googlecolab / colabtools Goto Github PK
View Code? Open in Web Editor NEWPython libraries for Google Colaboratory
License: Apache License 2.0
Python libraries for Google Colaboratory
License: Apache License 2.0






































































































































































































While installing caffe-cpu it asks for continue Y/N but how to give input as Y
using this command
!apt install caffe-cpu
Need to get 79.2 MB of archives.
After this operation, 298 MB of additional disk space will be used.
Do you want to continue? [Y/n]
_
I am using this tool for first time and I set up the tool for using GPU . I installed tensorflow with GPU and tensorflow in itself is working fin. But when keras is called which uses tf as backend the session dies and restarts.
import google.colab.output
print('one')
with google.colab.output.use_tags(['logging']):
print('two')
print('three')yields:
/usr/local/lib/python2.7/dist-packages/google/colab/output/_tags.pyc in _add_or_remove_tags(tags_to_add, tags_to_remove)
45 'nodisplay': True,
46 'add_tags': tags_to_add,
---> 47 'remove_tags': tags_to_remove
48 }
49 })
TypeError: publish_display_data() got multiple values for keyword argument 'metadata'
Args should follow:
https://github.com/ipython/ipython/blob/43994e7b6fa1afd849fd36edc0cae45083f4857b/IPython/core/display.py#L79
I installed the library (from the notebook itself) and it showed the installation is successful
!pip install bokeh
but when I use it. It doesn't show anything (not even an error). Just blank output. When I check chrome's Javascript console, I see the follwoing
Bokeh: ERROR: Unable to run BokehJS code because BokehJS library is missing
I tried to download file yesterday and it worked. the same code is showing error today !!
basically, i am using this:
from google.colab import files
files.download('amit.txt')
MessageError: TypeError: Failed to fetch
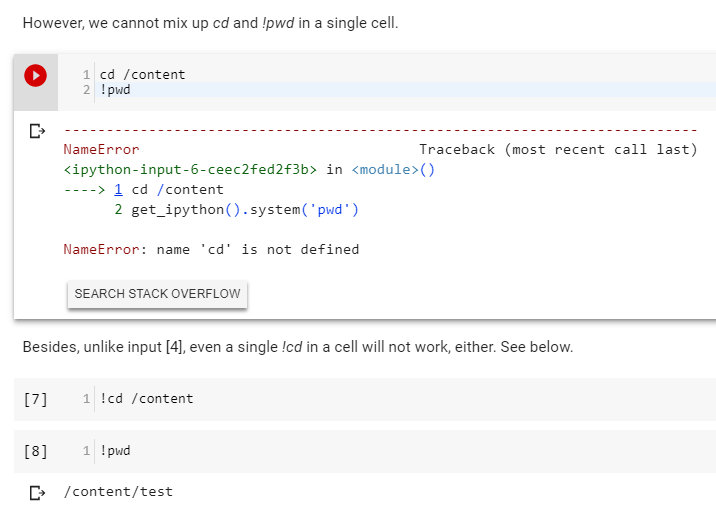
When attempting to change directory with !cd command, it didn't seem to work well. A notebook to reproduce this issue can be found at https://colab.research.google.com/notebook#fileId=1C9x_lQreBVBUvIBOtJD0NHecD6UAHYv4
For your convenience, the screenshots are also attached.

Hi,
I am unable to use the colb, while trying to open it is giving below error as
"NotSupportedError: Failed to register a ServiceWorker: The user denied permission to use Service Worker."
While using below code getting error.
#Uploading the Dataset
from google.colab import files
uploaded = files.upload()
Upload widget is only available when the cell has been executed in the current browser session. Please rerun this cell to enable.
Thanks in Advance.
