![]()
This is the PyPi module for the Graphlet AI Property Graph Factory for building enterprise knowledge graphs as property graphs. Our mission is to create a PySpark-based wizard for building large knowledge graphs in the form of property graphs that makes them easier to build for fewer dollars and with less risk.
A 100-slide presentation on Graphlet AI explains where we are headed! The motivation for the project is described in Property Graph Factory: Extract, Transform, Resolve, Model, Predict, Explain.

A video of this presentation is available.
The knowledge graph and graph database markets have long asked themselves: why aren't we larger? The vision of the semantic web was that many datasets could be cross-referenced between independent graph databases to map all knowledge on the web from myriad disparate datasets into one or more authoritative ontologies which could be accessed by writing SPARQL queries to work across knowledge graphs. The reality of dirty data made this vision impossible. Most time is spent cleaning data which isn't in the format you need to solve your business problems. Multiple datasets in different formats each have quirks. Deduplicate data using entity resolution is an unsolved problem for large graphs. Once you merge duplicate nodes and edges, you rarely have the edge types you need to make a problem easy to solve. It turns out the most likely type of edge in a knowledge graph that solves your problem easily is defined by the output of a Python program using the machine learning. For large graphs, this program needs to run on a horizontally scalable platform PySpark and extend rather than be isolated inside a graph databases. The quality of developer's experience is critical. In this talk I will review an approach to an Open Source Large Knowledge Graph Factory built on top of Spark that follows the ingest / build / refine / public / query model that open source big data is based upon.
--Russell Jurney in Knowledge Graph Factory: Extract, Transform, Resolve, Model, Predict, Explain
This project is new, some features we are building are:
-
Create a generic, configurable system for entity resolution of heterogeneous networks
-
Create an efficient pipeline for computing network motifs and aggregating higher order networks
-
Implement efficient motif searching via neural subgraph matching
Graphlet AI is a knowledge graph factory designed to scale to 10B node property graphs with 30B edges.
If your network is 10K nodes, let me introduce you to networkx :)
This project is in a state of development, things are still forming and changing. If you are here, it must be to contribute :)
We manage dependencies with poetry which are managed (along with most settings) in pyproject.toml.
To install poetry, run:
curl -sSL https://install.python-poetry.org | python3 -Then upgrade to poetry 1.2b3 (required for PyDantic non-binary install):
poetry self update --previewTo build the project, run:
poetry installTo add a PyPi package, run:
poetry add <package>To add a development package, run:
poetry add --dev <package>If you do edit pyproject.toml you must update to regenerate poetry.lock:
poetry updateWe use pre-commit to run black, flake8, isort and mypy. This is configured in .pre-commit-config.yaml.
The following VSCode settings are defined for the project in .vscode/settings.json to ensure code is formatted consistent with our pre-commit hooks:
{
"editor.rulers": [90, 120],
"[python]": {
"editor.defaultFormatter": "ms-python.python",
"editor.formatOnSave": true,
"editor.codeActionsOnSave": {"source.organizeImports": true},
},
"python.jediEnabled": false,
"python.languageServer": "Pylance",
"python.linting.enabled": true,
"python.formatting.provider": "black",
"python.sortImports.args": ["--profile", "black"],
"python.linting.pylintEnabled": false,
"python.linting.flake8Enabled": true,
"autoDocstring.docstringFormat": "numpy",
"mypy.dmypyExecutable": "~/opt/anaconda3/envs/graphlet/bin/dmypy"
}The system architecture for Graphlet AI is based on a standard "Delta Architecture" that ingests, transforms, refines and publishes data for a graph database on top of a search engine to serve along with an MLOps platform for ML APIs.

This architecture is intended to optimize the construction of large property graphs from multiple data sources and eventually using NLP - information extraction and entity linking.
The process of building a knowledge graph - a property graph - out of multiple large (and many small) datasets is described below. This is the process we are optimizing.
-
Assess the input datasets, come up with the Pandera ontology classes. What your graph will look like. I am using films as an example for the test dataset... horror.csv, comedy.csv, directors.csv... and it becomes Movies, Actors, Directors, Awards. So you create those classes and Directed, ActedIn, Won, etc. edges... as Pandera classes.

-
Use the Pandera classes that define your ontology to build custom transformation and validation of data so you instantiate a simple class to transform data from one format to another rather than writing independent implementations. Implement your ETL as part of these classes using Pandera functions in the class to efficiently transform and also validate data. Pandera validates the ENTIRE record, even if one field fails to parse... so you get ALL the fields' errors at once. The system will report every erroneous error rather than dying on the first error. This would make ETL MUCH faster. You will know all the issues up front, and can put checks in place to prevent creeper issues that kill productivity from making it through the early stages of te lengthy, complex ETL pipelines that large knowledge graph projects often create.
-
Take these classes that we have ETL'd the original datasets into, feed them into a Ditto style encoding and turn them into text documents and feed them into a Graph Attention Network (GAN) ER model.

