blog's People
Contributors

Watchers
blog's Issues
行为型模式
策略模式
概念:策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
概念中的策略对象就是我们平常的 if 中的逻辑,我们将不同功能的函数单独封装后,再不同的逻辑执行不同功能的函数,那如何根据不同逻辑执行不同功能的函数呢(除了大量的if-else)?
使用映射来实现,不同的策略对象则执行不同的功能函数,这就是策略模式。
示例:
// 定义一个询价处理器对象
const priceProcessor = {
pre(originPrice) {
if (originPrice >= 100) {
return originPrice - 20;
}
return originPrice * 0.9;
},
onSale(originPrice) {
if (originPrice >= 100) {
return originPrice - 30;
}
return originPrice * 0.8;
},
back(originPrice) {
if (originPrice >= 200) {
return originPrice - 50;
}
return originPrice;
},
fresh(originPrice) {
return originPrice * 0.5;
},
};
// 询价函数
function askPrice(tag, originPrice) {
return priceProcessor[tag](originPrice)
}状态模式
概念:状态模式中,类的行为是基于它的状态改变的,我们创建表示各种状态的对象和一个行为随着状态对象改变而改变的 context 对象。
状态模式和策略模式基本上是相似的,它们都封装行为、都通过委托来实现行为分发。
区别如下:
策略模式的行为函数不依赖主体,互相平行;
状态模式中的行为函数,首先是和状态主体之间存在着关联,由状态主体把它们串在一起;另一方面,正因为关联着同样的一个(或一类)主体,所以不同状态对应的行为函数可能并不会特别割裂。
观察者模式
概念:观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个目标对象,当这个目标对象的状态发生变化时,会通知所有观察者对象,使它们能够自动更新。
观察者模式,是所有 JavaScript 设计模式中使用频率最高的。
观察者模式有一个“别名”,叫发布 - 订阅模式(之所以别名加了引号,是因为两者之间存在着细微的差异,下面会讲到这点)。这个别名非常形象地诠释了观察者模式里两个核心的角色要素——“发布者”与“订阅者”。
简单实现
在观察者模式里,至少有两个关键角色是一定要出现的——发布者和订阅者。用面向对象的方式表达的话,那就是要有两个类。
发布者类的功能:增加订阅者;通知订阅者;移除订阅者
// 定义发布者类
class Publisher {
constructor() {
this.observers = []
console.log('Publisher created')
}
// 增加订阅者
add(observer) {
console.log('Publisher.add invoked')
this.observers.push(observer)
}
// 移除订阅者
remove(observer) {
console.log('Publisher.remove invoked')
this.observers.forEach((item, i) => {
if (item === observer) {
this.observers.splice(i, 1)
}
})
}
// 通知所有订阅者
notify() {
console.log('Publisher.notify invoked')
this.observers.forEach((observer) => {
observer.update(this) // 一个个去执行订阅者的update函数
})
}
}订阅者类的功能:被通知,被执行
// 定义订阅者类
class Observer {
constructor() {
console.log('Observer created')
}
update() {
console.log('Observer.update invoked')
}
}这就是基本的发布者和订阅者类的设计和编写。接下来以一个例子,来看下他们是如何执行的
有以下场景,如果产品经理是发布者,前端后端测试都是订阅者,那么产品经理修改产品文档时则会通知这些订阅者查看文档的更新,首先产品经理需要继承 Publisher 这个类:
// 定义一个具体的需求文档(prd)发布类
class PrdPublisher extends Publisher {
constructor() {
super()
// 初始化需求文档
this.prdState = null
// 产品经理还没有拉群,开发群目前为空
this.observers = []
console.log('PrdPublisher created')
}
// 该方法用于获取当前的prdState
getState() {
console.log('PrdPublisher.getState invoked')
return this.prdState
}
// 该方法用于改变prdState的值
setState(state) {
console.log('PrdPublisher.setState invoked')
// prd的值发生改变
this.prdState = state
// 需求文档变更,立刻通知所有开发者
this.notify()
}
}作为订阅方,也需要继承 Observer 类
class DeveloperObserver extends Observer {
constructor() {
super()
// 需求文档一开始还不存在,prd初始为空对象
this.prdState = {}
console.log('DeveloperObserver created')
}
// 重写一个具体的update方法
update(publisher) {
console.log('DeveloperObserver.update invoked')
// 更新需求文档
this.prdState = publisher.getState()
// 调用工作函数
this.work()
}
// work方法,用于工作
work() {
// 获取需求文档
const prd = this.prdState
// 开始基于需求文档提供的信息工作。。。
...
console.log('996 begins...')
}
}类定义好之后,接下来就是整个执行流程:
// 创建订阅者:前端开发小A
const A = new DeveloperObserver()
// 创建订阅者:后端开发小B
const B = new DeveloperObserver()
// 创建订阅者:测试同学小C
const C = new DeveloperObserver()
// 产品经理
const productManager = new PrdPublisher()
// 需求文档出现了
const prd = {
// 具体的需求内容
...
}
// 产品经理开始拉群
productManager.add(A)
productManager.add(B)
productManager.add(C)
// 产品经理发送了需求文档,并@了所有人
productManager.setState(prd)以上就是观察者模式的一个简单实现
生产实践
项目中常见的观察者模式有:
- Vue的响应式系统
- Event Bus/Event Emitter(全局事件总线)
观察者模式和发布-订阅模式之间的区别
发布者直接触及订阅者的操作,叫观察者模式。
发布者不直接触及到订阅者、而是由统一的第三方来完成实际的通信的操作,叫发布-订阅模式。
总结
为什么要有观察者模式?观察者模式,解决的其实是模块间的耦合问题,有它在,即便是两个分离的、毫不相关的模块,也可以实现数据通信。但观察者模式仅仅是减少了耦合,并没有完全地解决耦合问题——被观察者必须去维护一套观察者的集合,这些观察者必须实现统一的方法供被观察者调用,两者之间还是有着说不清、道不明的关系。
而发布-订阅模式,则是快刀斩乱麻了——发布者完全不用感知订阅者,不用关心它怎么实现回调方法,事件的注册和触发都发生在独立于双方的第三方平台(事件总线)上。发布-订阅模式下,实现了完全地解耦。
但这并不意味着,发布-订阅模式就比观察者模式“高级”。在实际开发中,我们的模块解耦诉求并非总是需要它们完全解耦。如果两个模块之间本身存在关联,且这种关联是稳定的、必要的,那么我们使用观察者模式就足够了。而在模块与模块之间独立性较强、且没有必要单纯为了数据通信而强行为两者制造依赖的情况下,我们往往会倾向于使用发布-订阅模式。
迭代器模式
概念:迭代器模式提供一种方法顺序访问一个聚合对象中的各个元素,而又不暴露该对象的内部表示。
迭代器模式是设计模式中少有的目的性极强的模式。所谓“目的性极强”就是说它不操心别的,它就解决这一个问题——遍历。迭代器模式比较特别,它非常重要,重要到语言和框架都争着抢着已经帮我们实现了。
说到遍历,可能会想到数组的遍历,JS已经有很多方法来实现数组的遍历,例如 forEach,但这种方法只能遍历数组,像类数组等其他结构或集合则不能遍历。
而迭代器的定义是我们遍历集合的同时,我们不需要关心集合的内部结构,也就是一个通用的迭代器。
例如JS中的四种集合类型:Array、Object、Map、Set
我们如果要用同一套规则去遍历它们,则要使用 ES6 推出的一套统一的接口机制——迭代器(Iterator)。
ES6约定,任何数据结构只要具备Symbol.iterator属性(这个属性就是Iterator的具体实现,它本质上是当前数据结构默认的迭代器生成函数),就可以被遍历——准确地说,是被for...of...循环和迭代器的next方法遍历。 事实上,for...of...的背后正是对next方法的反复调用。
在ES6中,针对Array、Map、Set、String、TypedArray、函数的 arguments 对象、NodeList 对象这些原生的数据结构都可以通过for...of...进行遍历,原理都是一样的。例如数组,之所以能够按顺序一次一次地拿到数组里的每一个成员,是因为我们借助数组的Symbol.iterator生成了它对应的迭代器对象,通过反复调用迭代器对象的next方法访问了数组成员,像这样:
const arr = [1, 2, 3]
// 通过调用iterator,拿到迭代器对象
const iterator = arr[Symbol.iterator]()
// 对迭代器对象执行next,就能逐个访问集合的成员
iterator.next()
iterator.next()
iterator.next()可以看出,for...of...其实就是iterator循环调用换了种写法。在ES6中我们之所以能够用for...of...遍历各种各种的集合,全靠迭代器模式在背后给力。
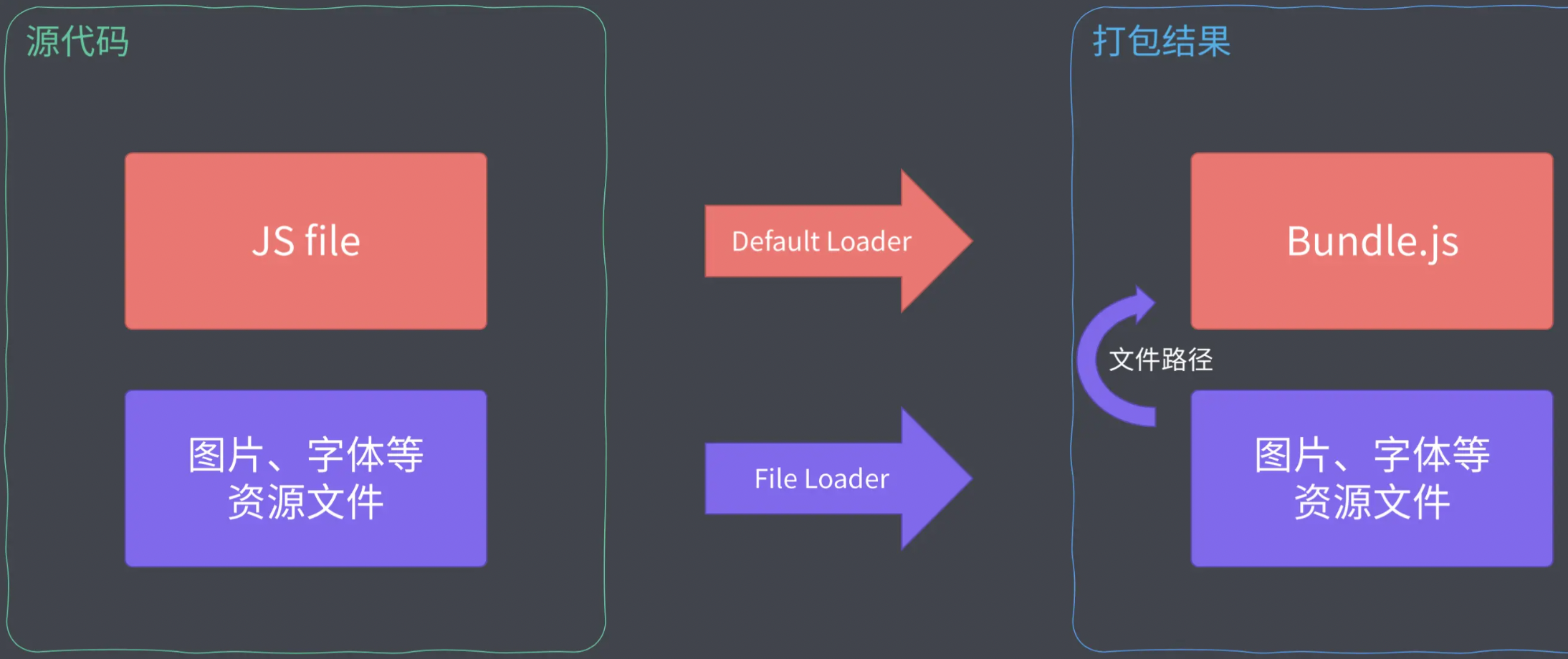
Webpack打包结果优化
Webpack 打包优化并没有固定的几个模式,一般常见的优化就是拆包、分块、压缩等,但并不是对每一个项目都适用,针对于特定项目,我们需要根据项目实际的情况,不断的调试不断的优化,找到最适合的方式。
今天主要介绍用来优化 Webpack 打包的两个高级特性:Tree Shaking 和 sideEffects
Tree shaking
概念
Tree shaking 在中文里是 “摇树” 的意思,如果将整个项目比作一棵参天大树,摇树就是将这颗树上的一些枯树叶树枝给摇下来,这些枯树枝,就是项目里的 dead-code(未引用的代码),Tree shaking 的作用就是用来移除这些 dead-code。
另外,Tree-shaking 并不是指 Webpack 中的某一个配置选项,而是一组功能搭配使用过后实现的效果,这组功能在生产模式下都会自动启用,所以使用生产模式打包就会有 Tree-shaking 的效果。
Tree-shaking 最早是 Rollup 中推出的一个特性,Webpack 从 2.0 过后也开始支持这个特性。
先来看一个例子:
├── src
│ ├── components.js
│ └── main.js
├── package.json
└── webpack.config.js
// ./src/components.js
export const Button = () => {
return document.createElement('button')
console.log('dead-code')
}
export const Link = () => {
return document.createElement('a')
}
export const Heading = level => {
return document.createElement('h' + level)
}可以看到上面的 console.log 是在 return 之后的,所以这句代码是永远都不会被执行的。这个时候的 console.log 就属于 dead-code。
在 main.js 文件中导入 compnents.js:
// ./src/main.js
import { Button } from './components'
document.body.appendChild(Button())这里,我们只提取了模块中的 Button 成员,这就意味着 Link 和 Heading 成员并不会被用到,那它们两个函数的相关代码就也属于冗余代码。
我们需要去除冗余的代码,这是生产环境优化中一个很重要的工作。Webpack 的 Tree-shaking 功能就很好地实现了这一点。
当我们使用 production 模式运行打包时,就可以开启 Tree shaking 功能:
$ npx webpack --mode=production最终打包后的文件如图

可以看到,打包完成后的 bundle.js 文件中,我们上述提到的冗余代码(即dead-code)就并不会输出,这就是经过 Tree shaking 处理之后的效果。
开启方式
开启 Tree shaking 的方式主要有如下几种:
- 生产模式下会自动打开
- 其他模式
- usedExports
- minimize
如我们上文所说,生产模式下可自动开启 Tree shaking,接下来介绍一下在其他模式下如何开启 Tree shaking。
我们来再次运行一遍 Webpack 打包,不过这一次我们不再使用 production 模式,而是使用 none,也就是不开启任何内置功能和插件,具体命令如下:
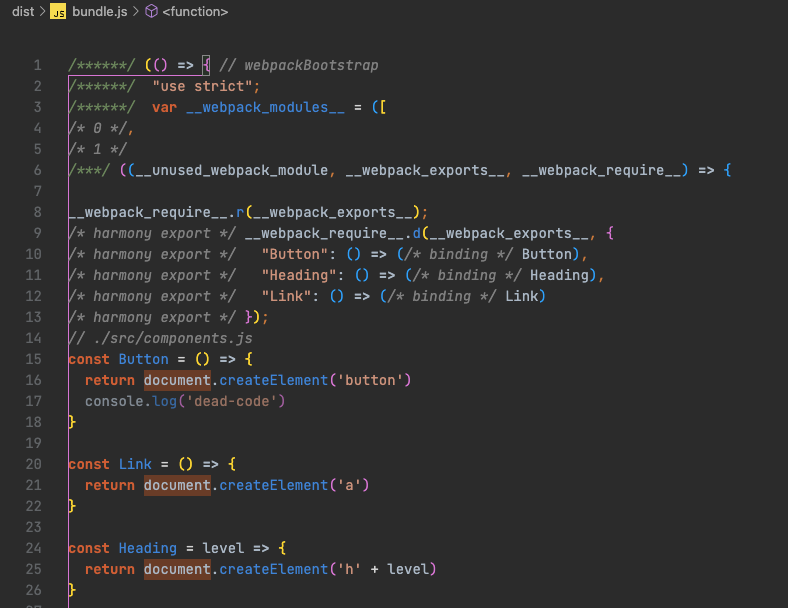
$ npx webpack --mode=none打包过后的 bundle.js 文件如下
components.js 对应模块
main.js 对应模块
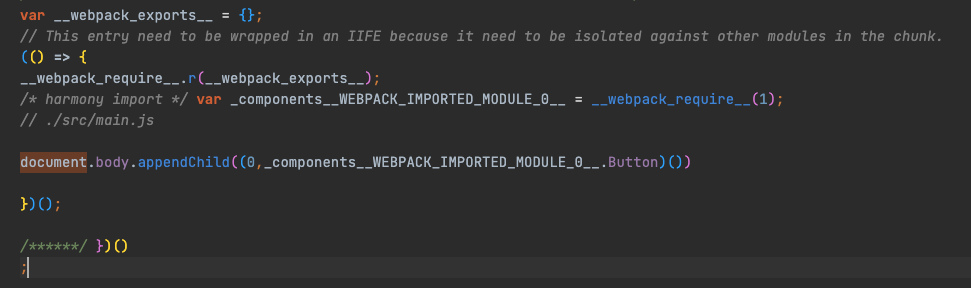
可以看到,源代码中的一个模块就对应这里的一个函数,这里 components 对应的这个模块,虽然外部没有使用这里的 Link 函数和 Heading 函数,但是仍然导出了它们。
接下来我们打开 Webpack 的配置文件,在配置对象中添加一个 optimization 属性,这个属性是用来集中配置 Webpack 内置优化功能的,它的值也是一个对象。
在 optimization 配置中我们开启一个 usedExports 选项。这个配置项表示在输出结果中只导出外部使用了的成员,具体配置如下:
// ./webpack.config.js
module.exports = {
// ... 其他配置项
optimization: {
// 模块只导出被使用的成员
usedExports: true
}
}配置完成后我们再重新进行打包,再来看一下输出的 bundle.js:
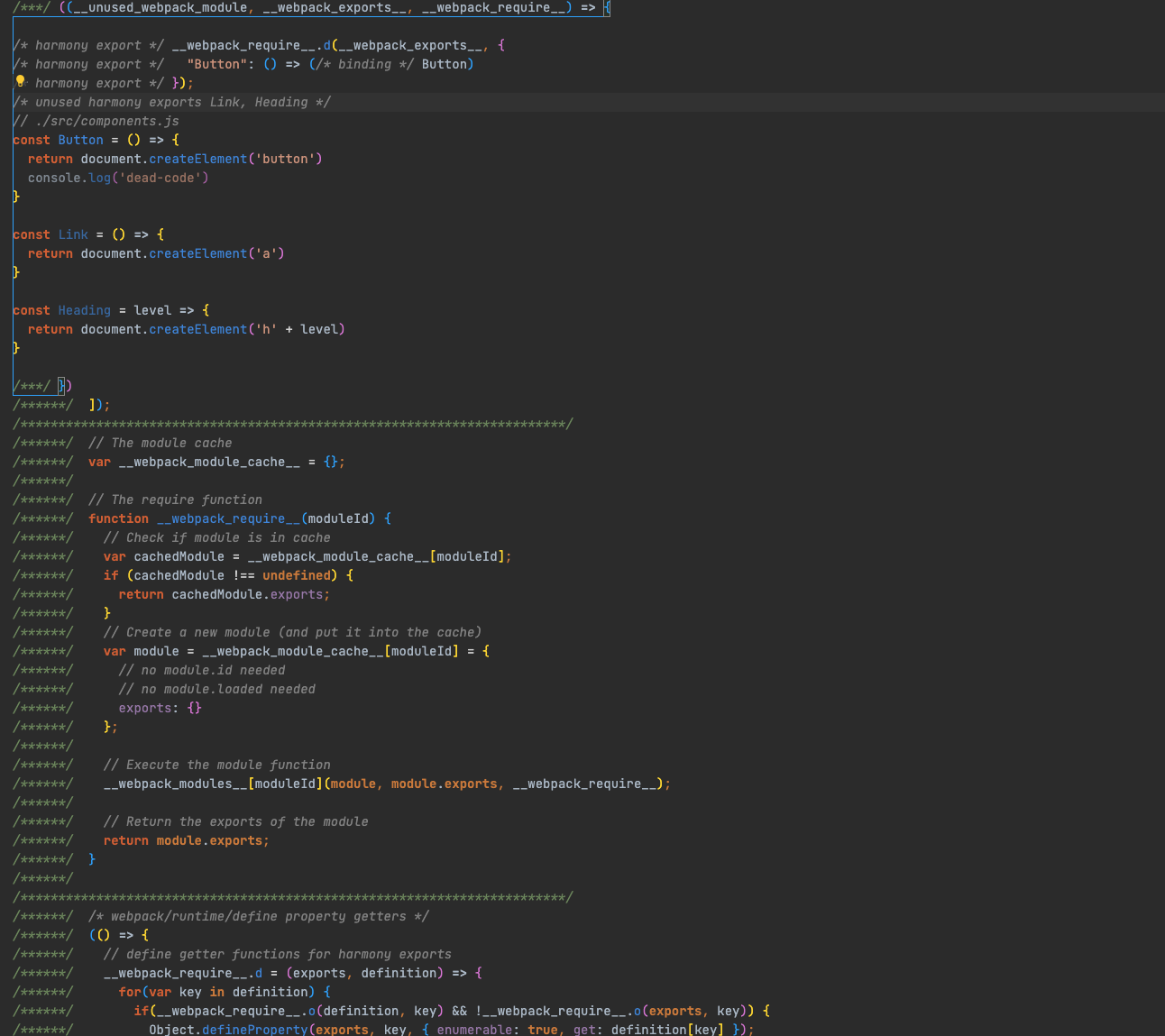
虽然 bundle.js 文件中还会出现 Link 和 Heading 这两个函数,但他们不再被导出了,没有任何地方依赖这些代码(vscode中代码颜色变淡,表示未被引用),那它们对应的代码就变成了 未引用代码。
对于这种未引用代码,如果我们开启压缩代码功能,就可以自动压缩掉这些没有用到的代码。
我们再在配置文件中开启 minimize,具体配置如下:
// ./webpack.config.js
module.exports = {
// ... 其他配置项
optimization: {
// 模块只导出被使用的成员
usedExports: true,
// 压缩输出结果
minimize: true
}
}然后重新进行打包,结果如下:

可以发现,Link 和 Heading 这些未引用代码就都被自动移除了。
所以,如果把我们的代码看成一棵树,那么以上这两个配置的功能就是
- usedExports 的作用就是标记树上哪些是枯树枝和枯树叶
- minimize 的作用就是负责把枯树枝、枯树叶摇下来
我们在其他模式下就可以通过这两个配置结合,来开启 Tree shaking。
合并模块
除了上述两种配置外,我们还可以使用一个 concatenateModules 配置继续优化输出。
concatenateModules 配置的作用是尽可能将所有模块合并到一起输出到一个函数中,这样做就既提升了运行效率,又减少了代码的体积。
普通的打包只是将一个模块最终放入一个单独的函数中,如果我们的模块很多,就意味着在输出结果中会有很多的模块函数。
接下来我们在配置文件中的 optimization 属性下开启 concatenateModules。具体配置如下:
// ./webpack.config.js
module.exports = {
// ... 其他配置项
optimization: {
// 模块只导出被使用的成员
usedExports: true,
// 尽可能合并每一个模块到一个函数中
concatenateModules: true
}
}打包结果如图所示:
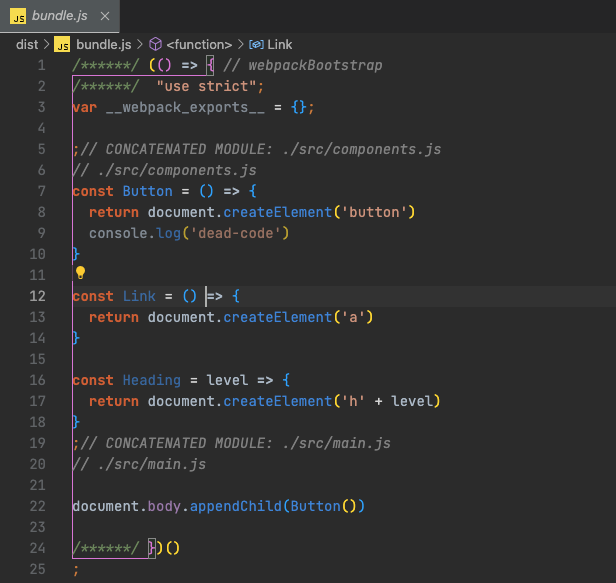
如果我们同时再将 minimize 置为 true,打包结果的体积又会减小很多:

babel-loader 问题
有的时候我们会发现这样一个问题:当为 JS 模块配置 babel-loader 时,会导致 Tree-shaking 失效。
这里我们需要明确一点:Tree-shaking 实现的前提是 ES Modules,也就是说:最终交给 Webpack 打包的代码,必须是使用 ES Modules 的方式来组织的模块化。
为什么这么说呢?
