icoz69 / cec-cvpr2021 Goto Github PK
View Code? Open in Web Editor NEWPytorch code for CVPR2021 paper "Few-Shot Incremental Learning with Continually Evolved Classifiers"
License: MIT License
Pytorch code for CVPR2021 paper "Few-Shot Incremental Learning with Continually Evolved Classifiers"
License: MIT License










































































































Hi, Thank you for your wonderful work!
You describe in your article that the first stage of the method is to use the training data from session 0 to pre-train the backbone so that it has some feature extraction capability. However, in your code, the pre-trained model you provided on Google Drive is loaded directly by default. I tried to run the code without loading the pre-trained model and got poor results.
So, could you possibly share how you are doing in the first stage of pre-training?
Or, it would be great if you could add the code for the pre-training stage, thank you very much!
Thanks for your great work CEC.
I am trying to follow your paper but I found that I cannot find the original images of the mini_imagenet dataset downloaded from the google drive link in this repo.
Based on my understanding, the mini_imagenet dataset is originally created by Ravi et al. . For example, n0153282900000005.jpg,n01532829 means the no.5 image of the imagenet train split.
n01532829
|---n01532829_3.JPEG
|---n01532829_6.JPEG
| ---n01532829_26.JPEG
| ---n01532829_27.JPEG
| ---n01532829_28.JPEG (this one)
However, I cannot find the miniimagenet/images/n0153282900000005.jpg image (in the zipped file) from the original imagenet dataset (by file hash search).

May I ask how to create the mini imagenet dataset from scratch?
Thanks again
In incremential training session: where use graph to update fc? I find only use prototypical point as fc which doesn't accord with the framework picture.
hello, nice work. I have some questions about the code. why is session from 0 to 9 in pre-train stage? All we need is a pre-trained model which could classify 60 base classes. What's more, in the session_*.txt, should we write the label such as 60,61,62.etc rather than some big number?
Hello,
First of all, thank you for your great work!
During understanding the code and paper, I have a confusion about the point of freezing the backbone. If the workflow of the process is: a)pre-training stage, b)pseudo-incremental learning stage, and c)classifier learning and adaptation stage, which one is right? :
- After the pre-training stage, the backbone model is freezing
- After the pseudo-incremental learning stage, the backbone model is freezing
I am confused because it seems to be 1 according to Figure 2 in the paper.
learnable params in the pseudo-incremental learning stage don't have model R(backbone).
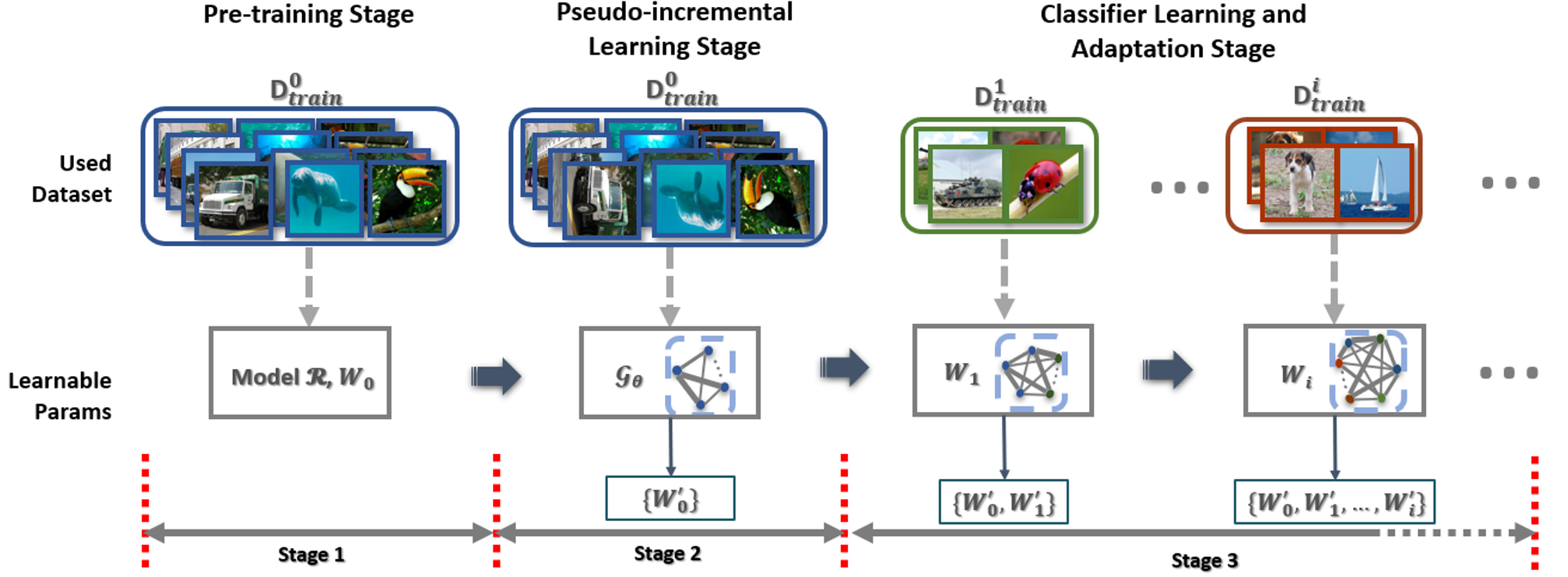
However, according to the code, in the pseudo-incremental learning stage, the encoder is one of the learnable params. The encoder parameters are included in the optimizer. So it seems to be 2.
