gwuhaolin / blog Goto Github PK
View Code? Open in Web Editor NEW浩的技术博客
Home Page: https://wuhaolin.cn
浩的技术博客
Home Page: https://wuhaolin.cn


![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")








































































































































































































本文将教你从0写一个Shadowsocks,无需任何基础,读完本文你就能完成一个轻量级、高性能的 Shadowsocks 代替品。
我们暂且把最终完成的项目叫做 Lightsocks,如果你很急切地想看到结果,可以先体验本文最终完成的项目 Lightsocks ,也可以下载阅读源码。
Shadowsocks 是一个能骗过防火墙的网络代理工具。它把要传输的原数据经过加密后再传输,网络中的防火墙由于得不出要传输的原内容是什么而只好放行,于是就完成了防火墙穿透,也即是所谓的“翻墙”。
在自由的网络环境下,在本机上访问服务时是直接和远程服务建立连接传输数据,流程如图:

但在受限的网络环境下会有防火墙,本机电脑和远程服务之间传输的数据都必须通过防火墙的检查,流程如图:

如果防火墙发现你在传输受限的内容,就把拦截本次传输,就会导致在本机无法访问远程服务。
而 Shadowsocks 所做的就是把传输的数据加密,防火墙得到的数据是加密后的数据,防火墙不知道传输的原内容是什么,于是防火墙就放行本次请求,于是在本机就访问到了远程服务,流程如图:
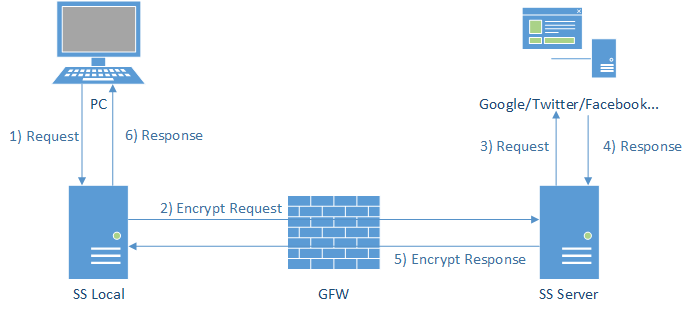
也就是说使用 Shadowsocks 的前提是:
Shadowsocks 由两部分组成,运行在本地的 ss-local 和运行在防火墙之外服务器上的 ss-server,下面来分别详细介绍它们的职责(以下对 Shadowsocks 原理的解析只是我的大概估计,可能会有细微的差别)。
ss-local 的职责是在本机启动和监听着一个服务,本地软件的网络请求都先发送到 ss-local,ss-local 收到来自本地软件的网络请求后,把要传输的原数据根据用户配置的加密方法和密码进行加密,再转发到墙外的服务器去。
ss-server 的职责是在墙外服务器启动和监听一个服务,该服务监听来自本机的 ss-local 的请求。在收到来自 ss-local 转发过来的数据时,会先根据用户配置的加密方法和密码对数据进行对称解密,以获得加密后的数据的原内容。同时还会解 SOCKS5 协议,读出本次请求真正的目标服务地址(例如 Google 服务器地址),再把解密后得到的原数据转发到真正的目标服务。
当真正的目标服务返回了数据时,ss-server 端会把返回的数据加密后转发给对应的 ss-local 端,ss-local 端收到数据再解密后,转发给本机的软件。这是一个对称相反的过程。
由于 ss-local 和 ss-server 端都需要用对称加密算法对数据进行加密和解密,因此这两端的加密方法和密码必须配置为一样。Shadowsocks 提供了一系列标准可靠的对称算法可供用户选择,例如 rc4、aes、des、chacha20 等等。Shadowsocks 对数据加密后再传输的目的是为了混淆原数据,让途中的防火墙无法得出传输的原数据。但其实用这些安全性高计算量大的对称加密算法去实现混淆有点“杀鸡用牛刀”。
Shadowsocks 的数据传输是建立在 SOCKS5 协议之上的,SOCKS5 是 TCP/IP 层面的网络代理协议。
ss-server 端解密出来的数据就是采用 SOCKS5 协议封装的,通过 SOCKS5 协议 ss-server 端能读出本机软件想访问的服务的真正地址以及要传输的原数据,下面来详细介绍 SOCKS5 协议的通信细节。
客户端向服务端连接连接,客户端发送的数据包如下:
| VER | NMETHODS | METHODS |
|---|---|---|
| 1 | 1 | 1 |
其中各个字段的含义如下:
-VER:代表 SOCKS 的版本,SOCKS5 默认为0x05,其固定长度为1个字节;
-NMETHODS:表示第三个字段METHODS的长度,它的长度也是1个字节;
-METHODS:表示客户端支持的验证方式,可以有多种,他的长度是1-255个字节。
目前支持的验证方式共有:
0x00:NO AUTHENTICATION REQUIRED(不需要验证)0x01:GSSAPI0x02:USERNAME/PASSWORD(用户名密码)0x03: to X'7F' IANA ASSIGNED0x80: to X'FE' RESERVED FOR PRIVATE METHODS0xFF: NO ACCEPTABLE METHODS(都不支持,没法连接了)服务端收到客户端的验证信息之后,就要回应客户端,服务端需要客户端提供哪种验证方式的信息。服务端回应的包格式如下:
| VER | METHOD |
|---|---|
| 1 | 1 |
其中各个字段的含义如下:
VER:代表 SOCKS 的版本,SOCKS5 默认为0x05,其固定长度为1个字节;METHOD:代表服务端需要客户端按此验证方式提供的验证信息,其值长度为1个字节,可为上面六种验证方式之一。举例说明,比如服务端不需要验证的话,可以这么回应客户端:
| VER | METHOD |
|---|---|
0x05 |
0x00 |
客户端发起的连接由服务端验证通过后,客户端下一步应该告诉真正目标服务的地址给服务器,服务器得到地址后再去请求真正的目标服务。也就是说客户端需要把 Google 服务的地址google.com:80告诉服务端,服务端再去请求google.com:80。
目标服务地址的格式为 (IP或域名)+端口,客户端需要发送的包格式如下:
| VER | CMD | RSV | ATYP | DST.ADDR | DST.PORT |
|---|---|---|---|---|---|
| 1 | 1 | 0x00 |
1 | Variable | 2 |
各个字段的含义如下:
VER:代表 SOCKS 协议的版本,SOCKS 默认为0x05,其值长度为1个字节;CMD:代表客户端请求的类型,值长度也是1个字节,有三种类型;
CONNECT: 0x01;BIND: 0x02;UDP: ASSOCIATE 0x03;RSV:保留字,值长度为1个字节;ATYP:代表请求的远程服务器地址类型,值长度1个字节,有三种类型;
IPV4: address: 0x01;DOMAINNAME: 0x03;IPV6: address: 0x04;DST.ADDR:代表远程服务器的地址,根据 ATYP 进行解析,值长度不定;DST.PORT:代表远程服务器的端口,要访问哪个端口的意思,值长度2个字节。服务端在得到来自客户端告诉的目标服务地址后,便和目标服务进行连接,不管连接成功与否,服务器都应该把连接的结果告诉客户端。在连接成功的情况下,服务端返回的包格式如下:
| VER | REP | RSV | ATYP | BND.ADDR | BND.PORT |
|---|---|---|---|---|---|
| 1 | 1 | 0x00 |
1 | Variable | 2 |
各个字段的含义如下:
VER:代表 SOCKS 协议的版本,SOCKS 默认为0x05,其值长度为1个字节;0x00 succeeded0x01 general SOCKS server failure0x02 connection not allowed by ruleset0x03 Network unreachable0x04 Host unreachable0x05 Connection refused0x06 TTL expired0x07 Command not supported0x08 Address type not supported0x09 to 0xFF unassignedRSV:保留字,值长度为1个字节ATYP:代表请求的远程服务器地址类型,值长度1个字节,有三种类型
0x010x030x04BND.ADDR:表示绑定地址,值长度不定。BND.PORT: 表示绑定端口,值长度2个字节客户端在收到来自服务器成功的响应后,就会开始发送数据了,服务端在收到来自客户端的数据后,会转发到目标服务。
SOCKS5 协议的目的其实就是为了把来自原本应该在本机直接请求目标服务的流程,放到了服务端去代理客户端访问。
其运行流程总结如下:
以上内容来自 SOCKS5 协议规范 rfc1928。
要实现 Lightsocks 需要实现两部分:运行在本地的 lightsocks-local,和运行在墙外代理服务器上 lightsocks-server。
下面来分别教你如果使用 Golang 来实现它们,采用 Golang 语言的原因在于:性能好、跨平台、适合高并发、学习门槛低。对Golang感兴趣?请看Golang 中文学习资料汇总
在 Shadowsocks 中是采用的标准的对称加密算法去实现数据混淆的,对称算法在加密和解密过程中需要大量计算。
为了简单起见,Lightsocks 将采用最简单高效的方法去实现数据混淆,具体原理如下。
这个数据混淆算法和对称加密很相似,两端都需要有同样的密钥。
这个密钥有如下要求:
[256]byte;I个的值不能等于I;例如以下为一个合法的密钥(上为索引,下为值):
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 80 | 81 | 82 | 83 | 84 | 85 | 86 | 87 | 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | 100 | 101 | 102 | 103 | 104 | 105 | 106 | 107 | 108 | 109 | 110 | 111 | 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | 120 | 121 | 122 | 123 | 124 | 125 | 126 | 127 | 128 | 129 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | 168 | 169 | 170 | 171 | 172 | 173 | 174 | 175 | 176 | 177 | 178 | 179 | 180 | 181 | 182 | 183 | 184 | 185 | 186 | 187 | 188 | 189 | 190 | 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 204 | 205 | 206 | 207 | 208 | 209 | 210 | 211 | 212 | 213 | 214 | 215 | 216 | 217 | 218 | 219 | 220 | 221 | 222 | 223 | 224 | 225 | 226 | 227 | 228 | 229 | 230 | 231 | 232 | 233 | 234 | 235 | 236 | 237 | 238 | 239 | 240 | 241 | 242 | 243 | 244 | 245 | 246 | 247 | 248 | 249 | 250 | 251 | 252 | 253 | 254 | 255 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 186 | 118 | 82 | 201 | 235 | 236 | 180 | 66 | 228 | 96 | 43 | 90 | 203 | 200 | 34 | 104 | 41 | 222 | 165 | 74 | 240 | 20 | 244 | 67 | 114 | 191 | 220 | 147 | 196 | 183 | 229 | 123 | 208 | 19 | 127 | 187 | 84 | 148 | 56 | 170 | 133 | 160 | 202 | 21 | 53 | 78 | 59 | 64 | 120 | 27 | 167 | 175 | 39 | 10 | 4 | 132 | 89 | 230 | 152 | 73 | 221 | 88 | 141 | 158 | 251 | 79 | 225 | 87 | 14 | 23 | 68 | 250 | 199 | 168 | 218 | 60 | 40 | 169 | 75 | 86 | 153 | 134 | 83 | 49 | 128 | 231 | 217 | 239 | 226 | 177 | 57 | 24 | 234 | 63 | 7 | 112 | 166 | 211 | 254 | 179 | 157 | 215 | 227 | 224 | 233 | 81 | 172 | 26 | 122 | 219 | 48 | 151 | 232 | 50 | 108 | 44 | 0 | 192 | 65 | 76 | 109 | 252 | 248 | 47 | 154 | 33 | 209 | 115 | 31 | 15 | 45 | 206 | 247 | 124 | 77 | 8 | 182 | 144 | 1 | 72 | 131 | 52 | 245 | 198 | 238 | 5 | 188 | 116 | 55 | 216 | 155 | 2 | 178 | 189 | 162 | 136 | 243 | 184 | 58 | 69 | 70 | 99 | 36 | 25 | 35 | 174 | 195 | 18 | 205 | 30 | 190 | 142 | 210 | 113 | 145 | 101 | 97 | 161 | 100 | 91 | 242 | 138 | 93 | 171 | 98 | 237 | 212 | 255 | 80 | 102 | 119 | 204 | 107 | 105 | 111 | 11 | 29 | 146 | 129 | 117 | 135 | 176 | 163 | 207 | 103 | 22 | 246 | 125 | 150 | 106 | 126 | 197 | 249 | 62 | 51 | 193 | 32 | 3 | 110 | 46 | 85 | 71 | 159 | 139 | 12 | 164 | 95 | 121 | 140 | 241 | 253 | 130 | 173 | 213 | 54 | 143 | 16 | 94 | 9 | 61 | 156 | 214 | 28 | 17 | 37 | 42 | 181 | 149 | 185 | 223 | 92 | 38 | 13 | 194 | 6 | 137 |
如果原数据为 [5,0,1,2,3],则采用以上密钥加密后变成 [236,186,118,82,201]。
如果加密后的数据为 [186,118,82,201,235],则采用以上密钥解密得到的原数据为 [0,1,2,3,4]
聪明的你肯定看懂了其中的规律:把1~255 这256个数字确定一种一对一的映射关系,加密是从一个数字得到对应的一个数字,而解密则是反向的过程,而这个密钥的作用正是描述这个映射关系。
这其实就是中学学的反函数。
为什么要这样设计数据混淆算法呢?在数据传输时,数据是以 byte 为最小单位流式传输的。一个 byte 的取值只可能是 0~255。该混淆算法可以直接对一个个 byte 进行加解密,而无需像标准的对称算法那样只能对一大块数据进行加密。
再加上本算法的加解密 N byte 数据的算法复杂度为 N(直接通过数组索引访问),非常适合流式加密。
以上加密算法的安全性怎么样呢?符合以上要求的密钥匙有多少种组合呢?我们来算算:
这其实就是初中学的排列组合中的排列问题,形象点其实就是,把 0~255 个不同编号的人安排到 0~255 个不同编号的坑去,并且不能有编号一样的情况,有多少种排法。
也就是 A(255,255)=255*254*253*...*1=255!,但其中有一半为有重复的情况,
最终结果为 255!/2,
其值大概为 10^500 这个数量级。
以上加密算法虽然破绽很多,但足以实现高效的数据混淆,骗过防火墙。
目前采用对称加密算法实现数据混淆的 Shadowsocks 已经能被一些防火墙通过机器学习算法通过特征分析识别出传输的原内容适合合法,而 Lightsocks 的这套混淆算法目前还不能被轻易的识别出来。
随机产生一个以上密钥匙的代码如下:
package core
import (
"math/rand"
"time"
)
const PasswordLength = 256
type Password [PasswordLength]byte
func init() {
// 更新随机种子,防止生成一样的随机密码
rand.Seed(time.Now().Unix())
}
// 产生 256个byte随机组合的 密码
func RandPassword() *Password {
// 随机生成一个由 0~255 组成的 byte 数组
intArr := rand.Perm(PasswordLength)
password := &Password{}
for i, v := range intArr {
password[i] = byte(v)
if i == v {
// 确保不会出现如何一个byte位出现重复
return RandPassword()
}
}
return password
}对数据进行加密解密的代码如下:
package core
type Cipher struct {
// 编码用的密码
encodePassword *Password
// 解码用的密码
decodePassword *Password
}
// 加密原数据
func (cipher *Cipher) encode(bs []byte) {
for i, v := range bs {
bs[i] = cipher.encodePassword[v]
}
}
// 解码加密后的数据到原数据
func (cipher *Cipher) decode(bs []byte) {
for i, v := range bs {
bs[i] = cipher.decodePassword[v]
}
}
// 新建一个编码解码器
func NewCipher(encodePassword *Password) *Cipher {
decodePassword := &Password{}
for i, v := range encodePassword {
encodePassword[i] = v
decodePassword[v] = byte(i)
}
return &Cipher{
encodePassword: encodePassword,
decodePassword: decodePassword,
}
}再使用以上的 Cipher 去封装一个加密传输的 SecureSocket,以方便直接加解密 TCP Socket 中的流式数据,代码如下:
package core
import (
"errors"
"fmt"
"io"
"net"
)
const (
BufSize = 1024
)
// 加密传输的 TCP Socket
type SecureSocket struct {
Cipher *Cipher
ListenAddr *net.TCPAddr
RemoteAddr *net.TCPAddr
}
// 从输入流里读取加密过的数据,解密后把原数据放到bs里
func (secureSocket *SecureSocket) DecodeRead(conn *net.TCPConn, bs []byte) (n int, err error) {
n, err = conn.Read(bs)
if err != nil {
return
}
secureSocket.Cipher.decode(bs[:n])
return
}
// 把放在bs里的数据加密后立即全部写入输出流
func (secureSocket *SecureSocket) EncodeWrite(conn *net.TCPConn, bs []byte) (int, error) {
secureSocket.Cipher.encode(bs)
return conn.Write(bs)
}
// 从src中源源不断的读取原数据加密后写入到dst,直到src中没有数据可以再读取
func (secureSocket *SecureSocket) EncodeCopy(dst *net.TCPConn, src *net.TCPConn) error {
buf := make([]byte, BufSize)
for {
readCount, errRead := src.Read(buf)
if errRead != nil {
if errRead != io.EOF {
return errRead
} else {
return nil
}
}
if readCount > 0 {
writeCount, errWrite := secureSocket.EncodeWrite(dst, buf[0:readCount])
if errWrite != nil {
return errWrite
}
if readCount != writeCount {
return io.ErrShortWrite
}
}
}
}
// 从src中源源不断的读取加密后的数据解密后写入到dst,直到src中没有数据可以再读取
func (secureSocket *SecureSocket) DecodeCopy(dst *net.TCPConn, src *net.TCPConn) error {
buf := make([]byte, BufSize)
for {
readCount, errRead := secureSocket.DecodeRead(src, buf)
if errRead != nil {
if errRead != io.EOF {
return errRead
} else {
return nil
}
}
if readCount > 0 {
writeCount, errWrite := dst.Write(buf[0:readCount])
if errWrite != nil {
return errWrite
}
if readCount != writeCount {
return io.ErrShortWrite
}
}
}
}
// 和远程的socket建立连接,他们之间的数据传输会加密
func (secureSocket *SecureSocket) DialRemote() (*net.TCPConn, error) {
remoteConn, err := net.DialTCP("tcp", nil, secureSocket.RemoteAddr)
if err != nil {
return nil, errors.New(fmt.Sprintf("连接到远程服务器 %s 失败:%s", secureSocket.RemoteAddr, err))
}
return remoteConn, nil
}这个 SecureSocket 用于 local 端和 server 端之间进行 TCP 通信,并且只使用 SecureSocket 通信时中间传输的数据会被加密,防火墙无法读到原数据。
运行在本机的 local 端的职责是把本机程序发送给它的数据经过加密后转发给墙外的代理服务器,总体工作流程如下:
实现以上功能的 local 端代码如下:
package local
import (
"github.com/gwuhaolin/lightsocks/core"
"log"
"net"
)
type LsLocal struct {
*core.SecureSocket
}
// 新建一个本地端
func New(password *core.Password, listenAddr, remoteAddr *net.TCPAddr) *LsLocal {
return &LsLocal{
SecureSocket: &core.SecureSocket{
Cipher: core.NewCipher(password),
ListenAddr: listenAddr,
RemoteAddr: remoteAddr,
},
}
}
// 本地端启动监听,接收来自本机浏览器的连接
func (local *LsLocal) Listen(didListen func(listenAddr net.Addr)) error {
listener, err := net.ListenTCP("tcp", local.ListenAddr)
if err != nil {
return err
}
defer listener.Close()
if didListen != nil {
didListen(listener.Addr())
}
for {
userConn, err := listener.AcceptTCP()
if err != nil {
log.Println(err)
continue
}
// userConn被关闭时直接清除所有数据 不管没有发送的数据
userConn.SetLinger(0)
go local.handleConn(userConn)
}
return nil
}
func (local *LsLocal) handleConn(userConn *net.TCPConn) {
defer userConn.Close()
proxyServer, err := local.DialRemote()
if err != nil {
log.Println(err)
return
}
defer proxyServer.Close()
// Conn被关闭时直接清除所有数据 不管没有发送的数据
proxyServer.SetLinger(0)
// 进行转发
// 从 proxyServer 读取数据发送到 localUser
go func() {
err := local.DecodeCopy(userConn, proxyServer)
if err != nil {
// 在 copy 的过程中可能会存在网络超时等 error 被 return,只要有一个发生了错误就退出本次工作
userConn.Close()
proxyServer.Close()
}
}()
// 从 localUser 发送数据发送到 proxyServer,这里因为处在翻墙阶段出现网络错误的概率更大
local.EncodeCopy(proxyServer, userConn)
}运行在墙外代理服务器的 server 端职责如下:
实现以上功能的代码如下:
package server
import (
"encoding/binary"
"github.com/gwuhaolin/lightsocks/core"
"log"
"net"
)
type LsServer struct {
*core.SecureSocket
}
// 新建一个服务端
func New(password *core.Password, listenAddr *net.TCPAddr) *LsServer {
return &LsServer{
SecureSocket: &core.SecureSocket{
Cipher: core.NewCipher(password),
ListenAddr: listenAddr,
},
}
}
// 运行服务端并且监听来自本地代理客户端的请求
func (lsServer *LsServer) Listen(didListen func(listenAddr net.Addr)) error {
listener, err := net.ListenTCP("tcp", lsServer.ListenAddr)
if err != nil {
return err
}
defer listener.Close()
if didListen != nil {
didListen(listener.Addr())
}
for {
localConn, err := listener.AcceptTCP()
if err != nil {
log.Println(err)
continue
}
// localConn被关闭时直接清除所有数据 不管没有发送的数据
localConn.SetLinger(0)
go lsServer.handleConn(localConn)
}
return nil
}
// 解 SOCKS5 协议
// https://www.ietf.org/rfc/rfc1928.txt
func (lsServer *LsServer) handleConn(localConn *net.TCPConn) {
defer localConn.Close()
buf := make([]byte, 256)
/**
The localConn connects to the dstServer, and sends a ver
identifier/method selection message:
+----+----------+----------+
|VER | NMETHODS | METHODS |
+----+----------+----------+
| 1 | 1 | 1 to 255 |
+----+----------+----------+
The VER field is set to X'05' for this ver of the protocol. The
NMETHODS field contains the number of method identifier octets that
appear in the METHODS field.
*/
// 第一个字段VER代表Socks的版本,Socks5默认为0x05,其固定长度为1个字节
_, err := lsServer.DecodeRead(localConn, buf)
// 只支持版本5
if err != nil || buf[0] != 0x05 {
return
}
/**
The dstServer selects from one of the methods given in METHODS, and
sends a METHOD selection message:
+----+--------+
|VER | METHOD |
+----+--------+
| 1 | 1 |
+----+--------+
*/
// 不需要验证,直接验证通过
lsServer.EncodeWrite(localConn, []byte{0x05, 0x00})
/**
+----+-----+-------+------+----------+----------+
|VER | CMD | RSV | ATYP | DST.ADDR | DST.PORT |
+----+-----+-------+------+----------+----------+
| 1 | 1 | X'00' | 1 | Variable | 2 |
+----+-----+-------+------+----------+----------+
*/
// 获取真正的远程服务的地址
n, err := lsServer.DecodeRead(localConn, buf)
// n 最短的长度为7 情况为 ATYP=3 DST.ADDR占用1字节 值为0x0
if err != nil || n < 7 {
return
}
// CMD代表客户端请求的类型,值长度也是1个字节,有三种类型
// CONNECT X'01'
if buf[1] != 0x01 {
// 目前只支持 CONNECT
return
}
var dIP []byte
// aType 代表请求的远程服务器地址类型,值长度1个字节,有三种类型
switch buf[3] {
case 0x01:
// IP V4 address: X'01'
dIP = buf[4 : 4+net.IPv4len]
case 0x03:
// DOMAINNAME: X'03'
ipAddr, err := net.ResolveIPAddr("ip", string(buf[5:n-2]))
if err != nil {
return
}
dIP = ipAddr.IP
case 0x04:
// IP V6 address: X'04'
dIP = buf[4 : 4+net.IPv6len]
default:
return
}
dPort := buf[n-2:]
dstAddr := &net.TCPAddr{
IP: dIP,
Port: int(binary.BigEndian.Uint16(dPort)),
}
// 连接真正的远程服务
dstServer, err := net.DialTCP("tcp", nil, dstAddr)
if err != nil {
return
} else {
defer dstServer.Close()
// Conn被关闭时直接清除所有数据 不管没有发送的数据
dstServer.SetLinger(0)
// 响应客户端连接成功
/**
+----+-----+-------+------+----------+----------+
|VER | REP | RSV | ATYP | BND.ADDR | BND.PORT |
+----+-----+-------+------+----------+----------+
| 1 | 1 | X'00' | 1 | Variable | 2 |
+----+-----+-------+------+----------+----------+
*/
// 响应客户端连接成功
lsServer.EncodeWrite(localConn, []byte{0x05, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00})
}
// 进行转发
// 从 localUser 读取数据发送到 dstServer
go func() {
err := lsServer.DecodeCopy(dstServer, localConn)
if err != nil {
// 在 copy 的过程中可能会存在网络超时等 error 被 return,只要有一个发生了错误就退出本次工作
localConn.Close()
dstServer.Close()
}
}()
// 从 dstServer 读取数据发送到 localUser,这里因为处在翻墙阶段出现网络错误的概率更大
lsServer.EncodeCopy(localConn, dstServer)
}以上就是实现一个轻量级 Shadowsocks 的核心代码。其它一些零碎的代码,例如启动入口、配置读写等,可以去 lightsocks 项目中阅读完整代码。
在聊原理之前先了解下qiankun提供的能力,一句话介绍qiankun功能:
能根据路由自动调度子应用并实现沙箱(主子、子子应用之间的JS和CSS)隔离。
举个例子:在主应用里注册两个子应用A&B,
import { registerMicroApps } from 'qiankun';
registerMicroApps([
{
name: 'A',
entry: 'https://baidu.com',
container: '#yourContainer',
activeRule: '/baidu',
},
{
name: 'B',
entry: 'https://google.com',
container: '#yourContainer2',
activeRule: '/google',
},
]);在pathname是_/baidu_时加载和运行子应用A,如果路由pushState到了_/google_时会unmount子应用A再加载和运行子应用B。
从上面的例子可以看出qiankun提供的能力可以划分为3大部分:

