Klasifikasi Harga Handphone (HP).
Saat ini hp sudah sangat mudah untuk dimiliki oleh hampir semua orang, mulai dari yg harganya ratusan ribu hingga puluhan juta, tentu tergantung pada kebutuhan masing-masing orang, ada yang menganggap harga puluhan juta itu wajar dan ada yang mengangggapnya itu kemahalan.
- Hal tersebut tentu membuat kita kadang tidak jadi membeli suatu hp, karena kita khawatir apakah nanti semua fitur tersebut Gimmik atau bukan.
- Kita kadang juga merasa khawatir apakah semua fitur di suatu hp tersebut secara harga sesuai apa tidak, tentu kita tidak ingin terkena genjutsu sales-sales hp di toko yang mengatakah "Beli hp ini aja kak, PUBG rata kanan semua!", namun setelah di rumah kita baru sadar kok beli hp yang ini? Padahal tadi maunya bukan yang ini.
- Sebagai orang yang jarang tau berita tentang teknologi, dan sedang mencari hp dengan kelas harga tertentu kita kadang bingung dan kesusahan dalam menentukan pilihan
Solusi dari masalah tersebut, kita kembangkan sebuah model Machine Learning (ML) untuk membantu kita yang kesulitan menentukan sebuah rentang kelas harga dari hp, apakah hp dengan spesifikasi sekian-sekian yang berada di kelas harga menengah, apakah sesuai dengan kelas harganya, atau kita di tipu oleh sales-sales hp, karena mereka ingin prodak tersebut segera habis.
- Menurut (Aqmal Maulana, Spek HP berdasar harga)
- Menurut (Bang Dedy Irvan, Membedakan Hape Pakai Gimmick Marketing)
- Menurut (Bang Tira, Genjutsu Marketing)
- Dari serangkaian fitur yang ada, fitur apa yang paling berpengaruh terhadap kelas harga suatu hp?
- Berapa kelas harga pasar hp dengan karakteristik atau fitur tertentu?
- Mengetahui fitur yang paling berkorelasi dengan kelas harga hp.
- Membuat model machine learning yang dapat memprediksi kelas harga hp seakurat mungkin berdasarkan fitur-fitur yang ada.
- Untuk menghasilkan model yang optimal namun tetap sederhana kita akan menggunakan 3 algoritma yaitu KNeighborsClassifier, RandomForestClassifier, GradientBoostingClassifier.
- Dari 3 algoritma di atas kita akan menggunakan metrik
accuracy_scoredanclassification_reportyang memang cocok untuk kasus klasifikasi, untuk melihat pada ketiga algoritma diatas mana yang paling powerfull.
Kita akan menggunkan dataset yang berisi 21 variabel yang biasanya sering ditanyakan ketika membeli hp atau mungkin menjadi suatu standar yang digunakan masyarakat dalam menggolongkan kelas harga dari suatu hp.
Sumber dataset yang akan kita gunakan berasal dari Kaggle. Yang di publish oleh ABHISHEK SHARMA.
- battery_power : total kapasitas baterai dalam mAh
- blue : apakah memiliki bluethoot atau tidak
- clock_speed : kecepatan dari prosesor
- dual_sim : apakah mendukung dua sim card
- fc : kamera depan dalam mega pixel
- four_g : sudah 4G atau belum
- int_memory : memory internal
- m_dep : kedalaman hp dalam satuan cm
- mobile_wt : berat dari hp
- n_cores : jumlah dari core prosessor
- pc : kamera utama dalam mega pixel
- px_height : tinggi resolusi dalam satuan pixel
- px_width : lebar resolusi dalam satuan pixel
- ram : jumlah ram yang dipakai dalam satuan Megabytes
- sc_h : tinggi layar hp dalam satuan cm
- sc_w : lebar layar hp dalam satuan cm
- talk_time : lama penggunaan setelah satu kali pengisian daya
- three_g : sudah 3G atau belum
- touch_screen : sudah layar sentuh apa belum
- wifi : punya wifi atau tidak
- price_range : rentang harga
Dari 21 variabel diatas variabel price_range adalah sasaran kita, kita akan membuat model berdasar rentang harga yang ada di dalam variabel price_range, dengan nilai:
- 0 = low cost (Entry-level)
- 1 = medium cost (Mid-range)
- 2 = high cost (High-end)
- 3 = very high cost (Flagship / hp para Sultan)
Kita akan melakukan sedikit analisis untuk mengethui beberapa hal tentang variabel diatas diantaranya :
- Kita akan melihat ada berapa jumlah baris dari data dalam tampilan tabel.
