.png) The Pipe
The Pipe
![]()


Feed PDFs, URLs, Slides, YouTube videos, Word docs and more into Vision-Language models with one line of code ⚡
The Pipe is a multimodal-first tool for feeding files and web pages into vision-language models such as GPT-4V. It is best for LLM and RAG applications that want to support comprehensive textual and visual understanding across a wide range of data sources. The Pipe is available as a hosted API at thepi.pe, or it can be set up locally if you have the the compute.
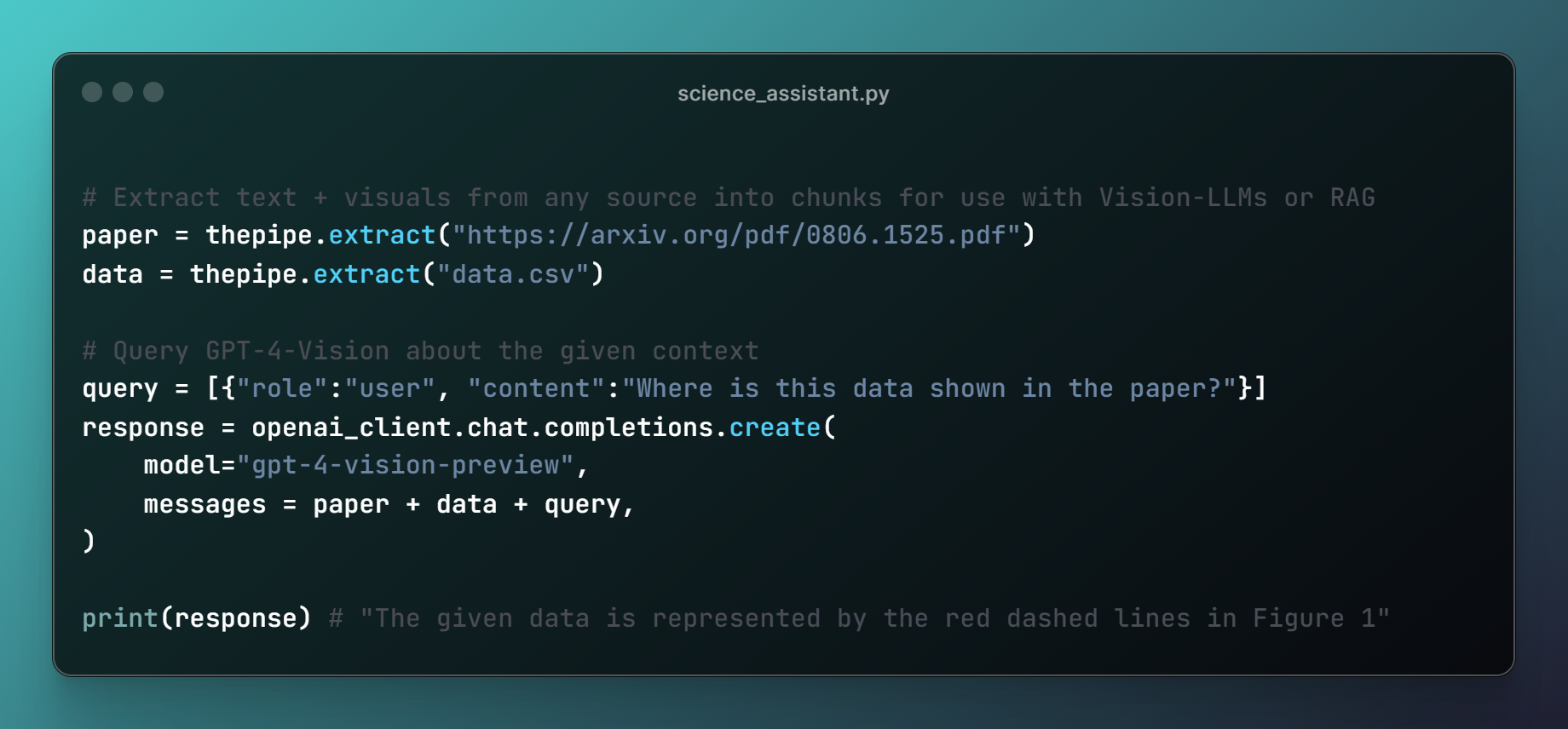
- Extracts text and visuals from files or web pages 📚
- Outputs chunks optimized for multimodal LLMs and RAG frameworks 🖼️
- Interpret complex PDFs, web pages, docs, videos, data, and more 🧠
- Auto-compress prompts exceeding your chosen token limit 📦
- Works even with missing file extensions, in-memory data streams 💾
- Works with codebases, git repos, and custom integrations 🌐
- Multi-threaded ⚡️
The Pipe can read a wide array of file types, and thus has many dependencies that must be installed separately. It also requires a strong machine for good response times. For this reason, we host it as an API that works out-of-the-box.
First, install The Pipe.
pip install thepipe_api
The Pipe is available as a hosted API, or it can be set up locally. An API key is recommended for out-of-the-box functionality (alternatively, see the local installation section). Ensure the THEPIPE_API_KEY environment variable is set. Don't have a key yet? Get one here.
