问题是,它省略了为构造函数传递初始化参数这一环节,结果所有实例在默认情况下都将取得相同的属性值,原型模式的最大问题是由其共享的本性所导致的。如在原型对象里边有一引用型属性,那么对象实例的修改,就会对其他对象实例造成影响。
解决办法是组合使用构造函数和原型模式,下面的代码解决了前面提到的问题。
function Person(name){
this.name = name;
this.friends = ["Shelby", "Court"];
}
Person.prototype = {
constructor : Person,
sayName : function(){alert(this.name);}
}在这个例子中,实例属性都是在构造函数中定义的,而由所有实例共享的属性 constructor 和方法 sayName() 则是在原型中定义的。而修改了某一个对象实例的 friends并不会影响到其他对象实例的 friends,因为它们分别引用了不同的数组。
用以下关系图来总结上面的内容:
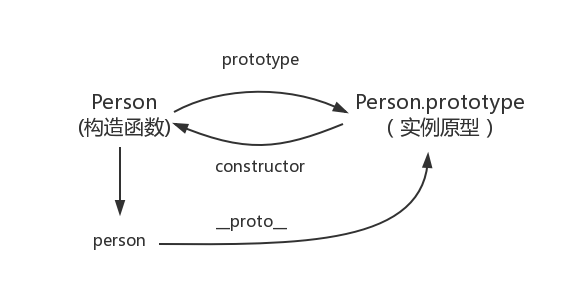
ECMAScript 中描述了原型链的概念,并将原型链作为实现继承的主要方法。其基本**是利用原型让一个引用类型继承另一个引用类型的属性和方法。实现继承是让原型对象等于另一个类型的实例,此时的原型对象将包含一个指向另一个原型的指针,相应地,如此层层递进,就构成了实例与原型的链条,这就是所谓原型链的基本概念。关系图如下:
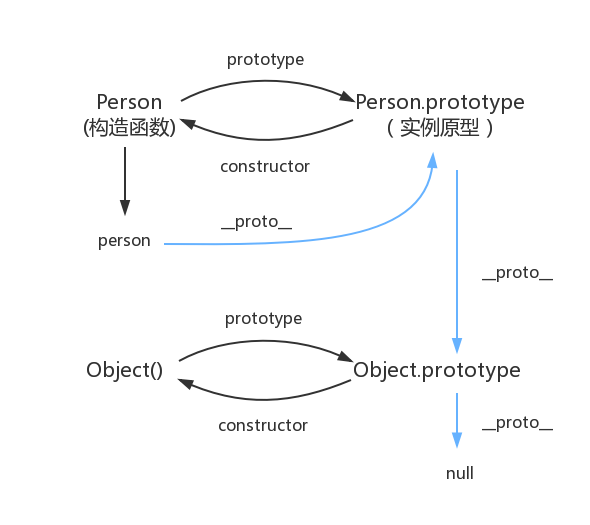
原型链的问题有:
那么除了直接使用原型实现继承,还有其他的方式吗?
这种技术的基本**相当简单,即在子类型构造函数的内部调用超类型构造函数,示例代码如下:
function Person(name, age) {
this.name = name,
this.age = age,
this.setName = function () {}
}
Person.prototype.setAge = function () {}
function Student(name, age) {
Person.call(this, name, age);
// ...
}这种方式只是实现部分的继承,如果父类的原型还有方法和属性,子类是拿不到这些方法和属性的,若将其写在构造函数中复用就无从谈起了。
其背后的思路是使用原型链实现对原型属性和方法的继承,而通过借用构造函数来实现对实例属性的继承。这样,既通过在原型上定义方法实现了函数复用,又能够保证每个实例都有它自己的属性。
function SuperType (name) {
this.name = name,
this.color = [‘red’, ‘blue'];
}
SuperType.prototype.setAge = function () {
// ...
}
function SubType (name, age) {
SuperType.call(this, name);
this.age = age;
}
SubType.prototype = new SuperType();
SubType.prototype.setAge = function () {
// ...
}组合继承的优点是可以继承实例属性,也可以继承原型方法,解决了引用属性的共享问题,可传参,缺点是调用了两次父类构造函数,生成了两份实例。
那要优化生成两份实例的问题,可以使用 SubType.prototype = new prototype; 的方式,缺点是没办法辨别实例是子类还是父类创造的。
直接上高级程序设计上的代码示例吧:
function object(original){
function F() {}
F.prototype = original;
return new F();
}
function inheritPrototype(subType, superType) {
var prototype = object(superType.prototype);
prototype.constructor = subType;
subType.prototype = prototype;
}
function SuperType(name) {
this.name = name;
this.colors = ["red", "blue", "green"];
}
SuperType.prototype.sayName = function() {alert(this.name); };
function SubType(name, age) {
SuperType.call(this, name);
this.age = age;
}
inheritPrototype(SubType, SuperType);
SubType.prototype.sayAge = function(){alert(this.age);}这个例子的高效率体现在它只调用了一次 SuperType 构造函数,并且因此避免了在 SubType. prototype 上面创建不必要的、多余的属性,且原型链还能保持不变;因此,还能够正常使用 instanceof 和 isPrototypeOf()。
ES6 的继承机制与之前的方式完全不同,实质是先将父类实例对象的属性和方法,加到 this 上面(所以必须先调用 super 方法),然后再用子类的构造函数修改 this,其本质还是原型链的继承。
最近在开发金钥匙经理端 RN 版本的时候,经常会用到组件生命周期的相关的方法,刚开始接触有些迷糊,现在整理 React Native 组件的结构和生命周期。
每一个组件都有一些生命周期方法,通过重写这些方法方便在程序运行的过程中使用。如带有 will 的方法被执行则表示某个状态的发生,RN 中的生命周期方法大致归类如下三类:
表示调用某个被创建的组件实例
这两个回调函数分别表示组件最初被创建渲染后调用,用来获取初始化的 state 和 props,这两个方法在组件中全局只被调用一次。
在组件第一次绘制之后,会调用 componentDidMount(),通知组件已经加载完成,需要注意的是,这个阶段不会重新渲染组件视图
该方法在组件中是必须的,一旦调用,则去检查 this.props 和 this.state 的数据并返回一个 React 元素。render() 方法不能修改组件的 state,同时需要注意的是,shouldComponentUpdate() 方法必须返回 true,否则将不会再执行 render() 方法。
这个组件方法表示在组件第一次绘制之后,componentDidMount() 会被调用,用来通知组件已经加载完成,通常我们会在这里去从服务器拉取数据来渲染页面。
表示 props 或者 state 的改变,将会导致组件的重新渲染
表示组件收到了新的属性(props),调用 componentWillReceiveProps() 来进行某些操作,通常用来更新 state 的状态,在这通过比较 this.props 和 nextProps 来 setState。
当组件接收到新的 state 和 props 改变,该方法将会被触发调用。与前一个方法类似, nextProps 用来比较 state 和 props 是否有改变,通过检查来决定 UI 是否需要更新(返回 true 或 false),在一定程度上可以提高性能。
表示开始准更新组件,即调用 render() 来更新界面,该方法被调用的条件是 shouldComponentUpdate() 方法最终返回 true。需要注意的是,在这个函数里面,不能使用 this.setState 来修改状态。
表示调用 render() 方法完成了界面的更新,需要注意的是,该方法在初始的 render 中将不会被调用。
组件的销毁阶段
componentWillUnmount 表示组件即将被销毁或退出该组件,在这里常用来移除一些功能方法,如timeout事件或者abort相关的request。
生命周期表示从开始生成到最后销毁所经历的状态,网上已有很好的路程图,收藏该流程图如下:

从图中可以清晰的划分为以下三类:
通过前面的图可以看出,在生命周期函数中只有以下三个才能调用 setState() 方法的,这些方法为:componentWillMount、componentDidMount、componentWillReceiveProps。
团队中不少开发同事基本使用的是 --no-ff 的方式合并,但是这样会有很多无用的 commit log 信息,且 git log graph 不够线性。下面参考别人的动图,总结一下git的四种 merge 方式。
git 中的分支其实就是一类文件记录了分支所指向的 commit id,以下都用 master 和 test 分支举例。
如果待合并的分支在当前分支的下游,也就是说没有分叉时,快速合并是不错的选择。这种方法相当于直接把 master 分支 HEAD 指针移动到了 test 分支最近的一次提交,如下图:

快速合并给人的感觉是不知道主干分支 master 代码合并自哪里,其实可以强制指定为非快速合并,只需加上 --no-ff 参数,如:git merge –no-ff test。这种合并方法会在 master 分支上新建一个提交节点,从而完成合并,如下图:
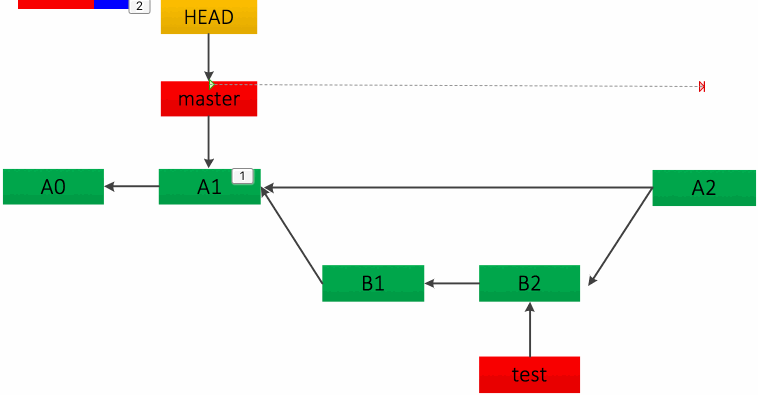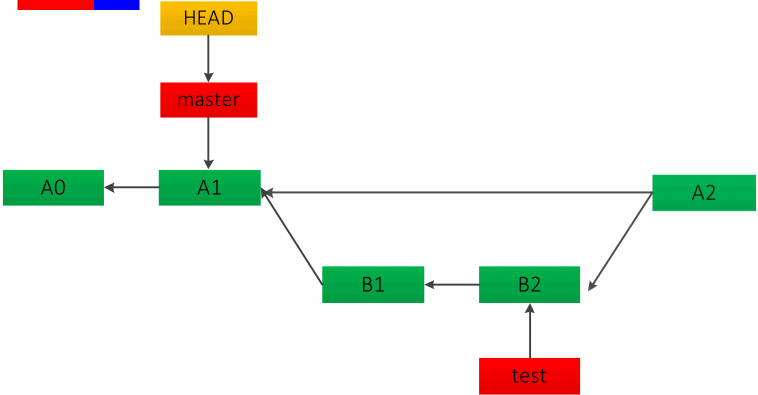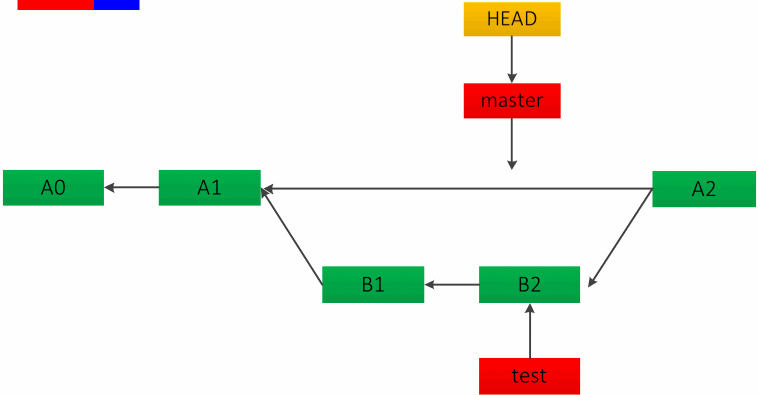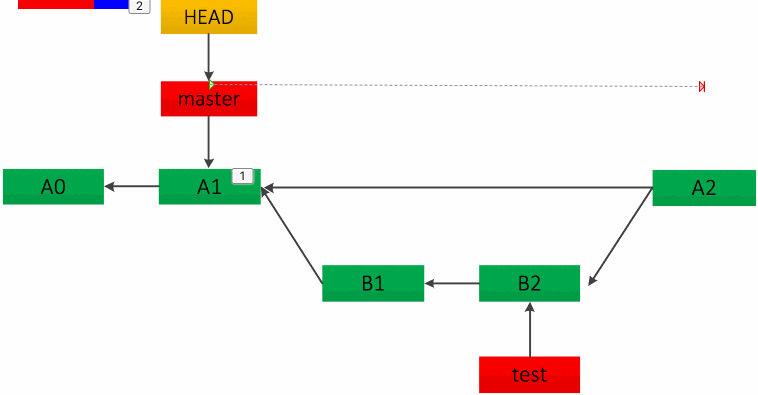
总结一下以上两种合并方式,快速 merge 和 --no-ff 两种方式都有风险存在,即如果 test 分支删除可能会丢提交的代码。
squash 会在当前分支新建一个提交节点,但不会保留对合入分支的引用。如下图:
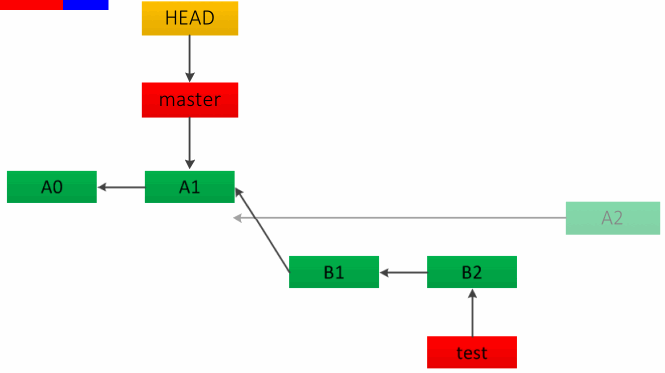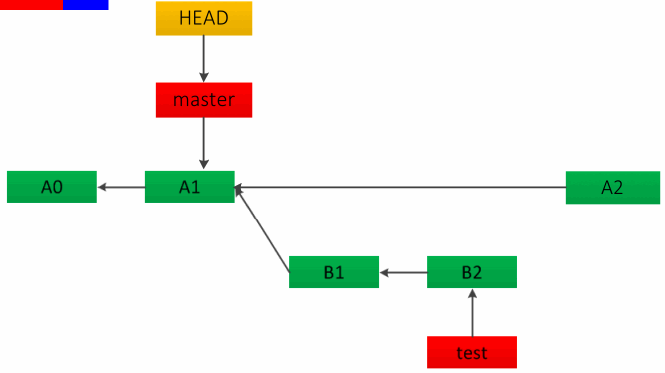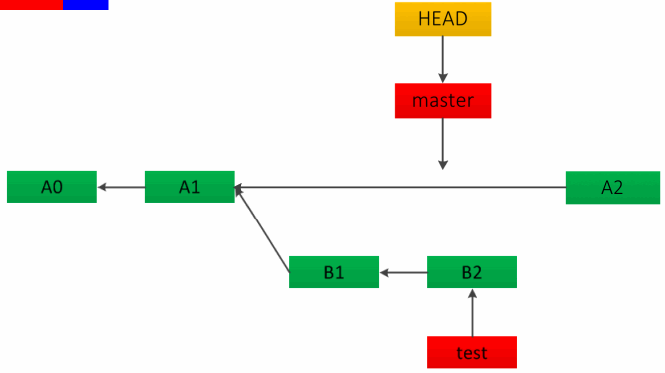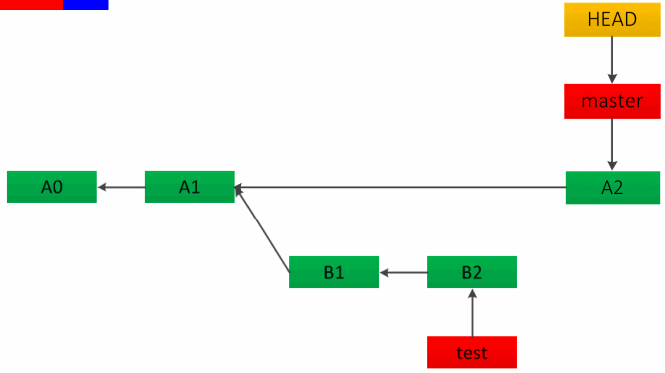
rebase 与 merge 不同,它会将合入分支上超前的节点在待合入分支上重新提交一遍,且保留了原本的 commit log 信息,如下图,B1、B2 会变为 B1’、 B2’,看起来会变成线性历史。
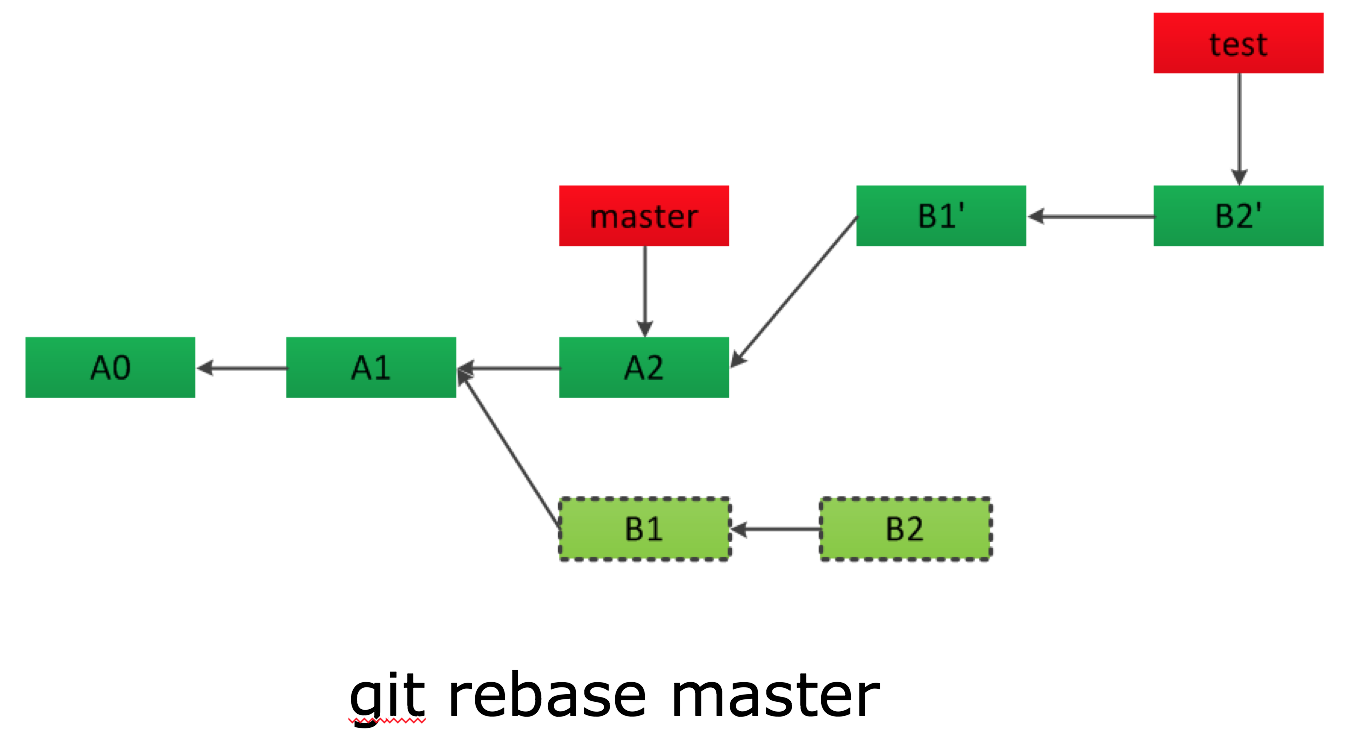
cherry-pick 给你想要的自由度,即把想要的某一 commit 提交节点合并到你想要的分支。
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务,被 Worker 线程负担了,主线程(通常负责 UI 交互)就会很流畅,不会被阻塞或拖慢。