Regards,
Mallikarjun

The following doesn't work in Google Colab
from ipywidgets import interact
def f(x):
return x
interact(f, x=10)
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secr
and output:
gpg: /tmp/tmpb1cyw0o_/trustdb.gpg: trustdb created
gpg: key AD5F235DF639B041: public key "Launchpad PPA for Alessandro Strada" imported
gpg: Total number processed: 1
gpg: imported: 1
Warning: apt-key output should not be parsed (stdout is not a terminal)
Please, open the following URL in a web browser: https://accounts.google.com/o/oauth2/auth?client_id=32555940559.apps.googleusercontent.com&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive&response_type=code&access_type=offline&approval_prompt=force
··········
Please, open the following URL in a web browser: https://accounts.google.com/o/oauth2/auth?client_id=%7Bcreds.client_id%7D&redirect_uri=urn%3Aietf%3Awg%3Aoauth%3A2.0%3Aoob&scope=https%3A%2F%2Fwww.googleapis.com%2Fauth%2Fdrive&response_type=code&access_type=offline&approval_prompt=force
Please enter the verification code: Cannot retrieve auth tokens.
Failure("Unexpected error response: {\n \"error\" : \"invalid_client\",\n \"error_description\" : \"The OAuth client was not found.\"\n}")
Text cells are not treated as spellcheck eligible in chrome
A previous run-time error continues to sustain when attempting to import a different library.
Particularly when testing installation of ROS framework -
!apt-get install ros-indigo-desktop-full
Its obvious this wouldn't work. But I was curious about the result.
Result
E: Malformed entry 1 in list file /etc/apt/sources.list.d/ros-latest.list (Component)
E: The list of sources could not be read.
The point being post this attempt, any other attempt to install a valid library results in the similar error.
!apt-get -qq install -y libarchive-dev && pip install -q -U libarchive
import libarchive
Result:
E: Malformed entry 1 in list file /etc/apt/sources.list.d/ros-latest.list (Component)
E: The list of sources could not be read.
E: Malformed entry 1 in list file /etc/apt/sources.list.d/ros-latest.list (Component)
E: The list of sources could not be read.
ImportErrorTraceback (most recent call last)
in ()
1 get_ipython().system(u'apt-get -qq install -y libarchive-dev && pip install -q -U libarchive')
----> 2 import libarchive
ImportError: No module named libarchive
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
Examples of installing some common dependencies can be found at:
https://colab.research.google.com/notebook#fileId=/v2/external/notebooks/snippets/importing_libraries.ipynb
Here's the interesting observation,
When the libarchive installtion is attempted in a different working directory (different Google drive), it executes as suggested in the tutorial.
I am suspecting the cause to be in the build environment.
I have import h5py in colab like this
!pip install h5py
import h5py
but when I save model use model.save(), the error of missing h5py still occur:
ImportErrorTraceback (most recent call last)
<ipython-input-33-14c760cfc8c2> in <module>()
20 print("训练耗时:%f 秒" %(finish-start))
21 # 保存模型
---> 22 model.save("health_and_tech_design.h5")
23
24 # 加载预训练的模型
/usr/local/lib/python2.7/dist-packages/keras/engine/topology.pyc in save(self, filepath, overwrite, include_optimizer)
2554 """
2555 from ..models import save_model
-> 2556 save_model(self, filepath, overwrite, include_optimizer)
2557
2558 def save_weights(self, filepath, overwrite=True):
/usr/local/lib/python2.7/dist-packages/keras/models.pyc in save_model(model, filepath, overwrite, include_optimizer)
55
56 if h5py is None:
---> 57 raise ImportError('`save_model` requires h5py.')
58
59 def get_json_type(obj):
ImportError: `save_model` requires h5py.
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
---------------------------------------------------------------------------
I am having the next issue when try to load a file from drive that is bigger than 10mb.
the code:
file_id = ...
import io
from googleapiclient.http import MediaIoBaseDownload
request = drive_service.files().get_media(fileId=file_id)
downloaded = io.BytesIO()
downloader = MediaIoBaseDownload(downloaded, request)
done = False
while done is False:
_, done = downloader.next_chunk()
downloaded.seek(0)
print('Downloaded file contents are: {}'.format(downloaded.read()))
The issue:
IOPub data rate exceeded. The notebook server will temporarily stop sending output to the client in order to avoid crashing it. To change this limit, set the config variable --NotebookApp.iopub_data_rate_limit.
Current values: NotebookApp.iopub_data_rate_limit=1000000.0 (bytes/sec) NotebookApp.rate_limit_window=3.0 (secs)
Using the %load magic causes the runtime to hang and disconnect.

As shown above, this issue is easy to reproduce. Also, %load hangs when loading code from the namespace, i.e:
def test_func(x, y):
return x + y
%load -n test_func
Some tasks need interactions between JS frontend and python backend.
