huruji / blog Goto Github PK
View Code? Open in Web Editor NEW红日初升,其道大光:sun_with_face::house_with_garden:请star或watch,不要fork
Home Page: https://juejin.im/user/5894886f2f301e00693a3e49/posts
红日初升,其道大光:sun_with_face::house_with_garden:请star或watch,不要fork
Home Page: https://juejin.im/user/5894886f2f301e00693a3e49/posts














































































































P.S.最近在看dayjs的源码,源码上用到了 valueOf 方法,虽然知道这个方法,但是很少接触,就试着找来了ECMAscript标准文档来看看标准的定义。
首先看下标准对于 Object.prototype.valueOf 的定义:

关于 ToObject,标准如下定义:


翻译过来就是:
| 参数类型 | 返回结果 |
|---|---|
| Undefined | 抛出 TypeError 异常 |
| Null | 抛出 TypeError 异常 |
| Boolean | 创建一个Boolean对象,初始值为参数值 |
| Number | 创建一个Number对象,初始值为参数值 |
| String | 创建一个String对象,初始值为参数值 |
| Symbol | 创建一个Symbol对象,初始值为参数值 |
| Object | 返回参数值 |
到了这里,貌似可以停止查阅文档了,但是我们不要忘了一个事情那就是原型链,这只是定义在Object对象原型链上的。我们还需要看看各种类型自身的原型上是否定义了 valueOf 方法:

果不其然,Boolean、Number、String、Symbol的原型上都有自己的 valueOf 方法,分别查阅规范:
Boolean


Number

String

Symbol

根据上面的规范,制成表格为:
在这里我们假设调用的都是该定义的方法的类型,如调用Boolean.prototype.valueOf() 方法的一个布尔类型的值。
| 方法 | 返回结果 |
|---|---|
| Boolean.prototype.valueOf() | 返回布尔值本身 |
| Number.prototype.valueOf() | 返回数字本身 |
| String.prototype.valueOf() | 返回字符串本身 |
| Symbol.prototype.valueOf() | 返回Symbole本身 |
那么,或许有人问了那这几个重新定义的 valueOf 方法和定义在Object原型上的 valueOf 返回值有啥不同吗?当然不同呀,定义在Object对象上返回的是一个对象,而重新定义的方法返回的是一个值,如下

这就跟你用使用字面量定义数字和使用构造函数定义使用数字的区别一样!!!

既然我们都知道js完全可以通过使用 call 和 apply 来改变this指向,那么也就是说完全这些方法可以被任意类型的值使用,那么此时的返回值又是什么呢?
我们还是来看文档:
首先看 String.prototype.valueOf() 方法,规范中指出返回的值是抽象操作符 thisStringValue(value) 的返回值,而 thisStringValue(value) 的处理过程是这样子的:
其他几个的规范也类似:
所以归根到底这里需要解决的是这个形如 [[SymbolData]] internal slot 是啥子东东的问题(姑且全翻译为类型内部插槽吧)。
查询文档,可以看到规范对于 Internal slots 的说明:
大致意思是说 internal slots 不是对象的属性,不会被继承,初始值都是未定义的。那就可以初步认为 internal slots 是一个类似于属性但是不能被直接获取的值,同时StackOverflow上也有人出来解释这个问题 What is an “internal slot” of an object in JavaScript?
。大致我们可以认为这是一个内部值。同时在文档中可以查阅到诸如 Set the value of O’s [[NumberData]] internal slot to n 之类的话语,
因此,大致可以认为拥有 [[NumberData]] internal slot 的为数字类型,拥有 [[StringData]] internal slot 为字符串类型。
按照这个思路,String.prototype.valueOf() 、Number.prototype.valueOf() 这些方法是不能被其他数据类型调用的,调用则会抛出 TypeError 异常。
测试:
完全符合!
接下来需要考虑的就是Date、Math、functioin等对象的原型是否定义了 valueOf 方法,通过搜索查阅手册可以发现在这些对象中只有Date对象重写了 valueOf 方法
继续查阅可以知道这个 time value 就是时间戳,从 getTime() 方法的描述也可以证实:
所以 Date对象的 valueOf 方法直接返回时间戳。
因此根据上述的查阅取证,总结一下 valueOf:
定义在 Object 的原型上的 valueOf 方法内部调用了内部的方法 ToObject(),而 ToObject() 方法除了 Undefined 和 null 之外都会返回一个对象。而 Boolean 、Number、String、Symbol、Date对象的原型则重写了 valueOf 方法,且传入不是该类型的参数参数时会报错,列表为:
Object.prototype.valueOf
| 参数类型 | 返回结果 |
|---|---|
| Undefined | 抛出 TypeError 异常 |
| Null | 抛出 TypeError 异常 |
| Boolean | 创建一个Boolean对象,初始值为参数值 |
| Number | 创建一个Number对象,初始值为参数值 |
| String | 创建一个String对象,初始值为参数值 |
| Symbol | 创建一个Symbol对象,初始值为参数值 |
| Object | 返回参数值 |
Boolean.prototype.valueOf
| 参数类型 | 返回结果 |
|---|---|
| Boolean | 返回值 |
| 其他 | 抛出 TypeError 异常 |
String.prototype.valueOf
| 参数类型 | 返回结果 |
|---|---|
| String | 返回值 |
| 其他 | 抛出 TypeError 异常 |
Number.prototype.valueOf
| 参数类型 | 返回结果 |
|---|---|
| Number | 返回值 |
| 其他 | 抛出 TypeError 异常 |
Symbol.prototype.valueOf
| 参数类型 | 返回结果 |
|---|---|
| Symbol | 返回值 |
| 其他 | 抛出 TypeError 异常 |
Date.prototype.valueOf
| 参数类型 | 返回结果 |
|---|---|
| Date | 返回时间戳 |
| 其他 | 抛出 TypeError 异常 |
参考:
nodercms是一个使用express+mongoose编写的cms。整个项目目录结构是一个典型的Express应用的项目结构,项目的后端代码量为7000行左右。
项目对于新手值得学习的地方主要在于
1、将routes和controllers的关系通过一个json对象指定有效的将routes和controllers分离开了
2、使用log4js保存整个项目的日志,并且将日志分为access、database、errors、system四类,并且按照日期保存为单独文件
3、将对mongodb的model的操作划分为单独的services,不至于controllers过于臃肿,同时能够有效解耦
同时项目也是mongoose操作、Express项目、log4js、cms等的使用和开发的范本,非常适合node.js新手阅读。
渣渣一枚,目前只能想到这些了,以后想到再补。
在webpack中使用Babel通过使用babel-loader即可,babel中的配置可以通过options选项进行配置。
安装:
npm i babel-loader -Dconst config = {
// ......
module: {
rules: [{
test: /\.js$/,
use:{
loader: 'babel-loader',
options: {
presets: ['env']
}
}
}]
}
};
module.exports = config;webpack.config.js
const config = {
// ......
module: {
rules: [{
test: /\.js$/,
use:[
'babel-loader'
]
}]
}
};
module.exports = config;.babelrc
{
"presets": [
"es2015"
]
}使用ESLint使用eslint-loader即可,类似于babel-loader的使用
安装:
npm i eslint-loader -Dconst config = {
// ......
module: {
rules: [{
test: /\.js$/,
use:[
'eslint-loader',
'babel-loader'
]
}]
}
};
module.exports = config;在Webpack中对Sass进行编译需要使用sass-loader,而sass-loader依赖于node-sass和webpack,因此需要安装
npm i node-sass sass-loader webpack -D由于sass没有提供重写url的功能,因此所有的链接资源都是相对于输出文件(output)来说的,因此在实际开发中通常会加入resolve-url-loader来实现资源url的正常使用
npm i resolve-url-loader -D和style-loader、css-loader一起使用,这样就可以正常使用编译sass了
const config = {
// ......
module: {
rules: [{
test: /\.scss$/,
use: [
'style-loader',
'css-loader',
'resolve-url-loader',
'sass-loader?sourceMap'
]
}]
}
};
module.exports = config;类似于Sass的使用,Less的编译只需要安装less-loader即可
npm i less-loader -Dconst config = {
// ......
module: {
rules: [{
test: /\.scss$/,
use: [
'style-loader',
'css-loader',
'less-loader'
]
}]
}
};
module.exports = config;创建ndarray对象:
import numpy as np
np.array([1,2,3,4])
np.array([[1,2,3,4],[5,6,7,8]])转换为list
np.array([1,2,3,4]).tolist()获取ndarray对象的基本信息:维数(ndim)、行列信息(shape)、数据存储类型(dtype)
arr = np.array([[1,2,3,4],[5,6,7,8]])
print(arr.ndim)
print(arr.shape)
print(arr.dtype)设置数据存储类型
np.array([1,2,3,4], dtype=np.int32)
np.arrat([1.2,1.3,1.4], dtype=np.float64)创建特殊ndarray对象:全0(zeros)、全1(ones)、随机值(empty),参数是形状
np.zeros(8)
np.ones((2,3))
np.empty((3,4))指定范围创建ndarray对象(arange)
arr1 = np.arange(1,8,2)
# [1 3 5 7]创建网格数据(linspace)
np.linspace(0, 80, 5)
# [0 20 40 60 80]修改形状(reshape)
np.arange(0,12).reshape((3,4))
# [[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]]展平,转化为一维数组(flatten)
a = np.arange(12).shape(3,4)
a.flatten()矩阵转置(transpose)
a = np.arange(12).reshape(3,4)
a.transpose()
# 等同于
a.T数学运算(+ - * / )、点乘(矩阵乘法)、三角函数
a = np.arange(12).reshape(3,4)
b = np.arange(12).reshape(4,3)
a + 1
a + b
a - 1
a - b
a * 2
a * b
a / 2
a / b
# 平方
arr ** 2
# 点乘
np.dot(a, b)
a.dot(b)
np.sin(a)深浅复制,赋值操作为浅复制,使用clone方法深复制:
a = np.arange(12)
b = a
c = a.clone()
在上一篇文章中,我们的AMD模块加载器基本已经能够使用了,但是还不够,因为我们没有允许匿名模块,以及没有依赖等情况。实际上在amd的规范中规定的就是define函数的前两个参数是可选的,当没有id(模块名)的时候也就意味着不会有模块依赖于这个模块。很显然,我们的define函数的每个参数的类型是不同的,因此我们需要一些函数来做类型判断,如下:
function isFun(f) {
return Object.prototype.toString.call(f).toLowerCase().indexOf('function') > -1;
}
function isArr(arr) {
return Array.isArray(arr);
}
function isStr(str) {
return typeof str === 'string';
}将这些类型判断函数运用在define函数,判断这个模块是否有依赖,是否为匿名模块,这是一个比较简单的工作,修改define函数如下:
function define(name, deps, callback) {
if(!isStr(name)) {
callback = deps;
deps = name;
name = null;
}
if(!isArr(deps)) {
callback = deps;
deps = [];
}
if(moduleMap[name]) {
name=moduleMap[name]
}
name = replaceName(name);
deps = deps.map(function(ele, i) {
return replaceName(ele);
});
modMap[name] = modMap[name] || {};
modMap[name].deps = deps;
modMap[name].status = 'loaded';
modMap[name].callback = callback;
modMap[name].oncomplete = modMap[name].oncomplete || [];
}进行一次测试,不过在测试之前,我们需要知道的是,我们将匿名模块的name修改为了null,而后面有一个replaceName方法是做name替换的,这里没有判断name是否为null的情况,因此需要在开头做一次判断,增加如下代码:
function replaceName(name) {
if(name===null) {
return name;
}
// ......
}测试代码如下:
loadjs.config({
baseUrl:'./static',
paths: {
app: './app'
}
});
loadjs.define('cc',['a'], function(a) {
console.log(1);
console.log(a.add(1,2));
});
loadjs.define('ab', function() {
console.log('ab');
});
loadjs.define(function() {
console.log('unknow');
});
loadjs.use(['ab','cc'],function() {
console.log('main');
});测试结果如下:

说明正确。此时我们的一个简单的amd模块加载器就这样写完了,删除console增加注释就可以比较好的使用了,最后整理一下代码如下:
(function(root){
var modMap = {};
var moduleMap = {};
var cfg = {
baseUrl: location.href.replace(/(\/)[^\/]+$/g, function(s, s1){
return s1
}),
path: {
}
};
// 完整网址
var fullPathRegExp = /^[(https?\:\/\/) | (file\:\/\/\/)]/;
// 局对路径
var absoPathRegExp = /^\//;
// 以./开头的相对路径
var relaPathRegExp = /^\.\//;
// 以../开头的的相对路径
var relaPathBackRegExp = /^\.\.\//;
function isFun(f) {
return Object.prototype.toString.call(f).toLowerCase().indexOf('function') > -1;
}
function isArr(arr) {
return Array.isArray(arr);
}
function isStr(str) {
return typeof str === 'string';
}
function merge(obj1, obj2) {
if(obj1 && obj2) {
for(var key in obj2) {
obj1[key] = obj2[key]
}
}
}
function outputPath(baseUrl, path) {
if (relaPathRegExp.test(path)) {
if(/\.\.\//g.test(path)) {
var pathArr = baseUrl.split('/');
var backPath = path.match(/\.\.\//g);
var joinPath = path.replace(/[(^\./)|(\.\.\/)]+/g, '');
var num = pathArr.length - backPath.length;
return pathArr.splice(0, num).join('/').replace(/\/$/g, '') + '/' +joinPath;
} else {
return baseUrl.replace(/\/$/g, '') + '/' + path.replace(/[(^\./)]+/g, '');
}
} else if (fullPathRegExp.test(path)) {
return path;
} else if (absoPathRegExp.test(path)) {
return baseUrl.replace(/\/$/g, '') + path;
} else {
return baseUrl.replace(/\/$/g, '') + '/' + path;
}
}
function replaceName(name) {
if(name===null) {
return name;
}
if(fullPathRegExp.test(name) || absoPathRegExp.test(name) || relaPathRegExp.test(name) || relaPathBackRegExp.test(name)) {
return outputPath(cfg.baseUrl, name);
} else {
var prefix = name.split('/')[0] || name;
if(cfg.paths[prefix]) {
if(name.split('/').length === 0) {
return cfg.paths[prefix];
} else {;
var endPath = name.split('/').slice(1).join('/');
return outputPath(cfg.paths[prefix], endPath);
}
} else {
return outputPath(cfg.baseUrl, name);
}
}
}
function fixUrl(name) {
return name.split('/')[name.split('/').length-1]
}
function config(obj) {
if(obj){
if(obj.baseUrl) {
obj.baseUrl = outputPath(cfg.baseUrl, obj.baseUrl);
}
if(obj.paths) {
var base = obj.baseUrl || cfg.baseUrl;
for(var key in obj.paths) {
obj.paths[key] = outputPath(base, obj.paths[key]);
}
}
merge(cfg, obj);
}
}
function use(deps, callback) {
if(deps.length === 0) {
callback();
}
var depsLength = deps.length;
var params = [];
for(var i = 0; i < deps.length; i++) {
moduleMap[fixUrl(deps[i])] = deps[i];
deps[i] = replaceName(deps[i]);
(function(j){
loadMod(deps[j], function(param) {
depsLength--;
params[j] = param;
if(depsLength === 0) {
callback.apply(null, params);
}
})
})(i)
}
}
function loadMod(name, callback) {
/*模块还未定义*/
if(!modMap[name]) {
modMap[name] = {
status: 'loading',
oncomplete: []
};
loadscript(name, function() {
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
});
} else if(modMap[name].status === 'loading') {
// 模块正在加载
modMap[name].oncomplete.push(callback);
} else if (!modMap[name].exports){
//模块还未执行完
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
}else {
callback(modMap[name].exports);
}
}
function execMod(name, callback, params) {
var exp = modMap[name].callback.apply(null, params);
modMap[name].exports = exp;
callback(exp);
execComplete(name);
}
function execComplete(name) {
for(var i = 0; i < modMap[name].oncomplete.length; i++) {
modMap[name].oncomplete[i](modMap[name].exports);
}
}
function loadscript(name, callback) {
var doc = document;
var node = doc.createElement('script');
node.charset = 'utf-8';
node.src = name + '.js';
/*为每个模块添加一个随机id*/
node.id = 'loadjs-js-' + (Math.random() * 100).toFixed(3);
doc.body.appendChild(node);
node.onload = function() {
callback();
}
}
function define(name, deps, callback) {
/*匿名模块*/
if(!isStr(name)) {
callback = deps;
deps = name;
name = null;
}
/*没有依赖*/
if(!isArr(deps)) {
callback = deps;
deps = [];
}
if(moduleMap[name]) {
name=moduleMap[name]
}
name = replaceName(name);
/*对每个依赖名进行路径替换*/
deps = deps.map(function(ele, i) {
return replaceName(ele);
});
modMap[name] = modMap[name] || {};
modMap[name].deps = deps;
modMap[name].status = 'loaded';
modMap[name].callback = callback;
modMap[name].oncomplete = modMap[name].oncomplete || [];
}
var loadjs = {
define: define,
use: use,
config: config
};
root.define = define;
root.loadjs = loadjs;
root.modMap = modMap;
})(window);resource-router-middleware是一个提供restful API的Express中间件,由preact作者developit开发。
一个简单使用案例就是:
const resource = require('resource-router-middleware');
let users = [];
const huruji = {
id:12,
name: 'huruji',
age: 12,
sex: 'man'
};
const grey = {
id: 13,
name: 'grey',
age: 12,
sex: 'man'
};
users = [huruji, grey];
module.exports = resource({
mergeParams: true,
id: 'user',
load: function(res,id, callback) {
callback(null, huruji);
},
list: function(req, res) {
res.json(users);
},
create: function(req, res) {
var user = req.body;
users.push(user);
res.json(user);
},
read: function(req, res) {
res.json(req.user);
},
update: function(req, res) {
var id = req.params[this.id];
for(var i = users.length;i--;) {
if(users[i].id === id){
users[i] = req.body;
users[i].id = id;
return res.status(204).send('Accepted');
}
}
res.status(404).send('Not found');
},
delete: function(req, res) {
var id = req.params[this.id];
for(var i =users.length;i--;) {
if(users[i].id===id) {
users.splice(i,1);
return res.status(200);
}
}
res.status(404).send('Not found');
}
});const express = require('express');
const app = express();
const bodyParser = require('body-parser');
const userResource = require('./user');
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: false }));
app.use('/user',userResource);
app.listen(5000, function(err) {
if(err) {
return console.log(err);
}
console.log('server is listening port 5000')
});可以学习的点主要是:
1、Express.Router可以提供一个对象参数
{
mergeParams: 是否保留父级路由的req.params,且父子的req.params冲突时,优先使用子级的
caseSensitive:路由的路径是否大小写敏感,默认为false
strict:是否启用严格模式,即/foo与/foo/区别对待
}
2、router.param的使用
3、取反运算,这个使用真的是相当巧妙
4、restful API的设计
var Router = require('express').Router;
var keyed = ['get', 'read', 'put', 'update', 'patch', 'modify', 'del', 'delete'],
map = { index:'get', list:'get', read:'get', create:'post', update:'put', modify:'patch' };
module.exports = function ResourceRouter(route) {
route.mergeParams = route.mergeParams ? true : false;
// Express.Router可以提供一个对象参数
/**
* @param {
* mergeParams: 是否保留父级路由的req.params,且父子的req.params冲突时,优先使用子级的
* caseSensitive:路由的路径是否大小写敏感,默认为false
* strict:是否启用严格模式,即/foo与/foo/区别对待
* }
*/
var router = Router({mergeParams: route.mergeParams}),
key, fn, url;
// 如果有中间件则装载中间价
if (route.middleware) router.use(route.middleware);
// router.param方法的回调函数的参数分别是req,res,next,params的值,params的key
// 使用这个我们可以为路由的params找到数据之后直接定义在req对象中,供后续处理
if (route.load) {
router.param(route.id, function(req, res, next, id) {
route.load(req, id, function(err, data) {
if (err) return res.status(404).send(err);
req[route.id] = data;
next();
});
});
}
for (key in route) {
// fn为对应的http method
fn = map[key] || key;
if (typeof router[fn]==='function') {
// ~取反位运算,这个很有意思,三目运算符只有在~keyed.indexOf(key)为0时运算'/',取反值与原值相加为-1的原则知原值keyed.indexOf(key)为-1,也就是说
// url = ~keyed.indexOf(key) ? ('/:'+route.id) : '/'与url = (keyed.indexOf(key) > -1) ? ('/:'+route.id) : '/';效果相同
// 意义在于如果用户是使用keyed数组里的元素来定义键的,则使用('/:'+route.id)路由路径,否则使用'/'路由路径
url = ~keyed.indexOf(key) ? ('/:'+route.id) : '/';
console.log(key);
console.log('url:' + url)
router[fn](url, route[key]);
}
}
return router;
};
module.exports.keyed = keyed;小菜鸟布局第一次布局,orz
<RelativeLayout android:layout_width="match_parent"
android:layout_height="match_parent">
<TableLayout
android:layout_height="wrap_content"
android:layout_width="match_parent"
android:layout_alignParentBottom="true"
android:stretchColumns="*">
<TextView android:id="@+id/textView1"
android:layout_width="wrap_content"
android:layout_height="50dp"
android:text="0"
android:gravity="right|center_vertical"/>
<TableRow android:id="@+id/tableRow1"
android:layout_width="wrap_content"
android:layout_height="80dp">
<Button android:id="@+id/button1"
android:layout_height="80dp"
android:layout_width="wrap_content"
android:text="7"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button2"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="8"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button3"
android:layout_width="wrap_content"
android:layout_height="match_parent"
android:text="9"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button4"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="/"
android:background="#db8122"
/>
</TableRow>
<TableRow android:id="@+id/tableRow2"
android:layout_height="80dp"
android:layout_width="wrap_content"
android:layout_marginTop="1dp">
<Button android:id="@+id/button5"
android:layout_height="80dp"
android:layout_width="wrap_content"
android:text="4"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button6"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="5"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button7"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="6"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button8"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="*"
android:background="#db8122" />
</TableRow>
<TableRow android:id="@+id/tableRow3"
android:layout_height="80dp"
android:layout_width="wrap_content"
android:layout_marginTop="1dp">
<Button android:id="@+id/button9"
android:layout_height="80dp"
android:layout_width="wrap_content"
android:text="1"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button10"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="2"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button11"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="3"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button12"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="-"
android:background="#db8122"/>
</TableRow>
<TableRow android:id="@+id/tableRow4"
android:layout_height="80dp"
android:layout_width="wrap_content"
android:layout_marginTop="1dp">
<Button android:id="@+id/button13"
android:layout_height="80dp"
android:layout_width="wrap_content"
android:text="0"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button14"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="."
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button15"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="+"
android:background="#0a89b6"
android:layout_marginRight="1dp"/>
<Button android:id="@+id/button16"
android:layout_height="match_parent"
android:layout_width="wrap_content"
android:text="="
android:background="#db8122"
android:/>
</TableRow>
</TableLayout>
</RelativeLayout>
截图:

嘿嘿 感觉您很厉害能否加个好友!
node-mkdirp是一个linux命令 mkdir -p的node版本,也就是创建多级目录。node-mkdirp值得新手学习的地方在于学习对于错误码的利用和基本的API使用。我曾经也写过一个创建多级目录的方法,不过自己都只是通过split方法对目录分隔开后逐层判断是否存在,再创建。node-mkdirp的方式则是通过fs.mkdir的错误码来判断,挺巧妙的。
var path = require('path');
var fs = require('fs');
var _0777 = parseInt('0777', 8);
module.exports = mkdirP.mkdirp = mkdirP.mkdirP = mkdirP;
function mkdirP (p, opts, f, made) {
// 如果opts是函数,则说明这是指定的回调,非函数且非对象则opt是指定的mode
if (typeof opts === 'function') {
f = opts;
opts = {};
}
else if (!opts || typeof opts !== 'object') {
opts = { mode: opts };
}
var mode = opts.mode;
var xfs = opts.fs || fs;
if (mode === undefined) {
mode = _0777 & (~process.umask());
}
if (!made) made = null;
var cb = f || function () {};
p = path.resolve(p);
// 尝试创建目录,mkdir创建一个不存在的目录时候会返回的错误码是ENOENT
xfs.mkdir(p, mode, function (er) {
// 无错误则表明创建的就是最后一级目录了
if (!er) {
made = made || p;
return cb(null, made);
}
switch (er.code) {
// 错误码是ENOENT表明无此文件或目录,则不断尝试创建父级目录
case 'ENOENT':
mkdirP(path.dirname(p), opts, function (er, made) {
// 无错误则继续尝试创建传入的目录,有错误则说明是已经存在,则直接执行回调
if (er) cb(er, made);
else mkdirP(p, opts, cb, made);
});
break;
// In the case of any other error, just see if there's a dir
// there already. If so, then hooray! If not, then something
// is borked.
// 出现其他错误主要是目录存在,则获取stat
default:
xfs.stat(p, function (er2, stat) {
// if the stat fails, then that's super weird.
// let the original error be the failure reason.
if (er2 || !stat.isDirectory()) cb(er, made)
else cb(null, made);
});
break;
}
});
}
mkdirP.sync = function sync (p, opts, made) {
if (!opts || typeof opts !== 'object') {
opts = { mode: opts };
}
var mode = opts.mode;
var xfs = opts.fs || fs;
if (mode === undefined) {
mode = _0777 & (~process.umask());
}
if (!made) made = null;
p = path.resolve(p);
// 同步版本类似于异步版本的处理,不过需要使用try...catch...来捕捉错误
try {
xfs.mkdirSync(p, mode);
made = made || p;
}
catch (err0) {
switch (err0.code) {
case 'ENOENT' :
made = sync(path.dirname(p), opts, made);
sync(p, opts, made);
break;
// In the case of any other error, just see if there's a dir
// there already. If so, then hooray! If not, then something
// is borked.
default:
var stat;
try {
stat = xfs.statSync(p);
}
catch (err1) {
throw err0;
}
if (!stat.isDirectory()) throw err0;
break;
}
}
return made;
};
纯函数:相同输入永远相同输出且无任何可观察的副作用。如slice和splice,可以把slice看作是纯函数,而splice不是,因为splice修改原数组,违背了了相同输入不同输出的原则。
纯函数借鉴于数学中函数的概念,即一对一,而不是一对多(即相同输入永远相同输出)
纯函数的输出结果不应该依赖外部的环境,如:
// 不纯
const minimum = 21;
const checkAge = function(age){
return age >= minimum
}
// 纯的
const checkAge = function(age) {
const minimum = 21;
return age >= minimum;
}很明显,对于不纯的函数的实现, minimum 变量在外部环境中,而这个变量随时都可能被更改。
在JavaScript中,我们可以使用 Object.freeze 方法将一个变量变为不可变对象,这样状态不会变化,也就保持了其 纯粹性。
const immutableState = Object.freeze({
minimum: 21
});
immutableState.minimumu;
// 21
immutableState.minimumu = 32;
// 严格模式下将会报错
immutableState.minimumu;
// 21副作用是在计算结果的过程中,系统状态的一种改变,或者与外部世界进行的可观察的交互。
包括不限于:
只要是 跟外部环境发生的交互 都是副作用,面对副作用,不是要完全禁止,而是应该让这些副作用变得 可控。
纯函数的好处
对输入进行缓存(得益于一对一原则)
const squareNumber = memoize(function(x){
return x * x;
})
squareNumber(4);
// 16 首次计算
squareNumber(4);
// 16 从缓存中直接读取结果一个简单的记忆函数实现:
const memoize = function(f) {
const cache = {};
return function(){
const arg_str = JSON.stringify(arguments);
cache[arg_str] = cache[arg_str] || f.apply(f, arguments);
return cache[arg_str];
}
}可移植性可以意味着把函数序列化(serializing)并通过 socket 发送。也可以意味着代码能够在 web workers 中运行。总之,可移植性是一个非常强大的特性
只需要简单的输入,然后对输出断言即可。
相同输入永远相同输出。
引用透明性 :如果一段代码的 执行结果 可以 替换 成这段 代码,并且不改变整个程序的行为,那么这段代码是引用透明的。
纯函数允许我们并行执行任意的纯函数,因为不需要访问共享的内存,也就不会进入竞争态。对于JavaScript来说服务端的Nodejs环境与 web worker 的浏览器都可以实现。
概念:把接受多个参数的函数转化为接受一个单一参数的(最初函数的第一个参数)的函数,并且返回接受余下参数并且返回结果的新函数的技术。
const add = function(x) {
return function(y) {
return x + y;
}
}
const addTen = add(10);
addTen(2);
// 12很明显,上文柯里化的秘密在于闭包。
使用 lodash curry 方法的例子:
const curry = require("lodash").curry;
const match = curry(function(what, str){
return str.match(what);
});
const replace = curry(function(what, replacement, str){
return str.replace(what, replacement);
})使用:
match(/\s+/g, "hello world");
// [" "]
match(/\s+/g)("hello world");
// [" "]
const hasSpaces = match(/\s+/g);
hasSpaces("hello world");
// [" "]可想而知,这种看似“预加载”的能力,在大型项目中使用可以大大简化代码。
柯里化非常符合纯函数的定义,一个输入准确对应于一个输出,当然为了减少()的调用,curry函数同样可以一次传递多个参数。
一个简单的例子:
const compose = function(f, g) {
return function(x){
return f(g(x));
}
}使用 compose 将字母转大写与末尾添加 ! 的两个函数组合,如此一来两个函数产生的奇妙的变化,两个函数的 魔法 的作用将组成起一个崭新的函数。
const toUpperCase = function(x) {
return x.toUpperCase();
};
const exclaim = function(x) {
return x + '!';
};
cosnt shout = compose(exclaim, toUpperCase);
shout("good student");
// "GOOD STUDENT!"代码对于 compose 函数来说是 右参数 先与 左参数 执行,这样就是一个 从右到左 的数据流。
一个顺序很重要的例子:
const head = function(x){
return x[0];
}
const reverse = reduce(function(acc, x) {
return [x].concat(acc);
}, []);
const last = compose(head, reverse);从右向左执行更加反映数学上的含义。而且实际上,所有的组合都有一个 共性 就是 符合结合律。
const associative = compose(f, compose(g, h)) == compose(compose(f,g), h);既然符合结合律,也就意味着调用分组并不重要,也就是说可以无关参数顺序了。

#!/bin/bash
echo "hello, world"
运行程序可以作为解释器参数或者作为可执行程序
bash test.sh
chmod +x test.sh
test.sh
命名
name="huruji"
需要注意的是变量名与等号之间不能有空格。
echo $name
echo ${name}
使用在变量名前添加$即可,{}表示这个变量名的边界。
只读变量
name="huruji"
readonly name
使用readonly可以将变量定义为只读变量,只读变量不能再次赋值
删除变量
name="huruji"
unset name
使用unset删除变量,之后不能再使用。
name="huruji"
echo "my name is $name"
字符串可以使用单引号和双引号,单引号中不能包含单引号,即使转义单引号也不次那个,双引号则可以,双引号也可以使用字符串。
拼接
name="huruji"
hello="my name is ${name}"
获取字符串长度
str="huruji"
echo ${#str} #6
提取子字符串
str="huruji"
echo ${str:2:3}
从字符串的第二个字符开始提取3个字符,输出ruj
查找
str="huruji"
echo `expr index "$str" u`
此时输出2,因为此时第一个字符位置从1开始
定义
names=("huruji" "greywind" "xie")
echo ${names[0]}
echo ${names[2]}
读取
echo ${names[2]}
echo ${names[@]}
如上例子,使用@可以获取数组中的所有元素
获取长度
length=${#names[@]}
length=${#names[*]}
执行Shell脚本的时候,可以向脚本传递参数,在Shell中获取这些参数的格式为$n,即$1,$2.......,
echo "第一个参数是:$1"
echo "第一个参数是:$2"
echo "第一个参数是:$3"
运行
chmod +x test.sh
test.sh 12 13 14
则此时输出:
第一个参数是:12
第一个参数是:13
第一个参数是:14
此外,还有其他几个特殊字符来处理参数
算数运算
原生bash不支持简单的数学运算,可以借助于其他命令来完成,例如awk和expr,其中expr最常用。expr是一款表达式计算工具,使用它能完成表达式的求值操作。
val=`expr 2 + 2`
echo $val
需要注意的是运算符两边需要空格,且使用的是反引号。
算术运算符包括:+ - × / % = == !=
关系运算
关系运算只支持数字,不支持字符串,除非字符串的值是数字。
a=12
b=13
if [ $a -eq $b ]
then
echo "相等"
else
echo "不等"
fi
布尔运算
逻辑运算符
字符串运算符
文件测试运算符
用于检测Unix文件的各种属性。
file="/home/greywind/Desktop/learnShell/test.sh"
if [ -e $file ]
then
echo "文件存在"
else
echo "文件不存在"
fi
if [ -r $file ]
then
echo "可读"
else
echo "不可读"
fi
if [ -w $file ]
then
echo "可写"
else
echo "不可写"
fi
if [ -x $file ]
then
echo "可执行"
else
echo "不可执行"
fi
if [ -d $file ]
then
echo "是目录"
else
echo "不是目录"
fi
if [ -f $file ]
then
echo "是普通文件"
else
echo "不是普通文件"
fi
echo在显示输出的时候可以省略双引号,使用read命令可以从标准输入中读取一行并赋值给变量
read name
echo your name is $name
换行使用转义\n,不换行使用\c
此外使用 > 可以将echo结果写入指定文件,这个文件不存在会自动创建
echo "it is a test" > "/home/greywind/Desktop/learnShell/hello"
使用反引号可以显示命令执行的结果,如date、history、pwd
echo `pwd`
echo `date`
Shell中的输出命令printf类似于C语言中的printf(),
语法格式:
printf format-string [arguments...]
printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg
printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234
printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543
printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876
test命令用于检查某个条件是否成立,可以进行数值、字符、文件三方面的测试
a=100
b=200
if test a == b
then
echo "相等"
else
echo "不等"
fi
if
a=100
b=200
if test $a -eq $b
then
echo "相等"
else
echo "不等"
fi
a=100
b=200
if test $a -eq $b
then
echo "相等"
elif test $a -gt $b
then
echo "a大于b"
elif test $a -lt $b
then
echo "a小于b"
fi
for
for num in 1 2 3 4
do
echo ${num}
done
num=10
for((i=1;i<10;i++));
do
((num=num+10))
done
echo $num
while
num=1
while [ $num -lt 100 ]
do
((num++))
done
echo $num
无限循环
while:
do
command
done
while true
do
command
done
for (( ; ; ))
until
until condition
do
command
done
case
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac
需要注意的是与其他语言不同Shell使用;;表示break,另外没有一个匹配则使用*捕获该值
echo "输入1 2 3任意一个数字"
read num
case $num in
1)echo "输入了1"
;;
2)echo "输入了2"
;;
3)echo "输入了3"
;;
*)echo "输入的值不是1 2 3"
;;
esac
与其他语言类似,循环可以使用break和continue跳出
函数定义
用户自定义函数可以使用或者不使用function关键字,同时指定了return值则返回这个值,如果没有return语句则以最后一条运行结果作为返回值。
function first(){
echo "hello world"
}
first(){
echo "hello world"
}
调用函数直接使用这个函数名即可
first
函数参数
调用函数可以传入参数,函数内部使用$n获取传入的参数,类似于运行程序使用时获取使用的参数,不过需要注意的是两位数以上应该使用{}告诉shell边界例如${12}、${20}
function add(){
num=0;
for((i=1;i<=$#;i++));
do
num=`expr $i + $num`
done
return $num
}
add 1 2 3 4 5
a=$?
echo $a
函数本身是一个命令,所以只能通过$?来获得这个返回值
在上文的例子中可以使用 > 可以将echo结果写入指定文件,这就是一种输出重定向,重定向主要有以下:
将whoami命令输出保存到user文件中
who > "./user"
使用cat命令就可以看到内容已经保存了,如果不想覆盖文件的内容那么就使用追加的方式即可。
who >> "./user"
Shell脚本可以包含外部脚本,可以很方便的封装一些公用的代码作为一个独立的文件,包含的语法格式如下:
. filename
# 或
source filename
如:
test1.sh
echo "hello world"
test.sh
source ./test1.sh
echo "hello"
~~的作用javascript:void 0到底意味着什么 Object.create(null)创建的对象没有继承任何原型,也就是说他的原型链没有上一层,而{}显然是Object的实例


我们要知道Object.create()方法的第一个参数是新建对象的原型对象呀!!!
Object.create(null)显然比{}的好处就是不用考虑和原型对象的属性重名的问题
Object.create(null)常常会在很多流行的开源项目中出现,我初次见到的时候就开始一脸懵逼了,完全不明白这有啥意义,等我明白之后不得不承认这就是大神呀
另外在IE6/7中没有JSON这个JavaScript对象,不过可以使用json2.js、clarinet、Oboe.js等库。
另外不要忘记查标准、看官网呀,(这怎么越来越像搞科研的了,F**k)。json官网:http://json.org、ECMA404标准(也就是JSON标准):http://www.ecma-international.org/publications/files/ECMA-ST/ECMA-404.pdf
首先请记住一点:void 是一个操作符,且这个操作符返回的是 undefined
经常会在href中看到javascript: void(0) 类似的代码,这段代码直接表现就是禁用了链接点击后跳转的默认功能,浏览器中的行为是遇到javascript:开头的URI,将会将后面的结果替换为href的内容,除非返回的值是 undefined。
其实,不仅在浏览器端可以使用,在任何时候我们需要这个 undefined 的时候都可以使用,比如:dayjs判断是否全等于 undefined 就是利用 void 0
const isUndefined = s => s === void 0参考:
What does “javascript:void(0)” mean?
表达式会产生一个值,表达式之间使用逗号连接,语句是一种行为,像循环语句、if语句,语句之间使用分号连接。
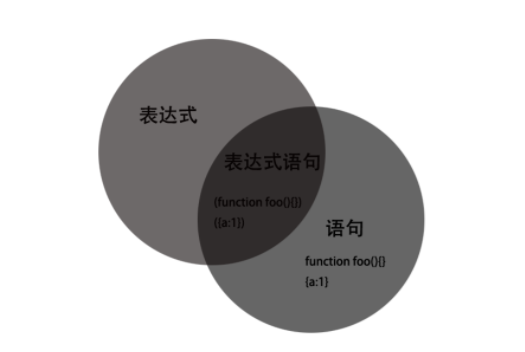
参考:
在input为file中添加capture = “camera” 即可
<input type="file" accept="image/*" capture="camera" id="selectpic" multiple="multiple" style="display:none;" />redux的主要API集中在createStore函数返回值中,以下这个迷你的redux只简单实现createStore、dispatch、subscribe、getState方法,如下:
const createStore = function(reducer, initialState){
let currentState = undefined;
if(initialState) {
currentState = initialState;
}
let currentReducer = reducer;
let listeners = [];
return {
getState() {
return currentState;
},
dispatch(action) {
if(!currentState){
currentState = currentReducer(currentState, action);
}
currentState = currentReducer(currentState, action);
listeners.forEach((item) => {
item();
});
return this;
},
subscribe(fn) {
listeners.push(fn);
}
}
};
测试代码:
let reducer = function(state, action) {
if(!state) {
return {counter: 0};
}
switch(action.type) {
case 'ADD':
return {counter: state.counter+1};
case 'DEL':
return {counter: state.counter-1};
default:
return state;
}
};
let store = createStore(reducer);
store.subscribe(function(){
console.log('before1')
});
store.subscribe(function() {
console.log('before2')
});
store.dispatch({
type:'ADD'
});
console.log(store.getState());
store.dispatch({
type: 'ADD'
});
console.log(store.getState());
store.dispatch({
type: 'DEL'
});
console.log(store.getState());
运行结果:

使用child_process模块可以开启多个子进程,在多个子进程之间可以共享内存空间,可以通过子进程之间的互相通信来实现信息的交换,多个子进程之间也可以通过共享端口的方式将请求分配给多个子进程来执行。
spawn(command, [args], [options]):第一个参数为命令,args为运行该命令需要使用的参数,options为开启子进程的选项,主要有cwd指定目录,stdio指定子进程的标准输入输出,其中stdio可以简要的使用inherit指定为子进程和父进程共享输入输出。
spawn方法返回一个隐式的代表子进程的ChildProcess对象,因此同样可以使用前面文章提到的process的各种属性、方法和事件。如下是一个简单的例子:
const spawn = require('child_process').spawn;
const child = spawn('node', ['test.js', 'one', 'two'],{
cwd: './test',
stdio: 'inherit'
});const fs = require('fs');
const out = fs.createWriteStream('./message.txt');
console.log('请输入:');
process.stdin.on('data', function(data) {
out.write(data)
});
process.stdin.on('end', function(data) {
process.exit()
});如果子进程开启失败将会触发error事件,可以在这个error事件的回调函数中指定处理方式
child.on('error', function(err) {
// 错误处理程序
})如果我们需要强制关闭子进程,可以使用kill方法强制关闭子进程。
child.kill();在默认情况下,只有子进程全部退出之后,父进程才能退出。有时候需要允许父进程退出,同时子进程继续运行,可以在开启子进程的时候使用参数detached,同时使用子进程的unref()方法允许父进程退出,如下
const child = spawn('node',['test.js'], {
cwd: __dirname,
stdio: 'inherit',
detached: true
});
child.unref();上面提到的spawn方法运行的是一个命令进程,也就意味着不仅运行node命令了。而fork方法则是专门用于运行Node.js某个模块,使用方法如下:
const fork = require('child_process').fork;
fork('./test/test.js',['123123123'], {
cwd: __dirname,
encoding: 'utf-8',
slient: false
});上面列出了fork方法的使用,第一个参数为运行的node模块,第二个可选参数为一个运行的参数列表,最后为一个配置选项的对象,其中slient表示是否和父进程共享一个标准输入输出,false默认为父、子进程共享,此外还有一个env对象用来配置环境变量。
使用fork方法开启的子进程可以使用send()方法父子进程之间互发信息,接收到信息后会触发message事件,因此可以实现父子进程的通信,如下就是一个简单的例子:
const fork = require('child_process').fork;
fork('./test/test.js',['123123123'], {
cwd: __dirname,
encoding: 'utf-8',
slient: false
});process.on('message', (m) => {
console.log('子进程收到消息');
console.log(m.userName);
});
process.send({age: 1200});这时候运行主进程文件,运行效果如下:

exec方法用于运行某个命令的子进程并缓存子进程的输出结果,这个方法很像spawn方法,区别在于spawn方法是对子进程的输入输出实时接收,而exec必须等到子进程的输出数据全部缓存成功才能接收数据,直观上的表现就是spawn方法异步,而exec方法同步。exec方法使用如下:
exec(command, [options], [callback]):同样command为命令,option为开启进程的选项,同样有cwd、env、encoding属性,这里需要注意的是timeout属性,这个属性用于指定子进程的超时时间,单位是毫秒,当子进程运行时间超过该时间时,将强制关闭该子进程,默认值为0,即不限定时间,callback则为终止子进程触发的回调函数。
execFile方法是专门用于开启运行某个可执行文件的子进程,使用如下:
execFile(file,[args], [options], [callback]):使用方法一目了然,options和callback的使用和exec()方法一致。
方法暂时先介绍到这里,具体使用案例请期待下一篇文章。