Service Worker 是基于 Web Worker 的事件驱动的,执行的机制都是新开一个线程去处理一些额外的任务。对于 Web Worker,可以使用它来进行复杂的计算,因为它并不阻塞浏览器主线程的渲染。而 Service Worker,可以用它来进行本地缓存或请求转发,相当于一个浏览器端本地的 proxy。它可以认为是使用了Web Worker 技术来处理网络请求、响应等方面的事务。
使用构建工具生成静态 HTML ;
将生成的 HTML 部署到 CDN 服务器;
CDN 提供服务器视图;
服务器视图到客户端视图转换(见下文)
HTTP GET 请求发送到服务器;
服务器生成一个包含渲染的 HTML 和内联 JavaScript 的以便“Preboot”的页面(可以选择添加序列化数据进行缓存);
服务器视图到客户端视图转换(见下文)
浏览器从服务器接收初始化 payload;
用户看到服务器视图;
Preboot 创建隐藏的 div 以用于客户端初始化并开始记录事件;
浏览器对其他资源进行异步请求(如 image,css 等);
一旦加载完外部资源,Angular 客户端初始化开始;
客户端视图呈现给由 Preboot 创建的隐藏 div;
初始化完成后,Angular 客户端调用 preboot.done();
为了调整应用程序状态以反映用户在 Angular 初始化完成之前所做的更改(如 click 事件等),Preboot 事件将被重播;
Preboot 切换隐藏的客户端视图 div 为可见的服务器视图 div;
最后,Preboot 在可见的客户端视图上执行一些清理,包括设置焦点
年初在面试相关候选人的时候总是会问到 setState,其中不少人含糊其辞,没有很好的理解,这里再梳理记录一下吧。
当组件 state 数据有变更的时候,通过 setState(updater, callback) 这个方法来告诉组件更新数据,即能驱动组件的更新过程,触发 componentDidUpdate、render 等一系列生命周期函数的调用,如有需要则重新渲染。该方法是异步执行的过程,特点是批量执行且通过一次更新来确保性能,正因为它是异步执行的,在使用setState 改变状态之后,通常立刻通过 this.state 去拿最新的状态往往是拿不到的。举个例子:
addCount = () => {
this.setState({ index: this.state.count + 1 });
this.setState({ index: this.state.count + 1 });
}在以上代码中,调用一个累加方法,同步调用两次 setState,其效果最终只是+1,如果想获取最新的 state 的话可以在componentDidUpdate 或者 setState 的回调函数里获取,也可以通过第一个参数 return function 的方式,具体代码实例如下:
addCount = () => {
this.setState((prevState, props) => {
return {count: prevState.count + 1};
});
this.setState((prevState, props) => {
return {count: prevState.count + 1};
});
}setState 通过一个队列机制来实现 state 更新,当执行 setState() 时,会将需要更新的 state 浅合并后放入状态队列,而不会立即更新 state,通过队列机制来批量更新 state。
这里记录一下其详细过程:
1、调用 setState 方法,其内部判断第一个参数是否是 Object 或 Function,随后调用 enqueueSetState;
2、通过查看 enqueueSetState 方法的源码,其主要是做了两件事: 将新的 partialState 入队(_pendingStateQueue 数组中),执行 enqueueUpdate;
enqueueSetState: function(publicInstance, partialState, ...) {
var internalInstance = getInternalInstanceReadyForUpdate(publicInstance);
if (internalInstance) {
(internalInstance._pendingStateQueue || (internalInstance._pendingStateQueue = [])).push(partialState),
enqueueUpdate(internalInstance);
}
}setState 是通过 enqueueUpdate 来执行 state 更新的,那 enqueueUpdate 是如何实现更新 state 的?继续往下走。
3、enqueueUpdate 如果当前正处于创建/更新组件的过程,就不会立刻去更新组件,而是先把当前的组件放在 dirtyComponent 里,这里也很好的解释了上面的例子,不是每一次的 setState 都会更新组件。否则执行 batchedUpdates 进行批量更新组件;
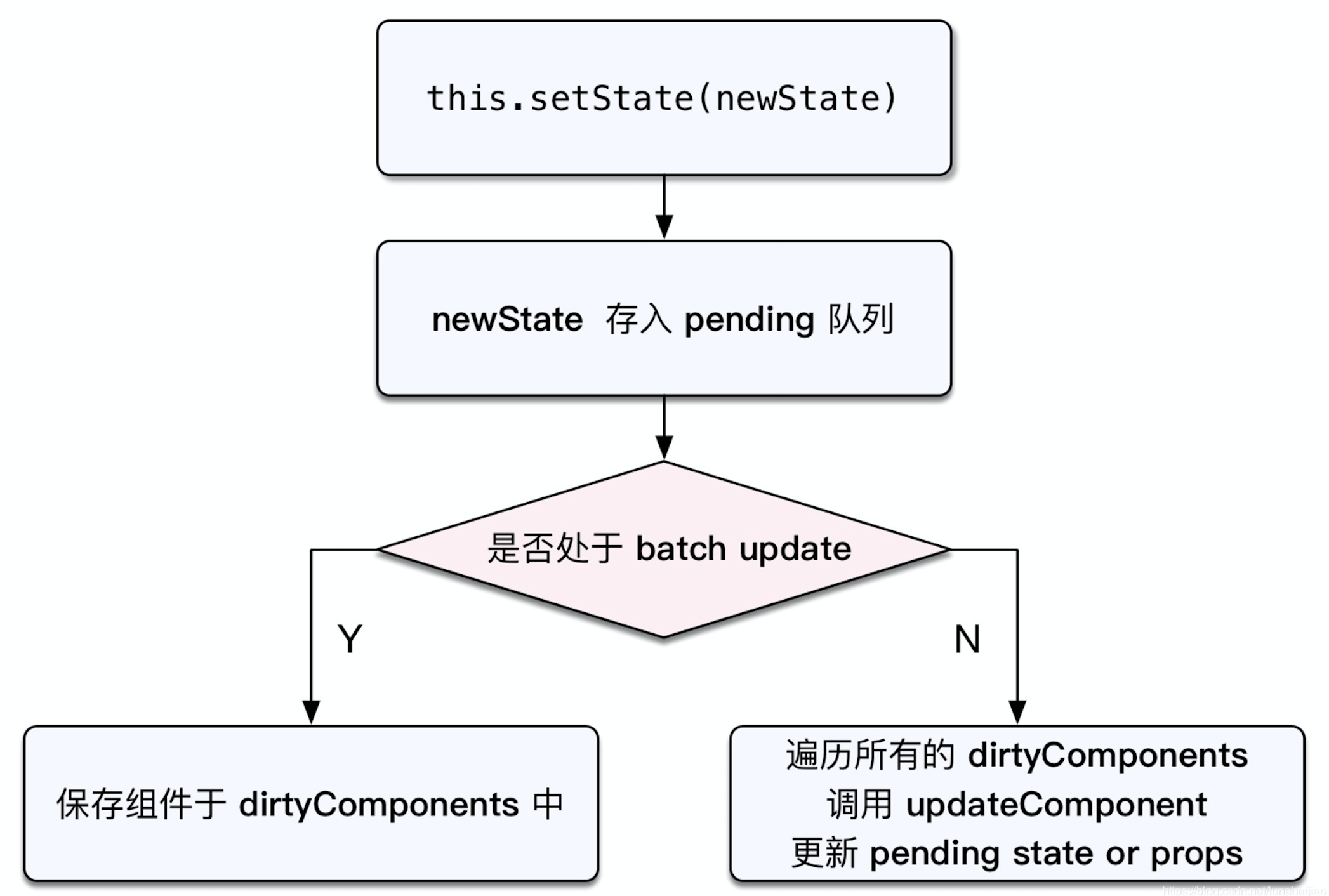
贴一下以上 3 的源码助于理解其中的过程,如下:
function enqueueUpdate(component) {
// ...
if (!batchingStrategy.isBatchingUpdates) {
batchingStrategy.batchedUpdates(enqueueUpdate, component);
return;
}
dirtyComponents.push(component);
}4、batchedUpdates 是将当次所有的 dirtyComponent 遍历,执行其 updateComponent 来更新组件,如调用 componentDidUpdate 生命周期方法来更新组件。
注,下文大致意译至 inside-browser-part1
在接下来的4个 blog 系列里边,将探索 Chrome 浏览器的底层架构和渲染管道细节,旨在弄明白从代码转换成可视化界面的过程,以此来写出更优秀性能的网站或应用。
本文是该系列的第一遍,我们先了解一些关键的计算机术语以及 Chrome 浏览器的多进程架构。
想要理解浏览器的运行环境,首先要搞明白计算机的一些核心概念以及它们的作用。
CPU 即 Central Processing Unit,可以理解成计算机的大脑。CPU core 可以想象成办公室里的工人,精通天文地理琴棋书画,可以串行地一件接着一件处理交给它的任务。现在的硬件设备多以多核为主,具备更优的计算性能。
图形处理器 GPU(Graphics Processing Unit)是计算机的另一组成部分,能通过多核处理简单的任务,这样就具备了极强的计算能力。GPU 顾名思义就是用来处理图形的,在说到图形 useing GPU 或 GPU backed 时,人们就会联想到图形快速渲染或者流畅的用户体验相关的概念。最近几年来,随着 GPU 加速概念的流行,在 GPU 上单独进行的计算也变得越来越多了。
在手机或者电脑上打开某个应用程序时,背后其实是 CPU 和 GPU 支撑着这个应用程序的运行。
在往下了解前,先理解清楚进程和线程的概念。进程可以看成是正在执行的应用程序,而线程则是跑在进程里面的,一个进程可以有一个或者多个线程,这些线程可以执行任何一部分应用程序的代码。
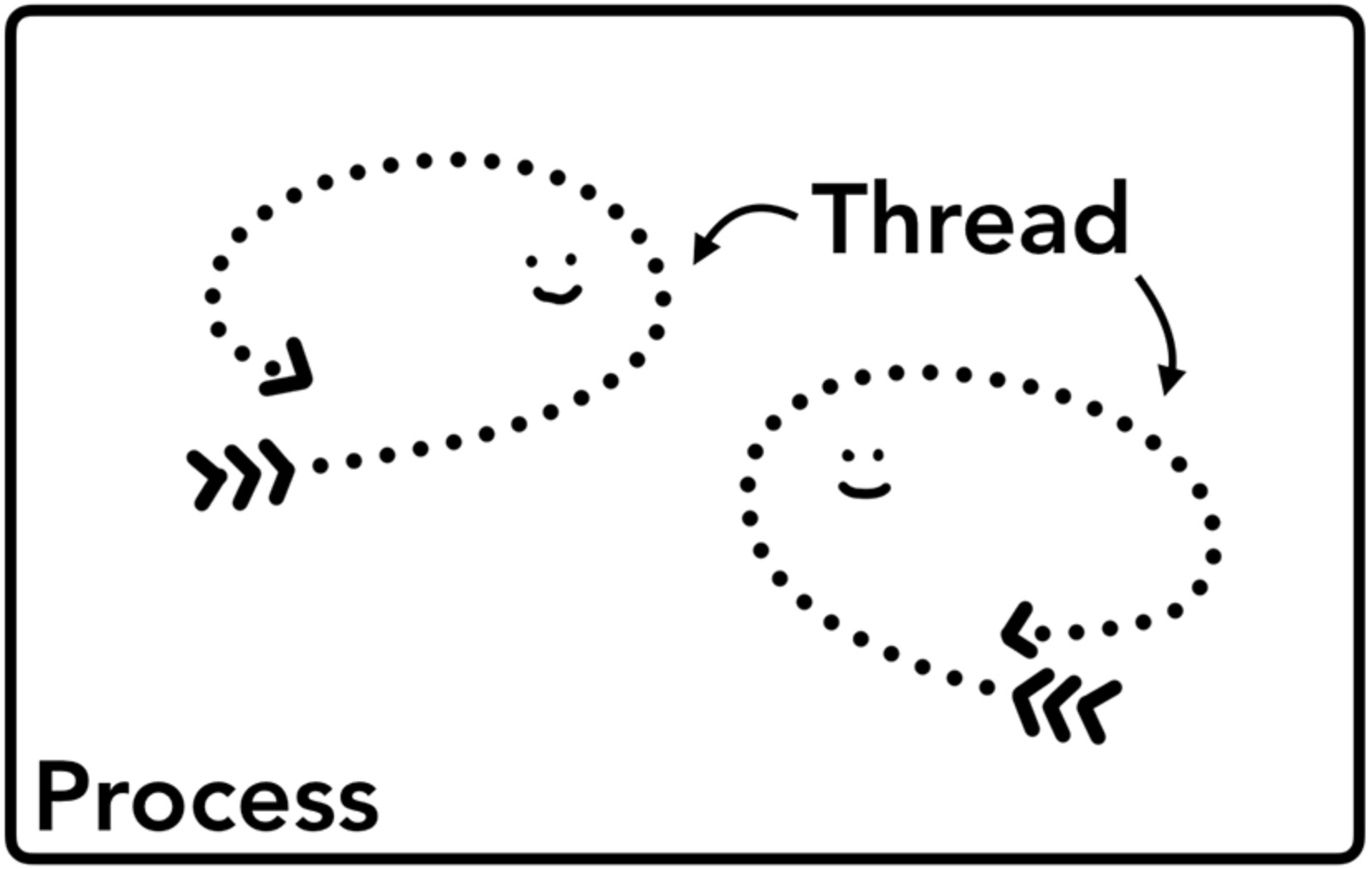
在启动一个应用程序后,操作系统将会为这个程序创建一个进程同时还为这个进程分配一片私有的内存空间,这片空间会被用来存储所有程序相关的数据和状态。当关闭程序,这个程序对应的进程也会随之消失,进程对应的内存空间也会被操作系统回收掉。
而在应用程序中,为了满足功能的需要,进程会创建其它新的进程来处理其他任务,这些创建出来的新进程拥有全新独立的内存空间,不能与原来的进程共享内存,很多应用程序都会采取这种多进程的方式来工作,因为进程和进程之间是互相独立的它们互不影响。如果这些进程之间需要通信,可以通过IPC机制(Inter Process Communication)来进行。
那么浏览器是怎么使用进程和线程的呢?一种可能是单进程配合多个线程工作,另一种是启动多进程,每个进程里面有一些线程,不同进程通过 IPC 进行通信。
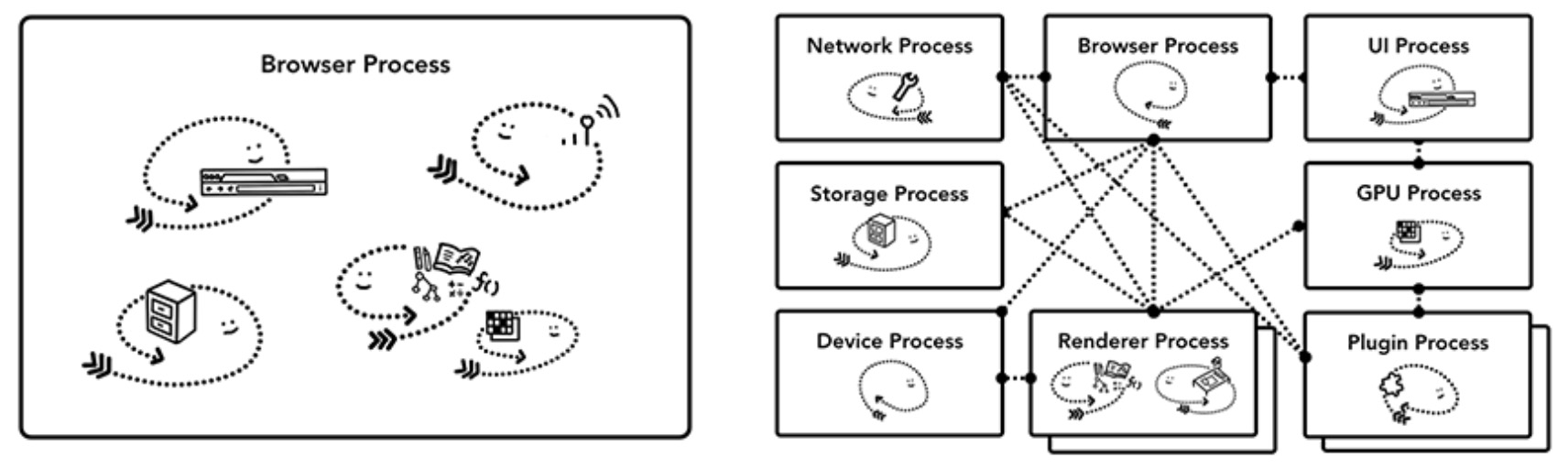
上图架构基本包含了浏览器架构的具体实现,但在现实中并没有一个标准化的浏览器实现标准,不同浏览器的实现方式可能会完全不一样,注,下文以 Chrome 浏览器为例,介绍浏览器的多进程架构。
在 Chrome 中,主要的四个进程为:
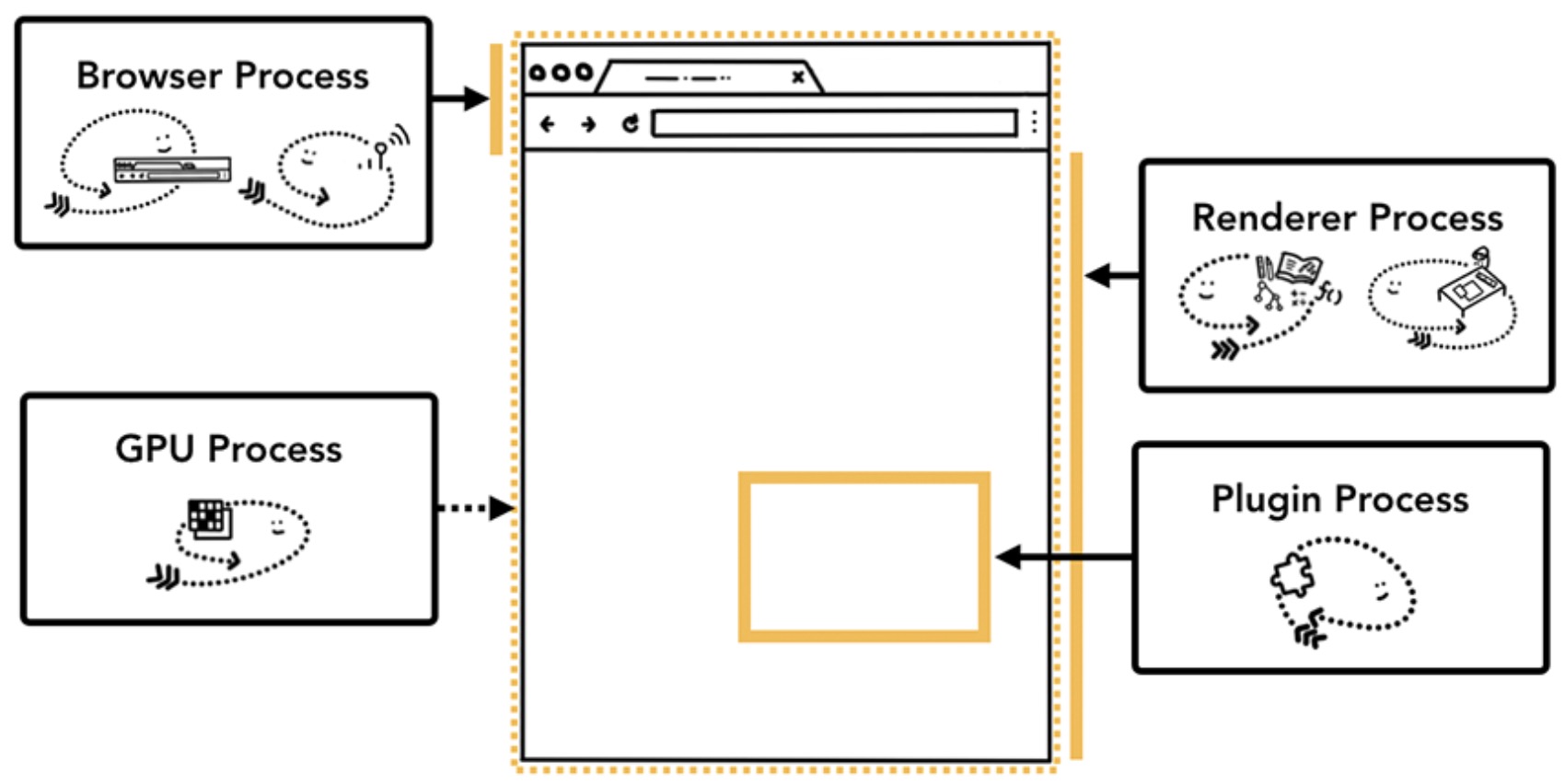
这4个进程之间的关系是什么呢?我们从浏览器的地址栏里输入 URL 后点击回车说起。
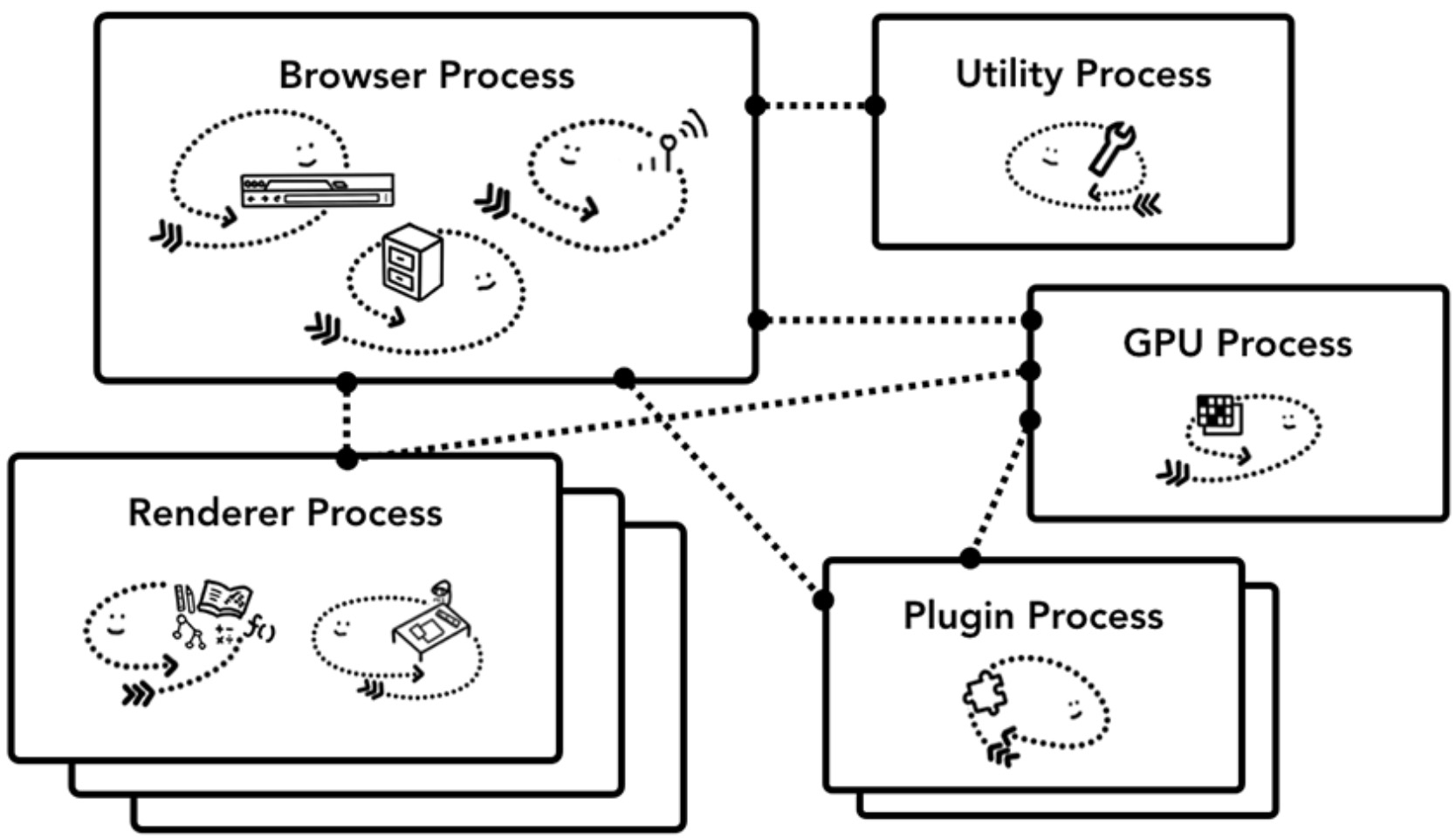
通过将和浏览器本身(Chrome)相关的部分拆分为一个个不同的服务或聚合为一个进程。如果 Chrome 应用运行在高性能的硬件上,则相关进程服务放到不同的进程运行以提高系统的稳定性,反之,则放在同一个进程里面执行来减少内存的占用。
Chrome 为不同的跨站 iframe 启用不同的渲染引擎。同源策略是浏览器最核心的安全模型,而进程隔离是隔离网站最有效的办法了,再加上 CPU 存在 Meltdown and Spectre 的隐患,网站隔离变得势在必行。
在 Chrome 67 版本之后支持了该特性
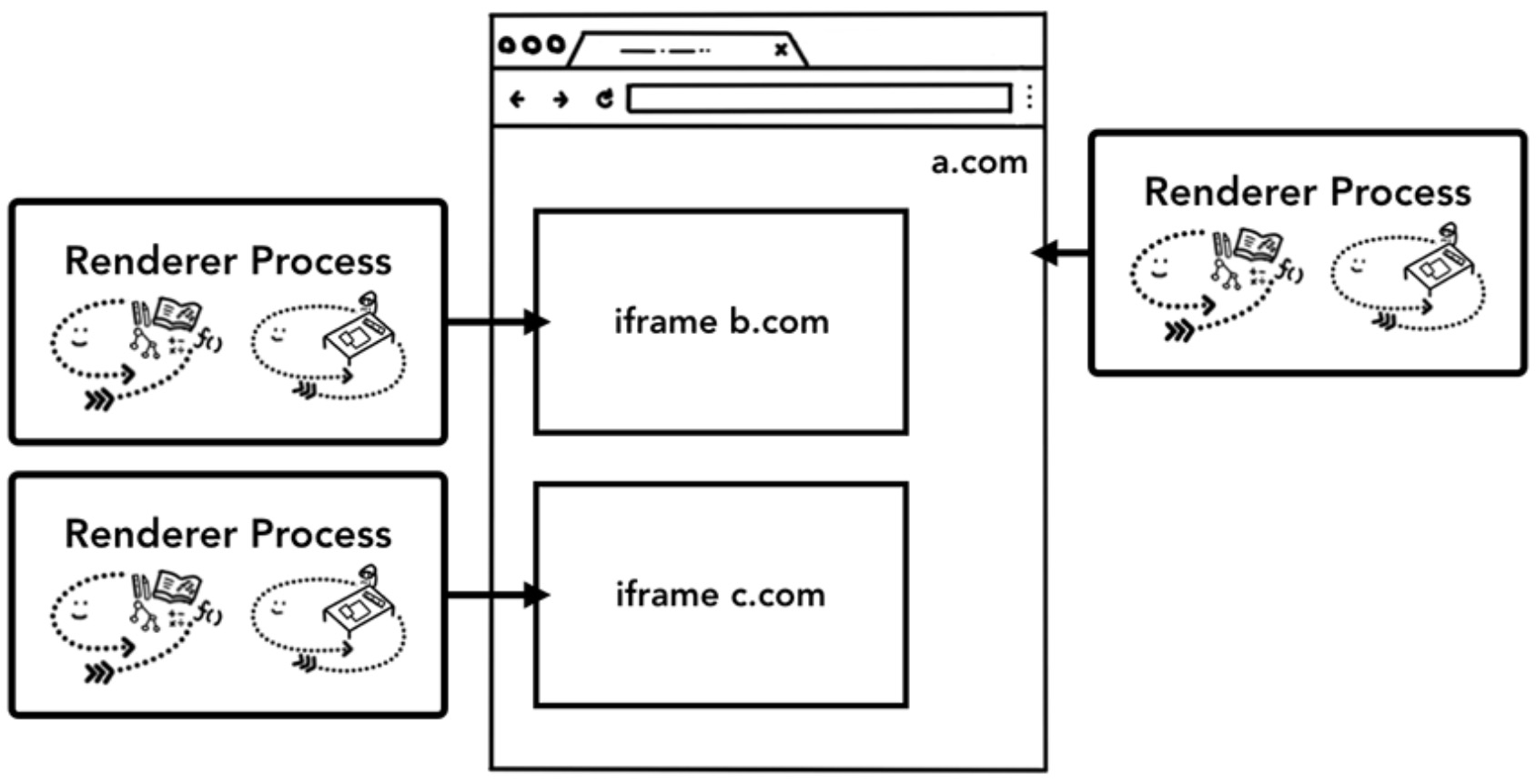
理解了概念之后,后边的文章我们将开始研究这些进程和线程之间发生了什么,如何显示一个网站内容。
我们的很多应用场景是基于这样一个简单的任务,获取数据,转换过滤后再展示给用户,angular2中我们引入了管道(Pipes)的概念,即管道是用来将数据模型中的数据经过过滤转换,然后通过模板内并展示给用户,这样做是为了更好的用户体验,例如从视图模型中直接获得的数据,不一定完全是我们想要的格式或者适合于人们查看的,举个例子,我们需要获取一个班级所有学生的平均分:
<div>this class‘s average is: {{getAvgScore()}}</div>
虽然通过视图模型中的getAvgScore方法获取到了我们需要的平均分来展示了,但是可能我们获取到的数据是一个除不断的多位小数位的数据,那么这样的结果看上去是不那么顺眼的。除了在视图模型的方法来控制小数位外,我们也可以利用管道来格式化这样的数据,也就是在模板里改变数据的显示格式。这就是angular2中管道的作用。
在angular2中,管道是在模板中对输入数据进行变换,并输出变换后的结果。在模板的内嵌表达式中,使用管道操作符“|”和其右边的管道方法来实现一个管道操作,使用“:”来向管道传入参数,所有的管道都是沿用这样这的一种机制。我们举个简单的例子来说明一下管道的使用:
import {Component} from 'angular2/core'
@Component({
selector: 'hero-birthday',
template: `<p>The hero's birthday is {{ birthday | date:"MM/dd/yy" }}</p>`
