ghliu / pytorch-ddpg Goto Github PK
View Code? Open in Web Editor NEWImplementation of the Deep Deterministic Policy Gradient (DDPG) using PyTorch
License: Apache License 2.0
Implementation of the Deep Deterministic Policy Gradient (DDPG) using PyTorch
License: Apache License 2.0














































































































Traceback (most recent call last):
File "D:\Master\Codes\pytorch-ddpg\main.py", line 156, in
train(args.train_iter, agent, env, evaluate,
File "D:\Master\Codes\pytorch-ddpg\main.py", line 44, in train
observation2, reward, done, info = env.step(action)
File "D:\AI\Software\Conda\Miniconda\envs\torch\lib\site-packages\gym\core.py", line 349, in step
return self.env.step(self.action(action))
File "D:\AI\Software\Conda\Miniconda\envs\torch\lib\site-packages\gym\core.py", line 353, in action
raise NotImplementedError
NotImplementedError
Hi Guan-Horng,
Thanks for your great implementation! I am wondering why do we append additional (s a r) pair to the replay buffer after one episode is done? The reward in that pair is zero, I think it is probably not mentioned in the original paper.
Line 64 in e9db328
Thank you!
At line 127 in file ddpg.py, I think we should squeeze index 0 instead of index 1. However, because the two example game action space is only 1 dim, so this bug didn't show out.
I tried it on a high-dimensional action space, it only works when I change it to 0.
I have a question about the following line in the code in the training logic:
Line 75 in e9db328
In the computation of the target Q-values, shouldn't the multiplication be done with
(1-to_tensor(terminal_batch.astype(np.float)))
as we would like the next state Q-values to be zeroed if the state was terminal. In fact, in this case the next state might not belong to the same episode as the current state, thus the evaluation of the target network is invalid.
Apologies if I'm missing something trivial.
What is needed to implement GPUs?
target_q_batch = to_tensor(reward_batch) + \
self.discount*to_tensor(terminal_batch.astype(np.float))*next_q_values
I think it should be
target_q_batch = to_tensor(reward_batch) + \
self.discount*to_tensor(1.0 - terminal_batch.astype(np.float))*next_q_values
Hi, I'm not sure if it would calculate the gradient of the action-value with respect to actions?
policy_loss = -self.critic([
to_tensor(state_batch),
self.actor(to_tensor(state_batch))
])
In the definition of the train function (https://github.com/ghliu/pytorch-ddpg/blob/master/main.py#L16) the second argument is called gent instead of agent, but it is referred as agent inside the function.
Hi, thank you for this great implementation!!
However, I'm not very sure about the effect of normalized_env.py. Actually, if I remove it, the results seem to be worse than not removing it. What does it do?
Look forward to your reply!
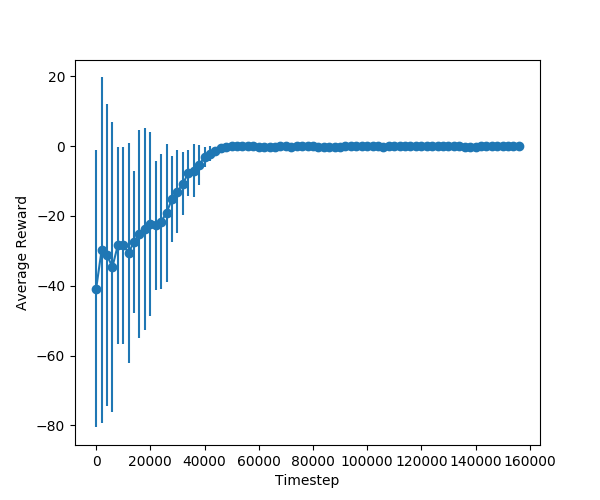
I used the code to train MountainCarContinuous-v0 directly.
But reward converges to 0.
I tried with same setting and the final stable average reward is close to 0, instead of 100. Is anyone tried this implementation doing getting expected values?
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.