下面分别拆解来分析原理。
一句话介绍single-spa:根据路由变化做子应用调度(子应用生命周期管理)

以单个子应用的生命周期来看流程如下:

singleSpa.registerApplication({ // 注册一个子应用,注册其他子应用同理
name: 'taobao', // 子应用名,需要唯一
app: () => System.import('taobao'), // 如何拿到子应用的生命周期,这里demo用的System,qiankun实际上不是基于System
activeWhen: '/appName', // url 匹配规则,表示啥时候开始走这个子应用的生命周期
customProps: {} // 自定义 props,从子应用的 bootstrap, mount, unmount 回调可以拿到
})子应用在自己的入口 js导出了生命周期函数钩子,那在切换路由时子应用A的unmount会执行,子应用B的mount会执行。针对React体系的子应用通常在各生命周期中做如下事情:
/**
* bootstrap 只会在微应用初始化的时候调用一次,下次微应用重新进入时会直接调用 mount 钩子,不会再重复触发 bootstrap。
* 通常我们可以在这里做一些全局变量的初始化,比如不会在 unmount 阶段被销毁的应用级别的缓存等。
*/
export async function bootstrap() {
console.log('react app bootstraped');
}
/**
* 应用每次进入都会调用 mount 方法,通常我们在这里触发应用的渲染方法
*/
export async function mount(props) {
ReactDOM.render(<App />, props.container ? props.container.querySelector('#root') : document.getElementById('root'));
}
/**
* 应用每次 切出/卸载 会调用的方法,通常在这里我们会卸载微应用的应用实例
*/
export async function unmount(props) {
ReactDOM.unmountComponentAtNode(
props.container ? props.container.querySelector('#root') : document.getElementById('root'),
);
}一句话介绍html-entry-loader:把HTML当作子应用的manifest,加载和执行其中的JS拿到JS导出的模块,加载拿到其中的CSS。

特别说明:
importHTML('https://xxx.com/subApp.html')
.then(res => {
res.execScripts(proxy = window /*传入沙箱,默认全局window*/).then(exports => {
console.log(exports); // 导出的JS模块,子应用生命周期从这里拿
});
res.getExternalStyleSheets() // Promise<string[]> 获取导出的CSS内容
});主应用需要拿到运行一个子应用所需要的信息,包括:JS、CSS、mountId。
除能用HTML作为载体之外,还有一种方式是通过一个JSON来描述,类似这样:
{
"version": "1.3.1",
"js": ["main.js", "common.js"],
"css": ["main.css"],
"publicPath": "https://cdn.cn/appXXX",
"mountId": "root"
}这两种方式各有千秋:
| 优点 | 缺点 |
|---|---|
| 完全兼容原来就是以HTML方式输出的网页更灵活,支持HTML中内敛的JS、CSS等复用已有的公知的HTML规范作为协议,而不是新创造一种协议 | 存在信息冗余,传输体积大于JSON解析HTML耗时大于解析JSON |
| 协议更简单,传输和解析更快 | 操作了一种新协议、规范,需要接入方按此新规范去改造适配,推广成本上升不够灵活 |
选择HTML最主要的原因是 “复用已有的公知的HTML规范作为协议,而不是新创造一种协议”,因为一个子应用可能需要在多个站点投放、或者需要独立运行。
通过正则表达式提取,源码里枚举了各种可能的情况下的正则提取式:
const ALL_SCRIPT_REGEX = /(<script[\s\S]*?>)[\s\S]*?<\/script>/gi;
const SCRIPT_TAG_REGEX = /<(script)\s+((?!type=('|")text\/ng-template\3).)*?>.*?<\/\1>/is;
const SCRIPT_SRC_REGEX = /.*\ssrc=('|")?([^>'"\s]+)/;
const SCRIPT_TYPE_REGEX = /.*\stype=('|")?([^>'"\s]+)/;
const SCRIPT_ENTRY_REGEX = /.*\sentry\s*.*/;
const SCRIPT_ASYNC_REGEX = /.*\sasync\s*.*/;
const SCRIPT_NO_MODULE_REGEX = /.*\snomodule\s*.*/;
const SCRIPT_MODULE_REGEX = /.*\stype=('|")?module('|")?\s*.*/;
const LINK_TAG_REGEX = /<(link)\s+.*?>/isg;
const STYLE_TAG_REGEX = /<style[^>]*>[\s\S]*?<\/style>/gi;
const STYLE_TYPE_REGEX = /\s+rel=('|")?stylesheet\1.*/;
const STYLE_HREF_REGEX = /.*\shref=('|")?([^>'"\s]+)/;function getExecutableScript(scriptSrc, scriptText, proxy, strictGlobal) {
const sourceUrl = isInlineCode(scriptSrc) ? '' : `//# sourceURL=${scriptSrc}\n`;
// 通过这种方式获取全局 window,因为 script 也是在全局作用域下运行的,所以我们通过 window.proxy 绑定时也必须确保绑定到全局 window 上
// 否则在嵌套场景下, window.proxy 设置的是内层应用的 window,而代码其实是在全局作用域运行的,会导致闭包里的 window.proxy 取的是最外层的微应用的 proxy
const globalWindow = (0, eval)('window');
globalWindow.proxy = proxy;
// TODO 通过 strictGlobal 方式切换 with 闭包,待 with 方式坑趟平后再合并
return strictGlobal
? `;(function(window, self, globalThis){with(window){;${scriptText}\n${sourceUrl}}}).bind(window.proxy)(window.proxy, window.proxy, window.proxy);`
: `;(function(window, self, globalThis){;${scriptText}\n${sourceUrl}}).bind(window.proxy)(window.proxy, window.proxy, window.proxy);`;
}with的初衷是为了避免冗余的对象调用:
foo.bar.baz.x = 1;
foo.bar.baz.y = 2;
foo.bar.baz.z = 3;
with(foo.bar.baz){
x = 1;
y = 2;
z = 3;
}const evalCache = {};
export function evalCode(scriptSrc, code) {
const key = scriptSrc;
if (!evalCache[key]) {
const functionWrappedCode = `window.__TEMP_EVAL_FUNC__ = function(){${code}}`;
(0, eval)(functionWrappedCode);
evalCache[key] = window.__TEMP_EVAL_FUNC__;
delete window.__TEMP_EVAL_FUNC__;
}
const evalFunc = evalCache[key];
evalFunc.call(window);
}JS隔离是qiankun最核心最复杂的部分。JS隔离需要实现的目标是:
问:沙箱会做避免主应用对子应用A的window污染么? 答:不会,启动一个子应用时,子应用的window继承自主应用
| 不同的JS沙箱实现 | 原理简介 | 优点 | 缺点 | 开启方法 |
|---|---|---|---|---|
| ProxySandbox | 基于Proxy API实现 | 隔离性和性能较好 | 浏览器兼容性问题,依赖无法polyfill的Proxy API | sanbox = true |
| SnapshotSandbox | 基于diff算法实现 | 性能低,只支持单例子应用隔离作用有限 | 浏览器兼容性好,支持IE11 | 用于不支持 Proxy 的低版本浏览器降级使用 |
| LegacySandbox | 基于Proxy API实现,现已废弃不推荐使用 | 中间产物 | 中间产物 | singular = true |
拦截对window上字段的读&写,每个子应用一个沙箱(一个fakewindow),子应用对window读&写实际是对fakewindow的读写。

const fakewindow = new ProxySandbox(); // 给子应用分配的代理window变量
((window) => {
with(window){
子应用代码
}
})(fakewindow);子应用代码中对window的读写,实际上变成了对subAppProxy的读写。
把主应用的 window 对象做浅拷贝,将 window 的键值对存成一个 Hash Map。之后无论微应用对 window 做任何改动,当要在恢复环境时,把这个 Hash Map 又应用到 window 上就可以了。
微应用 mount 时:
微应用 unmount 时
你的JS里有诸如 document.body.appendChild(scriptElement) 这样的代码,会动态往DOM里面插入JS,如果不处理这些JS会在主应用的 window 上执行可能污染真正的window。
为此,沙箱还会拦截appendChild方法,凡是子应用中appendChild进去的JS都会被fetch下来去沙箱里面执行。

https://github.com/umijs/qiankun/blob/master/src/sandbox/patchers/dynamicAppend/common.ts#L396
qiankun提供以下三种隔离样式的方式
| CSS隔离实现方式 | 原理简介 | 优点 | 缺点 | 开启方法 |
|---|---|---|---|---|
| CSS生命周期管理 | 子应用之间切换时,是会自动做子应用CSS的加载和卸载的,防止子应用A的CSS代入到子应用B中 | 无额外性能开销兼容性好 | 只能做子应用之间切换时的隔离,无法做主子、并发子的隔离 | 内置逻辑全程开启无法关闭 |
| Scopted Style | 给子应用套一层特殊选择器的div修改子应用CSS选择器前缀 | 能做到主子、并发子的隔离 | 提升CSS选择器复杂性,降低页面性能 | experimentalStyleIsolation |
| Shadow DOM | 用Shadow DOM包裹 | 能做到主子、并发子的隔离 | 浏览器兼容性问题,依赖无法polyfill的Shadow DOM API子应用需要做一些适配 | strictStyleIsolation |
子应用之间切换时,是会自动做子应用CSS的加载和卸载的,防止子应用A的CSS代入到子应用B中。

