Gül Varol, Ivan Laptev and Cordelia Schmid, Long-term Temporal Convolutions for Action Recognition, PAMI 2018.
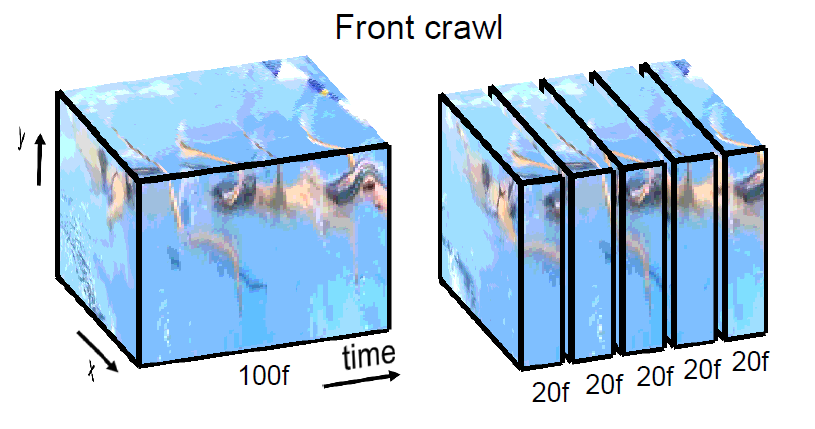
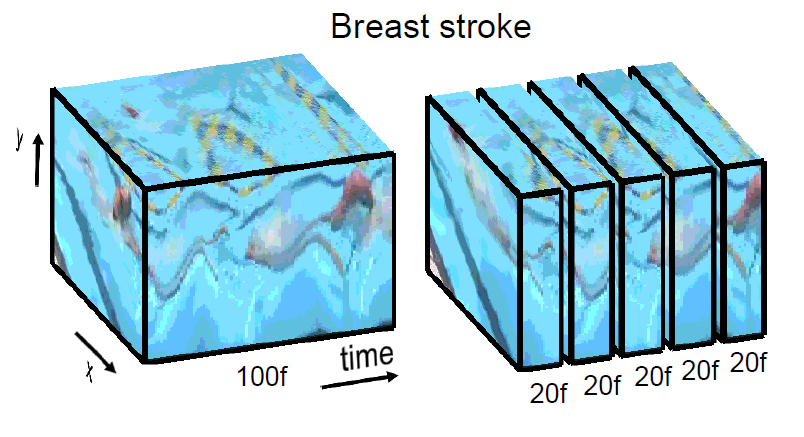
Find a few pre-processing scripts under preprocessing/ directory. The contents of the datasets directory is explained here.
preprocess_flow.lua and preprocess_rgb.lua create the .t7 files. This was to accelerate data loading when libraries such as torch-opencv did not exist. Now you could modify the loading function to directly read from .mp4 files as in here. We don't recommend to do this pre-processing anymore.
We had some redundant files that we created with generate_sliding_test_clips.m to have a list of sliding windows.
We extracted the Brox flow with this code at that time. This produces the *_minmax.txt files that save the min/max flow values to be able to go back to the original flow values and to still use jpeg compression.
4. C3D model in Torch.
See the c3dtorch directory to find the scripts that are used to convert C3D model in caffe to torch, as well as converting the mean files.
The c3d.t7 (305MB) model file is produced by running convert_c3d_caffe2torch.lua with the modified version of loadcaffe that is provided. Special thanks to Sergey Zagoruyko for the help.
The file sport1m_train16_128_mean.binaryproto is converted to data/volmean_sports1m.t7 using the caffemodel2json tool from Vadim Kantorov. create_mean_files.lua further creates mean files used for 58x58 and 71x71 resolutions. We subtract them from each input frame.
Some scripts that are used to prepare experiments with different spatial (58x58, 71x71) and temporal (20, 40, 60, 80, 100) resolutions are also provided for convenience. Additional layers on C3D were trained on UCF101 with 16f input. These layers were then attached to the pre-trained C3D with modifications in fc6 layer (with scripts convert_c3d_varyingtemp_ucf_58.lua and convert_c3d_varyingtemp_ucf_71.lua). Finally these networks were fine-tuned end-to-end for different resolutions to obtain RGB stream results on UCF101 dataset.