因为 Webpack 在打包所有的模块代码之前,先是将模块根据配置交给不同的 Loader 处理,最后再将 Loader 处理的结果打包到一起。
很多时候,我们为了更好的兼容性,会选择使用 babel-loader 去转换我们源代码中的一些 ECMAScript 的新特性。而 Babel 在转换 JS 代码时,很有可能就会处理掉我们代码中的 ES Modules 部分,将 ES Modules 转换成了 CommonJS 的方式。
而 Babel 具体会不会处理 ES Modules 代码,取决于我们有没有为它配置使用转换 ES Modules 的插件。很多时候,我们为 Babel 配置的都是一个 preset(预设插件集合),而不是某些具体的插件。例如,我们在项目中使用最多的 @babel/preset-env,这个预设里面就有转换 ES Modules 的插件。所以当我们使用这个预设时,代码中的 ES Modules 部分就会被转换成 CommonJS 方式。那 Webpack 再去打包时,拿到的就是以 CommonJS 方式组织的代码了,所以 Tree-shaking 不能生效。
但是在最新版本(8.x)的 babel-loader 中,已经自动帮我们关闭了对 ES Modules 转换的插件,感兴趣的可以参考对应版本 babel-loader 的源码,核心代码如下:
// Webpack >= 2 supports ESM and dynamic import.
supportsStaticESM: true,
supportsDynamicImport: true这里标识了当前环境支持 ES Modules,然后在 @babal/preset-env 模块的源码中,会根据这两个环境标识来自动禁用对 ES Modules 的转换插件,所以经过 babel-loader 处理后的代码默认仍然是 ES Modules,那 Webpack 最终打包得到的还是 ES Modules 代码,Tree-shaking 自然也就可以正常工作了。
我们也可以在 babel-loader 的配置中强制开启 ES Modules 转换成 commonJS 插件:
module: {
rules: [
{
test: /\.js$/,
use: {
loader: 'babel-loader',
options: {
presets: [
['@babel/preset-env', { modules: 'commonjs' }] // 这里的 commonjs 则是强制开启,默认这个属性是 auto
]
}
}
}
]
}sideEffects
sideEffects 是 Webpack 4 中新增的特性,它允许我们通过配置标识我们的代码是否有副作用,从而提供更大的压缩空间。
模块的副作用指的是模块执行的时候除了导出成员,是否还做了其他的事情。
基于上文的案例将 components.js 文件中的函数拆成多个组件文件,再在 src/components/index.js 中将这些组件文件集中导出,结构如下:
├── src
│ ├── components
│ │ ├── button.js
│ │ ├── heading.js
│ │ ├── index.js
│ │ └── link.js
│ └── main.js
├── package.json
└── webpack.config.js
// ./src/components/index.js
export { default as Button } from './button'
export { default as Link } from './link'
export { default as Heading } from './heading'我们在每个组件中,都添加一个 console 操作(副作用代码),具体代码如下:
// ./src/components/button.js
console.log('Button component') // 副作用代码
export default () => {
return document.createElement('button')
}我们再到打包入口文件(main.js)中去载入 components 中的 Button 成员,具体代码如下:
// ./src/main.js
import { Button } from './components'
document.body.appendChild(Button())根据代码我们希望的是载入 Button 模块,但这时我们执行打包,实际上载入的是 components/index.js,而 index.js 中又载入了这个目录中全部的组件模块,这就会导致所有组件模块都会被加载执行。
配置如下:
// ./webpack.config.js
module.exports = {
// ... 其他配置项
optimization: {
// 模块只导出被使用的成员
usedExports: true,
// 压缩输出结果
minimize: true,
// 尽可能合并每一个模块到一个函数中
concatenateModules: true
}
}打包结果如下:

从打包结果可以看到,所有的组件模块都被打包进了 bundle.js,即使我们开启 Tree-shaking 特性,这些模块也不会完全被移除。
因为我们在其中添加了 console 的代码,这段代码具有副作用,但我们的实际情况中这些模块内的副作用代码都是为这个模块服务的,例如我们这里添加的 console 只是希望表示一下当前这个模块被加载了。但是最终整个模块都没用到,所以我们其实没必要留下这些副作用代码。但是这些副作用代码却会被打包进 bundle.js,与我们的意愿不相符。
所以,这里的结论是,Tree-shaking 只能移除没有用到的代码成员,而想要完整移除没有用到的模块,那就需要开启 sideEffects 特性了。
我们在配置文件中的 optimization 中开启 sideEffects 特性,具体配置如下:
// ./webpack.config.js
module.exports = {
entry: './src/main.js',
output: {
filename: 'bundle.js'
},
optimization: {
sideEffects: true
}
}sideEffects 这个特性在 production 模式下同样会自动开启。
在开启了 sideEffects 之后,Webpack 在打包某个模块之前就会先检查这个模块所属的 package.json 中的 sideEffects 标识,以此来判断这个模块是否有副作用,如果没有副作用的话,这些没用到的模块就不再被打包。所以,当我们这些没有用到的模块中存在一些副作用代码时,我们也可以通过 package.json 中的 sideEffects 去强制声明没有副作用。
sideEffects 配置开启之后,我们需要在 package.json 中去声明是否有副作用:
{
"name": "sideeffects",
"version": "1.0.0",
"description": "",
"main": "main.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"devDependencies": {
"webpack": "^5.74.0",
"webpack-cli": "^4.10.0"
},
"sideEffects": false
}这里我们直接 "sideEffects": false 表示项目中所有代码都没有副作用,这样 Webpack 打包时就会完全的忽略副作用代码来进行打包,如果我们需要仅忽略部分文件的副作用的话,则需要这样配置:
"sideEffects": [
"./src/components/extend.js",
"*.css"
]这时我们那些没有用到的模块就彻底不会被打包进来了,这就是 sideEffects 的作用。
总结一下,sideEffects需要设置两个地方:
- webpack.config.js 中的 sideEffects 用来开启这个功能
- package.json 中的 sideEffects 用来标识我们的哪些代码没有副作用
目前很多第三方的库或者框架都已经使用了 sideEffects 标识,所以我们不会再为了一个小功能而引入一个很大体积的库了。例如,某个 UI 组件库中只有一两个组件会用到,但只要它支持 sideEffects,就可以放心的直接用了。
需要注意的是,使用 sideEffects 这个功能的前提是确定你的代码没有副作用(即副作用代码没有全局影响),否则打包时就会误删掉你那些有意义的副作用代码。
总结
本篇文章介绍了两个 Webpack 中的高级特性,分别是 Tree-shaking 和 sideEffects。
Tree-shaking 是一种 Webpack 内部优化打包结果后的效果,我们可以通过相关的配置来开启它。
sideEffects 的话则需要我们人为的判断哪些副作用代码是可以随着模块的移除而移除,哪些又是不可以移除的。通常是对全局有影响的副作用代码不能移除,而如果是只是对模块有影响的副作用代码就可以移除。
当我们对 sideEffects 特性有了一定的了解之后,就应该意识到:尽可能不要写影响全局的副作用代码。
总而言之,不管是 Tree-shaking 还是 sideEffects,它们都是为了弥补 JavaScript 早期在模块系统设计上的不足。随着 Webpack 这类技术的发展,JavaScript 的模块化已经越来越好用,缺失的功能也得到了弥补,模块化设计也越来越合理。
响应式系统的设计与实现
响应式数据与副作用函数
副作用函数也就是会产生副作用的函数,例如:
function effect () {
document.body.innerText = 'hello world'
}假设在一个副作用函数中读取了某个对象的属性:
const obj = { text: 'hello world' }
function effect () {
document.body.innerText = obj.text
}当obj.text的值发生变化时,我们希望副作用函数effect会重新执行,如果能实现这个目标,那么对象obj就是响应式数据。
响应式数据的基本实现
如何才能让obj变成响应式数据呢?通过观察我们发现两点线索:
- 当副作用函数effect执行时,会触发字段obj.text的
读取操作 - 当修改obj.text的值时,会触发字段obj.text的
设置操作
如果我们能拦截一个对象的读取和设置操作,事情就变得简单了。
当读取字段obj.text时,我们可以把副作用函数effect存储到一个“桶”里面
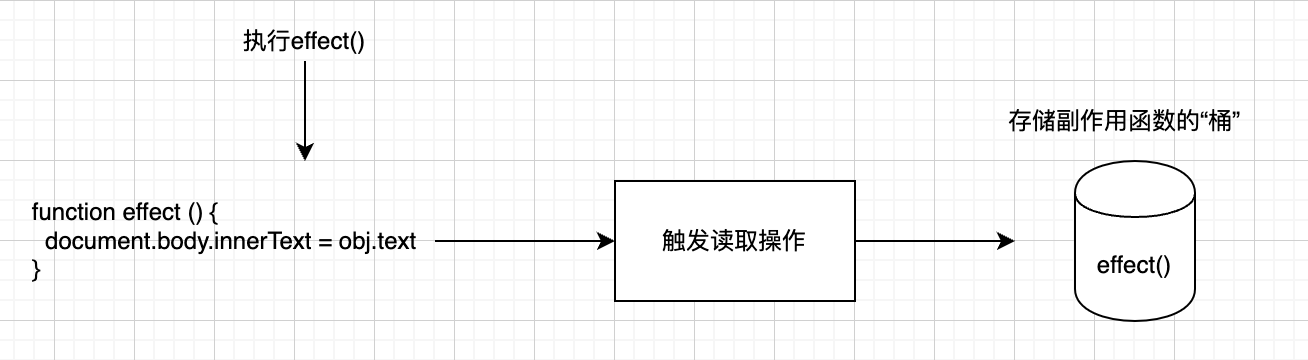
接着,当设置obj.text时,再把副作用函数从“桶”里取出并执行即可
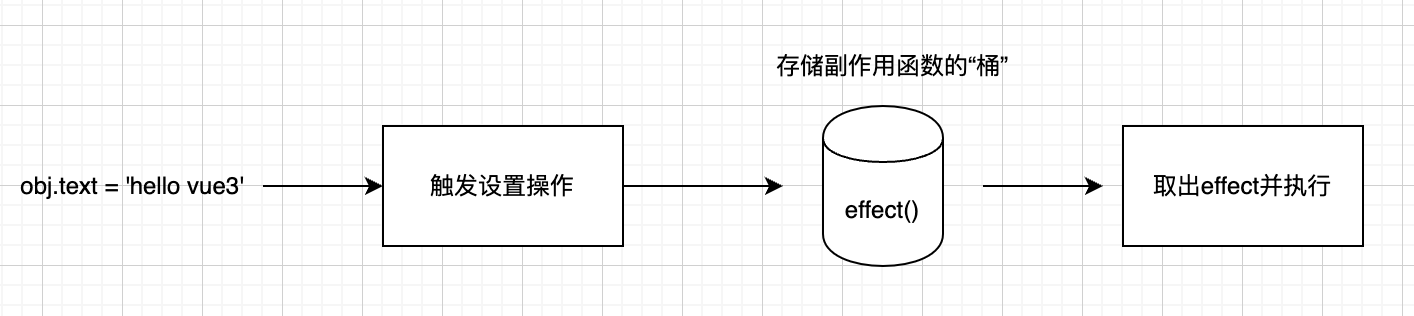
那么我们怎么才能拦截一个对象属性的读取和设置操作呢?在ES2015之前我们采用Object.defineProperty函数来实现,在ES2015之后,我们可以使用代理对象Proxy来实现:
// 存储对象的桶
const bucket = new Set()
// 原始数据
const data = { text: 'hello world' }
// 对原始数据的代理
const obj = new Proxy(data, {
// 拦截读取操作
get (target, key) {
// 将副作用函数effect添加到存储副作用函数的桶中
bucket.add(effect)
return target[key]
},
// 拦截设置操作
set (target, key, newVal) {
// 设置属性值
target[key] = newVal
// 将副作用函数从桶里取出并执行
bucket.forEach(fn => fn())
// 返回true代表设置操作成功
return true
}
})这时,我们更改data.text的值后,即可实现effect函数的调用
但是目前的实现存在很多缺陷,例如我们直接通过名字(effect)来获取副作用函数,这种硬编码方式很不灵活。副作用函数的名字应该可以任意的取,我们完全可以把副作用函数命名为myEffect,甚至是一个匿名函数,因此我们要想办法去掉这种硬编码的机制。
设计一个完整的响应式系统
首先我们需要提供一个用来注册副作用函数的机制:
// 用一个全局变量存储被注册的副作用函数
let activeEffect
const fn = () => {
document.body.innerText = obj.text
}
// effect函数用于注册副作用函数
function effect (fn) {
acticeEffect = fn
fn()
}所以当effect函数执行时,我们可以把匿名的副作用函数fn赋值给全局变量 activeEffect,接着执行fn,然后就触发了响应式数据obj.text的读取操作,进而触发代理对象Proxy的get拦截函数。
下一个问题是,当我们在obj上设置一个不存在的属性时:
obj.notExist = 'hello vue3'这个操作是在副作用函数fn之外进行的,但这时也会触发obj的设置操作,从而触发副作用函数的执行。导致该问题的根本原因是:没有在副作用函数与被操作的目标字段之间建立明确的联系。我们需要重新设计“桶”的数据结构。
如果用target来表示被代理的obj,用key来表示被操作的属性,用effectFn来表示被注册的副作用函数,那么会有以下关系:
target
|—— key1
|——effectFn1
|—— key2
|——effectFn2
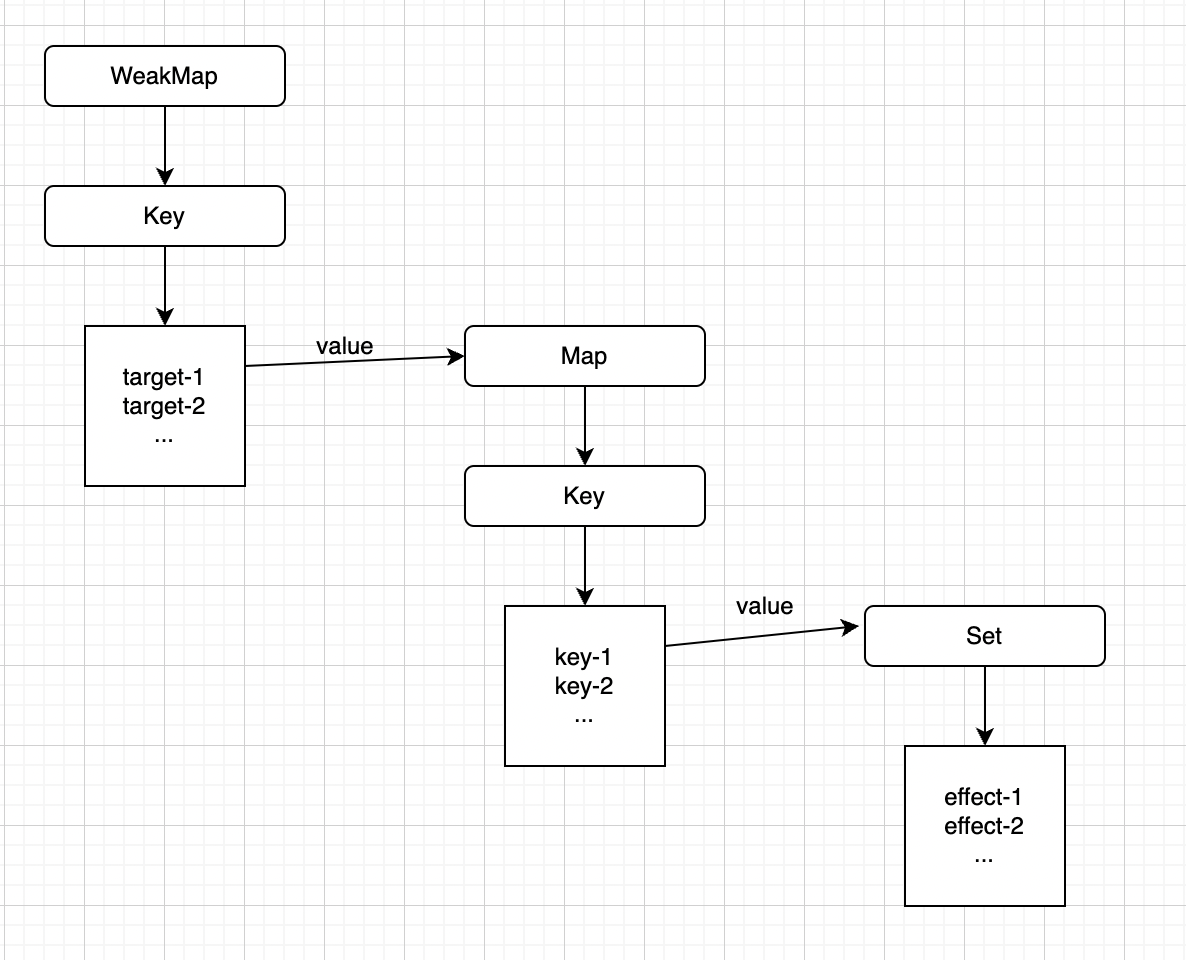
我们可以用WeakMap代替Set作为“桶”的数据结构:
- WeakMap由target --> Map构成
- Map由 key --> Set构成
关系如图所示:
❓为何要使用WeakMap?
