googlecloudplatform / mlops-on-gcp Goto Github PK
View Code? Open in Web Editor NEWLicense: Apache License 2.0
License: Apache License 2.0
In Lab 02, for "Exercise: build your pipeline with the TFX CLI", the instructions state:
- `ARTIFACT_STORE` - An existing GCS bucket. You can use any bucket or use the GCS bucket created during installation of AI Platform Pipelines. The default bucket name will contain the `kubeflowpipelines-` prefix.
But no such bucket is created by default, you need to create it manually.
I followed the steps to create the notebook. The steps completed successfully but the entry is not coming under "Notebooks" tab in "AI Platform".
The label on the orange box in images/Pusher.png is incorrect - it says "InfraValidator", but it should be "Pusher" instead.
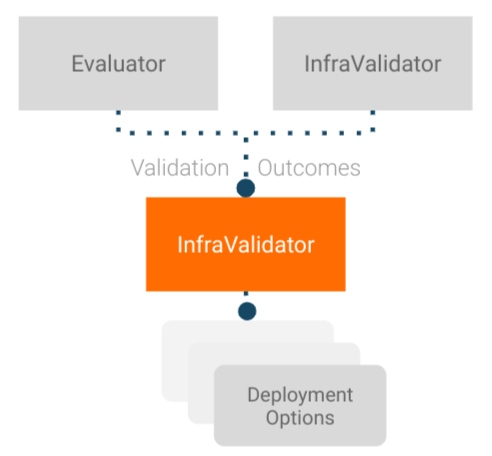
This image is used in the workshops/tfx-caip-tf23/lab-01-tfx-walkthrough/labs/lab-01.ipynb notebook.
In Lab 02, for "Validate lab package version installation", the kfp package is not installed by default:
TFX version: 0.26.3
Traceback (most recent call last):
File "<string>", line 1, in <module>
ModuleNotFoundError: No module named 'kfp'
Fortunately the suggested %pip install --upgrade --user kfp==1.0.4 command works.
It seems that the follow script to create a Kubeflow instance is not working anymore on GCP:
https://github.com/GoogleCloudPlatform/mlops-on-gcp/tree/master/examples/mlops-env-on-gcp/provisioning-kfp
The issue is in the install.sh script and I am getting:
Unable to recognize "STDIN": no matches for kind "Deployment" in version "apps/v1beta2"
current and not working
# Deploy KFP to the cluster
export PIPELINE_VERSION=0.2.5
kustomize build \
github.com/kubeflow/pipelines/manifests/kustomize/base/crds/?ref=$PIPELINE_VERSION | kubectl apply -f -
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kustomize build . | kubectl apply -f -
working solution
# Deploy KFP to the cluster
export PIPELINE_VERSION=1.0.4
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources?ref=$PIPELINE_VERSION"
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "github.com/kubeflow/pipelines/manifests/kustomize/env/dev?ref=$PIPELINE_VERSION"
I am not an expert so I don't do a PR. Just highlighting what was working for me in case it can help other users.
In "mlops-on-gcp/continuous_training/composer/solutions/chicago_taxi_dag.py", line 308
bq_check_rmse_query_op = BigQueryValueCheckOperator(
task_id="bq_value_check_rmse_task",
sql=model_check_sql,
pass_value=0,
tolerence=0,
use_legacy_sql=False,
)
and "mlops-on-gcp/continuous_training/composer/labs/chicago_taxi_dag.py ", line 294
bq_check_rmse_query_op = BigQueryValueCheckOperator(
tolerence=0,
use_legacy_sql=False,
#ADD YOUR CODE HERE
)
the argument "tolerence" should be "tolerance".
I'll submit a PR
In TFX on Cloud AI Platform Pipelines, Cloud Shell is never used in the lab, so the "Activate Cloud Shell" section of the instructions is not needed.
In Lab 02, "Exercise: deploy your pipeline container to AI Platform Pipelines with TFX CLI" fails because Skaffold is not installed by default:
No executable skaffold
please refer to https://github.com/GoogleContainerTools/skaffold/releases for installation instructions.
No container image is built.
Traceback (most recent call last):
File "/home/jupyter/.local/lib/python3.7/site-packages/tfx/tools/cli/container_builder/skaffold_cli.py", line 40, in __init__
stdout=subprocess.DEVNULL)
File "/opt/conda/lib/python3.7/subprocess.py", line 512, in run
output=stdout, stderr=stderr)
subprocess.CalledProcessError: Command '['which', 'skaffold']' returned non-zero exit status 1.
