haidra-org / hordelib Goto Github PK
View Code? Open in Web Editor NEWA wrapper around ComfyUI to allow use by the AI Horde.
Home Page: https://hordelib.org
License: GNU Affero General Public License v3.0
A wrapper around ComfyUI to allow use by the AI Horde.
Home Page: https://hordelib.org
License: GNU Affero General Public License v3.0


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")

















































Currently do_baselines_match() returns always True to avoid rejecting mislabeled loras on CivitAI. As Comfy already reports mismatch errors, we can hook into that, but we'll need to replace the lora loader with a hordelib one

(also # FIXME)
There are at least 80 of these, each of which requires a varying degree of attention, ranging from removing it (the concern stated has been obviated) to a potentially major refactor/rewrite of functions or classes.
The minor ones should be resolved, obsolete remarks removed, and any remaining issues converted to github issues.
Currently, the API relies on a bool for karras, and while hordelib does support extra schedulers in principal, it is not explicitly handled right now.
Currently Loras and TI MMs in different inference keep their own "knowledge" of ad-hoc downloads, which is probably a problem as they might be deleting each other's files and clobbering the saved file.
I remain uncertain the exact meaning of this error in the context of this project. I have not had time to investigate fully.
A common source of confusion for worker performance stems from the models being on slow disk. Detecting this condition, and notifying the user when appropriate that this is causing a problem, may help reduce confusion.
Now that the major systems are in place, there is an opportunity to continue my efforts in adding type hints to the signatures of many functions and to class attrs as the function signatures are much better understood and less likely to change.
If so, we should unload them in low vram situations.
LoRa files can be fetched/validated by the LoRa MM and then sent to comfyui, at which point when they are attempted to be read from off disk, the .safetensors file turns out to be an HTML webpage.
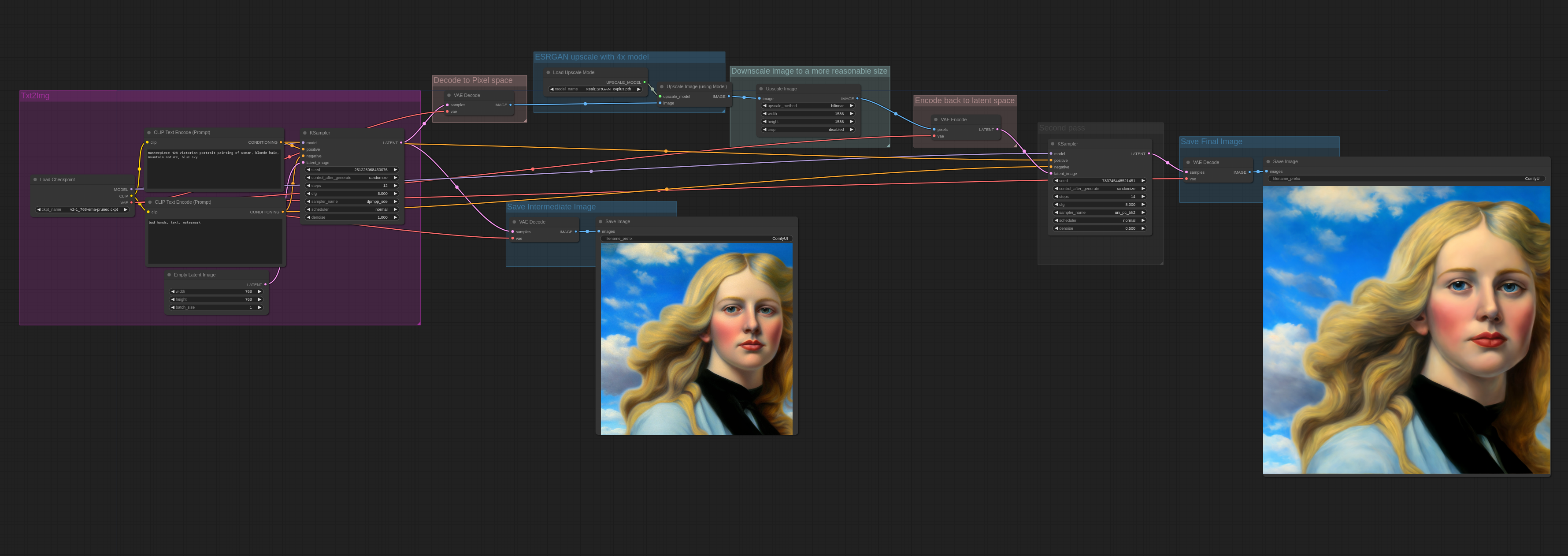
Currently hires fix runs an initial image job at the number of input steps. If the user requests 30 steps, the worker generates a 30 step image latent with the resolution of the smallest side pinned to 512 (and the longer side, if the sizes don't match, is set so the aspect ratio is respected). The worker then runs that image latent using the same number of steps (e.g., 30 as in this example) at the final resolution.