这涉及到垃圾回收机制,WeakMap的key是弱引用,它不影响垃圾回收器的工作,所以一旦表达式执行完毕,垃圾回收器就会将key从内存中移除。
所以WeakMap经常用于存储那些只有当key所引用的对象存在时(没有被回收)才有价值的信息,例如上面的场景中,如果target对象没有任何引用了,说明用户侧不再需要它了,这时垃圾回收器会完成回收任务。但如果使用Map,那么这个target将不会被回收,最终可能导致内存溢出。
初步实现:
const obj = new Proxy (data, {
// 拦截读取操作
get(target, key) {
// 将副作用函数activeEffect 添加到存储副作用函数的桶中
track(target, key)
return target[key]
},
// 拦截设置操作
set(target, key, newVal) {
//设置属性值
target[key] = newVal
// 把副作用函数从桶里取出并执行
trigger (target, key)
}
})
// 在get 拦截函数内调用 track 函数追踪变化
function track(target, key) {
// 没有activeEffect,直接 return
if (!activeEffect) return
let depsMap = bucket.get(target)
if (!depsMap) {
bucket.set(target, (depsMap = new Map()))
}
let deps = depsMap.get(key)
if (!deps) {
depsMap.set(key, (deps = new Set()))
}
deps.add(activeEffect)
}
// 在set 拦截函数内调用 trigger 函数触发变化
function trigger (target, key) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
effects && effects.forEach(fn => fn())
}当读取属性值时,我们直接在get拦截函数里编写把副作用函数收集到 “桶”里的这部分逻辑单独封装到一个 track 函数中,函数的名字叫 track 是为了表达追踪的含义。同样,我们也可以把触发副作用函数重新执行的逻辑封装到trigger函数中。
分支切换与cleanup
切换分支的定义:
const data = { ok: true, text: 'hello' }
const obj = new Proxy(data, { /* ... */ })
effect(function effectFn() {
document.body.innerText = obj.ok ? obj.text : 'not'
})当字段obj.ok的值发生变化时,代码执行的分支会跟着变化,这就是所谓的分支切换。
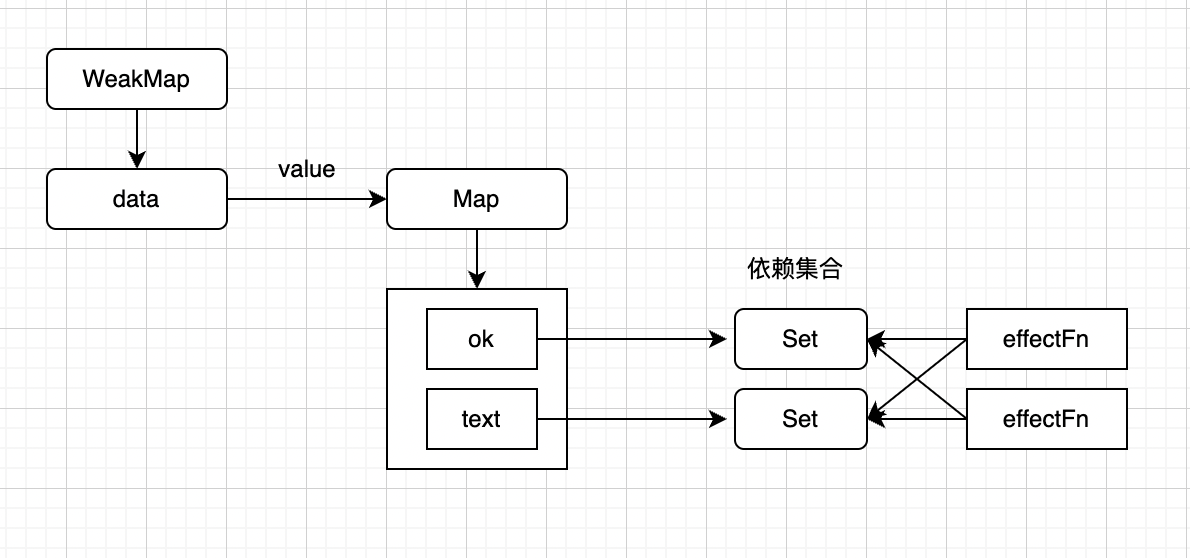
这时,副作用函数与响应式数据之间建立的联系如下:
data
|—— ok
|——effectFn
|—— text
|——effectFn
副作用函数 effectFn 分别被字段 data.ok 和字段 data.text 所对应的依赖集合收集
也就是说,当我们切换分支时,obj.ok = false,此时不会再读取 obj.text 的值,那么 obj.text 的值此时再变化后就不应该再继续执行 effectFn,我们需要及时清理遗留的副作用函数,以达到这个效果。
解决这个问题的思路是:每次副作用函数执行时,我们需要先把它从所有与之关联的依赖集合中删除,当副作用函数执行完毕后,会重新建立联系,但在新的联系中不会包含遗留的副作用函数。
要将一个副作用函数从所有关联的依赖集合中移除,就需要明确知道哪些依赖集合中包含它,因此我们需要重新设计副作用函数:
// 用一个全局变量存储被注册的副作用函数
let activeEffect
// effect函数用于注册副作用函数
function effect (fn) {
const effectFn = () => {
// 当 effectFn 执行时,将其设置为当前激活的副作用函数
activeEffect = effectFn
fn()
}
// activeEffect.deps 用来存储所有与该副作用函数相关联的依赖集合
effectFn.deps = []
effectFn()
}在 effect 内部我们定义了新的 effectFn 函数,并为其添加了 effectFn.deps 属性,该属性是一个数组,用来存储所有包含当前副作用函数的依赖集合。
那么 effectFn.deps 数组中的依赖集合是如何收集的呢?其实是在 track 函数中:
// 在get 拦截函数内调用 track 函数追踪变化
function track(target, key) {
// 没有activeEffect,直接 return
if (!activeEffect) return
let depsMap = bucket.get(target)
if (!depsMap) {
bucket.set(target, (depsMap = new Map()))
}
let deps = depsMap.get(key)
if (!deps) {
depsMap.set(key, (deps = new Set()))
}
// 把当前激活的副作用函数添加到依赖集合 deps 中
deps.add(activeEffect)
// deps 就是一个与当前副作用函数存在联系的依赖集合
// 将其添加到 activeEffect.deps 数组中
activeEffect.deps.push(deps) // 新增
}关系如图所示:
有了这个联系后,我们就可以在每次副作用函数执行时,根据 effectFn.deps 获取所有相关联的依赖集合,进而将副作用函数从依赖集合中移除:
// 用一个全局变量存储被注册的副作用函数
let activeEffect
// effect函数用于注册副作用函数
function effect (fn) {
const effectFn = () => {
cleanup(effectFn) // 新增
activeEffect = effectFn
fn()
}
// activeEffect.deps 用来存储所有与该副作用函数相关联的依赖集合
effectFn.deps = []
effectFn()
}嵌套的 effect 与 effect 栈
effect 是可以发生嵌套的,例如:
effect(function fn1 () {
effect(function fn2 () {
/*...*/
})
})什么情况下会出现嵌套的 effect 呢?实际上 Vue.js 的渲染函数就是在一个 effect 中执行的:
// Foo 组件
const Foo = {
render () {
return /*...*/
}
}在一个 effect 中执行 Foo 组件的渲染函数:
effect(() => {
Foo.render()
})当组件发生嵌套时,例如 Foo 组件渲染了 Bar 组件:
const Bar = {
render () {
return /*...*/
}
}
const Foo = {
render () {
return <Bar />
}
}此时就发生了 effect 嵌套,它相当于:
effect(() => {
Foo.render()
// 嵌套
effect(() => {
Bar.render()
})
})但观察现在的代码,我们用全局变量 activeEffect 来存储通过 effect 函数注册的副作用函数,这意味着同一时刻 activeEffect 所存储的副作用函数只能有一个。当副作用函数发生嵌套时,内层副作用函数的执行会覆盖 activeEffect 的值,并且永远不会恢复到原来的值。这时如果再有响应式数据进行依赖收集,即使这个响应式数据是在外层副作用函数中读取的,它们收集到的副作用函数也都会是内层副作用函数,这就是问题所在。
为了解决这个问题,我们需要一个副作用函数栈 effectStack,在副作用函数执行时,将当前副作用函数压入栈中,待副作用函数执行完毕后,将其从栈中弹出,并始终让 activeEffect 指向栈顶的副作用函数。这样就能做到一个响应式数据只会收集直接读取其值的副作用函数,而不会出现相互影响的情况。
如以下代码所示:
// 用一个全局变量存储当前激活的 effect 函数
let activeEffect
// effect 栈
const effectStack = [] // 新增
function effect (fn) {
const effectFn = () => {
cleanup(effectFn)
// 当调用 effect 注册副作用函数时,将副作用函数复制给 activeEffect
activeEffect = effectFn
// 在调用副作用函数之前将当前副作用函数压入栈中
effectStack.push(effectFn) // 新增
fn()
// 在当前副作用函数执行完毕后,将当前副作用函数弹出栈,并把 activeEffect 还原为之前的值
effectStack.pop() // 新增
activeEffect = effectStack[effectStack.length - 1] // 新增
}
// activeEffect.deps 用来存储所有与该副作用函数相关联的依赖集合
effectFn.deps = []
// 执行副作用函数
effectFn()
}这样,将内层副作用函数 effectFn2 执行完毕后,他会被弹出栈,并将副作用函数 effectFn1 设置为 activeEffect。这样一来,响应式数据就只会收集直接读取其值的副作用函数作为依赖,从而避免发生错乱。
避免无限递归循环
实现一个完善的响应式系统要考虑诸多细节,下面要介绍的无限递归循环就是其中之一。
举个例子:
const data = { foo: 1 }
const obj = new Proxy(data, { /*...*/ })
effect(() => obj.foo++)可以看到,在 effect 注册的副作用函数内有一个自增操作 obj.foo++,该操作会引起栈溢出:
Uncaught RangeError: Maximum call stack size exceeded
为什么会这样呢?
实际上,我们可以把 obj.foo++ 这个自增操作分开来看,它相当于 obj.foo = obj.foo + 1。在这个语句中,既会读取 obj.foo 的值,又会设置 obj.foo 的值,而这就是导致问题的根本原因。
首先读取 obj.foo 的值,这会触发 track 操作,将当前副作用函数收集到 “桶” 中,接着将其加 1 后再赋值给 obj.foo,此时又会同时触发 trigger 操作,即把 “桶” 中的副作用函数取出并执行。此时又会触发相同的操作,会无限递归的调用自己,于是就产生了栈溢出。
通过分析,我们发现读取和设置操作是在同一个副作用函数内进行的,此时无论是 track 时收集的副作用函数,还是 trigger 时要触发执行的副作用函数,都是 activeEffect。基于此,我们可以在 trigger 动作发生时增加守卫条件:如果 trigger 触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行,如下代码所示:
function trigger (target, key) {
const depsMap = bucket.get(target)
if (!depsMap) return
const effects = depsMap.get(key)
const effectsToRun = new Set()
effects && effects.forEach(effectFn => {
// 如果 trigger 触发执行的副作用函数与当前正在执行的副作用函数相同,则不触发执行
if (effectFn !== activeEffect) { // 新增
effectsToRun.add(effectFn)
}
})
effectsToRun.forEach(effectFn => effectFn())
}这样我们就能避免无限递归调用,从而避免栈溢出。
调度执行
可调度性:当 trigger 动作触发副作用函数重新执行时,有能力决定副作用函数执行的时机、次数以及方式
可调度性也是响应系统非常重要的特性
创建型模式
构造器模式
使用构造函数去初始化对象,就是应用了构造器模式。
初始化两个用户:
const A = {
name: 'AAA',
age: 25,
career: 'coder',
}
const B = {
name: 'BBB',
age: 24,
career: 'product manager'
}使用构造函数方式:
function User (name , age, career) {
this.name = name
this.age = age
this.career = career
}
const user = new User('lilei', 25, 'coder')在创建一个user过程中,谁变了,谁不变?
很明显,变的是每个user的姓名、年龄、工种这些值,这是用户的个性,不变的是每个员工都具备姓名、年龄、工种这些属性,这是用户的共性。
工厂模式
在使用构造器模式的时候,我们本质上是去抽象了每个对象实例的变与不变。那么使用工厂模式时,我们要做的就是去抽象不同构造函数(类)之间的变与不变。
例如,我们创建的不同职位的用户之间,需要添加一个 work 标签,代表每个职位所做的工作:
function Coder (name , age) {
this.name = name
this.age = age
this.career = 'coder'
this.work = ['写代码','写系分', '修Bug']
}
function ProductManager (name, age) {
this.name = name
this.age = age
this.career = 'product manager'
this.work = ['订会议室', '写PRD', '催更']
}
...现在我们有两个类(后面可能还会有更多的类),我们每次从数据库拿到一条数据,都要人工判断一下这个员工的工种,然后手动给它分配构造器吗?
不行,这也是一个“变”,我们把这个“变”交给一个函数去处理:
function Factory (name, age, career) {
switch(career) {
case 'coder':
return new Coder(name, age)
break
case 'product manager':
return new ProductManager(name, age)
break
...
}但整个公司上下有数十个工种,难道要手写数十个类、数十行 switch 吗?我们需要将上述两段代码结合,进一步提取“变”与“不变”。
不同工种的员工,共同点是:都拥有 name、age、career、work 这四个属性这样的共性。
它们之间的区别是:
- 每个字段取值的不同
- work 字段需要随 career 字段取值的不同而改变。
接下来我们将共性和个性分离,将共性封装:
function User (name , age, career, work) {
this.name = name
this.age = age
this.career = career
this.work = work
}
function Factory (name, age, career) {
let work
switch(career) {
case 'coder':
work = ['写代码','写系分', '修Bug']
break
case 'product manager':
work = ['订会议室', '写PRD', '催更']
break
case 'boss':
work = ['喝茶', '看报', '见客户']
case 'xxx':
// 其它工种的职责分配
...
}
return new User(name, age, career, work)
}总结一下,工厂模式其实就是将创建对象的过程单独封装。它很像我们去餐馆点菜:比如说点一份西红柿炒蛋,我们不用关心西红柿怎么切、怎么打鸡蛋这些菜品制作过程中的问题,我们只关心摆上桌那道菜。在工厂模式里,我传参这个过程就是点菜,工厂函数里面运转的逻辑就相当于炒菜的厨师和上桌的服务员做掉的那部分工作——这部分工作我们同样不用关心,我们只要能拿到工厂交付给我们的实例结果就行了。工厂模式的目的,就是为了实现无脑传参。
抽象工厂模式
抽象工厂在很长一段时间里,都被认为是 Java/C++ 这类语言的专利。因为在强类型的静态语言中,用这些语言创建对象时,我们需要时刻关注类型之间的解耦,以便该对象日后可以表现出多态性。
但 JavaScript,作为一种弱类型的语言,它具有天然的多态性,好像压根不需要考虑类型耦合问题。而目前的 JavaScript 语法里,也确实不支持抽象类的直接实现,我们只能凭借模拟去还原抽象类。但抽象工厂的这种设计**,是值得我们去学习的。
抽象工厂模式的定义,是围绕一个超级工厂创建其他工厂。
其中有四个关键角色:
- 抽象工厂(抽象类,它不能被用于生成具体实例)
- 具体工厂(用于生成产品族里的一个具体的产品)
- 抽象产品(抽象类,不能被用于生成具体实例)
- 具体产品(用于生成产品族里的一个具体的产品的更细粒度的产品)
如果我们需要一个工厂来生产手机,那么我们首先需要一个抽象类来约定住这台手机的基本组成:
// 抽象工厂
class MobilePhoneFactory {
// 提供操作系统的接口
createOS(){
throw new Error("抽象工厂方法不允许直接调用,你需要将我重写!");
}
// 提供硬件的接口
createHardWare(){
throw new Error("抽象工厂方法不允许直接调用,你需要将我重写!");
}
}抽象工厂不干活,具体工厂来干活。
当我们明确了生产方案,明确我们要生产什么样的手机了之后,就可以化抽象为具体,比如我现在想要一个专门生产 Android 系统 + 高通硬件的手机的生产线,我给这类手机型号起名叫 FakeStar,那我就可以为 FakeStar 定制一个具体工厂:
// 具体工厂继承自抽象工厂
class FakeStarFactory extends MobilePhoneFactory {
createOS() {
// 提供安卓系统实例
return new AndroidOS() // 具体产品类
}
createHardWare() {
// 提供高通硬件实例
return new QualcommHardWare() // 具体产品类
}
}这里我们调用了两个构造函数:AndroidOS 和 QualcommHardWare,它们分别用于生成具体的操作系统和硬件实例。像这种被我们拿来用于 new 出具体对象的类,叫做具体产品类。但具体产品类往往不会孤立存在,不同的具体产品类往往有着共同的功能,比如安卓系统类和苹果系统类,它们都是操作系统,都有着可以操控手机硬件系统这样一个最基本的功能。因此我们可以用一个抽象产品类来声明这一类产品应该具有的基本功能。
// 抽象产品类
class OS {
controlHardWare() {
throw new Error('抽象产品方法不允许直接调用,你需要将我重写!');
}
}
// 具体产品类继承自抽象产品类
class AndroidOS extends OS {
controlHardWare() {
console.log('我会用安卓的方式去操作硬件')
}
}
class AppleOS extends OS {
controlHardWare() {
console.log('我会用苹果的方式去操作硬件')
}
}
...硬件类产品同理:
// 抽象产品类
class HardWare {
// 手机硬件的共性方法,这里提取了“根据命令运转”这个共性
operateByOrder() {
throw new Error('抽象产品方法不允许直接调用,你需要将我重写!');
}
}
// 具体产品类
class QualcommHardWare extends HardWare {
operateByOrder() {
console.log('我会用高通的方式去运转')
}
}
class MiWare extends HardWare {
operateByOrder() {
console.log('我会用小米的方式去运转')
}
}
...如此一来,当我们需要生产一台FakeStar手机时,我们只需要这样做:
// 这是我的手机
const myPhone = new FakeStarFactory()
// 让它拥有操作系统
const myOS = myPhone.createOS()
// 让它拥有硬件
const myHardWare = myPhone.createHardWare()
// 启动操作系统(输出‘我会用安卓的方式去操作硬件’)
myOS.controlHardWare()
// 唤醒硬件(输出‘我会用高通的方式去运转’)
myHardWare.operateByOrder()如果我们需要再生产一款新种类的手机时,这时候我们不需要对抽象工厂MobilePhoneFactory做任何修改,只需要拓展它的种类:
class newStarFactory extends MobilePhoneFactory {
createOS() {
// 操作系统实现代码
}
createHardWare() {
// 硬件实现代码
}
}这样操作,对原有的系统不会造成任何潜在影响。所谓的**“对拓展开放,对修改封闭”**就这么圆满实现了。
前面我们之所以要实现抽象产品类,也是同样的道理。
总结,抽象工厂模式的定义,是围绕一个超级工厂创建其他工厂。只需留意以下三点:
- 学会用 ES6 模拟 JAVA 中的抽象类;
- 了解抽象工厂模式中四个角色的定位与作用;
- 对“开放封闭原则”形成自己的理解,知道它好在哪,知道执行它的必要性。
单例模式
保证一个类仅有一个实例,并提供一个访问它的全局访问点,这样的模式就叫做单例模式。
那么,如何才能保证一个类仅有一个实例?