柯里化的概念大家应该都清楚,就是将一个接受多个参数的函数转化为接受单一参数的函数的技术。
柯里化函数:
function inspect(x) {
return (typeof x === 'function') ? inspectFn(x) :inspectArgs(x);
}
function inspectFn(f) {
return (f.name) ? f.name : f.toString();
}
function inspectArgs(args) {
Array.prototype.slice.call(arguments, 0);
return [].slice.call(args, 0).reduce(function(acc, x){
return acc += inspect(x);
}, '(') + ')';
}
function curry(fx) {
// 函数的length属性返回函数必须传入的参数个数
var arity = fx.length;
return function f1() {
var args = Array.prototype.slice.call(arguments, 0);
// 参数个数满足的处理
if (args.length >= arity) {
return fx.apply(null, args);
}
else {
// 参数个数不满足的处理
var f2 = function f2() {
var args2 = Array.prototype.slice.call(arguments, 0);
return f1.apply(null, args.concat(args2));
}
f2.toString = function() {
return inspectFn(fx) + inspectArgs(args);
}
return f2;
}
};
}其中 f2.toString 的实现是会报错的,我已经向作者提交了PR,这段无关紧要,可以跳过不看这个 fs.toString 的实现。很显然实现curry函数的核心就是判断参数个数,然后各种使用apply函数。
接下来就可以体验curry的好处:
add = curry(function(x, y) {
return x + y;
});
const add5 = add(5);
ad5(4)
// 9这只是一个非常小的例子,源代码还有很多例子:
add = curry(function(x, y) {
return x + y;
});
match = curry(function(what, x) {
return x.match(what);
});
replace = curry(function(what, replacement, x) {
return x.replace(what, replacement);
});
filter = curry(function(f, xs) {
return xs.filter(f);
});
map = curry(function map(f, xs) {
return xs.map(f);
});
reduce = curry(function(f, a, xs) {
return xs.reduce(f, a);
});
split = curry(function(what, x) {
return x.split(what);
});
join = curry(function(what, x) {
return x.join(what);
});在这里我们可以看到,所有的数据参数都作为了最后一个参数,很明显这样在使用时的好处就在于,这可以成为一种预加载函数函数。
非常明显的在于这样柯里化处理函数,可以让这些函数成为底层部署的函数。
我们都知道webpack-dev-server为我们在开发的时候提供了一个服务器以便于我们的开发,我们在使用之前当然需要安装:
npm i webpack webpack-dev-server -D安装完成之后我们只需要在webpack配置中配置devServer选项即可,以下是一个简单的配置:
const path = require('path');
const webpack = require('webpack');
const config = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
devtool: 'inline-source-map',
devServer: {
contentBase: './dist',
hot: true
},
plugins: [
new webpack.HotModuleReplacementPlugin()
]
}
module.exports = config;这里指定webpack-dev-server所做的事情就是以dist文件夹为开启服务器的文件夹位置,并使用热更新。这篇文章中所有演示内容也将以这个配置为基础。
上面的webpack-dev-server中指定了contentBase和hot为我们做了我们的任务,那么除了这两个配置选项,webpac-dev-server还有那些配置选项呢?
我将webpack-dev-server中的配置选项进行简单分类,总结如下:
port:指定服务器的端口号,webpack-dev-server默认的端口号是8080
host:指定host,默认为losthost,当然指定此项大多数情况下是为了这个服务可以被外部服务访问,这种情况之下,你最好应该确保你的服务运行在DNS解析的域名IP一致
https:webpack-dev-server默认以http形式开启服务,如果需要指定允许https,应该在这个选项中指定相应的HTTPS证书
https:{
key: fs.readFileSync("/path/to/server.key"),
cert: fs.readFileSync("/path/to/server.crt"),
ca: fs.readFileSync("/path/to/ca.pem"),
}proxy:设置代理,如果我们在开发的时候需要使用到一个后端开发服务器,而却希望能够在同一个域名下访问,这通常会使用在前后端同时开发时,前端需要使用后端API时,这点类似于Nginx的proxy选项。
webpack-dev-server使用的是http-proxy-middleware这个包,配置的选项与其一致。
compress:对所有服务启用gzip压缩
contentBase:静态文件的文件夹地址,默认为当前文件夹
headers:在所有的响应中提供首部内容
headers: {
"X-Custom-Foo": "bar"
}historyApiFallback:指定相应的请求应该被指定的页面替代,如果404页面需要全部替代为index.html,则声明为true即可,其他情况则需要使用rewrites来重写
404:
historyApiFallback:truerewrites:
historyApiFallback: {
rewrites: [
{ from: /^\/$/, to: '/views/landing.html' },
{ from: /^\/subpage/, to: '/views/subpage.html' },
{ from: /./, to: '/views/404.html' }
]
}openPage:指定打开浏览器时跳转到的页面
color:使用颜色,有利于找出关键信息,只能在控制台中使用
hot:启用热替换属性
info:在控制台输出信息,默认输出
open:运行命令之后自动打开浏览器
progress:将运行进度输出到控制台,只可以使用控制台
以上的命令大部分在大部分情况下只会用到很少一部分,并且以上的很多命令都是可以在配置中声明或者在控制台声明的,推荐和开发体验相关的,如hot、open、progress、color等通过命令行来写,并且写在package.json中
如:
"scripts": {
"dev": "webpack-dev-server --open --hot --colors --progress --inline --config webpack.dev.js"
},参考:webpack中文文档
create_table :products do |t|
t.string :name
endcreate_table 是最基础的、最常用的方法,通常由生成器生成,默认情况下,这个方法会自动创建 id 字段, 可以使用 id: false 来禁用主键,可以使用 :primary_key 来修改主键名称,如果需要传递数据库特有的选项,可以在 :options 选项中使用SQL代码
create_table :products, options: "ENGINE=BLACKHOLE" do |t|
t.string :name, null: false
endcreate_join_table :products, :categories这会创建包含 category_id 和 product_id 字段的 categories_products 数据表,这两个字段的 :null 选项默认设置为 false,可以通过 :column_options 选项覆盖这一设置:
create_join_table :products, :categories, column_options: {null: true}需要说明的是数据表的名称默认由前两个参数按字母顺序组合而来,可以传入 :table_name 选项来自定义数据表名称:
create_join_table :products, :categories, table_name: :categorization这个方法也接受块作为参数,用于添加索引或附加字段。
change_table 与 create_table 方法非常类似,用于修改现有的数据表,风格类似,但是传入的快对象有更多的用法。
change_table :products do |t|
t.remove :description, :name
t.string :part_number
t.index :part_number
t.rename :upccode, :upc_code
endRails 提供了与 remove_column 和 add_column 类似的 change_column 迁移方法。
change_column :products, :part_number, :text这里的代码把 products 数据表的 :part_number 字段修改为 :text 字段,需要注意的是 change_column 命令是无法撤销的。
除此之外,还有 change_column_null 和 change_column_default 方法,分别用于设置字段是否可为空、修改字段的默认值。
change_column_null :products, :name, false
change_column_default :products, :approved, from: true, to: false作用是将products数据表的 :name 字段设置为 NOT_NULL,把 :approved 字段的默认值由
true 改为 false 。
字段修饰符可以在创建或修改字段时使用,有 limit precision scale polymorphic null default index comment
使用外键约束可以保证引用的完整性,方法有 add_foreign_key 和 remove_foreign_key
如果 Active Record 提供的辅助方法不够用,可以使用 excute 方法执行任意的SQL语句
Product.connection.execute("UPDATE products SET price = 'free' WHERE id = 1")change方法是编写迁移时最常用的,change方法中只能使用以下方法:
add_column
add_foreign_key
add_index
add_reference
add_timestamps
change_column_default
change_column_null
create_join_table
create_table
disable_extension
drop_join_table
drop_table
enable_extension
remove_column
remove_foreign_key
remove_index
remove_reference
remove_timestamps
rename_column
rename_index
rename-table
最常用的迁移命令就是 rails db:migrate 命令,这个方法会调用所有未运行的change或者up方法,调用的顺序是根据迁移文件名的时间戳确定的。
运行这个命令时会自动执行 db:schema:dump 任务,这个任务用于更新 db/schema.rb 文件,以匹配数据库结构。
可以指定目标版本进行迁移
rails db:migrate VERSION=20080906120000
版本号是时间戳,这是向上迁移,但包括指定的版本。
rails db:rollback这会回滚最后一个迁移
如果需要取消多个迁移任务可以使用STEP参数:
rails db:rollback STEP=3使用 db:migrate:redo 可以回滚并重新运行这个迁移,同样可以使用STEP参数
rails db:migrate:redo STEP=3一行代码完成资源资源路由声明:
resources :photos这会创建7个不同的路由,这些路由会映射到 Photos 控制器上。
这样4个URL地址就会映射到7个不同的控制器动作上。
在创建资源路由时,会同时创建多个可以在控制器中使用的辅助方法,如上面的资源路由会创建以下方法:
photos_path:返回值为 /photos
new_photos_path:返回值为 /photos/new
edit_photo_path(:id):返回值为 /photos/:id/edit
photo_path(:id):返回值为 /photos/:id
这些方法都有对应的_url形式(photos_url),前者返回的是路径,后者返回的是完整的url地址。
可以同时定义多个资源路由:
resources :photos, :books, :videos
等价于:
resources :photos
resources :books
resources :videos使用 resource 方法可以创建单数资源,这会创建6个不同的路由:
有时候在复数资源中希望能够不使用ID就能查找资源,如显示当前登录用户的信息:
get 'profile', to: 'users#show'如果 get 方法的to选项的值是字符串,那么这个字符串应该使用controller#action形式,如果是表示动作的符号,则还需要添加controller选项:
get 'profile', to: :show, controller: 'users'把控制器放入同一命名空间是非常常见的,如将管理员有关的控制器置于 Admin:: 命名空间中,这样可以把控制器文件放在 app/controllers/admin 文件夹中,在路由中这样声明:
namespace :admin do
resources :articles, :comments
end对于articles资源
如果想把 /articles 路径(不带/admin前缀)映射到Admin::Articles控制器上,可以这样声明:
scope module: 'admin' do
resources :articles, :comments
end或者
resources :articles, module: 'admin'
resources :articles, module: 'admin'或者:
resources :articles, path: '/admin/articles'有些资源是其他资源的子资源,这种情况非常常见:
class Magazine < ApplicationRecord
has_many :ads
end
class Ad < ApplicationRecord
belongs_to :magazine
end通过嵌套路由来反映模型关联:
resources :magazine do
resources :ads
end对于嵌套路由,可以不断嵌套:
resources :publishers do
resources :magazine do
resources :photos
end
end但是显然嵌套太深是非常麻烦的,经验告诉我们嵌套资源层级不应该超过一层,而避免嵌套过深的方法之一就是把动作集合放在父资源中,这样既可以表明层级关系,又不必嵌套成员动作:
resources :articles do
resources :comments, only: [:index, :new, :create]
end
resources :comments, only: [:show, :edit, :update, :destroy]当然,使用 :shallow 选项可以简化上面的代码:
resources :articles do
resources :comments, shallow: true
end当然,在复选项中使用 :shallow 选项,这样会在所有的子资源中使用 :shallow 选项:
resources :articles, shallow: true do
resources :comments
resources :quotes
end也可以使用 shallow 方法创建作用域,使得所有嵌套均为浅层嵌套:
shallow do
resources :articles do
resources :comments
resources :quotes
resources :drafts
end
end使用scope方法也可以来定义浅层路由,且有两个选项,:shallow_path 选项会为成员路径添加前缀:
scope shallow_path: "sekret" do
resources :articles do
resources :comments, shallow: true
end
end:shallow_prefix 选项会为具名方法添加指定前缀:
scope shallow_prefix: "sekret" do
resources :articles do
resources :comments, shallow: true
end
end路由concern用于声明公共路由,公共路由可以在其他资源和路由中重复使用:
concern :commentable do
resources :comments
end
concern :image_attachable do
resources :images, only: :index
end使用:
resources :messages, concerns: :commentable
resources :articles, concerns: [:commentable, :image_attachable]相当于:
resources :messages do
resources :comments
end
resources :articles do
resources :comments
resources :images, only: :index
end除了使用路由辅助方法,Rails还可以从参数数组创建路径和URL地址,假如有以下路由:
resources :magazine do
resources :ads
end使用 magazine_ad_path 方法时,可以传入Magazine和Ad的实例,而不只是数字ID:
<%= link_to 'Ad details', magazine_ad_path(@magazine, @ad) %>还可以使用 url_for 方法时传入一组对象,Rails会自动确定对应的路由:
<%= link_to 'Ad details', url_for([@magazine, @ad]) %>Rails能够识别各个实例,自动使用 magazine_ad_path 辅助方法。当然在使用 link_to 等辅助方法时,可以只指定对象,而不必完整调用 url_for 方法:
<%= link_to 'Ad details', [@magazine, @ad] %><%= link_to 'Magazine details', @magazine %>如果想要链接到其他控制器动作,只需把动作名称作为第一个元素插入对象数组即可:
<%= link_to 'Edit Ad', [:edit, @magazine, @ad] %>这样就可把模型实例看做URL地址,这是使用资源式风格最关键的优势之一。
和资源路由自动生成一系列路由不同,这时需要分别声明各个路由,非资源路由可以把任意URL地址映射到控制器动作的路由。
声明普通路由时,可以使用符号作为参数:
get 'photos(/:id)', to: :display在处理 /photos/1 请求时,会把请求映射到 Photos 控制器的 display 动作上,并把参数1传入params[:id],并将路由映射到 PhotosController#display 上,并且 /photos 请求也会映射到这个控制器动作上,因为 :id 在括号中,是可选参数。
声明普通路由时,允许使用多个动态片段,动态片段会传入params,以便在控制器动作中使用:
get 'photos/:id/:user_id', to: 'photos#show'/photos/1/2 请求会被映射到 photos#show 动作上,这时 params[:id] 的值是 1 ,params[:user_id] 的值是 2
params 也包含了查询字符串中的所有参数,如:
get 'photos/:id', to: 'photos#show'/photos/1?user_id=2 请求也会映射到 Photos#show 控制器动作上,这时params的值是
{controller: 'photos', action: 'show', id: '1', user_id: '2'}:defaults 选项设定的散列为路由定义默认值,未通过动态片段定义的参数也可以指定默认值
get 'photos/:id', to: 'photos#show', defaults: {format: 'jpg'}Rails会把 /photos/12 路径映射到 Photos#show 动作上,并把 params[:format] 设为 'jpg'
当然 defaults 还有块的形式,可以为多个路由定义默认值:
defaults format: :json do
resources :photos
end当然需要注意的是查询参数是不会覆盖默认值的
可以使用 :as 选项来为路由命名
get 'exit', to: 'sessions#destroy', as: :logout这个路由声明会创建 logout_path 和 logout_url 这两个具名辅助方法
路由命名可以覆盖资源路由定义的路由辅助方法:
get ':username', to: 'users#show', as: :user通过使用 match 方法和 :via 选项,可以一次匹配多个HTTP方法:
match 'photos', to: 'photos#show', via: [:get, :post]通过 via: :all 选项,路由可以匹配所有的HTTP方法
match 'photos', to: 'photos#show', via: :all把GET和POST请求映射到同一个控制器动作上会带来安全隐患,通常我们应该避免将不同的HTTP方法映射到同一个控制器动作上。
使用 :contraints 选项可以约束动态片段的格式:
get 'photos/:id', to: 'photos#show', contraints: { id: /[A-Z]\d{5}/ }这个路由会匹配 /photos/A12345 路径,但不会匹配 /photos/893 路径,这个还可以简写为:
get 'photos/:id', to: 'photos#show', id: /[A-Z]\d{5}/:contraints 选项的值可以是正则表达式,但不能使用 ^ 符号,比如下面就是错误的:
get '/:id', to: 'articles#show', constraints: { id: /^\d/ }路由通配符用于指定特殊参数,这个参数会匹配路由的所有剩余部分:
get 'photos/*other', to: 'photos#unknown'这个路由会匹配 photos/12 和 /photos/long/path/to/12 路径,并把 params[:other] 分别设置为 "12" 和 "long/path/to/12"。像 *other 这样以星号开头的片段,称作“通配符片段”。
通配符片段可以出现在路由中的任何位置:
get 'books/*section/:title', to: 'books#show'在路由中可以使用 redirect 辅助方法进行重定向
get '/stories', to: redirect('/articles')重定向中也可以使用源路径的动态片段:
get '/stories/:name', to: redirect('/articles/%{name}')redirect 默认是301永久重定向,有些浏览器和代理服务器缓存这种类型的重定向,从而导致无法访问重定向前的网页,为了避免这种情况,我们可以使用 :status 选项修改响应状态:
get '/stories/:name', to: redirect('/stories/%{name}'), status: 302root 方法指明如何处理根路径的请求:
root to: 'pages#main'简易写法
root 'pages#main'root路由只处理 GET 请求
声明路由时,可以直接使用 Unicode 字符:
get "忽如寄" , to: 'welcome#index':controller 选项用于显式指定资源使用的控制器:
resources :photos, controller: 'images'这时路由会把 /photos 路径映射到 Images 控制器上
对于命名空间中的控制器,可以使用目录表示法:
resources :user_permissions, controller: 'admin/user_permissions':constraints 选项用于指定隐式 ID 必须满足格式要求
resources :photos, constraints: {id: /[A-Z][A-Z][0-9]+/ }这时会约束 :id 参数,路由不会匹配 /photos/1 路径,会匹配 /photos/PR12
当然也可以同时约束多个路由:
constraints(id: /[A-Z][A-Z][0-9]+/) do
resources :photos
resources :accounts
endresources :photos, as: 'images'此时的具名辅助方法被修改为:
:path_names 选项用于覆盖路径中自动生成的 new 和 edit 片段
resources :photos, path_names: { new: 'make', edit: 'change' }这个路由能够识别以下路径:
/photos/make
/photos/1/change:path_names 选项不会改变控制器动作的名称,仍然映射到 new 和 edit 动作上
Rails 默认会为每个 REST 式路由创建7个默认动作,可以使用 :only 和 :except 选项来微调此行为。 :only 选项用于指定想生成的路由:
resources :photos, only: [:index, :show]:except 选项用于指定不想生成的路由:
resources :photos, except: :destroy使用 scope 方法,可以修改 resources 方法生成的路径名称:
scope(path_names: {new: 'neu', edit: 'bearbeiten'}) do
resources :categories, path: 'kategorien'
end这会覆盖自动生成的辅助方法名称:
resources :magazine do
resources :ads, as: 'periodical_ads'
end这会生成 magazine_periodical_ads_url 等辅助方法。
路由:koa-router
表单解析:koa-bodyparser
视图:koa-views、ejs
session: koa-session-minimal、koa-mysql-session
数据库引擎: mysql
用户表(users):id、name、pass
文章表(posts):id、name、title、content、uic、moment、comments、pv
评论表(comment):id、name、content、postid
使用连接池连接数据库,每次查询完毕之后释放链接,可以将数据表的建立在mysql.js中完成,为每一次query创建一个公共函数,
并且每次查询都封装为一个方法,如下:
const mysql = require('mysql');
const config = require('./../config/default');
const pool = mysql.createPool({
host: config.database.HOST,
port: config.database.PORT,
user: config.database.USERNAME,
password: config.database.PASSWORD,
database: config.database.DATABASE
});
let query = function(sql, values) {
return new Promise((resolve, reject) => {
pool.getConnection(function(err, connection) {
if(err) {
resolve(err);
} else {
connection.query(sql, values, (err, rows) => {
if(err) {
reject(err);
} else {
resolve(rows)
}
connection.release();
})
}
})
})
};
let users = `create table if not exists users(
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
pass VARCHAR(40) NOT NULL,
PRIMARY KEY ( id )
);`;
let posts = `create table if not exists posts(
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
title VARCHAR(40) NOT NULL,
content VARCHAR(40) NOT NULL,
uid VARCHAR(40) NOT NULL,
moment VARCHAR(40) NOT NULL,
comments VARCHAR(40) NOT NULL DEFAULT '0',
pv VARCHAR(40) NOT NULL DEFAULT '0',
PRIMARY KEY ( id )
);`;
let comment = `create table if not exists comment(
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
content VARCHAR(40) NOT NULL,
postid VARCHAR(40) NOT NULL,
PRIMARY KEY ( id )
);`;
let createTable = function(sql) {
return query(sql, []);
};
createTable(users);
createTable(posts);
createTable(comment);
let insertData = function(value) {
let _sql = "insert into users(name,pass) values(?,?);";
return query(_sql, value);
};
let insertPost = function(value) {
let _sql = "insert into posts(name, title, content, uid, moment) values(?,?,?,?,?);";
return query(_sql, value);
};
let updatePostComment = function(value) {
let _sql = "update posts set comment=? where id=?";
return query(_sql, value);
};
let updatePostPv = function(value) {
let _sql = "update posts set pv=? where id=? ";
return query(_sql, value);
};
let insertComment = function(value) {
let _sql = "insert into comment(name, content, postid) values(?,?,?);";
return query(_sql, value);
};
let findDataByName = function(name) {
let _sql =`select * from users where name="${name}"`;
return query(_sql);
};
let findDataByUser = function(name) {
let _sql = `select * from posts where name="${name}"`;
return query(_sql);
}
let findDataById = function(id) {
let _sql = `select * from posts where id="${id}"`;
return query(_sql);
}
let findCommentById = function(id) {
let _sql = `select * from comment where postid="${id}"`;
return query(_sql);
}
let findAllPost = function() {
let _sql = `select * from posts`;
return query(_sql);
}
let updatePost = function(values) {
let _sql = `update posts set title=?,content=? where id=?`;
return query(_sql, values);
}
let deletePost = function(id) {
let _sql = `delete from posts where id=?`;
return query(_sql);
}
let deleteComment = function(id) {
let _sql = `delete from comment where id = ${id}`;
return query(_sql);
}
let deleteAllPostComment = function (id) {
let _sql = `delete from comment where postid = ?`;
return query(_sql);
}
let findCommentLength = function(id) {
let _sql = `select content from comment where postid in (select id from posts where id=${id})`;
return query(_sql);
}
module.exports = {
query,
createTable,
insertData,
findDataByName,
findDataById,
findDataByUser,
insertPost,
findAllPost,
insertComment,
findCommentById,
updatePost,
deletePost,
deleteComment,
findCommentLength,
updatePostComment,
deleteAllPostComment,
updatePostPv
};const Koa = require('koa');
const config = require('./config/default');
const path = require('path');
const ejs = require('ejs');
const router = require('koa-router');
const koaStatic = require('koa-static');
const views = require('koa-views');
const bodyParser = require('koa-bodyparser');
const session = require('koa-session-minimal');
const MysqlStore = require('koa-mysql-session');
const app = new Koa();
const sessionMysqlConfig = {
user: config.database.USERNAME,
password: config.database.PASSWORD,
database: config.database.DATABASE,
host: config.database.HOST
};
app.use(session({
key:'USER_SID',
store: new MysqlStore(sessionMysqlConfig)
}))
app.use(koaStatic(path.join(path.join(__dirname, 'public'))));
app.use(views(path.join(__dirname,'views'),{
extension: 'ejs'
}));
app.use(bodyParser());
app.use(require('./routes/singup.js').routes());
app.use(require('./routes/signin.js').routes());
app.use(require('./routes/posts').routes());
app.use(require('./routes/signout').routes());
app.listen(config.port);我们应该将数据库等配置放置在一个公共的config文件中,如下:
const config = {
port: 3000,
database: {
DATABASE: 'koablog',
USERNAME: 'root',
PASSWORD: '123456',
PORT: '3306',
HOST: 'localhost'
}
};
module.exports = config;前后端未分离中,存在的问题就是,数据判断逻辑的放置,比如根据用户是否登录显示不同的header,这个可以在视图中判断session.name是否存在,
同样也可以在route中先判断,在给传值为logined:false,个人偏向后一种,毕竟我认为视图中应该尽量少出现逻辑。

