Arbitrary-Style-Per-Model Fast Neural Style Transfer Method
Using an Encoder-AdaIN-Decoder architecture - Deep Convolutional Neural Network as a Style Transfer Network (STN) which can receive two arbitrary images as inputs (one as content, the other one as style) and output a generated image that recombines the content and spatial structure from the former and the style (color, texture) from the latter without re-training the network. The STN is trained using MS-COCO dataset (about 12.6GB) and WikiArt dataset (about 36GB).
This code is based on Huang et al. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (ICCV 2017)
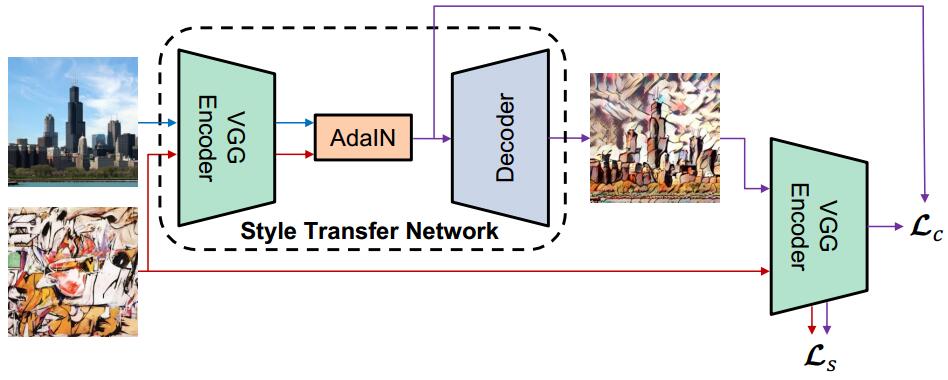 System overview. Picture comes from Huang et al. original paper. The encoder is a fixed VGG-19 (up to relu4_1) which is pre-trained on ImageNet dataset for image classification. We train the decoder to invert the AdaIN output from feature spaces back to the image spaces.
System overview. Picture comes from Huang et al. original paper. The encoder is a fixed VGG-19 (up to relu4_1) which is pre-trained on ImageNet dataset for image classification. We train the decoder to invert the AdaIN output from feature spaces back to the image spaces.
- Pre-trained VGG19 normalised network (MD5
c637adfa9cee4b33b59c5a754883ba82)
I have provided a convertor in thetoolfolder. It can extract kernel and bias from the torch model file (.t7 format) and save them into a npz file which is easier to process via NumPy.
Or you can simply download my pre-processed file:
Pre-trained VGG19 normalised network npz format (MD5c5c961738b134ffe206e0a552c728aea) - Microsoft COCO dataset
- WikiArt dataset
You can download my trained model from here which is trained with style weight equal to 2.0
Or you can directly use download_trained_model.sh in the repo.
- The main file
main.pyis a demo, which has already contained training procedure and inferring procedure (inferring means generating stylized images).
You can switch these two procedures by changing the flagIS_TRAINING. - By default,
(1) The content images lie in the folder"./images/content/"
(2) The style images lie in the folder"./images/style/"
(3) The weights file of the pre-trained VGG-19 lies in the current working directory. (SeePrerequisitesabove. By the way,download_vgg19.shalready takes care of this.)
(4) The MS-COCO images dataset for training lies in the folder"../MS_COCO/"(SeePrerequisitesabove)
(5) The WikiArt images dataset for training lies in the folder"../WikiArt/"(SeePrerequisitesabove)
(6) The checkpoint files of trained models lie in the folder"./models/"(You should create this folder manually before training.)
(7) After inferring procedure, the stylized images will be generated and output to the folder"./outputs/" - For training, you should make sure (3), (4), (5) and (6) are prepared correctly.
- For inferring, you should make sure (1), (2), (3) and (6) are prepared correctly.
- Of course, you can organize all the files and folders as you want, and what you need to do is just modifying related parameters in the
main.pyfile.
| style | output (generated image) |
|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
|
 |
Hardware
- CPU: Intel® Core™ i9-7900X (3.30GHz x 10 cores, 20 threads)
- GPU: NVIDIA® Titan Xp (Architecture: Pascal, Frame buffer: 12GB)
- Memory: 32GB DDR4
Operating System
- ubuntu 16.04.03 LTS
Software
- Python 3.6.2
- NumPy 1.13.1
- TensorFlow 1.3.0
- SciPy 0.19.1
- CUDA 8.0.61
- cuDNN 6.0.21
- The Encoder which is implemented with first few layers(up to relu4_1) of a pre-trained VGG-19 is based on Anish Athalye's vgg.py
@misc{ye2017arbitrarystyletransfer,
author = {Wengao Ye},
title = {Arbitrary Style Transfer},
year = {2017},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/elleryqueenhomels/arbitrary_style_transfer}}
}



















































































































