一般情况下,当我们创建了一个类(本质是构造函数)后,可以通过new关键字调用构造函数进而生成任意多的实例对象:
class SingleDog {
show() {
console.log('我是一个单例对象')
}
}
const s1 = new SingleDog()
const s2 = new SingleDog()
s1 === s2 // false这里的 s1 和 s2 之间没有任何瓜葛,两者是相互独立的对象,各占一块内存空间。
而单例模式想要做到的是,不管我们尝试去创建多少次,它都只给你返回第一次所创建的那唯一的一个实例。
实现方式有两种
通过类的静态方法实现:
class SingleDog {
static getInstance () {
if (!SingleDog.instance) {
SingleDog.instance = new SingleDog()
}
return SingleDog.instance
}
}
const s1 = SingleDog.getInstance()
const s2 = SingleDog.getInstance()
s1 === s2 // true通过闭包实现:
class SingleDog {
...
}
const single = (function () {
let instance = null
return function () {
if (!instance) {
instance = new SingleDog()
}
return instance
}
})()
const s1 = single()
const s2 = single()
s1 === s2 // true生产实践:Vuex中的单例模式
近年来,基于 Flux 架构的状态管理工具层出不穷,其中应用最广泛的要数 Redux 和 Vuex。无论是 Redux 和 Vuex,它们都实现了一个全局的 Store 用于存储应用的所有状态。这个 Store 的实现,正是单例模式的典型应用。
Vuex如何确保Store的唯一性?
我们先来看看如何在项目中引入 Vuex:
// 安装vuex插件
Vue.use(Vuex)
// 将store注入到Vue实例中
new Vue({
el: '#app',
store
})通过调用Vue.use()方法,我们安装了 Vuex 插件。Vuex 插件是一个对象,它在内部实现了一个 install 方法,这个方法会在插件安装时被调用,从而把 Store 注入到Vue实例里去。也就是说每 install 一次,都会尝试给 Vue 实例注入一个 Store。
在 install 方法里,有一段和我们上面的 getInstance 非常相似的逻辑:
let Vue // 这个Vue的作用和楼上的instance作用一样
...
export function install (_Vue) {
// 判断传入的Vue实例对象是否已经被install过Vuex插件(是否有了唯一的state)
if (Vue && _Vue === Vue) {
if (process.env.NODE_ENV !== 'production') {
console.error(
'[vuex] already installed. Vue.use(Vuex) should be called only once.'
)
}
return
}
// 若没有,则为这个Vue实例对象install一个唯一的Vuex
Vue = _Vue
// 将Vuex的初始化逻辑写进Vue的钩子函数里
applyMixin(Vue)
}这就是 Vuex 源码中单例模式的实现办法了,套路可以说和我们的getInstance如出一辙。通过这种方式,可以保证一个 Vue 实例(即一个 Vue 应用)只会被 install 一次 Vuex 插件,所以每个 Vue 实例只会拥有一个全局的 Store。
原型模式
原型模式不仅是一种设计模式,它还是一种编程范式,是 JavaScript 面向对象系统实现的根基。
原型模式是 JavaScript 这门语言面向对象系统的根本。但在其它语言,比如 JAVA 中,类才是它面向对象系统的根本。所以说在 JAVA 中,我们可以选择不使用原型模式 —— 这样一来,所有的实例都必须要从类中来,当我们希望创建两个一模一样的实例时,就只能这样做:
Dog dog = new Dog('旺财', 'male', 3, '柴犬')
Dog dog_copy = new Dog('旺财', 'male', 3, '柴犬')我们不得不把一模一样的参数传两遍,非常麻烦。而原型模式允许我们通过调用克隆方法的方式达到同样的目的,比较方便,所以 Java 专门针对原型模式设计了一套接口和方法,在必要的场景下会通过原型方法来应用原型模式。当然,在更多的情况下,Java 仍以“实例化类”这种方式来创建对象。
所以说在以类为中心的语言中,原型模式确实不是一个必选项,它只有在特定的场景下才会登场。
在 Java 等强类型语言中,原型模式的出现是为了实现类型之间的解耦。而 JavaScript 本身类型就比较模糊,不存在类型耦合的问题,所以说咱们平时根本不会刻意地去使用原型模式。因此我们此处不必强行把原型模式当作一种设计模式去理解,把它作为一种编程范式来讨论会更合适。
结构型模式
装饰器模式
概念:允许向一个现有的对象添加新的功能,同时又不改变其结构。只作为现有的类的一个包装。这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。
场景:当我们做需求的时候,我需要对它已有的功能做个拓展,只关心拓展出来的那部分新功能如何实现,不关心旧逻辑。
如果我们要实现一个按钮,在点击后弹出弹窗:
// 弹框创建逻辑
const Modal = (function() {
let modal = null
return function() {
if(!modal) {
modal = document.createElement('div')
modal.id = 'modal'
modal.style.display = 'none'
document.body.appendChild(modal)
}
return modal
}
})()
// 点击打开按钮展示modal
document.getElementById('open').addEventListener('click', function() {
const modal = new Modal()
modal.style.display = 'block'
})
// 点击关闭按钮隐藏modal
document.getElementById('close').addEventListener('click', function() {
const modal = document.getElementById('modal')
if(modal) {
modal.style.display = 'none'
}
})后续如果我们需要添加一系列新功能,例如点击后按钮文字改变,按钮置灰等,那么我们需要直接去修改已有的函数体,这种做法违背了我们的“开放封闭原则”;往一个函数体里塞这么多逻辑,违背了我们的“单一职责原则”。
这个时候我们就需要装饰器模式,只拓展新功能,并不关心已有的功能。
ES5
抽离旧逻辑:
// 将弹出Modal的逻辑单独封装
function openModal() {
const modal = new Modal()
modal.style.display = 'block'
}编写新逻辑:
// 按钮文案修改逻辑
function changeButtonText() {
const btn = document.getElementById('open')
btn.innerText = '快去登录'
}
// 按钮置灰逻辑
function disableButton() {
const btn = document.getElementById('open')
btn.setAttribute("disabled", true)
}
// 新版本功能逻辑整合
function changeButtonStatus() {
changeButtonText()
disableButton()
}然后把三个操作逐个添加open按钮的监听函数里:
document.getElementById('open').addEventListener('click', function() {
openModal()
changeButtonStatus()
})如此一来,我们就实现了“只添加,不修改”的装饰器模式
ES6
ES6实现:
// 定义打开按钮
class OpenButton {
// 点击后展示弹框(旧逻辑)
onClick() {
const modal = new Modal()
modal.style.display = 'block'
}
}
// 定义按钮对应的装饰器
class Decorator {
// 将按钮实例传入
constructor(open_button) {
this.open_button = open_button
}
onClick() {
// 旧逻辑
this.open_button.onClick()
// “包装”了一层新逻辑
this.changeButtonStatus()
}
changeButtonStatus() {
this.changeButtonText()
this.disableButton()
}
disableButton() {
const btn = document.getElementById('open')
btn.setAttribute("disabled", true)
}
changeButtonText() {
const btn = document.getElementById('open')
btn.innerText = '快去登录'
}
}
const openButton = new OpenButton()
const decorator = new Decorator(openButton)
document.getElementById('open').addEventListener('click', function() {
decorator.onClick()
})ES6 这个版本的实现我们需要特别的关注,这里我们把按钮实例传给了 Decorator,以便于后续 Decorator 可以对它进行无限的逻辑的拓展。这是我们通常会用的实现方式
ES7
在 ES7 中,Decorator 作为一种语法被直接支持了,它的书写会变得更加简单,但背后的原理其实与此大同小异。
类装饰器:
// 类装饰器,它的第一个参数是目标类
function classDecorator(target) {
target.hasDecorator = true
return target
}
// 将装饰器“安装”到Button类上
@classDecorator
class Button {
// Button类的相关逻辑
}
// 验证装饰器是否生效
console.log('Button 是否被装饰了:', Button.hasDecorator)函数装饰器:
// 函数装饰器
function funcDecorator(target, name, descriptor) {
let originalMethod = descriptor.value
descriptor.value = function() {
console.log('我是Func的装饰器逻辑')
return originalMethod.apply(this, arguments)
}
return descriptor
}
class Button {
@funcDecorator
onClick() {
console.log('我是Func的原有逻辑')
}
}
// 验证装饰器是否生效
const button = new Button()
button.onClick()装饰器的最最基本操作就是定义装饰器函数,将被装饰者“交给”装饰器。这也正是装饰器语法糖首先帮我们做掉的工作,我们一起看看装饰器的实现细节:
当我们定义类装饰器函数时,此时的入参 target 就是被装饰的类本身;当我们给一个类中的方法添加装饰器时,例如给上述给 button 添加的装饰器,此处的 target 变成了Button.prototype,即类的原型对象。
这是因为 onClick 方法总是要依附其实例存在的,修饰 onClick 其实是修饰它的实例。实例是在我们的代码运行时动态生成的,而装饰器函数则是在编译阶段就执行了。所以说装饰器函数真正能触及到的,就只有类这个层面上的对象。
在编写类装饰器时,我们一般获取一个target参数就足够了。但在编写方法装饰器时,我们往往需要至少三个参数:
- target:类的原型对象
- name:修饰的目标属性属性名
- descriptor:属性描述对象,是我们使用频率最高的一个参数,相当于
Object.defineProperty(obj, prop, descriptor)中的 descriptor,这里面有数据描述符(value),存取描述符(get, set)等。很明显,拿到了 descriptor,就相当于拿到了目标方法的控制权。通过修改 descriptor,我们就可以对目标方法的逻辑进行无限的拓展了。
适配器模式
适配器模式是作为两个不兼容的接口之间的桥梁。它结合了两个独立接口的功能。这种模式涉及到一个单一的类,该类负责加入独立的或不兼容的接口功能。
生产实践:axios中的适配器
axios 本身就用到了我们的适配器模式,它的兼容方案值得我们学习和借鉴。
在使用axios时,作为用户我们只需要掌握下面常用的接口为代表的一套api,便可轻松地发起各种姿势的网络请求,而不用去关心底层的实现细节:
axios.post('/user', {
firstName: 'Fred',
lastName: 'Flintstone'
})
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
axios({
method: 'post',
url: '/user/12345',
data: {
firstName: 'Fred',
lastName: 'Flintstone'
}
})除了简明优雅的api之外,axios 强大的地方还在于,它不仅仅是一个局限于浏览器端的库。在Node环境下,我们尝试调用上面的 api,会发现它照样好使 —— axios 完美地抹平了两种环境下api的调用差异,靠的正是对适配器模式的灵活运用。
在 axios 的核心逻辑中,我们可以注意到实际上派发请求的是 dispatchRequest 方法。该方法内部其实主要做了两件事:
- 数据层面的适配,数据转换,转换请求体/响应体;
- 调用适配器。
调用适配器的逻辑如下:
// 若用户未手动配置适配器,则使用默认的适配器
var adapter = config.adapter || defaults.adapter;
// dispatchRequest方法的末尾调用的是适配器方法
return adapter(config).then(function onAdapterResolution(response) {
// 请求成功的回调
throwIfCancellationRequested(config);
// 转换响应体
response.data = transformData(
response.data,
response.headers,
config.transformResponse
);
return response;
}, function onAdapterRejection(reason) {
// 请求失败的回调
if (!isCancel(reason)) {
throwIfCancellationRequested(config);
// 转换响应体
if (reason && reason.response) {
reason.response.data = transformData(
reason.response.data,
reason.response.headers,
config.transformResponse
);
}
}
return Promise.reject(reason);
});“若用户未手动配置适配器,则使用默认的适配器”。手动配置适配器允许我们自定义处理请求。
在实际开发中,我们使用默认适配器的频率更高。默认适配器在axios/lib/default.js里是通过getDefaultAdapter方法来获取的:
function getDefaultAdapter() {
var adapter;
// 判断当前是否是node环境
if (typeof process !== 'undefined' && Object.prototype.toString.call(process) === '[object process]') {
// 如果是node环境,调用node专属的http适配器
adapter = require('./adapters/http');
} else if (typeof XMLHttpRequest !== 'undefined') {
// 如果是浏览器环境,调用基于xhr的适配器
adapter = require('./adapters/xhr');
}
return adapter;
}http适配器:
module.exports = function httpAdapter(config) {
return new Promise(function dispatchHttpRequest(resolvePromise, rejectPromise) {
// 具体逻辑
}
}xhr适配器:
module.exports = function xhrAdapter(config) {
return new Promise(function dispatchXhrRequest(resolve, reject) {
// 具体逻辑
}
}除开具体逻辑,我们现在可以注意两点:
- 两个适配器的入参都是 config
- 两个适配器的出参都是一个 Promise
要是仔细读了源码,会发现两个适配器中的 Promise 的内部结构也是如出一辙
这么一来,通过 axios 发起跨平台的网络请求,不仅调用的接口名是同一个,连入参、出参的格式都只需要掌握同一套。这导致它的学习成本非常低,开发者看了文档就能上手;同时因为足够简单,在使用的过程中也不容易出错,带来了极佳的用户体验,axios 也因此越来越流行。
这正是一个好的适配器的自我修养——把变化留给自己,把统一留给用户。
在此处,所有关于 http 模块、关于 xhr 的实现细节,全部被 Adapter 封装进了自己复杂的底层逻辑里,暴露给用户的都是十分简单的统一的东西——统一的接口,统一的入参,统一的出参,统一的规则。用起来就很舒服。
代理模式
概念:一个对象不能直接访问另一个对象,需要一个第三者(代理)牵线搭桥从而间接达到访问目的,这样的模式就是代理模式。
实践:
-
科学上网
-
在 ES6 中,提供了专门以代理角色出现的代理器 —— Proxy。它的基本用法如下:
const proxy = new Proxy(obj, handler)
第一个参数是我们的目标对象,handler 也是一个对象,用来定义代理的行为。当我们通过 proxy 去访问目标对象的时候,handler 会对我们的行为作一层拦截,我们的每次访问都需要经过 handler 这个第三方。
下面是常见的四种代理类型:事件代理、虚拟代理、缓存代理和保护代理
事件代理
事件代理是代理模式最常见的一种应用方式,最常见的就是利用事件“冒泡”的特性,来让父元素代理子元素的事件。例如统一在父元素上绑定点击事件的回调函数。
虚拟代理
实践:图片预加载
除了图片懒加载,还有一种操作叫图片预加载。预加载主要是为了避免网络不好、或者图片太大时,页面长时间给用户留白的尴尬。常见的操作是先让这个 img 标签展示一个占位图,然后创建一个 Image 实例,让这个 Image 实例的 src 指向真实的目标图片地址、观察该 Image 实例的加载情况 —— 当其对应的真实图片加载完毕后,即已经有了该图片的缓存内容,再将 DOM 上的 img 元素的 src 指向真实的目标图片地址。此时我们直接去取了目标图片的缓存,所以展示速度会非常快,从占位图到目标图片的时间差会非常小、小到用户注意不到,这样体验就会非常好了。
具体实现如下:
class PreLoadImage {
// 占位图的url地址
static LOADING_URL = 'xxxxxx'
constructor(imgNode) {
// 获取该实例对应的DOM节点
this.imgNode = imgNode
}
// 该方法用于设置真实的图片地址
setSrc(targetUrl) {
// img节点初始化时展示的是一个占位图
this.imgNode.src = PreLoadImage.LOADING_URL
// 创建一个帮我们加载图片的Image实例
const image = new Image()
// 监听目标图片加载的情况,完成时再将DOM上的img节点的src属性设置为目标图片的url
image.onload = () => {
this.imgNode.src = targetUrl
}
// 设置src属性,Image实例开始加载图片
image.src = targetUrl
}
}上述 PreLoadImage 乍一看没问题,但其实违反了我们设计原则中的单一职责原则。
PreLoadImage 不仅要负责图片的加载,还要负责 DOM 层面的操作(img 节点的初始化和后续的改变)。这样一来,就出现了两个可能导致这个类发生变化的原因。
这个时候我们就可以将两个逻辑分离,让 PreLoadImage 专心去做 DOM 层面的事情(真实 DOM 节点的获取、img 节点的链接设置),再找一个对象来专门来帮我们搞加载——这两个对象之间缺个媒介,这个媒介就是代理器:
class PreLoadImage {
constructor(imgNode) {
// 获取真实的DOM节点
this.imgNode = imgNode
}
// 操作img节点的src属性
setSrc(imgUrl) {
this.imgNode.src = imgUrl
}
}
class ProxyImage {
// 占位图的url地址
static LOADING_URL = 'xxxxxx'
constructor(targetImage) {
// 目标Image,即PreLoadImage实例
this.targetImage = targetImage
}
// 该方法主要操作虚拟Image,完成加载
setSrc(targetUrl) {
// 真实img节点初始化时展示的是一个占位图
this.targetImage.setSrc(ProxyImage.LOADING_URL)
// 创建一个帮我们加载图片的虚拟Image实例
const virtualImage = new Image()
// 监听目标图片加载的情况,完成时再将DOM上的真实img节点的src属性设置为目标图片的url
virtualImage.onload = () => {
this.targetImage.setSrc(targetUrl)
}
// 设置src属性,虚拟Image实例开始加载图片
virtualImage.src = targetUrl
}
}ProxyImage 帮我们调度了预加载相关的工作,我们可以通过 ProxyImage 这个代理,实现对真实 img 节点的间接访问,并得到我们想要的效果。
在这个实例中,virtualImage 这个对象是一个“幕后英雄”,它始终存在于 JavaScript 世界中、代替真实 DOM 发起了图片加载请求、完成了图片加载工作,却从未在渲染层面抛头露面。因此这种模式被称为“虚拟代理”模式。
缓存代理
在这种场景下,我们需要“用空间换时间”——当我们需要用到某个已经计算过的值的时候,不想再耗时进行二次计算,而是希望能从内存里去取出现成的计算结果。这种场景下,就需要一个代理来帮我们在进行计算的同时,进行计算结果的缓存了。
一个比较典型的例子,是对传入的参数进行求和:
// addAll方法会对你传入的所有参数做求和操作
const addAll = function() {
console.log('进行了一次新计算')
let result = 0
const len = arguments.length
for(let i = 0; i < len; i++) {
result += arguments[i]
}
return result
}
// 为求和方法创建代理
const proxyAddAll = (function(){
// 求和结果的缓存池
const resultCache = {}
return function() {
// 将入参转化为一个唯一的入参字符串
const args = Array.prototype.join.call(arguments, ',')
// 检查本次入参是否有对应的计算结果
if(args in resultCache) {
// 如果有,则返回缓存池里现成的结果
return resultCache[args]
}
return resultCache[args] = addAll(...arguments)
}
})()proxyAddAll 针对重复的入参只会计算一次,这将大大节省计算过程中的时间开销。当我们入参比较少的时候,可能还看不出来,当我们针对大量入参、做反复计算时,缓存代理的优势将得到更充分的凸显。
保护代理
所谓“保护代理”,就是在访问层面做文章,在 getter 和 setter 函数里去进行校验和拦截,确保一部分变量是安全的。上节中我们提到的 Proxy,它本身就是为拦截而生的,所以我们目前实现保护代理时,考虑的首要方案就是 ES6 中的 Proxy。
组件渲染流程(creatApp)
creatApp
文件入口
import { creatApp } from Vue
import App from './App.ts'
creatApp(App).mount(#app)我们需要了解 createApp 里面都做了些什么
createApp 其实是个入口函数,它是 Vue.js 对外暴露的一个函数,我们来看一下它的内部实现:
// packages/runtime-dom/src/index.ts
const createApp = ((...args) => {
// 创建 app 对象
const app = ensureRenderer().createApp(...args)
const { mount } = app
// 重写 mount 方法
app.mount = (containerOrSelector) => {
// ...