Please add support for IPython.notebook.kernel.execute(python_code)
Also, some modules like ipyleaflet, bqplot, and other Jupyter Widgets don't work without them.
When training is almost complete (1 min remaining), kernel restarts. I've tried this many times, same thing happens. Also I have to install dependencies again.
Monokai ? the current colors are hurting the eyes =)
Currently Google Colaboratory uses 2 spaces for 1 tab.
I personally prefer using 4 spaces for 1 tab. This quickly leads to tabulation errors when copy-pasting code from a local text editor to an already partially filed notebook cell.
Could we add a setting allowing the user to specify the number of spaces corresponding to 1 tab.
PS
I tried to change it using the browser's js console:
var cell = colab.Notebook.get_selected_cell();
var config = cell.config;
var patch = {
CodeCell:{
cm_config:{indentUnit:4}
}
}
config.update(patch)get_selected_cell is not defined, I will still need to play a bit to get it working
^
There should be an easy way to play audio files in the browser, with the option of being ephemeral.
Currently the code to do this is:
import os
import socket
import threading
import IPython
import portpicker
from six.moves import SimpleHTTPServer
from six.moves import socketserver
from google.colab import output
class _V6Server(socketserver.TCPServer):
address_family = socket.AF_INET6
class _FileHandler(SimpleHTTPServer.SimpleHTTPRequestHandler):
"""SimpleHTTPRequestHandler with a couple tweaks."""
def translate_path(self, path):
# Client specifies absolute paths.
return path
def log_message(self, fmt, *args):
# Suppress logging since it's on the background. Any errors will be reported
# via the handler.
pass
def end_headers(self):
# Do not cache the response in the notebook, since it may be quite large.
self.send_header('x-colab-notebook-cache-control', 'no-cache')
SimpleHTTPServer.SimpleHTTPRequestHandler.end_headers(self)
def play_audio(filename):
"""Downloads the file to the user's local disk via a browser download action.
Args:
filename: Name of the file on disk to be downloaded.
"""
started = threading.Event()
port = portpicker.pick_unused_port()
def server_entry():
httpd = _V6Server(('::', port), _FileHandler)
started.set()
# Serve multiple requests, in case the audio is played more than once.
httpd.serve_forever()
thread = threading.Thread(target=server_entry)
thread.start()
started.wait()
output.eval_js("""
(()=> {
const audio = document.createElement('audio');
audio.controls = true;
audio.autoplay = true;
audio.src = `https://localhost:%(port)d%(path)s`;
document.body.appendChild(audio);
})()
"""% {'port': port, 'path': os.path.abspath(filename)})
print('playing')
play_audio('noise2.wav')Save Failed
Invalid query
GapiError: Invalid query
at Yr.Hg [as constructor] (https://colab.research.google.com/v2/external/external_polymer_binary.js?vrz=colab_20171221_134930-RC01_179872204:523:1430)
at new Yr (https://colab.research.google.com/v2/external/external_polymer_binary.js?vrz=colab_20171221_134930-RC01_179872204:829:252)
at https://colab.research.google.com/v2/external/external_polymer_binary.js?vrz=colab_20171221_134930-RC01_179872204:893:410
at https://apis.google.com/_/scs/apps-static/_/js/k=oz.gapi.en.rH_DNAowp7o.O/m=client/rt=j/sv=1/d=1/ed=1/am=AQ/rs=AGLTcCPjBnH1F4aCnBCh3-1YeKgkbV6kbg/cb=gapi.loaded_0:600:208
at https://apis.google.com/_/scs/apps-static/_/js/k=oz.gapi.en.rH_DNAowp7o.O/m=client/rt=j/sv=1/d=1/ed=1/am=AQ/rs=AGLTcCPjBnH1F4aCnBCh3-1YeKgkbV6kbg/cb=gapi.loaded_0:595:220
at https://apis.google.com/_/scs/apps-static/_/js/k=oz.gapi.en.rH_DNAowp7o.O/m=client/rt=j/sv=1/d=1/ed=1/am=AQ/rs=AGLTcCPjBnH1F4aCnBCh3-1YeKgkbV6kbg/cb=gapi.loaded_0:584:221
at Object. (https://apis.google.com/_/scs/apps-static/_/js/k=oz.gapi.en.rH_DNAowp7o.O/m=client/rt=j/sv=1/d=1/ed=1/am=AQ/rs=AGLTcCPjBnH1F4aCnBCh3-1YeKgkbV6kbg/cb=gapi.loaded_0:197:72)
at Object.E.__cb (https://apis.google.com/_/scs/apps-static/_/js/k=oz.gapi.en.rH_DNAowp7o.O/m=client/rt=j/sv=1/d=1/ed=1/am=AQ/rs=AGLTcCPjBnH1F4aCnBCh3-1YeKgkbV6kbg/cb=gapi.loaded_0:133:191)
at g (https://apis.google.com/_/scs/apps-static/_/js/k=oz.gapi.en.rH_DNAowp7o.O/m=client/rt=j/sv=1/d=1/ed=1/am=AQ/rs=AGLTcCPjBnH1F4aCnBCh3-1YeKgkbV6kbg/cb=gapi.loaded_0:127:62)
at c (https://apis.google.com/_/scs/apps-static/_/js/k=oz.gapi.en.rH_DNAowp7o.O/m=client/rt=j/sv=1/d=1/ed=1/am=AQ/rs=AGLTcCPjBnH1F4aCnBCh3-1YeKgkbV6kbg/cb=gapi.loaded_0:123:26)
While connecting (and only while connecting) to a (Python 3) runtime, the tooltip status message has "Python 2" in it.