Some thoughts on improvements:
Jug did the initial training of the model. Having not looked, and merely not knowing the answers at this time, I wonder:
n_iter)?As part of a future push to stay on top of the code being maintainable, I propose we enforce the presence of docstrings on functions (at a minimum). I also would strongly encourage docstring for any consts, and for most attrs in classes.
Ruff has a facility for this. You can find more information at https://beta.ruff.rs/docs/rules/#pydocstyle-d.
This would include running progressively more intensive jobs and simulating/comparing the results to the kudos model/
The following are prerequisites:
Civitai is now allowing LoRa authors to only allow a LoRa to be downloaded by a logged in user. Workers (or consumers of this library) should be able to be able continue to use the LoRa functionality for these LoRas by specifying a login cookie or other suitable credentials.
There are a bunch of inference parameters for which we don't have matching payload parameters to adjust the default hardcoded values.
Add any other parameters from our pipelines as optional payload parameters.
Ultimately, when it comes to worker users already having models downloaded, the expectation that the file is named is a certain way is a sore point. Looking at only the SHA256 sum should be sufficient.
@jug-dev When time permits, and if you're otherwise able, could you investigate or offer an alterative course of action? The repo settings state it is offline. The runner hasn't been used since the repo was returned to haidra-org, so I suspect it is either offline, or a config wasn't altered when the switch took place.
comfy_horde.py and horde.py, but thorough testing would be required, and support from the API, to be sure it is in a production ready state.While the readme is very robust, some of the finer points of developing within the code base should be included, as some of the best practices, and tools used/recommended.
@jug-dev With no rush whatsoever, if you could investigate when possible.
Format would be like
response = requests.get(lora["versions"][version]["url"] + "?token=abc554bcc138d97a9323856c2dee3333", ...The current testing strategy for build_helper.py being importable in the release process relies on the developer to read, understand, and follow some directions which are easily overlooked. There should be a scheme to not require multiple places to be updated by hand.
xformers is often version pinned, and its inclusion in the requirements.txt can lead to torch being installed, uninstalled, and then installed again at the version pinned by xformers. hordelib is agnostic to this presence of xformers, and it should likely be up to the consumer of the library to have it installed or not.
The prior round of testing used this fixture for the lora inference tests:
@pytest.fixture(autouse=True, scope="class")
def setup_and_teardown(self, shared_model_manager: type[SharedModelManager]):
assert shared_model_manager.manager.lora
shared_model_manager.manager.lora.download_default_loras()
shared_model_manager.manager.lora.wait_for_downloads()
yield
shared_model_manager.manager.lora.stop_all()Which, when run on my machine (and particularly through the CI runner), would hang here indefinitely during full CI runs, but not when the lora inference tests were first or run on their own.
Does running the lora model manager, or some other test(s) lead to this hang up in certain circumstances?