}
return app
})可以看到,createApp 主要做了两件事情:创建 app 对象和重写 app.mount 方法
创建 app 对象
首先,使用了 ensureRenderer().createApp() 来创建 app 对象 :
const app = ensureRenderer().createApp(...args)其中 ensureRenderer() 用来创建一个渲染器对象,它的内部代码是这样的:
// packages/runtime-dom/src/index.ts
// 渲染相关的一些配置,比如更新属性的方法,操作 DOM 的方法
const rendererOptions = {
patchProp,
...nodeOps
}
let renderer
// 延时创建渲染器,当用户只依赖响应式包的时候,可以通过 tree-shaking 移除核心渲染逻辑相关的代码
function ensureRenderer() {
return renderer || (renderer = createRenderer(rendererOptions))
}这里先用 ensureRenderer() 来延时创建渲染器,这样做的好处是当用户只依赖响应式包的时候,就不会创建渲染器,因此可以通过 tree-shaking 的方式移除核心渲染逻辑相关的代码。
这个渲染器(可以简单地把渲染器理解为包含平台渲染核心逻辑的 JavaScript 对象),是为跨平台渲染做准备的
结合上面的代码继续深入,在 Vue.js 3.0 内部通过 createRenderer 创建一个渲染器,这个渲染器内部会有一个 createApp 方法
// packages/runtime-core/src/renderer.ts
function createRenderer(options) {
return baseCreateRenderer(options)
}
function baseCreateRenderer(options) {
function render(vnode, container) {
// 组件渲染的核心逻辑
}
...
return {
render,
createApp: createAppAPI(render)
}
}createApp 方法是执行 createAppAPI 方法返回的函数,接受了 rootComponent 和 rootProps 两个参数,我们在应用层面执行 createApp(App) 方法时,会把 App 组件对象作为根组件传递给 rootComponent。这样,createApp 内部就创建了一个 app 对象,它会提供 mount 方法,这个方法是用来挂载组件的。
// packages/runtime-core/src/apiCreateApp.ts
function createAppAPI(render) {
// createApp 方法接受的两个参数:根组件的对象和 prop
return function createApp(rootComponent, rootProps = null) {
const app = {
_component: rootComponent,
_props: rootProps,
mount(rootContainer) {
// 创建根组件的 vnode
const vnode = createVNode(rootComponent, rootProps)
// 利用渲染器渲染 vnode
render(vnode, rootContainer)
app._container = rootContainer
return vnode.component.proxy
}
}
return app
}
}在整个 app 对象创建过程中,Vue.js 利用闭包和函数柯里化的技巧,很好地实现了参数保留。比如,在执行 app.mount 的时候,并不需要传入渲染器 render,这是因为在执行 createAppAPI 的时候渲染器 render 参数已经被保留下来了。
可以看到,createApp 是将若干属性和方法挂载在 app 这个变量中,最后返回 app。
重写 app.mount 方法
根据前面的分析,我们知道 createApp 返回的 app 对象已经拥有了 mount 方法了,但在入口函数中,接下来的逻辑却是对 app.mount 方法的重写。为什么要重写这个方法,而不把相关逻辑放在 app 对象的 mount 方法内部来实现呢?
因为 Vue.js 不仅仅是为 Web 平台服务,它的目标是支持跨平台渲染,而 createApp 函数内部的 app.mount 方法是一个标准的可跨平台的组件渲染流程:先创建vnode,再渲染vnode
mount(rootContainer) {
// 创建根组件的 vnode
const vnode = createVNode(rootComponent, rootProps)
// 利用渲染器渲染 vnode
render(vnode, rootContainer)
app._container = rootContainer
return vnode.component.proxy
}此外,参数 rootContainer 也可以是不同类型的值,比如,在 Web 平台它是一个 DOM 对象,而在其他平台(比如 Weex 和小程序)中可以是其他类型的值。所以这里面的代码不应该包含任何特定平台相关的逻辑,也就是说这些代码的执行逻辑都是与平台无关的。因此我们需要在外部重写这个方法,来完善 Web 平台下的渲染逻辑。
看看 app.mount 重写都做了哪些事情:
// packages/runtime-dom/src/index.ts
app.mount = (containerOrSelector) => {
// 标准化容器
const container = normalizeContainer(containerOrSelector)
if (!container) return
const component = app._component
// 如组件对象没有定义 render 函数和 template 模板,则取容器的 innerHTML 作为组件模板内容
if (!isFunction(component) && !component.render && !component.template) {
component.template = container.innerHTML
}
// 挂载前清空容器内容
container.innerHTML = ''
// 真正的挂载
return mount(container)
}首先是通过 normalizeContainer 标准化容器(这里可以传字符串选择器或者 DOM 对象,但如果是字符串选择器,就需要把它转成 DOM 对象,作为最终挂载的容器),然后做一个 if 判断,如果组件对象没有定义 render 函数和 template 模板,则取容器的 innerHTML 作为组件模板内容;接着在挂载前清空容器内容,最终再调用 app.mount 的方法走标准的组件渲染流程。
从 app.mount 开始,才算真正进入组件渲染流程,接下来,重点看一下核心渲染流程做的两件事情:创建 vnode 和渲染 vnode。
创建 vnode
vnode 本质上是用来描述 DOM 的 JavaScript 对象,它在 Vue.js 中可以描述不同类型的节点,比如普通元素节点、组件节点等。
普通元素节点,例如:
<button class="btn" style="width:100px;height:50px">click me</button>我们可以用 vnode 这样表示<button>标签:
const vnode = {
type: 'button',
props: {
'class': 'btn',
style: {
width: '100px',
height: '50px'
}
},
children: 'click me'
}其中,type 属性表示 DOM 的标签类型;props 属性表示 DOM 的一些附加信息,比如 style 、class 等;children 属性表示 DOM 的子节点,它也可以是一个 vnode 数组,只不过 vnode 可以用字符串表示简单的文本 。
然后,vnode 除了可以像上面那样用于描述一个真实的 DOM,也可以用来描述组件。组件节点 示例:
<custom-component msg="test"></custom-component>我们可以用 vnode 这样表示 <custom-component> 组件标签:
const CustomComponent = {
// 在这里定义组件对象
}
const vnode = {
type: CustomComponent,
props: {
msg: 'test'
}
}组件 vnode 其实是对抽象事物的描述,这是因为我们并不会在页面上真正渲染一个 <custom-component> 标签,而是渲染组件内部定义的 HTML 标签。
除了上两种 vnode 类型外,还有纯文本 vnode、注释 vnode 等等。
另外,Vue3 内部还针对 vnode 的 type,做了更详尽的分类,包括 Suspense、Teleport 等,且把 vnode 的类型信息做了编码,以便在后面的 patch 阶段,可以根据不同的类型执行相应的处理逻辑:
const shapeFlag = isString(type)
? 1 /* ELEMENT */
: isSuspense(type)
? 128 /* SUSPENSE */
: isTeleport(type)
? 64 /* TELEPORT */
: isObject(type)
? 4 /* STATEFUL_COMPONENT */
: isFunction(type)
? 2 /* FUNCTIONAL_COMPONENT */
: 0
......vnode的优点:
- 首先是抽象,引入 vnode,可以把渲染过程抽象化,从而使得组件的抽象能力也得到提升。
- 其次是跨平台,因为 patch vnode 的过程不同平台可以有自己的实现,基于 vnode 再做服务端渲染、Weex 平台、小程序平台的渲染都变得容易了很多。
不过这里要特别注意,使用 vnode 并不意味着不用操作 DOM 了,很多人会误以为 vnode 的性能一定比手动操作原生 DOM 好,这个其实是不一定的。
因为,首先这种基于 vnode 实现的 MVVM 框架,在每次 render to vnode 的过程中,渲染组件会有一定的 JavaScript 耗时,特别是大组件,比如一个 1000 * 10 的 Table 组件,render to vnode 的过程会遍历 1000 * 10 次去创建内部 cell vnode,整个耗时就会变得比较长,加上 patch vnode 的过程也会有一定的耗时,当我们去更新组件的时候,用户会感觉到明显的卡顿。虽然 diff 算法在减少 DOM 操作方面足够优秀,但最终还是免不了操作 DOM,所以说性能并不是 vnode 的优势。
那么,Vue.js 内部是如何创建这些 vnode 的呢?
在 app.mount 函数内部是通过 createVNode 函数创建了根组件的 vnode:
const vnode = createVNode(rootComponent, rootProps)我们来看一下 createVNode 函数的大致实现:
// packages/runtime-core/src/vnode.ts
export const createVNode = (
__DEV__ ? createVNodeWithArgsTransform : _createVNode
) as typeof _createVNode
function _createVNode(type, props = null, children = null) {
if (props) {
// 处理 props 相关逻辑,标准化 class 和 style
}
// 对 vnode 类型信息编码
const shapeFlag = isString(type)
? 1 /* ELEMENT */
: isSuspense(type)
? 128 /* SUSPENSE */
: isTeleport(type)
? 64 /* TELEPORT */
: isObject(type)
? 4 /* STATEFUL_COMPONENT */
: isFunction(type)
? 2 /* FUNCTIONAL_COMPONENT */
: 0
const vnode = {
type,
props,
shapeFlag,
// 一些其他属性
}
// 标准化子节点,把不同数据类型的 children 转成数组或者文本类型
normalizeChildren(vnode, children)
return vnode
}通过上述代码可以看到,其实 createVNode 做的事情很简单,就是:
- 对 props 做标准化处理
- 对 vnode 的类型信息编码
- 创建 vnode 对象
- 标准化子节点 children 。
我们现在拥有了这个 vnode 对象,接下来要做的事情就是把它渲染到页面中去。
渲染 vnode
// packages/runtime-core/src/render.ts
const render = (vnode, container, isSVG) => {
if (vnode == null) {
// 销毁组件
if (container._vnode) {
unmount(container._vnode, null, null, true)
}
} else {
// 创建或者更新组件
patch(container._vnode || null, vnode, container, null, null, null, isSVG)
}
// 缓存 vnode 节点,表示已经渲染
container._vnode = vnode
}如果它的第一个参数 vnode 为空,则执行销毁组件的逻辑,否则执行创建或者更新组件的逻辑。
接着看上面渲染 vnode 的代码中涉及的 patch 函数的实现:
// packages/runtime-core/src/render.ts
const patch = (
n1, // 上次渲染过的vnode(旧节点)
n2, // 新传进来的vnode(新节点)
container,
anchor = null,
parentComponent = null,
parentSuspense = null,
isSVG = false,
optimized = false
) => {
if (n1 === n2) {
return
}
// 如果存在新旧节点, 且新旧节点类型不同,则销毁旧节点
if (n1 && !isSameVNodeType(n1, n2)) {
anchor = getNextHostNode(n1)
unmount(n1, parentComponent, parentSuspense, true)
n1 = null
}
const { type, shapeFlag } = n2
switch (type) {
case Text:
// 处理文本节点
processText(n1, n2, container, anchor)
break
case Comment:
// 处理注释节点
processCommentNode(n1, n2, container, anchor)
break
case Static:
// 处理静态节点
...
break
case Fragment:
// 处理 Fragment 元素
...
break
default:
if (shapeFlag & 1 /* ELEMENT */) {
// 处理普通 DOM 元素
processElement(n1, n2, container, anchor, parentComponent, parentSuspense, isSVG, optimized)
}
else if (shapeFlag & 6 /* COMPONENT */) {
// 处理组件
processComponent(n1, n2, container, anchor, parentComponent, parentSuspense, isSVG, optimized)
}
else if (shapeFlag & 64 /* TELEPORT */) {
// 处理 TELEPORT
}
else if (shapeFlag & 128 /* SUSPENSE */) {
// 处理 SUSPENSE
}
}
}patch 这个函数有两个功能:
- 根据 vnode 挂载 DOM(创建)
- 根据新旧 vnode 更新 DOM(更新)
我们分析一下创建的过程。在创建的过程中,patch 函数接受多个参数,这里我们目前只重点关注前三个:
- 第一个参数 n1 表示旧的 vnode,当 n1 为 null 的时候,表示是一次挂载的过程;
- 第二个参数 n2 表示新的 vnode 节点,后续会根据这个 vnode 类型执行不同的处理逻辑;
- 第三个参数 container 表示 DOM 容器,也就是 vnode 渲染生成 DOM 后,会挂载到 container 下面。
对于渲染的节点,我们这里重点关注两种类型节点的渲染逻辑:
- 对
组件的处理 - 对
普通 DOM 元素的处理
对组件的处理
由于初始化渲染的是 App 组件,它是一个组件 vnode,所以我们来看一下组件的处理逻辑是怎样的。首先是用来处理组件的 processComponent 函数的实现,然后是挂载组件的 mountComponent 函数的实现
// packages/runtime-core/src/render.ts
const processComponent = (
n1,
n2,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
) => {
if (n1 == null) {
// 挂载组件
mountComponent(n2, container, anchor, parentComponent, parentSuspense, isSVG, optimized)
}
else {
// 更新组件
updateComponent(n1, n2, parentComponent, optimized)
}
}
const mountComponent = (
initialVNode,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
) => {
// 创建组件实例
const instance = initialVNode.component || (initialVNode.component = createComponentInstance(initialVNode, parentComponent, parentSuspense))
// 设置组件实例
setupComponent(instance)
// 设置并运行带副作用的渲染函数
setupRenderEffect(instance, initialVNode, container, anchor, parentSuspense, isSVG, optimized)
}可以看到,挂载组件函数 mountComponent 主要做三件事情:
- 创建组件实例
- 设置组件实例
- 设置并运行带副作用的渲染函数。
首先是创建组件实例,Vue.js 3.0 虽然不像 Vue.js 2.x 那样通过类的方式去实例化组件,但内部也通过对象的方式去创建了当前渲染的组件实例(createComponentInstance函数)。
其次设置组件实例,instance 保留了很多组件相关的数据,维护了组件的上下文,包括对 props、插槽,以及其他实例的属性的初始化处理。
最后是运行带副作用的渲染函数 setupRenderEffect,我们重点来看一下这个函数的实现:
// packages/runtime-core/src/render.ts
const setupRenderEffect = (
instance,
initialVNode,
container,
anchor,
parentSuspense,
isSVG,
optimized
) => {
const componentUpdateFn = () => {
if (!instance.isMounted) {
// 渲染组件生成子树 vnode
const subTree = (instance.subTree = renderComponentRoot(instance))
// 把子树 vnode 挂载到 container 中
patch(null, subTree, container, anchor, instance, parentSuspense, isSVG)
// 保留渲染生成的子树根 DOM 节点
initialVNode.el = subTree.el
instance.isMounted = true
}
else {
// 更新组件
}
}
// 创建响应式的副作用渲染函数
const effect = new ReactiveEffect(
componentUpdateFn,
() => queueJob(instance.update),
instance.scope // track it in component's effect scope
)
const update = (instance.update = effect.run.bind(effect) as SchedulerJob)
}该函数利用响应式库的 ReactiveEffect 函数创建了一个副作用渲染函数 componentUpdateFn