To see docstring lookup, need to execute with ? instead of easier Shift + Tab as it can be done in Jupyter
This does not give the expected result in the TOC,
### The convolution operator $\ast$
Expectation,
I've tried using
!pip install -q http://download.pytorch.org/whl/cu75/torch-0.2.0.post3-cp27-cp27mu-manylinux1_x86_64.whl torchvision import torch
Output:
torch-0.2.0.post4-cp35-cp35m-linux_x86_64.whl is not a supported wheel on this platform.
I've also tried building from the source but conda is not well supported.
I've tried installing with torch 0.3 as well, it shows the same output. Can you update the snippet for installation of Pytorch for manylinux for colab.
When installing a package using apt-get install the machine asks for Y/N but I can't type anything in output
Running the following:
import numpy as np
import matplotlib.pyplot as plt
plt.plot(np.arange(10), linestyle=' ', marker='x')
plt.show()
gives an empty figure and no markers. In general I can't use markers when plotting with matplotlib.
I am trying to connect to a MongoDB, but am receiving this error:
ConfigurationError: Server at c604.candidate.12.mongolayer.com:10604 reports wire version 0, but this version of PyMongo requires at least 2 (MongoDB 2.6).
I believe it is some server configuration because the same script works fine in Jupiter Notebook within my computer.
This is a feature request. It would be nice to be able to resume work from where I left (when launching colab next day), so I would not need to reinstall all my libraries and re-map access to my google drive folder.
I am guessing one can try to store image of VM on google drive
I have placed the dataset file on my drive folder but it is not able to open the files.Please help on where to place these files
``---------------------------------------------------------------------------
OSError Traceback (most recent call last)
in ()
----> 1 X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
2
3 # Normalize image vectors
4 X_train = X_train_orig/255.
5 X_test = X_test_orig/255.
in load_dataset()
6
7 def load_dataset():
----> 8 train_dataset = h5py.File('train_signs.h5', "r")
9 train_set_x_orig = np.array(train_dataset["train_set_x"][:]) # your train set features
10 train_set_y_orig = np.array(train_dataset["train_set_y"][:]) # your train set labels
/usr/local/lib/python3.6/dist-packages/h5py/_hl/files.py in init(self, name, mode, driver, libver, userblock_size, swmr, **kwds)
267 with phil:
268 fapl = make_fapl(driver, libver, **kwds)
--> 269 fid = make_fid(name, mode, userblock_size, fapl, swmr=swmr)
270
271 if swmr_support:
/usr/local/lib/python3.6/dist-packages/h5py/_hl/files.py in make_fid(name, mode, userblock_size, fapl, fcpl, swmr)
97 if swmr and swmr_support:
98 flags |= h5f.ACC_SWMR_READ
---> 99 fid = h5f.open(name, flags, fapl=fapl)
100 elif mode == 'r+':
101 fid = h5f.open(name, h5f.ACC_RDWR, fapl=fapl)
h5py/_objects.pyx in h5py._objects.with_phil.wrapper()
h5py/_objects.pyx in h5py._objects.with_phil.wrapper()
h5py/h5f.pyx in h5py.h5f.open()
OSError: Unable to open file (unable to open file: name = 'train_signs.h5', errno = 2, error message = 'No such file or directory', flags = 0, o_flags = 0)`
Failed building wheel for pocketsphinx
?25h Running setup.py clean for pocketsphinx
Failed to build pocketsphinx
Installing collected packages: pocketsphinx
Running setup.py install for pocketsphinx ... ?25l-� �error
Complete output from command /usr/bin/python3 -u -c "import setuptools, tokenize;__file__='/tmp/pip-build-ng194sfh/pocketsphinx/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /tmp/pip-iw5epd6l-record/install-record.txt --single-version-externally-managed --compile:
running install
running build_ext
building 'sphinxbase._ad' extension
swigging swig/sphinxbase/ad.i to swig/sphinxbase/ad_wrap.c
swig -python -modern -Ideps/sphinxbase/include -Ideps/sphinxbase/include/sphinxbase -Ideps/sphinxbase/include/android -Ideps/sphinxbase/swig -outdir sphinxbase -o swig/sphinxbase/ad_wrap.c swig/sphinxbase/ad.i
unable to execute 'swig': No such file or directory
error: command 'swig' failed with exit status 1
----------------------------------------