- Kita akan melihat tipe data dari 21 kolom di dataset.
- Kita akan mengecek deskripsi statistik data.
- Kita akan melihat apakah ada data yang kosong / tidak ada isinya.
- Kita akan melihat apakah data kita memiliki outliers.
- Kita akan melihat variabel apa saja yang memiliki hubungan yang kuat atas klasifikasi harga suatu hp.
Langsung saja kita mulai dari yang pertama yaitu:
-
Kita akan melihat ada berapa jumlah baris dari data dalam tampilan tabel.
Kita akan menggunakan menggunakan kode
data_train,data_trainadalah nama variabel yang kita ganakan saat meload dataset kita.
Dari kode
data_trainkita mendapat informasi:- Ada 2000 baris dalam dataset
- Dan seperti yang dijelaskan dalam deskipsi variabel ada 21 kolom
-
Kita akan melihat tipe data dari 21 kolom di dataset.
Kita akan menggunakan
data_train.info(),.infoakan menampilkan informasi tipe data 21 kolom dataset yang kita gunakan.
Dari output terlihat bahwa:
- Terdapat 2 kolom numerik dengan tipe data float64 yaitu : clock_speed dan m_dept.
- Terdapat 19 kolom numerik dengan tipe data int64 yaitu : battery_power, blue, dual_sim, fc, four_g, int_memory, mobile_wt, n_cores, pc, px_height, px_width, ram, sc_h, sc_w, talk_time, three_g, touch_schreen, wifi dan price_range.
-
Kita akan mengecek deskripsi statistik data.
Kita akan mengeceknya dengan fungsi
describe().
Fungsi
describe()memberikan informasi statistik pada masing-masing kolom, antara lain:- Count adalah jumlah sampel pada data.
- Mean adalah nilai rata-rata.
- Std adalah standar deviasi.
- Min yaitu nilai minimum setiap kolom.
- 25% adalah kuartil pertama. Kuartil adalah nilai yang menandai batas interval dalam empat bagian sebaran yang sama.
- 50% adalah kuartil kedua, atau biasa juga disebut median (nilai tengah).
- 75% adalah kuartil ketiga.
- Max adalah nilai maksimum.
-
Kita akan melihat apakah ada data yang kosong / tidak ada isinya.
Kita akan mengeceknya dengan fungsi
.isnull().sum(). Fungsi.isnull()akan mengecek apakah ada data kosng pada setiap baris pada semua kolom di dataset kita, kemudian kita gunakan juga fungsi.sum()untuk menjumlahnya sehingga hasilnya akan seperti berikut.
Dari hasil outputnya data kita tidak memiliki data yang kosong.