A number of optimizations could be made, including (but not limited to):
conftest.py.
tests/ logically separating the functions being tested (a folder for inference, clip/blip, utilities, etc) would allow a conftest.py for each level of the hierarchy, potentially side stepping a lot of repeat code by having fixtures which are better designed.This should be straight forward enough to do within hordelib, the worker will need a bit of wrangling to handle this.
When sent along with a control_type, the source_image is actually the control image.
There should be a facility to support verbosity between the major levels. For example, INFO is considered level 20, and WARN level 30, but the worker (and other schemes) may use levels such as 25 for SUCCESS.
Comfy logically separates out the VAE in fairly easy way. The following would be needed
Unhandled exception when trying to retrieve model reference ends up in a hung worker endlessly looping models.
@db0 reports tox hanging indefinitely (at least overnight) at the test_no_initialize_comfy_horde test when using tox through SSH.
I am unable to reproduce the issue locally, nor does the CI runner experience this problem. There may be some quirks or oddities with this particular version of tox and either linux, ssh, or another python dependency.
discussed on discord:
Efreak
It might be worth considering adding some of the ffusion SDXL model lora extracts to horde. If they work close enough to the models they're based on, they could be used as separate models from the API with only an additional ~500-600mb each (plus the base model, which is either SDXL ffusion base; I'm not clear which) instead of 4-8gb for full SDXL models. Besides the likely-popular nsfw models, they've got extracts for Faetastic, nightvision, dynavision. Dreamshaper, counterfeit, animagine, and a bunch of realism models. Most of those named have been requested iirc (possible exception of counterfeit and Faetastic).
db0
Can you explain what is going on here exactly? Are these Loras to apply to basic sdxl to simulate finetunes like dreamshaper or something?
rcnz
Basically they are extracting the difference between the fine-tune and the base model and putting it in lora form. You then apply the lora to the base model and you're off laughing. Doing a lora that way takes the 6.5gb model down to a 450-2000mb lora depending on extraction technique, and the distance between base and finetune
spinagon
It's not exact, but does approximate model style
rcnz
the ffusion ones at 500mb are more approximate, some of the higher dimension ones (128+) come out at 2gb and are pretty much identical
but a 2gb lora would break horde systems lol
Tazlin
maybe when we work in LCM's as a special exceptions we can leave it flexible enough to support something like this too
Efreak
This is why I suggested adding them as models, not as loras. Call it dynavision lite or some such
It would be a compromise between having models you want on horde and not having to download too many giant 6gb SDXL models
As long as the quality is high enough
Basically a controlnet WF that can help fix hands in an image:
https://www.youtube.com/watch?v=Tt-Fyn1RA6c
There is a breaking change to using str as a mix-in to Enum which breaks the syntax being used currently for the relevant enums.
Do one of the following:
StrEnum for 3.10 compatibility that reproduces the behavior of the 3.11 class by that nameOther incompatibilities may continue to lurk with 3.11 that may fail on runtime or, possibly, prior.
hordelib/hordelib/model_manager/lora.py
Line 379 in 75341ff
Batches create images that are currently only reproducible from using batch again. However, it is possible, using the LatentFromBatch node to generate only one (or more) image from a batch, without having to do the entire set. For example, if you generate 20 images, it is possible (using this node) to generate only images 16-18 (3 images total, without doing all 20).
So, I'm not exactly sure if this is a mistake on my part or not, but I've been trying to use negative embeddings in ArtBot and Lucid Creations, and they don't properly work on either of them with auto-injections. ArtBot always injects the embedding, while it's optional with Lucid Creations (so you can inject manually).