当组件的数据发生变化时,effect 函数包裹的内部渲染函数 componentUpdateFn 会重新执行一遍,从而达到重新渲染组件的目的。
渲染函数内部也会判断这是一次初始渲染还是组件更新。这里我们只分析初始渲染流程。
初始渲染主要做两件事情:渲染组件生成 subTree、把 subTree 挂载到 container 中。
首先,是渲染组件生成 subTree,它也是一个 vnode 对象。这里要注意区别 subTree 和 initialVNode(在 Vue.js 3.0 中,根据命名我们已经能很好地区分它们了,而在 Vue.js 2.x 中它们分别命名为 _vnode 和 $vnode)。
举个例子,在父组件 App 中里引入了 Hello 组件:
<template>
<div class="app">
<p>This is an app.</p>
<hello></hello>
</div>
</template>在 Hello 组件中是 <div> 标签包裹着一个 <p> 标签:
<template>
<div class="hello">
<p>Hello, Vue 3.0!</p>
</div>
</template>在 App 组件中, <hello> 节点渲染生成的 vnode ,对应的就是 Hello 组件的 initialVNode,我们可以把它称作“组件 vnode”。而 Hello 组件内部整个 DOM 节点对应的 vnode 就是执行 renderComponentRoot 渲染生成对应的 subTree,我们可以把它称作“子树 vnode”。
我们知道每个组件都会有对应的 render 函数,即使你写 template,也会编译成 render 函数,而 renderComponentRoot 函数就是去执行 render 函数创建整个组件树内部的 vnode,把这个 vnode 再经过内部一层标准化,就得到了该函数的返回结果:子树 vnode。
渲染生成子树 vnode 后,接下来就是继续调用 patch 函数把子树 vnode 挂载到 container 中了。
那么我们又再次回到了 patch 函数,会继续对这个子树 vnode 类型进行判断,对于上述例子,App 组件的根节点是 <div> 标签,那么对应的子树 vnode 也是一个普通元素 vnode,那么我们接下来看 对普通 DOM 元素的处理流程。
对普通DOM元素的处理
处理普通 DOM元素的 processElement 函数的实现:
// packages/runtime-core/src/render.ts
const processElement = (
n1,
n2,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
) => {
isSVG = isSVG || n2.type === 'svg'
if (n1 == null) {
//挂载元素节点
mountElement(n2, container, anchor, parentComponent, parentSuspense, isSVG, optimized)
}
else {
//更新元素节点
patchElement(n1, n2, parentComponent, parentSuspense, isSVG, optimized)
}
}
const mountElement = (
vnode,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
) => {
let el
const { type, props, shapeFlag } = vnode
// 创建 DOM 元素节点
el = vnode.el = hostCreateElement(vnode.type, isSVG, props && props.is)
if (props) {
// 处理 props,比如 class、style、event 等属性
for (const key in props) {
if (!isReservedProp(key)) {
hostPatchProp(el, key, null, props[key], isSVG)
}
}
}
if (shapeFlag & 8 /* TEXT_CHILDREN */) {
// 处理子节点是纯文本的情况
hostSetElementText(el, vnode.children)
}
else if (shapeFlag & 16 /* ARRAY_CHILDREN */) {
// 处理子节点是数组的情况
mountChildren(vnode.children, el, null, parentComponent, parentSuspense, isSVG && type !== 'foreignObject', optimized || !!vnode.dynamicChildren)
}
// 把创建的 DOM 元素节点挂载到 container 上
hostInsert(el, container, anchor)
}主要看挂载元素的 mountElement 函数,可以看到,挂载元素函数主要做四件事:
- 创建 DOM 元素节点
- 处理 props
- 处理 children
- 挂载 DOM 元素到 container 上。
首先是创建 DOM 元素节点,通过 hostCreateElement 方法创建,这是一个平台相关的方法,我们来看一下它在 Web 环境下的定义:
// packages/runtime-dom/src/nodeOps.ts
function createElement (tag, isSVG, is, props) => {
const el = isSVG
? doc.createElementNS(svgNS, tag)
: doc.createElement(tag, is ? { is } : undefined)
if (tag === 'select' && props && props.multiple != null) {
;(el as HTMLSelectElement).setAttribute('multiple', props.multiple)
}
return el
}它调用了底层的 DOM API document.createElement 创建元素,所以本质上 Vue.js 强调不去操作 DOM ,只是希望用户不直接碰触 DOM,它并没有什么神奇的魔法,底层还是会操作 DOM。
另外,如果是其他平台比如 Weex,hostCreateElement 方法就不再是操作 DOM ,而是平台相关的 API 了,这些平台相关的方法是在 创建渲染器阶段作为参数传入的。
创建完 DOM 节点后,接下来要做的是判断如果有 props 的话,给这个 DOM 节点添加相关的 class、style、event 等属性,并做相关的处理,这些逻辑都是在 hostPatchProp 函数内部做的。
接下来是对子节点的处理,我们知道 DOM 是一棵树,vnode 同样也是一棵树,并且它和 DOM 结构是一一映射的。
如果子节点是纯文本,则执行 hostSetElementText 方法,它在 Web 环境下通过设置 DOM 元素的 textContent 属性设置文本:
// packages/runtime-dom/src/nodeOps.ts
function setElementText (el, text) => {
el.textContent = text
}如果子节点是数组,则执行 mountChildren 方法:
// packages/runtime-core/src/renderer.ts
const mountChildren = (
children,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized,
start = 0
) => {
for (let i = start; i < children.length; i++) {
// 预处理 child
const child = (children[i] = optimized
? cloneIfMounted(children[i])
: normalizeVNode(children[i]))
// 递归 patch 挂载 child
patch(
null,
child,
container,
anchor,
parentComponent,
parentSuspense,
isSVG,
optimized
)
}
}子节点的挂载逻辑同样很简单,遍历 children 获取到每一个 child,然后递归执行 patch 方法挂载每一个 child 。注意,这里有对 child 做预处理的情况(属于编译优化的内容)。
可以看到,mountChildren 函数的第二个参数是 container,而我们调用 mountChildren 方法传入的第二个参数是在 mountElement 时创建的 DOM 节点,这就很好地建立了父子关系。
通过 patch,我们就可以构造完整的 DOM 树,完成组件的渲染。
处理完所有子节点后,最后通过 hostInsert 方法把创建的 DOM 元素节点挂载到 container 上,它在 Web 环境下这样定义:
// packages/runtime-dom/src/nodeOps.ts
function insert(child, parent, anchor) {
if (anchor) {
parent.insertBefore(child, anchor)
}
else {
parent.appendChild(child)
}
}在 mountChildren 的时候递归执行的是 patch 函数,而不是 mountElement 函数,这是因为子节点可能有其他类型的 vnode,比如组件 vnode。
在真实开发场景中,嵌套组件的场景很多,前面我们举的 App 和 Hello 组件的例子就是嵌套组件的场景。组件 vnode 主要维护着组件的定义对象,组件上的各种 props,而组件本身是一个抽象节点,它自身的渲染其实是通过执行组件定义的 render 函数渲染生成的子树 vnode 来完成,然后再 patch 。通过这种递归的方式,无论组件的嵌套层级多深,都可以完成整个组件树的渲染。
流程图
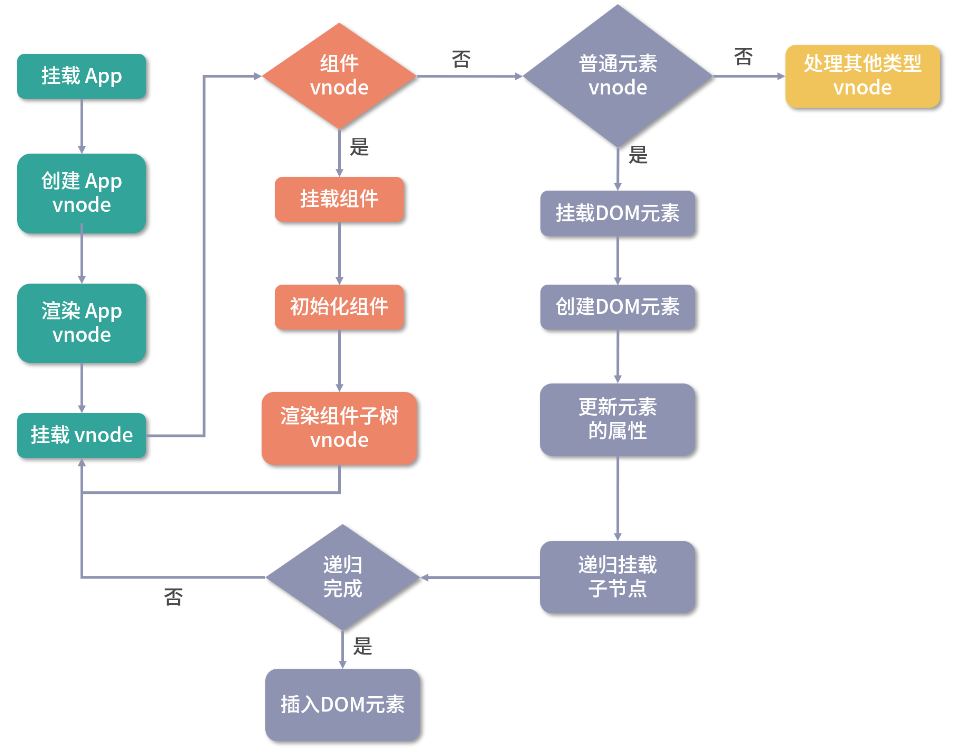
Webpack核心工作流程
背景
模块化的演进
随着互联网的深入发展,前端行业模块化的复杂度越来越高,导致我们在实现前端模块化的道路上不断受阻,但随着时间的推进,前端也出现了很多标准和工具来解决这些问题。以下是前端模块化的几个发展阶段:
- 文件划分方式
- 命名空间方式
- IIFE
- IIFE 依赖参数
- 前端模块化规范的出现
随着 JavaScript 的标准逐渐走向完善,现在我们前端模块化已经发展到非常成熟的地步了,而且对前端模块化规范的最佳实践方式也基本实现了统一。
- 在 Node.js 环境中,我们遵循 CommonJS 规范
- 在浏览器环境中,我们遵循 ES Modules 规范

CommonJS 是属于内置模块系统,我们在 Node.js 环境中使用的时候,就不会有环境支持问题,只需要按照标准使用 require 和 module 即可。但是对于 ES Modules 规范来说,兼容的情况会相对差一些。因为 ES Modules 是 ECMAScript 2015(ES6)中才定义的模块系统,是近几年才制定的标准,所以肯定会存在环境兼容的问题。在这个标准刚推出的时候,几乎所有主流的浏览器都不支持。但是随着 Webpack 等一系列打包工具的流行,这一规范才开始逐渐被普及。
经过发展,ES Modules 现在已经成为最主流的前端模块化标准。相比于 AMD 这种社区提出的开发规范,ES Modules 是在语言层面实现的模块化,因此它的标准更为完善也更为合理。现在,绝大多数浏览器都已经开始原生支持 ES Modules 特性了。所以如今,我们需要重点学习的是如何在不同的环境中去更好的使用 ES Modules。
模块打包工具的出现
随着模块化**的引入,前端的应用又会产生一些新的问题:
- ES Modules 模块系统的环境兼容问题。尽管现在主流浏览器的最新版本都支持这一特性,但是目前还无法保证用户的浏览器使用情况。所以我们还是需要解决兼容问题。
- 过多且零散的模块文件导致浏览器的频繁发送网络请求。模块化的方式划分出来的模块文件过多,前端应用运行在浏览器中,每一个文件都需要单独从服务器请求回来,影响前端应用的工作效率。
- 前端应用日益复杂,在前端应用开发过程中不仅仅只有 JavaScript 代码需要模块化,HTML 和 CSS 这些资源文件也会面临需要被模块化的问题。这些文件也都应该看作前端应用中的一个模块,只不过这些模块的种类和用途跟 JavaScript 不同。
所以我们需要模块化打包工具来帮我们解决上述的一些问题,一个好的模块打包工具需要具备以下基本功能:
-
需要具备编译代码的能力,将开发阶段编写的那些包含新特性的代码转换为能够兼容大多数环境的代码,解决环境兼容问题。
-
具备将散落的模块打包到一起的能力,解决浏览器频繁请求模块文件的问题。
我们只在开发阶段才需要模块化的文件划分,因为它能够帮我们更好地组织代码,到了实际运行阶段,这种划分就没有必要了。
-
具备支持不同种类的前端模块类型,可以将开发过程中涉及的样式、图片、字体等所有资源文件都作为模块使用,这样就能拥有一个统一的模块化方案。
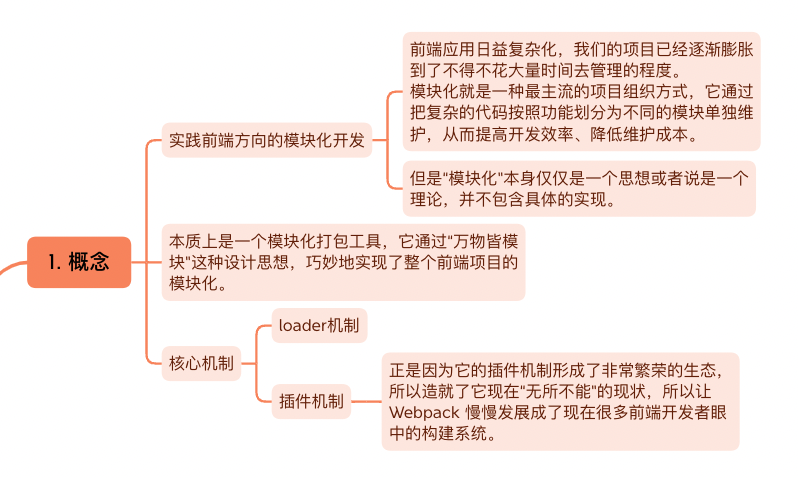
所以如今,Webpack 可以看作是现代化前端应用的模块化管理工具,Webpack 以模块化**为核心,帮助我们前端开发者更好的管理整个前端工程。
以下是其大致概念:
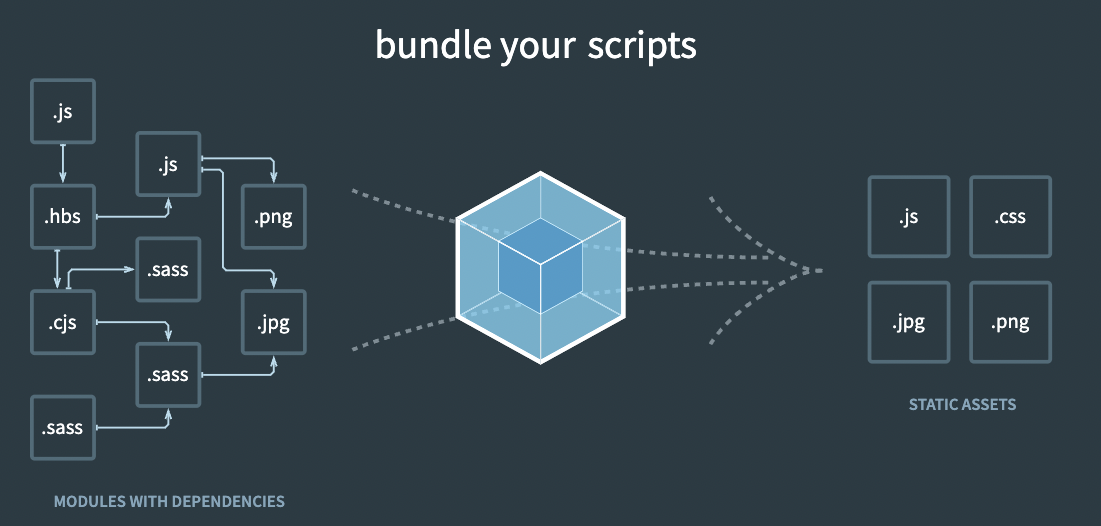
核心机制
Webpack 本质上是一个模块化打包工具,它通过“万物皆模块”这种设计**(从官方文档的图可以看出),巧妙地实现了整个前端项目的模块化。
Webpack 的核心机制就两个:loader和plugin。loader 负责完成项目中各种各样资源模块的加载,从而实现整体项目的模块化,作用范围在模块的加载环节。plugin 是用来解决项目中除了资源模块打包以外的其他自动化工作。plugin 的能力范围更广,用途也更多。借助插件,我们就可以轻松实现前端工程化中绝大多数经常用到的功能。plugin的作用范围在每一个环节,我们通过往不同钩子环节上挂载不同的任务,就可以扩展 Webpack 的能力。
核心工作流程
Webpack CLI 启动打包流程
源码在 [webpack-cli](https://github.com/webpack/webpack-cli) 模块中。为了增强 Webpack 本身的灵活性,所以 CLI 部分的代码从 Webpack 4 开始被单独抽出
webpack cli 的作用是将 CLI 参数和 Webpack 配置文件中的配置整合,得到一个完整的配置对象。
那么它是如何将配置整合的呢?
webpack cli 会通过 yargs 模块解析 CLI 参数,所谓 CLI 参数指的就是我们在运行 webpack 命令时通过命令行传入的参数,例如 --mode=production(如果出现重复的情况,会优先使用 CLI 参数)。
载入 Webpack 核心模块,创建 Compiler 对象
在 webpack cli 将配置项整合之后,我们会得到一个 options 配置项。
紧接着,我们会运行到 webpack 的核心模块,源码直接在 webpack 模块中。入口文件是 [lib/webpack.js](https://github.com/webpack/webpack/blob/v4.43.0/lib/webpack.js)。
这里我们首先会校验 webpack cli 传递过来的 options 参数是否符合要求,紧接着判断 options 的类型。这里传入的 options 不仅仅可以是一个对象,还可以是一个数组。
接下来我们通过传递的 options 配置项,来创建一个 Compiler 对象。
这个 Compiler 对象是整个 Webpack 工作过程中最核心的对象,负责完成整个项目的构建工作。
如果我们传入的 options 是一个数组,那么 Webpack 内部创建的就是一个 MultiCompiler,也就是说 Webpack 这时会支持同时开启多路打包,配置数组中的每一个成员就是一个独立的 webpack 配置选项:
compiler = new MultiCompiler(
Array.from(options).map(option => webpack(option))
)如果我们传入的是一个普通的对象,就会按照我们最熟悉的方式创建一个 Compiler 对象,进行单线打包:
compiler = webpack(options)创建了 Compiler 对象过后,Webpack 开始注册我们 options 配置中的每一个插件。接下来 Webpack 工作过程的生命周期就要开始了,所以必须在这里将插件先注册,这样才能确保插件中的每一个钩子都能被命中。
Webpack 注册插件的方式如下:
// 注册已配置的插件
if (options.plugins && Array.isArray(options.plugins)) {
for (const plugin of options.plugins) {
if (typeof plugin === 'function') {
plugin.call(compiler, compiler)
} else {
plugin.apply(compiler)
}
}
}注册完插件后,会触发两个钩子:environment, afterEnvironment。
然后创建内置的插件(后面 make 阶段会用到):
compiler.options = new WebpackOptionsApply().process(options, compiler)使用 Compiler 对象开始编译整个项目
接下来 Webpack 会使用 Compiler 对象开始编译整个项目。
首先,会判断配置选项中是否启用了 watch 监视模式。如果是监视模式就调用 Compiler 对象的 watch 方法,以监视模式启动构建(这不属于我们关心的主线)。
如果不是监视模式,就调用 Compiler 对象的 run 方法,开始构建整个应用。
if (firstOptions.watch || options.watch) {
...
} else {
compiler.run((err, stats) => {
...
})
}这里是使用 compiler.run 方法进行构建,run 方法的具体文件在 webpack 模块下的 [lib/Compiler.js](https://github.com/webpack/webpack/blob/v4.43.0/lib/Compiler.js) 中。
run 方法中,会先触发 beforeRun 和 run 两个钩子,然后调用了当前对象的 this.compile 方法,真正开始编译整个项目(最关键的部分)。
this.compiler 方法内部主要创建了一个 Compilation 对象,也就是一次构建过程中的上下文对象,里面包含了这次构建中全部的资源和信息。创建完 Compilation 对象过后,会触发 make 钩子,进入整个构建过程最核心的 make 阶段。
从入口文件开始,解析模块依赖,形成依赖关系树
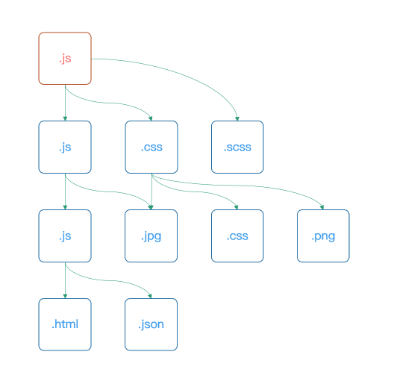
make 阶段会从入口文件开始,解析模块依赖,形成依赖关系树。然后将递归到的每个模块交给不同的 Loader 处理:
this.hooks.make.callAsync(compilation, err => {
if (err) return callback(err)
compilation.finish(err => { ... })
})make 阶段的调用过程比较特别。这个阶段并不会直接调用某个对象的某个方法,而是采用事件触发机制来触发执行的插件,所有之前监听了这个 make 事件的插件会在这时候开始执行。
Webpack 中有6个内置插件都监听了 make 事件。这些插件是前面创建 Compiler 对象的时候创建的。
我们默认使用的是单一入口打包的方式,所以这里最终会执行其中的 SingleEntryPlugin 插件。SingleEntryPlugin 插件中调用了 Compilation 对象的 addEntry 方法,开始解析我们源代码中的入口文件。addEntry 方法中又会调用 _addModuleChain 方法,将入口模块添加到模块依赖列表中,一层层的递进。
递归依赖树,将每个模块交给对应的 Loader 处理
上个步骤中,我们形成了依赖关系树,接下来 Webpack 会通过 Compilation 对象的 buildModule 方法进行模块构建,buildModule 方法中会执行具体的 Loader,处理特殊资源的加载。
build 完成过后,Webpack 通过 acorn 库生成模块代码的 AST 语法树。根据语法树分析这个模块是否还有依赖的模块,如果有则继续递归的循环 build 每一个依赖。
合并 Loader 处理完的结果,将打包结果输出到 dist 目录
到这里核心的流程基本已完成,所有的依赖解析完成,build 阶段结束。
最后 Webpack 会合并生成需要输出的 bundle.js 文件,并写入 dist 目录。
总结
以上就是 Webpack 运行的核心流程。Webpack 的源码比较复杂且繁多,如果直接阅读的话很难看懂,我们可以先理解核心流程,这些流程涉及到的源码文件都分散在 Webpack 的各个模块中,由此我们可以对单独的一个流程通过查阅对应源码的方式来深入理解 Webpack 的工作原理。
了解了核心流程的你,想必接下来会更有兴趣的去探讨其中的实现细节吧!
