facebookresearch / adversarial-continual-learning Goto Github PK
View Code? Open in Web Editor NEWImplementation for the paper "Adversarial Continual Learning" in PyTorch.
License: MIT License
Implementation for the paper "Adversarial Continual Learning" in PyTorch.
License: MIT License















































































































Hi Sayna,
I am testing Cifar10 dataset with the ACL code whatever samples value I provide in the config file I am getting this error once It reached saving the model for task 3 , its look like the generator is not generating any new samples ? your input is appreciated.
Test on task 0 - CIFAR10-0-[26, 86, 2, 55, 75, 93, 16, 73, 54, 95]: loss=0.005, acc=100.0% <<<
Test on task 1 - CIFAR10-1-[53, 92, 78, 13, 7, 30, 22, 24, 33, 8]: loss=0.353, acc= 87.6% <<<
Test on task 2 - CIFAR10-2-[43, 62, 3, 71, 45, 48, 6, 99, 82, 76]: loss=0.715, acc= 50.0% <<<
Saved accuracies at ./checkpoints/1fe898adc337474abbf3eaacc1c71d8e/cifar10_10_tasks_seed_0.txt
Files already downloaded and verified
Files already downloaded and verified
printing test_tt []
printing test_td []
Traceback (most recent call last):
File "main.py", line 189, in
main(args)
File "main.py", line 170, in main
acc, bwt = run(args, n)
File "main.py", line 98, in run
dataset = dataloader.get(t)
File "/home/tarek/ACL/Adversarial-Continual-Learning/src/dataloaders/cifar10.py", line 259, in get
train_loader = torch.utils.data.DataLoader(train_split, batch_size=self.batch_size, num_workers=self.num_workers,
File "/home/tarek/PycharmProjects/pythonProject/venv/lib/python3.8/site-packages/torch/utils/data/dataloader.py", line 224, in init
sampler = RandomSampler(dataset, generator=generator)
File "/home/tarek/PycharmProjects/pythonProject/venv/lib/python3.8/site-packages/torch/utils/data/sampler.py", line 95, in init
raise ValueError("num_samples should be a positive integer "
ValueError: num_samples should be a positive integer value, but got num_samples=0
Hi, I have a question regarding the replay buffer. If I set use_memory = True in the config file, it has no effect. Where exactly do you use the replay buffer in the code?
In the paper the number of validation samples not used for training is mentioned to be 375 out of 2500 per task. Which accounts to 15% of the training samples while in the code it is mentioned as 2% (pc_valid = 0.02). Can you please let me know which is the final validation ratio?
Hi , thank you for making the code opensource. I am trying to load my own png image dataset to acl, however I encounter some problems,



Hi @SaynaEbrahimi,
I checked Algorithm 1 L13 In the paper; the private network at task t is optimized after getting the total loss. However, I checked the code in acl.py and could not find the optimizer and the optimization for every private network. Could you please elaborate a bit more about the optimization part of the private networks?
Hi Sayna,
I trained the model, while I am trying to load the saved model the below error is showing up:
elf.class.name, "\n\t".join(error_msgs)))
831 return _IncompatibleKeys(missing_keys, unexpected_keys)
832
RuntimeError: Error(s) in loading state_dict for Target:
Missing key(s) in state_dict: "conv_layer.0.weight", "conv_layer.0.bias", "conv_layer.1.weight", "conv_layer.1.bias", "conv_layer.4.weight", "conv_layer.4.bias", "conv_layer.5.weight", "conv_layer.5.bias", "conv_layer.7.weight", "conv_layer.7.bias", "conv_layer.8.weight", "conv_layer.8.bias", "conv_layer.11.weight", "conv_layer.11.bias", "conv_layer.12.weight", "conv_layer.12.bias", "conv_layer.14.weight", "conv_layer.14.bias", "conv_layer.15.weight", "conv_layer.15.bias", "conv_layer.18.weight", "conv_layer.18.bias", "conv_layer.19.weight", "conv_layer.19.bias", "conv_layer.21.weight", "conv_layer.21.bias", "conv_layer.22.weight", "conv_layer.22.bias", "conv_layer.24.weight", "conv_layer.24.bias"
getting this when training on CIFAR100
| Epoch 33, time=210.8ms/ 14.3ms | Train losses=0.087 | T: loss=0.077, acc=99.44% | D: loss=0.207, acc=100.0%, Diff loss:0.000 |[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
Valid losses=0.579 | T: loss=0.569013, acc=78.93%, | D: loss=0.207, acc=100.00%, Diff loss=0.000 | *
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
| Epoch 34, time=219.4ms/ 20.8ms | Train losses=0.102 | T: loss=0.093, acc=98.68% | D: loss=0.197, acc=100.0%, Diff loss:0.000 |[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
[W pthreadpool-cpp.cc:90] Warning: Leaking Caffe2 thread-pool after fork. (function pthreadpool)
Valid losses=0.633 | T: loss=0.623067, acc=77.60%, | D: loss=0.197, acc=100.00%, Diff loss=0.000 |
Hello,
Thanks a lot for open sourcing the code. I want to reproduce the results using https://github.com/facebookresearch/Adversarial-Continual-Learning/ for miniImageNet for comparison.
However, miniImagenet is divided into 64, 16, 20 classes as train, val, test splits in the original repository. Can you please let me know the exact indices of the images being used for the test and train for your model. I want to use the exact images for fair comparison. Each class has 600 images in miniImageNet dataset but which images amongst these are used for train and for test?
If possible it would be great if you can share me your data preparation code so that I could use it directly.
It's wonderful that this code was released to accompany the paper; thanks!
I have trained on the 20-task CIFAR-100 dataset and the models are saved to src/checkpoints. I am now attempting to call the test method in acl.py without first calling the train method like was done during training. I manually set the checkpoint to correspond to the dir of the saved model. I changed the relevant parts of the run() function in main.py to look like this image:
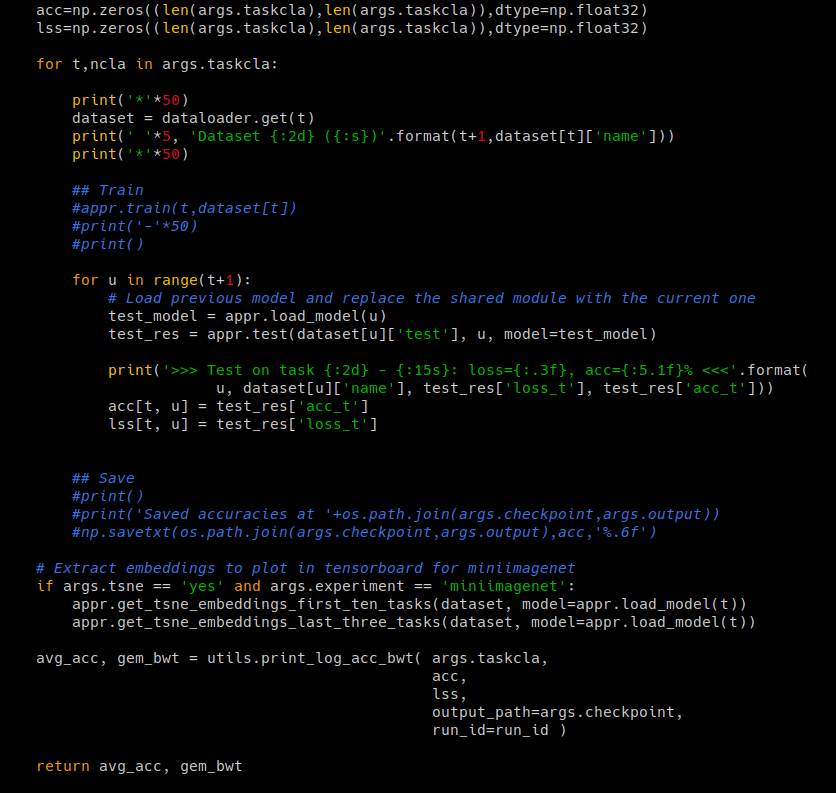
The first task returns a reasonable result I suppose (I only trained the network for 2 epochs each task). But when test is called on the data from the next task, I get the errors in the next image:

There is more output, so here's the final part:
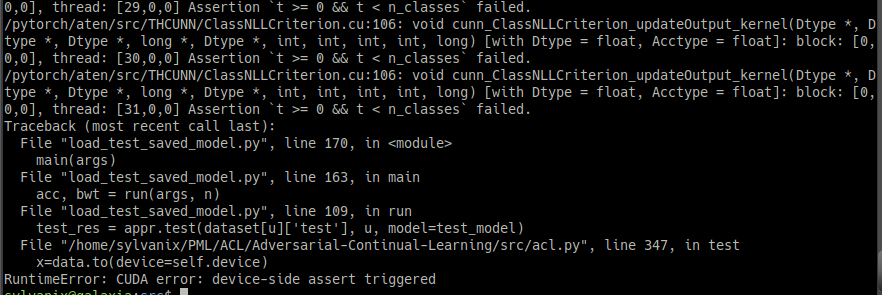
Is there a way to do what I am attempting without substantially changing the code? I know that this is not a shortcoming with the code, I just couldn't help trying some tests with a view to eventually training on my own dataset and using the model for inference.
Hi, thanks for providing the code. You are using a GAN like training to train the shared module. How do you ensure that no mode collapse occurs here? The discriminator has either a 0% or 100% detection rate, which seems a bit odd to me.
I am trying your code, while any of the tests are skipped. I am sure the data is correctly downloaded in /data. Something goes wrong in main.py at " appr.train(t,dataset[t]) " .
How to produce the training part result? Are there some settings that I should change? 5 blank lines in the last part could be 5 running, I guess.
I've tried to redownload the git, I would be appreciated if you help me.
Thanks,

Hi, i want to know what's the difference between the two files "Adversarial-Continual-Learning\src" and "Adversarial-Continual-Learning\ACL-resnet\src" ? They seem to be a little different, such as the private module in the former dosen't need task_id while the latter need. Is the former just an optimized version of the latter code?
Hopes for your reply, thanks.
I have read your program, it is very well written. But there seems to be a problem with logic when testing data.
Task module labels for data seem to be needed when testing the model. But we need to get the label of the data itself to get the task block label, right? But in actual application, it is impossible for us to obtain the label of the data to be detected, which means it is impossible to obtain the label of the task module. If so, what is the use of your proposed method?
我已经阅读了您的程序,它写得很好。 但是在测试数据时逻辑似乎存在问题。
测试模型时,似乎需要数据的任务模块标签。 但是我们需要获取数据本身的标签才能获取任务块标签,对吗? 但是在实际应用中,我们不可能获得待检测数据的标签,这意味着不可能获得任务模块的标签。 如果是这样,您提出的方法有什么用呢?
Hi, thanks for openning ACL codes. I see that there is a parameter ‘diff’ in config file. And in discriminator.py, if args.diff =='yes', there will have GradientReversal in discriminator, otherwise there is no. However, in acl.py, the arg.diff is used to choose whether to use diff_loss. I think the GradientReversal is used for adv_loss of adversarial training, regardless of whether diff loss is used or not. Can you solve my doubts? Thank you!
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.