CEC-CVPR2021/models/cec/fscil_trainer.py
Line 142 in 3a5d335
That is why I'm confused about where the backbone model is freezing. I would appreciate it if you could let me know which one is right, 1 or 2.
And if there's something I misunderstood, please let me know. Thank you.
您好,非常感谢你们的工作。
我在阅读代码的时候遇见了一个问题,我想知道在CEC的fscil_trainer.py的session0的训练中中为什么在validation阶段需要更新增量部分的fc权重,目的是为了选取更加适应后期增量学习的模型吗?
期望得到您的答复
请问代码完整吗?里面对linear,cosine,L2,DeepEMD分类器都有吗?微调以及icral和eeil方法的代码是不是没有涉及。
Hello, first of all thank you sharing great project.
During understanding the code, I got some questions about the details.
First is about the difference between episode_way<>low_way and episode_shot<>query_shot
I thought it is way, shot used for PIL algorithm on the session 0 training in cec/fscil_trainer.
Is it correct that episode_way/shot is for extracting (Sb,Qb) and low_way/shot is for (Si,Qi) on algorithm 1?
If it is right, is there any meaning for making difference on them? On the example training arguments that is written on Readme, all episode_way=low_way and episode_shot=low_shot.
Thank you for reading
Hi, I would like to ask if I can run my own dataset with this model?
Could you tell me how to visualize the decision boundary and data as Figure4 shows using t-sne? Looking forward to your reply.
Hi, thanks for your transparent and impressive work!
I find that the test data split seems missing in data/index_list compared to the original implementation. In addition, it seems that the model evaluation code is not provided.
Hello, I got some short questions.
In models/cec/fscil_trainer.py,
At 175 line is model.eval()
I wonder why model.eval() is used instead of train().
Was there any reason not to use batchnorm & Dropout at cec trainer, updating encoder & attn?
Hi, Thanks for your great work!
I have a question about the GAT module. I notice that, in your implementation, the attention module only participates the pseudo-incremental learning stage (session == 0). But in the paper, it seems that GAT is used in adaptation stage (session > 0) to generate the weights of classifier.
I really appreciate any help you can provide. Thanks!
also, What's the difference between the scripts in models/base and models/cec?
Hello, I would like to ask you for advice on the following questions.
Hello, the author, can you provide some visual code in the paper? Thank you very much if you can
Hi, Thank you for making your code public!
I have a question about the pre-trained model specifically one with CUB200 dataset. Whether the model you are sharing 'session0_max_acc7552_cos.pth' is the model after all the sessions have passed or just after the base session. As I was looking at the architecture and the fc layer has 200 nodes (module.fc.weight: torch.Size([200, 512])), whereas after session 0 there should only be 100 nodes. On the other hand, the name of the model suggest session0.
Please advise.
Thanks,
Touqeer
First of all thank you for your contribution.
It is mentioned in the paper that in each incoming session, we use the adaptation module to update the classifiers learned in the current session and previous sessions, and then concatenate the updated classifiers to make predictions over all classes. How to predict the categories that have not appeared in the base data and the previous and current session? Why the test accuracy gradually decrease with the increase of the session?
Hello,
When I tried to run train.py script,
modification of PROJECT='cec' & dataset default as 'miniimagenet' occurs such error.
It occurs on miniimagenet.py line 80, proceeding data2label[img_path]
in miniimagenet.py, @ class MiniImageNet
self.data2label is created (44line) according to csv files (27, 36~44 lines)
It seems the error occured due to mismatch between contents of session files and csv files
Have you proceed any modifications on it?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.