})
export class HeroBirthday {
birthday = new Date(1988,3,15); // April 15, 1988
}
我们通过视图组件获取到我们要输出的生日日期birthday,通过插值和模板联系起来,在模板的内嵌表达式中,我们输出生日组件的值是通过管道操作符“|”和其右边的内置管道Data Pipe方法来实现的。至于管道的参数,我们在内置管道Data Pipe方法后边加冒号(:)来添加参数值,并且如果有多个参数的话,我们用多个冒号来区分开参数就好了。
最后要说一下的是,angular2管道可以链式运用。我们可以将多个管道通过“|”链式的书写到一个实用的组合体上,如我们将birthday链到DatePipe和UpperCasePipe上以便我们将生日日期显示为大写,下面的日期将会是APR 15, 1988:
<p>The chained hero's birthday is {{ birthday | date | uppercase}}</p>
为了方便使用,Angular2针对之前的经验,设置了一套常用的内置管道,如DatePipe,JsonPipe,UpperCasePipe, LowerCasePipe,CurrencyPipe,PercentPipe及SlicePipe.其目的是在任何模板中都可以便捷使用。我们将详细介绍他们的具体用法。
DatePipe是对日期\时间数据进行格式变换,在模板中直接使用date来引用DatePipe,参数用来指定所需的格式,需要说明的是,不需要再在视图组件中声明,
<p>{{day | date: 'yyMMdd'}}</p>
JsonPipe是将Json数据对象转换成字符串格式输出,在模板中使用json来引用JsonPipe,其实现是基于JSON.stringify(),这个管道主要用来调试。
<p>{{key1: "value1", key2: "value2"}} | json</p>
UpperCasePipe&LowerCasePipe用于将输入的字符串转换成大小写,在模板中直接使用uppercase&lowercase即可。
<p>{{“this is a demo” | uppercase}} | json</p>
CurrencyPipe是将获取到的金钱数转换成特定格式的数字,在模板中直接使用currency来引用CurrencyPipe。
<p>{{price | currency: 'USD': true}}</p>
PercentPipe是将数值转换成百分比,在模板中使用percent来引用PercentPipe即可。
<p>{{1.23456 | percent: '1.2-3'}} | json</p>
例子中的“:'1.2-3'”表示调用这个这个管道时传入的参数为“'1.2-3'”,对于PercentPipe,这三个数字分别依次表示最少整数位、最少小数位和最多小数位。
SlicePipe是用来提取输入字符串中的指定切片,在模板中使用slice来引用SlicePipe。第一个参数指定切片的起始索引,第二个参数指定切片的终止索引的下一个。
<p>{{ '01234567890' | slice:1:4 }}</p>
通过上一节的内置管道可以看出,angular2内置的管道并不是特别的丰富,更进一步的是angular2允许自定义管道。自定义一个管道需要以下两个步骤:
和实现一个组件类似,一个自定义的管道也是具有特定元数据的类,如
import {Component,Pipe} from "angular2/core";
@Pipe({name: "anyPipeName"})
class anyPipeNamePipe {...}
Pipe注解为被装饰的类附加了管道元数据,其最重要的属性是name,也就是我们在模板中调用这个管道时使用的名称。上面定义的管道,我们可以在模板中这样使用:
<p>{{ data | anyPipeName }}</p>
定义一个自定义的管道必须实现一个预定的方法transform(input,args),其中这个方法的input参数代表输入数据,args参数代表输入参数,返回值将被作为管道的输出。
import {Component,Pipe} from "angular2/core";
@Pipe({name: "anyPipeName"})
class anyPipeNamePipe {
transform(input,args){
return ...;
}
}
通过以上定义一个自定义的管道,需要说明的是这样的一个pipe需要以下这样几个关键的点:
最后我们通过例子来说明自定义管道的使用,但是需要特别注意的是:
自定义管道完整的例子如下:
import {Component,Pipe} from "angular2/core";
import {bootstrap} from "angular2/platform/browser";
@Pipe({name:"title"})
class TitlePipe{
transform(input,args){
return input.split(" ")
.map(word => word[0].toUpperCase() + word.slice(1))
.join(" ");
}
}
@Component({
selector:"Demo-app",
template:`
<p>{{text | title}}</p>
`,
pipes : [TitlePipe]
})
class DemoApp{
constructor(){
this.text = "what a wonderful world!";
}
}
bootstrap(DemoApp);
无状态的管道是一个纯粹的方法,流入的数据将不会记录任何东西,或者不会导致任何的副作用。大多数的管道是无状态的,例如我们之前例子的Datapipe就是一个无状态的pipe。据我们之前了解到的管道,包括angular2内置的管道,都具有这么一个特点,就是其输出仅仅是依赖于输入,这就是angular2中的无状态管道,对于无状态的管道,当视图组件的输入没有变化时,angular2框架是不会重新计算管道的输出的。
有状态的管道在概念上类似于面向对象编程类,它们可以管理数据的变换,例如管道创建一个HTTP请求,存储它的返回和显示结果,就是一个有状态的pipe。需要注意的是,检索或请求数据的管道应该要谨慎使用,因为使用网路数据往往会引入错误的条件,在javascript中处理更优于在模板中处理。我们可以为了特定的后端和基本的异常捕获而创建自定义的pipe来减轻任何风险。
angular2对有状态的管道定义的关键在于使用使用Pipe注解的属性“pure”,并设置该属性的值为false即可,其作用是要求angular2框架在每个变化检查周期都执行管道的transform()方法。下面我们给一个例子,实现一个10到0的倒数计时器。
import {Component,Pipe} from "angular2/core";
import {bootstrap} from "angular2/platform/browser";
@Pipe({
name : "countdown",
pure : false
})
class CountdownPipe {
transform(input){
this.initOnce(input);
return this.counter;
}
initOnce(input){
this.counter = input;
this.timer = setInterval(() => {
this.counter--;
if(this.counter === 0)
clearInterval(this.timer);
}, 1000);
}
}
@Component({
selector:"demo-app",
template:`<h1>this is a stateful pipe : {{ 10 | countdown }}</h1>`,
pipes : [CountdownPipe]
})
class DemoApp{}
bootstrap(DemoApp);
从这个例子中可以看出,自定义管道countdownPipe的输出不仅依赖输出,还依赖与其内部的变化或者运行状态。
而angular2中,AsyncPipe是有状态管道的一个标志性的例子,AsyncPipe它的输入是一个异步对象:Promise对象、Observable对象或者EventEmitter对象,并且自动的订阅(subscrib)输入对象,最终每当异步对象产生新的值,AsyncPipe会返回这个新的值,它的有状态性是因为pipe维护一个输入的订阅并且它的返回值也依赖于这个订阅器。下面给出的例子,我们将用AsyncPipe绑定一个简单的promise给一个view。
import {Component} from 'angular2/core';
// Initial view: "Message: "
// After 500ms: Message: You are my Hero!"
@Component({
selector: 'hero-message',
template: 'Message: {{delayedMessage | async}}',
})
export class HeroAsyncMessageComponent {
delayedMessage: Promise<string> = new Promise((resolve, reject) => {
setTimeout(() => resolve('You are my Hero!'), 500);
});
}
管道的有状态和无状态的区别,关键在于是否是需要Angular2框架在输入不变的情况下依然持续地进行变化检测,而angular2的无状态的管道是依赖输入的,即同样的输入,总是产生同样的输出。举个例子,例如我们上面的管道,当我们输入一个默认的数字后,输出值依赖其内部的运行状态变化,而无状态的管道,例如一个加减乘除的管道,在Angular2中,它被视为无状态的,因为它的一次输入不会产生多次输出。
实例代码:
function Person(name){
this.name = name;
}
Person.prototype.getName = function() {
return this.name;
}
var p1 = new Person('Dan');
console.log(p1); // Person {name: "Dan"}
console.log(p1.__proto__ === Person.prototype); // truenew 操作符实现了如下的功能:
构造函数如果返回基本类型,则还是会返回原来的 this (新对象)。如果返回的是引用类型,则返回该返回值。(可以自己在上面例子加上代码验证一下)
function createNew(func, ...args) {
let obj = {};
// 将空对象指向构造函数的原型链
Object.setPrototypeOf(obj, func.prototype);
// obj 绑定到构造函数上,便可以访问构造函数中的属性
