EdgeOpenCL(EDCL) is a C++11 based framework developed to hide the complexity of programming on a heterogeneous mobile SoC like Snapdragon 845.
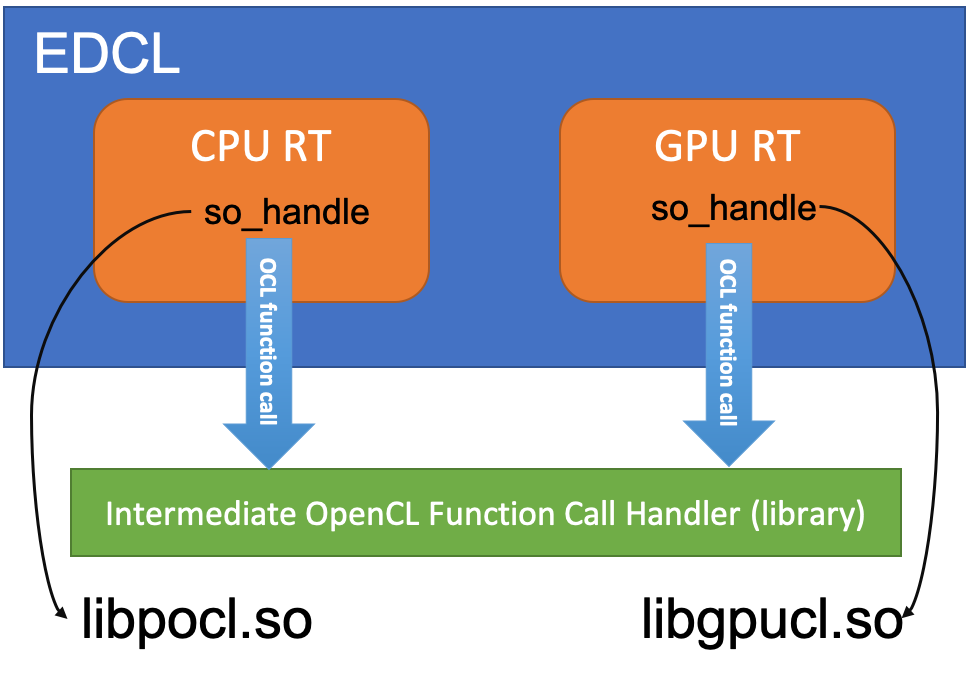
The image above shows the structure of EDCL. EDCL holds two OpenCL runtime(RT) objects, one for the CPU and another for the GPU. Each OpenCL RT object keeps a dynamic library handle(returned by dlopen()) associated with corresponding OpenCL libray. An OpenCL function call layer is implemented to handle OpenCL function invocations.
EDCL also keep track of the resource usage like creating and releasing command queues, buffer objects, kernel objects, etc.. Here's an example of using EDCL performing a vector addition followed by a matrix addition:
#include "EDCL.h"
#include "EDCL_Scheduler.h"
const char *source =
#include "vecAdd.cl"
unsigned int vDim = 4096;
uint n = vDim * vDim;
size_t nByte = n * sizeof(float);
size_t glob_MA[2] = {vDim / 4, vDim};
size_t local_MA[2] = {32, 32};
size_t glob_VA[1] = {n};
size_t local_VA[1] = {1024};
int main() {
EDCL *edcl = new EDCL();
// Init Buffers
EDBuffer A = edcl->createBuffer(nByte);
EDBuffer B = edcl->createBuffer(nByte);
EDBuffer C = edcl->createBuffer(nByte);
fillBuf<float>((float*)A->hostPtr, n);
fillBuf<float>((float*)B->hostPtr, n);
memset(C->hostPtr, 0, nByte);
// Init Kernels
EDProgram prog = edcl->createProgram(&source);
// program, kernel name, number of args
EDKernel matAdd = edcl->createKernel(prog, "matAdd", 5);
EDKernel vecAdd = edcl->createKernel(prog, "vecAdd", 4);
// Config kernel: work_dim, global_work_size, local_work_size, arg1, arg2...
matAdd->configKernel(2, glob_MA, local_MA, A, B, C, &vDim, &vDim);
matAdd->addSubscriber(edcl, vecAdd);
vecAdd->configKernel(1, glob_VA, local_VA, A, B, C, &n);
// Get a scheduler instance
auto scheduler = EDCL_Scheduler::getInstance(edcl);
scheduler->submitKernels(matAdd, vecAdd);
// Create scheduling strategy
Sequential strategy(edcl);
// Set strategy parameters
strategy.setExecutionDevice(GPU);
// Execution
scheduler->executeKernels(strategy);
std::cout << "Planing overhead: " << strategy.planingTime;
std::cout << ", execution time: " << strategy.executionTime << "\n";
delete edcl;
return 0;
}Two kernels in vecAdd.cl, matAdd and vecAdd, are created and submitted to the scheduler. Here vecAdd is a subscriber of matAdd meaning that the execution of vecAdd depends on the completion of matAdd. A simple sequential scheduling strategy is used here. Developers can implement their own scheduling strategies.
