代码很丑,但跑的通,字符分离那部分代码是很多年前写的,现在回过头看自己也蒙了,有空重写一下。祖传代码
Anaconda 2019.10(python 3.7) tensorflow2.0(别的版本应该都没什么问题,猜的)
爬取验证码图片,将验证码分离为独立字母保存本地,用来准备用于文字识别的训练集。核心函数splitImg,用于把验证码图片降噪后分离成独立字母,具体原理随后说。
把标注好的样本读入pandas并保存到本地
tensorflow训练模型,结构很简单。前面两个文档都不重要,都是准备数据的,直接运行“3.识别模型、4.模型测试”就行
读取一个验证码,识别后转换为字符串,输出。
乱七八糟一堆,有价值的代码只有两段,一个是从验证码中分离字母,另一个是卷积神经网络。
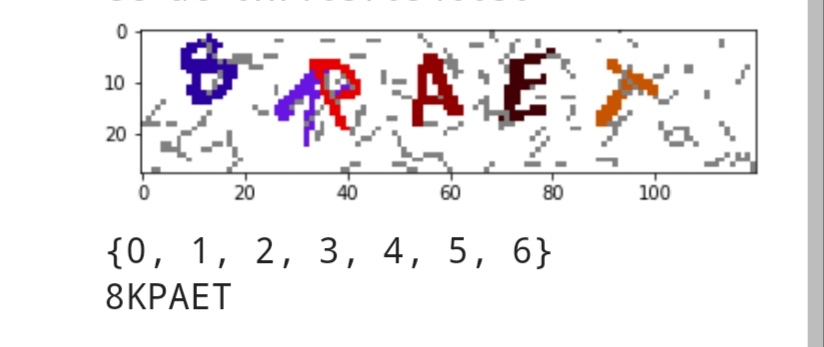
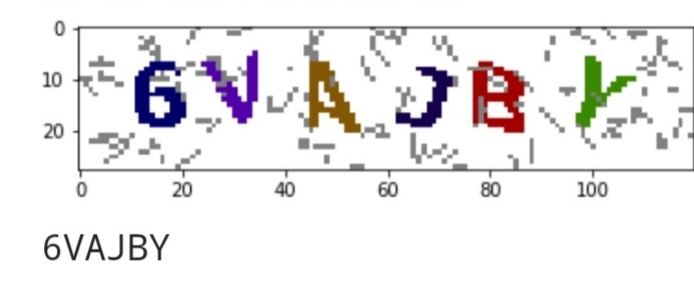
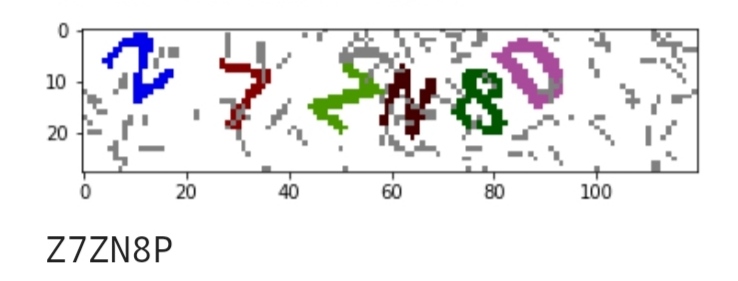
这个验证码难度偏低,特点是每次都是6位数字加字母验证码,没有0 1 O,每个字符颜色不同,噪声也比较有迹可循。 直接使用dbscan对图片坐标和颜色进行聚类后,会得到7个组,判断一下最大的那个一定是噪声,另外6个就是字符。
感觉没啥说的,我花了10块钱派我弟弟用了一晚上写作业时间帮我标注了1000多个样本。 神经网络结构是两个卷积层后面各跟一个池化层,再加一个全连接层和dropout层,输出one-hot向量。 20个轮次的训练识别率就基本上可以了,因为有dropout,多些轮次也可以,不过提高不大了。测试集识别率是93%,这样算起来6位验证码就是0.93的6次方,才65%,正常来说很不满意,不过考虑到才花了10块,够了够了。