-
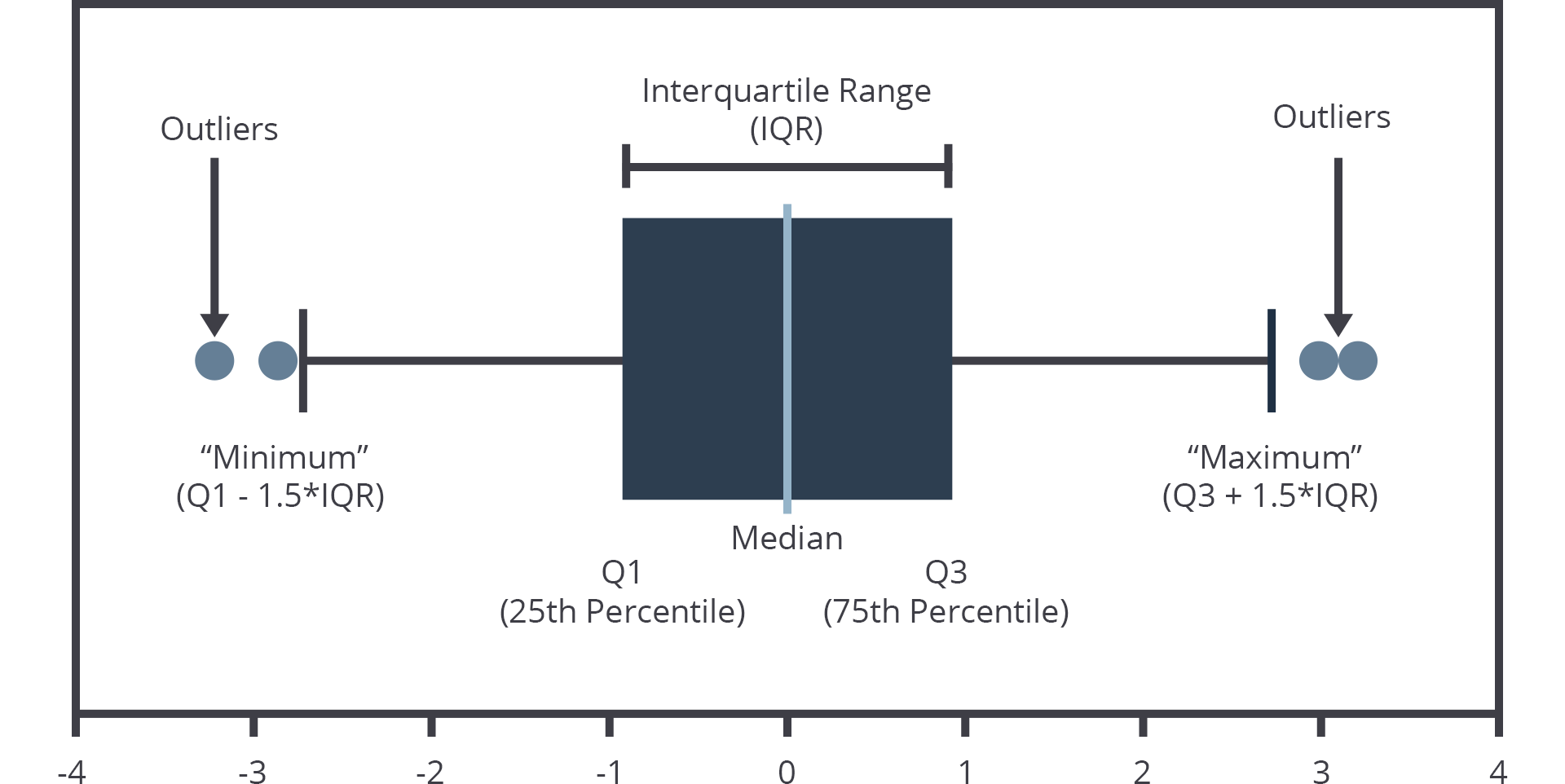
Kita akan melihat apakah data kita memiliki outliers.
Kita akan mengeceknya dengan fungsi
sns.boxplot(x=data_train['px_height'])[1]. Variabelsnsadalah tempat kita menampung library Seaborn yang akan kita gunakan untuk memvisualisaikan dataset kita. Fungsi.boxplot()akan menampilkan visualisasi dari dataset kita dengan visualisasi seperti gambar berikut:Dalam hal ini kita menggunakan sampel
px_heghtdari gambar bisa kita lihat adanya outliers.