Base parameters for all generations:
Base prompt - 1girl, college student, black hair, long hair, glasses, upper body
Model - Anything Diffusion
Resolution - 512x768
Seed - 1234
Steps - 30
Guidance - 7.5
Sampler - k_dpmpp_2m
Karras - Enabled
Clip skip - 1 (default)
With just those settings with no negative prompt whatsoever:
 Same generation on ArtBot - https://tinybots.net/artbot?i=h7twhJUM16o
Same generation on ArtBot - https://tinybots.net/artbot?i=h7twhJUM16o
Manually injecting EasyNegative (Inject Embedding: No) with (embedding:7808:1)
 You can clearly see that the image has become "better" as to normal anime art standards. Not possible to repeat in ArtBot as it always injects embeddings automatically.
You can clearly see that the image has become "better" as to normal anime art standards. Not possible to repeat in ArtBot as it always injects embeddings automatically.
Automatically injecting the same EasyNegative (Inject Embedding: Negative prompt) without specifying anything in the negative prompt.  It seems like that in the case of an automatic injection to the negative prompt, the embedding still somehow ends up in the positive prompt, making the image worse. Same generation on ArtBot - https://tinybots.net/artbot?i=gFD6RSgyfWB
It seems like that in the case of an automatic injection to the negative prompt, the embedding still somehow ends up in the positive prompt, making the image worse. Same generation on ArtBot - https://tinybots.net/artbot?i=gFD6RSgyfWB
Very simple post-processor. Doesn't really belong in the bridge
import rembg
def strip_background(payload):
session = rembg.new_session("u2net")
image = rembg.remove(
payload["source_image"],
session=session,
only_mask=False,
alpha_matting=10,
alpha_matting_foreground_threshold=240,
alpha_matting_background_threshold=10,
alpha_matting_erode_size=10,
)
del session
return imageMight be worth sending a PR to ComfyUI with it as an official node, but for now this should be OK
On Linux with 16GB RAM and 8GB VRAM, 80% leave free settings it seems we free a model from RAM, and then unload it from the GPU back into RAM. The next action in this log was the process being killed by the kernel OOM killer. Only 2 models were configured to load.
DEBUG | 2023-05-18 22:47:24.129614 | hordelib.cache.cache:__init__:63 - Cache file: ./nataili/embeds/ViT-L_14/text/cache.db
DEBUG | 2023-05-18 22:47:24.129669 | hordelib.cache.cache:__init__:64 - Cache dir: ./nataili/embeds/ViT-L_14/text
DEBUG | 2023-05-18 22:47:24.129907 | hordelib.cache.cache:__init__:63 - Cache file: ./nataili/embeds/ViT-L_14/image/cache.db
DEBUG | 2023-05-18 22:47:24.129975 | hordelib.cache.cache:__init__:64 - Cache dir: ./nataili/embeds/ViT-L_14/image
DEBUG | 2023-05-18 22:47:24.166874 | worker.csam:check_for_csam:369 - Similarity Result after 0.036801815032958984 seconds - Result = False
DEBUG | 2023-05-18 22:47:24.167054 | worker.jobs.stable_diffusion:start_job:277 - Post-processing with RealESRGAN_x4plus_anime_6B...