EDProgram and EDKernel both keep two copies of their corresponding OpenCL objects for GPU and CPU. EDKernel will keep a reference to each kernel argument and will only set the arguments once the execution environment is confirmed (with EDQueue). An EDKernel can accept other kernels as its subscribers and all the subscribers will wait for its completion of execution. For example, kernel A can subscribe to kernel B B->addSubscriber(A), and A will wait for the completion of execution of Kernel B. To achieve cross-platform clevent like functionalities, an EDUserEvent which contains user events for both OpenCL platforms will be created. Later, kernel A will submit the corresponding user event to an event waiting list when calling clEnqueueNDRangeKernel. Once B completes, it will notify all its subscribers by setting the status of all EDUserEvents in the subscriber list to COMPLETE.
EDQueue is a wrapper class for OpenCL's cl_command_queue. Each EDQueue is bound to a physical device. During the initialization stage, EDCL will gather basic information about the SoC like number of levels of heterogeneity, number of compute units(CUs) at each level. For a Snapdragon 845(the SoC I used), Qualcomm provides OpenCL library for the GPU. Though there are two CUs in Adreno 630, Qualcomm's OpenCL implementation doesn't allow users to create sub-devices. As for the CPU, you can use your own CPU OpenCL library on Android like POCL that you can create sub-device containing any number of CUs and physically bind each CU to a CPU core by setting its affinity. As a result, various device partitioning schemes can be created and developers can assign different tasks to each device partition.
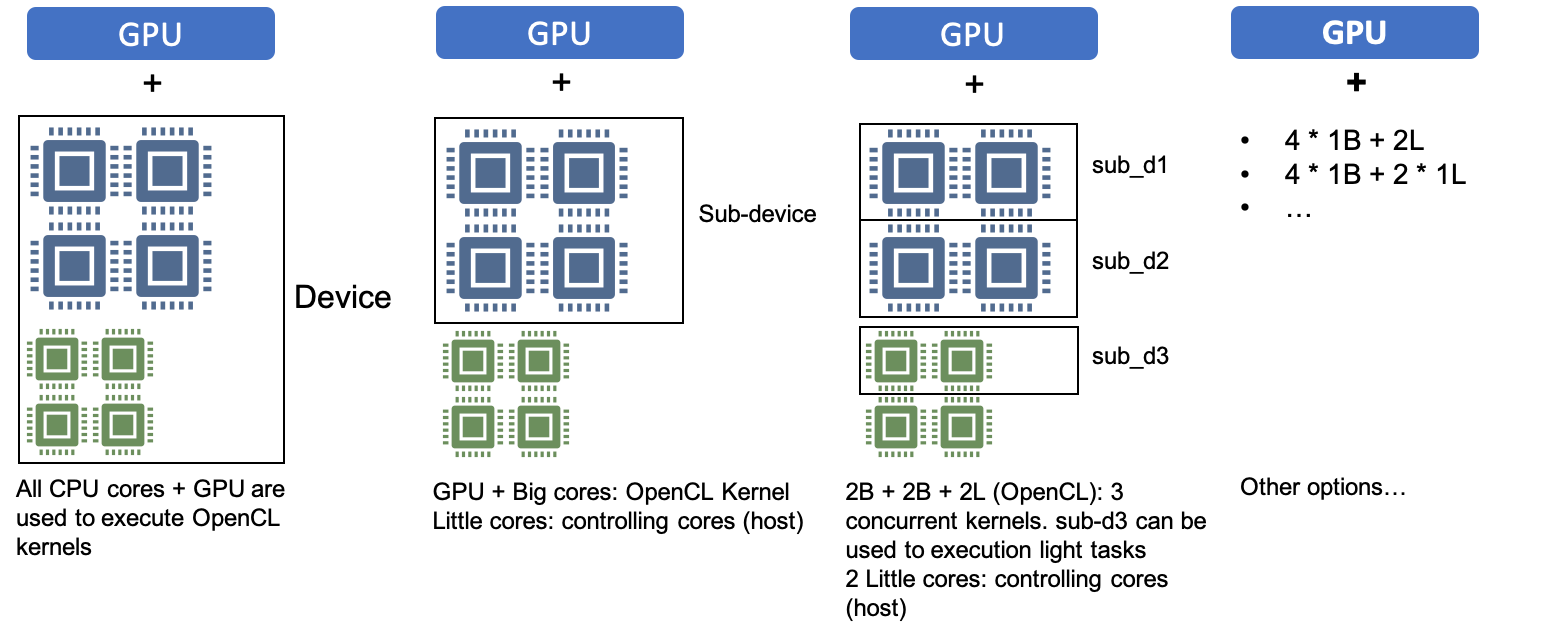
The image above demonstrates some possible partitioning examples which the framework supports. All user needs to do are creating EDQueue for OpenCL kernel execution and setting core affinities.