Skaffold can be installed by the following:
curl -Lo skaffold https://storage.googleapis.com/skaffold/releases/v1.30.0/skaffold-linux-amd64 && chmod +x skaffold && sudo mv skaffold /usr/local/bin
The file covertype_training_pipeline.py is missing from its appropriate folder mlops-on-gcp/workshops/kfp-caip-sklearn/lab-02-kfp-pipeline/exercises/pipeline/
Following the instructions for the kfp-caip-sklearn setup, the connection to the notebook popup indicates a missing container and the connection to http://localhost:8080/ fails.

Hi,
I have an endless loop when installing mlops-composer-mlflow.
as far as I understand the code, there is no specific script to install MLFlow Tracking Server.
Problematic paragraph
MLFLOW_TRACKING_EXTERNAL_URI="https://"
# Internal access from Composer to Mlflow
MLFLOW_URI_FOR_COMPOSER=="http://"
while [ "$MLFLOW_TRACKING_EXTERNAL_URI" == "https://" ] || [ "$MLFLOW_URI_FOR_COMPOSER" == "http://" ]
do
echo "wait 5 seconds..."
sleep 5s
MLFLOW_TRACKING_EXTERNAL_URI="https://"$(kubectl describe configmap inverse-proxy-config -n mlflow | grep "googleusercontent.com")
MLFLOW_URI_FOR_COMPOSER="http://"$(kubectl get svc -n mlflow mlflow -o jsonpath='{.spec.clusterIP}{":"}{.spec.ports[0].port}')
done
Command line output:
Waiting for MLflow Tracking server provisioned
wait 5 seconds...
Error on line: 234
Caused by: MLFLOW_TRACKING_EXTERNAL_URI="https://"$(kubectl describe configmap inverse-proxy-config -n mlflow | grep "googleusercontent.com")
That returned exit status: 1
Aborting...
wait 5 seconds...
Error on line: 234
Caused by: MLFLOW_TRACKING_EXTERNAL_URI="https://"$(kubectl describe configmap inverse-proxy-config -n mlflow | grep "googleusercontent.com")
That returned exit status: 1
Aborting...
^C
Debug code:
_<username>_@cloudshell:~/mlops-composer-mlflow _(<gcp_project_name>)_$ kubectl describe configmap inverse-proxy-config -n mlflow
Name: inverse-proxy-config
Namespace: mlflow
Labels: app.kubernetes.io/managed-by=Helm
app.kubernetes.io/name=mlflow
Annotations: meta.helm.sh/release-name: mlflow
meta.helm.sh/release-namespace: mlflow
Data
====
BinaryData
====
Events: <none>
I cannot pass this despite completing the notebook with the bucket value and appropriate credentials

Here is my notebook for reference:
lab-02-Abdur-RahmaanJ.ipynb.txt
I mean, does the solution notebook needs updating?
In Lab 02, when the TFX Tuner SA is configured as documented:
CUSTOM_SERVICE_ACCOUNT = 'tfx-tuner-caip-service-account@qwiklabs-gcp-01-1057c4de4b13.iam.gserviceaccount.com'
Runs of the TFX pipeline fail because Pipelines can't write into the bucket (which is missing by default, see issue #124).
tensorflow.python.framework.errors_impl.PermissionDeniedError: Error executing an HTTP request: HTTP response code 403 with body '{
"error": {
"code": 403,
"message": "Insufficient Permission",
"errors": [
{
"message": "Insufficient Permission",
"domain": "global",
"reason": "insufficientPermissions"
}
]
}
}
'
when initiating an upload to gs://my-missing-bucket/tfx_covertype_continuous_training/
I'm somewhat baffled as to why, since the Tuner SA and a few more all have Object Storage Admin privs on the bucket:
qwiklabs-gcp-01-1057c4de4b13@qwiklabs-gcp-01-1057c4de4b13.iam.gserviceaccount.com | Qwiklabs User Service Account | Storage Admin | qwiklabs-gcp-01-1057c4de4b13 | |
[email protected] | Google Cloud ML Engine Service Agent | AI Platform Service AgentStorage Object Admin | qwiklabs-gcp-01-1057c4de4b13 qwiklabs-gcp-01-1057c4de4b13
tfx-tuner-caip-service-account@qwiklabs-gcp-01-1057c4de4b13.iam.gserviceaccount.com | TFX Tuner CAIP Vizier | Storage Object Admin
Unfortunately you can't really tell from the logs which SA it's using.