Now you can extract comprehensive text and visuals from any file:
from thepipe_api import thepipe
messages = thepipe.extract("example.pdf")Or websites:
messages = thepipe.extract("https://example.com")Then feed it into GPT-4V like so:
response = openai.chat.completions.create(
model="gpt-4-turbo",
messages = messages,
)
You can also use The Pipe from the command line. Here's how to recursively extract from a directory, matching only files containing a substring (in this example, typescript files) and ignore files containing other substrings (in this example, anything in the "tests" folder):
thepipe path/to/folder --match tsx --ignore tests| Source Type | Input types | Token Compression 🗜️ | Image Extraction 👁️ | Notes 📌 |
|---|---|---|---|---|
| Directory | Any /path/to/directory |
✔️ | ✔️ | Extracts from all files in directory, supports match and ignore patterns |
| Code | .py, .tsx, .js, .html, .css, .cpp, etc |
✔️ (varies) | ❌ | Combines all code files. .c, .cpp, .py are compressible with ctags, others are not |
| Plaintext | .txt, .md, .rtf, etc |
✔️ | ❌ | Regular text files |
.pdf |
✔️ | ✔️ | Extracts text and images of each page; can use AI for extraction of table data and images within pages | |
| Image | .jpg, .jpeg, .png |
❌ | ✔️ | Extracts images, uses OCR if text_only |
| Spreadsheet | .csv, .xls, .xlsx |
✔️ | ❌ | Extracts data from spreadsheets; converts each row into a JSON formatted string |
| Jupyter Notebook | .ipynb |
❌ | ✔️ | Extracts code, markdown, and images from Jupyter notebooks |
| Microsoft Word Document | .docx |
✔️ | ✔️ | Extracts text and images from Word documents |
| Microsoft PowerPoint Presentation | .pptx |
✔️ | ✔️ | Extracts text and images from PowerPoint presentations |
| Video | .mp4, .mov, .wmv |
✔️ | ✔️ | Extracts frames and audio transcript from videos in per-minute chunks. |
| Audio | .mp3, .wav |
✔️ | ❌ | Extracts text from audio files; supports speech-to-text conversion |
| Website | URLs (inputs starting with http, https, ftp) |
✔️ | ✔️ | Extracts text from web page along with image (or images if scrollable); text-only extraction available |
| GitHub Repository | GitHub repo URLs (inputs starting with https://github.com or https://www.github.com) |
✔️ | ✔️ | Extracts from GitHub repositories; supports branch specification |
| YouTube Video | YouTube video URLs (inputs starting with https://youtube.com or https://www.youtube.com) |
✔️ | ✔️ | Extracts frames and transcript from YouTube videos in per-minute chunks. |
| ZIP File | .zip |
✔️ | ✔️ | Extracts contents of ZIP files; supports nested directory extraction |
The input source is either a file path, a URL, or a directory. The pipe will extract information from the source and process it for downstream use with language models, vision transformers, or vision-language models. The output from the pipe is a sensible list of multimodal messages representing chunks of the extracted information, carefully crafted to fit within context windows for any models from gemma-7b to GPT-4. The messages returned should look like this:
[
{
"role": "user",
"content": [
{
"type": "text",
"text": "..."
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,..."
}
}
]
}
]If you want to feed these messages directly into the model, it is important to be mindful of the token limit.
OpenAI does not allow too many images in the prompt (see discussion here), so long files should be extracted with text_only=True to avoid this issue, while long text files should either be compressed or embedded in a RAG framework.
The text and images from these messages may also be prepared for a vector database with thepipe.core.create_chunks_from_messages or for downstream use with RAG frameworks. LiteLLM can be used to easily integrate The Pipe with any LLM provider.
It uses a variety of heuristics for optimal performance with vision-language models, including AI filetype detection with filetype detection, opt-in AI table, equation, and figure extraction, efficient token compression, automatic image encoding, reranking for lost-in-the-middle effects, and more, all pre-built to work out-of-the-box.
.png)
The Pipe handles a wide array of complex filetypes, and thus requires installation of many different packages to function. It also requires a very capable machine for good response times. For this reason, we host it as an API that works out-of-the-box. To use The Pipe locally for free instead, you will need playwright, ctags, pytesseract, pytube and the remaining local python requirements, which differ from the more lightweight API requirements:
git clone https://github.com/emcf/thepipe
pip install -r requirements_local.txtTip for windows users: Install the python-libmagic binaries with pip install python-magic-bin. Ensure the tesseract-ocr binaries and the ctags binaries are in your PATH. For YouTube video extraction to function consistently, you will need to modify your pytube installation to send a valid user agent header (I know, it's complicated. See this issue for more).
Now you can use The Pipe with Python:
from thepipe_api import thepipe
chunks = thepipe.extract("example.pdf", local=True)or from the command line:
thepipe path/to/folder --match .tsx --ignore testsArguments are:
source(required): can be a file path, a URL, or a directory path.local(optional): Use the local version of The Pipe instead of the hosted API.match(optional): Substring to match files in the directory. Regex is not yet supported.ignore(optional): Substring to ignore files in the directory. Regex is not yet supported.limit(optional): The token limit for the output prompt, defaults to 100K. Prompts exceeding the limit will be compressed. This may not work as expected with the API, as it is in active development.ai_extraction(optional): Extract tables, figures, and math from PDFs using our extractor. Incurs extra costs.text_only(optional): Do not extract images from documents or websites. Additionally, image files will be represented with OCR instead of as images.

Thank you to Cal.com for sponsoring this project. Contact [email protected] for sponsorship information.










































































