Tenang tidak perlu panik kita akan mengatasinya dengan teknik IQR dimana data yang berada di luar Q1 dan Q3 adalah outlier, dimana kita akan menentukan nilai batas atas dan bawah, dengan persamaan berikut:
- Batas bawah = Q1 - 1.5 * IQR
- Batas atas = Q3 + 1.5 * IQR
Langsung saja kita set variabel Q1, Q2 dan IQR-nya
Q1 = data_train.quantile(0.25)Q3 = data_train.quantile(0.75)IQR=Q3-Q1
Setelah itu kita hitung dan hapus sekalian data yang tidak sesuai dengan spesifikasi yang kita buat dengan kode berikut
data_train=data_train[~((data_train<(Q1-1.5*IQR))|(data_train>(Q3+1.5*IQR))).any(axis=1)]data_train.shapekemudian kita periksa juga sisa dataset kita, yaitu tersisa 1506 baris dan 21 kolom
-
Kita akan melihat variabel apa saja yang memiliki hubungan yang kuat atas klasifikasi harga suatu hp.
Pertama kita akan melihat 21 kolom yang ada dalam dataset dalam bentuk tabel supaya kita bisa lebih mengetahui tentang isi dari nilai setiap kolom dengan kode berikut
data_train.hist(bins=50, figsize=(20,15))fungsi.hist()akan menampilkan data dalam bentul diagram dengan variabelbins=50adalah jumlah menara pada data yaitu 50 sedangfigsize=(20,15)adalah ukuran dari diagram kita. setelah itu kita gunkan kodeplt.show()untuk menampilkan diagramnya.

Dari tampilan diagram dapat kita simpulkan bahwa ada beberapa variabel yang bertipe biner atau yang isinya hanya 0 dan 1, dan ada yang isinya angka lebih dari itu. Kita lihat list dibawah untuk lebi jelas mana yang memiliki fitur biner dan bukan.
- binary_features = blue, dual_sim, four_g, three_g, touch_screen, wifi
- non_binary_features = battery_power, clock_speed, fc, int_memory, m_dep, mobile_wt, n_core, pc, px_height, px_width, ram, sc_h, sc_w, talk_time, price_range
Selanjutnya kita lanjut melihat setiap korelasi setiap fitur dengan dengan price_range, dengan koefisien korelasi berkisar antara -1 dan +1. Ia mengukur kekuatan hubungan antara dua variabel serta arahnya (positif atau negatif). Mengenai kekuatan hubungan antar variabel, semakin dekat nilainya ke 1 atau -1, korelasinya semakin kuat. Sedangkan, semakin dekat nilainya ke 0, korelasinya semakin lemah.
Kita akan melihat untuk binary_features terlebih dulu.


- Di binary_features, fitur three_g tidak memiliki gambar atau gambarnya putih bersih, karena nilai hanya 1 saja atau kebanyakan hp pada dataset sudah masuk kategori three_g semua, jadi kita akan menghapus fitur ini, fitur four_g dan dual_sim juga karena memiliki korelasi paling kecil yaitu 0.
Selanjutnya kita akan lihat non_binary_features.


- Di non_binary_features, fitur ram merupakan fitur dengan tingkat korelasi tertinggi yaitu: 0.92. Sedang n_core dan talk_time memiliki korelasi paling kecil yaitu 0, maka kita akan menghapus 2 fitur ini.
Kita cek lagi data kita dan hasilnya adalah:

Dengan ini total kolom yang kita miliki ada 16, menyusut 5 dari total di awal kita memiliki 21 kolom.
-
Kita akan melihat perbandingan jumlah sampel dari variabel price_range
Kita akan melihatnya dalam bentuk tabel.

Dari hasil visualisasi diatas dapat kita simpulkan bahawa dataset kita memiliki jumlah sampel yang seimbang atau tidak berat sebelah.
Di proses ini kita akan melakukan 2 proses yaitu:
- Reduksi dimensi dengan Principal Component Analysis (PCA).
- Pembagian dataset dengan fungsi train_test_split dari library sklearn.
Baiklah mari kita lakukan hal diatas satu-persatu:
-
Reduksi dimensi dengan Principal Component Analysis (PCA). Teknik reduksi (pengurangan) dimensi adalah prosedur yang mengurangi jumlah fitur dengan tetap mempertahankan informasi pada data. Teknik pengurangan dimensi yang paling populer adalah Principal Component Analysis atau disingkat menjadi PCA. Teknik PCA digunakan untuk mereduksi variabel asli menjadi sejumlah kecil variabel baru yang tidak berkorelasi linier, disebut komponen utama (PC). Komponen utama ini dapat menangkap sebagian besar varians dalam variabel asli. Sehingga, saat teknik PCA diterapkan pada data, ia hanya akan menggunakan komponen utama dan mengabaikan sisanya.