When running the pipeline from the notebook two BQ components are failing:

It seems that the first component that succeeds creates a dataset, and the two other components that are failing are doing so because that dataset has already been created by that first component:

The pipeline succeeds though when run directly from the UI.
echo "# Deepak19025" >> README.md
git init
git add README.md
git commit -m "first commit"
git branch -M main
git remote add origin https://github.com/Deepak19025/Deepak19025.git
git push -u origin main
Ran through lab-02-tfx-pipeline 3 times with the following run-times:
I was a bit concerned by this runtime length on a small dataset (~500k examples) for delivery and motivating the use of CAIP pipelines compared to existing CAIP training and prediction services so wanted to flag it and discuss improvement opportunities.
Lot of deprecation warnings and non-fatal errors in the log. I am still learning the KFP interface compared to SmartEngine UI so wasn't sure how to view the runtimes of individual components to profile. From what I can tell, the ordering based on wall time is Trainer > Evaluator > Transform > CsvExampleGen.
To improve performance, are there opportunities to:
I see the GKE cluster created has 2 nodes with autoscaling on for up to 5. Looks like the cluster was well within memory and CPU limits but one of the nodes did have an autoscaler pod run. This guide https://cloud.google.com/ai-platform/pipelines/docs/configure-gke-cluster?hl=en_US#ensure mentions having at least 3 nodes (+1 node) with 2 CPUs with 4GB (+1GB each) memory. Perhaps mirroring this config and allocating more resources upfront would yield performance benefits?
Following the README at mlops-on-gcp/examples/mlops-env-on-gcp/creating-notebook-instance/README.md step by step results in below error:
W: GPG error: http://packages.cloud.google.com/apt gcsfuse-bionic InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY FEEA9169307EA071 NO_PUBKEY 8B57C5C2836F4BEB
E: The repository 'http://packages.cloud.google.com/apt gcsfuse-bionic InRelease' is not signed.
W: GPG error: http://packages.cloud.google.com/apt cloud-sdk-bionic InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY FEEA9169307EA071 NO_PUBKEY 8B57C5C2836F4BEB
E: The repository 'http://packages.cloud.google.com/apt cloud-sdk-bionic InRelease' is not signed.
The command '/bin/sh -c apt-get update -y && apt-get -y install kubectl' returned a non-zero code: 100
ERROR
ERROR: build step 0 "gcr.io/cloud-builders/docker" failed: step exited with non-zero status: 100
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
ERROR: (gcloud.builds.submit) build 9113de9f-5276-4960-8a47-994431acdf5c completed with status "FAILURE"
crogers@mbp-crogers lab-workspace % nano Dockerfile
crogers@mbp-crogers lab-workspace % gcloud builds submit --timeout 15m --tag ${IMAGE_URI} .
Creating temporary tarball archive of 3 file(s) totalling 3.0 KiB before compression.
Uploading tarball of [.] to [gs://PROJECT-REDACTED_cloudbuild/source/1623070913.599017-56c228c79bb6488d876045d2e8ceb9bc.tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/PROJECT-REDACTED/locations/global/builds/9571dabd-6d86-4139-9adf-960de21e3434].
Logs are available at [https://console.cloud.google.com/cloud-build/builds/9571dabd-6d86-4139-9adf-960de21e3434?project=169360861282].```
Work around is to add `RUN curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - ` as the second line of the Dockerfile
Hi -
First of all please allow me to congratulate you on putting together such a clear/concise training on such a complex topic.
May I also suggest that you look into adding a notebook on how to perform predictions using custom routines -
https://cloud.google.com/ai-platform/prediction/docs/custom-prediction-routines
I have tried implementing this but receive errors similar to the below -
regards
Sebastian
The last two lab checkpoints are about creating the pipeline, and then creating the pipeline run, which both can be done regardless if the run succeeds or not.
Section "Deploy the model to AI Platform Prediction", create model resource.
The following code always executes the ELSE part, instead of the IF, which means the resource does NOT get created.
model_name = 'forest_cover_classifier'
labels = "task=classifier,domain=forestry"
filter = 'name:{}'.format(model_name)
models = !(gcloud ai-platform models list --filter={filter} --format='value(name)')
if not models:
!gcloud ai-platform models create $model_name \
--regions=$REGION \
--labels=$labels
else:
print("Model: {} already exists.".format(models[0]))The reason for this to fail is because the following command
gcloud ai-platform models listgenerates the following output:
...@cloudshell:~ (my-project)$ gcloud ai-platform models list
Using endpoint [https://ml.googleapis.com/]
Listed 0 items.The "Using endpoint…" string passes the filter and therefore the models variable is not none.
models == ['Using endpoint [https://ml.googleapis.com/]']This cause the ELSE to be execute, therefore no resource is created.