Vue3初步介绍及优化
Vue's core engine
Reactivity Module(响应式模块)
响应式模块允许我们创建 Javascript 响应对象,并可以观察其变化
Compiler Module(编译器模块)
获取 HTML 模版,并将他们编译成渲染函数,这会在运行时的浏览器中发生 ,浏览器只接收这些渲染函数来渲染页面
Renderer Module(渲染模块)
该模块包括三个阶段:
渲染阶段(render)
该阶段将调用 render 函数,它返回一个虚拟 DOM 节点
挂载阶段(mount)
使用虚拟 DOM 节点,并调用 DOM API 来创建网页
补丁阶段(patch)
渲染器将旧的虚拟节点和新的虚拟节点进行比较,并只更新网页变化的的部分
Vue3相较于Vue2的优化
源码优化
更好的代码管理方式:monorepo
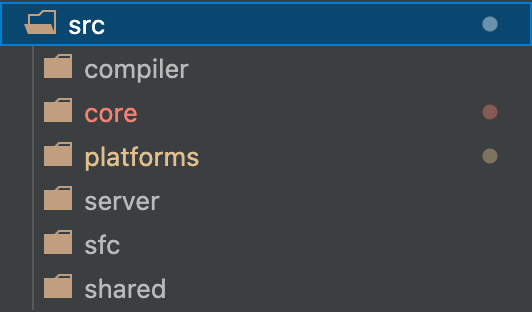
Vue.js 2.x 的源码托管在 src 目录,然后依据功能拆分出了 compiler(模板编译的相关代码)、core(与平台无关的通用运行时代码)、platforms(平台专有代码)、server(服务端渲染的相关代码)、sfc(.vue 单文件解析相关代码)、shared(共享工具代码) 等目录。
而到了 Vue.js 3.0 ,整个源码是通过 monorepo 的方式维护的,根据功能将不同的模块拆分到 packages 目录下面不同的子目录中。
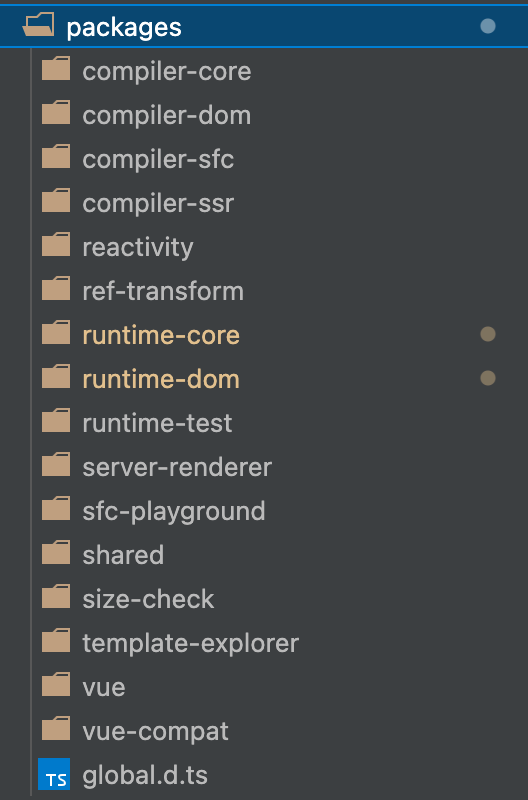
可以看出,相对于 Vue.js 2.x 的源码组织方式,monorepo 把这些模块拆分到不同的 package 中,每个 package 有各自的 API、类型定义和测试。这样使得模块拆分更细化,职责划分更明确,模块之间的依赖关系也更加明确,开发人员也更容易阅读、理解和更改所有模块源码,提高代码的可维护性。
另外,一些 package(比如 reactivity 响应式库)是可以独立于 Vue.js 使用的,这样用户如果只想使用 Vue.js 3.0 的响应式能力,可以单独依赖这个响应式库而不用去依赖整个 Vue.js,减小了引用包的体积大小,而 Vue.js 2 .x 是做不到这一点的。
使用Typescript
使用 TypeScript 重构了整个项目,提供了更好的类型检查,能支持复杂的类型推导。
性能优化
源码体积优化
- 首先,移除一些冷门的 feature(比如 filter、inline-template 等)
- 其次,引入 tree-shaking 的技术,减少打包体积。
数据劫持优化
我们都知道,Vue.js 2.x 内部都是通过 Object.defineProperty 这个 API 去劫持数据的 getter 和 setter:
Object.defineProperty(data, 'a',{
get(){
// track
},
set(){
// trigger
}
})这会带来一些问题:
- 它必须预先知道要拦截的 key 是什么,所以它并不能检测对象属性的添加和删除
- 对于一个嵌套层级较深的对象,如果要劫持它内部深层次的对象变化,就需要递归遍历这个对象,执行 Object.defineProperty 把每一层对象数据都变成响应式的。毫无疑问,如果我们定义的响应式数据过于复杂,这就会有相当大的性能负担。
为了解决上述 2 个问题,Vue.js 3.0 使用了 Proxy API 做数据劫持,它的内部是这样的:
observed = new Proxy(data, {
get() {
// track
},
set() {
// trigger
}
})由于它劫持的是整个对象,那么自然对于对象的属性的增加和删除都能检测到。
但要注意的是,Proxy API 并不能监听到内部深层次的对象变化,因此 Vue.js 3.0 的处理方式是在 getter 中去递归响应式,这样的好处是真正访问到的内部对象才会变成响应式,而不是无脑递归,这样无疑也在很大程度上提升了性能。
编译优化
以下是 Vue.js 2.x 从 new Vue 开始渲染成 DOM 的流程
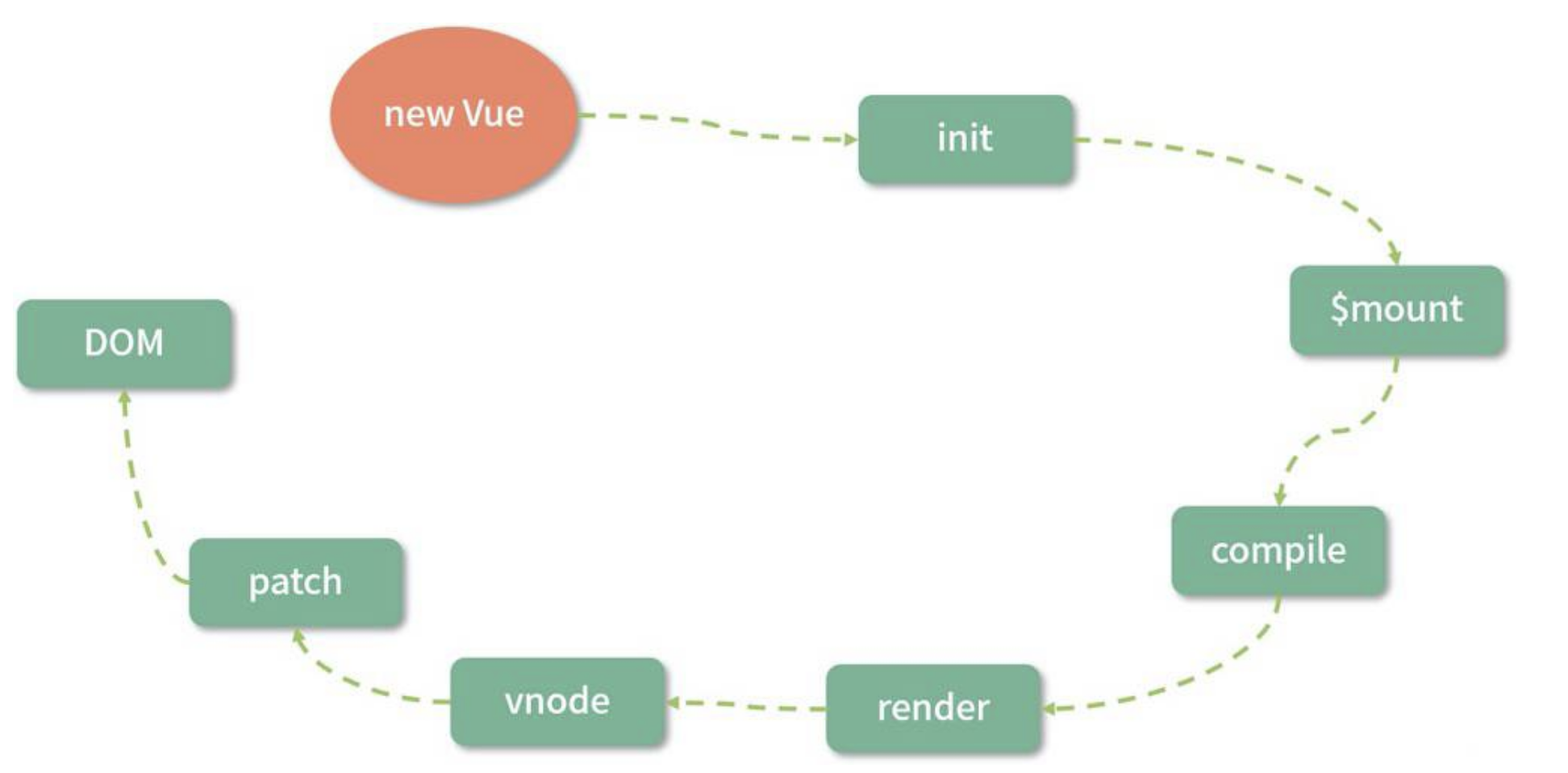
上面说过的响应式过程就发生在图中的 init 阶段,另外 template compile to render function 的流程是可以借助 vue-loader 在 webpack 编译阶段离线完成,并非一定要在运行时完成。
所以,在优化整个 Vue.js 的运行时,除了数据劫持部分的优化,Vue3 也在耗时相对较多的 patch 阶段想办法,并且它通过在编译阶段优化编译的结果,来实现运行时 patch 过程的优化。
例如我们要更新下面这个组件,我们就得先 diff div, 然后 diff props of div, diff children of div, diff p, diff props of p, diff children of p...
<template>
<div id="content">
<p class="text">static text</p>
<p class="text">static text</p>
<p class="text">{{message}}</p>
<p class="text">static text</p>
<p class="text">static text</p>
</div>
</template>可以看到,因为这段代码中只有一个动态节点,所以这里有很多 diff 和遍历其实都是不需要的,这就会导致 vnode 的性能跟模版大小正相关,跟动态节点的数量无关,当一些组件的整个模版内只有少量动态节点时,这些遍历都是性能的浪费。
整个 diff 过程如图所示:
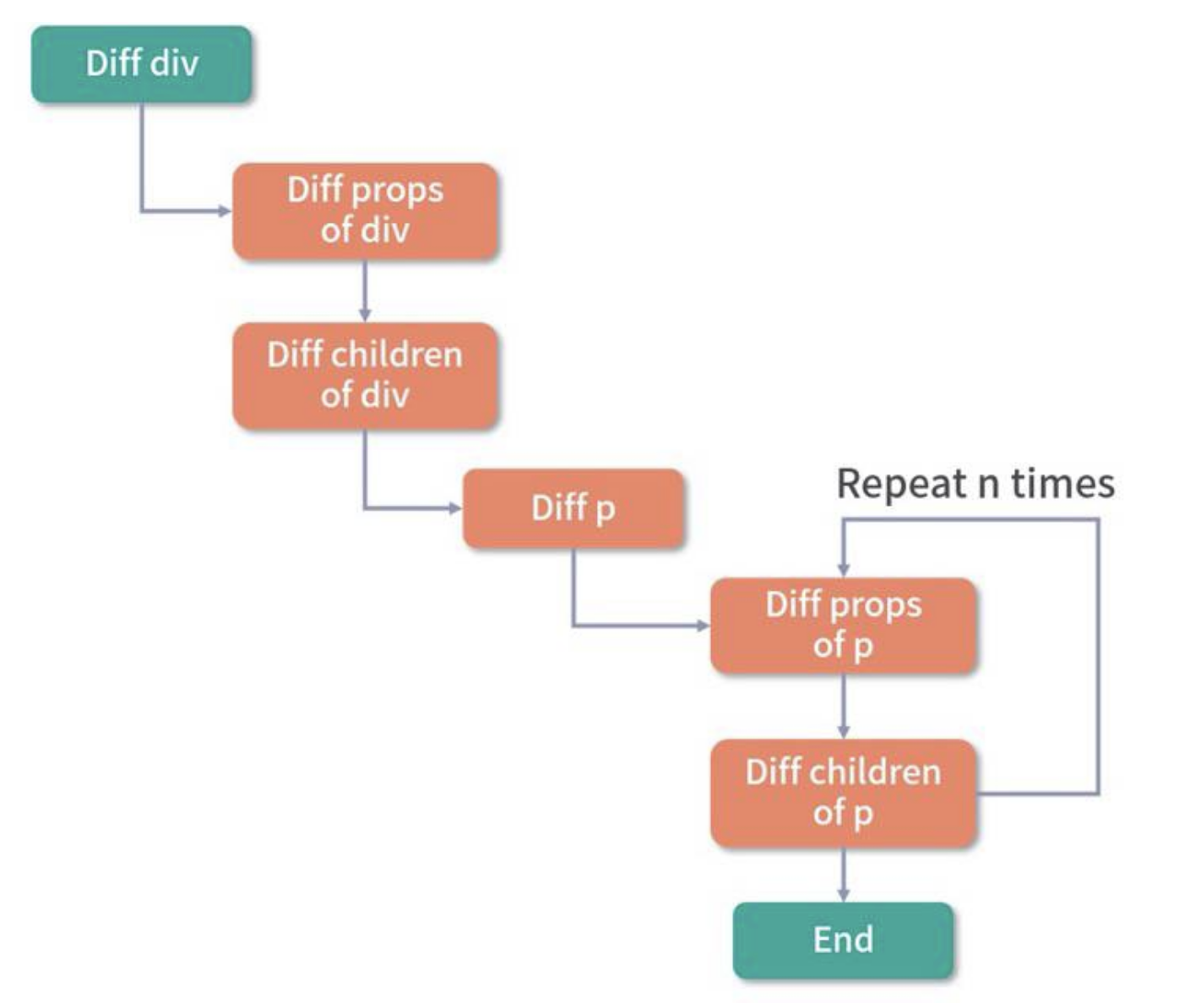
在 Vue3 中,它通过编译阶段对静态模板的分析,编译生成了 Block tree。Block tree 是一个将模版基于动态节点指令切割的嵌套区块,每个区块内部的节点结构是固定的,而且每个区块只需要以一个 Array 来追踪自身包含的动态节点。借助 Block tree,Vue3 将 vnode 更新性能由与模版整体大小相关提升为与动态内容的数量相关,这是一个非常大的性能突破。
语法 API 优化:Composition API
Composition API 可以优化我们写代码的逻辑组织。Vue2中是按照 methods、computed、data、props 这些不同的选项分类,在大型组件中,这些逻辑关注点是非常分散的。而在Vue3中,将某个逻辑关注点相关的代码全都放在一个函数里了,这样当需要修改一个功能时,就不再需要在文件中跳来跳去。
Composition API 还可以优化我们代码的逻辑复用。
在 Vue2 中,我们通常会用 mixins 去复用逻辑,当我们一个组件混入大量不同的 mixins 的时候,会存在两个非常明显的问题:命名冲突和数据来源不清晰。
Vue3 设计的 Composition API,就很好地解决了 mixins 的这两个问题。
一个典型的例子:
// mouse.ts
import { ref, onMounted, onUnmounted } from 'vue'
export default function useMousePosition() {
const x = ref(0)
const y = ref(0)
const update = e => {
x.value = e.pageX
y.value = e.pageY
}
onMounted(() => {
window.addEventListener('mousemove', update)
})
onUnmounted(() => {
window.removeEventListener('mousemove', update)
})
return { x, y }
}上面我们约定了 useMousePosition 这个函数为 hook 函数,然后在组件中使用:
<template>
<div>
Mouse position: x {{ x }} / y {{ y }}
</div>
</template>
<script>
import useMousePosition from './mouse'
export default {
setup() {
const { x, y } = useMousePosition()
return { x, y }
}
}
</script>可以看到,整个数据来源清晰了,即使去编写更多的 hook 函数,也不会出现命名冲突的问题。
Composition API 除了在逻辑复用方面有优势,也会有更好的类型支持,因为它们都是一些函数,在调用函数时,自然所有的类型就被推导出来了,不像 Options API 所有的东西使用 this。另外,Composition API 对 tree-shaking 友好,代码也更容易压缩。
但是,Composition API 属于 API 的增强,它并不是 Vue3 组件开发的唯一方式,如果你的组件足够简单,你还是可以使用 Vue2 的 Options API
Event Loop
异步
提起异步,相信每个人都知道,异步背后的“靠山”就是event loops。这里的异步准确的说应该叫浏览器的event loops或者说是javaScript运行环境的event loops,因为ECMAScript中没有event loops,event loops是在HTML Standard定义的。event loops规范中定义了浏览器何时进行渲染更新,了解它有助于性能优化。
首先看一个例子,思考例子中代码的执行顺序:
console.log('start')
setTimeout( function () {
console.log('setTimeout')
}, 0 )
Promise.resolve().then(function() {
console.log('promise1')
}).then(function() {
console.log('promise2')
})
console.log('end')
// start
// end
// promise1
// promise2
// setTimeout上面的顺序是在chrome运行得出的,而在safari 9.1.2中测试时,promise1 promise2会在setTimeout的后面执行,但是在safari 10.0.1中得到了和chrome一样的结果。为何浏览器有不同的表现,了解tasks, microtasks队列就可以解答这个问题。
event loop 的定义
event loop翻译出来就是事件循环,可以理解为实现异步的一种方式。我们看看event loop在HTML Standard中的定义章节:
为了协调事件,用户交互,脚本,渲染,网络等,用户代理必须使用本节所述的
event loop。
事件,用户交互,脚本,渲染,网络这些都是我们所熟悉的东西,他们都是由event loop协调的。触发一个click事件,进行一次ajax请求,背后都有event loop在运作。
知道了event loops的大致定义,我们再深入了解下event loops。
有两种event loops,一种在浏览器上下文,一种在Web Workers中。
每一个用户代理必须至少有一个浏览器上下文event loop,但是每个单元的相似源浏览器上下文至多有一个event loop。
event loop 总是具有至少一个浏览器上下文,当一个event loop的浏览器上下文全都销毁的时候,event loop也会销毁。一个浏览器上下文总有一个event loop去协调它的活动。
Web Workers的event loop相对简单一些,一个worker对应一个event loop,worker进程模型管理event loop的生命周期。
这里反复提到的一个词是browsing contexts(浏览器上下文)。
浏览器上下文是一个将 Document 对象呈现给用户的环境。在一个 Web 浏览器内,一个标签页或窗口常包含一个浏览上下文,如一个 iframe 或一个 frameset 内的若干 frame。
对于这些资料阐述的event loop做个总结:
- 每个线程都有自己的
event loop。 - 浏览器可以有多个
event loop,browsing contexts和web workers就是相互独立的。 - 所有同源的
browsing contexts可以共用event loop,这样它们之间就可以相互通信。
task
介绍:
一个event loop有一个或者多个task队列。
当用户代理安排一个任务,必须将该任务增加到相应的event loop的一个tsak队列中。
每一个task都来源于指定的任务源,比如可以为鼠标、键盘事件提供一个task队列,其他事件又是一个单独的队列。可以为鼠标、键盘事件分配更多的时间,保证交互的流畅。
task队列就是一个先进先出的队列,由指定的任务源去提供任务。
哪些是task任务源呢?
Generic task sources中有提及:
DOM操作任务源:
此任务源被用来响应dom操作,例如一个元素以非阻塞的方式插入文档。
用户交互任务源:
此任务源用于对用户交互作出反应,例如键盘或鼠标输入。响应用户操作的事件(例如click)必须使用task队列。
网络任务源:
网络任务源被用来响应网络活动。
history traversal任务源:
当调用history.back()等类似的api时,将任务插进task队列。
task任务源非常宽泛,比如ajax的onload,click事件,基本上我们经常绑定的各种事件都是task任务源,还有数据库操作(IndexedDB ),需要注意的是setTimeout、setInterval、setImmediate也是task任务源。总结来说task任务源:
- setTimeout
- setInterval
- setImmediate
- I/O
- UI rendering
microtask
介绍:
每一个event loop都有一个microtask队列,一个microtask会被排进microtask队列而不是task队列。
有两种microtasks:分别是solitary callback microtasks和compound microtasks。规范值只覆盖solitary callback microtasks。
如果在初期执行时,spin the event loop,microtasks有可能被移动到常规的task队列,在这种情况下,microtasks任务源会被task任务源所用。通常情况,task任务源和microtasks是不相关的。
microtask 队列和task 队列有些相似,都是先进先出的队列,由指定的任务源去提供任务。
不同的是:一个event loop里只有一个microtask 队列。
HTML Standard没有具体指明哪些是microtask任务源,通常认为是microtask任务源有:
- process.nextTick
- promises
- Object.observe
- MutationObserver
NOTES:
-
Promise的定义在 ECMAScript规范而不是在HTML规范中,但是ECMAScript规范中有一个jobs的概念和microtasks很相似。在Promises/A+规范的Notes 3.1中提及了promise的then方法可以采用“宏任务(macro-task)”机制或者“微任务(micro-task)”机制来实现。所以开头提及的promise在不同浏览器的差异正源于此。
-
有的浏览器将
then放入了macro-task队列,有的放入了micro-task 队列。一个普遍的共识是promises属于microtasks队列。比如一篇博文Tasks, microtasks, queues and schedules中提及了一个讨论vague mailing list discussions。
event loop的处理过程(Processing model)
在HTML Standard的Processing model中定义了event loop的循环过程:
一个event loop只要存在,就会不断执行下边的步骤:
1.在tasks队列中选择最老的一个task,用户代理可以选择任何task队列,如果没有可选的任务,则跳到下边的microtasks步骤。
2.将上边选择的task设置为正在运行的task。
3.Run: 运行被选择的task。
4.将event loop的currently running task变为null。
5.从task队列里移除前边运行的task。
6.Microtasks: 执行microtasks任务检查点。(也就是执行microtasks队列里的任务)
7.更新渲染(Update the rendering)...