You can simply run th main.lua to start a training with the default parameters. Following are several examples on how to set parameters in different scenarios:
#### From scratch experiments on UCF101
# Run with default parameters (UCF101 dataset, split 1, 100-frame 58x58 resolution flow network with 0.9 dropout)
th main.lua -expName flow_100f_d9
# Continue training from epoch 10
th main.lua -expName flow_100f_d9 -continue -epochNumber 10
# Test final prediction accuracy for model number 20
th main.lua -expName flow_100f_d9 -evaluate -modelNo 20
# Train 100-frame RGB network from scratch on UCF101 dataset
th main.lua -nFrames 100 -loadHeight 67 -loadWidth 89 -sampleHeight 58 -sampleWidth 58 \
-stream rgb -expName rgb_100f_d5 -dataset UCF101 -dropout 0.5 -LRfile LR/UCF101/rgb_d5.lua
# Train 71x71 spatial resolution flow network
th main.lua -nFrames 100 -loadHeight 81 -loadWidth 108 -sampleHeight 71 -sampleWidth 71 \
-stream flow -expName flow_100f_d5 -dataset UCF101 -dropout 0.5 -LRfile LR/UCF101/flow_d5.lua
# Train 16-frame 112x112 spatial resolution flow network
th main.lua -nFrames 16 -loadHeight 128 -loadWidth 171 -sampleHeight 112 -sampleWidth 112 \
-stream flow -expName flow_100f_d5 -dataset UCF101 -dropout 0.5 -LRfile LR/UCF101/flow_d5.lua
#### Fine-tune HMDB51 from UCF101
# Train the last layer and freeze the lower layers
th main.lua -expName flow_100f_58_d9/finetune/last \
-loadHeight 67 -loadWidth 89 -sampleHeight 58 -sampleWidth 58 \
-dataset HMDB51 \
-LRfile LR/HMDB51/flow_d9_last.lua \
-finetune last \
-retrain log/UCF101/flow_100f_58_d9/model_50.t7
# Fine-tune the whole network
th main.lua -expName flow_100f_58_d9/finetune/whole \
-loadHeight 67 -loadWidth 89 -sampleHeight 58 -sampleWidth 58 \
-dataset HMDB51 \
-LRfile LR/HMDB51/flow_d9_whole.lua \
-finetune whole \
-lastlayer log/HMDB51/flow_100f_58_d9/finetune/last/model_3.t7 \
-retrain log/UCF101/flow_100f_58_d9/model_50.t7
Note that the results are sensitive to the learning rate (LR) schedule. You can set your own LR by writing a -LRfile. Following are a few observations that can be useful:
- RGB networks converge faster than flow networks.
- High dropout takes longer to converge.
- HMDB51 dataset trains faster.
- Fewer number of frames trains faster.
We provide the 71x71 RGB networks that are used for the final results. 60f + 100f was used. We provide the initialization with 16f for convenience. You can find the download links under models/download_pretrained_rgb_models.sh. See here, for mean files. If you need other resolutions, please send an e-mail.
You can find the results of Fisher Vector encoding of the improved dense trajectory features under the IDT/ directory.
If you use this code, please cite the following:
@ARTICLE{varol18_ltc,
title = {Long-term Temporal Convolutions for Action Recognition},
author = {Varol, G{\"u}l and Laptev, Ivan and Schmid, Cordelia},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence},
year = {2018},
volume = {40},
number = {6},
pages = {1510--1517},
doi = {10.1109/TPAMI.2017.2712608}
}
This code is largely built on the ImageNet training example https://github.com/soumith/imagenet-multiGPU.torch by Soumith Chintala.




























































