INFO | 2023-05-18 22:47:24.167184 | hordelib.comfy_horde:run_pipeline:469 - Running pipeline image_upscale
DEBUG | 2023-05-18 22:47:24.167266 | hordelib.comfy_horde:reconnect_input:424 - Request to reconnect input sampler.latent_image to output vae_encode
DEBUG | 2023-05-18 22:47:24.167320 | hordelib.comfy_horde:reconnect_input:428 - Can not reconnect input sampler.latent_image to vae_encode as vae_encode does not exist
DEBUG | 2023-05-18 22:47:24.167378 | hordelib.comfy_horde:_set:415 - Attempt to set parameter CREATED parameter 'model_loader.model_manager'
DEBUG | 2023-05-18 22:47:24.167644 | hordelib.comfy_horde:send_sync:455 - execution_start, {'prompt_id': '864abba9-ef99-4e3f-91ea-8cd1758ab0d5'}, 864abba9-ef99-4e3f-91ea-8cd1758ab0d5
DEBUG | 2023-05-18 22:47:24.167729 | hordelib.comfy_horde:send_sync:455 - execution_cached, {'nodes': [], 'prompt_id': '864abba9-ef99-4e3f-91ea-8cd1758ab0d5'}, 864abba9-ef99-4e3f-91ea-8cd1758ab0d5
DEBUG | 2023-05-18 22:47:24.167798 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'model_loader', 'prompt_id': '864abba9-ef99-4e3f-91ea-8cd1758ab0d5'}, 864abba9-ef99-4e3f-91ea-8cd1758ab0d5
DEBUG | 2023-05-18 22:47:24.167857 | /home/gray/source/AI-Horde-Worker/conda/envs/linux/lib/python3.10/site-packages/hordelib/nodes/node_upscale_model_loader:load_model:20 - Loading model RealESRGAN_x4plus_anime_6B through our custom node
DEBUG | 2023-05-18 22:47:24.167934 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'image_loader', 'prompt_id': '864abba9-ef99-4e3f-91ea-8cd1758ab0d5'}, 864abba9-ef99-4e3f-91ea-8cd1758ab0d5
DEBUG | 2023-05-18 22:47:24.168674 | hordelib.comfy_horde:send_sync:455 - executing, {'node': '3', 'prompt_id': '864abba9-ef99-4e3f-91ea-8cd1758ab0d5'}, 864abba9-ef99-4e3f-91ea-8cd1758ab0d5
DEBUG | 2023-05-18 22:47:24.758123 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'output_image', 'prompt_id': '864abba9-ef99-4e3f-91ea-8cd1758ab0d5'}, 864abba9-ef99-4e3f-91ea-8cd1758ab0d5
DEBUG | 2023-05-18 22:47:25.110441 | hordelib.comfy_horde:send_sync:453 - Received output image(s) from comfyui
DEBUG | 2023-05-18 22:47:25.110622 | hordelib.comfy_horde:send_sync:455 - executing, {'node': None, 'prompt_id': '864abba9-ef99-4e3f-91ea-8cd1758ab0d5'}, 864abba9-ef99-4e3f-91ea-8cd1758ab0d5
DEBUG | 2023-05-18 22:47:25.227634 | worker.jobs.stable_diffusion:start_job:277 - Post-processing with CodeFormers...
INFO | 2023-05-18 22:47:25.227836 | hordelib.comfy_horde:run_pipeline:469 - Running pipeline image_facefix
DEBUG | 2023-05-18 22:47:25.227935 | hordelib.comfy_horde:reconnect_input:424 - Request to reconnect input sampler.latent_image to output vae_encode
DEBUG | 2023-05-18 22:47:25.227999 | hordelib.comfy_horde:reconnect_input:428 - Can not reconnect input sampler.latent_image to vae_encode as vae_encode does not exist
DEBUG | 2023-05-18 22:47:25.228066 | hordelib.comfy_horde:_set:415 - Attempt to set parameter CREATED parameter 'model_loader.model_manager'
DEBUG | 2023-05-18 22:47:25.228348 | hordelib.comfy_horde:send_sync:455 - execution_start, {'prompt_id': '3d74276c-50a1-45e7-9312-656c0de49eb1'}, 3d74276c-50a1-45e7-9312-656c0de49eb1
DEBUG | 2023-05-18 22:47:25.228459 | hordelib.comfy_horde:send_sync:455 - execution_cached, {'nodes': [], 'prompt_id': '3d74276c-50a1-45e7-9312-656c0de49eb1'}, 3d74276c-50a1-45e7-9312-656c0de49eb1
DEBUG | 2023-05-18 22:47:25.228536 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'model_loader', 'prompt_id': '3d74276c-50a1-45e7-9312-656c0de49eb1'}, 3d74276c-50a1-45e7-9312-656c0de49eb1