let result = func.apply(obj, args);
// 如果返回的 result 是一个对象则返回该对象,new 方法失效,否则返回 obj
return result instanceof Object ? result : obj;
}Object.setPrototypeOf()是ECMAScript 6最新草案中的方法,相对于 Object.prototype.proto ,它被认为是修改对象原型更合适的方法
写个测试用例:
function Test(name, age) {
this.name = name;
this.age = age;
}
let test = createNew(Test, 'Dan', 20);
console.log(test.name); // Dan
console.log(test.age); // 20在理解 RxJS 之前,先了解一下 Observable 的相关核心概念:
订阅者(subscriber)函数,Observable 实例可以发布多个任意类型的值,适用于事件处理、异步编程和处理多个值。来一个例子加深一下对上面概念的理解:
// declare a publishing operation
const observable = new Observable(observer => {
setTimeout(() => {
observe.next('test demo');
});
});
// initiate execution
observe.subscribe({
next: x => console.log(x),
error: err => console.error(err),
complete: () => console.log('done')
});根据前面的了解,我们可以大致实现一个 Observable 类。
初始化实例的时候传入 _observeFun,当调用类实例方法 subscribe 时执行传入的方法 _subscribeFun。
class Observable {
_observeFun: Function;
constructor(observeFun) {
this._observeFun = observeFun;
}
subscribe(observe: any) {
this._observeFun(observe);
}
}这就是一个简易版的观察者模式的实现。
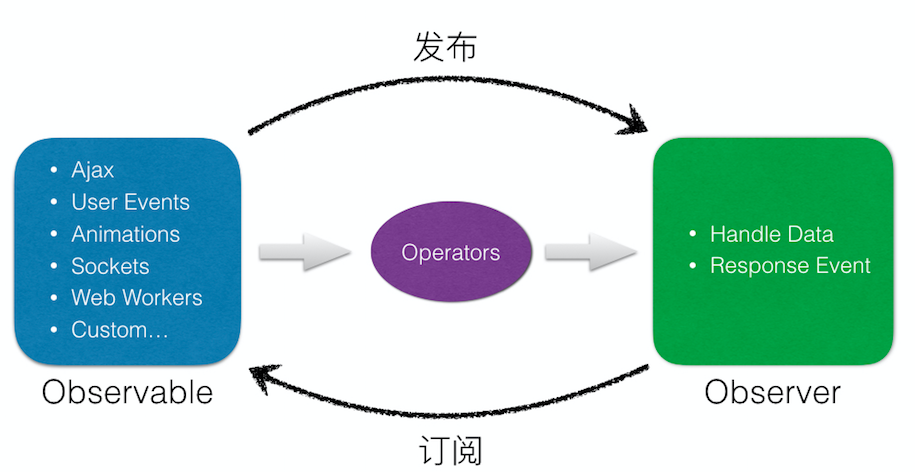
RxJS(Reactive Extensions for JavaScript) 是基于 ReactiveX 在 JavaScript 层面上的实现,关于 ReactiveX(An API for asynchronous programming with observable streams) 请参考reactivex.io
RxJS 是一个响应式编程库,它让组合异步代码和基于回调的代码变得更简单,整个库的基础就是 Observable,注意和观察者对象 Observer 区别开。对异步数据如 Ajax、User Events、Animation、Sockets、Workers 提供了一种 Observable 类型的发布订阅实现,输出给开发者使用,参考RxJS Docs。
举个例子,RxJS 提供了一个 fromEvent 用于监听相关 DOM 事件,通过 Observable 实现的这个 fromEvent 简单的代码示例如下:
function fromEvent(target, eventName) {
return new Observable((observer) => {
const handler = (e) => observer.next(e);
// Add the event handler to the target
target.addEventListener(eventName, handler);
return () => {
// Detach the event handler from the target
target.removeEventListener(eventName, handler);
};
});
}下面是对 fromEvent 的一个应用:
import { fromEvent } from 'rxjs';
const el = document.getElementById('my-element');
const mouseMoves = fromEvent(el, 'mousemove');
// Subscribe to start listening for mouse-move events
const subscription = mouseMoves.subscribe((evt: MouseEvent) => {
console.log(`Coords: ${evt.clientX} X ${evt.clientY}`);
});即当 Observeable 的实例 subscribe() 方法被调用后,实现了一个鼠标的事件监听,每当鼠标移动,通过发布者函数的 observer.next(e) 方法将数据流发布给订阅者。类似于:
el.addEventListener('mousemove', evt => {
console.log(`Coords: ${evt.clientX} X ${evt.clientY}`);
}, false);观察者模式在 Web 中最常见的应该是 DOM 事件的监听和触发。对于上面的例子,发布订阅相关信息如下:
fromEvent 和监听 DOM 事件的类比图效果如下:
RxJS 还有一个重要的概念:Operators,是对可操作的数据流进行一些中间处理的 API,在 subscribe 中的 observer 最终接收到的数据往往是经过 Operator 处理完后的数据。这些 API 是一些工具型函数,把现有的异步代码转换成可观察对象,对 observer stream 进行迭代处理,其中包括对不同类型的值进行例如 Mapping、过滤、组合等,把当前的流转成(transformTo)另一个流(更多时候配合 pipe 使用。
import { map } from 'rxjs/operators';
const nums = of(1, 3, 5, 7);
const squareValues = map((val: number) => val * 10);
const squaredNums = squareValues(nums);
squaredNums.subscribe(x => console.log(x));可以将上面代码形象表示成
--1---3--5-----7------
map(i => i * 10)
--10--30-50----70-----
以上是对 RxJS 的基础了解,RxJS 的核心大致理解成如下图:
下面我们更进一步。
RxJS 的核心概念是 Observable(可观察对象),通过以上基础概念理解,我们对比一下 Promise:
除了可以通过 Observer 的 error 回调来处理外,RxJS 还提供了 catchError 操作符,它允许你在 pipe 中处理已知错误。更重要的是 catchError 提供了 retry 操作符让你可以尝试失败的请求。对于错误处理,由于可观察对象会异步生成值,所以用 try/catch 是无法捕获错误的。
举个例子:
import { ajax } from 'rxjs/ajax';
import { map, retry, catchError } from 'rxjs/operators';
const apiData = ajax('/api/data').pipe(
retry(3), // Retry up to 3 times before failing
map(res => {
if (!res.response) {
throw new Error('Value expected!');
}
return res.response;
}),
catchError(err => of([]))
);
apiData.subscribe({
next(x) { console.log('data: ', x); },
error(err) { console.log('errors already caught... will not run'); }
});Promise 的错误处理方式可以如下:
somethingAync.then(function() {
return somethingElseAsync();
}, function(err) {
handleMyError(err);
});这种方式的缺点就是,没法捕获 somethingElseAsync() 里边的错误,可以使用 Promise 的原型方法 catch。
实现一个输入框搜索的功能,大致需要做这么些事情:
RxJS 一个简单的实现代码:
import { fromEvent } from 'rxjs';
import { ajax } from 'rxjs/ajax';
import { map, filter, debounceTime, distinctUntilChanged, switchMap } from 'rxjs/operators';
const searchBox = document.getElementById('search-box');
const typeahead = fromEvent(searchBox, 'input').pipe(
map((e: KeyboardEvent) => e.target.value),
filter(text => text.length > 2),
debounceTime(300),
distinctUntilChanged(),
switchMap(() => ajax('/api/endpoint'))
);
typeahead.subscribe(data => {
// Handle the data from the API
});Angular 原生集成了 RxJS,对它的应用可以说比较丰富了,如:
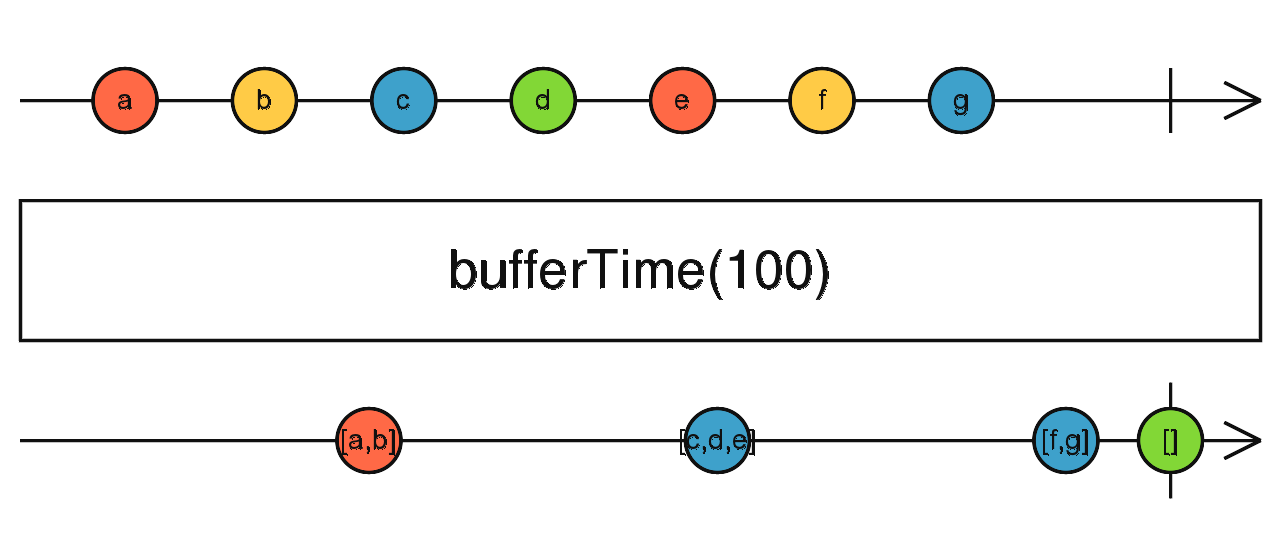
对于群聊,试想一下如果每收到一个 notification 都立刻渲染的话,会有什么问题。通常的做法是批量渲染,即收集一段时间的消息,然后把它们一起渲染出来,例如每一秒批量渲染一次。
用原生 JS 写的话,需要维护一个消息队列池、一个定时器,收到消息,先放进队列池,然后定时器负责把消息渲染出来。
使用 RxJS 的话,很简单:
Rx.Observable
.fromEvent(ws, 'message')
.bufferTime(1000)
.subscribe(messages => render(messages))其中最为关键的是 bufferTime 这个操作符,可以用下图来概括以上逻辑:
RxJS 具备的 100 多个 Operators 提供了强大的业务支撑能力,使用恰当可是事半功倍。到底什么样复杂的异步操作才不算杀鸡焉用牛刀呢?