Berikut penjelasan untuk masing-masing komponen utama (PC):
- PC pertama mewakili arah varians maksimum dalam data. Ia paling banyak menangkap informasi dari semua fitur dalam data.
- PC kedua menangkap sebagian besar informasi yang tersisa setelah PC pertama.
- PC ketiga menangkap sebagian besar informasi yang tersisa setelah PC pertama, PC kedua, dst.
Selanjutnya kita import dulu kelas PCA nya dengan kode
from sklearn.decomposition import PCA, setelah itu kita set variabel dari kelas PCA kita, untukn_components=2dann_components=3kita set = 2 dan 3 karena ada 5 fitur yang akan kita proses secara sendiri-sendiri, sedangrandom_state=123)kita set dengan = 123,random_stateini bebas kita isi dengan angka berapapun asal itu masih bilangan integer.Setelah itu kita print hasilnya yang
n_components=2dulu hasilnya adalaharray([0.75, 0.25])artinya 75% dari kedua fitur ada di PC pertama dan 25% di PC kedua, Sedang untukn_components=3hasilnya adalaharray([0.757, 0.241, 0.002])yang artinya 75% dari ke 3 fitur ada di PC pertama, 24% ada di PC kedua dan 0,002 atau sisanya ada di PC3.Selanjutnya Kita reduksi kelima fitur tersebut menjadi 2 yaitu resolution_px dan dimension_hp, resolution_px adalah dimensi pexel sedang dimension_hp adalah dimensi dari hp tersebut. Kita akan melakukan perubahan sebagai berikut
n_components=1karena hanya ada 1 komponen saja.- Fit model dengan data masukan.
- Tambahkan fitur baru ke dataset dengan nama 'resolution_px' dan dimension_hp, kemudian lakukan proses transformasi.
- Drop kolom 'px_height', 'px_width' untuk dimension_px, sedang 'sc_h','sc_w', 'm_dep' untuk dimension_hp.
Dan hasilnya seperti gambar di bawah:

Kita sudah memiliki 2 fitur baru yaitu 'resolution_px' dan 'dimension_hp'.
-
Pembagian dataset dengan fungsi train_test_split dari library sklearn. Membagi dataset menjadi data latih (train) dan data uji (test) merupakan hal yang harus kita lakukan sebelum membuat model. Kita perlu mempertahankan sebagian data yang ada untuk menguji seberapa baik klasifikasi model terhadap data baru. Tujuannya adalah agar kita tidak mengotori data uji dengan informasi yang kita dapat dari data latih. Proporsi pembagian bisanya 80:20 jika data kita hanya 1000-an.
Pertama kita import dulu kelas train_test_split dengan kode
from sklearn.model_selection import train_test_split, setelah itu kita hapus fitur price_range pada variabelXdengan kodeX = data_train.drop(["price_range"],axis =1)untuk variabelykita set isinya price_range dengan kodey = data_train["price_range"], setelah itu kita bagi dataset kita dengan proporsi data latih 80% dan data tes 20% dengan kodeX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 123).Hasil nya adalah:

Setelah itu kita print dan lihat total dari pembagiannya, dengan data latih berjumlah 1204 dan data tes berjumlah 302.
Di tahap ini kita akan menggunakan 3 jenis algoritma yaitu:
- K-Nearest Neighbor (KNN) dengan KNeighborsClassifier
- Random Forest dengan RandomForestClassifier
- Boosting Algorithm dengan GradientBoostingClassifier
Baiklah mari kita jabarkan ketiga poin diatas satu-persatu:
-
K-Nearest Neighbor (KNN) dengan KNeighborsClassifier [2]
Algoritma KNN menggunakan ‘kesamaan fitur’ untuk memprediksi nilai dari setiap data yang baru. Dengan kata lain, setiap data baru diberi nilai berdasarkan seberapa mirip titik tersebut dalam set pelatihan.