用https://developer.mozilla.org/en-US/docs/Web/Web_Components/Using_shadow_DOM 包裹子应用DOM区域,防止子应用DOM里面的CSS作用范围跑到子应用之外。
这个工具打不开动态网 http://dongtaiwang.com/
什么原因呢
随着react、vue、angular等前端框架的流行越来越多的web应用变成了单页应用,它们的特点是异步拉取数据在浏览器中渲染出HTML。使用这些框架极大的提升web用户体验和开发效率的同时缺带来一个新问题,那就是这样的网页无法被搜索引擎收录。虽然这些web框架支持服务端渲染,但这可能又会增加开发成本。
有没有一个可用于任何单页应用的SEO解决方案,让我们不用对代码做改变保持原有的开发效率?chrome-render可以帮我们做到这点,它通过控制HeadlessChrome渲染出最终的HTML返回给爬虫来实现。
前不久chrome团队宣布chrome支持headless模式,HeadlessChrome支持chrome所具有的所有功能只不过因为不显示界面而更快资源占用更小。相比于之前的phantomjs(作者因为HeadlessChrome的推出而宣布停止维护)chrome的优势在于它又一个很强的爹(google)会一直维护它优化它,并且chrome在用户量、体验、速度、稳定性都是第一的,所以我认为HeadlessChrome会渐渐替代之前所有的HeadlessBrowser方案。
既然HeadlessChrome是以无界面模式运行的,那要怎么控制它和它交互?
chrome提供了远程控制接口,目前可以通过chrome-remote-interface来用js代码向chrome发送命令进行交互。在启动chrome的时候要开启远程控制接口,然后通过 chrome-remote-interface 连接到chrome后再通过协议控制chrome。具体操作见文档:
chrome-render先会通过chrome-runner以headless模式启动和守护你操作上的chrome,再通过chrome-remote-interface操控chrome去访问需要被SEO的网页让chrome运行这个网页,等到包含数据的HTML被渲染出来时读取当前网页DOM转换成字符串后返回。
怎么知道你的网页什么时候已经渲染出包含数据的HTML了可以返回了呢?为了提升chrome-render效率,默认会在domContentEventFired时返回。对于复杂的场景还可以通过开启chrome-render的useReady选项,等到网页里调用了window.chromeRenderReady()时返回。
只渲染出了HTML还不够我们还需要检测出来着搜索引擎爬虫的访问,如果请求来着爬虫就返回chrome-render渲染后的HTML否则返回正常的单页应用所需HTML。
综上,整体架构如下:

只需以下几行简单代码就可让chrome渲染出HTML:
const ChromeRender = require('chrome-render');
ChromeRender.new().then(async(chromeRender)=>{
const htmlString = await chromeRender.render({
url: 'http://qq.com',
});
}); chrome-render只是做了渲染出HTML的工作,要实现SEO还需要和web服务器集成。为了方便大家使用我做了一个koa中间件koa-seo,要集成到你现有的项目很简单,如下:
const seoMiddleware = require('koa-seo');
const app = new Koa();
app.use(seoMiddleware());只需像这样接入一个中间件你的单页应用就被SEO了。
chrome-render除了用于通用SEO解决方案其实可以用于通用服务端渲染,因为目的都是渲染出最终的HTML再返回。针对通用服务端渲染我也做了一个koa中间件koa-chrome-render。使用chrome-render做服务端渲染的
优势在于:
window.chromeRenderReady(),保持原有开发效率缺点在于:
大家可能会说这个很像prerender.io,没错思路是一样的,chrome-render的优势在于:
本文中所提到的相关项目都是开源的并且有详细的使用文档,它们的文档链接如下:
喜欢的给个star,希望大家和我一起来改进它们让它们更强大。
本文只讨论应用于浏览器环境的流媒体协议的加密
付费观看视频的模式是很多平台的核心业务,如果视频被录制并非法传播,付费业务将受到严重威胁。因此对视频服务进行加密的技术变得尤为重要。
本文所指的视频加密是为了让要保护的视频不能轻易被下载,即使下载到了也是加密后的内容,其它人解开加密后的内容需要付出非常大的代价。
无法做到严格的让要保护的视频不被录制,原因在于你需要在客户端播放出视频的原内容,解密的流程在客户端的话不法分子就能模拟整个流程,最保守也能用屏幕录制软件录制到视频的原内容(可以通过加水印的方法缓解下)。我们的目标是让他获取原内容的代价更大。
视频加密技术分为两种:
一般结合这两种技术一起用,第1种技术很成熟也有很多教程就不再复述,本文主要介绍第2种加密技术。
看视频分为两种,看点播和看录播。
要看点播可以通过下载完整个视频后再看,或者通过流媒体边下边看。
看直播只能通过流媒体看最新的画面。
加密整个视频的技术很简单,把视频看成一个文件采用加密文件的技术,这种技术太多就不介绍了。
加密流媒体的技术很少,也很难找到学习资料,本文主要介绍流媒体加密技术。
常见的应用与浏览器播放的流媒体传输协议有:
可以看出一个规律这些流媒体传输协议都必须把视频流拆分成连续的小块之后再被传送,只不过分块的大小和视频容器的格式不一样而已。
流媒体加密技术的核心就在于对这每一小块视频分别使用对称加密算法,在服务端加密客户端解密,通过权限验证的用户才能拿到解密一小块视频的密钥。
可能有人会问为什么不用 HTTPS 加密?原因是 HTTPS 在网络传输层进行非对称加密,目的是为了防止中间人窃听劫持,任何人都可以和我们的服务器建立 HTTPS 链接获取到原数据。而视频加密的目的不是为了防止有中间人窃听我们的视频数据,而是要让视频数据本身被加密。
现代成熟的加密技术分为对称加密算法和公钥密码算法(非对称加密)。之所以选择对称加密是因为流媒体要求很强的实时性,数据量又很大。公钥密码算法的计算都比较复杂,效率较低,适合对少量数据进行加密。对称加密效率相对较高,所以流媒体加密首选对称加密。例如在 SSH 登入的时候会先通过公钥密码算法传输一个密钥,再用这个密钥用作对称加密算法的密钥,在数据传输过程中使用对称加密算法来提示数据传输效率。
HLS 是目前最成熟的支持流媒体加密的能应用在浏览器里的流媒体传输协议,HLS 原生支持加密,下面来详细介绍它。
在介绍如何加密 HLS 先了解下 HLS 相比于其它流媒体传输协议的优缺点。
优点在于:
缺点在于:
HLS 由两部分构成,一个是 .m3u8 文件,一个是 .ts 视频文件(TS 是视频文件格式的一种)。整个过程是,浏览器会首先去请求 .m3u8 的索引文件,然后解析 m3u8,找出对应的 .ts 文件链接,并开始下载。

m3u8 文件是一个文本文件,在开启 HLS 加密时,内容大致如下:
#EXTM3U
#EXT-X-VERSION:6
#EXT-X-TARGETDURATION:10
#EXT-X-MEDIA-SEQUENCE:26
#EXT-X-KEY:METHOD=AES-128,URI="https://priv.example.com/key.do?k=1"
#EXTINF:9.901,
http://media.example.com/segment26.ts
#EXT-X-KEY:METHOD=AES-128,URI="https://priv.example.com/key.do?k=2"
#EXTINF:9.501,
http://media.example.com/segment28.ts
这个文件描述了每个 TS 分片的 URL ,但这些分片都是加密后的内容,要还原出原内容需要从
#EXT-X-KEY:METHOD=AES-128,URI="https://priv.example.com/key.do?k=1"
中解析出获取解密密钥的URL https://priv.example.com/key.do 和对称加密算法 AES-128 。
获取到密钥后再在客户端解密出原内容。
可以看出启用 HLS 加密后会多出更多的事情:
这会带来更多的网络请求和计算量,可能会对延迟和性能造成一定的不良影响。
支持 HLS 的客户端都原生支持加密,所以要开启 HLS 加密你只需要修改你的服务端:
EXT-X-KEY 字段。https://priv.example.com/key.do?k=1 所指向的服务。目前大多数云服务都支持 HLS 加密服务,如果你想直接搭建 HLS 加密服务可以使用 nginx-rtmp-module。
目前 HLS 存在兼容性问题:
flashls 和 hls.js 都支持 HLS 加密技术。
有加密就有破解,在明白 HLS 加密原理后,你想过如何去破解它吗?先定义下破解成功是指:获取到视频加密前的完整原文件。我想到的方法是:
似乎破解的难度也不会很复杂。
目前流媒体加密技术还不成熟,除了 HLS 协议提供了方便成熟的方案外,其它协议的加密技术还不成熟。
RTMP 协议提供了一个变种版 RTMPE 可以加密流媒体,原理和 HLS 加密类似,但是我还找不到合适的服务端去支持 RTMPE 协议。
本文首发于IBMDev社区
Golang以其高效、稳定、简单吸引了大量开发者使用,越来越多公司和云计算平台开始选择Golang作为后端服务开发语言。
Golang对比目前主流的后端开发语言Java具有以下优势:
本文将以打造一个电影网站的后端服务为例,一步步教你如何用Golang开发GraphQL服务,内容涵盖:
搭建出的服务整体架构如图:

在阅读本文前你需要有一定的Golang基础,你可以阅读免费电子书入门。
Golang标准库内置的net/http包能快速实现一个HTTP服务器:
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/hello", func(writer http.ResponseWriter, request *http.Request) {
fmt.Fprintf(writer, "Hello, World!")
})
http.ListenAndServe(":8080", nil) // HTTP服务监听在8080端口
}但其功能太基础,要用在实际项目中还需要自己补充大量常用基础功能,例如:
/movie/:id 中提取id参数;/static 目录下的所有文件;好在Golang社区中已有多款成熟完善的HTTP框架,例如Gin、Echo等。
Gin和Echo功能相似,但Echo文档更齐全性能更好,因此本文选择Echo作为HTTP框架,接下来详细介绍Echo的用法。
Echo封装的简约但不失灵活,只需以下代码就能快速实现一个高性能HTTP服务:
import (
"net/http"
"github.com/labstack/echo/v4"
)
func main() {
e := echo.New()
e.GET("/hello", func(context echo.Context) error {
return c.String(http.StatusOK, "Hello, World!")
})
e.Start(":8080") // HTTP服务监听在8080端口
}要实现需要响应JSON也非常简单:
// 响应map类型JSON
e.GET("/map", func(context echo.Context) error {
return context.JSON(http.StatusOK, map[string]interface{}{"Hello": "World"})
})
// 响应数组类型JSON
e.GET("/array", func(context echo.Context) error {
return context.JSON(http.StatusOK, []string{"Hello", "World"})
})
// 响应结构体类型JSON
type Hi struct {
Hello string `json:"Hello"`
}
e.GET("/struct", func(context echo.Context) error {
return context.JSON(http.StatusOK, Hi{
Hello: "World",
})
})如果请求中带有参数,Echo能方便的帮你解析出来:
e.GET("/params/:operationName", func(context echo.Context) error {
email := c.QueryParam("email") // 从URL params?email=abc 中提取email字段的值
operationName := c.Param("operationName") // 从URL params/:abc 中提取operationName字段的值
variables := c.FormValue("variables") // 从POST Form请求的body中提取variables字段的值
})Echo还提供更强大的Bind功能,能根据请求自动的提取结构化的参数,同时还能校验参数是否合法:
// 定义参数的结构
type Params struct {
Email string `validate:"required,email"` // 改字段必填,并且是email格式
// 从JSON和Form请求中提取的字段名称是operationName,从URL中提取的字段名称是operation_name
OperationName string `json:"operationName" form:"operationName" query:"operation_name"`
Variables map[string]interface{}
}
e.GET("/structParams", func(context echo.Context) (err error) {
params:= Params{}
// Bind将自动根据请求类型,从URL、Body中提取参数转换为Params struct中定义的结构
err = context.Bind(¶ms)
// 如果校验失败,err将非空表示校验失败信息
if err != nil {
retuen
}
})在获取响应给客户端的数据时可能会发生异常,这时候需要HTTP服务作出响应,Echo的错误处理设计的很优雅:
e.GET("/movie", func(context echo.Context) (err error) {
// 获取电影数据,可能发生错误
movie, err := getMovie()
// 如果获取电影失败,直接返回错误
if err != nil {
// 客户端将收到HTTP 500响应码,内容为:{"message": "err.Error()对应的字符串"}
retuen
}
return context.JSON(http.StatusOK, movie)
})如果你不想返回默认的500错误,例如没有权限,可以自定义错误码:
e.GET("/movie", func(context echo.Context) (err error) {
movie, err := getMovie()
if err != nil {
// 客户端将收到HTTP 401响应码,内容为:{"message": "err.Error()对应的字符串"}
retuen echo.NewHTTPError(http.StatusUnauthorized, err.Error())
}
})如果你不想在出错时响应JSON,例如需要响应HTTP,可以自定义错误渲染逻辑:
e.HTTPErrorHandler = func(err error, context echo.Context) {
return context.HTML(http.StatusUnauthorized, err.Error())
}Echo内置了大量实用的中间件,例如:
import (
"github.com/labstack/echo/middleware"
)
// 采用Gzip压缩响应后能传输更少的字节,如果的HTTP服务没有在Nginx背后建议开启
e.Use(middleware.Gzip())
// 支持接口跨域请求
e.Use(middleware.CORS())
// 记录请求日志
e.Use(middleware.Logger())GraphQL作为一种全新的api设计**,把前端所需要的api用类似图数据结构的方式结构清晰地展现出来,让前端很方便的获取所需要的数据。
GraphQL可用来取代目前用的最多的restful规范,相比于restful有如下优势:
自从FaceBook2012公布了GraphQL规范后,引起了很多大公司和社区关注,逐渐有公司开始使用GraphQL作为API规范。
在Golang社区中也涌现了多个GraphQL服务端框架,例如:
本文将选择第三个graphql-go作为GraphQL服务端框架,接下来介绍如何使用它。
假如我们需要实现一个搜索电影的服务,我们需要先定义接口暴露的Schema
schema {
query: Query
}
type Query {
search(offset: Int,size: Int,q: String): [Movie!] # 通过关键字搜索电影
}
type Movie {
id: Int!
title: String!
casts: [Cast!]! # 一个电影有多个演员
image: String!
}
type Cast {
id: Int!
name: String!
image: String!
}客户端在调用接口时只需要发送以下请求:
{
search(q:"你好"){
title
image
casts{
name
}
}
}实现根query的取值逻辑:
import (
"net/http"
"github.com/gwuhaolin/echo_graphql"
"github.com/labstack/echo"
"github.com/graph-gophers/graphql-go"
)
// 定义筛选参数结构,对应Schema中定义的search方法的参数
type MovieFilter struct {
Offset *int32
Size *int32
Q *string
}
type QueryResolver struct {
}
// 对应Schema中定义的search方法,如果方法的error不为空,将响应500错误码
func (r *QueryResolver) Search(ctx context.Context, args model.MovieFilter) ([]*MovieResolver, error) {
ms, e := db.SearchMovies(args)
return WrapMovies(ms), e
}实现获取电影信息的取值逻辑:
type MovieResolver struct {
*model.Movie
}
func (r *MovieResolver) ID() int32 {
return r.Movie.ID
}
func (r *MovieResolver) Title() string {
return r.Movie.Title
}
func (r *MovieResolver) Image() string {
return r.Movie.Image
}
func (r *MovieResolver) Casts() ([]*CastResolver, error) {
cs, err := db.Casts(r.Movie.ID)
// 把返回的Cast数组包裹为CastResolver数组
return WrapCasts(cs), err
}
// 把返回的Movie数组包裹为MovieResolver数组
func WrapMovies(movies []*model.Movie) []*MovieResolver {
msr := make([]*MovieResolver, 0)
for i := range movies {
msr = append(msr, &MovieResolver{movies[i]})
}
return msr
}演员信息的取值实现逻辑和电影的非常相似就不再复述。
定义的Schema和Golang代码之间有一个很清晰的映射,包括下钻的嵌套字段,如图:

graphql-go暴露了一个Exec函数用于执行GraphQL语句,改函数入参为上下文和请求体返回为获取到的数据,用发如下:
schema := graphql.MustParseSchema(`上面定义的Schema`, QueryResolver{}, graphql.UseFieldResolvers())
data := schema.Exec(context.Request().Context(), params.Query, params.OperationName, params.Variables)其中Exec的入参都可以通过Echo拿到:
// graphql请求体的标准格式
type Params struct {
Query string `json:"query"`
OperationName string `json:"operationName"`
Variables map[string]interface{} `json:"variables"`
}
// 在Echo中注册graphql路由
e.Any("/graphql", func(context echo.Context) (err error) {
params := Params{}
err = context.Bind(¶ms)
if err != nil {
return
}
data := schema.Exec(context.Request().Context(), params.Query, params.OperationName, params.Variables)
return context.JSON(http.StatusOK, data)
})以上就开发完了一个基于Golang的GraphQL服务。
使用Docker部署服务能抹去大量繁琐易错的手工操作,使用Docker部署的第一步是需要把我们上面开发完的GraphQL服务构建成一个镜像,
为此需要写一个Dockerfile:
FROM golang:latest as builder
WORKDIR /app
COPY . .
RUN go mod download
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -o main ./http
FROM alpine:latest
COPY --from=builder /app/main .
EXPOSE 80
EXPOSE 443
CMD ["./main"]同时你可以定义一个Github Action来自动构建和发布镜像,新增Action配置文件.github/workflows/docker.yml如下:
name: release
on: [push]
jobs:
dy-server:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
- name: Docker dy-server release
uses: elgohr/Publish-Docker-Github-Action@master
with:
name: gwuhaolin/projectname/http-server
username: gwuhaolin
password: ${{ github.token }}
registry: docker.pkg.github.com
dockerfile: http/Dockerfile
workdir: ./每次你向Github推送代码后都会自动触发构建生产最新的GraphQL服务镜像,有了镜像你可以直接通过docker运行服务:
docker run -d --name http-server -p 80:80 -p 443:443 docker.pkg.github.com/gwuhaolin/projectname/http-server:latest自从2009年发布Golang到现在,Golang社交已发展的非常成熟,你可以在开源社区找到几乎所有的现成框架。
使用Golang开发出的Graphql服务不仅能支撑高并发量,编译出的产物也非常小,
由于不依赖虚拟机,搭配上Docker带来的自动化部署给开发者节省成本的同时又带来稳定和便利。
虽然Golang能开发出小巧高效的Graphql服务,但可以看出在实现GraphQL取数逻辑那块有大量繁琐重复的工作,
这归咎于Golang语法太过死板无法给框架开发者发挥空间来实现使用更便利的框架,希望后续Golang2能提供更灵活的语法来优化这些不足。
ReactNative三端同构是指在不改动原ReactNative的代码下,让其在浏览器中运行出和在ReactNative环境下一样的页面。
ReactNative三端同构的应用场景包括:
对于使用ReactNative开发的页面,如果又单独为Web平台重复写一份代码代价是极其大的,而ReactNative三端同构能以零花费快速做到一份代码三端复用。
ReactNative就像一套新的浏览器标准,ReactNative提供了大量内置的原生UI元素和系统API,对应着浏览器中的div、img等标签以及BOM API;但是ReactNative目前只专注于移动App平台,只适配了iOS和Android两大系统,而浏览器则是适配了各种操作系统,由于ReactNative需要适配的平台更少所以性能会比浏览器要好。
我们编写的React组件经过render后会以虚拟DOM的形式存储在内存中,React只负责UI层面的抽象和组件的状态管理,各平台都可用虚拟DOM去渲染出不同的结果,React架构如下:

由此可见虚拟DOM这层中间抽象在实现React渲染到多端时发挥了很大的作用。
目前社区中已经有多个ReactNative三端同构方案,比较成熟的有react-native-web和reactxp,下来从多方面对比二者以帮助你做出合适的选择。
reactxp是一个跨平台的UI库,由微软Skype团队维护和开源,Skype产品中就大量使用了它来实现写一份代码运行在多个平台上。目前reactxp支持以下平台:
reactxp充份发挥了react虚拟DOM的优势,它其实只是充当胶水的作用,把各个平台的渲染引擎整合起来,对外暴露平台一致的接口。
reactxp为各个平台都实现了一份代码,在构建的过程中构建工具会自动选择平台相关的代码进行打包输出。

从使用层面来说它们最大的区别在于:reactxp是为了一份代码在多个平台运行,而react-native是为了学一遍可为多个平台编写原生应用。
这一点从reactxp和react-native暴露出的API就可以看出来:react-native中大量诸如SegmentedControlIOS、PermissionsAndroid这样针对特定平台的API,而reactxp中所有的API在所有端中都可以正常调用。
事实上react-native也在为多端接口统一做努力,react-native中的大多数接口是可以在多端运行一致的,但为了保证灵活性react-native也提供了平台相关的接口。而reactxp磨平了多端接口的差异,但这也导致reactxp灵活性降低。
他们的相同点是都采用了react框架编程的**,由于reactxp是基于react-native封装的导致他们大多数API的使用方式都是一致的。
react-native-web实现了在不修改react-native代码的情况下渲染在浏览器里的功能,其实现原理如下:
在用webpack构建用于运行在浏览器里的代码时,会把react-native的导入路径替换为react-native-web的导入路径,在react-native-web内部则会以和react-native目录结构一致的方式实现了一致的react-native组件。在react-native-web组件的内部,则把react-native的API映射成了浏览器支持的API。

它们的目的都是为了实现多端同构,但react-native-web只专注于Web平台的适配,而reactxp则还需要适配UWP平台。
在实现Web平台的适配过程中它们都采用了类似的原理:把对外暴露的API或组件映射到Web平台去。
但在实现Web平台的样式适配时有细微区别:
对于这两种不同的实现方式,我更看好react-native-web的实现方式,原因有两个:
其中最为致命的缺点可能在于目前reactxp支持的组件和API相当匮乏,一些比较细的操作无法控制;如果你在reactxp项目中确实有需求超出reactxp的能力范围,可以通过导入和使用react-native实现,但这会导致整个项目脱离reactxp体系,因此reactxp为我们实现的多端同构将会无法实现;
reactxp只保证在它的体型内实现多端同构,但在它的体系内却有很多API不可用。
reactxp更像是微软为了挽救其奄奄一息的Windows Phone系统在做努力,但事实上微软已经失去了移动操作系统市场,无人愿意为用户量很少的WP系统开发APP。
| reactxp | react-native-web | 对比 | |
|---|---|---|---|
| 维护人 | 微软Skype团队和GitHub社区 | 来自Twitter的个人necolas和GitHub社区 | reactxp小胜 |
| 服务端渲染支持 | 官方没有明确要支持 | 完全支持 | react-native-web胜 |
| Web端包大小 | 435KB | 354.4KB | react-native-web胜 |
| 写代码效率 | 针对reactxp暴露的API去实现多端适配 | 需要自己去验证代码在多端的表现是否一致 | reactxp胜 |
| 学习成本 | 除了需要学习reactxp外,不可避免的还需要学习react-native | 只需学习react-native即可 | react-native-web胜 |
| Github数据 | start=2017年4月 star=6521 issues=23/739 commits=814 | start=2017年7月 star=10151 issues=45/1034 commits=1248 | react-native-web用户更多,代码变动频率更大。reactxp问题响应速度更快。 |
如果你开发的产品有适配UWP平台的需求就选择reactxp,否则选择react-native-web,因为reactxp相比于react-native-web除了多支持Windows平台外,并无其它明显优势。
为了给你现有的ReactNative接入react-native-web,实现ReactNative三端同构的能力,你需要做以下事情:
安装新的依赖:
# 运行时依赖
npm i react react-dom react-native-web react-art
# 构建工具
npm i -D webpack webpack-dev-server webpack-cli babel-loader babel-plugin-transform-runtime
为Web平台写一份Webpack配置文件webpack.config.js,内容如下:
module.exports = {
module: {
rules: [
{
// 支持图片等静态文件的加载
test: /\.(gif|jpe?g|png|svg)$/,
use: {
loader: 'file-loader'
}
},
{
// react-native包中有很多es6语法的js,需要用babel转换后才能在浏览器中运行
test: /\.js$/,
use: {
loader: 'babel-loader',
options: {
cacheDirectory: false,
presets: ['react-native'],
plugins: [
// 支持 async/await 语法
'transform-runtime'
]
}
}
}
]
},
resolve: {
// 优先加载以web.js结尾的针对web平台的文件
extensions: {
'.web.js',
'.js',
'.json',
},
alias: {
// 把react-native包映射成react-native-web
'react-native$': 'react-native-web'
}
}
}写一个针对Web平台启动入口文件index.web.js:
import { AppRegistry } from 'react-native';
// 注册组件
AppRegistry.registerComponent('App', () => App);
// 启动App组件
AppRegistry.runApplication('App', {
// 启动时传给App组件的属性
initialProps: {},
// 渲染App的DOM容器
rootTag: document.getElementById('react-app')
});写一个index.html文件,引入Webpack构建出的JavaScript,以在Web平台运行:
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<!--以下是正常运行所需的必须样式-->
<style>
html,body,#react-root{
height: 100%;
}
#react-root{
display:flex;
}
</style>
</head>
<body>
<div id="react-root"></div>
<script src="main.js"></script>
</body>
</html>完成以上步骤后重新执行webpack构建,再在浏览器中打开index.html你就可以看到ReactNative转出的Web网页了。
完整的例子可以参考react-native-web的官方例子。
由于reactxp所有暴露的API都是支持在Web平台和ReactNative平台同时正常运行的,因此为reactxp应用转Web的方法非常简单,只需为项目加入Webpack构建和运行Web页面的index.html文件。
Webpack配置文件如下:
module.exports = {
entry: "./src/index.tsx",
mode: "development",
output: {
filename: "bundle.js",
path: __dirname + "/dist"
},
resolve: {
// 优先加载web.js后缀的文件
extensions: [".web.js", ".ts", ".tsx", ".js"]
},
module: {
rules: [
// 转换TypeScript文件
{ test: /\.tsx?$/, loader: "awesome-typescript-loader" }
]
}
};再写一个运行Web页面的index.html文件:
<!doctype html>
<html>
<head>
<meta charset='utf-8'>
<style>
html, body, .app-container {
width: 100%;
height: 100%;
padding: 0;
border: none;
margin: 0;
}
*:focus {
outline: 0;
}
</style>
</head>
<body>
<div class="app-container"></div>
<script src="dist/bundle.js"></script>
</body>
</html>完整的例子可以参考reactxp的官方例子。
ReactNative开发的App中经常会出现ReactNative官方提供的NativeModules不够用的情况,这时你会在项目中开发自己的NativeModules,然后在JavaScript中去调用自己的NativeModules。这在ReactNative环境下运行没有问题,但转成Web后执行时会报错说NativeModules上找不到对应的模块,这时因为在浏览器环境下是不存在这些自定义的NativeModules。为了让页面能正常在浏览器中运行,需要为Web平台也实现一份自定义的NativeModules,实现方法可以web平台的执行入口的最开头注入以下polyfill:
import { NativeModules } from 'react-native';
import MyModule from './MyModule'; // 实现自定义NativeModules的地方
NativeModules.MyModule = MyModule; // 挂载MyModule这段代码的作用是把针对Web平台编写的自定义原生模块挂载到NativeModules对象上成为其属性,以让JavaScript代码在访问自定义NativeModules时访问到针对Web平台编写模块。
为了让ReactNative三端同构能正常的运行,在有些情况下你不得不编写平台特点的代码,因为有些代码只能在特点平台下才能运行,编写Web平台特定的代码的方法有以下三种:
ReactNative.Platform.OS:所有端的代码都在一个文件中,通过以下代码来写web平台专属代码:
import { Platform } from 'react-native';
if(Platform.OS==='web'){
// web平台专属代码
}process.env.platform:通过Webpack注入的环境变量来区分
if (process.env.platform === 'web') {
// web平台专属代码
}这段代码只会在web平台下被打包进去,这和ReactNative.Platform的区别是:
ReactNative.Platform的代码会打包进所有的平台。
要使用这种方法需要你在webpack.config.js文件中注入环境变量:
plugins: [
new webpack.DefinePlugin({
'process.env': {
platform: JSON.stringify(platform),
__DEV__: mode === 'development'
}),
].web.js: 在web模式下会优先加载.web.js文件,当.web.js文件不存在时才使用.js文件。
ReactNative三端同构在理论上虽然可行,并且有现成的方案,但实践是还是会遇到一些问题,例如:
ReactNative三端同构虽然无法实现100%和ReactNative环境运行一致,但能快速简单的转换大多数场景,以低成本的方式为你的项目带来收益。
本文首发于IBM Dev社区
webpack是当下最流行的js打包工具,这得益于网页应用日益复杂和js模块化的流行。webpack2增加了一些新特性也正式发布了一段时间,是时候告诉大家如何用webpack2优化你的构建让它构建出更小的文件尺寸和更好的开发体验。
打包结果更小可以让网页打开速度更快以及简约宽带。可以通过这以下几点做到
css-loader 在webpack2里默认是没有开启压缩的,最后生成的css文件里有很多空格和tab,通过配置
css-loader?minimize参数可以开启压缩输出最小的css。css的压缩实际是是通过cssnano实现的。
tree-shaking 是指借助es6 import export 语法静态性的特点来删掉export但是没有import过的东西。要让tree-shaking工作需要注意以下几点:
import export转换为cmd的module.export,配置如下:"presets": [
[
"es2015",
{
"modules": false
}
]
]import export 语法的代码。├── es
│ └── utils
├── lib
│ └── utils
其中lib目录里是编译出的es5代码,es目录里是编译出的采用import export 语法的es5代码,在redux的package.json文件里有这两个配置:
"main": "lib/index.js",
"jsnext:main": "es/index.js",
这是指这个库的入口文件的位置,所以要让webpack去读取es目录下的代码需要使用jsnext:main字段配置的入口,要做到这点webpack需要这样配置:
module.exports = {
resolve: {
mainFields: ['jsnext:main','main'],
}
};这会让webpack先使用jsnext:main字段,在没有时使用main字段。这样就可以优化支持tree-shaking的库。
webpack --optimize-minimize 选项会开启 UglifyJsPlugin来压缩输出的js,但是默认的UglifyJsPlugin配置并没有把代码压缩到最小输出的js里还是有注释和空格,需要覆盖默认的配置:
new UglifyJsPlugin({
// 最紧凑的输出
beautify: false,
// 删除所有的注释
comments: false,
compress: {
// 在UglifyJs删除没有用到的代码时不输出警告
warnings: false,
// 删除所有的 `console` 语句
// 还可以兼容ie浏览器
drop_console: true,
// 内嵌定义了但是只用到一次的变量
collapse_vars: true,
// 提取出出现多次但是没有定义成变量去引用的静态值
reduce_vars: true,
}
})很多库里(比如react)有部分代码是这样的:
if(process.env.NODE_ENV !== 'production'){
// 不是生产环境才需要用到的代码,比如控制台里看到的警告
}在环境变量 NODE_ENV 等于 production 的时候UglifyJs会认为if语句里的是死代码在压缩代码时删掉。
CommonsChunkPlugin可以提取出多个代码块都依赖的模块形成一个单独的模块。要发挥CommonsChunkPlugin的作用还需要浏览器缓存机制的配合。在应用有多个页面的场景下提取出所有页面公共的代码减少单个页面的代码,在不同页面之间切换时所有页面公共的代码之前被加载过而不必重新加载。这个方法可以非常有效的提升应用性能。
webpack编译在生产环境出来的js、css、图片、字体这些文件应该放到CDN上,再根据文件内容的md5命名文件,利用缓存机制用户只需要加载一次,第二次加载时就直接访问缓存。如果你之后有修改就会为对应的文件生产新的md5值。做到以上你需要这样配置:
{
output: {
publicPath: CND_URL,
filename: '[name]_[chunkhash].js',
},
}知道以上原理后我们还可以进一步优化:利用CommonsChunkPlugin提取出使用页面都依赖的基础运行环境。比如对于最常见的react体系你可以抽出基础库react react-dom redux react-redux到一个单独的文件而不是和其它文件放在一起打包为一个文件,这样做的好处是只要你不升级他们的版本这个文件永远不会被刷新。如果你把这些基础库和业务代码打包在一个文件里每次改动业务代码都会导致浏览器重复下载这些包含基础库的代码。以上的配置为:
// vender.js 文件抽离基础库到单独的一个文件里防止跟随业务代码被刷新
// 所有页面都依赖的第三方库
// react基础
import 'react';
import 'react-dom';
import 'react-redux';
// redux基础
import 'redux';
import 'redux-thunk';// webpack配置
{
entry: {
vendor: './path/to/vendor.js',
},
}在webpack1里经常会使用 DedupePlugin 插件来消除重复的模块以及使用 OccurrenceOrderPlugin 插件让被依赖次数更高的模块靠前分到更小的id 来达到输出更少的代码,在webpack2里这些已经这两个插件已经被移除了因为这些功能已经被内置了。
除了压缩文本代码外还可以:
以上优化点只需要在构建用于生产环境代码的时候才使用,在开发环境时最好关闭因为它们很耗时。
优化开发体验主要从更快的构建和更方便的功能入手。
webpack的resolve.modules配置模块库(通常是指node_modules)所在的位置,在js里出现import 'redux'这样不是相对也不是绝对路径的写法时会去node_modules目录下找。但是默认的配置会采用向上递归搜索的方式去寻找node_modules,但通常项目目录里只有一个node_modules在项目根目录,为了减少搜索我们直接写明node_modules的全路径:
module.exports = {
resolve: {
modules: [path.resolve(__dirname, 'node_modules')]
}
};除此之外webpack配置loader时也可以缩小文件搜索范围。
.js文件时就不要把test写成/\.jsx?$/只对项目目录下src目录里的代码进行babel编译
{
test: /\.js$/,
loader: 'babel-loader',
include: path.resolve(__dirname, 'src')
} 项目目录下的所有js都会进行babel编译,包括庞大的node_modules下的js
{
test: /\.js$/,
loader: 'babel-loader'
} babel编译过程很耗时,好在babel-loader提供缓存编译结果选项,在重启webpack时不需要创新编译而是复用缓存结果减少编译流程。babel-loader缓存机制默认是关闭的,打开的配置如下:
module.exports = {
module: {
loaders: [{
test: /\.js$/,
loader: 'babel-loader?cacheDirectory',
}]
}
};resolve.alias 配置路径映射。
发布到npm的库大多数都包含两个目录,一个是放着cmd模块化的lib目录,一个是把所有文件合成一个文件的dist目录,多数的入口文件是指向lib里面下的。
默认情况下webpack会去读lib目录下的入口文件再去递归加载其它依赖的文件这个过程很耗时,alias配置可以让webpack直接使用dist目录的整体文件减少文件递归解析。配置如下:
module.exports = {
resolve: {
alias: {
'moment': 'moment/min/moment.min.js',
'react': 'react/dist/react.js',
'react-dom': 'react-dom/dist/react-dom.js'
}
}
};module.noParse 配置哪些文件可以脱离webpack的解析。
有些库是自成一体不依赖其他库的没有使用模块化的,比如jquey、momentjs、chart.js,要使用它们必须整体全部引入。
webpack是模块化打包工具完全没有必要去解析这些文件的依赖,因为它们都不依赖其它文件体积也很庞大,要忽略它们配置如下:
module.exports = {
module: {
noParse: /node_modules\/(jquey|moment|chart\.js)/
}
};除此以外还有很多可以加速的方法:
模块热替换是指在开发的过程中修改代码后不用刷新页面直接把变化的模块替换到老模块让页面呈现出最新的效果。
webpack-dev-server内置模块热替换,配置起来也很方便,下面以react应用为例,步骤如下:
--hot参数开启模块热替换,在开启--hot后针对css的变化是会自动热替换的,但是js涉及到复杂的逻辑还需要进一步配置。import App from './app';
function run(){
render(<App/>,document.getElementById('app'));
}
run();
// 只在开发模式下配置模块热替换
if (process.env.NODE_ENV !== 'production') {
module.hot.accept('./app', run);
}当./app发生变化或者当./app依赖的文件发生变化时会把./app编译成一个模块去替换老的,替换完毕后重新执行run函数渲染出最新的效果。
webpack只做了资源打包的工作还缺少把这些加载到html里运行的功能,在庞大的app里手写html去加载这些资源是很繁琐易错的,我们需要自动正确的加载打包出的资源。
webpack原生不支持这个功能于是我做了一个插件 web-webpack-plugin
具体使用点开链接看详细文档,使用大概如下:
webpack配置
module.exports = {
entry: {
A: './a',
B: './b',
},
plugins: [
new WebPlugin({
// 输出的html文件名称,必填,注意不要重名,重名会覆盖相互文件。
filename: 'index.html',
// 该html文件依赖的entry,必须是一个数组。依赖的资源的注入顺序按照数组的顺序。
requires: ['A', 'B'],
}),
]
};将会输出一个index.html文件,这个文件将会自动引入 entry A 和 B 生成的js文件,
输出的html:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
</head>
<body>
<script src="A.js"></script>
<script src="B.js"></script>
</body>
</html>输出的目录结构
├── A.js
├── B.js
└── index.html
虽然webpack适用于单页应用,但复杂的系统经常是由多个单页应用组成,每个页面一个功能模块。webpack给出了js打包方案但缺少管理多个页面的功能。 web-webpack-plugin的AutoWebPlugin会自动的为你的系统里每个单页应用生成一个html入口页,这个入口会自动的注入当前单页应用依赖的资源,使用它你只需如下几行代码:
plugins: [
// ./src/pages/ 代表存放所有页面的根目录,这个目录下的每一个目录被看着是一个单页应用
// 会为里面的每一个目录生成一个html入口
new AutoWebPlugin('./src/pages/', {
//使用单页应用的html模版文件,这里你可以自定义配置
template: './src/assets/template.html',
}),
],查看web-webpack-plugin的文档了解更多
如果你对当前的配置输出或者构建速度不满意,webpack有一个工具叫做webpack analyze 以可视化的方式直观的分析构建,来进一步优化构建结果和速度。要使用它你需要在执行webpack的时候带上--json --profile2个参数,这代表让webpack把构建结果以json输出并带上构建性能信息,使用如下:
webpack --json --profile > stats.json 会生产一个stats.json 文件,再打开webpack analyze 上传这个文件开始分析。
最后附上这篇文章所讲到的webpack整体的配置,分为开发环境的webpack.config.js和生产环境的webpack-dist.config.js
为什么要在这个时候探索flv.js做直播呢?原因在于各大浏览器厂商已经默认禁用Flash,之前常见的Flash直播方案需要用户同意使用Flash后才可以正常使用直播功能,这样的用户体验很致命。
在介绍flv.js之前先介绍下常见的直播协议以及给出我对它们的延迟与性能所做的测试得出的数据。
如果你看的很吃力可以先了解下音视频技术的一些基础概念。
TCP,在浏览器端依赖Flash。HTTP流式IO传输FLV,依赖浏览器支持播放FLV。WebSocket传输FLV,依赖浏览器支持播放FLV。WebSocket建立在HTTP之上,建立WebSocket连接前还要先建立HTTP连接。HTTP的流媒体传输协议。HTML5可以直接打开播放。UDP,延迟1秒,浏览器不支持。| 传输协议 | 播放器 | 延迟 | 内存 | CPU |
|---|---|---|---|---|
| RTMP | Flash | 1s | 430M | 11% |
| HTTP-FLV | Video | 1s | 310M | 4.4% |
| HLS | Video | 20s | 205M | 3% |
在支持浏览器的协议里,延迟排序是:
RTMP = HTTP-FLV = WebSocket-FLV < HLS
而性能排序恰好相反:
RTMP > HTTP-FLV = WebSocket-FLV > HLS
也就是说延迟小的性能不好。
可以看出在浏览器里做直播,使用HTTP-FLV协议是不错的,性能优于RTMP+Flash,延迟可以做到和RTMP+Flash一样甚至更好。
flv.js是来自Bilibli的开源项目。它解析FLV文件喂给原生HTML5 Video标签播放音视频数据,使浏览器在不借助Flash的情况下播放FLV成为可能。
H.264,音频编码必须是AAC或MP3, IE11和Edge浏览器不支持MP3音频编码,所以FLV里采用的编码最好是H.264+AAC,这个让音视频服务兼容不是问题。原生HTML5 Video标签 和 Media Source Extensions APIHTTP FLV 或者 WebSocket 中的一种协议来传输FLV。其中HTTP FLV需通过流式IO去拉取数据,支持流式IO的有fetch或者stream flv.min.js 文件大小 164Kb,gzip后 35.5Kb,flash播放器gzip后差不多也是这么大。Media Source Extensions,目前所有iOS和Android4.4.4以下里的浏览器都不支持,也就是说目前对于移动端flv.js基本是不能用的。flv.js只做了一件事,在获取到FLV格式的音视频数据后通过原生的JS去解码FLV数据,再通过Media Source Extensions API 喂给原生HTML5 Video标签。(HTML5 原生仅支持播放 mp4/webm 格式,不支持 FLV)
flv.js 为什么要绕一圈,从服务器获取FLV再解码转换后再喂给Video标签呢?原因如下:
由于目前flv.js兼容性还不是很好,要用在产品中必要要兼顾到不支持flv.js的浏览器。兼容方案如下:
说了这么多介绍与原理,接下来教大家如何用flv.js搭建一个完整的直播系统。
我已经搭建好了一个demo可以供大家体验。
主播推流到音视频服务,音视频服务再转发给所有连接的客户端。为了让你快速搭建服务推荐我用go语言实现的livego,因为它可以运行在任何操作系统上,对Golang感兴趣?请看Golang 中文学习资料汇总。
livego,服务就启动好了。它会启动RTMP(1935端口)服务用于主播推流,以及HTTP-FLV(7001端口)服务用于播放。在react体系里使用react flv.js 组件reflv 快速实现。
先安装npm i reflv,再写代码:
import React, { PureComponent } from 'react';
import Reflv from 'reflv';
export class HttpFlv extends PureComponent {
render() {
return (
<Reflv
url={`http://localhost:7001/live/test.flv`}
type="flv"
isLive
cors
/>
)
}
}让以上代码在浏览器里运行。这是你还看不到直播,是因为还没有主播推流。
ffmpeg -f avfoundation -i "0" -vcodec h264 -acodec aac -f flv rtmp://localhost/live/test按照上面的教程运行起来的直播延迟大概有3秒,经过优化可以到1秒。在教你怎么优化前先要介绍下直播运行流程:
主播端在采集到一段时间的音视频原数据后,因为音视频原数据庞大需要先压缩数据:
压缩完后再通过FLV容器格式封装压缩后的数据,封装成一个FLV TAG
再把FLV TAG通过RTMP协议推流到音视频服务器,音视频服务器再从RTMP协议里解析出FLV TAG。
音视频服务器再通过HTTP协议通过和浏览器建立的长链接流式把FLV TAG传给浏览器。
flv.js 获取FLV TAG后解析出压缩后的音视频数据喂给Video播放。
知道流程后我们就知道从哪入手优化了:
{
enableWorker: true,
enableStashBuffer: false,
stashInitialSize: 128,// 减少首桢显示等待时长
}这里是优化后的完整代码
本文还未完成,还在不断补充中
你的团队是不是遇到过网页出故障了无法第一时间知道只能等用户反馈后才知道出现了问题?我曾因为一次疏忽导致产品的一个页面不可用被批评,这让我难受低沉了一个星期。
我总是追求合理高效的方法来解决我所遇到的问题,于是我幻想要是有一个工具可以智能的监视网页一旦出现异常就提醒我们该多好。就在出故障的几天后chrome团队宣布chrome支持headless模式,这让我很兴奋因为它正是我在找的,于是我开始做FinalTest(等成熟了再开源)。
HeadlessChrome支持chrome所具有的所有功能只不过因为不显示界面而更快资源占用更小。相比于之前的phantomjs(作者因为HeadlessChrome的推出而宣布停止维护)chrome的优势在于它又一个很强的爹(google)会一直维护它优化它,并且chrome在用户量、体验、速度、稳定性都是第一的,所以我认为HeadlessChrome会渐渐替代之前所有的HeadlessBrowser方案。
既然HeadlessChrome是以无界面模式运行的,那要怎么控制它和它交互?
chrome提供了远程控制接口,目前可以通过chrome-remote-interface来用js代码向chrome发送命令进行交互。在启动chrome的时候要开启远程控制接口,然后通过 chrome-remote-interface 连接到chrome后再通过协议控制chrome。具体操作见文档:
FinalTest是一个自动化的网页功能异常检测工具。名称来源于它做了测试阶段的最后一环,也是最后一道质量保障。
需要特别说明的是FinalTest只是用来检查网页的功能异常(无法正常使用)而不做浏览器兼容性检查。
当发生以下情况时,FinalTest会认为网页是异常的:

其中包含这些模块:
爱折腾的前端圈时常会有新轮子诞生,只要是好东西就能快速获得大量关注,资历再好的大哥只要不如新人也很快会被替代。
横空出世的Parcel近日成为了前端圈的又一大热点,在短短几周内就获得了13K的Star。
作为前端构建工具新人的Parcel为什么能在短期内获得这么多赞同?他和老大哥Webpack比起来到底有什么优势呢?
我花了6个月的时间写了一本全面介绍Webpack的图书《深入浅出 Webpack》近日刚出版,感觉被新出的Parcel给腰斩了。
但本文将本着公平公正的心态来详细对比一下他两,让你能明白他们直接的异同和优缺点对比,好决定是选Parcel还是Webpack。
为了对比他两,我们从实际出发举一个实战项目为例子,分别用Parcel和Webpack去实现,实战项目要求如下:
在用了很久Webpack后用Parcel的感觉就像用了很久Android机后用iPhone,不用再去操心细节和配置,大多数时候Parcel刚刚够用而且用的很舒服。
用Parcel去完成以上项目的要求,我只是专心去写项目页面所必须的代码,Parcel智能快速的帮我构建出了能正常运行的结果。
以下是Parcel让我心动的点:
而反观Webpack,比Parcel要麻烦很多:
这个项目我用Parcel时花在构建配置上的时间不到一分钟,而用Webpack构建时花了5分钟去配置。
通过以上项目实践,发现Parcel目前有如下明显的缺点:
零配置其实是把各种常见的场景做为默认值来实现的,这虽然能节省很多工作量,快速上手,但这同时会带来一些问题:
.babelrc postcss.config.js tsconfig.json这些配置文件也一起发布上去了,.babelrc文件发布到了Npm上,项目依赖的本来是lib中已经编译成了ES5的JS代码了,但Parcel还会去用Babel处理一遍。目前Parcel只能用来构建用于运行在浏览器中的网页,这也是他的出发点和专注点。
在软件行业不可能存在即使用简单又可以适应各种场景的方案,就算所谓的人工智能也许能解决这个问题,但人工智能不能保证100%的正确性。
反观Webpack除了用于构建网页,还可以做:
分别去用Parcel和Webpack构建以上项目,收集的数据如下:
| 数据项 | Parcel | Webpack |
|---|---|---|
| 生成环境构建时间 | 8.310s | 9.58s |
| 开发环境启动时间 | 5.42s | 8.06s |
| 监听变化构建时间 | 3.17s | 2.87s |
| 生成环境输出JS文件大小 | 544K | 274K |
| 生成环境输出CSS文件大小 | 23K | 23K |
从以上数据可以看出:Parcel构建速度快,但Parcel输出文件大
导致Parcel构建速度快的原因和iOS比Android用起来更流畅的原因类似:
导致Parcel输出JS文件大的原因在于:

现阶段的Parcel就像beta版的iPhone,看上去很美好但还不能用于生成环境,如果你现在就把Parcel用于生成环境,相信我你一定会踩很多坑。
踩坑不要紧,要命的是无法在网上找到解决方法以快速解决问题。
我不是不鼓励大家使用Parcel,历史总需要先驱去推动,就像乔布斯义无反顾的引领了一个时代,我们也需要去实践Parcel,坑都是一个个填平的,所以我鼓励大家在一些个人小项目中使用Parcel。
如果Parcel能解决上面提到的这些问题,我会毫不犹豫的在我的下一个项目中使用他。
我看这代码里的local部分也没有写入Socks5规定的那些格式,就是直接把接收到的包转发到server,为什么server部分直接就能读取到目的地址呢?
本文首发于IBM Dev社区
Web 应用日益复杂,相关开发技术也百花齐放,这对前端构建工具提出了更高的要求。 Webpack 从众多构建工具中脱颖而出成为目前最流行的构建工具,几乎成为目前前端开发里的必备工具之一。 大多数人在使用 Webpack 的过程中都会遇到构建速度慢的问题,在项目大时显得尤为突出,这极大的影响了我们的开发体验,降低了我们的开发效率。
本文将传授你一些加速 Webpack 构建的技巧,下面来一一介绍。
由于有大量文件需要解析和处理,构建是文件读写和计算密集型的操作,特别是当文件数量变多后,Webpack 构建慢的问题会显得严重。 运行在 Node.js 之上的 Webpack 是单线程模型的,也就是说 Webpack 需要处理的任务需要一件件挨着做,不能多个事情一起做。
文件读写和计算操作是无法避免的,那能不能让 Webpack 同一时刻处理多个任务,发挥多核 CPU 电脑的威力,以提升构建速度呢?
HappyPack 就能让 Webpack 做到上面抛出的问题,它把任务分解给多个子进程去并发的执行,子进程处理完后再把结果发送给主进程。
接入 HappyPack 的相关代码如下:
const path = require('path');
const ExtractTextPlugin = require('extract-text-webpack-plugin');
const HappyPack = require('happypack');
module.exports = {
module: {
rules: [
{ test: /\.js$/,
// 把对 .js 文件的处理转交给 id 为 babel 的 HappyPack 实例
use:['happypack/loader?id=babel'],
// 排除 node_modules 目录下的文件,node_modules目录下的文件都是采用的 ES5 语法,没必要再通过 Babel 去转换
exclude: path.resolve(__dirname, 'node_modules'),
},
{
// 把对 .css 文件的处理转交给 id 为 css 的 HappyPack 实例
test: /\.css$/,
use:ExtractTextPlugin.extract({
use: ['happypack/loader?id=css'],
}),
},
] },
plugins: [
new HappyPack({
// 用唯一的标识符 id 来代表当前的HappyPack 是用来处理一类特定的文件
id: 'babel',
// 如何处理 .js 文件,用法和 Loader配置中一样
loaders: ['babel-loader?cacheDirectory'],
}),
new HappyPack({
id: 'css',
// 如何处理 .css 文件,用法和Loader 配置中一样
loaders: ['css-loader'], }),
new ExtractTextPlugin({
filename: `[name].css`,
}),
],
};以上代码有两点重要的修改:
接入 HappyPack 后,你需要给项目安装新的依赖:
npm i -D happypack安装成功后重新执行构建,你就会看到以下由 HappyPack 输出的日志:
Happy[babel]: Version: 4.0.0-beta.5. Threads: 3
Happy[babel]: All set; signaling webpack to proceed.Happy[css]: Version: 4.0.0-beta.5. Threads: 3Happy[css]: All set; signaling webpack to proceed.
说明你的 HappyPack 配置生效了,并且可以得知 HappyPack 分别启动了3个子进程去并行的处理任务。
在整个 Webpack 构建流程中,最耗时的流程可能就是 Loader 对文件的转换操作了,因为要转换的文件数据巨多,而且这些转换操作都只能一个个挨着处理。 HappyPack 的核心原理就是把这部分任务分解到多个进程去并行处理,从而减少了总的构建时间。
从前面的使用中可以看出所有需要通过 Loader 处理的文件都先交给了 happypack/loader 去处理,收集到了这些文件的处理权后 HappyPack 就好统一分配了。
每通过 new HappyPack() 实例化一个 HappyPack 其实就是告诉 HappyPack 核心调度器如何通过一系列 Loader 去转换一类文件,并且可以指定如何给这类转换操作分配子进程。
核心调度器的逻辑代码在主进程中,也就是运行着 Webpack 的进程中,核心调度器会把一个个任务分配给当前空闲的子进程,子进程处理完毕后把结果发送给核心调度器,它们之间的数据交换是通过进程间通信 API 实现的。
核心调度器收到来自子进程处理完毕的结果后会通知 Webpack 该文件处理完毕。
在使用 Webpack 构建出用于发布到线上的代码时,都会有压缩代码这一流程。 最常见的 JavaScript 代码压缩工具是 UglifyJS,并且 Webpack 也内置了它。
用过 UglifyJS 的你一定会发现在构建用于开发环境的代码时很快就能完成,但在构建用于线上的代码时构建一直卡在一个时间点迟迟没有反应,其实卡住的这个时候就是在进行代码压缩。
由于压缩 JavaScript 代码需要先把代码解析成用 Object 抽象表示的 AST 语法树,再去应用各种规则分析和处理 AST,导致这个过程计算量巨大,耗时非常多。
为什么不把多进程并行处理的**也引入到代码压缩中呢?
ParallelUglifyPlugin 就做了这个事情。 当 Webpack 有多个 JavaScript 文件需要输出和压缩时,原本会使用 UglifyJS 去一个个挨着压缩再输出, 但是 ParallelUglifyPlugin 则会开启多个子进程,把对多个文件的压缩工作分配给多个子进程去完成,每个子进程其实还是通过 UglifyJS 去压缩代码,但是变成了并行执行。 所以 ParallelUglifyPlugin 能更快的完成对多个文件的压缩工作。
使用 ParallelUglifyPlugin 也非常简单,把原来 Webpack 配置文件中内置的 UglifyJsPlugin 去掉后,再替换成 ParallelUglifyPlugin,相关代码如下:
const path = require('path');
const ParallelUglifyPlugin = require('webpack-parallel-uglify-plugin');
module.exports = {
plugins: [
// 使用 ParallelUglifyPlugin 并行压缩输出的 JS 代码
new ParallelUglifyPlugin({
// 传递给 UglifyJS 的参数
uglifyJS: {
},
}),
],
};接入 ParallelUglifyPlugin 后,项目需要安装新的依赖:
npm i -D webpack-parallel-uglify-plugin安装成功后,重新执行构建你会发现速度变快了许多。如果设置 cacheDir 开启了缓存,在之后的构建中会变的更快。
Webpack 启动后会从配置的 Entry 出发,解析出文件中的导入语句,再递归的解析。 在遇到导入语句时 Webpack 会做两件事情:
以上两件事情虽然对于处理一个文件非常快,但是当项目大了以后文件量会变的非常多,这时候构建速度慢的问题就会暴露出来。 虽然以上两件事情无法避免,但需要尽量减少以上两件事情的发生,以提高速度。
接下来一一介绍可以优化它们的途径。
Webpack的resolve.modules 用于配置 Webpack 去哪些目录下寻找第三方模块。
resolve.modules 的默认值是 ['node_modules'],含义是先去当前目录下的 ./node_modules 目录下去找想找的模块,如果没找到就去上一级目录 ../node_modules 中找,再没有就去 ../../node_modules 中找,以此类推,这和 Node.js 的模块寻找机制很相似。
当安装的第三方模块都放在项目根目录下的 ./node_modules 目录下时,没有必要按照默认的方式去一层层的寻找,可以指明存放第三方模块的绝对路径,以减少寻找,配置如下:
module.exports = {
resolve: {
// 使用绝对路径指明第三方模块存放的位置,以减少搜索步骤
// 其中 __dirname 表示当前工作目录,也就是项目根目录
modules: [path.resolve(__dirname, 'node_modules')]
},
};除此之外在使用 Loader 时可以通过 test 、 include 、 exclude 三个配置项来命中 Loader 要应用规则的文件。 为了尽可能少的让文件被 Loader 处理,可以通过 include 去命中只有哪些文件需要被处理。
以采用 ES6 的项目为例,在配置 babel-loader 时,可以这样:
module.exports = {
module: {
rules: [
{
// 如果项目源码中只有 js 文件就不要写成 /\.jsx?$/,提升正则表达式性能
test: /\.js$/,
// babel-loader 支持缓存转换出的结果,通过 cacheDirectory 选项开启
use: ['babel-loader?cacheDirectory'],
// 只对项目根目录下的 src 目录中的文件采用 babel-loader
include: path.resolve(__dirname, 'src'),
},
]
},
};你可以适当的调整项目的目录结构,以方便在配置 Loader 时通过 include 去缩小命中范围。
在导入语句没带文件后缀时,Webpack 会自动带上后缀后去尝试询问文件是否存在。 Webpack 配置中的 resolve.extensions 用于配置在尝试过程中用到的后缀列表,默认是:
extensions: ['.js', '.json']也就是说当遇到 require('./data') 这样的导入语句时,Webpack 会先去寻找 ./data.js 文件,如果该文件不存在就去寻找 ./data.json 文件,如果还是找不到就报错。
如果这个列表越长,或者正确的后缀在越后面,就会造成尝试的次数越多,所以 resolve.extensions 的配置也会影响到构建的性能。 在配置 resolve.extensions 时你需要遵守以下几点,以做到尽可能的优化构建性能:
相关 Webpack 配置如下:
module.exports = {
resolve: {
// 尽可能的减少后缀尝试的可能性
extensions: ['js'],
},
};Webpack 配置中的 resolve.mainFields 用于配置第三方模块使用哪个入口文件。
安装的第三方模块中都会有一个 package.json 文件用于描述这个模块的属性,其中有些字段用于描述入口文件在哪里,resolve.mainFields 用于配置采用哪个字段作为入口文件的描述。
可以存在多个字段描述入口文件的原因是因为有些模块可以同时用在多个环境中,针对不同的运行环境需要使用不同的代码。 以 isomorphic-fetchfetch API 为例,它是 的一个实现,但可同时用于浏览器和 Node.js 环境。
为了减少搜索步骤,在你明确第三方模块的入口文件描述字段时,你可以把它设置的尽量少。 由于大多数第三方模块都采用 main 字段去描述入口文件的位置,可以这样配置 Webpack:
module.exports = {
resolve: {
// 只采用 main 字段作为入口文件描述字段,以减少搜索步骤
mainFields: ['main'],
},
};使用本方法优化时,你需要考虑到所有运行时依赖的第三方模块的入口文件描述字段,就算有一个模块搞错了都可能会造成构建出的代码无法正常运行。
Webpack 配置中的 module.noParse 配置项可以让 Webpack 忽略对部分没采用模块化的文件的递归解析处理,这样做的好处是能提高构建性能。 原因是一些库,例如 jQuery 、ChartJS, 它们庞大又没有采用模块化标准,让 Webpack 去解析这些文件耗时又没有意义。
在上面的 优化 resolve.alias 配置 中讲到单独完整的 react.min.js 文件就没有采用模块化,让我们来通过配置 module.noParse 忽略对 react.min.js 文件的递归解析处理, 相关 Webpack 配置如下:
module.exports = {
module: {
// 独完整的 `react.min.js` 文件就没有采用模块化,忽略对 `react.min.js` 文件的递归解析处理
noParse: [/react\.min\.js$/],
},
};注意被忽略掉的文件里不应该包含 import 、 require 、 define 等模块化语句,不然会导致构建出的代码中包含无法在浏览器环境下执行的模块化语句。
Webpack 配置中的 resolve.alias 配置项通过别名来把原导入路径映射成一个新的导入路径。
在实战项目中经常会依赖一些庞大的第三方模块,以 React 库为例,库中包含两套代码:
默认情况下 Webpack 会从入口文件 ./node_modules/react/react.js 开始递归的解析和处理依赖的几十个文件,这会时一个耗时的操作。 通过配置 resolve.alias 可以让 Webpack 在处理 React 库时,直接使用单独完整的 react.min.js 文件,从而跳过耗时的递归解析操作。
相关 Webpack 配置如下:
module.exports = {
resolve: {
// 使用 alias 把导入 react 的语句换成直接使用单独完整的 react.min.js 文件,
// 减少耗时的递归解析操作
alias: {
'react': path.resolve(__dirname, './node_modules/react/dist/react.min.js'),
}
},
};除了 React 库外,大多数库发布到 Npm 仓库中时都会包含打包好的完整文件,对于这些库你也可以对它们配置 alias。
但是对于有些库使用本优化方法后会影响到后面要讲的使用 Tree-Shaking 去除无效代码的优化,因为打包好的完整文件中有部分代码你的项目可能永远用不上。 一般对整体性比较强的库采用本方法优化,因为完整文件中的代码是一个整体,每一行都是不可或缺的。 但是对于一些工具类的库,例如 lodash,你的项目可能只用到了其中几个工具函数,你就不能使用本方法去优化,因为这会导致你的输出代码中包含很多永远不会执行的代码。
在介绍 DllPlugin 前先给大家介绍下 DLL。 用过 Windows 系统的人应该会经常看到以 .dll 为后缀的文件,这些文件称为动态链接库,在一个动态链接库中可以包含给其他模块调用的函数和数据。
要给 Web 项目构建接入动态链接库的**,需要完成以下事情:
为什么给 Web 项目构建接入动态链接库的**后,会大大提升构建速度呢? 原因在于包含大量复用模块的动态链接库只需要编译一次,在之后的构建过程中被动态链接库包含的模块将不会在重新编译,而是直接使用动态链接库中的代码。 由于动态链接库中大多数包含的是常用的第三方模块,例如 react、react-dom,只要不升级这些模块的版本,动态链接库就不用重新编译。
Webpack 已经内置了对动态链接库的支持,需要通过2个内置的插件接入,它们分别是:
下面以基本的 React 项目为例,为其接入 DllPlugin,在开始前先来看下最终构建出的目录结构:
├── main.js
├── polyfill.dll.js
├── polyfill.manifest.json
├── react.dll.js
└── react.manifest.json
其中包含两个动态链接库文件,分别是:
以 react.dll.js 文件为例,其文件内容大致如下:
var _dll_react = (function(modules) {
// ... 此处省略 webpackBootstrap 函数代码
}([
function(module, exports, __webpack_require__) {
// 模块 ID 为 0 的模块对应的代码
}
// ... 此处省略剩下的模块对应的代码
]));可见一个动态链接库文件中包含了大量模块的代码,这些模块存放在一个数组里,用数组的索引号作为 ID。 并且还通过 _dll_react 变量把自己暴露在了全局中,也就是可以通过 window._dll_react 可以访问到它里面包含的模块。
其中 polyfill.manifest.json 和 react.manifest.json 文件也是由 DllPlugin 生成,用于描述动态链接库文件中包含哪些模块, 以 react.manifest.json 文件为例,其文件内容大致如下:
{
// 描述该动态链接库文件暴露在全局的变量名称
"name": "_dll_react",
"content": {
"./node_modules/process/browser.js": {
"id": 0,
"meta": {}
},
// ... 此处省略部分模块
}
}可见 manifest.json 文件清楚地描述了与其对应的 dll.js 文件中包含了哪些模块,以及每个模块的路径和 ID。
main.js 文件是编译出来的执行入口文件,当遇到其依赖的模块在 dll.js 文件中时,会直接通过 dll.js 文件暴露出的全局变量去获取打包在 dll.js 文件的模块。 所以在 index.html 文件中需要把依赖的两个 dll.js 文件给加载进去,index.html 内容如下:
<!--导入依赖的动态链接库文件-->
<script src="./dist/polyfill.dll.js"></script>
<script src="./dist/react.dll.js"></script>
<!--导入执行入口文件-->
<script src="./dist/main.js"></script>以上就是所有接入 DllPlugin 后最终编译出来的代码,接下来教你如何实现。
构建输出的以下这四个文件
├── polyfill.dll.js
├── polyfill.manifest.json
├── react.dll.js
└── react.manifest.json
和以下这一个文件
├── main.js
是由两份不同的构建分别输出的。
与动态链接库相关的文件需要由一个独立的构建输出,用于给主构建使用。新建一个 Webpack 配置文件 webpack_dll.config.js 专门用于构建它们,文件内容如下:
const path = require('path');
const DllPlugin = require('webpack/lib/DllPlugin');
module.exports = {
// JS 执行入口文件
entry: {
// 把 React 相关模块的放到一个单独的动态链接库
react: ['react', 'react-dom'],
// 把项目需要所有的 polyfill 放到一个单独的动态链接库
polyfill: ['core-js/fn/object/assign', 'core-js/fn/promise', 'whatwg-fetch'],
},
output: {
// 输出的动态链接库的文件名称,[name] 代表当前动态链接库的名称,
// 也就是 entry 中配置的 react 和 polyfill
filename: '[name].dll.js',
// 输出的文件都放到 dist 目录下
path: path.resolve(__dirname, 'dist'),
// 存放动态链接库的全局变量名称,例如对应 react 来说就是 _dll_react
// 之所以在前面加上 _dll_ 是为了防止全局变量冲突
library: '_dll_[name]',
},
plugins: [
// 接入 DllPlugin
new DllPlugin({
// 动态链接库的全局变量名称,需要和 output.library 中保持一致
// 该字段的值也就是输出的 manifest.json 文件 中 name 字段的值
// 例如 react.manifest.json 中就有 "name": "_dll_react"
name: '_dll_[name]',
// 描述动态链接库的 manifest.json 文件输出时的文件名称
path: path.join(__dirname, 'dist', '[name].manifest.json'),
}),
],
};构建出的动态链接库文件用于在其它地方使用,在这里也就是给执行入口使用。
用于输出 main.js 的主 Webpack 配置文件内容如下:
const DllReferencePlugin = require('webpack/lib/DllReferencePlugin');
module.exports = {
plugins: [
// 告诉 Webpack 使用了哪些动态链接库
new DllReferencePlugin({
// 描述 react 动态链接库的文件内容
manifest: require('./dist/react.manifest.json'),
}),
new DllReferencePlugin({
// 描述 polyfill 动态链接库的文件内容
manifest: require('./dist/polyfill.manifest.json'),
}),
],
devtool: 'source-map'
};注意:在 webpack_dll.config.js 文件中,DllPlugin 中的 name 参数必须和 output.library 中保持一致。 原因在于 DllPlugin 中的 name 参数会影响输出的 manifest.json 文件中 name 字段的值, 而在 webpack.config.js 文件中 DllReferencePlugin 会去 manifest.json 文件读取 name 字段的值, 把值的内容作为在从全局变量中获取动态链接库中内容时的全局变量名。
在修改好以上两个 Webpack 配置文件后,需要重新执行构建。 重新执行构建时要注意的是需要先把动态链接库相关的文件编译出来,因为主 Webpack 配置文件中定义的 DllReferencePlugin 依赖这些文件。
执行构建时流程如下:
相信给你的项目加上以上优化方法后,构建速度会大大提高,赶快去试试把!
webpack是一个js打包工具,不一个完整的前端构建工具。它的流行得益于模块化和单页应用的流行。webpack提供扩展机制,在庞大的社区支持下各种场景基本它都可找到解决方案。本文的目的是教会你用webpack解决实战中常见的问题。
在深入实战前先要知道webpack的运行原理
entry 一个可执行模块或库的入口文件。chunk 多个文件组成的一个代码块,例如把一个可执行模块和它所有依赖的模块组合和一个 chunk 这体现了webpack的打包机制。loader 文件转换器,例如把es6转换为es5,scss转换为css。plugin 插件,用于扩展webpack的功能,在webpack构建生命周期的节点上加入扩展hook为webpack加入功能。从启动webpack构建到输出结果经历了一系列过程,它们是:
webpack.config.js文件里配置的参数,生产最后的配置结果。entry入口文件开始解析文件构建AST语法树,找出每个文件所依赖的文件,递归下去。entry配置生成代码块chunk。chunk到文件系统。需要注意的是,在构建生命周期中有一系列插件在合适的时机做了合适的事情,比如UglifyJsPlugin会在loader转换递归完后对结果再使用UglifyJs压缩覆盖之前的结果。
通过各种场景和对应的解决方案让你深入掌握webpack
demo redemo
一个单页应用需要配置一个entry指明执行入口,webpack会为entry生成一个包含这个入口所有依赖文件的chunk,但要让它在浏览器里跑起来还需要一个HTML文件来加载chunk生成的js文件,如果提取出了css还需要让HTML文件引入提取出的css。web-webpack-plugin里的WebPlugin可以自动的完成这些工作。
webpack配置文件
const { WebPlugin } = require('web-webpack-plugin');
module.exports = {
entry: {
app: './src/doc/index.js',
},
plugins: [
// 一个WebPlugin对应生成一个html文件
new WebPlugin({
//输出的html文件名称
filename: 'index.html',
//这个html依赖的`entry`
requires: ['app'],
}),
],
};requires: ['doc']指明这个HTML依赖哪些entry,entry生成的js和css会自动注入到HTML里。
你还可以配置这些资源的注入方式,支持如下属性:
_dist 只有在生产环境下才引入该资源_dev 只有在开发环境下才引入该资源_inline 把该资源的内容潜入到html里_ie 只有IE浏览器才需要引入的资源要设置这些属性可以通过在js里配置
new WebPlugin({
filename: 'index.html',
requires: {
app:{
_dist:true,
_inline:false,
}
},
}),或者在模版里设置,使用模版的好处是灵活的控制资源注入点。
new WebPlugin({
filename: 'index.html',
template: './template.html',
}),<!DOCTYPE html>
<html lang="zh-cn">
<head>
<link rel="stylesheet" href="app?_inline">
<script src="ie-polyfill?_ie"></script>
</head>
<body>
<div id="react-body"></div>
<script src="app"></script>
</body>
</html>WebPlugin插件借鉴了fis3的**,补足了webpack缺失的以HTML为入口的功能。想了解WebPlugin的更多功能,见文档。
一般项目里会包含多个单页应用,虽然多个单页应用也可以合并成一个但是这样做会导致用户没访问的部分也加载了。如果项目里有很多个单页应用,为每个单页应用配置一个entry和WebPlugin ?如果项目又新增了一个单页应用,又去新增webpack配置?这样做太麻烦了,web-webpack-plugin里的AutoWebPlugin可以方便的解决这些问题。
module.exports = {
plugins: [
// 所有页面的入口目录
new AutoWebPlugin('./src/'),
]
};AutoWebPlugin会把./src/目录下所有每个文件夹作为一个单页页面的入口,自动为所有的页面入口配置一个WebPlugin输出对应的html。要新增一个页面就在./src/下新建一个文件夹包含这个单页应用所依赖的代码,AutoWebPlugin自动生成一个名叫文件夹名称的html文件。AutoWebPlugin的更多功能见文档。
一个好的代码分割对浏览器首屏效果提升很大。比如对于最常见的react体系你可以
react react-dom redux react-redux到一个单独的文件而不是和其它文件放在一起打包为一个文件,这样做的好处是只要你不升级他们的版本这个文件永远不会被刷新。如果你把这些基础库和业务代码打包在一个文件里每次改动业务代码都会导致文件hash值变化从而导致缓存失效浏览器重复下载这些包含基础库的代码。以上的配置为:// vender.js 文件抽离基础库到单独的一个文件里防止跟随业务代码被刷新
// 所有页面都依赖的第三方库
// react基础
import 'react';
import 'react-dom';
import 'react-redux';
// redux基础
import 'redux';
import 'redux-thunk';// webpack配置
{
entry: {
vendor: './path/to/vendor.js',
},
}chunk。在应用有多个页面的场景下提取出所有页面公共的代码减少单个页面的代码,在不同页面之间切换时所有页面公共的代码之前被加载过而不必重新加载。demo remd
除了构建可运行的web应用,webpack也可用来构建发布到npm上去的给别人调用的js库。
const nodeExternals = require('webpack-node-externals');
module.exports = {
entry: {
index: './src/index.js',
},
externals: [nodeExternals()],
target: 'node',
output: {
path: path.resolve(__dirname, '.npm'),
filename: '[name].js',
libraryTarget: 'commonjs2',
},
};这里有几个区别于web应用不同的地方:
externals: [nodeExternals()]用于排除node_modules目录下的代码被打包进去,因为放在node_modules目录下的代码应该通过npm安装。libraryTarget: 'commonjs2'指出entry是一个可供别人调用的库而不是可执行的,输出的js文件按照commonjs规范。服务端渲染的代码要运行在nodejs环境,和浏览器不同的是,服务端渲染代码需要采用commonjs规范同时不应该包含除js之外的文件比如css。webpack配置如下:
module.exports = {
target: 'node',
entry: {
'server_render': './src/server_render',
},
output: {
filename: './dist/server/[name].js',
libraryTarget: 'commonjs2',
},
module: {
rules: [
{
test: /\.js$/,
loader: 'babel-loader',
},
{
test: /\.(scss|css|pdf)$/,
loader: 'ignore-loader',
},
]
},
};其中几个关键的地方在于:
target: 'node' 指明构建出的代码是要运行在node环境里libraryTarget: 'commonjs2' 指明输出的代码要是commonjs规范{test: /\.(scss|css|pdf)$/,loader: 'ignore-loader'} 是为了防止不能在node里执行服务端渲染也用不上的文件被打包进去。fis3和webpack有相似的地方也有不同的地方。相似在于他们都采用commonjs规范,不同在于导入css这些非js资源的方式。fis3通过// @require './index.scss'而webpack通过require('./index.scss')。如果想从fis3平滑迁移到webpack可以使用comment-require-loader。比如你想在webpack构建是使用采用了fis3方式的imui模块,配置如下:
loaders:[{
test: /\.js$/,
loaders: ['comment-require-loader'],
include: [path.resolve(__dirname, 'node_modules/imui'),]
}]如果你在社区找不到你的应用场景的解决方案,那就需要自己动手了写loader或者plugin了。
在你编写自定义webpack扩展前你需要想明白到底是要做一个loader还是plugin呢?可以这样判断:
如果你的扩展是想对一个个单独的文件进行转换那么就编写
loader剩下的都是plugin。
其中对文件进行转换可以是像:
babel-loader把es6转换成es5file-loader把文件替换成对应的URLraw-loader注入文本文件内容到代码里去demo comment-require-loader
编写loader非常简单,以comment-require-loader为例:
module.exports = function (content) {
return replace(content);
};loader的入口需要导出一个函数,这个函数要干的事情就是转换一个文件的内容。
函数接收的参数content是一个文件在转换前的字符串形式内容,需要返回一个新的字符串形式内容作为转换后的结果,所有通过模块化倒入的文件都会经过loader。从这里可以看出loader只能处理一个个单独的文件而不能处理代码块。想编写更复杂的loader可参考官方文档
demo end-webpack-plugin
plugin应用场景广泛,所以稍微复杂点。以end-webpack-plugin为例:
class EndWebpackPlugin {
constructor(doneCallback, failCallback) {
this.doneCallback = doneCallback;
this.failCallback = failCallback;
}
apply(compiler) {
// 监听webpack生命周期里的事件,做相应的处理
compiler.plugin('done', (stats) => {
this.doneCallback(stats);
});
compiler.plugin('failed', (err) => {
this.failCallback(err);
});
}
}
module.exports = EndWebpackPlugin;loader的入口需要导出一个class, 在new EndWebpackPlugin()的时候通过构造函数传入这个插件需要的参数,在webpack启动的时候会先实例化plugin再调用plugin的apply方法,插件需要在apply函数里监听webpack生命周期里的事件,做相应的处理。
webpack plugin 里有2个核心概念:
Compiler: 从webpack启动到推出只存在一个Compiler,Compiler存放着webpack配置Compilation: 由于webpack的监听文件变化自动编译机制,Compilation代表一次编译。Compiler 和 Compilation 都会广播一系列事件。
webpack生命周期里有非常多的事件可以在event-hooks和Compilation里查到。以上只是一个最简单的demo,更复杂的可以查看 how to write a plugin或参考web-webpack-plugin。
webpack其实很简单,可以用一句话涵盖它的本质:
webpack是一个打包模块化js的工具,可以通过loader转换文件,通过plugin扩展功能。
如果webpack让你感到复杂,一定是各种loader和plugin的原因。
希望本文能让你明白webpack的原理与本质让你可以在实战中灵活应用webpack。
自从 JavaScript 诞生起到现在已经变成最流行的编程语言,这背后正是 Web 的发展所推动的。Web 应用变得更多更复杂,但这也渐渐暴露出了 JavaScript 的问题:
针对以上两点缺陷,近年来出现了一些 JS 的代替语言,例如:
以上尝试各有优缺点,其中:
三大浏览器巨头分别提出了自己的解决方案,互不兼容,这违背了 Web 的宗旨; 是技术的规范统一让 Web 走到了今天,因此形成一套新的规范去解决 JS 所面临的问题迫在眉睫。
于是 WebAssembly 诞生了,WebAssembly 是一种新的字节码格式,主流浏览器都已经支持 WebAssembly。 和 JS 需要解释执行不同的是,WebAssembly 字节码和底层机器码很相似可快速装载运行,因此性能相对于 JS 解释执行大大提升。 也就是说 WebAssembly 并不是一门编程语言,而是一份字节码标准,需要用高级编程语言编译出字节码放到 WebAssembly 虚拟机中才能运行, 浏览器厂商需要做的就是根据 WebAssembly 规范实现虚拟机。
要搞懂 WebAssembly 的原理,需要先搞懂计算机的运行原理。 电子计算机都是由电子元件组成,为了方便处理电子元件只存在开闭两种状态,对应着 0 和 1,也就是说计算机只认识 0 和 1,数据和逻辑都需要由 0 和 1 表示,也就是可以直接装载到计算机中运行的机器码。 机器码可读性极差,因此人们通过高级语言 C、C++、Rust、Go 等编写再编译成机器码。
由于不同的计算机 CPU 架构不同,机器码标准也有所差别,常见的 CPU 架构包括 x86、AMD64、ARM, 因此在由高级编程语言编译成可自行代码时需要指定目标架构。
WebAssembly 字节码是一种抹平了不同 CPU 架构的机器码,WebAssembly 字节码不能直接在任何一种 CPU 架构上运行, 但由于非常接近机器码,可以非常快的被翻译为对应架构的机器码,因此 WebAssembly 运行速度和机器码接近,这听上去非常像 Java 字节码。
相对于 JS,WebAssembly 有如下优点:
每个高级语言都去实现源码到不同平台的机器码的转换工作是重复的,高级语言只需要生成底层虚拟机(LLVM)认识的中间语言(LLVM IR),LLVM 能实现:
除此之外 LLVM 还实现了 LLVM IR 到 WebAssembly 字节码的编译功能,也就是说只要高级语言能转换成 LLVM IR,就能被编译成 WebAssembly 字节码,目前能编译成 WebAssembly 字节码的高级语言有:
通常负责把高级语言翻译到 LLVM IR 的部分叫做编译器前端,把 LLVM IR 编译成各架构 CPU 对应机器码的部分叫做编译器后端; 现在越来越多的高级编程语言选择 LLVM 作为后端,高级语言只需专注于如何提供开发效率更高的语法同时保持翻译到 LLVM IR 的程序执行性能。
接下来详细介绍如何使用 AssemblyScript 来编写 WebAssembly,实现斐波那契序列的计算。 用 TypeScript 实现斐波那契序列计算的模块 f.ts 如下:
export function f(x: i32): i32 {
if (x === 1 || x === 2) {
return 1;
}
return f(x - 1) + f(x - 2)
}在按照 AssemblyScript 提供的安装教程成功安装后, 再通过
asc f.ts -o f.wasm就能把以上代码编译成可运行的 WebAssembly 模块。
为了加载并执行编译出的 f.wasm 模块,需要通过 JS 去加载并调用模块上的 f 函数,为此需要以下 JS 代码:
fetch('f.wasm') // 网络加载 f.wasm 文件
.then(res => res.arrayBuffer()) // 转成 ArrayBuffer
.then(WebAssembly.instantiate) // 编译为当前 CPU 架构的机器码 + 实例化
.then(mod => { // 调用模块实例上的 f 函数计算
console.log(mod.instance.f(50));
});以上代码中出现了一个新的内置类型 i32,这是 AssemblyScript 在 TypeScript 的基础上内置的类型。 AssemblyScript 和 TypeScript 有细微区别,AssemblyScript 是 TypeScript 的子集,为了方便编译成 WebAssembly 在 TypeScript 的基础上加了更严格的类型限制, 区别如下:
总体来说 AssemblyScript 比 TypeScript 又多了很多限制,编写起来会觉得局限性很大; 用 AssemblyScript 来写 WebAssembly 经常会出现 tsc 编译通过但运行 WebAssembly 时出错的情况,这很可能就是你没有遵守以上限制导致的;但 AssemblyScript 通过修改 TypeScript 编译器默认配置能在编译阶段找出大多错误。
AssemblyScript 的实现原理其实也借助了 LLVM,它通过 TypeScript 编译器把 TS 源码解析成 AST,再把 AST 翻译成 IR,再通过 LLVM 编译成 WebAssembly 字节码实现; 上面提到的各种限制都是为了方便把 AST 转换成 LLVM IR。
AssemblyScript 相对于 C、Rust 等其它语言去写 WebAssembly 而言,好处除了对前端来说无额外新语言学习成本外,还有对于不支持 WebAssembly 的浏览器,可以通过 TypeScript 编译器编译成可正常执行的 JS 代码,从而实现从 JS 到 WebAssembly 的平滑迁移。
任何新的 Web 开发技术都少不了构建流程,为了提供一套流畅的 WebAssembly 开发流程,接下来介绍接入 Webpack 具体步骤。
安装以下依赖,以便让 TS 源码被 AssemblyScript 编译成 WebAssembly。
{
"devDependencies": {
"assemblyscript": "github:AssemblyScript/assemblyscript",
"assemblyscript-typescript-loader": "^1.3.2",
"typescript": "^2.8.1",
"webpack": "^3.10.0",
"webpack-dev-server": "^2.10.1"
}
}修改 webpack.config.js,加入 loader:
module.exports = {
module: {
rules: [
{
test: /\.ts$/,
loader: 'assemblyscript-typescript-loader',
options: {
sourceMap: true,
}
}
]
},
};
修改 TypeScript 编译器配置 tsconfig.json,以便让 TypeScript 编译器能支持 AssemblyScript 中引入的内置类型和函数。
{
"extends": "../../node_modules/assemblyscript/std/portable.json",
"include": [
"./**/*.ts"
]
}
配置直接继承自 assemblyscript 内置的配置文件。
前面提到了 WebAssembly 的二进制文件格式 wasm,这种格式的文件人眼无法阅读,为了阅读 WebAssembly 文件的逻辑,还有一种文本格式叫 wast; 以前面讲到的计算斐波那契序列的模块为例,对应的 wast 文件如下:
func $src/asm/module/f (param f64) (result f64)
(local i32)
get_local 0
f64.const 1
f64.eq
tee_local 1
if i32
get_local 1
else
get_local 0
f64.const 2
f64.eq
end
i32.const 1
i32.and
if
f64.const 1
return
end
get_local 0
f64.const 1
f64.sub
call 0
get_local 0
f64.const 2
f64.sub
call 0
f64.add
end
这和汇编语言非常像,里面的 f64 是数据类型,f64.eq f64.sub f64.add 则是 CPU 指令。
为了把二进制文件格式 wasm 转换成人眼可见的 wast 文本,需要安装 WebAssembly 二进制工具箱WABT, 在 Mac 系统下可通过 brew install WABT 安装,安装成功后可以通过命令 wasm2wast f.wasm 获得 wast;除此之外还可以通过 wast2wasm f.wast -o f.wasm 逆向转换回去。
除了前面提到的 WebAssembly 二进制工具箱,WebAssembly 社区还有以下常用工具:
目前 WebAssembly 只能通过 JS 去加载和执行,但未来在浏览器中可以通过像加载 JS 那样 <script src='f.wasm'></script> 去加载和执行 WebAssembly,下面来详细介绍如何用 JS 调 WebAssembly。
JS 调 WebAssembly 分为 3 大步:加载字节码 > 编译字节码 > 实例化,获取到 WebAssembly 实例后就可以通过 JS 去调用了,以上 3 步具体的操作是:
其中的第 2、3 步可以合并一步完成,前面提到的 WebAssembly.instantiate 就做了这两个事情。
WebAssembly.instantiate(bytes).then(mod=>{
mod.instance.f(50);
})之前的例子都是用 JS 去调用 WebAssembly 模块,但是在有些场景下可能需要在 WebAssembly 模块中调用浏览器 API,接下来介绍如何在 WebAssembly 中调用 JS。
WebAssembly.instantiate 函数支持第二个参数 WebAssembly.instantiate(bytes,importObject),这个 importObject 参数的作用就是 JS 向 WebAssembly 传入 WebAssembly 中需要调用 JS 的 JS 模块。举个具体的例子,改造前面的计算斐波那契序列在 WebAssembly 中调用 Web 中的 window.alert 函数把计算结果弹出来,为此需要改造加载 WebAssembly 模块的 JS 代码:
WebAssembly.instantiate(bytes,{
window:{
alert:window.alert
}
}).then(mod=>{
mod.instance.f(50);
})对应的还需要修改 AssemblyScript 编写的源码:
// 声明从外部导入的模块类型
declare namespace window {
export function alert(v: number): void;
}
function _f(x: number): number {
if (x == 1 || x == 2) {
return 1;
}
return _f(x - 1) + _f(x - 2)
}
export function f(x: number): void {
// 直接调用 JS 模块
window.alert(_f(x));
}修改以上 AssemblyScript 源码后重新用 asc 通过命令 asc f.ts 编译后输出的 wast 文件比之前多了几行:
(import "window" "alert" (func $src/asm/module/window.alert (type 0)))
(func $src/asm/module/f (type 0) (param f64)
get_local 0
call $src/asm/module/_f
call $src/asm/module/window.alert)
多出的这部分 wast 代码就是在 AssemblyScript 中调用 JS 中传入的模块的逻辑。
除了以上常用的 API 外,WebAssembly 还提供一些 API,你可以通过这个 d.ts 文件去查看所有 WebAssembly JS API 的细节。
WebAssembly 作为一种底层字节码,除了能在浏览器中运行外,还能在其它环境运行。
前面提到的 Binaryen 提供了在命令行中直接执行 wasm 二进制文件的工具,在 Mac 系统下通过 brew install binaryen 安装成功后,通过 wasm-shell f.wasm 文件即可直接运行。
目前 V8 JS 引擎已经添加了对 WebAssembly 的支持,Chrome 和 Node.js 都采用了 V8 作为引擎,因此 WebAssembly 也可以运行在 Node.js 环境中;
V8 JS 引擎在运行 WebAssembly 时,WebAssembly 和 JS 是在同一个虚拟机中执行,而不是 WebAssembly 在一个单独的虚拟机中运行,这样方便实现 JS 和 WebAssembly 之间的相互调用。
要让上面的例子在 Node.js 中运行,可以使用以下代码:
const fs = require('fs');
function toUint8Array(buf) {
var u = new Uint8Array(buf.length);
for (var i = 0; i < buf.length; ++i) {
u[i] = buf[i];
}
return u;
}
function loadWebAssembly(filename, imports) {
// 读取 wasm 文件,并转换成 byte 数组
const buffer = toUint8Array(fs.readFileSync(filename));
// 编译 wasm 字节码到机器码
return WebAssembly.compile(buffer)
.then(module => {
// 实例化模块
return new WebAssembly.Instance(module, imports)
})
}
loadWebAssembly('../temp/assembly/module.wasm')
.then(instance => {
// 调用 f 函数计算
console.log(instance.exports.f(10))
});在 Nodejs 环境中运行 WebAssembly 的意义其实不大,原因在于 Nodejs 支持运行原生模块,而原生模块的性能比 WebAssembly 要好。 如果你是通过 C、Rust 去编写 WebAssembly,你可以直接编译成 Nodejs 可以调用的原生模块。
从上面的内容可见 WebAssembly 主要是为了解决 JS 的性能瓶颈,也就是说 WebAssembly 适合用于需要大量计算的场景,例如:
WebAssembly 标准虽然已经定稿并且得到主流浏览器的实现,但目前还存在以下问题:
总之现在的 WebAssembly 还不算成熟,如果你的团队没有不可容忍的性能问题,那现在使用 WebAssembly 到产品中还不是时候, 因为这可能会影响到团队的开发效率,或者遇到无法轻易解决的坑而阻塞开发。
本文首发于IBM Dev社区
mark
在开发React组件时我们通常需要处理2个问题:
最原始的方法莫过于开发时建一个页面用于调试,开发完后再为其手写文档。然而一个详细的React组件文档应该包括:
propTypes)如果你想做到以上估计得花上你一天的功夫,我希望能把精力放在开发更好的组件上剩下的能毫不费劲的优雅完成,于是我做了本文的主角Redemo。
Redemo是用来简单优雅的完成以上问题让你专注于开发自己的组件,剩下的一切它都为你做好了。先看下Redemo为组件生成文档的效果图或直接体验部分实践中的项目redemo文档、imuix:

结构如下:
propTypes),支持markdown为你的组件生成这个你几乎不用写超过10行简单的代码更不用单独为组件写文档。假设你编写了一个Button组件,让我们来为Button组件编写一个demo:
npm i redemo 安装 redemoimport Redemo from 'redemo';
import Demo from './demo';//为一个使用场景实例化Button组件的demo源码
// 使用docgen 从 Button 组件源码里分析出 propTypes
const docgen = require('!!docgen-loader!../button');
// 读取为Button组件编写的demo的源码
const code = require('!!raw-loader!../demo');
const doc = `为这个demo做一些说明,支持*markdown*`
render(
<Redemo
docgen={docgen}
doc={doc}
code={code}
>
<Demo/>
</Redemo>
)聪明的你大概会问以上代码并没有为Button属性编写文档,属性列表里的说明是哪来的?其实是通过react-docgen从Button组件源码里提取出来的。大家都知道为代码写注释是个好习惯方便维护和理解,而这些注释正好也可以放在文档里一举两得。所以你在编写Button组件时需要为propTypes写注释,就像这样:
class Button extends Component {
static propTypes = {
/**
* call after button is clicked,支持*markdown*
*/
onClick: PropTypes.func,
}
...
}想更深的了解redemo请看这里
希望redemo可以提升你的效率,觉得有用可告诉你的朋友。
在开发微信公众号或小程序的时候,由于微信平台规则的限制,部分接口需要通过线上域名才能正常访问。但我们一般都会在本地开发,因为这能快速的看到源码修改后的运行结果。但当涉及到需要调用微信接口时,由于不和你在同一个局域网中的用户是无法访问你的本地开发机的,就必须把修改后的代码重新发布到线上域名所在的服务器才能去验证结果。每次修改都重新发布很繁琐也很浪费时间。
本文将教你如何通过 SSH 隧道把本地服务映射到外网,以方便调试,通常把这种方法叫内网穿透。
阅读完本文后,你能解决以下常见问题:
把运行在本地开发机上的 HTTP 服务映射到外网,让全世界都能通过外网 IP 服务到你本地开发机上的 HTTP 服务。例如你本地的 HTTP 服务监听在 127.0.0.1:8080,你有一台公网 IP 为 12.34.56.78 的服务器,通过本文介绍的方法,可以让全世界的用户通过 http://12.34.56.78:8080 访问到你本地开发机上的 HTTP 服务。
总结成一句话就是:把内网端口映射到外网。
为了把内网服务映射到外网,以下资源为必须的:
ssh 登入到外网服务器。要满足以上条件很简单:
要实现把内网端口映射到外网,最简单的方式就是通过 SSH 隧道。
SSH 隧道就像一根管道,能把任何2台机器连接在一起,把发送到其中一台机器的数据通过管道传输到另一台机器。假如已经通过 SSH 隧道把本地开发机和外网服务器连接在了一起,外网服务器端监听在 12.34.56.78:8080,那么所有发给 12.34.56.78:8080 的数据都会通过 SSH 隧道原封不动地传输给本地开发机的 127.0.0.1:8080,如图所示:
也就是说,去访问 12.34.56.78:8080 就像是访问本地开发机的 127.0.0.1:8080,本地开发机上的 8080 端口被映射到了外网服务器上的 8080 端口。
如果你的外网服务器 IP 配置了域名解析,例如 yourdomin.com 会通过 DNS 解析为 12.34.56.78,那么也可以通过 yourdomin.com:8080 去访问本地开发机上的服务。
这样就做到了访问外网地址时其实是本地服务返回的结果。
通过 SSH 隧道传输数据时,数据会被加密,就算中间被劫持,黑客也无法得到数据的原内容。
所以 SSH 隧道还有一个功能就是保证数据传输的安全性。
把本地开机和外网服务器通过 SSH 隧道连接起来就和在本地开发机 SSH 登入远程登入到外网服务器一样简单。
先来回顾以下 SSH 远程登入命令,假如想在本地远程登入到 12.34.56.78,可以在本地开发机上执行以下命令:
而实现 SSH 隧道只需在本地开发机上执行:
ssh -R 8080:127.0.0.1:8080 [email protected]如果想同时映射多个端口则可以执行:
ssh [email protected] -R 8080:127.0.0.1:8080 -R 8081:127.0.0.1:8081可以看出实现 SSH 隧道的命令相对于 SSH 登入多出来 -R 8080:127.0.0.1:8080,多出的这部分的含义是:
在远程机器(12.34.56.78)上启动 TCP 8080端口监听着,再把远程机器(12.34.56.78)上8080端口映射到本地的127.0.0.1:8080。
执行完以上命令后,就可以通过 12.34.56.78:8080 去访问本地的 127.0.0.1:8080 了。
通常把这种技术叫做 SSH 远程端口转发(remote forwarding)。
其实不限于只能把本地开发机上运行的服务映射到外网服务器上去,还可以把任何本地开发机可以访问的服务映射到外网服务器上去。例如在本地开发机上能访问 github.com:80,在本地开发机上执行:
ssh -R 8080:github.com:80 [email protected]就能通过 12.34.56.78:8080 去访问 github.com:80 了。
在执行完上面介绍的 SSH 隧道命令后,你会发现登入到了外网服务器上去了,如果你登出外网服务器,就会发现 12.34.56.78:8080 无法访问了。导致这个问题的原因是你登出外网服务器时,在外网服务器上本次操作对应的 SSH 进程也跟着退出了,而这个退出的进程曾负责监听在 8080 端口进行转发操作。
为了让 SSH 隧道一直保持在后台执行,有以下方法。
SSH 还支持这些参数:
因此要让 SSH 隧道一直保持在后台执行,可以通过以下命令:
ssh -NTf -R 8080:127.0.0.1:8080 [email protected]SSH 隧道是不稳定的,在网络恶劣的情况下可能随时断开。如果断开就需要手动去本地开发机再次向外网服务器发起连接。
AutoSSH 能让 SSH 隧道一直保持执行,他会启动一个 SSH 进程,并监控该进程的健康状况;当 SSH 进程崩溃或停止通信时,AutoSSH 将重启动 SSH 进程。
使用AutoSSH 只需在本地开发机上安装 AutoSSH ,方法如下:
brew install autossh;apt-get install autossh;安装成功后,在本地开发机上执行:
autossh -N -R 8080:127.0.0.1:8080 [email protected]就能完成和上面一样的效果,但本方法能保持 SSH 隧道一直运行。
可以看出这行命令和上面的区别在于把 ssh 换成了 autossh,并且少了 -f 参数,原因是 autossh 默认会转入后台运行。
如果你遇到通过以上方法成功启动 SSH 隧道后,还是无法访问 12.34.56.78:8080,那么很有可能是外网服务器上的 SSH 没有配置对。为此你需要去外网服务器上修改 /etc/ssh/sshd_config 文件如下:
GatewayPorts yes
这个选项的意思是,SSH 隧道监听的服务的 IP 是对外开放的 0.0.0.0,而不是只对本机的 127.0.0.1。不开 GatewayPorts 的后果是不能通过 12.34.56.78:8080 访问,只能在外网服务器上通过 127.0.0.1:8080 服务到本地开发机的服务。
修改好配置文件后,你还需要重启 sshd 服务来加载新的配置,命令如下:
service sshd restart如果使用以上方法还是无法访问 12.34.56.78:8080,请检查你外网服务器的防火墙配置,确保 8080 端口是对外开放的。
除了 SSH 隧道能实现内网穿透外,还有以下常用方法。
frp 是一个可用于内网穿透的高性能的反向代理应用,支持 tcp, udp, http, https 协议。
frp 有以下特性:
ngrok 是一个商用的内网穿透工具,它有以下特点:
这些代替方案的缺点在于都需要再额外安装其它工具,没有 SSH 隧道来的直接。
想了解更多可以访问它们的主页。
检索数据库中的条目是很基本常见的功能,实现的方法也很多,常见包括:
虽然基于Elasticsearch这类系统能实现高级灵活的检索功能,但开发和运维成本也将大大增加,
本文将教会你如何利用PostgresSQL内置的功能快速高效的实现大多数中文检索场景。
检索是大多数系统需要的功能,虽然已有很多成熟的检索方案,但多数是面向英文的对中文不友好。
虽然有Elasticsearch这类高级的检索引擎能实现中文检索但其学习和运维成本高,本文将教会你如何使用PostgresSQL数据库自带的功能实现大多数中文检索场景。
LIKE语句通过通配符实现文字检索,例如SELECT * FROM movies WHERE title LIKE '权力的%'语句能找出所有名称以权力的为开头的电影。
LIKE语句支持两种通配符:
%:代表任意个数的字符_:代表一个字符例如以下匹配结果:
'abc' LIKE 'abc' true
'abc' LIKE 'a%' true
'abc' LIKE '_b_' true
'abc' LIKE 'abc_' false
如果你想忽略大小写可以通过ILIKE实现,例如 'abc' LIKE 'aBc'会返回true。
PostgresSQL还提供了LIKE语句的一些简写形式:
~~ 等价于 LIKE~~* 等价于 ILIKE!~~ 等价于 NOT LIKE!~~* 等价于 NOT ILIKE通过SIMILAR语句能让我们借助正则表达式实现更高级的匹配,而不是像LIKE那样简单的通配符,例如以下语句:
'abc' SIMILAR TO 'abc' true
'abc' SIMILAR TO 'a' false
'abc' SIMILAR TO '%(b|d)%' true
'abc' SIMILAR TO '(b|c)%' false
有了正则表达式,还可以通过内置的substring函数提取出特定的字符串:
substring('foobar' from '%#"o_b#"%' for '#') oob
substring('foobar' from '#"o_b#"%' for '#') NULL
PostgresSQL同样提供了SIMILAR TO语句的简写形式:
~ 'abc' 等价于 SIMILAR TO '.*abc.*',以及对应的取反操作!~ 'abc'~* 'abc' 等价于 SIMILAR TO '.*abc.*' 但会忽略大小写,以及对应的取反操作!~* 'abc'这些SQL语法都是PostgresSQL特有的,虽然便捷但不推荐使用,因为兼容性和可读性不好。
pg_trgm模块提供了两个字符串相似度计算的函数,
该方法区别于上面两种方法的区别在于利用了概率论的**来寻找最相似的结果,而不是严格的匹配。
该模块的算法是基于Trigram模型实现的,
Trigram全名third grammar,是N-gram模型的在N=3时的一个特例。
Trigram的前提**是假设第X个词的出现只与前面3-1=2个词相关,而与其它任何词都不相关。
在计算相似度时先把一段文字拆分成为多个词,3个一组形成一个Trigram,再找出这个序列中最大相似的Trigram。
以文字oneTrigram的拆分规则为:
one{ o, on,ne ,one}你通过通过
SELECT show_trgm('one')语句来查询如何文本的拆分结果(实际上show_trgm除了调试很少有用)。
为什么这里N选择了3而不是其它?是因为N太大会导致计算量成指数上升,而3有着不错的效果同时也能有很好的性能。
PostgresSQL默认没有开启pg_trgm模块,需要通过以下语句启用:
CREATE EXTENSION pg_trgm成功开启后,可以通过similarity(a, b)函数判断两句话的相似度,返回的结果是一个[0,1]的浮点数,
0表示完全没有一致的字符,1表示完全一样。
如果你想求一句话和一个词的相似度,例如two words和word的相似度,如果用上面提到的similarity函数会得到0.36,
得到这个很低的结果是因为similarity会考虑整体的相似性;
如果想求局部相似性,也就是句子里的words和单词word相似的,可以使用word_similarity('word','two words')得到的结果是0.8。
针对以上函数PostgresSQL还提供了简写形式:
a % b:判断similarity(a, b)是否大于阀值pg_trgm.similarity_threshold(默认0.3)a <% b:判断word_similarity(a, b)是否大于阀值pg_trgm.strict_word_similarity_threshold(默认0.6)a <-> b:a和b之间的整体相似距离,越大表示越不相似,等价于1-similarity(a, b)a <<-> b:a和b之间的局部相似距离,越大表示越不相似,等价于1-word_similarity(a, b)你可以通过
SET pg_trgm.similarity_threshold = 0.8语句修改默认的阀值,但通常情况下使用默认值就能获得很好的效果。
在PostgresSQL里提升查询性能最有效地方式是使用索引,针对不同检索方式需要用不同索引来优化,先来看下内置的各种索引和其特点:
B树索引是使用范围最广的索引,也是执行CREATE INDEX时默认使用的索引,几乎所有的数据库都支持B树索引。
B树索引可以有效地用于等值和范围查询,并且也可以用于检索NULL值,排序。
B树索引适用于前匹配的LIKE检索,例如权力的%,但不能用于%权力的或%权力的%,原因在于只有前匹配才能建立B-tree。
哈希索引原理就像map一样对数据进行KV映射,因此只在等值比较时才有用,但它性能非常好。
倒排索引以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
倒排索引的结构图如下图:
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以非常适用用于索引数组值。
它是一种平衡树结构的访问方法,在系统中作为一个基本模版,可以使用它实现任意索引模式,GiST实际上是一个通用的索引框架,支持多种数据类型。
Gist索引适用于多维数据类型和集合数据类型,和Btree索引类似,同样适用于其他的数据类型。
和Btree索引相比,Gist多字段索引在查询条件中包含索引字段的任何子集都会使用索引扫描,而Btree索引只有查询条件包含第一个索引字段才会使用索引扫描。
来总结下四种索引适用的场景,方便后续根据场景查询适用的索引:
| 索引类型 | 适用场景 |
|---|---|
| B-tree | 前匹配LIKE如权力的%、等值、范围、排序 |
| Hash | 等值 |
| GIN | 数组、zhparser分词 |
| GiST | LIKE通配符、SIMILAR TO正则表达式 |
| 场景 | PostgresSQL关键字 | 适用索引 |
|---|---|---|
| 精确搜索 | LIKE 通配符 | B-tree支持前匹配如权力的% GiST支持所有 |
| SIMILAR 正则表达式 | GiST | |
| 模糊搜索 | pg_trgm 字符串相似度 | GIN(gin_trgm_ops) GIST (gist_trgm_ops) |
| 分词搜索 | zhparser+tsquery 分词检索 | GIN |
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