Command "/usr/bin/python3 -u -c "import setuptools, tokenize;__file__='/tmp/pip-build-ng194sfh/pocketsphinx/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /tmp/pip-iw5epd6l-record/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /tmp/pip-build-ng194sfh/pocketsphinx/
To avoid cross-posting, see https://stackoverflow.com/questions/47603155/google-cloud-libs-not-working-on-colaboratory
In a nutshell, I understand there is way to interact with other GCloud components (GCS or bq) but I want to experiment with the libraries that I would end up using in production.
In the spirit of 'same code runs everywhere' on GCP, am I missing a required package in colab to make google.cloud work ?
Hi,
Thanks for this awesome service. I have noticed some weird behavior around the Python 3 with GPU runtime. Whenever I open one notebook with the Python 3 with GPU runtime type the python version used is 3 as expected, however, any additional notebooks I open while the other one is still connected end up using Python 2 with GPU, ie.
import sys
print(sys.version)
returns on the first notebook:
3.6.3 (default, Oct 3 2017, 21:45:48)
[GCC 7.2.0]
and on the second and other additionally opened notebooks:
2.7.14 (default, Sep 23 2017, 22:06:14)
[GCC 7.2.0]
If I disconnect and wait until the VM goes away and come back after a while and start the notebooks in the reverse order it is still the notebook that is started first which has Python 3 and the second one getting Python 2, so it does not seem related to settings on the actual notebooks (I also looked at the notebook files in plain text to confirm that the runtime config is identical).
If I switch the runtime type to remove the GPU acceleration the issue seems to go away.
Also ps xauww shows two processes for the two notebooks, the first one running with /usr/bin/python3 and the second with /usr/bin/python.
Screenshot first notebook:

Screenshot second notebook:

Let me know if there is anything else you need to know or if you want me to test anything to help resolving the issue!
Thanks and best regards,
Fabian
Currently, if I have a .csv file (output from some instrument, for example), all options for getting that loaded into the notebook and read into e.g. a Pandas dataframe are pretty awkward. I wouldn't mind so much, but I'm teaching a class of 35 undergrads with minimal programming experience and I'd like to make it easy for them. I feel like this:

with the associated file upload dialog clicking is way more awkward that the equivalent scenario in Azure notebooks where I load the dice.csv file into the workspace before class, and then cells 2-4 just become the usual one line df = pd.read_csv('dice.csv'). In Colab, the students have to point and click and find the data somewhere and execute a few more cells. I could put in on Drive or Sheets or the web, but then there are a bunch of nuisance Google API commands that distract from the Data Science lesson as it would be taught on a stand-alone local Jupyter notebook server with real local file storage. For example, doesn't this seem a bit excessive for a student trying to load one file?

Maybe there is some security concern preventing the "easy" solution of, say, letting a user mark an entire Drive folder containing a Colab notebook as public, and then allowing local file reads within that folder (through a transparent-to-the-user set of background calls to googleapiclient). It's also not clear why the user has to authenticate to download one file. From my end it would be easier to use the API docs to compose the raw file download URL, and then use urllib and io.StringIO to read it back in. But again, couldn't this be even easier?
If there isn't a simpler auxiliary file handling solution already in the works, and since you aren't considering PRs right now, would you welcome a rapidly installable package on PyPI for one-line loading of public GDrive files into Colab? Something as simple (or simpler) than the implementation for Google Cloud Storage file loading?
I only write this because Colab is so awesome and I really love it, but right now for teaching a class, Azure Notebooks is still better because of this one major issue.