KNN bekerja dengan membandingkan jarak satu sampel ke sampel pelatihan lain dengan memilih sejumlah k tetangga terdekat (dengan k adalah sebuah angka positif). Nah, itulah mengapa algoritma ini dinamakan K-nearest neighbor (sejumlah k tetangga terdekat). KNN bisa digunakan untuk kasus klasifikasi dan regresi.
Kelebihan pada Algoritma KNN adalah:
- Algoritma K-NN kuat dalam mentraining data yang noisy.
- Algoritma K-NN sangat efektif jika datanya besar.
- Mudah diimplementasikan.
Kekurangan pada Algoritma KNN adalah:
- Algoritma K-NN perlu menentukan nilai parameter K.
- Sensitif pada data pencilan / titik data yang terpaut jauh dari titik data lainnya.
- Rentan pada variabel yang non-informatif.
-
Random Forest dengan RandomForestClassifier [3]
Algoritma random forest adalah salah satu algoritma supervised learning. Ia dapat digunakan untuk menyelesaikan masalah klasifikasi dan regresi. Random forest juga merupakan algoritma yang sering digunakan karena cukup sederhana tetapi memiliki stabilitas yang mumpuni.
Random forest merupakan salah satu model machine learning yang termasuk ke dalam kategori ensemble (group) learning. Apa itu model ensemble? Sederhananya, ia merupakan model prediksi yang terdiri dari beberapa model dan bekerja secara bersama-sama. Ide dibalik model ensemble adalah sekelompok model yang bekerja bersama menyelesaikan masalah. Sehingga, tingkat keberhasilan akan lebih tinggi dibanding model yang bekerja sendirian. Pada model ensemble, setiap model harus membuat prediksi secara independen. Kemudian, prediksi dari setiap model ensemble ini digabungkan untuk membuat prediksi akhir.
Kelebihan pada Algoritma Random Forest adalah:
- Dapat mengatasi noise dan missing value.
- Dapat mengatasi data dalam jumlah yang besar.
Kekurangan pada Algoritma Random Forest adalah:
- Interpretasi yang sulit.
- Membutuhkan tuning model yang tepat untuk data.
-
Boosting Algorithm dengan GradientBoostingClassifier [4]
Algoritma yang menggunakan teknik boosting bekerja dengan membangun model dari data latih. Kemudian ia membuat model kedua yang bertugas memperbaiki kesalahan dari model pertama. Model ditambahkan sampai data latih terprediksi dengan baik atau telah mencapai jumlah maksimum model untuk ditambahkan.
Seperti namanya, boosting, algoritma ini bertujuan untuk meningkatkan performa atau akurasi prediksi. Caranya adalah dengan menggabungkan beberapa model sederhana dan dianggap lemah (weak learners) sehingga membentuk suatu model yang kuat (strong ensemble learner). Algoritma boosting muncul dari gagasan mengenai apakah algoritma yang sederhana seperti linear regression dan decision tree dapat dimodifikasi untuk dapat meningkatkan performa.
Kelebihan pada Algoritma Boosting adalah:
- Hasil pemodelan yang lebih akurat.
- Model yang stabil dan lebih kuat (robust).
Kekurangan pada Algoritma Boosting adalah:
- Pengurangan kemampuan interpretasi model.
- Tingkat kesulitan yang tinggi.
Ditahap ini kita akan mengevaluasi setiap model dengan menggunakan metrik accuracy_score dan classification_report. Dan diakhir kita akan memilih model yang paling baik dari evaluasi menggunakan kedua mertik tersebut.
Baiklah tanpa berlama-lama lagi kita lihat cara cara kerja dari kedua metrik diatas:
-
Cara kerja metrik
accuracy_score[5]Metrik
accuracy_scorebekerja dengan rumus, Accuracy Score = (TP+TN)/ (TP+FN+TN+FP) [6], dimana:- TP = True Positive
- TN = True Negative
- FP = False Positive
- FN = False Negatif Dalam klasifikasi multilabel, fungsi mengembalikan akurasi subset. Jika seluruh rangkaian label yang diprediksi untuk sampel secara akurat cocok dengan rangkaian label yang sebenarnya. Maka akurasi subset adalah 1,0 jika tidak, akurasinya hampir 0,0.