To take advantage of shared main memory design of the mobile SoC, we can choose to keep only one physical copy of data and let both CPU and GPU cl_mem object and a host pointer point to that memory region as shown in the figure below:

The scheduler class is responsible for managing kernels and executing those kernels with a given strategy. The scheduling process consists of three phases: planning, executing and finishing. Developers only need to implement these three functions for their own strategies. An instance of the resource manager will be passed to each phase so that a strategy can request system resources like a command queue for a specific device where no other kernels can be executed except via this command queue, setting frequencies of processors, etc.. During the planning phase, a strategy can prepare for its necessary data. For example, a machine learning based scheduling scheme may need to extract the kernel features and train some models. Runtime execution process should be implemented in the execute() function. When the execution completes, resources such as temporary memory space and command queues should be released in the finishing phase.
This class provides some handy functions related to the hardware like, recording energy consumption indicator, setting CPU core affinity, setting processors' frequencies, querying hardware information, etc.
Unlike development board like Odroid-XU3, many smartphones don't have a dedicated power meter to directly measure the power consumption in realtime. To estimate the power consumption, a new metric called energy consumption indicator(ECI) is used in EDCL. For a processor, the power can be calculated with P = CV^2f where P is the power, C is the capacitance of processor, V is the supplied voltage, and f is frequency. Along with Ohm's law (V = IR), the power consumption can be roughly related to the current and frequency whose values can be read from the Android OS (current: /sys/class/power_supply/, GPU frequency: /sys/class/kgsl/kgsl-3d0/, and CPU frequencies: /sys/devices/system/cpu/cpufreq/).
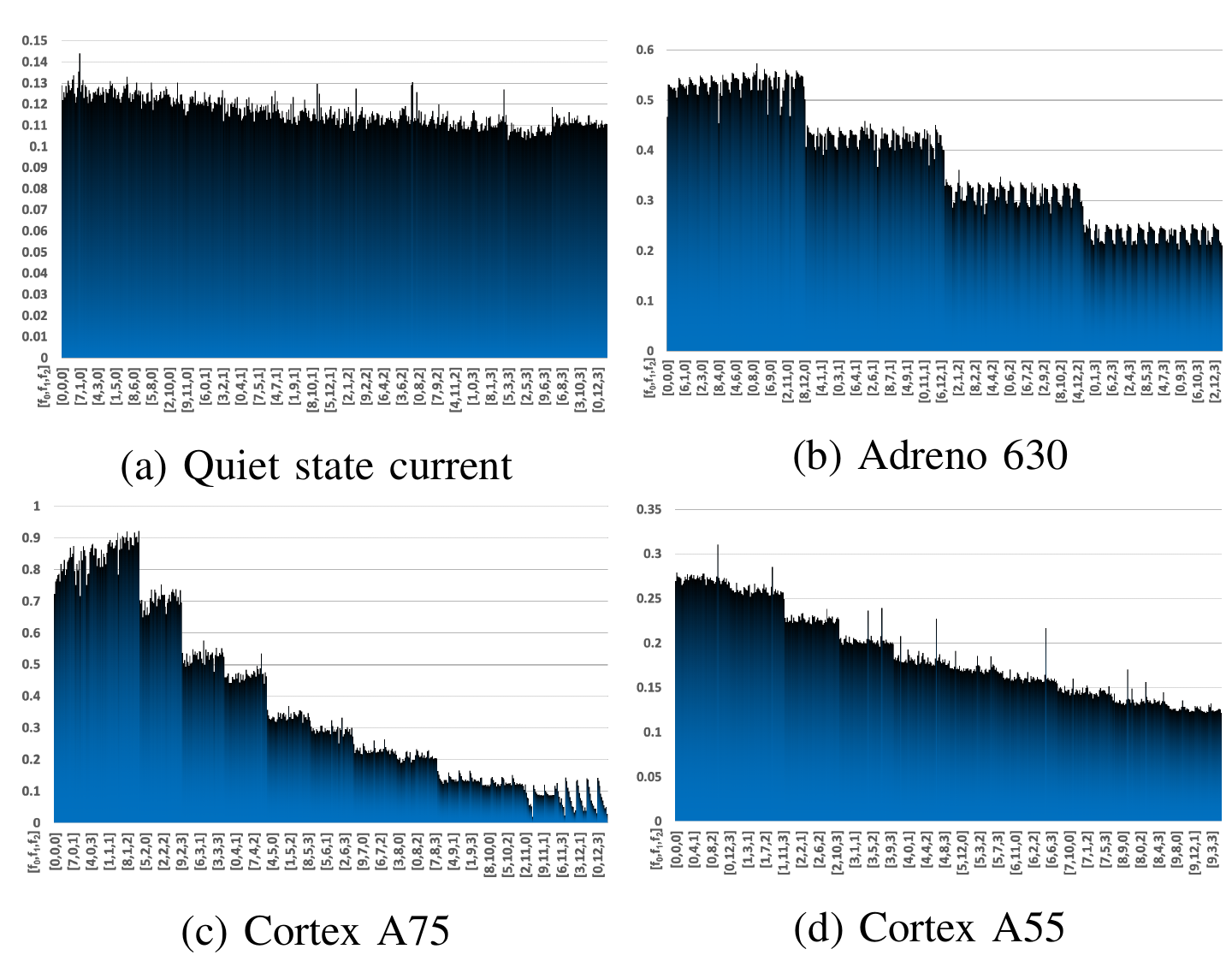
The figure above shows the scaled current value under different frequency combinations(quiet state means no other process except the OS background processes and the current monitor process were running). ECI is an indicator estimated by measuring the frequency and current in realtime.
Each EDKernel instance holds a list of subscriber kernels who have to wait for the completion of subscribed kernels. For all submitted kernels, the dependency relationship can be represented by a directed acyclic graph(DAG). Then we can assign each kernel with a scheduling priority number(larger number has higher priority). Here's an example of DAG and kernel priority number:

When scheduling the execution, kernels with the same priority number can run in parallel on different devices safely. In addition, by further analysing the subscriber list (of kernels with the same priority number), a scheduler strategy can have a better understanding of the dependency relationship easily.
Kernel slicing is a technique which splits an OpenCL kernel into sub-kernels. Slicing is a technique commonly used during runtime execution for better hardware utilization. EDCL library also provides a kernel slicing mechanism which doesn't require remapping or flatten high dimensional kernel to on dimension. EDCL takes a slice factor as a reference or a guide to the number of slices. The number of slices generated will be in the same magnitude of 2^sliceFactor.

The figure above illustrates an example of slicing a kernel with work group size of 7x6 and sliceFactor=2.
OpenCL library for GPU: can be pulled from the smartphone from /vendor/lib64/libOpenCL.so if the vendor provides one.
OpenCL library for CPU: I cross-compiled POCL for Snapdragon 845. I briefly described how I managed to do that in the issue here
Other dependencies and building script can be found in another repository pocl-android-dependency
[1] P. Pandit and R. Govindarajan, “Fluidic kernels: Cooperative execution
of opencl programs on multiple heterogeneous devices,” in Proceedings
of Annual IEEE/ACM International Symposium on Code Generation and
Optimization, 2014, pp. 273–283.
[2] J. Zhong and B. He, “Kernelet: High-throughput gpu kernel executions
with dynamic slicing and scheduling,” IEEE Transactions on Parallel
and Distributed Systems, vol. 25, no. 6, pp. 1522–1532, 2013.
[3] A. K. Singh, K. R. Basireddy, A. Prakash, G. V. Merrett, and B. M. Al-
Hashimi, “Collaborative adaptation for energy-efficient heterogeneous
mobile socs,” IEEE Transactions on Computers, vol. 69, no. 2, pp. 185–
197, 2019.
[4] B. Taylor, V. S. Marco, and Z. Wang, “Adaptive optimization for
opencl programs on embedded heterogeneous systems,” ACM SIGPLAN
Notices, vol. 52, no. 5, pp. 11–20, 2017.
[5] S. Pai, M. J. Thazhuthaveetil, and R. Govindarajan, “Improving gpgpu
concurrency with elastic kernels,” ACM SIGARCH Computer Architecture
News, vol. 41, no. 1, pp. 407–418, 2013.
1. krrishnarraj/pocl-android-prebuilts
2. cameron314/concurrentqueue
3. ben-strasser/fast-cpp-csv-parser
4. PolyBench/GPU
5. Parboil Benchmarks
6. zuzuf/freeocl
7. krrishnarraj/libopencl-stub
Disclaimer: This library was developed based on a research project I was doing in HKU till early 2021. It's no longer maintained or updated since then. The original code was developed as a proof of concept and has been tested on Snapdragon 845, 855 and 655 only.