pseudomap项目是一个ES6之前使用Map数据结构的一个工具库,map的特点在于拓展了对象的键只能是字符串的短板,在ES6之前很容易想到使用一个构造函数来实现,同时对于每一个键值关系使用一个新的对象存储,this.key=key;this.value=value的形式。适合JavaScript初学者学习构造函数的使用,同时大神的代码质量还是非常值得学习的,大神终究是大神!!!
var hasOwnProperty = Object.prototype.hasOwnProperty
module.exports = PseudoMap
function PseudoMap (set) {
// 检测this的指向来判断该函数是否被当做构造函数运行,使用new实例化
// 构造函数时将改变this的指向为该对象,直接运行函数,this则是指全局对象
if (!(this instanceof PseudoMap)) // whyyyyyyy
throw new TypeError("Constructor PseudoMap requires 'new'")
this.clear()
// 设置传递的参数
if (set) {
if ((set instanceof PseudoMap) ||
(typeof Map === 'function' && set instanceof Map))
set.forEach(function (value, key) {
this.set(key, value)
}, this)
else if (Array.isArray(set))
set.forEach(function (kv) {
this.set(kv[0], kv[1])
}, this)
else
throw new TypeError('invalid argument')
}
}
PseudoMap.prototype.forEach = function (fn, thisp) {
thisp = thisp || this
Object.keys(this._data).forEach(function (k) {
if (k !== 'size')
fn.call(thisp, this._data[k].value, this._data[k].key)
}, this)
}
PseudoMap.prototype.has = function (k) {
return !!find(this._data, k)
}
PseudoMap.prototype.get = function (k) {
var res = find(this._data, k)
// 利用逻辑与的执行特点,不存在时直接返回undefined,这样就不需要在find方法中去判断了,妙
return res && res.value
}
// 存储
PseudoMap.prototype.set = function (k, v) {
set(this._data, k, v)
}
// 删除
PseudoMap.prototype.delete = function (k) {
var res = find(this._data, k)
if (res) {
delete this._data[res._index]
this._data.size--
}
}
PseudoMap.prototype.clear = function () {
// 创建一个空对象
var data = Object.create(null)
data.size = 0
// 重新设置构造函数的_data属性,不可写,不可枚举防止其被篡改
Object.defineProperty(this, '_data', {
value: data,
enumerable: false,
configurable: true,
writable: false
})
}
// 设置size的get方法返回this._data.size
Object.defineProperty(PseudoMap.prototype, 'size', {
get: function () {
return this._data.size
},
set: function (n) {},
enumerable: true,
configurable: true
})
PseudoMap.prototype.values =
PseudoMap.prototype.keys =
PseudoMap.prototype.entries = function () {
throw new Error('iterators are not implemented in this version')
}
// 两者相等或者两个都是NaN时返回true,注意逻辑与的优先级大于逻辑或
// Either identical, or both NaN
function same (a, b) {
return a === b || a !== a && b !== b
}
// 用来储存键值信息的对象
function Entry (k, v, i) {
this.key = k
this.value = v
this._index = i
}
function find (data, k) {
for (var i = 0, s = '_' + k, key = s;
hasOwnProperty.call(data, key);
key = s + i++) {
if (same(data[key].key, k))
return data[key]
}
}
function set (data, k, v) {
// 此时则是重新设置值
for (var i = 0, s = '_' + k, key = s;
hasOwnProperty.call(data, key);
key = s + i++) {
if (same(data[key].key, k)) {
data[key].value = v
return
}
}
// size自增
data.size++
// 将键值关系作为一个Entry对象储存,这样就避免了传统的对象键只能是字符串的短板
data[key] = new Entry(k, v, key)
}在实际开发中,异步总是不可逃避的一个问题,尤其是Node.js端对于数据库的操作涉及大量的异步,同时循环又是不可避免的,想象一下一次一个数据组的存储数据库就是一个典型的循环异步操作,而在循环之后进行查询的话就需要确保之前的数据组已经全部存储在了数据库中。可以得到关于循环的异步操作主要有两个问题:
方法一:设置一个flag,在每个异步操作中对flag进行检测
let flag = 0;
for(let i = 0; i < len; i++) {
flag++;
Database.save_method().exec().then((data) => {
if(flag === len) {
// your code
}
})
}方法二:将所有的循环放在一个promise中,使用then处理
new Promise(function(resolve){
resolve()
}).then(()=> {
for(let i = 0; i < len; i++) {
Database.save_method().exec()
}
}).then(() => {
// your code
})方法一:使用递归,在异步操作完成之后调用下一次异步操作
function loop(i){
i++;
Database.save_method().exec().then(() => {
loop(i)
})
}方法二:使用async和await
async function loop() {
for(let i = 0; i < len; i++) {
await Database.save_method().exec();
}
}以上的方法基本上能解决大部分的问题。
如果有兴趣,发个简历到 [email protected]
相信很多人都和我一样,刚接触babel的时候都是使用 babel-preset-es2015 这个预设套餐的,但是显然目前而言 babel-preset-env 会是一个更好的选择,babel-preset-env 可以根据配置的目标浏览器或者运行环境来自动将ES2015+的代码转换为es5。
吸引人的地方在于我们可以通过 [.browserslistrc](https://github.com/browserslist/browserslist) 文件来指定特定的目标浏览器。当然也可以通过targets选项的browsers选项指定。不过如果你的目标浏览器支持 es modules 特性,browsers 选项则会失效,如下:
{
"presets": [
["@babel/preset-env"
"targets": {
"esmodules": true
}
]
]
}同样也可以指定Node.js的版本:
{
"presets": [
["@babel/preset-env"
"targets": {
"node": "6.10"
}
]
]
}如果node的选项值为 current 则说明是指定运行时的node.js版本。
{
"presets": [
["@babel/preset-env"
"targets": {
"node": "current"
}
]
]
}我们需要知道的是制定个targets的browsers时使用的是 browserslist ,我们可以在 .babelrc 文件、package.json文件、browserslist中指定浏览器版本选项,优先级规则是 .babelrc文件定义了则会忽略 browserslist、.babelrc 没有定义则会搜索 browserslist 和 package.json 两者应该只定义一个,否则会报错。
babel-preset-env 的主要参数选项有:
targets
targets.node
targets.browsers
spec : 启用更符合规范的转换,但速度会更慢,默认为 false
loose:是否使用 loose mode,默认为 false
modules:将 ES6 module 转换为其他模块规范,可选 "adm" | "umd" | "systemjs" | "commonjs" | "cjs" | false,默认为 false
debug:启用debug,默认 false
include:一个包含使用的 plugins 的数组
exclude:一个包含不使用的 plugins 的数组
useBuiltIns:为 polyfills 应用 @babel/preset-env ,可选 "usage" | "entry" | false,默认为 false
Refs:
在Shell编程快速入门指南一文中已经简单介绍了字符串的变量命名、截取、获取长度等操作,但通常我们对字符串的操作的需求远远不止这些,Shell本身一起已经内置了一些对字符串的操作。
a="linux"
b="win"
c=${d-$b}
e=${a-$b}
echo $c
echo $e
# 输出
# win
# linux例子使用上例
c=${d-$b}
e=${a-$b}
echo $c
echo $e
# 输出
# win
# linux*${var+other} 和 ${var:+other}:如果var声明了,那么其值就是$other,否则就是null字符串(echo打印为一个空行)
a="linux"
b="win"
c=${d+$b}
e=${a+$b}
echo $c
echo $e
# 输出
#
# win${var?ERR_MSG} 和 ${var:?ERR_MSG}:如果var没有被声明,就会打印ERR_MSG(也就是说会打印出错误信息,用在调试中会非常有用)
a="linux"
b="win"
c=${d?$b}
e=${a:?$b}
echo $c
echo $e
# 输出
# test.sh:line 4: d: win${!varprefix}* 和 ${!varprefix@}:匹配之前所有以varprefix开头进行声明的变量,这是一个数组
javaLang="java"
javascriptLang="javascript"
pythonLang="python"
b="java123"
for ele in ${!java*}
do
echo $ele
done
# 输出
# javaLang
# javascriptLang${#str}:获取长度
os="linux"
echo ${#os}
# 输出
# 5
${str:position:length}:从position位置开始截取长度为length的子串,其中length可以省略,省略则是截取到最后
lang="javascript"
echo ${lang:4}
echo ${lang:4:3}
echo ${lang}
# 输出
# script
# sci
# javascript${str#substr}:从str开头删除最短匹配$substr的子串,匹配都是从开头匹配的,开头匹配不上则不删除
lang="javascript is good"
echo ${lang#java*}
echo ${lang#java}
echo ${lang#[^b-c]}
echo ${lang#[^j-z]}
# 输出
# script is good
# script is good
# avascript is good
# javascript is good${str#substr}:从str开头删除最长匹配$substr的子串,匹配都是从开头匹配的,开头匹配不上则不删除
lang="javascript is good, good study"
echo ${lang##*,}
echo ${lang##java}
# 输出
# good study
# script is good, good study${str%substr}:从str结尾删除最短匹配$substr的子串
lang="javascript is good, good,study"
good="javascript is good, good study"
echo ${lang%,*}
echo ${good%,*}
# 输出
# javascript is good, good
# javascript is good${str%%substr}:从str结尾删除最长匹配$substr的子串
lang="javascript is good, good,study"
good="javascript is good, good study"
echo ${lang%%,*}
echo ${good%%,*}
# 输出
# javascript is good
# javascript is good${str/substr/replacement}:使用$replacement来替代第一个匹配的substr子串
lang="java is good, javascript is good"
lang2="python"
bast="the best"
echo ${lang/java/$lang2}
echo ${lang/good/$bast}
# 输出
# python is good, javascript is good
# java is the best, javascript is good${str//substr/replacement}:使用$replacement来替代所有匹配的substr子串
lang="java is good, javascript is good"
lang2="python"
bast="the best"
echo ${lang//java/$lang2}
echo ${lang//good/$bast}
# 输出
# python is good, pythonscript is good
# java is the best, javascript is the best${str/#substr/replacement}:如果$str的前缀匹配$substr则使用$replacement替代
lang="java is good, javascript is good"
lang2="python"
echo ${lang/#java/$lang2}
# 输出
# python is good, javascript is good${str/%substr/replacement}:如果$str的后缀缀匹配$substr则使用$replacement替代
lang="java is good, javascript is good"
bast="the bast"
echo ${lang/%good/$bast}
# 输出
# java is good, javascript is the best列出当前文件夹下所有文件含有的后缀名
function hasItem() {
arr=$1;
item=$2;
for ele in ${arr[@]}
do
if [[ $item = $ele ]]; then
return 0
fi
done
return 1
}
arr=()
for file in `ls`
do
ext=${file#*.}
echo ${arr[@]}
hasItem $arr $ext
if [ $? -eq 1 ]; then
length=${#arr[*]}
if [ $length -eq 0 ]; then
arr=($ext)
else
arr=("${arr[@]}" "${ext}")
fi
else
arr=$arr
fi
done
for name in ${arr[@]}
do
echo $name
doneloose mode 我翻译为松散模式,loose mode在babel中通常是不推荐使用的,但是我们需要知道的是使用 loose mode 转换而来的代码更加像ES5的代码(更像是人手写的)
大多数Babel插件都有两种模式 normal mode 和 loose mode,normal mode 转换而来的ES5代码更加符合ECMAScript 6 的语义,而 loose mode 转换而来的代码更加简单,更像是人写的。
loose mode 的优点在于兼容旧引擎,可能会更加快,缺点在于如果我们需要将转换之后的代码重新转换为 native ES6 代码,可能会遇到问题,而这个冒险在大多数时候是不值得的。
以ES6的class为例,我们编写以下代码:
class person {
constractor(name, age) {
this.name = name;
this.age = age;
}
getName(){
return this.name;
}
getAge(){
return this.age;
}
}normal mode 下转换为:
"use strict";
var _createClass = function () { function defineProperties(target, props) { for (var i = 0; i < props.length; i++) { var descriptor = props[i]; descriptor.enumerable = descriptor.enumerable || false; descriptor.configurable = true; if ("value" in descriptor) descriptor.writable = true; Object.defineProperty(target, descriptor.key, descriptor); } } return function (Constructor, protoProps, staticProps) { if (protoProps) defineProperties(Constructor.prototype, protoProps); if (staticProps) defineProperties(Constructor, staticProps); return Constructor; }; }();
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
var person = function () {
function person() {
_classCallCheck(this, person);
}
_createClass(person, [{
key: "constractor",
value: function constractor(name, age) {
this.name = name;
this.age = age;
}
}, {
key: "getName",
value: function getName() {
return this.name;
}
}, {
key: "getAge",
value: function getAge() {
return this.age;
}
}]);
return person;
}();loose mode 下转换为:
"use strict";
function _classCallCheck(instance, Constructor) { if (!(instance instanceof Constructor)) { throw new TypeError("Cannot call a class as a function"); } }
var person = function () {
function person() {
_classCallCheck(this, person);
}
person.prototype.constractor = function constractor(name, age) {
this.name = name;
this.age = age;
};
person.prototype.getName = function getName() {
return this.name;
};
person.prototype.getAge = function getAge() {
return this.age;
};
return person;
}();可以看到,非常直观的是 loose mode 下的代码更加像是人手写的。尽管如此,但是仍然不推荐使用 loose mode
References:
从控制器的角度,创建HTTP响应有三种方法:
调用 render 方法
调用 redirect_to 方法
调用 head 方法,向浏览器发送只含HTTP首部的响应
一个控制器:
class BooksController < ApplicationController
def index
@books = Book.all
end
end基于“多约定,少配置”原则,在 index 动作末尾并没有指定要渲染的视图,Rails会自动在控制器的视图文件夹中寻找 action_name.html.erb 模板,然后渲染。这里渲染的就是 app/views/books/index.html.erb
render 方法的行为有多种定制方式,可以渲染Rails模板的默认视图、指定的模板、文件、行间代码或者什么也不渲染。渲染的内容可以是 文本 、JSON 或者 XML,而且可以设置响应的内容类型和HTTP状态码。
渲染同个控制器的其他模板
def update
@book = Book.find(params[:id])
if @book.update(book_params)
redirect_to @book
else
render "edit"
end
end不想用字符串,也可以使用符号:
render :edit渲染其他控制器的动作
使用 render 方法,指定模板的完整路径(相对于 app/views)即可。
render "products/show"为了代码意图更加明显,还可以使用 :template 选项:
render template: "products/show"渲染任意文件
render file: "/u/apps/warehouse_app/current/app/views/products/show" 想要渲染 views/books 下的 edit.html.erb 模板,以下方法都行:
render :edit
render action: :edit
render "edit"
render "edit.html.erb"
render action: "edit"
render action: "edit.html.erb"
render "books/edit"
render "books/edit.html.erb"
render template: "books/edit"
render template: "books/edit.html.erb"
render "/path/to/rails/app/views/books/edit"
render "/path/to/rails/app/views/books/edit.html.erb"
render file: "/path/to/rails/app/views/books/edit"
render file: "/path/to/rails/app/views/books/edit.html.erb"渲染纯文本
使用 :plain 选项,可以把没有标记语言的纯文本发给浏览器,这主要用于响应Ajax或无需使用HTML的网络服务。
render plain: "OK"渲染HTML
使用 :html 选项可以把HTML字符串发送给浏览器:
render html: "<p>hello, world</p>".html_safe如果没调用 html_safe 方法,HTML实体会转义
渲染JSON
render json: @product在需要渲染的对象上无需调用 to_json 方法,使用了 :json 选项,render 方法会自动调用 to_json 。
渲染XML
render xml: @product在需要渲染的对象上无需调用 to_xml 方法,使用了 :xml 选项,render 方法会自动调用 to_xml 。
渲染javascript
render js: "alert('hello, rails')"此时发送给浏览器的字符串,其MIME类型就是 text/javascript
渲染原始的主体
render body: "raw"这时候返回的类型是 text/html ,只有在不在意内容类型的时候才应该使用这个选项。大多数时候,使用 :plain 或 :html 选项更加合适。
render 方法一般还可接受其他5个选项:
:content_type
:layout
:location
:status
:formats
:content_type选项
默认情况下,Rails渲染得到的结果内容类型为 text/html,如果使用 :json 选项,内容类型为 application/json,如果使用 :xml 选项,则内容类型为 application/xml ,如果需要修改内容类型,可使用 :content_type 选项:
render file: filename, content_type: "application/rss":layout 选项
render 方法大部分渲染得到的结果都会作为当前布局的一部分显示,:layout 选项指定使用特定的文件作为布局:
render layout: "special_layout"当设置为 false 时,则说明不使用布局:
render layout: false:location选项
用于设置HTTP的location首部:
render xml: photo, location: photo_url(photo):status选项
设定HTTP状态码,(在大多数情况下都是200),可以使用HTTP状态码,也可以使用状态码含义设定。
render status: 500
render status: :forbidden:formats选项
改变格式,值可以是一个符号或者一个数组,默认使用 :html:
render formats: :xml
render formats: [:json, :xml]查找布局时,首先在文件夹 app/views/layouts 文件夹中是否有和控制器同名的文件。例如,渲染 PhotosController 中的动作会使用 app/views/layouts/photo.html.erb 或者 app/views/layouts/photos.builder 。如果没有针对控制器的布局,Rails会使用 app/views/layouts/application.html.erb 或 app/views/layouts/application.builder 。如果没有 .erb 布局,Rails会使用 .builder 布局。
指定控制器的布局
在控制器中使用 layout 声明,可以覆盖默认使用的布局约定:
class ProductsController < ApplicationController
layout "inventory"
end若要指定整个应用使用的布局,可以在ApplicationController类中使用layout声明:
class ApplicationController < ActionController::Base
layout "main"
end在运行时选择布局
使用符号把布局延后到处理请求时再选择:
class ProductsController < ApplicationController
layout :products_layout
def show
@product = Product.find(params[:id])
end
private
def products_layout
@current_user.special? ? "special" : "products"
end现在,如果用户是特殊用户,会使用一个特殊的布局渲染。
根据条件设定布局
使用 :only 和 :except 选项,可以设定条件
class ProductsController < ApplicationController
layout "product", except: [:index, :rss]
endredirect_to 方法告诉浏览器向另一个URL发起新请求:
redirect_to photos_url可以使用 redirect_back 把用户带回他们之前所在的页面,页面地址从 http_referer 中获取,不过浏览器不一定会设定,所以需要设定 fallback_location
redirect_back(fallback_location: root_path)默认 redirect_to 方法把HTTP状态码设为302,如果想要设定其他状态码,可以使用 :status 选项:
redirect_to photos_path, status: 301head 方法只把首部发送给浏览器,参数是HTTP状态码数字,或者符号形式,选项是一个散列,指定首部的名称和对应的值
head :bad_request
head :created, location: photo_path(@photo)aotu_discovery_link_tag
javascript_include_tag
stylesheet_link_tag
image_tag
video_tag
audio_tag
<%= auto_discovery_link_tag(:rss, {action: "feed"}, {title: "RSS Feed"}) %>Rails应用的javascript文件可以存放在三个位置: app/assets 、lib/assets 、vendor/assets。文件的地址可使用相对文档根目录的完整路径或URL。例如,如果想链接到 app/assets、lib/assets 或 vendor/assets 文件夹中名为 javascripts 的子文件夹中的文件,可以这么做:
<%= javascript_include_tag "main" %>Rails生成的script标签如下:
<script src="/assets/main.js"></script>同时引入多个文件:
<%= javascript_include_tag "main", "columns" %>引入外部文件:
<%= javascript_include_tag "http://example.com/main.js" %>类似于 javascript_include_tag
<%= stylesheet_link_tag "main" %><%= stylesheet_link_tag "main", "column" %>默认情况下, stylesheet_link_tag 创建的链接属性为 media="screen" rel="stylesheet",指定相应的选项可以覆盖默认值:
<%= stylesheet_link_tag "main_print", media: "print" %>生成img标签,默认从 public/images 文件夹中加载文件:
<%= image_tag "header.png" %>
文件名必须指定图像的拓展名
同样可以通过散列指定HTML属性,另外如果没有 alt 属性,
Rails会使用图片的首字母大写的文件名(去掉拓展名)。
<%= image_tag "home.gif" %>
<%= image_tag "home.gif", alt: "Home" %>生成 <video> 标签,默认从 public/vedios 文件夹中加载文件。
<%= video_tag "movie.ogg" %>生成
<video src="/videos/movie.ogg" />同样也支持散列指定HTML属性。
把数组传递给 video_tag 方法可以指定多个视频
<%= video ["trailer.ogg", "movie.ogg"] %>生成
<video>
<source src="trailer.ogg" />
<source src="movie.ogg" />
</video>生成 <audio> 标签,默认从 public/audio 文件夹中加载
<%= audio_tag "music.mp3" %>
在布局中,yield 标明一个区域,渲染的视图会插在这里,最简单的情况是只有一个 yield ,此时渲染的整个视图都会插入在这个区域:
<html>
<head></head>
<body>
<%= yield %>
</body>
</html>表明多个区域:
<html>
<head>
<%= yield %>
</head>
<body>
<%= yield %>
</body>
</html>视图的主体会插入未命名的yield区域,若想在具名yield中插入内容,可以使用 content_for 方法。
<% content_for :head do %>
<title>A simple page</title>
<% end %>
<p>Hello, World!</p>套入布局后生成:
<html>
<head>
<title>A simple page</title>
</head>
<body>
<p>Hello, World!</p>
</body>
</html>如果不同区域需要不同的内容(sidebar、footer等),就可以使用 content_for 方法。
<%= render "menu" %>这会渲染名为 _menu.html.erb 的文件,局部视图的文件名都是以下划线开头的,以便和普通视图区分开,引用时无需加入下划线。
局部布局
与视图使用布局一样,局部视图也可以使用布局
<%= render partial: "link_area", layout: "graybar" %>这里会使用 _graybar.html.erb 布局渲染局部视图 _link_area.html.erb ,此时局部布局与局部视图保存在同一个文件夹中。
传递局部变量
局部变量可以传入局部视图,这样可以使得局部视图更加强大、更加灵活。
new.html.erb
<h1>New zone</h1>
<%= render partial: "form", locals: {zone: @zone} %>edit.html.erb
<h1>Editing zone</h1>
<%= render partial: "form", locals: {zone: @zone} %>_form.html.erb
<%= form_for(zone) do |f| %>
<p>
<b>Zone name</b><br>
<%= f.text_field :name %>
</p>
<p>
<%= f.submit %>
</p>
<% end %>每个局部视图中都有一个和局部视图同名的局部变量,通过object选项可以把这个对象传给这个变量:
<%= render partial: "customer", object: @new_customer %>如果要在局部视图中渲染模型实例,可以使用简写:
<%= render @customer %>如果要在局部视图中自定义局部变量的名字,可以使用 :as 选项指定:
<%= render partial: "product", collection: @products, as: :item %>Active Record 是MVC中的M,负责处理数据和业务逻辑,Active Record实现了Active Record模式,是一种 对象关系映射 系统
Active Record 模式: 在 Active Record 模式: 中,对象中既有持久存储的数据,也有针对数据的操作,Active Record 模式把数据存取逻辑作为对象的一部分,处理对象的用户知道如何读写数据。
对象关系映射: ORM是一种技术手段,把应用中的对象和关系型数据库中的数据表连接起来,使用ORM,应用中对象的属性和对象之间的关系可以通过一种简单额方法从数据库中获取,无需直接编写SQL语句,也不过度依赖特定的数据库种类。
Active Record重要的功能有:
表示模型和其中的数据
表示模型之间的关系
通过相关联的模型表示继承层次结构
持久存入数据之前,验证模型
以面向对象的形式操作数据库
Rails把模型的类名转换为复数,然后查找对应的数据表,Rails提供的单复数转换功能非常强大,类名应该使用驼峰命名:
外键: 使用 singularized_table_name_id 形式命名,例如 item_id,order_id。创建模型关联后,Active Record 会查找这个字段。
主键: 默认情况下,使用证整数字段id作为表的主键。
还有一些可选的字段:created_at、updated_at、type、lock_version
只需要继承 ApplicationRecord 类就行:
class Product < ApplicationRecord
end如果应用需要使用其他的命名约定,或者在 Rails 中使用已有的数据库,则可以覆盖默认的命名约定,如修改表名和主键名:
class Product < ApplicationRecord
self.table_name = "my_products"
self.primary_key = "product_id"
end创建记录并存入数据库
user = User.create(name: "huruji", age: 12)实例化,但不保存
user = User.new调用save实例方法可以保存
user.save使用块可以初始化对象
user = User.new do |u|
u.name = 'huruji'
u.age = 12
end返回所有数据
users = User.all返回第一条数据
user = User.first查找返回
huruji = User.find(name : 'huruji')排序返回
users = User.where(age: 12).order(created_at: :desc)获取到Active Record对象之后,修改属性之后再保存
user = User.find_by(name: 'huruji')
user.name = 'xie'
user.save使用update
user = User.find_by(name: 'huruji')
user.update(name: 'xie')
使用update_all批量更新数据
User.update_all "age = 12, sex = man"user = User.find_by(name: "huruji")
user.destroy在存入数据库之前,Active Record 可以验证模型,已检查属性值是否不为,是否唯一等。
调用 save 和 update 方法都会做数据验证,验证失败返回false。
class User < ApplicationRecord
validates :name, presence: true
endRails提供了一个DSL来处理数据库模式,叫做迁移,迁移的代码储存在特定的文件中,可以通过rails命令执行。
Web 和 Native 最大的差距不是调用底层接口的能力甚至不是性能,而在于各种细节,保证从设计到实现做到精细化。
流程规范:设计稿标准 + 视觉走查流程
基础方案:沉淀设计还原的基础方案
工具辅助:视觉还原对比工具
对于动画我们应该参考 iOS 和 Android 的原生动画,参考其动画方式和缓动模式。
主要反映在以下几点:
极速响应:在100ms内响应用户的操作
实时反馈:实时响应手势过程
操作流畅:动画、手势响应、滚动
并行加载资源和数据
足够快时不需要Loading
组合Promise
另外可以前端采集响应时间大于100ms的异常进行上报。
跨端加载机制,保证页面可加载(基于 Service Worker 的跨端预加载方案,保证页面一定能打开,并且秒开)
统一的异常提示和重试机制
避免误操作-点击区域(尽可能将点击区域做大,防止用户点击无响应)
Refs

cookie-parser相信使用过Express的人肯定使用过,cookie-parser是一个Express解析cookie的中间件,其中关于signed cookie的疑问可以在 What are “signed” cookies in connect/expressjs?这里找到。(等我智商涨一点再来看了)。
req本质是inComingMessage,cookie-parser所做的工作是将cookie从header中转移到req中,并且转化为json对象。
var secrets = !secret || Array.isArray(secret)
? (secret || [])
: [secret]作用是:将字符串、空值、数组都转化为数组
/*!
* cookie-parser
* Copyright(c) 2014 TJ Holowaychuk
* Copyright(c) 2015 Douglas Christopher Wilson
* MIT Licensed
*/
'use strict'
/**
* Module dependencies.
* @private
*/
var cookie = require('cookie')
var signature = require('cookie-signature')
/**
* Module exports.
* @public
*/
module.exports = cookieParser
module.exports.JSONCookie = JSONCookie
module.exports.JSONCookies = JSONCookies
module.exports.signedCookie = signedCookie
module.exports.signedCookies = signedCookies
/**
* Parse Cookie header and populate `req.cookies`
* with an object keyed by the cookie names.
*
* @param {string|array} [secret] A string (or array of strings) representing cookie signing secret(s).
* @param {Object} [options]
* @return {Function}
* @public
*/
function cookieParser (secret, options) {
return function cookieParser (req, res, next) {
// 如果cookies已经存储在req对象中,则直接跳过
if (req.cookies) {
return next()
}
// req本质是inComingMessage,cookie存在headers中
var cookies = req.headers.cookie
// secret可以为空,字符串,或者数组,全部转化为数组
var secrets = !secret || Array.isArray(secret)
? (secret || [])
: [secret]
req.secret = secrets[0]
// 普通cookie对象
req.cookies = Object.create(null)
// signed cookie对象
req.signedCookies = Object.create(null)
// no cookies
if (!cookies) {
return next()
}
// 利用cookie模块将其解析为json对象
req.cookies = cookie.parse(cookies, options)
// parse signed cookies
if (secrets.length !== 0) {
req.signedCookies = signedCookies(req.cookies, secrets)
req.signedCookies = JSONCookies(req.signedCookies)
}
// parse JSON cookies
req.cookies = JSONCookies(req.cookies)
next()
}
}
/**
* Parse JSON cookie string.
*
* @param {String} str
* @return {Object} Parsed object or undefined if not json cookie
* @public
*/
function JSONCookie (str) {
if (typeof str !== 'string' || str.substr(0, 2) !== 'j:') {
return undefined
}
try {
return JSON.parse(str.slice(2))
} catch (err) {
return undefined
}
}
/**
* Parse JSON cookies.
*
* @param {Object} obj
* @return {Object}
* @public
*/
function JSONCookies (obj) {
var cookies = Object.keys(obj)
var key
var val
for (var i = 0; i < cookies.length; i++) {
key = cookies[i]
val = JSONCookie(obj[key])
if (val) {
obj[key] = val
}
}
return obj
}
/**
* Parse a signed cookie string, return the decoded value.
*
* @param {String} str signed cookie string
* @param {string|array} secret
* @return {String} decoded value
* @public
*/
function signedCookie (str, secret) {
if (typeof str !== 'string') {
return undefined
}
if (str.substr(0, 2) !== 's:') {
return str
}
var secrets = !secret || Array.isArray(secret)
? (secret || [])
: [secret]
for (var i = 0; i < secrets.length; i++) {
var val = signature.unsign(str.slice(2), secrets[i])
if (val !== false) {
return val
}
}
return false
}
/**
* Parse signed cookies, returning an object containing the decoded key/value
* pairs, while removing the signed key from obj.
*
* @param {Object} obj
* @param {string|array} secret
* @return {Object}
* @public
*/
function signedCookies (obj, secret) {
// 获取cookie的所有键名为数组
var cookies = Object.keys(obj)
var dec
var key
var ret = Object.create(null)
var val
for (var i = 0; i < cookies.length; i++) {
// 键
key = cookies[i]
// 值
val = obj[key]
dec = signedCookie(val, secret)
if (val !== dec) {
ret[key] = dec
delete obj[key]
}
}
return ret
}先说环境,我测试了两台IOS手机,iphone 8 ios 11.4.1 和 iphone 6s plus ios 11.4.1,都存在这个诡异的bug。
这几天老大告诉我要做一个用户的引导页,引导页大致的效果像是这样子:
我也用过很多APP,很多APP其实这个引导页可视区域都是用图片代替的,但是我认为使用图片的话,当引导页消失的时候,用户会发现这和自己在引导页看到的不一致,我认为这是一种不好的用户体验,因此我不想用图片来代替!!!
于是灵光一现使用box-shadow来做,因为box-shadow的第四个值就是阴影的拓展尺寸,我把这个设置为非常大,这样就很适合作为黑色的蒙层部分,想想都感觉自己是如此的机智。
box-shadow: 0 0 0 9999999px rgba(0,0,0,.8)
当我兴致勃勃写了一连串的引导页的时候,满心欢喜的以为可以交差了,然后使用了iphone测试了一下,然后就发现了问题,整个引导页蒙层的黑色部分消失了,我的引导页瞬间成了这样子。
纳尼。。。。也就是说 box-shadow不生效。
看到这里,一顿操作,先把浏览器前缀加上,-webkit-box-shadow来一发,不行,那就-webkit-appearance试一试,竟然还是不行
思前想后,不对呀,在安卓上都是正常的呀,应该是ios下的问题,但是不对呀,很对地方都用到了box-shadow,不应该出问题,看着这里的代码,我不禁陷入了深深的思考。。。
要不试试将这个值设置小一点试一下,对呀,于是我做了一个简单的demo,如下:
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<title>CSS border-shadow 属性</title>
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=0, shrink-to-fit=no">
</head>
<style>
#mask{
width: 200px;
height: 200px;
background: #fff;
box-shadow: 0px 0px 0px 10px #000;
border-radius: 5px;
}
</style>
<body>
<div id="mask">
hello
</div>
</body>
</html>
于是我不断尝试修改box-shadow的尺寸10px 、100px 、1000px、10000px、2000px.....(论二分法在现实测试中的应用,哈哈哈哈),于是经过一番折腾,我最终确定了2039px这个边界值,也就是说2039px(准确来说是2039.98px)
当尺寸小于等于这个值的时候是显示正常的,大于这个值是不能显示box-shadow的,如下:
在这个时候,我扶了扶我想象中的眼镜,真相只有一个
就在我准备下结论的时候,我觉得我仔细看看了这些属性,我觉得border-radius还是很诡异,毕竟应该尽量减少变量才能下结论呢
我尝试这个时候增加10px的圆角,可是此时整个页面又白屏了,纳尼
于是我减少了10px的尺寸,发现这时候显示正常了,wc,2044px,难道和这个有关
我尝试修改其中一个的圆角值,如下:
box-shadow: 0px 0px 0px 2039px #000;
border-radius: 6px 6px 6px 90px;
显示正常
box-shadow: 0px 0px 0px 2039px #000;
border-radius: 6px 6px 6px 6px;
不显示
box-shadow: 0px 0px 0px 2039px #000;
border-radius: 6px 6px 5.9999px 6px;
显示正常,纳尼,卧槽,可以这样修复呀。
我尝试将尺寸修改为丧心病狂的9999px,正常。
心累,就这样我成了一下午的测试工程师,ios的bug真累人。
最后,得出结论就是:
元素同时设置border-radius和box-shadow的时候:如果圆角的值一致,请确保这两个值的和不超过2044px,如果一定会超过的话,请微小修改其中一个圆角的值,如5.999px
另外,如果有更好的解决方法请告诉我。
开发web应用时,我们总是需要对用户的数据进行验证,这包括客户端的验证以及服务端的验证,仅仅依靠客户端的验证是不可靠的,毕竟我们不能把所有的用户都当成是普通用户,绕过客户端的验证对于部分用户来说并不是什么难事,因此所有数据应该在服务端也进行一次验证。Express应用可以通过express-validator进行数据验证,这样就不必自己烦琐的为每一个数据单独写验证程序(过来人告诉你这感觉简直糟透了)。
通过一个简单的例子让我们来看看express-validator的便捷,让用户上传一些数据,表单如下:
最简单的服务端代码如下:
var express = require('express');
var bodyParser = require('body-parser');
var expressValidator = require('express-validator');
var check = require('express-validator/check').check;
var validationResult = require('express-validator/check').validationResult;
var app = express();
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({extended:false}));
app.get('/', function(req, res) {
res.sendFile('index.html', {root:'./test'});
});
app.post('/data', [
check('email')
.isEmail()
.withMessage('must be an email'),
check('username')
.isLength({min:6})
.withMessage('ust be at least 6 chars long')
],function(req, res) {
var errors = validationResult(req);
if(!errors.isEmpty()) {
return res.json({errors: errors.mapped()});
}
res.json({msg:'success'});
});
app.listen(4000);当用户上传数据之后会在服务端对用户的用户名和邮箱进行验证,当数据不符合时,错误信息显示如下:
从上面的例子中可以看到对数据的验证错误可以随时获取,从而进行处理。
validationResult方法获取捕获的错误,mapped()方法获取具体的错误信息。
express-validator是基于validator.js的,express-validator也类似将API分为check和filter两个部分(关于validator.js的使用可以参考使用validator.js对字符串数据进行验证
)
field是一个字符串或者是一个数组,message是验证不通过的错误信息,返回验证链(链式调用)
check方法默认会验证req.body、req.cookies、req.headers、req.params、req.query中的字段,如果有相同字段,其中一个不通过就会显示错误信息。
如将以上例子的post地址新增一个名为email的query则错误信息如下:
注意location的值。
如果需要单独验证req.body、req.cookies、req.headers、req.params、req.query的其中一个目标的字段,则可以使用对应的方法body、cookie、header、param、query、body、
validationChains是验证链组成的数组,如果验证链至少有一条通过则不显示错误。
var express = require('express');
var bodyParser = require('body-parser');
var expressValidator = require('express-validator');
var check = require('express-validator/check').check;
var oneOf = require('express-validator/check').oneOf;
var validationResult = require('express-validator/check').validationResult;
var app = express();
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({extended:false}));
app.get('/', function(req, res) {
res.sendFile('index.html', {root:'./test'});
});
app.post('/data', oneOf([
check('email')
.isEmail()
.withMessage('must be an email'),
check('username')
.isLength({min:6})
.withMessage('ust be at least 6 chars long')
]),function(req, res) {
var errors = validationResult(req);
if(!errors.isEmpty()) {
return res.json({errors: errors.mapped()});
}
res.json({msg:'success'});
});
app.listen(4000);获取验证的结果是否通过
从指定的locaation中构建check,locations是body、cookies、headers、params、query一个或者几个组成的数组,相当于指定位置的字段进行验证(请不要忘记check方法会对这5个部分都进行验证)
var buildCheckFunction = require('express-validator/check').buildCheckFunction;
var checkBodyAndQuery = buildCheckFunction(['body','query']);获取check的字段数据,也就是获取上文例子出现的错误信息中的value字段值,options为一个json对象,允许的字段为
{
onlyValidData:true,
locations:[]
}onlyValidData显然就是是否仅仅获取验证的字段值,默认为true,locations就是指定位置。
app.post('/data', [
check('email')
.isEmail()
.withMessage('must be an email'),
check('username')
.isLength({min:6})
.withMessage('ust be at least 6 chars long')
],function(req, res) {
var queryData = matchedData(req, {locations: ['query']});
var bodyData = matchedData(req, {locations: ['body']});
console.log(queryData);
console.log(bodyData);
var errors = validationResult(req);
if(!errors.isEmpty()) {
return res.json({errors: errors.mapped()});
}
res.json({msg:'success'});
});类似于check,只不过是返回一个处理链,理所当然有类似的sanitizeBody、sanitizeCookie、sanitizeParam、sanitizeQuery、buildSanitizeFunction。(注意req.headers在这里不适用)
进行自定义处理程序
除此之外,express-validator保留了版本3的作为express中间件的使用方式。
var express = require('express');
var expressValidator = require('express-validator');
app.use(expressValidator({
errorFormatter: function(param, message, value) {
return {
param: param,
message: message,
value: value
}
},
customValidators: {
isEmail: function(value) {
return /\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/.test(value);
},
isString: function(value) {
return typeof value === 'string';
},
isObject: function(value) {
return (typeof value === 'object' && !Array.isArray(value));
},
isArray: function(value){
return Array.isArray(value);
},
isBoolean: function(value) {
return value === true || value === false;
},
custom: function(value, callback) {
if(typeof value !== 'undefined') {
callback(value);
return true;
} else {
return false;
}
}
}
}));可以在使用use加载中间件的时候自定义第三方验证方法和处理方法。
验证数据时的使用方式如下:
req.checkBody('email', '邮件格式不正确').isEmail();
req.checkBody('password', '密码不能小于6位').isLength(6);
对于AMD规范的具体描述在这里可以找到AMD (中文版). AMD规范作为JavaScript模块加载的最流行的规范之一,已经有很多的实现了,我们就来实现一个最简单的AMD加载器
首先我们需要明白我们需要有一个所有模块的入口也就是主模块,主模块的依赖加载的过程中迭代加载相应的依赖,我们使用use方法来加载使用主模块。
同时我们需要明白加载依赖之后需要执行模块的方法,这显然应该使用callback,同时为了多个模块依赖同一个模块的时候,不会多次执行这个模块我们应该判断这个模块是否已经加载过,因此我们可以使用一个对象来描述一个模块。而所有的模块我们可以一个对象来存储,使用模块名作为属性名来区分不同模块。
首先我们先来实现use方法,这个方法就是主模块方法,使用这个模块的方法就是加载依赖之后,执行主模块的方法,如下:
function use(deps, callback) {
if(deps.length === 0) {
callback();
}
var depsLength = deps.length;
var params = [];
for(var i = 0; i < deps.length; i++) {
(function(j){
loadMod(deps[j], function(param) {
depsLength--;
params[j] = param;
if(depsLength === 0) {
callback.apply(null, params);
}
})
})(i)
}
}说明一下loadMod方法为加载依赖的方法,其中因为主模块加载了这些模块之后是需要作为callback的参数来使用这些模块的,因此我们既需要判断是否加载完毕,也需要将这些模块作为参数传递给主模块的callback。
接下来我们来实现这个loadMod方法,为了一步一步实现功能,我们假设这里所有的模块都没有依赖其他模块,只有主模块依赖,因此这个时候loadMod方法做的事情就是创建script并将相应的文件加载进来,这里我们再次假设所有模块名和文件名一致,并且所有的js文件路径与页面文件路径一致。
这个过程中我们需要知道这个script的确是加载了才执行callback,因此需要使用事件进行监听,所以有以下代码
function loadMod(name, callback) {
var doc = document;
var node = doc.createElement('script');
node.charset = 'utf-8';
node.src = name + '.js';
node.id = 'loadjs-js-' + (Math.random() * 100).toFixed(3);
doc.body.appendChild(node);
if('onload' in node) {
node.onload = callback;
} else {
node.onreadystatechange = function() {
if(node.readyState === 'complete') {
callback();
}
}
}
}接着我们需要来实现最为核心的define函数,这个函数的目的是定义模块,为了简便避免做类型判断,我们暂时规定所有的模块都必须定义模块名,不允许匿名模块的使用,并且我们先暂且假设这里没有模块依赖。如下:
var modMap = [];
function define(name, callback) {
modMap[name] = {};
modMap[name].callback = callback;
}这时我们发现一个问题这样定义的模块内部的方法并没有被调用而且模块返回的参数也没有传递给主模块上,因此在loadMod的过程中我们应该再次使用use方法,只不过此时依赖为一个空数组,因此我们可以将loadMod方法再次抽离出一个loadScript方法来,如下:
function loadMod(name, callback) {
use([], function() {
loadscript(name, callback);
})
}
function loadscript(name, callback) {
var doc = document;
var node = doc.createElement('script');
node.charset = 'utf-8';
node.src = name + '.js';
node.id = 'loadjs-js-' + (Math.random() * 100).toFixed(3);
doc.body.appendChild(node);
node.onload = function() {
var param = modMap[name].callback();
callback(param);
}
}这个时候我们先不管功能是否实现,而是可以发现现在这个代码的全局变量实在太多,因此我们需要简单封装一下,如下:
(function(root){
var modMap = [];
function use(deps, callback) {
if(deps.length === 0) {
callback();
}
var depsLength = deps.length;
var params = [];
for(var i = 0; i < deps.length; i++) {
(function(j){
loadMod(deps[j], function(param) {
depsLength--;
params[j] = param;
if(depsLength === 0) {
callback.apply(null, params);
}
})
})(i)
}
}
function loadMod(name, callback) {
use([], function() {
loadscript(name, callback);
})
}
function loadscript(name, callback) {
var doc = document;
var node = doc.createElement('script');
node.charset = 'utf-8';
node.src = name + '.js';
node.id = 'loadjs-js-' + (Math.random() * 100).toFixed(3);
doc.body.appendChild(node);
node.onload = function() {
var param = modMap[name].callback();
callback(param);
}
}
function define(name, callback) {
modMap[name] = {};
modMap[name].callback = callback;
}
var loadjs = {
define: define,
use: use
};
root.define = define;
root.loadjs = loadjs;
root.modMap = modMap;
})(window);这个时候我们简单使用一下,我们在同级路径下新建a.js和b.js,内容仅仅为输出内容,如下:
define('a', function() {
console.log('a');
});define('b', function() {
console.log('b');
});使用主模块如下:
loadjs.use(['a','b'], function(a, b) {
console.log('main');
})这个时候我们打开浏览器可以发现a,b,main依次被打印出来了,如下:

我们使得a.js和b.js更复杂一些,可以放回方法,如下
define('a', function() {
console.log('a');
return {
add: function(a, b) {
return a + b;
}
}
});define('b', function() {
console.log('b');
return {
equil: function(a,b) {
return a===b;
}
}
});loadjs.use(['a','b'], function(a, b) {
console.log('main');
console.log(a.add(1,2));
console.log(b.equil(1,2));
})这个时候我们打开浏览器可以发现是正常输出的,如下:

这也就是说我们的功能目前来说是可用的。
我们紧接着来拓展一下define方法,目前来说是不支持依赖的,其实基本上来说是不可用的,那么接下来我们来拓展一下使得支持依赖.
遵循由简到繁的原则,我们先暂定所有的依赖都是独立的,也就是说我们先认为,一个模块不会被超过两个模块依赖,也就是说我们此时应该loadMod函数中同时去解析是否有依赖。
我们先修改一下最简单的define方法,只需要增加一下依赖属性即可,如下:
function define(name, deps, callback) {
modMap[name] = {};
modMap[name].deps = deps;
modMap[name].callback = callback;
}接下来我们考虑一下loadMod方法,前面我们非常简单就是在这里调用了脚本加载的函数,现在模块会对其他模块进行依赖了,所以我们在这里必须要调用use方法,并且这个模块的依赖属性作为第一个参数,因此在这之前我们必须先使用loadscript方法来确保脚本已经加载完毕,所以大致修改如下:
function loadMod(name, callback) {
loadscript(name, function() {
use(modMap[name].deps, function() {
})
});
}接着考虑一下loadscript方法,之前的loadscript方法加载完毕脚本之后执行了主模块的回调函数,然而目前loadscript方法的回调是一个对use方法的封装,因此直接执行callback就行了,修改为如下:
function loadscript(name, callback) {
var doc = document;
var node = doc.createElement('script');
node.charset = 'utf-8';
node.src = name + '.js';
node.id = 'loadjs-js-' + (Math.random() * 100).toFixed(3);
doc.body.appendChild(node);
node.onload = function() {
callback();
}
}接下来我们再考虑一下如何能够将一个模块的返回值传递给依赖他的模块,按照之前的思路主模块中我们使用一个回调函数,最后这个arguments是在loadscript中传递进去的,而现如今我们在loadMod方法和use方法有了循环调用,所以我们应该给最后一个没有依赖的函数一个出口,同时需要调用loadMod方法的callback方法,所以我们单独抽离一个execMod方法,如下:
function execMod(name, callback, params) {
var exp = modMap[name].callback.apply(null, params);
callback(exp);
}在loadMod方法中调用这个方法即可,如下:
function loadMod(name, callback) {
loadscript(name, function() {
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
});
}这里需要理解的是arguments,看似这个arguments为空,但是我们注意到我们之前已经在use方法中使用了apply方法将参数传递进来了,所以arguments就是相应的依赖,
此时整个内容如下:
(function(root){
var modMap = [];
function use(deps, callback) {
if(deps.length === 0) {
callback();
}
var depsLength = deps.length;
var params = [];
for(var i = 0; i < deps.length; i++) {
(function(j){
loadMod(deps[j], function(param) {
depsLength--;
params[j] = param;
if(depsLength === 0) {
callback.apply(null, params);
}
})
})(i)
}
}
function loadMod(name, callback) {
loadscript(name, function() {
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
});
}
function execMod(name, callback, params) {
console.log(callback);
var exp = modMap[name].callback.apply(null, params);
callback(exp);
}
function loadscript(name, callback) {
var doc = document;
var node = doc.createElement('script');
node.charset = 'utf-8';
node.src = name + '.js';
node.id = 'loadjs-js-' + (Math.random() * 100).toFixed(3);
doc.body.appendChild(node);
node.onload = function() {
callback();
}
}
function define(name, deps, callback) {
modMap[name] = {};
modMap[name].deps = deps;
modMap[name].callback = callback;
}
var loadjs = {
define: define,
use: use
};
root.define = define;
root.loadjs = loadjs;
root.modMap = modMap;
})(window);此时我们再次做一个测试,如下:
loadjs.use(['a'], function(a) {
console.log('main');
console.log(a.add(1,2));
})define('a', ['b'], function(b) {
console.log('a');
console.log(b.equil(1,2));
return {
add: function(a, b) {
return a + b;
}
}
});define('b', ['c'], function(c) {
console.log('b');
console.log(c.sqrt(4));
return {
equil: function(a,b) {
return a===b;
}
}
});define('c', [], function() {
console.log('c');
return {
sqrt: function(a) {
return Math.sqrt(a)
}
}
});此时运行结果如下:

结果正确,说明我们的实现是正确的。
接下来我们继续往下走,我们上面的实现是基于一个模块只会被一个模块依赖的,如果被多个模块依赖的时候我们需要防止的是这个被依赖的模块中的callback被多次调用,因此我们可以对每个模块使用一个loaded属性来标识出这个模块是否已经加载。
将define函数修改为以下内容:
function define(name, deps, callback) {
modMap[name] = {};
modMap[name].deps = deps;
modMap[name].loaded = true;
modMap[name].callback = callback;
}我们需要知道的是我们可以通过判断modMap中是否有相应的模块来判断是否模块加载,但是如果加载完毕再次使用use方法,则会再次执行该模块的代码,这是不对的,因此我们需要将每个模块的exports缓存起来,以便我们再次调用。同时我们思考一下一个模块在加载的过程中,会有几种状态呢?
可想而知,大概可以分为没有load、loading中、load完毕但代码没有执行完成、代码执行完成这几种状态,同样可以用属性来标识出。
没有load则执行loadscript方法、loading中则可以将callback推到一个数组中,等到loaded和代码执行完毕之后执行,而load完毕代码未执行完则执行代码,因此我们可以开始进行修改。
先修改define函数如下:
function define(name, deps, callback) {
modMap[name] = modMap[name] || {};
modMap[name].deps = deps;
modMap[name].status = 'loaded';
modMap[name].callback = callback;
modMap[name].oncomplete = modMap[name].oncomplete || [];
}将loadMod方法修改如下:
function loadMod(name, callback) {
console.log('modMap', modMap);
if(!modMap[name]) {
modMap[name] = {
status: 'loading',
oncomplete: []
};
console.log('initloading');
loadscript(name, function() {
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
});
} else if(modMap[name].status === 'loading') {
modMap[name].oncomplete.push(callback);
} else if (!modMap[name].exports){
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
}else {
callback(modMap[name].exports);
}
}代码执行完毕之后将结果添加到每个模块的exports中,同时需要执行oncomplete数组中的函数,所以将execmod修改为以下:
function execMod(name, callback, params) {
var exp = modMap[name].callback.apply(null, params);
modMap[name].exports = exp;
callback(exp);
execComplete(name);
}添加execComplete方法,如下:
function execComplete(name) {
for(var i = 0; i < modMap[name].oncomplete.length; i++) {
modMap[name].oncomplete[i](modMap[name].exports);
}
}此时整个代码如下:
(function(root){
var modMap = {};
function use(deps, callback) {
if(deps.length === 0) {
callback();
}
var depsLength = deps.length;
var params = [];
for(var i = 0; i < deps.length; i++) {
(function(j){
loadMod(deps[j], function(param) {
depsLength--;
params[j] = param;
if(depsLength === 0) {
callback.apply(null, params);
}
})
})(i)
}
}
function loadMod(name, callback) {
console.log('modMap', modMap);
if(!modMap[name]) {
modMap[name] = {
status: 'loading',
oncomplete: []
};
console.log('initloading');
loadscript(name, function() {
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
});
} else if(modMap[name].status === 'loading') {
modMap[name].oncomplete.push(callback);
} else if (!modMap[name].exports){
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
}else {
callback(modMap[name].exports);
}
}
function execMod(name, callback, params) {
var exp = modMap[name].callback.apply(null, params);
modMap[name].exports = exp;
callback(exp);
execComplete(name);
}
function execComplete(name) {
for(var i = 0; i < modMap[name].oncomplete.length; i++) {
modMap[name].oncomplete[i](modMap[name].exports);
}
}
function loadscript(name, callback) {
var doc = document;
var node = doc.createElement('script');
node.charset = 'utf-8';
node.src = name + '.js';
node.id = 'loadjs-js-' + (Math.random() * 100).toFixed(3);
doc.body.appendChild(node);
node.onload = function() {
callback();
}
}
function define(name, deps, callback) {
modMap[name] = modMap[name] || {};
modMap[name].deps = deps;
modMap[name].status = 'loaded';
modMap[name].callback = callback;
modMap[name].oncomplete = modMap[name].oncomplete || [];
}
var loadjs = {
define: define,
use: use
};
root.define = define;
root.loadjs = loadjs;
root.modMap = modMap;
})(window);
同样,再次进行测试,如下:
loadjs.use(['a', 'b'], function(a, b) {
console.log('main');
console.log(b.equil(1,2));
console.log(a.add(1,2));
})define('a', ['c'], function(c) {
console.log('a');
console.log(c.sqrt(4));
return {
add: function(a, b) {
return a + b;
}
}
});define('b', ['c'], function(c) {
console.log('b');
console.log(c.sqrt(9));
return {
equil: function(a,b) {
return a===b;
}
}
});define('c', [], function() {
console.log('c');
return {
sqrt: function(a) {
return Math.sqrt(a)
}
}
});此时结果输出如下:

结果符合我们预期。
是否允许用户选中文字,这在 防止用户copy内容 的时候非常有用,值有以下:
webkit浏览器很早开始就支持自定义滚动条,利用提供的伪元素即可实现,scrollbar提供的部分有
::-webkit-scrollbar { /* 1 */ } // 滚动条整体部分
::-webkit-scrollbar-button { /* 2 */ } // 滚动条两端的按钮
::-webkit-scrollbar-track { /* 3 */ } // 滚动条的轨道
::-webkit-scrollbar-track-piece { /* 4 */ } / 轨道除去小方块的部分
::-webkit-scrollbar-thumb { /* 5 */ } // 滚动条里的小方块
::-webkit-scrollbar-corner { /* 6 */ } // 横竖滚动条的交汇处
::-webkit-resizer { /* 7 */ } // 拖动调整元素大小的小控件
在浏览器中分别对应的部分是:
同时为这些元素提供了很多不同状态的伪类选择器,具体内容可看custom-scrollbars-in-webkit、scrollbar
可以按照以下步骤:
2.添加 -webkit-appearance:none:消除ios下的默认样式。
-webkit-appearance是用来改变按钮和其他控件的外观,使其外观类似于原生控件。
添加至少为1px的圆角 border-radius: 1px
如果是有模糊距离或者拓展的阴影尺寸设置,没有偏移值,如 box-shadow: 0 0 30px 300px #000,至少添加1px的偏移值
5.如果阴影尺寸设置得非常大,如 box-shadow: 0 0 0 999999px #000,同时又设置了border-radius 为四个相同的值,那么请确保这个值和圆角值的和不超过 2044px,或者保证四个值不是相同的。如:
不生效的设置:
box-shadow: 0px 0px 0px 99999px #000;
border-radius: 10px 10px 10px 10px;
生效的设置:
box-shadow: 0px 0px 0px 99999px #000;
border-radius: 10px 10px 10px 9.9999px;
生效的设置:
box-shadow: 0px 0px 0px 2034px #000;
border-radius: 10px 10px 10px 10px;
2044px 这个边界值我是在iphone 8 ios 11.4.1和iphone 6s plus ios 11.4.1 上测试均有这个问题。
Refs:
Box shadow spread bug in WebKit in iOS 7 on Retina iPads
-webkit-appearance —— webkit外观样式属性
在使用react开发中,重定向和404这种需求非常常见,使用React-router4.0可以使用Redirect进行重定向
最常用的就是用户登录之后自动跳转主页。
import React, { Component } from 'react';
import axios from 'axios';
import { Redirect } from 'react-router-dom';
class Login extends Component{
constructor(){
super();
this.state = {value: '', logined: false};
this.handleChange = this.handleChange.bind(this);
this.toLogin = this.toLogin.bind(this);
}
handleChange(event) {
this.setState({value: event.target.value})
}
toLogin(accesstoken) {
axios.post('yoururl',{accesstoken})
.then((res) => {
this.setState({logined: true});
})
}
render() {
if(this.props.logined) {
return (
<Redirect to="/user"/>
)
}
return (
<div>
<input type="text" value={this.state.value} onChange={this.handleChange} />
<a onClick={() => { this.toLogin(this.state.value) }}>登录</a>
</div>
)
}
}
export default Login;以上这个示例仅仅是将登录的状态作为组件的state使用和维护的,在实际开发中,是否登录的状态应该是全局使用的,因此这时候可能你会需要考虑使用redux等这些数据状态管理库,方便我们做数据的管理。这里需要注意的使用传统的登录方式使用cookie存储无序且复杂的sessionID之类的来储存用户的信息,使用token的话,返回的可能是用户信息,此时可以考虑使用sessionStorage、localStorage来储存用户信息(包括头像、用户名等),此时书写reducer时需要指定初始状态从存储中获取,如:
const LOGIN_SUCCESS = 'LOGIN_SUCCESS';
const LOGIN_FAILED = 'LOGIN_FAILED';
const LOGINOUT = 'LOGINOUT';
const Login = function(state, action) {
if(!state) {
console.log('state');
if(sessionStorage.getItem('usermsg')) {
return {
logined: true,
usermsg: JSON.parse(sessionStorage.getItem('usermsg'))
}
}
return {
logined: false,
usermsg: {}
}
}
switch(action.type) {
case LOGIN_SUCCESS:
return {logined: true,usermsg: action.usermsg};
case LOGIN_FAILED:
return {logined: false,usermsg:{}};
case LOGINOUT:
return {logined: false, usermsg: {}};
default:
return state
}
};
export default Login;指定404页面也非常简单,只需要在路由系统最后使用Route指定404页面的component即可
<Switch>
<Route path="/" exact component={Home}/>
<Route path="/user" component={User}/>
<Route component={NoMatch}/>
</Switch>当路由指定的所有路径没有匹配时,就会加载这个NoMatch组件,也就是404页面
相对布局可以让控件之间互相确定关系,保证屏幕的局部范围内几个控件之间的关系不受外部影响。
相对布局位置的属性有
android:layout_centerHorizontal 水平居中
android:layout_centerVertical 垂直居中
android:layout_centerInParent 相对于父元素完全居中
android:layout_alignParentBottom 贴紧父元素下边缘
android:layout_alignParentTop 贴紧父元素上边缘
android:layout_alignParentLeft 贴紧父元素左边缘
android:layout_alignParentRight 贴紧父元素右边缘
android:layout_below 在某元素下方
android:layout_above 在某元素上方
android:layout_toLeftOf 在某元素左边
android:layout_toRightOf 在某元素右边
android:layout_alignTop 元素上边缘与某元素的上边缘对齐
android:layout_alignBottom 元素下边缘与某元素的下边缘对齐
android:layout_alignRight 元素右边缘与某元素的右边缘对齐
android:layout_alignLeft 元素左边缘与某元素的左边缘对齐
android:layout_marginBottom 离某元素下边缘的距离
android:layout_marginLeft 离某元素左边缘的距离
android:layout_marginRight 离某元素右边缘的距离
android:layout_marginTop 离某元素上边缘的距离
JSONP的原理就不细说了,就是利用script可以跨域的特点来实现跨域,首先我们考虑一个最简单的jsonp,就是简简单单创建script标签,
添加url的功能,如下:
function jsonp(url) {
const script = document.createElement('script');
script.src = url;
script.type = 'text/javascript';
document.body.appendChild(script);
}此时我们使用服务端的代码如下:
const http = require('http');
const data = {'data':'hello'};
const url = require('url');
const queryString = require('querystring');
http.createServer(function(req, res) {
var params = url.parse(req.url);
console.log(params);
if(params.query && queryString.parse(params.query).callback) {
console.log(1231232);
const str = queryString.parse(params.query).callback + '(' + JSON.stringify(data) + ')';
return res.end(str)
}
res.end(JSON.stringify(data));
}).listen(5000);这是我们调用jsonp,假设我们只是想要alert出返回的数据,如下:
function msg(res) {
alert(res.data);
}
jsonp('http://localhost:5000?callback=msg');这时候我们运行代码可以发现已经正确弹出了相应的数据。
但是我们会发现这里的callback回调函数是一个全局的,这是不可取的,因此我们需要进行一些修改,将处理修改为一个局部的,我们可以将其作为一个回调函数来处理,如下:
function jsonp(url, callback) {
window.jsonpCallback = callback;
const script = document.createElement('script');
script.src = url + '?callback=jsonpCallback';
script.type = 'text/javascript';
document.body.appendChild(script);
}
jsonp('http://localhost:5000', function(res) {
alert(res.data);
});这时候我们会发现我们不再需要在url中声明相应的callback了,但是我们还是会发现一个问题,就是我们将所有的callback都设置成了一个全局变量,这样的原因是因为我们需要在数据请求完成之后调用这个方法,因此不得不设置为一个全局变量。但是当我们有多个请求,并且每个请求的处理都是不一样的时候,这个变量将会被覆盖。这是不行的,因此我们应该为每一次请求设置一个唯一且不会冲突的变量,因此增加一个生成callback名字的方法如下:
function generateJsonpCallback() {
return `jsonpcallback_${Date.now()}_${Math.floor(Math.random() * 100000)}`;
}
function jsonp(url, callback) {
const funcName = generateJsonpCallback();
window[funcName] = callback;
const script = document.createElement('script');
script.src = `${url}?callback=${funcName}`;
script.type = 'text/javascript';
document.body.appendChild(script);
}
jsonp('http://localhost:5000', function(res) {
alert(res.data);
});
jsonp('http://localhost:5000', function(res) {
const text = document.createTextNode(res.data);
document.body.appendChild(text);
});这时候我们会发现我们已经利用了一个类似于随机ID的形式完成了多次请求。
但是还是有一个问题大量的请求之后,window中会含有大量的全局变量,而且还有大量的script标签,这显然不是我们想要的,所以我们可以在请求完成之后删除变量和script标签。
function generateJsonpCallback() {
return `jsonpcallback_${Date.now()}_${Math.floor(Math.random() * 100000)}`;
}
function removeScript(id) {
document.body.removeChild(document.getElementById(id));
}
function removeFunc(name) {
delete window[name];
}
function jsonp(url, timeout = 3000, callback) {
const funcName = generateJsonpCallback();
window[funcName] = callback;
const script = document.createElement('script');
script.src = `${url}?callback=${funcName}`;
script.id = funcName;
script.type = 'text/javascript';
document.body.appendChild(script);
setTimeout(() => {
removeScript(funcName);
removeFunc(funcName);
}, timeout)
}
jsonp('http://localhost:5000', 3000, function(res) {
alert(res.data);
});
jsonp('http://localhost:5000', 3000, function(res) {
const text = document.createTextNode(res.data);
document.body.appendChild(text);
});我们通过将利用一个timeout时间定时为我们清除相应的script标签和全局变量就可以了,这个定时时间的作用类似于ajax的timeout时间。
我们所有的内容都是使用es6的,那为什么不使用Promise来处理呢,还要使用烦人的回调,接下来那就来Promise化吧。
function jsonp(url, options = {timeout:3000}) {
const timeout = options.timeout;
return new Promise((resolve, reject) => {
const funcName = generateJsonpCallback();
window[funcName] = (res) => {
resolve(res);
setTimeout(() => {
removeScript(funcName);
removeFunc(funcName);
}, timeout)
};
const script = document.createElement('script');
script.src = `${url}?callback=${funcName}`;
script.id = funcName;
script.type = 'text/javascript';
document.body.appendChild(script);
})
}调用只需要如下就可以了
jsonp('http://localhost:5000').then((res) => alert(res.data));
jsonp('http://localhost:5000').then((res) => {
const text = document.createTextNode(res.data);
document.body.appendChild(text);
});到目前为止,一个较为完整的jsonp就实现了,但是我们还是会觉得少了一些什么,相信你已经看出来了,那就是错误处理。
迄今为止,并没有测试过如果这个script标签加载不成功如何处理,判断资源加载失败,显然使用的是onerror事件,我们这就把他加上:
function jsonp(url, options = {timeout:3000}) {
const timeout = options.timeout;
let timeId;
return new Promise((resolve, reject) => {
const funcName = generateJsonpCallback();
window[funcName] = (res) => {
resolve(res);
timeId = setTimeout(() => {
removeScript(funcName);
removeFunc(funcName);
}, timeout)
};
const script = document.createElement('script');
script.src = `${url}?callback=${funcName}`;
script.id = funcName;
script.type = 'text/javascript';
document.body.appendChild(script);
script.onerror = () => {
reject(new Error(`fetch ${url} failed`));
removeScript(funcName);
removeFunc(funcName);
if(timeId) clearTimeout(timeId);
}
})
}我们可以测试一下,输入一个不存在的url:
jsonp('http://localhost:7000').then((res) => alert(res.data));可以发现这时正常处理错误了,可以在控制台看到相应的url获取失败,至此,完工;
至此所有的代码简单封装如下:
(function(global){
function generateJsonpCallback() {
return `jsonpcallback_${Date.now()}_${Math.floor(Math.random() * 100000)}`;
}
function removeScript(id) {
document.body.removeChild(document.getElementById(id));
}
function removeFunc(name) {
delete global[name];
}
function jsonp(url, options = {timeout:3000}) {
const timeout = options.timeout;
let timeId;
return new Promise((resolve, reject) => {
const funcName = generateJsonpCallback();
global[funcName] = (res) => {
resolve(res);
timeId = setTimeout(() => {
removeScript(funcName);
removeFunc(funcName);
}, timeout)
};
const script = document.createElement('script');
script.src = `${url}?callback=${funcName}`;
script.id = funcName;
script.type = 'text/javascript';
document.body.appendChild(script);
script.onerror = () => {
reject(new Error(`fetch ${url} failed`));
removeScript(funcName);
removeFunc(funcName);
if(timeId) clearTimeout(timeId);
}
})
}
window.jsonp = jsonp;
})(window);测试代码如下:
jsonp('http://localhost:5000').then((res) => alert(res.data));
jsonp('http://localhost:5000').then((res) => {
const text = document.createTextNode(res.data);
document.body.appendChild(text);
});
jsonp('http://localhost:7000').then((res) => alert(res.data));在上一篇文章中,我们已经基本完成了模块加载器的基本功能,接下来来完成一下路径解析的问题。
在之前的功能中,我们所有的模块默认只能放在同级目录下,而在实际项目中,我们的js很有可能位于多个目录,甚至是CDN中,所以现在这种路径解析是非常不合理的,因此我们需要将每个模块的name转化为一个绝对路径,这样才是一个比较完美的解决方案。
借鉴部分requirejs的**,我们可以通过配置来配置一个baseUrl,当没有配置这个baseUrl的时候,我们认为这个baseUrl就是html页面的地址,所以我们需要对外暴露一个config方法,如下:
var cfg = {
baseUrl: location.href.replace(/(\/)[^\/]+$/g, function(s, s1){
return s1
})
}
function config(obj) {
obj && merge(cfg, obj);
}
function merge(obj1, obj2) {
if(obj1 && obj2) {
for(var key in obj2) {
obj1[key] = obj2[key]
}
}
}
loadjs.config = config;上面的代码中,我们定义了一个基本的全局配置对象cfg、一个用来合并对象属性的merge方法和一个用来支持配置的config方法。但是显然这个时候配置baseUrl的时候需要使用一个绝对路径。但是在实际中我们可能更会使用的是一个相对路径,例如../或者./或者/这个需求是非常正常的,因此我们需要也支持这些实现。首先我们先来写这些的匹配的正则表达式,为了之后的使用我们同时也写出检测完整路径(包括http、https和file协议)
var fullPathRegExp = /^[(https?\:\/\/) | (file\:\/\/\/)]/;
var absoPathRegExp = /^\//;
var relaPathRegExp = /^\.\//;
var relaPathBackRegExp = /^\.\.\//;同时将这些判断写进一个outputPath方法中。
function outputPath(baseUrl, path) {
if (relaPathRegExp.test(path)) {
if(/\.\.\//g.test(path)) {
var pathArr = baseUrl.split('/');
var backPath = path.match(/\.\.\//g);
var joinPath = path.replace(/[(^\./)|(\.\.\/)]+/g, '');
var num = pathArr.length - backPath.length;
return pathArr.splice(0, num).join('/').replace(/\/$/g, '') + '/' +joinPath;
} else {
return baseUrl.replace(/\/$/g, '') + '/' + path.replace(/[(^\./)]+/g, '');
}
} else if (fullPathRegExp.test(path)) {
return path;
} else if (absoPathRegExp.test(path)) {
return baseUrl.replace(/\/$/g, '') + path;
} else {
return baseUrl.replace(/\/$/g, '') + '/' + path;
}
}这里可能需要关注的一个相对路径的问题,因为有可能是需要返回上一级目录的,即形如./../../的形式,因此也应该处理这种情况。另外之所以在这里都是要匹配baseUrl的最后一个斜杠/,是因为提供的这个很有可能带有斜杠,也很有可能不带斜杠。
最后使用config方法配置的时候,通过判断提供的path来做相应的处理,修改config方法如下:
function config(obj) {
if(obj){
if(obj.baseUrl) {
obj.baseUrl = outputPath(cfg.baseUrl, obj.baseUrl);
}
merge(cfg, obj);
}
}最后我们修改一下每个模块名为这个模块的绝对路径,这样我们就不必再修改loadScript方法了,我们在loadMod方法中修改name参数,增加代码:
name = outputPath(cfg.baseUrl, name);我们再来优化一下,毕竟如果我们每一个模块都要使用./或者../之类的,很多模块下这是要崩溃的,所以我们依旧是借鉴requirejs的方法,允许使用config方法来配置path属性这个问题,当我们配置了一个app的path之后我们认为在模块引用的时候,如果遇到app开头则需要替换这个path。
所以先来看config方法修改如下:
function config(obj) {
if(obj){
if(obj.baseUrl) {
obj.baseUrl = outputPath(cfg.baseUrl, obj.baseUrl);
}
if(obj.path) {
var base = obj.baseUrl || cfg.baseUrl;
for(var key in obj.path) {
obj.path[key] = outputPath(base, obj.path[key]);
}
}
merge(cfg, obj);
}
}因此在loadMod方法中同时也应该检测cfg.path中是否含有这个属性,这时候会比较复杂,因此单独抽出为一个函数来说是比较好的处理方式,单独抽出为一个replaceName方法,如下:
function replaceName(name) {
if(fullPathRegExp.test(name) || absoPathRegExp.test(name) || relaPathRegExp.test(name)) {
return outputPath(cfg.baseUrl, name);
} else {
var prefix = name.split('/')[0] || name;
if(cfg.path[prefix]) {
if(name.split('/').length === 0) {
return cfg.path[prefix];
} else {
var endPath = name.split('/').slice(1).join('/');
return outputPath(cfg.path[prefix], endPath);
}
}
}
}这样,我们只需要在loadMod方法中调用这个方法就可以了。
我们再优化一下,我们完全可以在define中将name替换为一个绝对路径,同时在主模块加载依赖的时候,将依赖替换为绝对路径即可,因此我们可以在定义模块的时候就将这个这个路径替换好。
不过这个时候我们需要明白的是,在定义模块的时候是一个类似单词,而声明依赖的时候则有可能含有路径,如何在模块声明的时候正确解析路径呢?
很明显我们可以使用一个变量来做这个事情,这个变量存储着所有模块名和依赖这个模块时的声明。那么我们就应该在use方法加载模块的时候将这些变量名添加到这个变量名之下,之后再define中进行转化,那么最后我们的整个代码如下:
(function(root){
var modMap = {};
var moduleMap = {};
var cfg = {
baseUrl: location.href.replace(/(\/)[^\/]+$/g, function(s, s1){
return s1
}),
path: {
}
};
var fullPathRegExp = /^[(https?\:\/\/) | (file\:\/\/\/)]/;
var absoPathRegExp = /^\//;
var relaPathRegExp = /^\.\//;
var relaPathBackRegExp = /^\.\.\//;
function outputPath(baseUrl, path) {
if (relaPathRegExp.test(path)) {
if(/\.\.\//g.test(path)) {
var pathArr = baseUrl.split('/');
var backPath = path.match(/\.\.\//g);
var joinPath = path.replace(/[(^\./)|(\.\.\/)]+/g, '');
var num = pathArr.length - backPath.length;
return pathArr.splice(0, num).join('/').replace(/\/$/g, '') + '/' +joinPath;
} else {
return baseUrl.replace(/\/$/g, '') + '/' + path.replace(/[(^\./)]+/g, '');
}
} else if (fullPathRegExp.test(path)) {
return path;
} else if (absoPathRegExp.test(path)) {
return baseUrl.replace(/\/$/g, '') + path;
} else {
return baseUrl.replace(/\/$/g, '') + '/' + path;
}
}
function replaceName(name) {
if(fullPathRegExp.test(name) || absoPathRegExp.test(name) || relaPathRegExp.test(name) || relaPathBackRegExp.test(name)) {
return outputPath(cfg.baseUrl, name);
} else {
var prefix = name.split('/')[0] || name;
if(cfg.paths[prefix]) {
if(name.split('/').length === 0) {
return cfg.paths[prefix];
} else {;
var endPath = name.split('/').slice(1).join('/');
return outputPath(cfg.paths[prefix], endPath);
}
} else {
return outputPath(cfg.baseUrl, name);
}
}
}
function fixUrl(name) {
return name.split('/')[name.split('/').length-1]
}
function config(obj) {
if(obj){
if(obj.baseUrl) {
obj.baseUrl = outputPath(cfg.baseUrl, obj.baseUrl);
}
if(obj.paths) {
var base = obj.baseUrl || cfg.baseUrl;
for(var key in obj.paths) {
obj.paths[key] = outputPath(base, obj.paths[key]);
}
}
merge(cfg, obj);
}
}
function merge(obj1, obj2) {
if(obj1 && obj2) {
for(var key in obj2) {
obj1[key] = obj2[key]
}
}
}
function use(deps, callback) {
if(deps.length === 0) {
callback();
}
var depsLength = deps.length;
var params = [];
for(var i = 0; i < deps.length; i++) {
moduleMap[fixUrl(deps[i])] = deps[i];
deps[i] = replaceName(deps[i]);
(function(j){
loadMod(deps[j], function(param) {
depsLength--;
params[j] = param;
if(depsLength === 0) {
callback.apply(null, params);
}
})
})(i)
}
}
function loadMod(name, callback) {
if(!modMap[name]) {
modMap[name] = {
status: 'loading',
oncomplete: []
};
loadscript(name, function() {
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
});
} else if(modMap[name].status === 'loading') {
modMap[name].oncomplete.push(callback);
} else if (!modMap[name].exports){
use(modMap[name].deps, function() {
execMod(name, callback, Array.prototype.slice.call(arguments, 0));
})
}else {
callback(modMap[name].exports);
}
}
function execMod(name, callback, params) {
var exp = modMap[name].callback.apply(null, params);
modMap[name].exports = exp;
callback(exp);
execComplete(name);
}
function execComplete(name) {
for(var i = 0; i < modMap[name].oncomplete.length; i++) {
modMap[name].oncomplete[i](modMap[name].exports);
}
}
function loadscript(name, callback) {
var doc = document;
var node = doc.createElement('script');
node.charset = 'utf-8';
node.src = name + '.js';
node.id = 'loadjs-js-' + (Math.random() * 100).toFixed(3);
doc.body.appendChild(node);
node.onload = function() {
callback();
}
}
function define(name, deps, callback) {
if(moduleMap[name]) {
name=moduleMap[name]
}
name = replaceName(name);
deps = deps.map(function(ele, i) {
return replaceName(ele);
});
modMap[name] = modMap[name] || {};
modMap[name].deps = deps;
modMap[name].status = 'loaded';
modMap[name].callback = callback;
modMap[name].oncomplete = modMap[name].oncomplete || [];
}
var loadjs = {
define: define,
use: use,
config: config
};
root.define = define;
root.loadjs = loadjs;
root.modMap = modMap;
})(window);
我们进行一下测试:
loadjs.config({
baseUrl:'./static',
paths: {
app: './app'
}
});
loadjs.use(['app/b', 'a'], function(b) {
console.log('main');
console.log(b.equil(1,2));
})
define('a', ['app/c'], function(c) {
console.log('a');
console.log(c.sqrt(4));
return {
add: function(a, b) {
return a + b;
}
}
});
define('c', ['http://ce.sysu.edu.cn/hope/Skin/js/jquery.min.js'], function() {
console.log('c');
return {
sqrt: function(a) {
return Math.sqrt(a)
}
}
});
define('b', ['c'], function(c) {
console.log('b');
console.log(c.sqrt(9));
return {
equil: function(a,b) {
return a===b;
}
}
});
打开浏览器我们可以看到正常输出,如下:

说明我们的所做的路径解析工作是正确的。
作为一个UI库,肯定是需要全局使用的,因此必然需要使用插件的方式。即 Vue.use(My-UI) 。因此全局来说应该是注册为插件的形式。一个插件作为一个对象时需要提供install函数,我们可以在这个函数中对我们所有的 component 进行全局注册,这样就不必要在在每次使用组件的时候都 import
了,即:
module.export = {
install: function (Vue, opts = {}) {
for (const item in components) {
if (components[item].name) {
Vue.component(components[item].name, components[item])
}
}
// ....
}
}很可能一部分用户只是想要使用其中的一部分组件,当然用户可以每个单文件中使用 import 的方式,之后声明为 components ,但是我们需要考虑到一些组件很可能用户会重复使用到,这些 组件可以作为全局组件 应该是更好的设计,所以我们同样可以为 单个组件 添加一个 install 方法,以便于以 插件 的形式注册为全局组件,即设计为:
import MyUiComponent from './src/myUiComponent.vue'
MyUiComponent.install = function(Vue) {
Vue.component(MyUiComponent.name, MyUiComponent)
}
export default MyUiComponent数据验证确保只有有效的数据才能存入数据库,在模型中做验证是最有保障的,只有通过验证的数据才能存入数据库。数据验证和使用的数据库种类无关,终端用户也无法跳过,而且容易测试和维护。
数据验证的方式主要有数据库原生约束、客户端验证和控制器层验证:
数据库约束无法兼容多种数据库,难以测试和维护,但是如果其他应用也要使用这个数据库,最好能够在数据库层做一些约束。
客户端验证可靠性不高,但是和其他验证方式结合可以提供实时反馈
控制器层验证不灵便,难以测试和维护,只要可能就应该保证控制器的代码简洁,这样才有利于长远发展
Active Record 对象分为两种,一种在数据库中有对应记录,一种没有,新建对象还不属于数据库,只有调用了 save 方法后,才会存入数据库,可以使用 new_record? 方法判断是否存入数据库,未存入则返回 true ,存入则返回 false
新建并保存会执行 SQL INSERT 操作,更新记录会执行 SQL UPDATE 操作,一般情况下,数据验证发生在执行这些SQL语句之前,如果验证失败,对象会被标记为无效, Active Record 不会向数据库发送指令。
以下方法会触发数据验证:
create
create!
save
save!
update
update!
炸弹方法会在验证失败后抛出异常。
以下方法会跳过验证,不管验证是否通过都会把对象存入数据库:
decrement!
decrement_counter
increment!
increment_counter
toggle!
touch
update_all
update_attribute
update_column
update_columns
update_counters
同时,使用 save 方法时,如果传入 validate: false 参数,也会跳过验证。
同时,也可以使用 valid? 方法自己执行验证,如果对象上没有错误则返回 true ,否则返回 false,invalid? 方法则相反。执行验证之后,错误可以通过实例方法 errors.message 获取,这个方法返回一个错误集合,如果为空,则说明对象是有效的。需要注意的是,如果没有验证数据,这个方法返回的也是一个空集合。
如果要验证某个属性是否有效,可以使用 errors[:attribute] ,这返回一个包含了所有错误的数组,如果没有错误则返回空数组,这个方法和 invalid? 方法不一样,这个方法不会验证整个对象,只会检查某个属性是否有错。
可以使用 errors.details[:attribute] 检查到底是哪个验证导致属性无效,这个方法返回一个由散列组成的数组。
辅助方法可以直接在模型中使用,这些方法提供了常用的验证规则,验证失败就会向对象的 errors 集合中添加一个消息。
每个辅助方法都可以接受任意个属性名,所以一行代码可以在多个属性上做同一种验证。
检查表单提交时,用户界面中的复选框是否被选中,一般用来要求用户接受应用的服务条款、确保用户阅读了一些文本等。
class Person < ApplicationRecord
validates :terms_of_service, acceptance: true
end如果模型与其他模型有关联,而且关联的模型也需要验证,就是用这个方法,保存对象时,会在相关联的每个对象上调用 valid? 方法。
class Library < ApplicationRecord
has_many :books
validates_associated :books
end不要在关联的两端使用,这样会造成无限的循环
检查两个文本字段的值是否完全相同,如确认邮件地址或者密码。这个验证创建一个虚拟属性,其名字为要验证的属性名后加 _confirmation 。
class Person < ApplicationRecord
validates :email, confirmation: true
end在视图模板中视图可以如下:
<%= text_field :person, :email %>
<%= text_field :person, :email_confirmation %>因为只有在 email_confirmation 值不是 nil 时才会验证,所以需要添加存在性验证
class Person < ApplicationRecord
validates :email, confirmation: true
validates :email_confirmation, presence: true
end使用 :case_sensitive 选项可以说明是否区分大小写,这个选项默认值是true
class Person < ApplicationRecord
validates :email, confirmation: {case_sensitive: false}
end这个方法检查属性的值是否不在指定的集合中,集合可以是任何一种可枚举的对象
class Account < Application
validates :subdomain, exclusion: {in: %w(www us ca jp), message: "%{value} is reserved"}
endin 选项设置哪些值不能作为属性的值,in 的别名是 with
这个方法检查属性的值是否匹配 :with 选项指定的正则表达式。
class Product < ApplicationReocrd
validates :legacy_code, formate: {with: /\A[a-zA-Z]+\z/, message: "only allows letters"}
end这个方法检查属性的值是否在指定的集合中,集合可以是任何一种可枚举的对象
class Coffee < ApplicationRecord
validates :size, inclusion: {in: %w(small mediun large), message: "%{value} is not a valid size"}
end这个方法验证属性值的长度,有多个选项
class Person < ApplicationRecord
validates :name, length: {minimum: 2}
validates :bio, length: {maximum: 500}
validates :password, length: {in: 6..20}
validates :registration_number, length:{is: 6}
end可用的长度约束选项有:
:minimum:最短长度
:maximum:最长长度
:in 或者 :within:长度范围
:is:等于该长度
定制错误消息可以使用 :wrong_length 、:too_long 、:too_short 选项,%{count} 表示长度限制的值
class Person < ApplicationRecord
validates :bio, length: {maximum: 1000, too_long: "%{count} characters is the maximum allowed"}
end检查属性是否只包含数字,默认匹配的值是可选的正负符号后加整数或浮点数,如果只接受整数,把 :only_integer 选项设置为 true,否则会使用Float把值转换为数字。
class Player < ApplicationRecord
validates :points, numericality: true
validates :games_played< numericality: {only_integer: true}
end除此之外,这个方法还可指定以下选项:
:greater_than :属性值需大于 >
:greater_than_or_equal_to :>=
:equal_to :=
:less_than :<
:less_than_or_equal_to :<=
:other_than :!=
:odd :必须为奇数
:even :必须为偶数
此方法默认不接受 nil 值,可以使用 allow_nil: true 选项允许接受 nil
检查属性是否为非空值,方法调用 blank? 方法检查是否为 nil 或空字符串
class Person < ApplicationRecord
validates :name, :login, :email, presence: true
end验证属性值是否为空,使用 present? 方法检查是否为 nil 或空字符串
class Person < ApplicationRecord
validates :name, :login, :email, absence: true
end这个方法在保存对象前验证属性值是否唯一,这个方法不会在数据库中创建唯一性约束,所以有可能两次数据库连接创建的记录具有相同的值,所以最好在数据库字段上建立唯一性约束。
class Account < ApplicationRecord
validates :email, uniqueness: true
end这个验证会在模型对应的表中执行一个 SQL 查询,检查现有的记录中该字段是否已经出现过相同的值。
可以使用 :case_sensitive 选项
class Person < ApplicationRecord
validates :name, uniqueness: {case_sensitive: false}
end这个方法把记录交给其他类做验证。
class GoodnessValidator < ActiveModel::Validator
def validate(record)
if record.first_name == "Evil"
record.errors[:base] << "This person is evil"
end
end
end
class Person < ApplicationRecord
validates_with GoodnessValidator
end这个方法的参数是一个类或者一组类。
这个方法使用代码块中的代码验证属性,需要在代码块中定义验证方式。
class Person < ApplicationRecord
validates_each :name, :surname do |record, attr, value|
record.errors.add(attr, 'must start with upper case') if value =~/\A[[:lower:]]/
end
end代码块的参数是记录、属性名和属性值。
允许 nil 值,如果要验证的值是 nil 就跳过验证
class Coffee < ApplicationRecord
validates :size, inclusion: {in: %w(small medium large), message: "%{value} is not a valid size"}, allow_nil: true
end与上面方法类似,使用 blank? 方法判断,空字符串和nil时跳过验证
添加错误消息,消息中可以包含 %{value} 、 %{attribute}、%{model}
指定验证时机,默认都在保存时验证,使用使用
on: :create :只在创建时验证
on: :update:只在更新时验证
class Person < ApplicationRecord
# 更新时允许电子邮件地址重复
validates :email, uniqueness: true, on: :create
# 创建记录时允许年龄不是数字
validates :age, numericality: true, on: :update
# 默认行为(创建和更新时都验证)
validates :name, presence: true
end使用严格验证模式,对象无效时抛出异常
class Person < ApplicationRecord
validates :name, presence: { strict: true }
end
Person.new.valid? # => ActiveModel::StrictValidationFailed: Name can't be blank使用 :if 和 :unless 选项只有满足特定条件才验证,值可以是符号、字符串、Proc或数组。
选项为符号时,表示验证之前执行对应的方法。这是最常用的设置方法。
class Order < ApplicationRecord
validates :card_number
end自定义验证类继承自 ActiveModel::Validator,必须实现validate方法,参数是要验证的记录
class MyValidator < ActiveModel::Validator
def validate(record)
unless record.name.starts_with? 'X'
record.errors[:name] << 'Need a name starting with X please!'
end
end
end
class Person
include ActiveModel::Validations
validates_with MyValidator
endActiveModel::Errors 的实例包含所有的错误,键是每个属性的名称,只是一个数组,包含错误消息字符串。
errors[] 用于获取某个属性上的错误消息
errors.add 用于手动添加某属性的错误消息,参数是属性和错误消息
errors.details 返回错误详情
errors.clear 清楚errors集合中的所有消息
errors.size 返回错误消息总数。
安装
npm i -g rollup打包成文件
rollup src/main.js -o bundle.js -f cjs等价于
rollup src/main.js -f cjs > bundle.js需要注意的是参数 -f 是 --output.format 的缩写,用来指定 bundle 的类型,有以下选项:
amd:amd规范
cjs:CommonJS规范
es:es规范
iife:立即执行函数
umd:umd规范(语法糖)默认文件名称为 rollup.config.js,
export default{
input: "src/main.js",
output: {
file: "bundle.js",
format: "cjs"
}
}打包:
rollup -c等价于
rollup --config通过在配置文件中使用 plugins 字段添加插件。
如:
使用 rollup-plugin-json 插件来处理json文件
使用 rollup-plugin-node-resolve 插件来处理外部模块(rollup默认无法处理外部模块,也就是说无法解析打包从npm上下载使用的包,使用这个插件可以帮助我们使用)
使用 rollup-plugin-commonjs 来处理导入的commonjs模块的包(rollup默认只支持ES6模块的包)
使用 rollup-plugin-babel 来支持babel
import json from 'rollup-plugin-json'
import resove from 'rollup-plugin-node-resolve'
import babel from 'rollup-plugin-babel'
export default {
input: 'src/main.js',
output: {
file: 'bundle.js',
format: 'umd',
name: 'roll',
},
plugins: [
json(),
resove(),
babel({
exclude: 'node_modules/**'
})
]
}有时候一些外部引用的库我们并不想一并打包在我们的库中,如:lodash、react,可以在配置文件中使用 external 字段来告诉rollup不要将这些库打包
export default {
// ...
external: ['lodash']
}rollup提供了JavaScript接口以便于通过Node.js来使用。
rollup.rollup
此函数范湖一个Promise,解析一个bundle对象,此对象带有不同的属性与方法,官网示例:
rollup.watch
检测磁盘上单个模块改变时,重新构建bundle,使用命令行时带上 --watch 参数,这个函数会在内部使用。
首先我们需要知道的是dayjs需要打包的文件有dayjs核心库、dayjs的plugins、dayjs的本地化文件三类文件。
从 package.json 文件中看到dayjs的build script实际上执行的build文件夹下的的 index.js 文件。
在 build 文件夹下有 index.js 文件和 rollup.config.js 两个文件,很显然,这个 rollup.config.js 文件就是rollup的配置文件。
这个配置文件如下:
const babel = require('rollup-plugin-babel')
const uglify = require('rollup-plugin-uglify')
module.exports = (config) => {
const { input, fileName, name } = config
return {
input: {
input,
external: [
'dayjs'
],
plugins: [
babel({
exclude: 'node_modules/**'
}),
uglify()
]
},
output: {
file: fileName,
format: 'umd',
name: name || 'dayjs',
globals: {
dayjs: 'dayjs'
}
}
}
}这里导出的是一个接受config参数的函数,可以想到这个函数是会在 index.js 中使用的,并且从解构赋值中可以知道config参数允许外部自定义input、输出的文件名fileName、umd使用的模块名。
这里使用了 rollup-plugin-babel 来配合使用babel,使用 rollup-plugin-uglify 插件来压缩js文件。
接下来看下 index.js 文件内容:
const rollup = require('rollup')
const configFactory = require('./rollup.config')
const fs = require('fs')
const util = require('util')
const path = require('path')
const { promisify } = util
const promisifyReadDir = promisify(fs.readdir)
const formatName = n => n.replace(/\.js/, '').replace('-', '_')
async function build(option) {
const bundle = await rollup.rollup(option.input)
await bundle.write(option.output)
}
(async () => {
try {
const locales = await promisifyReadDir(path.join(__dirname, '../src/locale'))
locales.forEach((l) => {
build(configFactory({
input: `./src/locale/${l}`,
fileName: `./locale/${l}`,
name: `dayjs_locale_${formatName(l)}`
}))
})
const plugins = await promisifyReadDir(path.join(__dirname, '../src/plugin'))
plugins.forEach((l) => {
build(configFactory({
input: `./src/plugin/${l}`,
fileName: `./plugin/${l}`,
name: `dayjs_plugin_${formatName(l)}`
}))
})
build(configFactory({
input: './src/index.js',
fileName: './dayjs.min.js'
}))
} catch (e) {
console.error(e) // eslint-disable-line no-console
}
})()可以看到作者将打包功能专门抽出来作为一个 build 函数,之后读取plugin、locale文件夹中的文件然后每个文件单独打包,之后打包核心模块文件dayjs文件,在这里使用 JavaScript API的作用非常明显就是实现了一个命令打包多个文件。
hyperapp的目的只有一个就是打包src/index.js文件,因此功能也不要太强大,所以作者直接使用命令行即可。
5.完整参数配置
rollup完整参数可以在官网查询https://rollupjs.org/guide/zh#big-list-of-options
在这篇文章中我们开始利用我们之前所学搭建一个简易的React开发环境,用以巩固我们之前学习的Webpack知识。首先我们需要明确这次开发环境需要达到的效果:1、能够编译JSX语言 2、css样式使用Sass开发 3.能够将基础的ES6转化为ES5 4.能够使用ESLint在开发的时候为我们做代码风格审查
首先,安装基本使用的webpack、webpack-dev-server
npm i webpack webpack-dev-server -D为了可以生成一个基本的页面我们使用html-webpack-plugin,为了方便我们定制,我们自己在src定义一个html文件,使用template指定这个文件。
安装html-webpack-plugin
npm i html-webpack-plugin -D在src文件夹下生成一个html文件,内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div id="app"></div>
</body>
</html>在webpack.config.js中写入以下内容作为基本的设置:
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const webpack = require('webpack');
const config = {
entry: './src/main.js',
output: {
filename: 'bundle-[hash].js',
path: path.join(__dirname, 'dist')
},
devtool:'inline-source-map',
devServer: {
contentBase: './dist',
hot: true
},
plugins: [
new HtmlWebpackPlugin({
template: './src/index.html'
}),
new webpack.HotModuleReplacementPlugin()
]
}
module.exports = config;此时在命令行中运行以下命令可以看到一切正常运行,尽管目前在浏览器上还没有任何效果:
webpack-dev-server --open在React开发的时候我们使用jsx语言和es6,因此需要使用babel对我们的开发进行一个编译,使用babel即可:
安装babel-loader:
npm i babel-loader -D为了使用这个babel-loader,我们需要安装babel-core(当我们需要以编程方式使用babel时就需要安装这个):
npm i babel-core -D为了编译es6和jsx需要安装相应的preset,即需要安装babel-preset-react和babel-preset-es2015:
npm i babel-preset-es2015 babel-preset-react -D在webpack的配置文件中引入babel-loader:
const config = {
//....
module:{
rules: [
{
test: /\.(js|jsx)$/,
use:[
'babel-loader'
]
}
]
}
// ......
}
module.exports = config;配置babel的配置文件,在.babelrc文件中写入以下内容:
{
"presets": [
"es2015",
"react"
]
}此时我们测试一下是否可以正常编译jsx和es2015,安装react和react-dom,同时在src中的main.js和App.js写入部分内容
npm i react react-dom -Smain.js
import ReactDOM from 'react-dom';
import React from 'react';
import App from './App';
ReactDOM.render(<App />, document.getElementById('app'));App.js
import React from 'react';
export default function () {
return (
<div className="header">
React
</div>
);
}在命令行运行命令,可以发现浏览器已经正常显示了,也就是说正常编译了jsx和es6
webpack-dev-server --open此时,整个webpack.config.js文件内容如下:
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const webpack = require('webpack');
const config = {
entry: './src/main.js',
output: {
filename: 'bundle-[hash].js',
path: path.join(__dirname, 'dist')
},
devtool:'inline-source-map',
devServer: {
contentBase: './dist',
hot: true
},
module: {
rules: [
{
test: /\.(js|jsx)/,
use:[
'babel-loader'
]
}
]
},
plugins: [
new HtmlWebpackPlugin({
title:'React简易开发环境',
template: './src/index.html'
}),
new webpack.HotModuleReplacementPlugin()
]
}
module.exports = config;编译Sass和之前文章提到的一样,需要使用style-loader、css-loader、sass-loader,首先进行安装:
npm i style-loader css-loader sass-loader -D因为sass-loader是依赖node-sass的,同时因为sass-loader的uri是相对于output的,因此需要使用resolve-url-loader
npm i node-sass resolve-url-loader -D在webpack.config.js中进行配置:
const config = {
// ......
module: {
rules: [
//......
{
test: /\.(sass|scss|css)/,
use: [
"style-loader",
"css-loader",
"resolve-url-loader",
"sass-loader?sourceMap"
]
}
]
},
// ......
}
module.exports = config;在src文件夹中新建一个名为sass的文件夹,同时新建_header.scss、_variablers.scss、main.scss,三个文件内容分别为:
_variablers.scss
$bgColor: red;
$fontColor: #fff;_header.scss
.header{
background: $bgColor;
color: $fontColor;
height:300px;
}main.scss
@import "variables"
,"header"
在main.js中引入main.scss文件:
import './sass/main.scss';此时再次运行命令,可以在浏览器中看到header部分的样式已经生效。
此时整个webpack.config.js文件内容如下:
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const webpack = require('webpack');
const config = {
entry: './src/main.js',
output: {
filename: 'bundle-[hash].js',
path: path.join(__dirname, 'dist')
},
devtool:'inline-source-map',
devServer: {
contentBase: './dist',
hot: true
},
module: {
rules: [
{
test: /\.(js|jsx)/,
use:[
'babel-loader'
]
},{
test: /\.(sass|scss|css)/,
use: [
"style-loader",
"css-loader",
"resolve-url-loader",
"sass-loader?sourceMap"
]
}
]
},
plugins: [
new HtmlWebpackPlugin({
title:'React简易开发环境',
template: './src/index.html'
}),
new webpack.HotModuleReplacementPlugin()
]
}
module.exports = config;使用eslint首先安装eslint和eslint-loader:
npm i eslint eslint-loader -D为了让eslint支持es6我们需要将eslint的解析器修改为babel-eslint,使用npm安装
npm i babel-eslint -D在webpack.config.js中配置eslint-loader
const config = {
// ......
module: {
rules: [
{
test: /\.(js|jsx)/,
use:[
'babel-loader',
'eslint-loader'
]
}
]
},
// ......
}
module.exports = config;新建一个eslint的配置文件.eslintrc.js:
module.exports = {
"parserOptions": {
"ecmaVersion": 6,
"sourceType": "module",
"ecmaFeatures": {
"jsx": true
}
},
"env": {
"browser": true,
"node": true
},
"parser": "babel-eslint"
};此时运行命令行会发现正常运行,原因是eslint默认所有规则都是禁用的,我们在.eslintrc.js中添加一条简单的禁用console的规则,当出现console时,将会报warning
module.exports = {
"parserOptions": {
"ecmaVersion": 6,
"sourceType": "module",
"ecmaFeatures": {
"jsx": true
}
},
"env": {
"browser": true,
"node": true
},
"parser": "babel-eslint",
"rules": {
"no-console": 1
}
};此时再次运行命令,可以发现以下界面,控制台已经很明确的告诉我们,我们的App.js中出现了console,说明此时eslint已经生效。