_
I have a problem, when I train unet network using the attached code, it stops and prompts "Runtime died, restarting"
And I cannot train the network properly
kindly help me
`from tf_unet import unet, util, image_util
data_provider = image_util.ImageDataProvider("/content/melanoma.1.0/training1/*", data_suffix='padding.jpg', mask_suffix='padding_ground.png')
#setup & training
net = unet.Unet(layers=23, features_root=32, channels=3, n_class=2)
output_path = "/content/unet_model"
trainer = unet.Trainer(net)
path = trainer.train(data_provider, output_path, training_iters=20, epochs=100)`
When I test tfe in colab, I came across the following problem:
pip install tf-nightly-gpu
import tensorflow as tf ===> crash and restarting
can not use latest tf... why?
Hi
For my research I am using a simulator that runs on my machine on some port and I want to train neural network on google colab. Please add a way to make connection between colab and other vpns. I even created a vpn and tried to connect colab to vpn but it didn't work.
I get the following error when I run !openvpn --config client.ovpn
ERROR: Cannot open TUN/TAP dev /dev/net/tun: No such file or directory (errno=2)
Exiting due to fatal error
Edit: I tried this after looking at his page
1.mkdir -p /dev/net
2.mknod /dev/net/tun c 10 200
3.chmod 600 /dev/net/tun
and then when I run !openvpn --config client.ovpn, I am getting the following error
ERROR: Cannot ioctl TUNSETIFF tun: Operation not permitted (errno=1)
2018 Exiting due to fatal error
!pip install vpython worked
but import vpython hangs.
If I interrupt runtime we seem to be stuck in sleep
KeyboardInterrupt Traceback (most recent call last)
in ()
----> 1 import vpython
/usr/local/lib/python3.6/dist-packages/vpython/init.py in ()
35 from .with_notebook import *
36 else:
---> 37 from .no_notebook import *
38
/usr/local/lib/python3.6/dist-packages/vpython/no_notebook.py in ()
157
158 while not (httpserving and websocketserving): # try to make sure setup is complete
--> 159 rate(60)
160
161 GW = GlowWidget()
/usr/local/lib/python3.6/dist-packages/vpython/vpython.py in call(self, N)
209 self.rval = N
210 if self.rval < 1: raise ValueError("rate value must be greater than or equal to 1")
--> 211 super(_RateKeeper2, self).call(self.rval) ## calls call in rate_control.py
212
213 if sys.version > '3':
/usr/local/lib/python3.6/dist-packages/vpython/rate_control.py in call(self, maxRate)
205 dt = self.lastSleep + self.calls*(self.userTime + self.callTime + self.delay) +
206 rendersself.renderTime + sleepsself.interactionPeriod - _clock()
--> 207 _sleep(dt)
208 self.lastSleep = _clock()
209 self.calls = 0
/usr/local/lib/python3.6/dist-packages/vpython/rate_control.py in _sleep(dt)
47 dtsleep = nticks*_tick
48 t = _clock()
---> 49 time.sleep(dtsleep)
50 t = _clock()-t
51 dt -= t
KeyboardInterrupt:
https://colab.research.google.com/notebook#fileId=1eVSKhwQH8eeBWbVXOsUW9nHctcEXOvCh
from IPython import display
from google.colab import output
display.display(display.HTML('''<marquee id='target'></marquee>'''))
with output.redirect_to_element('#target'):
print('hello world!')/usr/local/lib/python3.6/dist-packages/google/colab/output/_js_builder.py in encode(self, o)
379 # This fixes the latter issue. It keeps the former invaild.
380 result = result.replace('</script>', r'<\/script>')
--> 381 for k, v in self._replacement_map.iteritems():
382 result = result.replace('"%s"' % (k,), v)
383 return result
AttributeError: 'dict' object has no attribute 'iteritems'I want to write this:
Your output should be formatted like this:
Lasagne: $4
Pizza: $5
Total: $9
But the $ signs are being interpreted as inline LaTex markers.
I tried escaping them using
Python 2 is deprecated, users should be able to execute Python 3 notebooks.
Trusted outputframes should be able to send and receive messages with other trusted outputframes.
This is to allow widgets in one outputframe to affect the visualization in another one.
I am training an RNN model. My laptop CPU is much faster than The GPU. Is that normal?
The original report is in this Stack Overflow question. I've filed an upstream issue to make this possible, but we could also selectively turn off the logging for the duration of these calls ourselves.
Currently, i have to change language to english everytime I open a new notebook
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