RxJS 的设计核心在于响应式(reactive)编程,如果你把一个场景下所有 component/service 的 input 和 ouput 都理解为 stream 之间的 publish 和 subscribe,那自然而然就会选择 RxJS。RxJS 的响应式编程另外一大好处在于扩展性好,复杂场景下添加一个具有更新数据能力的组件带来的代码改动可以做到最小,因为你只需要关注 stream 之间的 dependency。
最后不得不再提的是 Operators,Operator 仅仅是提供一种业务抽象能力,但我觉得模式和思路收益更大,抛去上层扩展,Rx 的内核也就 Observable 和 Subject。
还有两个没提的概念,即 subject 和 scheduler。可以参考Rx中的subject和scheduler怎么理解概念?
本文翻译的文章链接:https://levelup.gitconnected.com/a-recap-of-frontend-development-in-2019-1e7d07966d6c
在即将过去的 2019 年,前端世界持续突飞猛进,本文主要回顾了web前端开发的主要事件,新闻以及未来趋势。
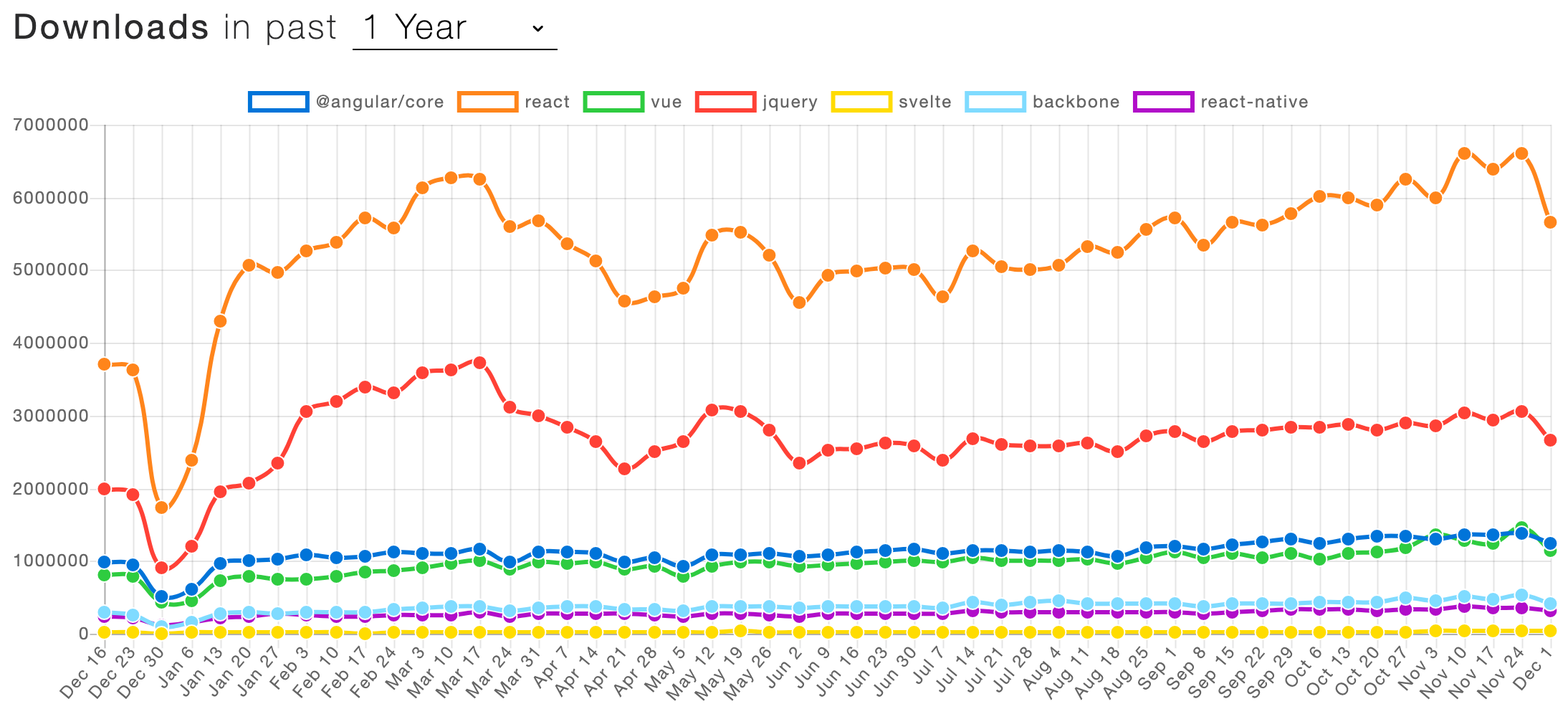
React 依旧保持遥遥领先的姿态并且还在持续增长,jQuery 占据在第二的位置(居然有这种事)。紧随其后的是 Angular 和 Vue,同样拥有庞大的用户群体。Svelte 在过去的一年中吸引了不少的注意力,但是还挣扎着能否生存下去。
WebAssembly 在今年持续保持低调,但在 12 月初却又重大消息 — W3C 联盟正式将其推荐为一种 web 语言。
自从在 2017 年发布 WebAssembly 后,其吸引了大量的关注并快速被采用,在过去几年来,我们看到了 1.0 规范的创建和在所有主流浏览器上的集成。
WebAssembly 在 2019 年的另一条新闻是字节码联盟的成立,该联盟似乎是“通过合作来实施并推动标准,提出新标准来打造 WebAssembly 在浏览器的未来”。
我们仍在等待 WebAssembly 真正站稳脚跟,并获得大量采用,并且随着每次更新,我们都更加接近这个目标。毫无疑问,W3C 的声明是公司使用其合法化迈出的重要一步,接下来需要继续降低使用 WebAssembly 的入门门槛,以使其更易于构建产品。
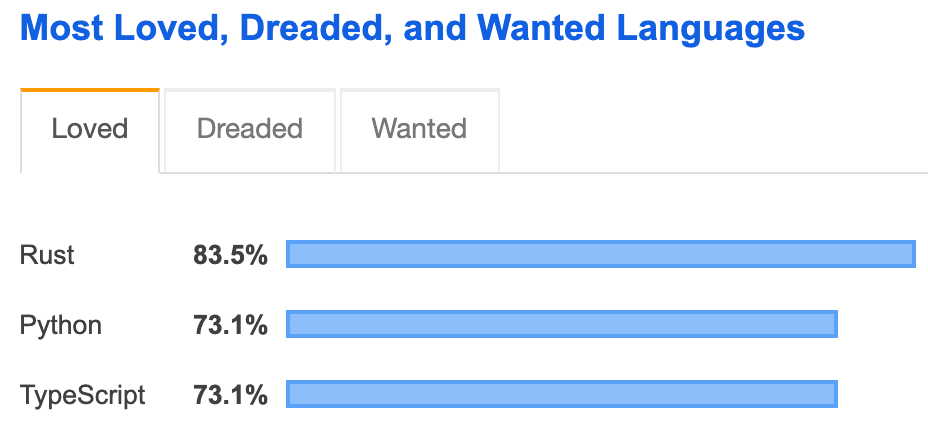
2019 年对于 TypeScript 来说是其爆发的一年,TypeScript 不仅仅是在 JS 代码中添加数据类型,而且许多开发人员经常选择在个人项目和工作中直接使用它。
在 2019 的 StackOverflow 最受欢迎语言调查报告中,TS 和 Python 一起并列第二,紧随 Rust 之后,在可预见的未来,如 2020 年,TS 还会继续飙升。
TS 被广泛运用到前后端当中,甚至使用 TS 是一种时髦的行为,这也导致了其迅速被广泛使用。
TS 几乎整合进了所有主流编辑器,提供了优质的开发体验,对于 JavaScript 开发者来说,TS 作为一种开发工具,用于类型校验和定义接口便于自查或者当做文档记录数据结构类型,以此来减少 bug。
值得注意的是,TS 在 2019 年的 npm 下载量超过了 react,远超了竞争对手 flow 和 Reason。
2018 年底发布了 TypeScript v3.0,在 2019 年已经更新到 release 3.7,包含了 ECMAScript 最新的特性以便提升类型检测的功能。
Learn TypeScript - Tutorials, Courses, and Books
Vue 和 Angular 拥有不少客户,甚至 Vue 在 github 上的 star 都超过了 React,但是在个人适用性和专业度来看,React 还是继续保持强劲的领先。
2018 React 团队首先介绍了 hooks,在2019年,hooks 席卷了 React 世界,绝大多数开发人员将其作为管理状态和组件生命周期的首选方式。整一年,关于 hooks 的文章铺天盖地的,模式开始固化,涌现了很多自定义的 hooks 功能性的包。
Hooks 为函数组件提供了一种简单简洁的语法来管理其状态和生命周期,另外,无需创建 HOC 和 render props,React 提供了构建自定义 hooks 的能力,可以用来复用代码和共享业务逻辑。
在 React v16.8 版本中引入 hooks 之后,此后的大部分更改都相对较小,同时在 2019 年发布了版本 16.14。
hooks 发版后,React 核心团队更加关注开发体验和工具来提升效率,在 Conf 2019 上,开发经验(developer experience)作为主题被提及。React Conf主题演讲者和React团队经理Tom Occhino表示,开发人员的经验植根于这三件事:低门槛,高效能和可扩展。让我们来看看 React 团队发布了什么或者计划中发布的功能:
其信念就是良好的开发体验带来良好的用户体验,以此来俘获各位。大会相关链接请戳 React Conf 2019 Day1。
Vue 可能尚未获得最多的使用率,但它确实拥有最热情的用户群体。Vue 吸收了 React 和 Angular 的最佳部分,同时也变得更加简单。它的另一个卖点就是更加开放,不被某一个大公司控制如 React (Facebook) 或者 Angular (Google)。
Vue 最大的的新闻就是即将发布 3.0 版本,它的 alpha 版本有望在 2019 第四季度末发布。Vue 2.x 在今年年初仅仅获得少量的更新,大部分精力都投入到了 v3 版本中。
今年发布的东西不多,并不意味着并没有发生什么,当尤雨溪发布了 RFC for v3 后,在社区引起了广泛的讨论。
不过另开发者不爽的是,Vue API 进行了大修改,然而,在反对声之后,它 API 更加被期待为叠加的和对 Vue 2 向后兼容的。随着 release 版本的持续进行,许多开发者声称 Vue 应该吸收一些 Svelte 的东西,否则真的和 React 太像了。尽管社区中仍有许多人对此表示关注,但在他们等待发布时,噪音似乎已平息。
伴随着各种讨论声, Vue 3 持续在更新一些大的变化:
Learn Vue.js - Tutorials, Courses, and Books
Angular 的面面俱到让其俘获了大量的用户群体,由于Angular是一个强有力的框架,它要求开发者遵循它的方式,并且为其提供了所需的工具。
这消除了关于应将哪些库和依赖项带入项目的许多争论,这是在构建 React 应用程序的团队中可能会发现的潜在问题。它还要求开发人员使用 TypeScript 编写其应用程序。由于大多数技术选型已有确定方案,因此公司将其视为一个不错的选择,因为它使开发人员可以专注于开发产品,而不是对某些 packages 做调研花掉很多时间。
在 2019 年,Angular 发布了 V8 版本,并且还发布了一个新的渲染器/编译管道,称之为 Ivy。 Ivy 最大的好处就是降低了 budle 包体积大小,除此之外,它还有很多额外的提升。目前为止,直到 Angular 9 为止,Ivy 是一项可选功能。 这篇文章 详细介绍了 V8 版本的新特性,主要的更新如下:
Angular 团队即将在 2019 年末或者 2020 年初发布版本 9,最大的变化就是 Ivy 将成为新的渲染器标准。
web 应该对所有人开放并可用,并且前端世界一直在优先考虑。从 2015 年开始,JavaScript 和 web 迅猛发展,一些开发模式和框架基本固化,事情变得更加稳定,那么开发者可以集中更多的精力去落地 App 并使其可访问性更好,但是还有很长的路要走。
国际化同样重要,要使得应用在不同地区、不同文化或语言能被很好的兼容到。
ECMAScript(JavaScript所基于的规范)继续其年度更新周期,为 ES2019 版本添加了新功能
尽管 ES2019 进行了一些重大更新,但即将面世的 ES2020 似乎才是自 ES6 / ES2015 以来最受期待的功能:
Flutter 在 React Native 发行 2 年后发布,但也发展迅猛。 Flutter 在 github 上 star 数(80.5k)几乎接近 RN 的 83k。 的速度在GitHub星中赶上了React Native,发展迅猛未来可期,Flutter 正在使自己成为最佳的跨平台移动框架。
为了支撑 JavaScript 生态系统和加速其发展,Node.js 基金会和 JS 基金会合并组成 OpenJS 基金会。基金会传达的信息是根据托管的 31 个开源项目,包括 Node,jQuery和 Webpack,来进行合作和发展。这一举动被视为对整个JS社区都是积极的,并得到了Google,IBM和Microsoft等大型科技公司的支持。
当前发布的Node version 12将被长期支持直到 2023 年,node 12 提供了许多新功能,安全更新和性能改进。一些值得注意的更新包括对 import/export,类私有字段的原生支持,V8 Engine 7.4 版的兼容性,以及对 TLS 1.3 的支持,增加了其他诊断工具。
Svelte 找到了将自己置身于本已拥挤的前端框架世界中的办法,然后,正如我们文章前面提到的,这还没有转化为大量实际应用,对 Svelte 最好的总结是“简单但强大”。在 Svelte 网站 提及了三点:
静态站点将旧网站与新工具,库和更新结合在一起,以提供优质的用户体验。我们能够使用像 React 这样的库来构建我们的站点,然后在构建时将它们编译成静态 HTML 页面。由于所有的页面都是预编译的,这就意味着无需等待请求数据并填充页面,这样页面将更加迅速的呈现出来。
上面提到的静态站点无法满足各种场景,另一个可选方案是 PWA(progressive web apps)。PWA 允许在浏览器中缓存资源,使得页面得到立即响应并提供离线支持,另外,也支持消息推送。
一个争议点是 PWA 能否取代原生应用,无论结果如何,毫无疑问,长期以来,PWA将成为公司构建产品的重要组成部分。
几年来,JavaScript fatigue 一直是前端开发人员抱怨的,但是我们已经慢慢看到,开源项目维护人员的不懈努力是这种情况得到缓解。
几年前,我们开发项目不得不自己搭建一套前端框架,包括如何构建和发布。现在一切都变的更加简单,我们有各种 CLI,且有比较成熟的一套前端工程化解决方案。
GraphQL 有望解决传统基于 REST 的应用程序呈现的许多问题。总而言之,目前 GraphQL 得到了部分大公司的青睐。
GraphQL 是数据驱动的模式,允许客户端开发人员自定义数据结构并以此来返回正确格式的数据。GraphQL API提供了一个架构,用于记录所有数据及其类型,从而使开发人员可以全面了解API。这一年的下载量如下:
Web 开发的进展感觉就像是在统一 JavaScript 下的所有东西一样,可以通过使用 import/export 语法来共享样式和依赖项,这在 CSS-in-JS 的采用中得到了体现。
VS Code 有多牛逼,直接看下面的这张图吧:
Webpack 已成为几乎所有现代 JavaScript 工具链的核心组件,并且是最常用的构建工具。Webpack 一直在提高其性能和可用性,使其对开发人员更友好, V5 版本致力于以下几点:
TODOS:
表单在我们的web应用中是至关重要的,表面上看,表单最直截了当的就是用户输入数据,点击提交这么简单。但事实上,表单所呈现的形式是非常复杂多变的,比如我们angular表单可以实现用户控制,监视变化,验证输入、错误信息处理和数据绑定等功能。
本节将详细介绍angular2表单,主要是从技巧方面来认识表单在angular2中带给用户的良好体验,具体如下:
angular2表单是基于HTML的模板及其控制该模板数据以及用户交互的组件组成,我们需要引入一个Componet,这意味着可以在该组件中定义选择器和模板或者引入一个外链的html模板。接下来定义一个组件类,其作用是控制表单相关属性的表现,定义表单方法等。
如下面的例子:【暂时用官网的例子。TODO...】
import {Compontent} from ‘angular2/core’;
import {NgForm} from ‘angular2/common’;
import {Hero} from ‘./hero’;
@Component ({
selector: ‘hero-form’,
templateUrl: ‘app/hero-form.compontent.html
})
export class HeroFormCompent {
powers = [‘ReallySmart’,’Super Flexible’,’Super Hot’,’Weather Changer’];
model=new Hero(18,’DrIQ’,this.powers[0],’Chuck Overstreet’);
submitted = false;
onSubmitt(){this.submitted= true;}在这个例子中,在引入的Component中,需要定义一个selector选择器,这表示我们能够在父模板中插入该表单。同样的,模板可以是外链URL模板也可以直接包裹在template键对应的值中。如:
template: `<form #f="ngForm" (submit)="search(f.value)">
<select>
<option value="web">网页</option>
<option value="news">新闻</option>
<option value="image">图片</option>
</select>
<input type="text" ngControl="kw">
<button type="submit">搜索</button>
</form>`而控制表单的属性或者用户行为等,我们将定义一个类来处理,如HeroFormCompent类,我们定义了相关的属性,提交数据方法等。
NgForm指令为表单建立一个控件组对象,它包含当前选择器所在的form标签,关于NgForm请看下面的例子:
import {Component} from "angular2/core";
import {bootstrap} from "angular2/platform/browser";
import {CORE_DIRECTIVES,FORM_DIRECTIVES} from "angular2/common";
//组件
@Component({
selector:"xx-app",
directives:[FORM_DIRECTIVES,CORE_DIRECTIVES],
template:`
<form #f="ngForm"
<input type="text" ngControl="title">
(ngSubmit)="onSubmit(f.value)"
</form>
`
})NgForm指令包含在预定义的数组变量FORM_DIRECTIVES中,所以我们要在组件注解的directives属性中优先声明FORM_DIRECTIVES,这样就可以直接使用NgForm指令了。
通过使用“#”符号,我们可以创建一个引用控件组对象的局部变量,如上例中的变量f,这个变量它的value属性是一个JSON对象,该对象的键对应的是表单中input元素的ng-control属性,值对应的是input元素的值。接下来我们介绍NgControl。
我们可以在input标签中添加ngControl属性,NgControl将创建一个新的Control并动态的将它添加到父ControlGroup中,同时绑定一个DOM元素到这个新的Control,这就将这个input标签和Control联系起来了,我们访问该标签将直接通过这个ngControl的属性值来访问。
需要注意的是,ngControl必须是作为一个NgForm或者NgFormModel的后代来使用,否则将会报错,因为这个指令需要将创建的控件对象添加到祖先(NgForm或者NgFormModel)所创建的控件中。
在这里,值得一提的是NgControlNmae,它的选择符是[ngControl],这就意味着,你必须和ngControl来搭配使用,这个指令才会发挥它的作用。NgControlName指令为宿主DOM对象创建一个控件对象,并将这个对象以ngControl属性指定的名称绑定到DOM对象上,举个例子,如我们最常用的用户名和密码表单:
<form #f="ngForm">
<input class="user-name" type="text" ngControl="user">
<input class="password" type="password" ngControl="password">
</form>我们创建了两个Control对象,NgControlName指令为宿主DOM对象创建两个控件对象,然后将ngControl属性指定的名称user、password绑定到了其对应的input标签对应的DOM数上。这样的好处是我们可以很方便的通过控件组获取对应的值,也能实现ngModel模型与表单的双向绑定,下一节我们将介绍NgModel。
表单不仅仅是数据的绑定,同样的,我们也希望能够监测到表单的状态,NgControl指令能够保持对状态的监视,除此之外,它会在这下面的三个状态值中影响着当前表单的控制器。
| 状态 | True | False |
| control是否被访问 | ng-touched | ng-untouched |
| control是否发生了变化 | ng-dirty | ng-pristine |
| control是否合法有效 | ng-valid | ng-invalid |
通过监测NgControl状态的改变,我们能设置我们想要的特殊css类来更新控制器,比如能够通过监视状态合法性的属性ng-valid和ng-invalid来改变控制器是否需要弹出或者显示输入非法的状态提醒,如显示、隐藏错误信息等。我们能瞬间探测到这些状态的改变,同时我们可以马上为我们的表单组件添加对应的处理。以下是对这些状态使用的一些例子:
// todo ...
在表单中,我们常常需要用到这样的场景,在model数据结构有变化的时候,我们希望能够及时的反应在表单中,同样的,我们在操作表单的时候,也是需要表单的变化需要实时的在model中有响应的。也就是说,我们需要同一时间去显示、监听和摘录数据。
angular2采用的是ngModel来实现数据的双向绑定的,NgModel指令可以令表单和模型(model)的数据绑定超级简单,它的语法是:[(ngModel)]=“...”,例子如下。
<input type=”text” class=”form-controt” required [(ngModel)]=”model.name”>
TODO:监视这个表单的值:{{model.name}}在模板语法里,我们已经了解过了属性绑定和事件绑定,在属性绑定里,值产生于模型赋值给目标属性,通过中括号-[]来包裹这个属性,那么我们的模型也将通过这个中括号内的属性值来辨识这个目标属性。这是一种由模型向视图的单项数据绑定。而事件绑定则相反,在事件绑定中,目标属性对应表单的变化的值将赋予给模型,通过小括号-()来包裹这个属性,这个包裹的属性将会标识模型中对应该目标属性名的变化。这是一种反向的视图向模型的单向数据绑定。这就是[()]实现数据双向绑定的方式,很好的预示将要发生什么。
如上面的例子,我们可以改写成这样:
<input type=”text” class=”form-control” required [ngModel]=”model.name” (ngModelChange)=”model.name=$event”>
TODO:监视这个表单的值: {{model.name}}该表单中,模板表达式:model.name=$event是被用来发现来自于DOM事件的$event事件,ngModelChange不是一个input元素事件,本身不会产生一个DOM事件,实际上它是NgModel指令的一个事件属性,它是能够返回输入框的一种angular的EventEmitter属性,这种属性能够精确的捕获我们分配给模型“anyName”属性的值。在angular2表单中,我们看到[(anyName)]时,它预示着这个anyName指令将拥有一个该属性的输入值和一个对应着anyName-change的输出值。
用户填完表单之后,我们需要获取表单的完整数据以便提交。通常我们会在表单的底部添加一个提交按钮并设置其type的值等于submit,按钮本身不做任何事情但是却能监听表单的提交这个动作,但是此刻的提交没什么作用,为此,angular2提供了一个NgSubmit指令于form标签,这样我们就可以绑定事件到模型的submit方法上用来出来表单的提交了。例子如下:
import { Component } from 'angular2/core';
import { FORM_DIRECTIVES } from 'angular2/common';
@Component({
selector: 'demo-form',
directives: [FORM_DIRECTIVES],
template: `
<form #f="ngForm" (ngSubmit)="onSubmit(f.value)">
<input type="text" ngControl="sku">
<button type="submit" class="button">Submit</button>
</form>
`
})
export class DemoForm {
onSubmit(value: string): void {
console.log('you submitted value: ', value);
}
}该例子中,我们定义了一个模板局部变量#f,并用NgForm指令来初始化它的值,这样我们就能通过submit来获取该表单需要提交的数据结构了。
Zones 是一个持续异步任务的执行上下文,允许 Zone 的创建者观察并控制其区域内代码的执行,Zones 的职责是对宿主环境的任务调度和处理,例如被用来 Debug 或测试等,对于某些框架如 Angular,Zones 主要被用作通知变化监测。
在深入理解 Zones 之前,我们需要了解 Zones 是如何创建的。通过引入 zone.js 库,可以在应用中全局的使用 Zone,该 Zone 我们通常称之为跟 Zone。而创建子 Zone 只需要在父 Zone 中 fork 另一份实例即可,示例代码如下:
let rootZone = Zone.current;
// 从父 Zone 中 fork 一个新的实例 ZoneA
let zoneA = rootZone.fork({name: 'zoneA'}); 通常情况下,我们需要将不同的框架或者业务代码在不同 Zone 的执行上下文中运行,Zone.current 表示当前执行环境下的宿主 Zone,唯一改变 Zone.current 的方式是使用 Zone.prototype.run() 方法,可以使用 run() 方法来控制 Zones 的进入或退出。通过下面的例子来加深对这个概念的理解,示例代码如下:
zoneA.run(fnOuter() => {
// 通过 `run()` 方法,`Zone.current` 被更新,当前 Zone 为 zoneA
console.log(Zone.current === zoneA);
// Zones 可以相互嵌套
rootZone.run(fnInner => () {
// 通过 `run()` 方法,`Zone.current` 被更新,当前 Zone 为 rootZone
// 同时让当前执行环境逃离 zoneA
console.log(Zone.current === rootZone);
});
});通过对上文的理解,我们知道了如何将某框架或者业务逻辑代码的执行环境加入或逃离某个 Zone,这对异步操作的跟踪是有意义的。通过下面的例子来说明,示例代码如下:
let rootZone = Zone.current;
let zoneA = rootZone.fork({name: 'A'});
setTimeout(timeoutCb1() => {
console.log('该 callback 将在 rootZone 中执行', Zone.current === rootZone);
}, 0);
zoneA.run(run1() => {
console.log('该 callback 将在 zoneA 中执行', Zone.current === zoneA);
setTimeout(timeoutCb2() => {
console.log('该 callback 将在 zoneA 中执行', Zone.current === zoneA);
}, 0);
});一旦异步工作被有序的调度执行的时候,回调函数将在与调用异步 API 时存在的 Zone 中执行,通过包装到 Zone 中的回调,所有的这些操作导致的调度任务将会被指向当前的 Zone 中。跟踪异步操作重要的作用是允许通过在 wrapCallback 之前或之后使用不同的请求方式来拦截它们。在某些情形下,包裹后的 wrapCallback 在有进程调度时,将在当前的 wrapCallback 完成调度,以确保每个异步任务的相互不影响。
上文提到了一个重要概念是回调包装,Zone 一个重要的方面就是支持跨异步操作,为了实现跨异步操作,当有一个任务需要通过异步 API 获取数据时,是需要捕获并恢复当前 Zone。举个例子,在某个 Zone 的上下文中执行一个异步操作如 setTimeout,这个 setTimeout() 方法需要完成的步骤是:
Zone.current 捕获当前 Zone;callback() 方法被执行则将会恢复当前 Zone也就是说,管理当前代码的规则将保留在将要执行的异步任务中,它将区别于其他的 Zone,不同的 Zone 关联着不同的异步任务并且有自己的规则,随着这些异步任务被处理,每一个异步的 wrapCallback 将准确的恢复其当前 Zone,同时保存以备下次异步任务的时候再次被调度。
为了说明这两个步骤的必要性,我们举例说明如下,通过调用 fetch() 方法来返回一个 promise,在 fetch() 方法内部可以使用它当前的 Zone 来做错误处理,而在应用中通过 then() 来返回请求结果,这使得跟踪异步操作井然有序。
父子 Zone 之间存在着继承关系,同样的也遵循了 JavaScript 的原型继承,Zone 的每个函数在被执行时都会创建自己的执行环境,当代码在某一执行环境中运行时,会创建由变量对象构成的一个作用域链,这确保了执行环境对所有变量或者函数的有序访问。通过下面的例子来理解一下 Zone 的继承,示例代码如下:
let rootZone = Zone.current;
let zoneA = rootZone.fork({name: 'zoneA', properties: {a: 1, b:1}});
let zoneB = zoneA.fork({name: 'zoneA', properties: {a: 2}});
console.log('zoneA 属性 a 的值是:', zoneA.get('a')); // 1
console.log('zoneA 属性 b 的值是:', zoneA.get('b')); // 1
console.log('zoneB 属性 a 的值是:', zoneB.get('a')); // 2
// 在当前 Zone 获取不到某属性是,将向父 Zone 查询改属性
console.log('zoneB 属性 b 的值是:', zoneB.get('a')); // 1Zones 可以通过 Zone.fork() 来组合在一起,并且所有运行在 Zone 中的业务代码都有一个根 Zone,确保所有的代码都在其中,并且其将有很多的子 Zone。子 Zone 有其独立的运行规则,其功能大致如下:
父子 Zone 之间通过 ZoneDelegate 来实现交互的,一个子 Zone 不能简单的调用父 Zone 中的方法,要实现继承父类方法的功能,需要在子 Zone 创建一个回调函数并且绑定到父 Zone 中。我们要做的就是在有异步操作触发该回调的时候拦截它,以便来确定是否需要通过 ZoneDelegate 再进一步触发父类中的方法。
并不是每个子 Zone 都重写了父 Zone 中的方法,不过 ZoneDelegate 存储了当前 Zone 最近的父 Zone 的一份实例,以便向上调用相关的方法。下面通过表格进一步说明他们之间的关系:
| Zone | ZoneDelegate | 描述 |
|---|---|---|
| run | invoke | 当运行在 run() 方法中的代码块被执行,ZoneDelegate 的钩子 invoke() 被调用,则表示在不改变当前 Zone 的情况下,允许向父级 Zone 派发钩子,即执行父 Zone 对应的钩子。 |
这就是父子组件间的可组合型。可组合性确保了 Zone 之间的职责分明,例如顶层的父 Zone 可以处理一些全局的错误处理,而子 Zone 则可以选择做用户行为跟踪。
通过上文对 Zones 的介绍,我们对其有了一个大致的认识。Zones 实际上是 Dart 的一种语言特性,是一种用于拦截和跟踪异步工作的机制,可以简单地将其理解为一个异步事件拦截器,也就是说 Zones 能够 hook 到异步任务的执行上下文,并在一些关键节点上重写相应的钩子方法,以此来完成某些操作。Zone 是一个全局对象,其配置了相应的规则用于拦截和跟踪异步回调,主要功能如下:
Zone 本身不做任何事情,它仅仅在执行异步任务或事件的时候去执行相应的钩子。zone.js 库重写了(monkey patches)所有的浏览器异步 API 并且在执行的时候将这些异步任务和事件重定向到新的 API 上,即 Zone 能够获取到异步任务或事件的执行上下文,并在一些关键节点上重写相应的钩子方法,以此来完成某些操作。下面以猴子补丁 setTimeout 来说明其被重写的过程,示例代码如下:
// 原生的 setTimeout
let originalSetTimeout = window.setTimeout;
// 重写 setTimeout
window.setTimeout = function(callback, delay) {
return originalSetTimeout(
// 在 Zone 中通过包装回调函数重写 setTimeout
Zone.current.wrap(callback),
delay
);
}
// zone.js 源码缩略
Zone.prototype.wrap = function (callback, source) {
// ...
var _callback = this._zoneDelegate.intercept(this, callback, source);
var zone = this; // 捕获当前 Zone
return function () {
// 在当前的 Zone 中执行最初的 callback
return zone.runGuarded(_callback, this, arguments, source);
};
};上面的代码示例中,Zone.prototype.wrap() 方法用于重新包装 callback,该 callback 通过 Zone.prototype.runGuarded() 来执行,执行的过程中将会被 ZoneSpec.onInvoke() 拦截并在该函数中处理,Zone.prototype.runGuarded() 方法类似于 Zone.prototype.run(),不同的是,除了将包裹函数执行在当前 Zone 之外,它还处理异步操作的异常捕获,任何的异常都会被捕获,并在 Zone.HandleError() 方法中处理。
通过前面的介绍可以了解到,Zones 以同样的接口、不同的方式实现并重写了一系列与事件相关的标准方法。因此,当开发者使用标准接口时,实际上会先调用 Zones 的重写方法,再由这些方法调用底层的标准方法。这种对上层应用透明的设计,使得在引入 Zones 的时候,原有代码不需要做太大的改动。
废弃【基于zone.js 0.6.x以下版本】
Angular应用程序通过组件实例和模板之间进行数据交互,也就是将组件的数据和页面DOM元素关连起来,当数据有变化后,NG2能够监测到这些变化并更新视图,反之亦然,它的数据流向是单项的,通过属性绑定和事件绑定来实现数据的流入和流出,数据从属性绑定流入组件,从事件流出组件,数据的双向绑定就是通过这样来实现的。那么它是如何实现变化检测的呢?