但是在一个项目中我们如果配置每一个规则会显得非常麻烦,因此我们选择使用airbnb的规则,使用npm安装:
npm i eslint-config-airbnb -D安装完成之后可以发现控制台告诉我们需要安装eslint-plugin-jsx-a11y、eslint-plugin-import、eslint-plugin-react,同时安装时应该大于或者等于某个版本号:

npm i eslint-plugin-jsx-a11y@5.1.1 eslint-plugin-import@2.7.0 eslint-plugin-react@7.1.0 -D在.eslintrc.js文件中使用extends指定继承自airbnb的配置,如下:
module.exports = {
"parserOptions": {
"ecmaVersion": 6,
"sourceType": "module",
"ecmaFeatures": {
"jsx": true
}
},
"extends": "airbnb",
"env": {
"browser": true,
"node": true
},
"parser": "babel-eslint",
"rules": {
"no-console": 1
}
};此时,再次运行命令之后可以发现,在命令行和控制台中都报出了我们的代码风格问题,如下:
airbnb中的所有规则我们可以根据我们的需要进行重写,我们注意到其中一条error如下:
JSX not allowed in files with extension '.js' react/jsx-filename-extension前面的为相应说明,后面的为规则,这条不允许我们在.js文件中书写JSX语言,后面为对应的规则,显然是eslint-plugin-react插件的规则,我们可以重写以允许我们在.js文件中书写JSX,如下:
module.exports = {
"parserOptions": {
"ecmaVersion": 6,
"sourceType": "module",
"ecmaFeatures": {
"jsx": true
}
},
"extends": "airbnb",
"env": {
"browser": true,
"node": true
},
"parser": "babel-eslint",
"rules": {
"no-console": 1,
"react/jsx-filename-extension": [1, { "extensions": [".js", ".jsx"] }]
}
};再次运行可以发现这条error已经不存在了。
在之前的文章中我们已经提到过了,我们可以使用file-loader来实现:
npm i file-loader -D在webpack.config.js中配置:
const config = {
// ......
module: {
rules: [
{
test: /\.(png|jpg|svg|gif)/,
use:[
"file-loader"
]
}
]
},
// ......
}
module.exports = config;此时我们可以引入图片资源了。
我们在使用babel的时候我们需要明确知道的一点是,babel默认只是为我们转化语法层面上的东西(如箭头函数),并不会为我们去将一些方法进行转化为es2015的实现,也就是说如果我使用Array.of方法,如果浏览器不支持这个方法,及时按照上面的babel转化也是依旧没有办法运行的,我们可以在App.js中使用Array.of方法来测试一下,如下:
Array.of(1,2,3,4).forEach(function(item){
console.log(item);
});我们这次使用webpack命令直接在dist文件夹中生成相应的文件,我们可以在js文件中找到以下内容:

这就验证了上文的说法,因此我们需要使用babel-polyfill
首先进行安装:
npm i install babel-polyfill -D安装完成之后我们需要在webpack的入口中进行配置,将webpack的entry修改为以下内容:
entry: ['babel-polyfill','./src/main.js']我们现在使用webpack命令为我们打包一下内容,我们会发现打包后的文件非常大,只有部分内容却打包之后有3000+kb,这是不能用在生产环境上的,如下:

文件体积太大一个重要原因是devtool开启了inline-source-map方便我们定位bug,同时代码没有压缩也是重要原因之一,因此我们需要将开发和生产环境分离,使用不同的webpack配置。
还记得我们系列之前介绍的webpack-merge吗?我们通过这个插件可以将公共的配置分离到一起。首先进行安装
npm i webpack-merge -D新建一个名为webpack.common.js文件作为公共配置,写入以下内容:
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const config = {
entry: ['babel-polyfill','./src/main.js'],
output: {
filename: 'bundle-[hash].js',
path: path.join(__dirname, 'dist')
},
plugins: [
new HtmlWebpackPlugin({
title:'React简易开发环境',
template: './src/index.html'
})
]
}
module.exports = config;新建一个名为webpack.dev.js文件作为开发环境配置,写入以下内容:
const merge = require('webpack-merge');
const common = require('./webpack.common');
const webpack = require('webpack');
const config = merge(common, {
devtool:'inline-source-map',
devServer: {
contentBase: './dist',
hot: true
},
module: {
rules: [
{
test: /\.(js|jsx)/,
use:[
'babel-loader',
'eslint-loader'
]
},{
test: /\.(sass|scss|css)/,
use: [
"style-loader",
"css-loader",
"resolve-url-loader",
"sass-loader?sourceMap"
]
},{
test: /\.(png|jpg|svg|gif)/,
use:[
"file-loader"
]
}
]
},
plugins: [
new webpack.HotModuleReplacementPlugin()
]
});
module.exports = config;刚刚我们提到我们在开发环境中应该压缩混淆代码同时精简输出,因此需要使用uglifyjs-webpack-plugin插件,首先进行安装:
npm i uglifyjs-webpack-plugin -D新建一个名为webpack.prod.js的文件作为生产环境配置,写入以下内容:
const merge = require('webpack-merge');
const common = require('./webpack.common');
const UglifyJSPlugin = require('uglifyjs-webpack-plugin');
const config = merge(common, {
devtool:false,
module: {
rules: [
{
test: /\.(js|jsx)/,
use:[
'babel-loader'
]
},{
test: /\.(sass|scss|css)/,
use: [
"style-loader",
"css-loader",
"resolve-url-loader",
"sass-loader?sourceMap"
]
},{
test: /\.(png|jpg|svg|gif)/,
use:[
"file-loader"
]
}
]
},
plugins:[
new UglifyJSPlugin()
]
});
module.exports = config;因为在开发时我们需要使用的命令是
webpack-dev-server --open --config webpack.dev.js而在生产中我们需要使用的命令是
webpack --config webpack.prod.js为了精简我们在命令行中的输入我们将这些命令写在package.json中
"scripts": {
"dev": "webpack-dev-server --open --colors --progress --inline --config webpack.dev.js",
"build": "webpack --colors --progress --config webpack.prod.js"
}此时我们只要在命令行中输入npm run dev即可开启开发环境,使用npm run build即可自动生成用于生产环境的文件。
现在还有一个问题是我们修改文件之后再次使用npm run build命令则会出现多个js文件,这是因为我们使用了hash占位符,
这个占位符可以保证用户访问网站时始终保持最新的js文件,因此我们使用clean-webpack-plugin帮助我们每次删除dist文件夹的内容
npm i clean-webpack-plugin -D在webpack.prod.js中引用:
const merge = require('webpack-merge');
const common = require('./webpack.common');
const UglifyJSPlugin = require('uglifyjs-webpack-plugin');
const CleanWebpackPlugin = require('clean-webpack-plugin');
const config = merge(common, {
// ......
plugins:[
new CleanWebpackPlugin(['./dist']),
new UglifyJSPlugin()
]
});
module.exports = config;虽然目前一个简易的React开发环境已经搭建好了,但是还是需要对src目录进行划分以保证良好的开发体验,以下是划分的目录:
└───Components
└───......
└───......
└───Containers
└───......
└───......
└───static
└───sass
└───img
└───index.html
└───main.js目录功能相信一眼就能看出来了。这时一个简易的环境就已经搭建好了。
我大概是一个不学无术的化学人,
硬生生地上了写代码的船,
做着平平无奇的工作,
梦想着有一天真正变强,
从一个跟随者变为一个领导者。
validator.js是一个对字符串进行数据验证和过滤的工具库,同时支持Node端和浏览器端,github地址是https://github.com/chriso/validator.js
主要API如下:
验证str中是否含有seed
验证是否相等
验证str是否是一个指定date之后的时间字符串,默认date为现在,与之相反的是isBefore方法
检查是否是布尔值
检查是否是信用卡
检查str是否是一个可以被number整除的数字
检查是否是邮件地址
检查字符串是否为空
是否是域名
是否是浮点数
是否是哈希值
是否是十六进制颜色值,例如#ffffff
是否是十六进制数字
是否是IP地址值,version为4或者6
是否是ISBN号,version为10或者13
是否是整数
使用JSON.parse判断是否是json
判断字符串的长度是否在一个范围内,options默认为{min:0, max: undefined}
是否小写
是否是MAC地址
是否是MD5加密的哈希值
是否是MIME type值
是否是MongoDB的id值
是否仅仅包含数字
是否是一个端口号
是否是一个URL地址
是否大写
是否匹配,利用match方法,其中匹配的模式可以作为第三个参数,当然也可以卸载正则表达式pattern中
移除黑名单中的字符
对< > & ' " /进行HTML转义,与之相反的方法是unescape
对字符进行左缩进,与之对应的右缩进为rtrim方法,两端缩进trim
此外还有toBoolean、toDate、toFloat、toInt、whitelist
单文件入口
指定entry键值
const config = {
entry: './yourpath/file.js'
};
module.exports = config上面的是以下的简写:
const config = {
entry: {
main: './yourpath/file.js'
}
};
module.exports = config多文件入口
对entry采用对象写法,指定对应的键值对,为了输出这多个文件可以使用占位符
const path = require('path');
const config = {
entry: {
app1: './src/main.js',
app2: './src/app.js'
},
output: {
filename: '[name].bundle.js',
path: path.join(__dirname, 'dist')
}
};
module.exports = config;指定打包构建之后输出的文件
单文件输出
指定output键值,值为对象,对象中指定path和filename
const path = require('path');
const config = {
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
}
};
module.exports = config;多文件输出
使用占位符,输出文件将按照多文件入口指定的键来替代占位符
const path = require('path');
const config = {
entry: {
app1: './src/main.js',
app2: './src/app.js'
},
output: {
filename: '[name].bundle.js',
path: path.join(__dirname, 'dist')
}
};
module.exports = config;Loader可以在加载模块时预处理文件,类似于gulp中的task。配置loader需要在module选项下指定对应后缀名相应的rules,使用test正则指定后缀名,使用use指定相应的loader
允许在js中import css
需要使用style-loader和css-loader,首先需要安装:
npm i css-loader style-loader --save-dev使用loader
const path = require('path');
const config = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
module: {
rules: [{
test: /\.css$/,
use: [
'style-loader',
'css-loader'
]
}]
}
};
module.exports = config;模块文件写法:
import './css/main.css'允许加载图片
需要使用file-loader,首先安装:
npm i file-loader --save-dev使用:
const path = require('path');
const config = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
module: {
rules: [{
test: /\.(png|jpg|svg|gif)$/,
use: [
'file-loader'
]
}]
}
};
module.exports = config;模块文件写法:
import logo from './image/logo.svg';插件的目的在于解决loader解决不了的事情,使用插件指定plugins选项即可,需要注意的使用插件需要引入插件。如使用HtmlWebpackPlugin插件为我们自动生成一个html文件。
首先安装:
npm i --save-dev html-webpack-plugin配置webpack
const path = require('path');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const config = {
entry: './src/main.js',
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
module: {
rules: [{
test: /\.css$/,
use: [
'style-loader',
'css-loader'
]
},{
test: /\.(png|jpg|svg|gif)$/,
use: [
'file-loader'
]
}]
},
plugins: [
new HtmlWebpackPlugin({
title: '我的webpack'
})
]
};
module.exports = config;源代码被webpack打包之后,会很难追踪到原始的代码的位置,使用source map功能,可以将编译后的代码映射回原始代码位置,指定devtool选项即可:
const config = {
// ....
devtool: 'inline-source-map'
};
module.exports = config;webpack-dev-server提供了一个简单的web服务器,并能够实时重新加载使用webpack需要先安装:
npm i --save-dev webpack-dev-server在配置文件中指定devServer选项,告诉服务器在哪里寻找文件
const config = {
// ....
devServer: {
contentBase: './dist'
}
};
module.exports = config;使用命令行运行命令或者在package.json中指定scripts
webpack-dev-server --open此时服务将运行在8080端口,其中open选项表示服务开启之后立即在默认浏览器中打开页面。
开启热更新很简单,只需要更新webpack-dev-server配置,增加hot选项,同时使用webpack自带的HMR插件
const config = {
// ....
devServer: {
contentBase: './dist',
hot:true
},
plugins: [
new webpack.HotModuleReplacementPlugin()
]
};
module.exports = config;在实际中是开发中可能有些模块的方法并没有被使用,也就是说,在开发中这些方法并没有被import,这些没有被使用的代码应该被删除的,使用uglifyjs-webpack-plugin插件可以帮助我们删除这些代码,同时做代码混淆和压缩。
安装:
npm i -D uglifyjs-webpack-plugin使用:
const UglifyJSPlugin = require('uglifyjs-webpack-plugin')
const config = {
// ....
plugins: [
new UglifyJSPlugin()
]
};
module.exports = config;生产和开发中的构建肯定是不同,生产中侧重于一个更好的开发体验,而生产环境中则需要更多的性能优化,更小的chunk。webpakck可以指定命令运行以来的配置文件,通过在package.json中写入script是一种不错的方式。而生产和开发中的配置肯定有很多重复的地方,使用webpack-merge可以合并通用配置
安装:
npm i -D webpack-mergewebpack.common.js
const path = require('path');
const CleanWebpackPlugin = require('clean-webpack-plugin');
const HtmlWebpackPlugin = require('html-webpack-plugin');
const config = {
entry: './src/main.js',
plugins: [
new CleanWebpackPlugin(['dist']),
new HtmlWebpackPlugin({
title: 'My App'
})
],
output: {
filename: 'bundle.js',
path: path.join(__dirname, 'dist')
},
}
module.exports = config;webpack.dev.js
const merge = require('webpack-merge');
const common = require('./webpack.common');
const config = merge(common, {
devtool: 'inline-source-map',
devServer: {
contentBase: './dist'
}
});
module.exports = config;webpack.prod.js
const merge = require('webpack-merge');
const UglifyJSPlugin = require('uglifyjs-webpack-plugin');
const common = require('./webpack.common');
const config = merge(common, {
plugins: [
new UglifyJSPlugin()
]
});
module.exports = config;package.json
{
// ......
"scripts": {
"start": "webpack-dev-server --open --config webpack.dev.js",
"build": "webpack --config webpack.prod.js"
},
// ......
}许多lib通过与process.env.NODE_ENV环境关联来决定lib中使用哪些内容,使用webpack内置的DefinePlugin可以为所有依赖指定这个变量。
const config = {
// ......
plugins: [
new webpack.DefinePlugin({
'process.env': {
'MODE_ENV': JSON.stringify('production')
}
})
]
// ......
}让文件名带有hash可以方便在生产环境中用户及时更新缓存,让文件名带有hash可以使用和构建相关的[hash]占位符,也可以使用与chunk相关的[chunkhash]占位符,通常后一种是更好的选择
const config = {
//......
output: {
filename: [name].[chunkhash].js,
path: path.join(__dirname, 'dist')
}
// ......
}在开发中有些时候我们需要webpack不打包某些lib,这在我们开发lib的时候特别常见,比如我们为react开发插件,不希望打包的时候包含react。使用配置的external选项可以做到,
const config = {
"externals": [
"react",
"react-dom"
]
}以blog项目为例:
rails new blog只需几秒钟就会得到一个基本的rails项目结构:
各个目录的作用为:
app:存放web应用的控制器、视图、模型、helpers等,开发主要集中在这里
bin*:各种脚本
config:路由、数据库等的配置文件
db:数据库的schema和数据库的迁移文件
log:日志文件
package.json:npm包记录,使用yarn管理
public:静态文件
test:测试
使用 rails server 命令启动服务器即可在本地3000端口访问到服务
使用命令生成控制器hello
rails generate controller hellorails自主生成了部分文件:
修改 config/routes.rb 文件配置路由,修改如下:
Rails.application.routes.draw do
get "hello/index"
root "hello#index"
end这里定义了路由hello/index,并且使用root方法将首页修改为了hello控制器下的index方法,也就是两路由的控制器一致。
接下来定义控制器:
class HelloController < ApplicationController
def index
end
endrails足够智能可以自己在视图文件夹寻找名为 index.html.erb 的视图文件,将视图文件写入以下内容
<h1>hello, rails</h1>此时,浏览器中打开 / 和 /hello/index/ 路径都将返回同样的内容
使用以下生成数据库模型:
rails generate model Article title:string content:text
使用以下迁移数据库:
rails db:migrate
迁移成功会出现类似内容:
使用以下命令生成控制器:
rails generate controller Articles
配置articles的路由:
resources :articles
使用 rails routes 命令查看当前的路由配置:
很明显,从这里可以看到每个路由应该对应的控制器方法,这是一个典型的RESTful api的配置。
按照上文中的方法创建好 new.html.erb 文件和 new 方法,在 new.html.erb 文件中写入:
<h2>new article</h2>
<%= form_with(scope: :article, url: articles_path, local: true) do |form| %>
<p>
<%= form.label :title %> <br>
<%= form.text_field :title %>
</p>
<p>
<%= form.label :content %> <br>
<%= form.text_area :content %>
</p>
<%= form.submit %>
<% end %>form_with 方法默认是提交到当前路由,通过url字段将其定义为post到 /articles 路径。
此时访问 /articles/new 路径可以看到表单:
此时我们需要定义提交之后的处理路径,从上面的路由配置中我们可以知道对应于 create 方法
def create
@article = Article.new(article_params)
@article.save
redirect_to @article
end此时提交表单,可以看到报错:
于是我们定义show方法:
def show
@article = Article.find(params[:id])
end定义相应的视图文件 show.html.erb :
<h2>Show article</h2>
<p>
title: <br> <%= @article.title %>
</p>
<p>
content: <br> <%= @article.content %>
</p>此时提交表单则直接跳转到show视图定义:
我们利用 index action 列举所有的article,定义 index 方法
def index
@article = Article.all
end定义视图:
<h2>List all Articles </h2>
<%= link_to "new article", new_article_path %>
<% @article.each do |a| %>
<p>
title: <br> <%= a.title %>
</p>
<p>
content: <br> <%= a.content %>
</p>
<% end %>此时访问 /articles 路径可以看到
通过路由配置更新分别对应于edit和update两个action,定义edit方法:
def edit
@article = Article.find(params[:id])
end定义相应的视图文件:
<h2>Edit article</h2>
<%= form_with(model: @article, local: true) do |form| %>
<p>
<%= form.label :title %> <br>
<%= form.text_field :title %>
</p>
<p>
<%= form.label :content %> <br>
<%= form.text_area :content %>
</p>
<%= form.submit %>
<% end %>
定义update方法:
def update
@article = Article.find(params[:id])
@article.update article_params
redirect_to @article
end此时可以发现已经可以正常更新了。
首先在文章列表页声明删除文件的链接,修改为:
<h2>List all Articles </h2>
<%= link_to "new article", new_article_path %>
<% @article.each do |a| %>
<p>
title: <br> <%= a.title %>
</p>
<p>
content: <br> <%= a.content %>
</p>
<p>
<%= link_to "edit", edit_article_path(a) %> <br>
<%= link_to "delete", article_path(a), method: :delete %>
</p>
<% end %>定义destroy方法:
def destroy
@article = Article.find(params[:id])
@article.destroy
redirect_to articles_path
end此时已经可以删除文件了。
将model文件夹下的article.rb文件修改为
class Article < ApplicationRecord
validates :title, presence: true, length: {minimum: 5}
validates :content, presence: true
end将new对应的视图文件修改为:
<h2>new article</h2>
<%= form_with(model: @article, url: articles_path, local: true) do |form| %>
<% if @article.errors.any? %>
<div>
<%= @article.errors.count.to_s%> erors
</div>
<% end %>
<p>
<%= form.label :title %> <br>
<%= form.text_field :title %>
</p>
<p>
<%= form.label :content %> <br>
<%= form.text_area :content %>
</p>
<%= form.submit %>
<% end %>将控制器的new action修改为:
def new
@article=Article.new
endcreate action 修改为:
def create
@article = Article.new(article_params)
if @article.save
redirect_to @article
else
render 'new'
end
end此时,一个简单的带数据验证的crud就实现了。
ejs项目大名鼎鼎,应该就不需要介绍了,主要收获就是得知了实现一个模板引擎的流程,ejs是将模板作为字符串逐个解析,遇到正常的html代码,就放进一个数组中去,遇到js代码则进行过滤器、包含等的处理,最后数组join成一个可以成为Function构造函数第二个参数的字符串,构造成构造函数之后就是调用返回最终的html字符串。以下是阅读源码的笔记,因为源码中遗憾有很多说明,所以笔记很少。
ejs = (function(){
// CommonJS require()
function require(p){
if ('fs' == p) return {};
if ('path' == p) return {};
var path = require.resolve(p)
, mod = require.modules[path];
if (!mod) throw new Error('failed to require "' + p + '"');
if (!mod.exports) {
mod.exports = {};
mod.call(mod.exports, mod, mod.exports, require.relative(path));
}
return mod.exports;
}
require.modules = {};
require.resolve = function (path){
var orig = path
, reg = path + '.js'
, index = path + '/index.js';
return require.modules[reg] && reg
|| require.modules[index] && index
|| orig;
};
require.register = function (path, fn){
require.modules[path] = fn;
};
require.relative = function (parent) {
return function(p){
if ('.' != p.substr(0, 1)) return require(p);
var path = parent.split('/')
, segs = p.split('/');
path.pop();
for (var i = 0; i < segs.length; i++) {
var seg = segs[i];
if ('..' == seg) path.pop();
else if ('.' != seg) path.push(seg);
}
return require(path.join('/'));
};
};
require.register("ejs.js", function(module, exports, require){
/*!
* EJS
* Copyright(c) 2012 TJ Holowaychuk <[email protected]>
* MIT Licensed
*/
/**
* Module dependencies.
*/
var utils = require('./utils')
, path = require('path')
, dirname = path.dirname
, extname = path.extname
, join = path.join
, fs = require('fs')
, read = fs.readFileSync;
/**
* Filters.
*
* @type Object
*/
var filters = exports.filters = require('./filters');
/**
* Intermediate js cache.
*
* @type Object
*/
var cache = {};
/**
* Clear intermediate js cache.
*
* @api public
*/
exports.clearCache = function(){
cache = {};
};
/**
* Translate filtered code into function calls.
*
* @param {String} js
* @return {String}
* @api private
*/
function filtered(js) {
return js.substr(1).split('|').reduce(function(js, filter){
var parts = filter.split(':')
, name = parts.shift()
, args = parts.join(':') || '';
if (args) args = ', ' + args;
return 'filters.' + name + '(' + js + args + ')';
});
};
/**
* Re-throw the given `err` in context to the
* `str` of ejs, `filename`, and `lineno`.
*
* @param {Error} err
* @param {String} str
* @param {String} filename
* @param {String} lineno
* @api private
*/
function rethrow(err, str, filename, lineno){
var lines = str.split('\n')
, start = Math.max(lineno - 3, 0)
, end = Math.min(lines.length, lineno + 3);
// Error context
var context = lines.slice(start, end).map(function(line, i){
var curr = i + start + 1;
return (curr == lineno ? ' >> ' : ' ')
+ curr
+ '| '
+ line;
}).join('\n');
// Alter exception message
err.path = filename;
err.message = (filename || 'ejs') + ':'
+ lineno + '\n'
+ context + '\n\n'
+ err.message;
throw err;
}
/**
* Parse the given `str` of ejs, returning the function body.
*
* @param {String} str
* @return {String}
* @api public
*/
var parse = exports.parse = function(str, options){
var options = options || {}
, open = options.open || exports.open || '<%'
, close = options.close || exports.close || '%>'
, filename = options.filename
, compileDebug = options.compileDebug !== false
, buf = "";
buf += 'var buf = [];';
if (false !== options._with) buf += '\nwith (locals || {}) { (function(){ ';
buf += '\n buf.push(\'';
var lineno = 1;
var consumeEOL = false;
for (var i = 0, len = str.length; i < len; ++i) {
var stri = str[i];
if (str.slice(i, open.length + i) == open) {
i += open.length
var prefix, postfix, line = (compileDebug ? '__stack.lineno=' : '') + lineno;
switch (str[i]) {
case '=':
prefix = "', escape((" + line + ', ';
postfix = ")), '";
++i;
break;
case '-':
prefix = "', (" + line + ', ';
postfix = "), '";
++i;
break;
default:
prefix = "');" + line + ';';
postfix = "; buf.push('";
}
// 查找对应的结尾
var end = str.indexOf(close, i);
if (end < 0){
throw new Error('Could not find matching close tag "' + close + '".');
}
// 提取模板中的js代码
var js = str.substring(i, end)
, start = i
, include = null
, n = 0;
// 结尾-表示不需要转义,这种情况<%- code -%>
if ('-' == js[js.length-1]){
js = js.substring(0, js.length - 2);
consumeEOL = true;
}
// 处理调用include情况 <%- include() %>
if (0 == js.trim().indexOf('include')) {
var name = js.trim().slice(7).trim();
if (!filename) throw new Error('filename option is required for includes');
var path = resolveInclude(name, filename);
include = read(path, 'utf8');
include = exports.parse(include, { filename: path, _with: false, open: open, close: close, compileDebug: compileDebug });
buf += "' + (function(){" + include + "})() + '";
js = '';
}
// 处理js代码换行的情况,又路遇装逼犯,~(n = js.indexOf("\n", n))就是存在换行符情况之下执行
while (~(n = js.indexOf("\n", n))) n++, lineno++;
// 过滤器处理,<%=: users | map:'name' | join %>
if (js.substr(0, 1) == ':') js = filtered(js);
if (js) {
if (js.lastIndexOf('//') > js.lastIndexOf('\n')) js += '\n';
buf += prefix;
buf += js;
buf += postfix;
}
i += end - start + close.length - 1;
} else if (stri == "\\") {
buf += "\\\\";
} else if (stri == "'") {
buf += "\\'";
} else if (stri == "\r") {
// ignore
} else if (stri == "\n") {
if (consumeEOL) {
consumeEOL = false;
} else {
buf += "\\n";
lineno++;
}
} else {
buf += stri;
}
}
if (false !== options._with) buf += "'); })();\n} \nreturn buf.join('');";
else buf += "');\nreturn buf.join('');";
return buf;
};
/**
* Compile the given `str` of ejs into a `Function`.
*
* @param {String} str
* @param {Object} options
* @return {Function}
* @api public
*/
var compile = exports.compile = function(str, options){
options = options || {};
var escape = options.escape || utils.escape;
var input = JSON.stringify(str)
, compileDebug = options.compileDebug !== false
, client = options.client
, filename = options.filename
? JSON.stringify(options.filename)
: 'undefined';
if (compileDebug) {
// Adds the fancy stack trace meta info
str = [
'var __stack = { lineno: 1, input: ' + input + ', filename: ' + filename + ' };',
rethrow.toString(),
'try {',
exports.parse(str, options),
'} catch (err) {',
' rethrow(err, __stack.input, __stack.filename, __stack.lineno);',
'}'
].join("\n");
} else {
str = exports.parse(str, options);
}
if (options.debug) console.log(str);
if (client) str = 'escape = escape || ' + escape.toString() + ';\n' + str;
try {
// 别忘了,可以使用构造函数定义函数呀
var fn = new Function('locals, filters, escape, rethrow', str);
} catch (err) {
if ('SyntaxError' == err.name) {
err.message += options.filename
? ' in ' + filename
: ' while compiling ejs';
}
throw err;
}
if (client) return fn;
return function(locals){
return fn.call(this, locals, filters, escape, rethrow);
}
};
/**
* Render the given `str` of ejs.
*
* Options:
*
* - `locals` Local variables object
* - `cache` Compiled functions are cached, requires `filename`
* - `filename` Used by `cache` to key caches
* - `scope` Function execution context
* - `debug` Output generated function body
* - `open` Open tag, defaulting to "<%"
* - `close` Closing tag, defaulting to "%>"
*
* @param {String} str
* @param {Object} options
* @return {String}
* @api public
*/
// 渲染函数
exports.render = function(str, options){
var fn
, options = options || {};
// 检查是否缓存
if (options.cache) {
if (options.filename) {
fn = cache[options.filename] || (cache[options.filename] = compile(str, options));
} else {
throw new Error('"cache" option requires "filename".');
}
} else {
fn = compile(str, options);
}
options.__proto__ = options.locals;
return fn.call(options.scope, options);
};
/**
* Render an EJS file at the given `path` and callback `fn(err, str)`.
*
* @param {String} path
* @param {Object|Function} options or callback
* @param {Function} fn
* @api public
*/
exports.renderFile = function(path, options, fn){
var key = path + ':string';
if ('function' == typeof options) {
fn = options, options = {};
}
options.filename = path;
var str;
try {
str = options.cache
? cache[key] || (cache[key] = read(path, 'utf8'))
: read(path, 'utf8');
} catch (err) {
fn(err);
return;
}
fn(null, exports.render(str, options));
};
/**
* Resolve include `name` relative to `filename`.
*
* @param {String} name
* @param {String} filename
* @return {String}
* @api private
*/
function resolveInclude(name, filename) {
var path = join(dirname(filename), name);
var ext = extname(name);
if (!ext) path += '.ejs';
return path;
}
// express support
exports.__express = exports.renderFile;
/**
* Expose to require().
*/
if (require.extensions) {
require.extensions['.ejs'] = function (module, filename) {
filename = filename || module.filename;
var options = { filename: filename, client: true }
, template = fs.readFileSync(filename).toString()
, fn = compile(template, options);
module._compile('module.exports = ' + fn.toString() + ';', filename);
};
} else if (require.registerExtension) {
require.registerExtension('.ejs', function(src) {
return compile(src, {});
});
}
}); // module: ejs.js
require.register("filters.js", function(module, exports, require){
/*!
* EJS - Filters
* Copyright(c) 2010 TJ Holowaychuk <[email protected]>
* MIT Licensed
*/
/**
* First element of the target `obj`.
*/
// 过滤函数
exports.first = function(obj) {
return obj[0];
};
/**
* Last element of the target `obj`.
*/
// 过滤函数
exports.last = function(obj) {
return obj[obj.length - 1];
};
/**
* Capitalize the first letter of the target `str`.
*/
// 过滤函数
exports.capitalize = function(str){
str = String(str);
return str[0].toUpperCase() + str.substr(1, str.length);
};
/**
* Downcase the target `str`.
*/
// 过滤函数
exports.downcase = function(str){
return String(str).toLowerCase();
};
/**
* Uppercase the target `str`.
*/
// 过滤函数
exports.upcase = function(str){
return String(str).toUpperCase();
};
/**
* Sort the target `obj`.
*/
// 过滤函数
exports.sort = function(obj){
return Object.create(obj).sort();
};
/**
* Sort the target `obj` by the given `prop` ascending.
*/
exports.sort_by = function(obj, prop){
return Object.create(obj).sort(function(a, b){
a = a[prop], b = b[prop];
if (a > b) return 1;
if (a < b) return -1;
return 0;
});
};
/**
* Size or length of the target `obj`.
*/
exports.size = exports.length = function(obj) {
return obj.length;
};
/**
* Add `a` and `b`.
*/
exports.plus = function(a, b){
return Number(a) + Number(b);
};
/**
* Subtract `b` from `a`.
*/
exports.minus = function(a, b){
return Number(a) - Number(b);
};
/**
* Multiply `a` by `b`.
*/
exports.times = function(a, b){
return Number(a) * Number(b);
};
/**
* Divide `a` by `b`.
*/
exports.divided_by = function(a, b){
return Number(a) / Number(b);
};
/**
* Join `obj` with the given `str`.
*/
exports.join = function(obj, str){
return obj.join(str || ', ');
};
/**
* Truncate `str` to `len`.
*/
exports.truncate = function(str, len, append){
str = String(str);
if (str.length > len) {
str = str.slice(0, len);
if (append) str += append;
}
return str;
};
/**
* Truncate `str` to `n` words.
*/
exports.truncate_words = function(str, n){
var str = String(str)
, words = str.split(/ +/);
return words.slice(0, n).join(' ');
};
/**
* Replace `pattern` with `substitution` in `str`.
*/
exports.replace = function(str, pattern, substitution){
return String(str).replace(pattern, substitution || '');
};
/**
* Prepend `val` to `obj`.
*/
exports.prepend = function(obj, val){
return Array.isArray(obj)
? [val].concat(obj)
: val + obj;
};
/**
* Append `val` to `obj`.
*/
exports.append = function(obj, val){
return Array.isArray(obj)
? obj.concat(val)
: obj + val;
};
/**
* Map the given `prop`.
*/
exports.map = function(arr, prop){
return arr.map(function(obj){
return obj[prop];
});
};
/**
* Reverse the given `obj`.
*/
exports.reverse = function(obj){
return Array.isArray(obj)
? obj.reverse()
: String(obj).split('').reverse().join('');
};
/**
* Get `prop` of the given `obj`.
*/
exports.get = function(obj, prop){
return obj[prop];
};
/**
* Packs the given `obj` into json string
*/
exports.json = function(obj){
return JSON.stringify(obj);
};
}); // module: filters.js
require.register("utils.js", function(module, exports, require){
/*!
* EJS
* Copyright(c) 2010 TJ Holowaychuk <[email protected]>
* MIT Licensed
*/
/**
* Escape the given string of `html`.
*
* @param {String} html
* @return {String}
* @api private
*/
exports.escape = function(html){
return String(html)
.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/'/g, ''')
.replace(/"/g, '"');
};
}); // module: utils.js
return require("ejs");
})();better yourself!

将颜色的RGB设置为相同的值即可使得图片为灰色,一般处理方法有:
1、取三种颜色的平均值
2、取三种颜色的最大值(最小值)
3、加权平均值:0.3R + 0.59G + 0.11*B
for(var i = 0; i < data.length; i+=4) {
var grey = (data[i] + data[i+1] + data[i+2]) / 3;
data[i] = data[i+1] = data[i+2] = grey;
}顾名思义,就是图片的颜色只有黑色和白色,可以计算rgb的平均值arg,arg>=100,r=g=b=255,否则均为0
for(var i = 0; i < data.length; i += 4) {
var avg = (data[i] + data[i+1] + data[i+2]) / 3;
data[i] = data[i+1] = data[i+2] = avg >= 100 ? 255 : 0;
}就是RGB三种颜色分别取255的差值。
for(var i = 0; i < data.length; i+= 4) {
data[i] = 255 - data[i];
data[i + 1] = 255 - data[i + 1];
data[i + 2] = 255 - data[i + 2];
}rgb三种颜色取三种颜色的最值的平均值。
for(var i = 0; i < data.length; i++) {
var avg = Math.floor((Math.min(data[i], data[i+1], data[i+2]) + Math.max(data[i], data[i+1], data[i+2])) / 2 );
data[i] = data[i+1] = data[i+2] = avg;
}就是只保留一种颜色,其他颜色设为0
for(var i = 0; i < canvas.height * canvas.width; i++) {
data[i*4 + 2] = 0;
data[i*4 + 1] = 0;
}高斯模糊的原理就是根据正态分布使得每个像素点周围的像素点的权重不一致,将各个权重(各个权重值和为1)与对应的色值相乘,所得结果求和为中心像素点新的色值。我们需要了解的高斯模糊的公式:
function gaussBlur(imgData, radius, sigma) {
var pixes = imgData.data,
height = imgData.height,
width = imgData.width,
radius = radius || 5;
sigma = sigma || radius / 3;
var gaussEdge = radius * 2 + 1;
var gaussMatrix = [],
gaussSum = 0,
a = 1 / (2 * sigma * sigma * Math.PI),
b = -a * Math.PI;
for(var i = -radius; i <= radius; i++) {
for(var j = -radius; j <= radius; j++) {
var gxy = a * Math.exp((i * i + j * j) * b);
gaussMatrix.push(gxy);
gaussSum += gxy;
}
}
var gaussNum = (radius + 1) * (radius + 1);
for(var i = 0; i < gaussNum; i++) {
gaussMatrix[i] /= gaussSum;
}
for(var x = 0; x < width; x++) {
for(var y = 0; y < height; y++) {
var r = g = b = 0;
for(var i = -radius; i<=radius; i++) {
var m = handleEdge(i, x, width);
for(var j = -radius; j <= radius; j++) {
var mm = handleEdge(j, y, height);
var currentPixId = (mm * width + m) * 4;
var jj = j + radius;
var ii = i + radius;
r += pixes[currentPixId] * gaussMatrix[jj * gaussEdge + ii];
g += pixes[currentPixId + 1] * gaussMatrix[jj * gaussEdge + ii];
b += pixes[currentPixId + 2] * gaussMatrix[jj * gaussEdge + ii];
}
}
var pixId = (y * width + x) * 4;
pixes[pixId] = ~~r;
pixes[pixId + 1] = ~~g;
pixes[pixId + 2] = ~~b;
}
}
imgData.data = pixes;
return imgData;
}
function handleEdge(i, x, w) {
var m = x + i;
if(m < 0) {
m = -m;
} else if(m >= w) {
m = w + i -x;
}
return m;
}怀旧滤镜公式
for(var i = 0; i < imgData.height * imgData.width; i++) {
var r = imgData.data[i*4],
g = imgData.data[i*4+1],
b = imgData.data[i*4+2];
var newR = (0.393 * r + 0.769 * g + 0.189 * b);
var newG = (0.349 * r + 0.686 * g + 0.168 * b);
var newB = (0.272 * r + 0.534 * g + 0.131 * b);
var rgbArr = [newR, newG, newB].map((e) => {
return e < 0 ? 0 : e > 255 ? 255 : e;
});
[imgData.data[i*4], imgData.data[i*4+1], imgData.data[i*4+2]] = rgbArr;
}公式:
r = r128/(g+b +1);
g = g128/(r+b +1);
b = b*128/(g+r +1);
for(var i = 0; i < imgData.height * imgData.width; i++) {
var r = imgData.data[i*4],
g = imgData.data[i*4+1],
b = imgData.data[i*4+2];
var newR = r * 128 / (g + b + 1);
var newG = g * 128 / (r + b + 1);
var newB = b * 128 / (g + r + 1);
var rgbArr = [newR, newG, newB].map((e) => {
return e < 0 ? 0 : e > 255 ? 255 : e;
});
[imgData.data[i*4], imgData.data[i*4+1], imgData.data[i*4+2]] = rgbArr;
}公式:
r = (r-g-b)*3/2;
g = (g-r-b)*3/2;
b = (b-g-r)*3/2;
for(var i = 0; i < imgData.height * imgData.width; i++) {
var r = imgData.data[i*4],
g = imgData.data[i*4+1],
b = imgData.data[i*4+2];
var newR = (r - g -b) * 3 /2;
var newG = (g - r -b) * 3 /2;
var newB = (b - g -r) * 3 /2;
var rgbArr = [newR, newG, newB].map((e) => {
return e < 0 ? 0 : e > 255 ? 255 : e;
});
[imgData.data[i*4], imgData.data[i*4+1], imgData.data[i*4+2]] = rgbArr;
}公式:
R = |g – b + g + r| * r / 256
G = |b – g + b + r| * r / 256;
B = |b – g + b + r| * g / 256;
for(var i = 0; i < imgData.height * imgData.width; i++) {
var r = imgData.data[i*4],
g = imgData.data[i*4+1],
b = imgData.data[i*4+2];
var newR = Math.abs(g - b + g + r) * r / 256;
var newG = Math.abs(b -g + b + r) * r / 256;
var newB = Math.abs(b -g + b + r) * g / 256;
var rgbArr = [newR, newG, newB];
[imgData.data[i*4], imgData.data[i*4+1], imgData.data[i*4+2]] = rgbArr;
}
在Node.js中,process对象是一个全局对象,可以直接在Node.js的REPL环境中访问该对象。该process对象有用的主要属性有
execPath:表示可执行文件的绝对路径
version:Node.js的版本号
versions:Node.js各种依赖的版本,是一个对象,包括node、v8等版本
platform:Node.js运行的平台
argv:运行Node.js的命令行参数,是一个数组,第一个是命令,第二个是文件名,之后时附加参数
env:操作系统信息
pid:进程的PID
title:命令行窗口的标题在REPL环境中检验相应的属性如下:

另外process的stdin属性作为标准的输入流,默认情况下是暂停的,使用process.stdin.resume()方法恢复,如下就是一个简单的命令行交互界面:
process.stdin.resume();
console.log('请输入你想要输入的数据:');
process.stdin.on('data', function(chunk) {
process.stdout.write('你输入的数据是:' + chunk.toString());
});
一个Node.js进程的主要方法有以下方法:
process.memoryUsage():用于获取运行Node.js应用的进程的内存使用量,返回一个对象
rss:整数,进程的内存消耗量,单位是字节
heapTotal:整数,为V8所分配的内存量,单位字节
heapUsed:整数,V8的内存消耗量,单位字节
process.chdir():用于改变Node.js的工作目录,参数为一个路径,可以是相对,也可以是绝对
process.cwd():用于获取当前的工作目录,
console.log('directory ', process.cwd());
process.chdir('../');
console.log('directory ', process.cwd());
process.exit():用于退出进程,可提供一个整数作为退出代码,默认为0
process.kill(pid,[signall]):向另一个进程发送信号,如果不指定sinall,则说明是终止该进程。
process.uptime():获得应用程序当前的运行时间,单位秒

A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.





















































































