Section "Deploy the model to AI Platform Prediction", create model version.
A similar thing happens for creating the version:
model_version = 'v01'
filter = 'name:{}'.format(model_version)
versions = !(gcloud ai-platform versions list --model={model_name} --format='value(name)' --filter={filter})
if not versions:
!gcloud ai-platform versions create {model_version} \
--model={model_name} \
--origin=$JOB_DIR \
--runtime-version=1.15 \
--framework=scikit-learn \
--python-version=3.7
else:
print("Model version: {} already exists.".format(versions[0]))The version is not created either.
There are several issues with the ML ops examples.
The first requires modifications to the docker image to work, (and throws many dependency images along the way). Furthermore, it does not describe where to find the link to the running jupyter notebook, or what functionality this example provides. (I can see there is a jupyter instance running, and there is a containerd instance running, but it's unclear how they are related)
The second also fails, but in a way much harder to debug:
Fetching cluster endpoint and auth data.
ERROR: (gcloud.container.clusters.get-credentials) ResponseError: code=400, message=Location "\"us-central1-a\"" does not exist.
Error on line: 97
Caused by: gcloud container clusters get-credentials $CLUSTER_NAME --zone $ZONE --project $PROJECT_ID
That returned exit status: 1
These examples are clearly out of date and need to be checked against newly created vanilla projects.
Building of the mlops-dev image step 4 of the environments_setup/mlops-kfp-mlmd/creating-notebook-instance returns the following error in step 2 of the build:
W: GPG error: http://packages.cloud.google.com/apt gcsfuse-bionic InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 8B57C5C2836F4BEB NO_PUBKEY FEEA9169307EA071
E: The repository 'http://packages.cloud.google.com/apt gcsfuse-bionic InRelease' is not signed.
W: GPG error: http://packages.cloud.google.com/apt cloud-sdk-bionic InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY 8B57C5C2836F4BEB NO_PUBKEY FEEA9169307EA071
E: The repository 'http://packages.cloud.google.com/apt cloud-sdk-bionic InRelease' is not signed.
Adding the following to the Docker file prior to the update statement seems to have fixed it
**RUN curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add - **
Not sure if this is a common error folks have encountered but wanted to flag it.
Which zone should you enter in the following command: ZONE=[YOUR_ZONE]? What should [YOUR_ZONE] be replaced with?
Perhaps it would be good to give some advice on what region/zone to pick to place notebook in for:
https://github.com/GoogleCloudPlatform/mlops-on-gcp/tree/master/workshops/kfp-caip-sklearn
I had to delete and create my notebook again, it showed up under notebooks, but unable to connect to it...
Is there manner to use *.h5 model file when creating a model resource, and also a model version?
Looks like the only supported file is the *.pb format.
In mlops-on-gcp/workshops/tfx-caip-tf23/lab-01-tfx-walkthrough/solutions/lab-01.ipynb
DATA_ROOT = 'gs://workshop-datasets/covertype/small'
NotFoundError: Error executing an HTTP request: HTTP response code 404 with body '{ "error": { "code": 404, "message": "The requested project was not found.", "errors": [ { "message": "The requested project was not found.", "domain": "global", "reason": "notFound" } ] } } ' when reading gs://workshop-datasets/covertype/small
Also:
gs://workshop-datasets/: ERROR: (gcloud.alpha.storage.ls) gs://workshop-datasets not found: 404.
In lab ''TFX Standard Components Walkthrough'' task#4 ''Clone the example repo within your AI Platform Notebooks instance'' can't be completed becaue the versions used in the intall script are too old.
Specifically, the command
cd mlops-on-gcp/workshops/tfx-caip-tf23
./install.sh
results in error, even specifically mentioned the library version via pip install doesn't work. I think this lab needs to be updated to be compatible with currently supported versions.
Hi,
in google console, it saids composer version is too old(Its now not supporting).
--image-version=composer-1.13.4-airflow-1.10.12
i changed it to
--image-version=composer-1.18.7-airflow-2.2.3
and it worked well.
Can you check this issue please? thx.
In TFX on Cloud AI Platform Pipelines, the instruction state that:
A cluster named cluster-1 was provisioned for you on lab startup
This is not the case, you need to create it manually. Fortunately the defaults for "Create cluster" in the Pipelines creation work, although it takes a solid 5 minutes after everything is up and running until the Qwiklab "Check my progress" for this passes.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.