试想一下,在什么样的场景下,angular才需要去更新视图:
setTimeout, setInterval, requestAnimationFrame都是在某个延时后触发。以上的共同特征是什么?很明显共同点是它们都是异步的处理,即需要使用异步回调函数,这带给我们的结论就是,不管任何时候的一个异步操作,我们应用程序状态可能已经被改变,这就需要告诉Angular去更新视图。
我们创建一个组件来呈现一个Todo例子,我们可以在模板中这样使用这个组件:
<todo-cmp [model]="myTodo" (complete)="onCompletingTodo(todo)"></todo-cmp>
这将告诉Angular不管任何时候myTodo发生改变,Angular必须通过调用视图模型设置的myTodo数据(model setter)来自动的更新todo模板组件。
同样的,数据的流出是通过事件绑定来实现的,如果一个complete事件被触发,它将调用这个onCompletingTodo方法,该方法可能是一个获取后台最新数据的操作,这将需要用后台返回的异步数据与之前的数据参考进行对比来确定是否需要更新视图。
正如上面的例子,Angular2的属性和事件绑定的核心语法是很简单的,我们通过属性绑定实现了数据从父传递给了子,而事件绑定则实现了数据由子到父的传递,这也就是Angular2用来实现数据双向绑定的方法。它实现的是单向流的数据传递,也就是说,你的数据流只能向下流入组件,如果你需要进行数据变化,你可以发射导致变化的事件到顶部,待数据变化处理完成,然后再往下流入组件。那么问题来了,Angular2如何知道数据是否已经处理处理完成,这份新的数据是否有变化,如果数据有变化,那是怎么来通知数据往下流入组件通知组件来改变视图呢?这里我们先理解zone。
Zone实际上是Dart的一种语言特性,其是对Javascript某些设计缺陷的一些补充,简单的可以概述成Zone是一个异步事件拦截器,也就是说Zone能够hook到异步任务的执行上下文,以此来处理一些操作,比如说,在我们每次启动或者完成一个异步的操作、进行堆栈的跟踪处理、某段功能代码进入或者离开zone,我们可以在这些关键的节点重写我们所需处理的方法。
Zone中提供了各类hooks,允许在每一个回调函数的开始和结束时,去执行统一的自定义逻辑,其本身是不做任何事的,相反它是依赖其它的代码,获取到这些代码片段的执行上下文,通过hooks来完成相关的功能。Zone的另一个值得一提的是它必须依赖异步操作,当一个异步操作在执行时,它是有必要去捕获的这个异步操作并在该异步功能开始或者完成时建立对应的callback,然后存储到当前的zone,举个例子,如果一个代码片段在fork的zone中执行,并且这段代码中包含一个setTimeout的异步任务,那么执行到和完成这个setTimeout方法需要包裹一个异步的回调函数,存储到当前zone。
这样是确保每个异步操作之间的相互不受影响,也就是受保护的状态,例如一个页面由业务代码和一些第三方广告代码组成,这两份代码之间是相互独立的,我们需要的是业务代码的异常捕获数据提交到我们自己的后台服务器上,第三方广告代码的异常捕获提交到他们自己的服务器上。当fork了多个zone之后,异步操作将会精准的执行其所在的子zone上面方法。
Zone的一个重要意义在于,我们的功能或者业务代码运行在了fork的一个zone中,我们zone有了对该代码块执行上下文的控制权。其中也提供了一些钩子(hook)来处理我们基本的业务情景需求,大致有:
下面我们通过这样的一个例子来帮助你理解Zone,简单的代码如下:
zone.fork({
beforeTask: () => {
console.log('hi, beforeTask in.');
},
afterTask: () => {
console.log('hi, afterTask in.');
}
}).run(function () {
zone.inTheZone = true;
setTimeout(function () {
console.log('in the zone: ' + !!zone.inTheZone);
}, 0);
});
console.log('in the zone: ' + !!zone.inTheZone);这段代码按照执行上下文顺序的执行,我们在zone的run函数执行的开始和结束会有对应的hooks,例如要统计这段代码执行所消耗的时间,然而通常情况下,这里的异步处理,比如说是服务端异步返回给我们所需要的数据,或者是一些异步事件更改视图模型的数据等。这样通过beforeTask和afterTask统计到整个代码的耗时。这种情形在zone得到了很好的解决,Zone能够hook到异步任务的执行上下文,在异步事件发生或者结束的时候,允许我们在这样的异步任务节点执行一些分析代码。zone使用也很简单,一旦我们引入zone.js,那我们在全局作用域中可以获取到zone对象。
但是这远远不够的,很多时候我们的应用场景要比这个复杂的多,现在是时候体现zone的暴力美了,zone.js采用猴子补丁(Monkey-patched)的方式将Js中的异步任务都进行了包裹,同样的这使得这些异步任务都将运行在zone的执行上下文中,每一个异步的任务在zone.js都是一个task,除了提供了一些供开发者使用的勾子(hook)函数外,默认情况下zone.js重写了并提供了如下的方法:
综上所述,我们应该能理解zone.js的应用场景了,即实现了异步task的跟踪分析和错误记录以便更好的进行开发debug等。接下来将回到主题来探讨一下Angular2的数据绑定和zone的关系。
在Angular1.x中,默认的选择是双向的数据绑定,你的控制器数据发生变化,或者表单直接操作数据变动等,最终体现在视图中显示数据。
Angular1.x双向数据绑定的问题是,随着你的项目增长,它往往会导致整个应用的级联效应,并很难跟踪你的数据流。除非你使用Angular1.x框架的内置服务和指令,否则我们在model上做数据修改或者数据输出,Angular是无法预知的,当然就不会去更新视图模板中的数据来展示给UI。
好在Angular2框架把zone.js作为依赖,因为zone.js是一个独立的库,可以不依赖于其他库或者框架而单独被使用,因此在Angular2开发的应用中,zone拥有angular应用运行环境的执行上下文,事实证明,zone是能够解决在我们在angular应用中变化监测的问题的。
下面我们来介绍ngZone。实际上,ngZone是基于Zone.js来实现的,Angular2 fork了zone.js,它是zone派生出来的一个子zone,在Angular环境内注册的异步事件都运行在这个子zone上(因为ngZone拥有整个Angular运行环境的执行上下文),并且onTurnStart和onTurnDone事件也会在该子zone的run方法中触发。
在Angular2源码中,有一个ApplicationRef类,其作用是用来监听ngZone中的onTurnDone事件,不论何时只要触发这个事件,那么将会执行一个tick()方法用来告诉Angular去执行变化监测。
// very simplified version of actual source
class ApplicationRef {
changeDetectorRefs:ChangeDetectorRef[] = [];
constructor(private zone: NgZone) {
this.zone.onTurnDone
.subscribe(() => this.zone.run(() => this.tick());
}
tick() {
this.changeDetectorRefs
.forEach((ref) => ref.detectChanges());
}
}现在我们已经知道了Angular2的变化监测在何时被触发,那它是怎么去做变化监测的呢?实际上在Angular2中,任何的一个Angular2应用都是由大大小小的组件组成的,可以把它看成是一颗线性的组件树,重要的是,每一个组件都有自己的变化检测器。这样的一个图可以帮助你理解这些概念,具体也可以参考我翻译的关于Angular2变化监测的文章。
正是因为每个组件都拥有它的变化检测器,组成了Angular2应用的一颗组件树,同样的我们也有变化监测树,它也是线性的,数据的流向也是从上到下,因为变化监测在每个组件中的执行也是从根组件开始,从上往下的执行。单向的数据流相对angular1.x的环形数据流来说要更好预测的多,其实我们清楚视图中数据的来源,也就是说这些数据的变化是来自于哪个组件数据变化的结果。我们来举个例子吧:
@Component({
template: '<v-card [vData]="vData"></v-card>'
})
class VCardApp {
constructor() {
this.vData = {
name: '***',
email: '****@**.com'
}
}
changeData() {
this.vData.name = '*****';
}
}Angular2在整个运行期间都会为每一个组件创建监测类,用来监测每个组件在每个运行周期是否有异步操作发生。当变化监测被执行时会发生什么呢?假象一下changeData()方法在一个异步的操作之后被执行,那么vData.name被改变,然后被传递到<v-card [vData]="vData"></v-card>的变化检测器来和之前的数据对比是否有改变,如果和参照数据对比有变动的话,Angular将更新视图。
因为在JavaScript语言中不提供给我们对象的变化通知,所以Angular必须保守的要对每一个组件的每一次运行结果执行变化检测,但其实很多组件的输入属性是没有变化的,没必要对这样的组件来一次变化监测,如何减少不必要的监测,我们有两种方式去实现。
不可变对象(Immutable Objects)给我们提供的保障是对象不会改变,即当其内部的属性发生变化时,相对旧有的对象,我们将会保存另一份新的参照。它仅仅依赖输入的属性,也就是当输入属性没有变动(没有变动即没有产生一份新的参照),Angular将跳过对该组件的全部变化监测,直到有属性变化为止。如果需要在Angular2中使用不可变对象,我们需要做的就是设置changeDetection: ChangeDetectionStrategy.OnPush,如下的例子:
@Component({
template: `
<h2>{{vData.name}}</h2>
<span>{{vData.email}}</span>
`,
changeDetection: ChangeDetectionStrategy.OnPush
})
class VCardCmp {
@Input() vData;
}例子中,VCardCmp仅仅依赖它的输入属性,同时我们也设定了变化监测策略为OnPush来告诉Angular如果属性属性没有任何变化的话,则跳过该组件的变化监测。
和不可变对象类似,但却又和不可变对象不同,它们有相关变化的时候不会提供一份新的参照,可观测对象在输入属性发生变化的时候来触发一个事件来更新组件视图,同样的,我们也是添加OnPush来跳过子组件树的监测器,我们给这样的一个例子来帮你加深理解:
@Component({
template: '{{counter}}',
changeDetection: ChangeDetectionStrategy.OnPush
})
class CartBadgeCmp {
@Input() addItemStream:Observable<any>;
counter = 0;
ngOnInit() {
this.addItemStream.subscribe(() => {
this.counter++; // application state changed
})
}
}该组件是模拟的当用户触发一个事件后增加counter这样一个场景,确切的讲,CartBadgeCmp设置了一个插值counter和一个输入属性addItemStream,当有异步操作需要更新counter的时候,将会触发一个事件流,但是输入属性addItemStream作为参考对象将不会更改,意味着该组件树的变化监测将不会发生。那怎么办?我们将怎么来通知Angular某区块有改变呢?Angular2的变化监测总是从组件树的头到尾来执行,我们其实需要的就是在整个组件树的某个发生改变的地方来做出相应即可,Angular是不知道那一块目录有改变的,但是我们知道,我们可以通过依赖注入给组件来引入一个ChangeDetectorRef,这个方法正是我们所需要的,它能标记整颗组件树的目录直到下一次变化监测的执行,代码示例如下:
class CartBadgeCmp {
constructor(private cd: ChangeDetectorRef) {}
@Input() addItemStream:Observable<any>;
counter = 0;
ngOnInit() {
this.addItemStream.subscribe(() => {
this.counter++; // application state changed
this.cd.markForCheck(); // marks path
})
}
}当这个可监测的addItemStream触发一个事件,该事件处理句柄将会从根路径到这个已经改变的addItemStream组件来处理监测,一旦变化监测跑遍整个监测路径,它将会存储OnPush状态到整个组件树。这样做的好处是,变化监测系统将会走遍整棵树,你可以利用他们来监测树在局部是否有真正的改变,以此来做出相应的改变。
好了,当目前为止,我们已经清楚了Angular2的变化监测的实现,个人理解可能有不到位的地方,欢迎指正。
webkit 内核渲染过程图:
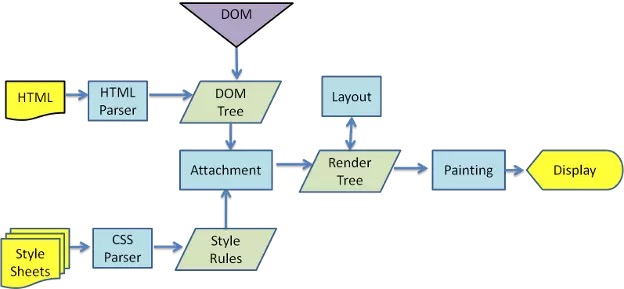
gecko 内核渲染过程图:
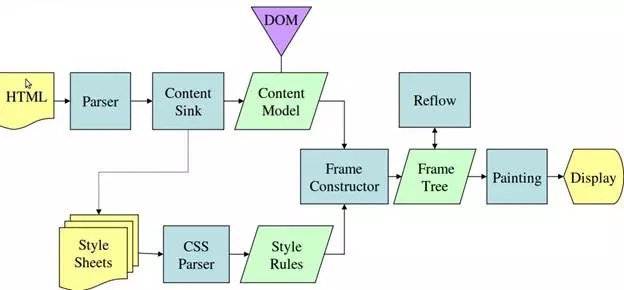
不同的浏览器内核有着不一样的渲染过程,细节不一致但大致的浏览器渲染的流程如下:
通过上面的流程则能很好的回答问题了。
而 JS 可能有调用相关 API 更新 DOM 节点和 CSS,在操作前必须等待这些元素渲染完毕,浏览器会维持 HTML 中 css 和 JS 的顺序,因此,样式表会在后面的 JS 执行前先加载执行完毕,所以,这也是阻碍的。
目前大多数设备的屏幕刷新率为 60 次/秒。因此,如果在页面中有一个动画或渐变效果,或者用户正在滚动页面,那么浏览器渲染动画或页面的每一帧的速率也需要跟设备屏幕的刷新率保持一致。
其中每个帧的预算时间仅比 16 毫秒多一点 (1 秒/ 60 = 16.66 毫秒)。但实际上,浏览器有整理工作要做,因此您的所有工作需要在 10 毫秒内完成。如果无法符合此预算,帧率将下降,并且内容会在屏幕上抖动。 此现象通常称为卡顿,会对用户体验产生负面影响。
像素至屏幕管道中的关键点:

JavaScript
一般来说,使用 JavaScript 来实现一些视觉变化的效果。比如用 jQuery 的 animate 函数做一个动画、对一个数据集进行排序或者往页面里添加一些 DOM 元素等。当然,除了 JavaScript,还有其他一些常用方法也可以实现视觉变化效果,比如:CSS Animations、Transitions 和 Web Animation API。
Style
此过程是根据匹配选择器(例如 .headline 或 .nav > .nav__item)计算出哪些元素应用哪些 CSS 规则的过程。从中知道规则之后,将应用规则并计算每个元素的最终样式。
Layout
在知道对一个元素应用哪些规则之后,浏览器即可开始计算它要占据的空间大小及其在屏幕的位置。
网页的布局模式意味着一个元素可能影响其他元素,例如 元素的宽度一般会影响其子元素的宽度以及树中各处的节点,因此对于浏览器来说,布局过程是经常发生的。
Paint
绘制是填充像素的过程。
它涉及绘出文本、颜色、图像、边框和阴影,基本上包括元素的每个可视部分。
绘制一般是在多个表面(通常称为层)上完成的。
Composite
由于页面的各部分可能被绘制到多层,由此它们需要按正确顺序绘制到屏幕上,以便正确渲染页面。
对于与另一元素重叠的元素来说,这点特别重要,因为一个错误可能使一个元素错误地出现在另一个元素的上层。
管道的每个部分都有机会产生卡顿,因此务必准确了解您的代码触发管道的哪些部分。
每一帧并不一定总是需要经过像素管道每个部分的处理。
可以直接参考:理解 async/await
ES7 提出的 async 函数,终于让 JavaScript 对于异步操作有了终极解决方案(No more callback hell
Async 函数的改进在于下面四点:
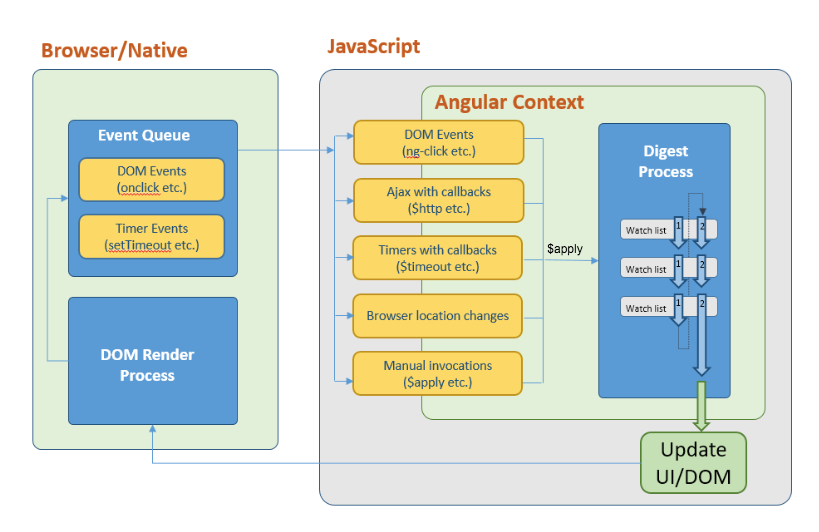
主要了解 $watch、$digest、$apply
参考下图:
在开发过程中,很多时候都在熟练的使用 Promise/A+ 规范,然而有时在使用的时候发现并不是很了解它的底层实现,下面扒一扒它的实现。
本文基于 AngularJs $q
Promise 是 JS 异步编程中的重要概念,异步抽象处理对象,是目前比较流行 Javascript 异步编程解决方案之一。
术语
Promise 解决的就是异步任务处理问题,简单举例如下(假设有一个异步任务 asyncJob1,它执行完成后要执行 asyncJob2):
// asyncJob2 作为参数传给 asyncJob1,在它完成某些操作后调用
asyncJob1(asyncJob2)
// asyncJob1 的伪代码
function asyncJob1(callback) {
// some task to get the 'result'
callback(result);
}这样做的问题是 callback 的控制权在 asyncJob1 里面了,并且若有多个异步任务将会有回调地狱的问题,如:
asyncJob1(param, function(job1Result) {
asyncJob2(job1Result, function (job2Result) {
asyncJob3(job2Result, function (job3Result) {
alert('we are done');
// ...