-
The ER model produces aggregate nodes with lots of sub-nodes... what we have called identities made up of entities.

-
The same Pandera classes for the Ontology then contain summarization methods. Some kind of summarization interface that makes things simple. You got 25 addresses? You have an interface for reducing them. Turn things into fields with lists, or duplicate them.
NOTE: At this point you have a property graph (property graph) you can load anywhere - TigerGraph, Neo4j, Elasticsearch or OpenSearch. -
Once this is accomplished, we build a graph DB on top of OpenSearch. The security-analytics project is going to do this, so we can wait for them and contribute to that project. Using an OpenSearch plugin reduces round-trip latency substantially, which makes scaling much easier for long walks that expand into many neighboring nodes.
-
Finally we create or use a middleware layer for an external API for the platform in front of MLFlow for MLOps / serving any live models and graph search and retrieval from OpenSearch.
-
Now that we have a clean property graph, we can pursue our network motif searching and motif-based representation learning.
Tonight we will take over the world! Muhahahahahaha!

GraphFrames uses PySpark DataFrames to perform network motif search for known motifs until we Implement efficient random motif searching via neural subgraph matching.
Below is an example of a network motif for financial compliance risk (KYC / AML) called Multiple-Path Beneficial Ownership for finding the ultimate beneficial owners a company that uses a layer of companies it owns between it and the asset it wishes to obscure. This motif indicates secrecy, not wrongdoing, but this is a risk factor.

Below is the PySpark / GraphFrames motif search code that detects this motif. While brute force searching for network motifs using MapReduce joins is not efficient, it does work well for finding known network motifs for most large networks. It is also flexible enough to search for variations, broadening results and providing domain experts with examples of variants from which to learn new motifs or expand existing motifs.

Optimizing the above process is the purpose of Graphlet AI. We believe that if we make all of that easier, we can help more organizations successfully build large, enterprise knowledge graphs (property graphs) in less time and for less money.
This project is created and published under the Apache License, version 2.0.
This project uses pre-commit hooks to enforce its conventions: git will reject commits that don't comply with our various flake8 plugins.
We use numpy docstring format on all Python classes and functions, which is enforced by pydocstring and flake8-docstrings.
We run black, flake8, isort and mypy in .pre-commit-config.yaml. All of these are configured in pyproject.toml except for flake8 which uses .flake8.
Flake8 uses the following plugins. We will consider adding any exceptions to the flake config that are warranted, but please document them in your pull requests.
flake8-docstrings = "^1.6.0"
pydocstyle = "^6.1.1"
flake8-simplify = "^0.19.2"
flake8-unused-arguments = "^0.0.10"
flake8-class-attributes-order = "^0.1.3"
flake8-comprehensions = "^3.10.0"
flake8-return = "^1.1.3"
flake8-use-fstring = "^1.3"
flake8-builtins = "^1.5.3"
flake8-functions-names = "^0.3.0"
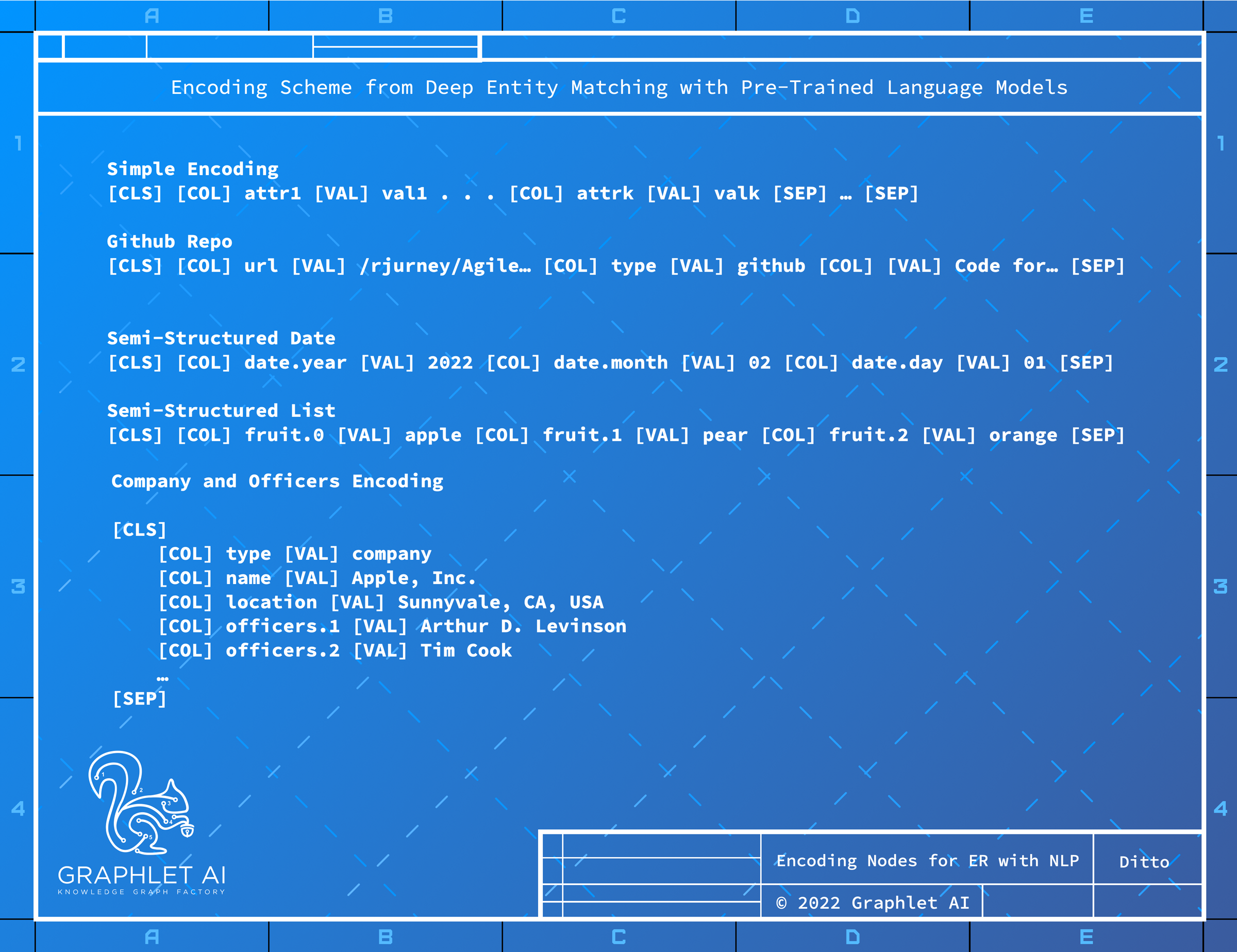
flake8-comments = "^0.1.2"This project includes a Graph Attention Network implementation of an entity resolution model where node features are based on the Ditto encoding defined in Deep Entity Matching with Pre-Trained Language Models, Li et al, 2020.
For specifics, see Issue 3: Create a generic, configurable system for entity resolution of heterogeneous networks
The motivation for Graphlet AI is to provide tools that facilitate the construction of networks for research into network motifs, motif search and motif-based representation learning. Without entity resolution... motif analysis does not work well.
-
Transform Datasets into a set of Common Schemas in a Property Graph Ontology
The first step in our ER process is to ETL multiple datasets into a common form - in silver tables - in our property graph ontology. Then a single model can be used for each type - rather than having to work across multiple schemas. This simplifies the implementation of entity resolution.