DEBUG | 2023-05-18 22:47:25.228612 | /home/gray/source/AI-Horde-Worker/conda/envs/linux/lib/python3.10/site-packages/hordelib/nodes/node_upscale_model_loader:load_model:20 - Loading model CodeFormers through our custom node
DEBUG | 2023-05-18 22:47:25.228721 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'image_loader', 'prompt_id': '3d74276c-50a1-45e7-9312-656c0de49eb1'}, 3d74276c-50a1-45e7-9312-656c0de49eb1
DEBUG | 2023-05-18 22:47:25.301300 | hordelib.comfy_horde:send_sync:455 - executing, {'node': '8', 'prompt_id': '3d74276c-50a1-45e7-9312-656c0de49eb1'}, 3d74276c-50a1-45e7-9312-656c0de49eb1
DEBUG | 2023-05-18 22:47:25.858860 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'output_image', 'prompt_id': '3d74276c-50a1-45e7-9312-656c0de49eb1'}, 3d74276c-50a1-45e7-9312-656c0de49eb1
DEBUG | 2023-05-18 22:47:26.186945 | hordelib.comfy_horde:send_sync:453 - Received output image(s) from comfyui
DEBUG | 2023-05-18 22:47:26.187120 | hordelib.comfy_horde:send_sync:455 - executing, {'node': None, 'prompt_id': '3d74276c-50a1-45e7-9312-656c0de49eb1'}, 3d74276c-50a1-45e7-9312-656c0de49eb1
DEBUG | 2023-05-18 22:47:26.311816 | worker.jobs.stable_diffusion:start_job:277 - Post-processing with GFPGAN...
INFO | 2023-05-18 22:47:26.312030 | hordelib.comfy_horde:run_pipeline:469 - Running pipeline image_facefix
DEBUG | 2023-05-18 22:47:26.312132 | hordelib.comfy_horde:reconnect_input:424 - Request to reconnect input sampler.latent_image to output vae_encode
DEBUG | 2023-05-18 22:47:26.312193 | hordelib.comfy_horde:reconnect_input:428 - Can not reconnect input sampler.latent_image to vae_encode as vae_encode does not exist
DEBUG | 2023-05-18 22:47:26.312257 | hordelib.comfy_horde:_set:415 - Attempt to set parameter CREATED parameter 'model_loader.model_manager'
DEBUG | 2023-05-18 22:47:26.312557 | hordelib.comfy_horde:send_sync:455 - execution_start, {'prompt_id': '55f4c77e-a105-45ab-9ad1-73a3effe840e'}, 55f4c77e-a105-45ab-9ad1-73a3effe840e
DEBUG | 2023-05-18 22:47:26.312670 | hordelib.comfy_horde:send_sync:455 - execution_cached, {'nodes': [], 'prompt_id': '55f4c77e-a105-45ab-9ad1-73a3effe840e'}, 55f4c77e-a105-45ab-9ad1-73a3effe840e
DEBUG | 2023-05-18 22:47:26.312771 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'model_loader', 'prompt_id': '55f4c77e-a105-45ab-9ad1-73a3effe840e'}, 55f4c77e-a105-45ab-9ad1-73a3effe840e
DEBUG | 2023-05-18 22:47:26.312855 | /home/gray/source/AI-Horde-Worker/conda/envs/linux/lib/python3.10/site-packages/hordelib/nodes/node_upscale_model_loader:load_model:20 - Loading model GFPGAN through our custom node
DEBUG | 2023-05-18 22:47:26.312934 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'image_loader', 'prompt_id': '55f4c77e-a105-45ab-9ad1-73a3effe840e'}, 55f4c77e-a105-45ab-9ad1-73a3effe840e
DEBUG | 2023-05-18 22:47:26.386555 | hordelib.comfy_horde:send_sync:455 - executing, {'node': '8', 'prompt_id': '55f4c77e-a105-45ab-9ad1-73a3effe840e'}, 55f4c77e-a105-45ab-9ad1-73a3effe840e
DEBUG | 2023-05-18 22:47:26.935303 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'output_image', 'prompt_id': '55f4c77e-a105-45ab-9ad1-73a3effe840e'}, 55f4c77e-a105-45ab-9ad1-73a3effe840e
DEBUG | 2023-05-18 22:47:27.263055 | hordelib.comfy_horde:send_sync:453 - Received output image(s) from comfyui
DEBUG | 2023-05-18 22:47:27.263256 | hordelib.comfy_horde:send_sync:455 - executing, {'node': None, 'prompt_id': '55f4c77e-a105-45ab-9ad1-73a3effe840e'}, 55f4c77e-a105-45ab-9ad1-73a3effe840e
DEBUG | 2023-05-18 22:47:27.387675 | worker.jobs.stable_diffusion:start_job:294 - post-processing done...