}
});
})稍稍把代码修改一下:
function asyncJob1() {
// some task to get the 'result'
// ...
return function (callback) {
callback(result);
}
}那么调用的方式就是:
asyncJob1()(function (job1Result) {
// ...
});写代码的时候,「同步」的写法语义更容易理解,即”干完某件事后,再处理另外一件事”,通过 then 方法来实现链式调用:
function asyncJob1() {
// some task to get the 'result'
return {
then: function (callback) {
callback(result);
}
}
}可按照如下例子来调用,这样看起来就更有序了。
asyncJob1(param).then(function (job1Result) {
return asyncJob2(job1Result);
}).then(function (job2Result) {
return asyncJob3(job3Result);
}).then(function (job3Result) {
// finally done
});带着上面的思路,接下来实现一个简版的 Promise。
上面的例子,都是函数执行完成后同步执行回调,看下面的例子:
var Promise = function () {
var _callback, _result;
return {
resolve: function (result) {
_result = result;
if (_callback) {
_callback(result);
}
_callback = null;
},
then: function (callback) {
_callback = callback;
}
}
};于是上面的回调实现就可以变成:
function asyncJob1(param) {
var promise = Promise();
setTimeout(function monkey() {
var result = param + ' with job1';
promise.resolve(result);
}, 100);
return promise;
}
asyncJob1('monkey').then(function (result) {
console.log('we are done', result);
});有时在某件事完成之后,可以同时做其他的多件事情,为此修改 Promise,增加回调队列:
var Promise = function () {
var _pending = [], _result;
return {
resolve: function (result) {
_result = result;
if (_pending) {
for (var i = 0, l = _pending.length; i < l; i++) {
_pending[i](_result);
}
}
_pending = null;
},
then: function (callback) {
_pending.push(callback);
}
}
};于是在 job1 后可以添加多个回调
var job1 = asyncJob1('monkey');
job1.then(function (result) {
console.log('we are done1:', result);
});
job1.then(function (result) {
console.log('we are done2:', result);
});这样之后可能还不够,因为如果另外一个回调是异步处理的话,可能就没法得到结果了,比如:
var job1 = asyncJob1('monkey');
job1.then(function (result) {
console.log('we are done1:', result);
});
setTimeout(function () {
job1.then(function (result) { // then 调用时已经报错了
console.log('we are done2:', result); // 此处没有打印
});
}, 1000);可以在 then 中增加一个判断,如果已经 resolve 过了,则直接执行回调:这样处理后上面的'done2'就可以输出了
var Promise = function () {
...
return {
...
then: function (callback) {
if (_pending) {
_pending.push(callback);
} else {
callback(_result);
}
}
}
};以上的 Promise 返回后,外部可以直接访问 then、resolve 这两个方法,然而外部应该只关心 then,resolve 方法不应该暴露出去,防止外部调用 resolve 修改了 Promise 的状态。代码修整如下:
var Deferred = function () {
...
return {
...
promise: {
then: function (callback) {
...
}
}
}
};以上只列出了修改的代码,可以看出这个改动很小,其实就是给 then 封装多了一层,调用的方式就变成如下:
function asyncJob1(param) {
var defer = Deferred();
setTimeout(function () {
var result = param + ' with job1';
defer.resolve(result);
}, 100);
return defer.promise;
}
asyncJob1('monkey').then(function (result) {
console.log('we are done', result);
});截到目前为止,promise 原型还不能实现链式调用,比如这样调用的话,第二个 then 就会报错
asyncJob1('monkey').then(function (job1Result) {
return asyncJob2(job1Result);
}).then(function (job2Result) { // <-- 此处的then会报错
console.log('we are done', job2Result);
});链式调用是promise很重要的特性,为了实现链式调用,我们要实现:
先来看看代码实现:
var Deferred = function () {
var _pending = [], _result;
return {
resolve: function (result) {
_result = result;
if (_pending) {
for (var item, r, i = 0, l = _pending.length; i < l; i++) {
item = _pending[i];
r = item[1](_result);
// 如果回调的结果返回的是 promise(有then方法), 则调用 then 方法并将 resolve 方法传入
if (r && typeof r.then === 'function') {
r.then.call(r, item[0].resolve);
} else {
item[0].resolve(_result);
}
}
}
_pending = null;
},
promise: {
then: function (callback) {
// 创建一个新的 defer 并返回, 并且将 defer 和 callback 同时添加到当前的 pending 中
var defer = Deferred();
if (_pending) {
_pending.push([defer, callback]);
} else {
callback(_result);
}
return defer.promise;
}
}
}
};执行以下代码,我们能得到:we are all done! monkey with job1 with job2 的输出
asyncJob1('monkey').then(function cbForJob1(job1Result) {
return asyncJob2(job1Result);
}).then(function cbForJob2(job2Result) {
console.log('we are all done!', job2Result);
});以上的 Promise 都是只有成功的 resolve 调用,在使用的 Promise 都能接受 2 个回调:resolve、reject。
为了实现可以 reject,需要引入一个 promise 的状态,记录它是被 resolve 还是 reject 过。
var Deferred = function () {
var _pending = [], _result, _reason;
var _this = {
resolve: function (result) {
if (_this.promise.status !== 'pending') {
return;
}
_this.promise.status = 'resolved';
_result = result;
for (var item, r, i = 0, l = _pending.length; i < l; i++) {
item = _pending[i];
r = item[1](_result);
// 如果回调的结果返回的是 promise(有then方法), 则调用 then 方法并将 resolve 方法传入
if (r && typeof r.then === 'function') {
r.then.call(r, item[0].resolve, item[0].reject);
} else {
item[0].resolve(_result);
}
}
},
reject: function (reason) {
if (_this.promise.status !== 'pending') {
return;
}
_this.promise.status = 'rejected';
_reason = reason;
for (var item, r, i = 0, l = _pending.length; i < l; i++) {
item = _pending[i];
r = item[2](_reason);
if (r && typeof r.then === 'function') {
r.then.call(r, item[0].resolve, item[0].reject);
} else {
item[0].reject(_reason);
}
}
},
promise: {
then: function (onResolved, onRejected) {
// 创建一个新的 defer 并返回, 并且将 defer 和 callback 同时添加到当前的 pending 中
var defer = Deferred();
var status = _this.promise.status;
if (status === 'pending') {
_pending.push([defer, onResolved, onRejected]);
} else if (status === 'resolved') {
onResolved(_result);
} else if (status === 'rejected') {
onRejected(_reason);
}
return defer.promise;
},
status: 'pending'
}
};
return _this;
};为了简单起见,reject的代码和resolve差不多,可以抽取一下减少多余的代码。
在上面的所有调用中,resolve 或 reject 里的回调调用都是同步的,这取决于回调的实现。如果回调本身是同步的,就可能会出问题。
比如按上面的 promise 的代码,把 job 的调用中的 setTimeout 去掉,就会得不到结果。
function asyncJob1(param, isOk) {
var defer = Deferred();
//setTimeout(function () {
var result = param + ' with job1';
if (isOk) {
defer.resolve(result);
} else {
defer.reject('job1 fail');
}
//}, 100);
return defer.promise;
}
function asyncJob2(param, isOk) {
var defer = Deferred();
//setTimeout(function () {
var result = param + ' with job2';
if (isOk) {
defer.resolve(result);
} else {
defer.reject('job2 fail');
}
//}, 100);
return defer.promise;
}
asyncJob1('monkey', true).then(function (job1Result) {
return asyncJob2(job1Result, true);
}).then(function (job2Result) {
console.log('we are all done!', job2Result); // 无输出
});调用时机
resolve 和 reject 只有在执行环境堆栈仅包含平台代码时才可被调用 注1
注1 这里的平台代码指的是引擎、环境以及 promise 的实施代码。实践中要确保 resolve 和 reject 方法异步执行,且应该在 then 方法被调用的那一轮事件循环之后的新执行栈中执行。
这个事件队列可以采用“宏任务(macro - task)”机制或者“微任务(micro - task)”机制来实现。
由于 promise 的实施代码本身就是平台代码(译者注:即都是 JavaScript),故代码自身在处理在处理程序时可能已经包含一个任务调度队列。
所以我们要确保这些调用都是异步的,这里只是简单地用 setTimeout 来示意处理,这样之后像上面的调用也有结果输出了。
var Deferred = function () {
var _pending = [], _result, _reason;
var _this = {
resolve: function (result) {
if (_this.promise.status !== 'pending') {
return;
}
_result = result;
setTimeout(function () {
processQueue(_pending, _this.promise.status = 'resolved', _result);
_pending = null;
}, 0);
},
reject: function (reason) {
if (_this.promise.status !== 'pending') {
return;
}
_reason = reason;
setTimeout(function () {
processQueue(_pending, _this.promise.status = 'rejected', null, _reason);
_pending = null;
}, 0);
},
promise: {
then: function (onResolved, onRejected) {
var defer = Deferred();
var status = _this.promise.status;
if (status === 'pending') {
_pending.push([defer, onResolved, onRejected]);
} else if (status === 'resolved') {
onResolved(_result);
} else if (status === 'rejected') {
onRejected(_reason);
}
return defer.promise;
},
status: 'pending'
}
};
function processQueue(pending, status, result, reason) {
var item, r, i, l, callbackIndex, method, param;
if (status === 'resolved') {
callbackIndex = 1;
method = 'resolve';
param = result;
} else {
callbackIndex = 2;
method = 'reject';
param = reason;
}
for (i = 0, l = pending.length; i < l; i++) {
item = pending[i];
r = item[callbackIndex](param);
// 如果回调的结果返回的是promise(有then方法), 则调用then方法并将resolve方法传入
if (r && typeof r.then === 'function') {
r.then.call(r, item[0].resolve, item[0].reject);
} else {
item[0][method](param);
}
}
}
return _this;
};以上仅仅是简版的 Promise,离我们平常用的promise还差很远,仅仅给自己带来的一些思考。
redux 看上去足够简单,但却有非常强的规范约束,作为 react 全家桶中极为重要的组成部分,是 JavaScript 应用程序的可预测状态容器,是一种状态管理的解决方案。
import { createStore } from 'redux'
function counter(state = 0, action) {
switch (action.type) {
case 'INCREMENT':
return state + 1
case 'DECREMENT':
return state - 1
default:
return state
}
}
let store = createStore(counter)
store.subscribe(() =>
console.log(store.getState())
)
store.dispatch({ type: 'INCREMENT' }) // 1
store.dispatch({ type: 'INCREMENT' }) // 2
store.dispatch({ type: 'DECREMENT' }) // 1redux 的使用规范是确保整个应用程序的数据状态存储在单个 store 的对象树中,在 reducer 中更改状态树 state ,唯一方法是 dispatch action,这个 dispatch action 包含 type 及相关变化数据的一个对象。
一个应用往往有复杂的组件嵌套,单纯使用 redux的话,可以在最外层容器组件中初始化 store,通用做法是将 state 上的属性作为 props 层层传递下去,这种实践想想都是令人厌烦的。那接下来我们就引入 react-redux 的 connect。
react-redux 两个主要的 API 是 Provider、connect,我们先从一个简单的例子开始:
// root.js
class Root extends React.Component {
_store: Store<any>;
render() {
return (
<Provider store={this._store}>
<App />
</Provider>
);
}
}
// app.js
class App extends React.Component {}
const mapStateToProps = state => {
return {nav: state.router};
};
export default connect(mapStateToProps)(App);例子通过 connect 的方式将 store 数据连接到组件中,在 state 变化的时候,组件的 mapStateToProps 会被调用并重新计算出一个新的 stateProps 来更新当前组件数据。connect 做了两件事情,一是把组件需要的 store 对象树属性 map 到当前组件中,二是把组件需要的数据结构在这个 map 函数中以 plain Object 返回,这做可以方便的定制当前组件需要的数据从而避免了层层 store 数据的嵌套。
要理解 connect 是如何工作的,需要先理解以下两点:
旧版 context 的一个简单使用例子如下:
// 顶层组件
class Root extends Component {
getChildContext() {
return {
text: 'xxx'
}
}
render() {
return <Parent />
}
}
// 中间层组件
class IntermediateC extends Component {
render() {
return <Child />
}
}
// 需要数据的组件
class Child extends Component {
render() {
return this.context.text
}
}旧版 context 不用在每个中间层组件中都显示地将 props 设置到子组件的属性中,通过顶层组件中的 getChildContext() 方法设置需要返回的数据即可。
新版 context 用 Provider、Consumer 对来实现,Provider 用来包裹顶层组件,Consumer 用来包裹底层获取数据的组件。但是获取数据的组件有多个数据来源,那么以上的嵌套地域又将重现。关于新旧版的 context API 在使用上有很大区别,但本质上都是解决同样的问题,即解决跨组件数据传递的问题,只是新版 context API 更符合 react 风格。
Provider 查看源码其提供了3个方法:getChildContext、constructor、render,其中构造函数获取 props.store 供组件内部使用,render 方法返回一个 react 子元素,源码为 return Children.only(this.props.children),其中的 Children.only 是 react 提供的方法,this.props.children 表示的是一个 Provider 的子组件。
Provider 是一个容器组件, 从源码看做的事情很简单,即把嵌套的内容原封不动地作为子组件给渲染出来,最重要的是把 props.store 放到 context,从而子组件 connect 的时候都可以获取到。
要从 connect 源码看的确复杂了,这里不再逐行解析源码。我们来继续看看 connect 的使用:
connect(...args)(Component)
通过在根组件 Provider 组件设置 store 作为整个顶层组件的 context,其下所有子孙节点组件都可以获取到这个 store 对象树的数据。那接下来 connect 做的事情其实就很明了了,即 connect 首先执行的是一个 HOC,在这个高阶组件中,connect 接下来把 mapStateToProps 和 mapDispatchToProps 里的返回的属性,连同通过 context 获取到的 store 一起,过滤包装 store 数据最终传递给了被包裹的组件,connect 不会修改传递给它的组件类,相反它返回一个新的、被连接的组件类供开发者使用。
最后 connect 通过 redux store 的 subscribe API 来监听数据的变化,通过 shallowEqual 对比之前组件缓存的 props 和新计算出的属性,来决定是否需要更新组件,即重新将 args 里边的 props 传递给第二个被传入的 Component,达到更新组件的目的。理解了 connect 的工作原理,那么接下来就知道在开发过程中需要注意什么了。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.