-
Ditto Encode Nodes using Pre-Trained Language Models
As mentioned above, we use the Ditto encoding to encode documents as text documents with column name/type hints which we then embed using a pre-trained language model. Graph Neural Networks accept arbitrary input as features - we believe Ditto provides a general purpose encoding for multiple operations including entity resolution and link prediction.
-
Blocking Records with Sentence Transformers and Locality Sensitive Hashing (LSH)
Large knowledge graphs (property graphs) have too many records to perform an algebraic comparison of all records to all records - it is N^2 complexity!

We use Sentence Transformers (PyPi) (Github) for blocking, as in Ditto. We incorporate network topological features in addition to node features in the blocker.

Note: LSH is powerful for many operations using pairs of network nodes! Google Grale is described in Grale: Designing Networks for Graph Learning, Halcrow et al, 2020 (arXiv) from Google Research. Grale is a powerful paper from Google Research LSH is an incredibly powerful algorithm - for large graph ML the algorithm isn't MapReduce - it is MapLSH - for approximate grouping. -
Entity Matching with Graph Attention Networks
TBD :)

DBLP is a database of scholarly research in computer science.
The datasets we use are the actual DBLP data and a set of labels for entity resolution of authors.
- DBLP Official Dataset is available at https://dblp.org/xml/dblp.xml.gz.
- Feilx Naumann's DBLP Dataset 2 by Prof. Dr. Felix Naumann available in DBLP10k.csv is a set of 10K labels (5K true, 5K false) for pairs of authors. We use it to train our entity resoultion model.
Note that there are additional labels available as XML that we haven't parsed yet at:
- Felix Nauman's DBLP Dataset 1 is available in dblp50000.xml
The DBLP XML and the 50K ER labels are downloaded, parsed and transformed into a graph via graphlet.dblp.__main__ via:
python -m graphlet.dblpWe believe RDF/SPARQL are based on the false assumptions of the Semantic Web, which did not work out.

The reality is more like this, which our system is optimized for. At present we are not focusing on NLP, information extraction and entity linking in favor of tools optimized for building property graphs by using ETL to transform many datasets into a uniform ontology for solving problems using ML and information retrieval.