Hasil keluaran dari metriknya adalah seperti berikut:

Mari kita viasualisasikan hasil diatas ke dalam tampilan yang lebih menarik:

Dari hasil diatas Model KNN bisa dibilang yang terbaik menurut metrik
accuracy_score. -
Cara kerja metrik
classification_report[7]Metrik
classification_reportbekerja dengan mengembalikan 4 nilai yaitu 'precision', 'recall', 'f1-score', 'support'. Dengan acuan seperti berikut:- Jika dataset memiliki jumlah data False Negatif dan False Positif yang seimbang (Symmetric), maka bisa gunakan Accuracy, tetapi jika tidak seimbang, maka sebaiknya menggunakan F1-Score.
- Dalam suatu problem, jika lebih memilih False Positif lebih baik terjadi daripada False Negatif, misalnya: Dalam kasus Fraud/Scam, kecenderungan model mendeteksi transaksi sebagai fraud walaupun kenyataannya bukan, dianggap lebih baik, daripada transaksi tersebut tidak terdeteksi sebagai fraud tetapi ternyata fraud. Untuk problem ini sebaiknya menggunakan Recall.
- Sebaliknya, jika lebih menginginkan terjadinya True Negatif dan sangat tidak menginginkan terjadinya False Positif, sebaiknya menggunakan Precision. [8]
Hasil printnya sebagai berikut:



Dengan hasil:
- KNN = 92%
- Random Forest = 78%
- Boosting = 90%
Bisa di simpulkan Model KNN masih memimpin soal hasil, kita melihatnya dari Test nya bukan Trainnya. Kita lihat nilai accuracy karena jumlah data kita yang seimbang.
- Setelah Kita melihat hasil visual dari metrik evaluasi bisa kita simpulkan bahwa Model KNN memang yang paling powerfull, kita melihat nya dari hasil pengujian menggunakankan data tes.
- Kita juga akhirnya tau bahawa fitur yang paling berpengaruh menentukan kelas harga dari suatu hp adalah ram.
- Kita juga berhasil membuat 3 model model machine learning yang dapat memprediksi kelas harga hp berdasar fitur-fitur yang ada, dan kita mendapatkan dari 3 model yang ada Model KNN-lah yang paling powerfull.
[1] HHM, "Mengenal Box-Plot (Box and Whisker Plots)", in Articles Binus University. Tersedia: tautan. Diakses pada: Juli 2022.
[2] Scikit-learn K-NN Algorithm Documentation. Tersedia: tautan. Diakses pada: Juli 2022.
[3] Scikit-learn Random Forest Algorithm Documentation. Tersedia: tautan. Diakses pada: Juli 2022.
[4] Scikit-learn Boosting Algorithm Documentation. Tersedia: tautan. Diakses pada: Juli 2022.
[5] Scikit-learn accuracy_score Metrics Documentation. Tersedia: tautan. Diakses pada: Juli 2022.
[6] Kumar, Bijay. "Scikit learn accuracy_score", in Python Guides. Tersedia: tautan. Diakses pada: Juli 2022.
[7] Scikit-learn classification_report Metrics Documentation. Tersedia: tautan. Diakses pada: Juli 2022.
[8] Hendra, "Terminologi Machine Learning", in Blog. Tersedia: tautan. Diakses pada: Juli 2022.
Nama:
Username dicoding:
| Deskripsi | |
|---|---|
| Dataset | nama dataset |
| Masalah | Deskripsi masalah yang di angkat |
| Solusi machine learning | Deskripsi solusi machine learning yang akan dibuat |
| Metode pengolahan | Deskripsi metode pengolahan data yang digunakan |
| Arsitektur model | Deskripsi arsitektur model yang diguanakan |
| Metrik evaluasi | Deksripsi metrik yang digunakan untuk mengevaluasi performa model |
| Performa model | Deksripsi performa model yang dibuat |