DEBUG | 2023-05-18 22:47:27.390325 | worker.jobs.framework:start_submit_thread:86 - Finished job in threadpool
DEBUG | 2023-05-18 22:47:27.407690 | worker.workers.framework:check_running_job_status:170 - Job finished successfully in 10.437s (Total Completed: 8)
DEBUG | 2023-05-18 22:47:28.089355 | worker.jobs.stable_diffusion:prepare_submit_payload:339 - R2 Upload response: <Response [200]>
DEBUG | 2023-05-18 22:47:28.092322 | worker.jobs.framework:submit_job:111 - posting payload with size of 0.1 kb
DEBUG | 2023-05-18 22:47:28.499865 | worker.jobs.poppers:horde_pop:40 - Job pop took 1.069792 (node: kai:7002:4.14.0)
DEBUG | 2023-05-18 22:47:28.504502 | worker.workers.framework:start_job:139 - New job processing
DEBUG | 2023-05-18 22:47:28.504631 | worker.jobs.stable_diffusion:start_job:52 - Starting job in threadpool for model: Deliberate
DEBUG | 2023-05-18 22:47:28.504771 | worker.jobs.stable_diffusion:start_job:62 - ViT-L/14 model loaded
DEBUG | 2023-05-18 22:47:28.504876 | worker.jobs.stable_diffusion:start_job:186 - txt2img (Deliberate) request with id 98bb63ad-ae66-450f-b02d-8964482fdd27 picked up. Initiating work...
INFO | 2023-05-18 22:47:28.504944 | worker.jobs.stable_diffusion:start_job:204 - Starting generation for id 98bb63ad-ae66-450f-b02d-8964482fdd27: Deliberate @ 512x512 for 50 steps k_euler. Prompt length is 59 characters And it appears to contain 0 weights
WARNING | 2023-05-18 22:47:28.505080 | hordelib.comfy_horde:run_image_pipeline:562 - No job ran for 1.118 seconds
INFO | 2023-05-18 22:47:28.505160 | hordelib.comfy_horde:run_pipeline:469 - Running pipeline stable_diffusion
DEBUG | 2023-05-18 22:47:28.505291 | hordelib.comfy_horde:_set:415 - Attempt to set parameter CREATED parameter 'model_loader.model_manager'
DEBUG | 2023-05-18 22:47:28.506890 | hordelib.comfy_horde:send_sync:455 - execution_start, {'prompt_id': 'adb01794-173e-4ae9-bc8d-b5f9a449824e'}, adb01794-173e-4ae9-bc8d-b5f9a449824e
DEBUG | 2023-05-18 22:47:28.507273 | hordelib.comfy_horde:send_sync:455 - execution_cached, {'nodes': [], 'prompt_id': 'adb01794-173e-4ae9-bc8d-b5f9a449824e'}, adb01794-173e-4ae9-bc8d-b5f9a449824e
DEBUG | 2023-05-18 22:47:28.507503 | hordelib.comfy_horde:send_sync:455 - executing, {'node': 'model_loader', 'prompt_id': 'adb01794-173e-4ae9-bc8d-b5f9a449824e'}, adb01794-173e-4ae9-bc8d-b5f9a449824e
DEBUG | 2023-05-18 22:47:28.507686 | /home/gray/source/AI-Horde-Worker/conda/envs/linux/lib/python3.10/site-packages/hordelib/nodes/node_model_loader:load_checkpoint:32 - Loading model Deliberate through our custom node
INFO | 2023-05-18 22:47:28.507862 | /home/gray/source/AI-Horde-Worker/conda/envs/linux/lib/python3.10/site-packages/hordelib/nodes/node_model_loader:load_checkpoint:50 - Loading from disk cache model Deliberate
DEBUG | 2023-05-18 22:47:28.701817 | worker.jobs.framework:submit_job:120 - Upload completed in 0.608674
INFO | 2023-05-18 22:47:28.702108 | worker.jobs.framework:submit_job:157 - Submitted job with id ffe15043-b8c8-4803-8c90-c738e41ebdc7 and contributed for 16.7. Job took 11.7 seconds since queued and 11.7 since start.
