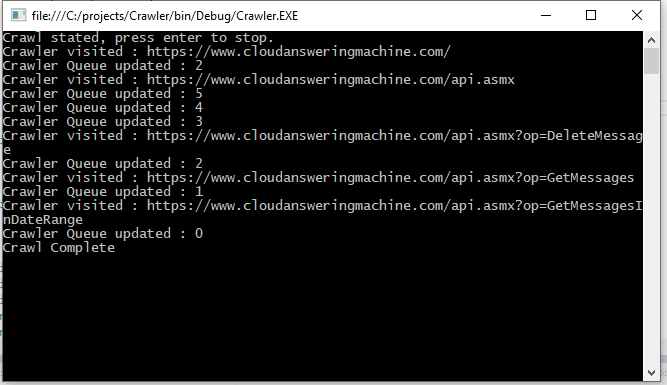
A Web Spider based using HTMLAgilityPack. This library will follow links within webpages in order to find more webpages, it works asynchronously, and will fire events every time a new page is encountered.
A few caveats, is that it's single-threaded, so, it's going to be rather slow. It holds it's queue in memory, so it's going to be a memory hog on really large websites. It also doesn't obey Robots.txt.
Please feel free to fork this library, and improve upon it!
Spider.OnQueueUpdate = q =>
{
Console.WriteLine("Crawler Queue updated : " + q);
if (q == 0)
{
// when this reaches 0, then the crawl is complete
Console.WriteLine("Crawl Complete");
}
};
Spider.OnVisitedPage = (webpage,content) =>
{
Console.WriteLine("Crawler visited : " + webpage);
};
Spider.OnCrawlError = (webpage, ex) =>
{
Console.WriteLine("Crawler hit error at : " + webpage);
};
Spider.StartPage = new Uri("https://www.cloudansweringmachine.com/");
Spider.Scope = "https://www.cloudansweringmachine.com/"; // Don't leave this domain.
Spider.Start();
Console.WriteLine("Crawl stated, press enter to stop.");
Console.ReadLine();