DEBUG | 2023-05-18 22:47:30.422808 | hordelib.model_manager.base:ensure_ram_available:208 - Free RAM is: 691 MB, (2 models loaded in RAM)
DEBUG | 2023-05-18 22:47:30.423061 | hordelib.model_manager.base:ensure_ram_available:212 - Not enough free RAM attempting to free some
DEBUG | 2023-05-18 22:47:30.423447 | hordelib.model_manager.base:ensure_ram_available:245 - Moving model Anything Diffusion to disk to free up RAM
DEBUG | 2023-05-18 22:47:30.423594 | hordelib.model_manager.base:validate_model:506 - Validating Anything Diffusion with 2 files
DEBUG | 2023-05-18 22:47:30.423664 | hordelib.model_manager.base:validate_model:507 - [{'path': 'Anything-Diffusion.ckpt', 'md5sum': '01a4fdec28cdb58e26246913871ff4a8', 'sha256sum': '633c153d96230355efb4230da6ae2e3ba85b084b93c89eb88cb1118d6cc06cef'}, {'path': 'v1-inference.yaml'}]
DEBUG | 2023-05-18 22:47:30.424029 | hordelib.model_manager.base:validate_file:612 - Getting sha256sum of ./nataili/compvis/Anything-Diffusion.ckpt
DEBUG | 2023-05-18 22:47:30.424427 | hordelib.model_manager.base:validate_file:615 - sha256sum: 633c153d96230355efb4230da6ae2e3ba85b084b93c89eb88cb1118d6cc06cef
DEBUG | 2023-05-18 22:47:30.424505 | hordelib.model_manager.base:validate_file:616 - Expected: 633c153d96230355efb4230da6ae2e3ba85b084b93c89eb88cb1118d6cc06cef
DEBUG | 2023-05-18 22:47:30.424571 | hordelib.model_manager.base:free_model_resources:474 - Received request to free model memory resources for Anything Diffusion
DEBUG | 2023-05-18 22:47:30.424629 | hordelib.comfy_horde:remove_model_from_memory:82 - Comfy_Horde received request to unload Anything Diffusion
DEBUG | 2023-05-18 22:47:30.424685 | hordelib.comfy_horde:remove_model_from_memory:85 - Model Anything Diffusion queued for GPU/RAM unload
DEBUG | 2023-05-18 22:47:30.424747 | hordelib.comfy_horde:cleanup:61 - Unloading Anything Diffusion from GPU
We lost it somewhere.
Due to the lora.json file being built locally, and it relying on being in the site-packages folder (a legacy behavior which wasn't a problem where all the other model references were downloaded from a remote on launch) the lora.json file was reliably deleted on reinstalling the package, such as when running update-runtime on the worker.
The lora being a rolling cache, these factors led to the net effect of frustrating users by deleting the downloaded loras, sometimes many dozens of gigabytes, which the user may have to downloaded again, needlessly.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}