8.如果这是一个worker event loop,但是没有任务在task队列中,并且WorkerGlobalScope对象的closing标识为true,则销毁event loop,中止这些步骤,然后进行定义在Web workers章节的run a worker。
9.返回到第一步。
event loop会不断循环上面的步骤,概括说来:
event loop会不断循环的去取tasks队列的中最老的一个任务推入栈中执行,并在当次循环里依次执行并清空microtask队列里的任务。- 执行完
microtask队列里的任务,有可能会渲染更新。(浏览器很聪明,在一帧以内的多次dom变动浏览器不会立即响应,而是会积攒变动以最高60HZ的频率更新视图)
在当次循环里依次执行并清空microtask队列里的任务,这句话所带来的现象就是:先会执行最外层task(script),然后将script里面的任务都推入栈,这些任务里,Microtasks 会先执行,task 后执行。
microtask的检查点(microtask checkpoint)
event loop运行的第6步,执行了一个microtask checkpoint,下面是HTML Standard描述的microtask checkpoint:
当用户代理去执行一个microtask checkpoint,如果microtask checkpoint的flag(标识)为false,用户代理必须运行下面的步骤:
1.将microtask checkpoint的flag设为true。
2.Microtask queue handling: 如果event loop的microtask队列为空,直接跳到第八步(Done)。
3.在microtask队列中选择最老的一个任务。
4.将上一步选择的任务设为event loop的currently running task。
5.运行选择的任务。
6.将event loop的currently running task变为null。
7.将前面运行的microtask从microtask队列中删除,然后返回到第二步(Microtask queue handling)。
8.Done: 每一个environment settings object它们的 responsible event loop就是当前的event loop,会给environment settings object发一个 rejected promises 的通知。
9.清理IndexedDB的事务。
10.将microtask checkpoint的flag设为flase。
由此可得,microtask checkpoint所做的就是执行microtask队列里的任务。那什么时候会调用microtask checkpoint呢?
- 当上下文执行栈为空时,执行一个microtask checkpoint。
- 在event loop的第六步(Microtasks: Perform a microtask checkpoint)执行checkpoint,也就是在运行task之后,更新渲染之前。
执行栈(JavaScript execution context stack)
task和microtask都是推入栈中执行的。
javaScript是单线程,也就是说只有一个主线程,主线程有一个栈,每一个函数执行的时候,都会生成新的execution context(执行上下文),执行上下文会包含一些当前函数的参数、局部变量之类的信息,它会被推入栈中, running execution context(正在执行的上下文)始终处于栈的顶部。当函数执行完后,它的执行上下文会从栈弹出。

完整异步过程
规范晦涩难懂,做一个形象的比喻:
主线程类似一个加工厂,它只有一条流水线,待执行的任务就是流水线上的原料,只有前一个加工完,后一个才能进行。event loops就是把原料放上流水线的工人。只要已经放在流水线上的,它们会被依次处理,称为同步任务。一些待处理的原料,工人会按照它们的种类排序,在适当的时机放上流水线,这些称为异步任务。
过程图:
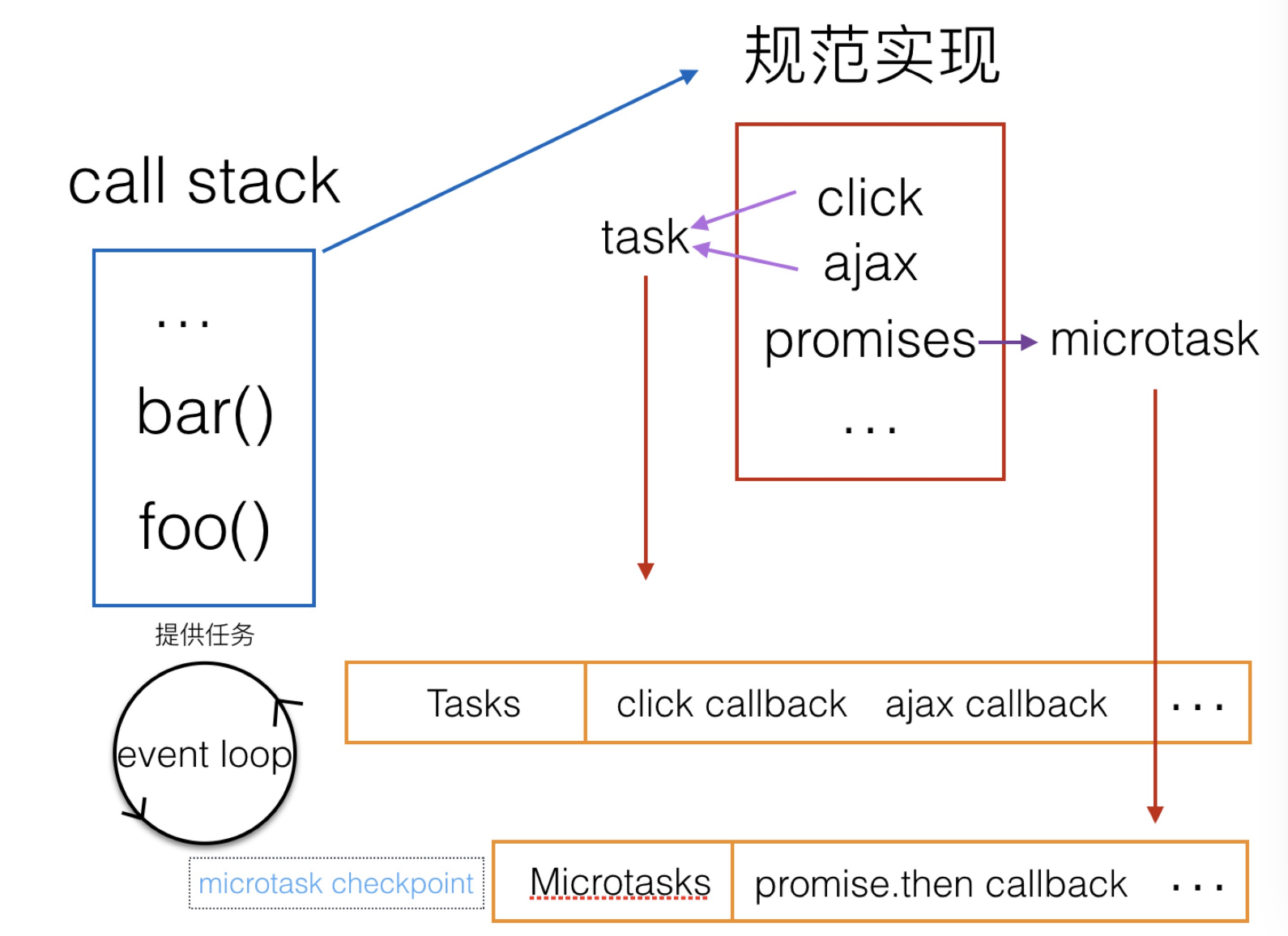
举个简单的例子,假设一个script标签的代码如下:
Promise.resolve().then(function promise1 () {
console.log('promise1');
})
setTimeout(function setTimeout1 (){
console.log('setTimeout1')
Promise.resolve().then(function promise2 () {
console.log('promise2');
})
}, 0)
setTimeout(function setTimeout2 (){
console.log('setTimeout2')
}, 0)运行过程:
首先script里的代码被列为一个task,放入task队列。
循环1:
- 【task队列:script ;microtask队列:】
- 从task队列中取出script任务,推入栈中执行。
- promise1列为microtask,setTimeout1列为task,setTimeout2列为task。
- 【task队列:setTimeout1 setTimeout2;microtask队列:promise1】
- script任务执行完毕,执行microtask checkpoint,取出microtask队列的promise1执行。
循环2:
- 【task队列:setTimeout1 setTimeout2;microtask队列:】
- 从task队列中取出setTimeout1,推入栈中执行,将promise2列为microtask。
- 【task队列:setTimeout2;microtask队列:promise2】
- 执行microtask checkpoint,取出microtask队列的promise2执行。
循环3:
- 【task队列:setTimeout2;microtask队列:】
- 从task队列中取出setTimeout2,推入栈中执行。
- setTimeout2任务执行完毕,执行microtask checkpoint。
- 【task队列:;microtask队列:】
event loop中的Update the rendering(更新渲染)
渲染的基本流程:
- 处理 HTML 标记并构建 DOM 树。
- 处理 CSS 标记并构建 CSSOM 树, 将 DOM 与 CSSOM 合并成一个渲染树。
- 根据渲染树来布局,以计算每个节点的几何信息。
- 将各个节点绘制到屏幕上
Note: 可以看到渲染树的一个重要组成部分是CSSOM树,绘制会等待css样式全部加载完成才进行,所以css样式加载的快慢是首屏呈现快慢的关键点。
更新渲染(Update the rendering)的时机:
- 在一轮event loop中多次修改同一dom,只有最后一次会进行绘制。
- 渲染更新(Update the rendering)会在event loop中的tasks和microtasks完成后进行,但并不是每轮event loop都会更新渲染,这取决于是否修改了dom和浏览器觉得是否有必要在此时立即将新状态呈现给用户。如果在一帧的时间内(时间并不确定,因为浏览器每秒的帧数总在波动,16.7ms只是估算并不准确)修改了多处dom,浏览器可能将变动积攒起来,只进行一次绘制,这是合理的。
- 如果希望在每轮event loop都即时呈现变动,可以使用requestAnimationFrame。
应用
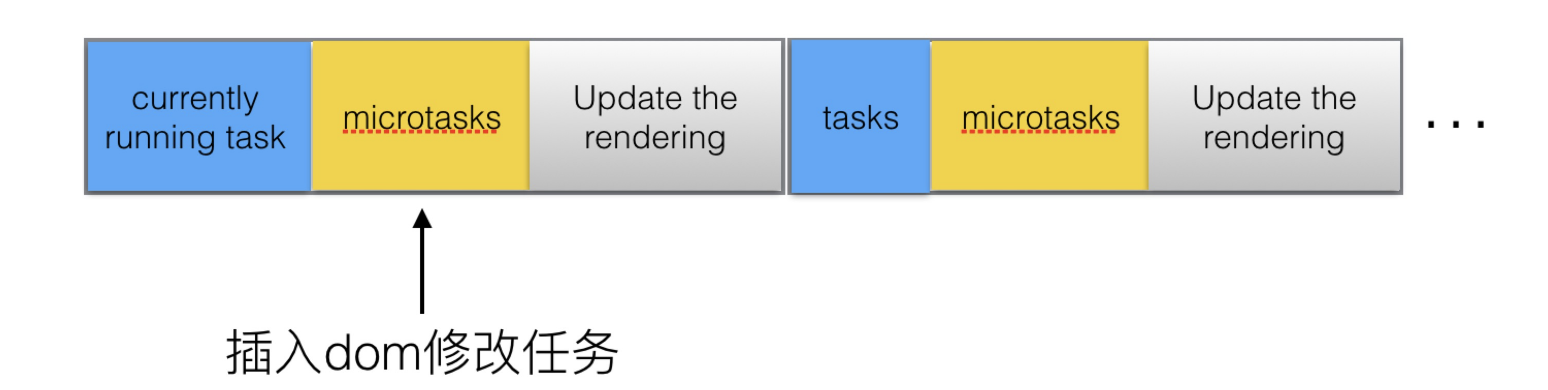
event loop的大致循环过程,可以用下边的图表示:
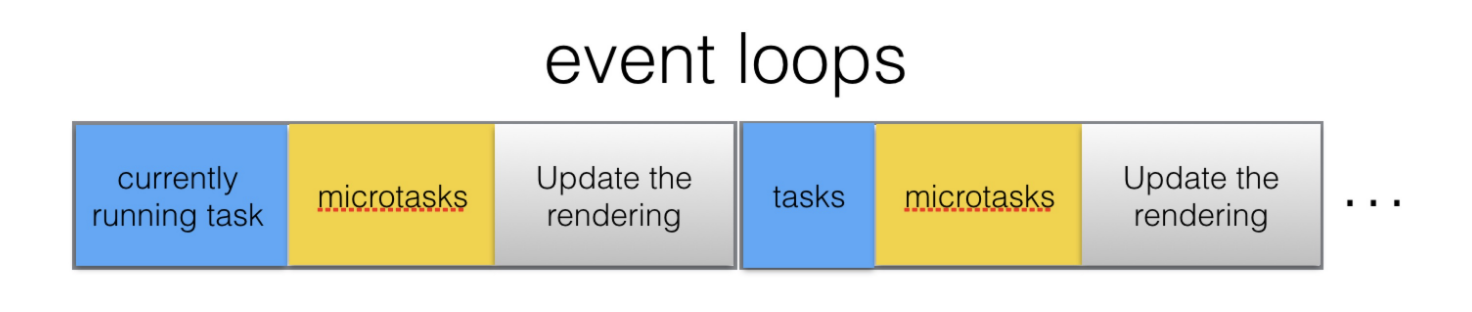
假设现在执行到currently running task,我们对批量的dom进行异步修改,我们将此任务插进task:
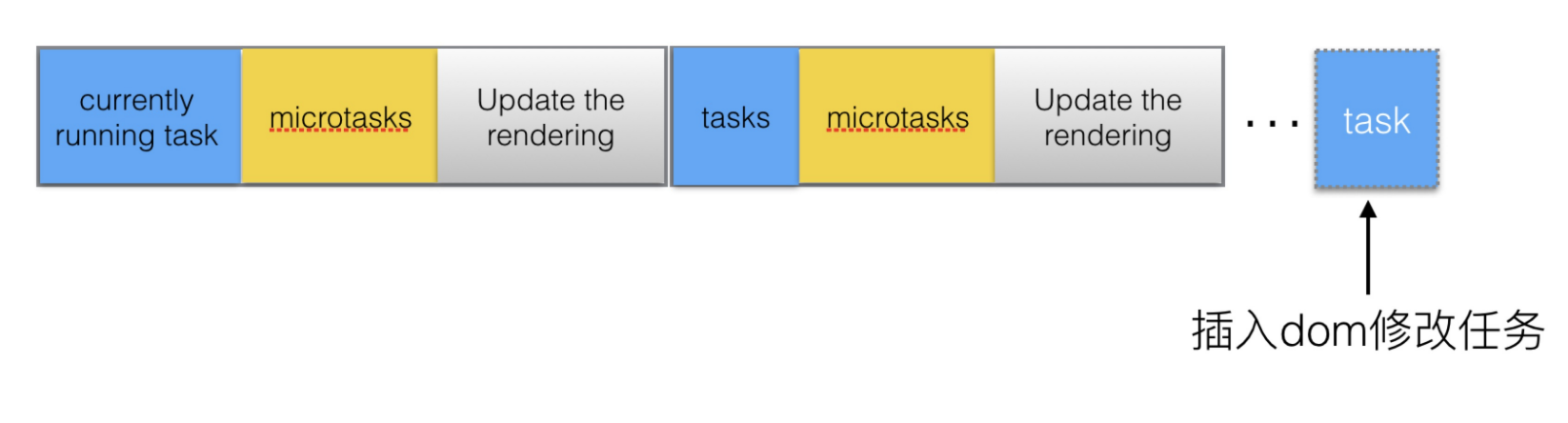
此任务插进microtasks:
可以看到如果task队列如果有大量的任务等待执行时,将dom的变动作为microtasks而不是task能更快的将变化呈现给用户。
同步简简单单就可以完成了,为啥要异步去做这些事?
对于一些简单的场景,同步完全可以胜任,如果得对dom反复修改或者进行大量计算时,使用异步可以作为缓冲,优化性能。
例子:
<div id='result'>this is result</div>有一个计算平方的函数,并且会将结果响应到对应的元素
function bar (num, id) {
const product = num * num
const resultEle = document.getElementById( id )
resultEle.textContent = product
}现在我们制造些问题,假设现在很多同步函数引用了bar,在一轮event loop里,可能bar会被调用多次,并且其中有几个是对id='result'的元素进行操作。就像下边一样:
...
bar( 2, 'result' )
...
bar( 4, 'result' )
...
bar( 5, 'result' )
...似乎这样的问题也不大,但是当计算变得复杂,操作很多dom的时候,这个问题就不容忽视了。
用我们上边讲的event loop知识,修改一下bar:
const store = {}
let flag = false
function bar (num, id) {
store[id] = num
if(!flag){
Promise.resolve().then(function () {
for(let k in store){
const num = store[k]
const product = num * num
const resultEle = document.getElementById(k)
resultEle.textContent = product
}
})
flag = true
}
}现在我们用一个store去存储参数,统一在microtasks阶段执行,过滤了多余的计算,即使同步过程中多次对一个元素修改,也只会响应最后一次。
参考文章
https://html.spec.whatwg.org/multipage/webappapis.html#event-loop
原型与原型链
prototype
每个函数都有一个 prototype 属性(prototype是函数才会有的属性),比如:
function Person(name) {
this.name = name
}
Person.prototype.name = 'Coran'
const person1 = new Person()
const person2 = new Person()
console.log(person1.name) // Coran
console.log(person2.name) // Coran函数的 prototype 属性指向了一个对象,这个对象正是调用该构造函数而创建的实例的原型,Person.prototype 也就是这个例子中的 person1 和 person2 的原型。
什么是原型?
你可以这样理解:每一个JavaScript对象(null除外)在创建的时候就会与之关联另一个对象,这个对象就是我们所说的原型,每一个对象都会从原型"继承"属性
Person(构造函数) => Person.prototype(实例原型)
这是构造函数与实例原型之间的关系
那么我们该怎么表示实例与实例原型,也就是 person 和 Person.prototype 之间的关系呢,这时候我们就要讲到第二个属性:__proto__
__proto__
__proto__是每一个JavaScript对象(除了null)都具有的一个属性,这个属性会指向该对象的原型。
function Person() {
}
const person = new Person()
console.log(person.__proto__ === Person.prototype) // true既然实例对象和构造函数都可以指向原型,那么原型是否有属性指向构造函数或者实例呢?
原型指向实例的属性倒是没有,因为一个构造函数可以生成多个实例。
原型指向构造函数的属性倒是有的,这就要讲到第三个属性:constructor。
constructor
每个原型都有一个 constructor 属性指向关联的构造函数。
function Person() {
}
console.log(Person === Person.prototype.constructor) // true实例与原型
当读取实例的属性时,如果找不到,就会查找与对象关联的原型中的属性,如果还查不到,就去找原型的原型,一直找到最顶层为止。
举个例子:
function Person() {
}
Person.prototype.name = 'Kevin'
let person = new Person()
person.name = 'Daisy'
console.log(person.name) // Daisy
delete person.name
console.log(person.name) // Kevin在这个例子中,我们给实例对象 person 添加了 name 属性,当我们打印 person.name 的时候,结果自然为 Daisy。
但是当我们删除了 person 的 name 属性时,读取 person.name,从 person 对象中找不到 name 属性就会从 person 的原型也就是 person.__proto__ ,也就是从 Person.prototype 中查找,幸运的是我们找到了 name 属性,结果为 Kevin。
但是万一还没有找到呢?原型的原型又是什么呢?
原型的原型
在前面,我们已经讲了原型也是一个对象,既然是对象,我们就可以用最原始的方式创建它,那就是:
let obj = new Object()
obj.name = 'Coran'
console.log(obj.name) // Coran其实这个原型对象就是通过 Object 构造函数生成的,结合之前所讲,实例的 __proto__ 指向构造函数的 prototype。
那 Object.prototype 的原型呢?
Object.prototype 的原型是 null
console.log(Object.prototype.__proto__ === null) // truenull 表示“没有对象”,即该处不应该有值。
所以 Object.prototype.__proto__ 的值为 null 跟 Object.prototype 没有原型,其实表达了一个意思。
所以查找属性的时候查到 Object.prototype 就可以停止查找了。
原型链
下图中由相互关联的原型组成的链状结构就是原型链,也就是蓝色的这条线。(可以理解为原型链通过__proto__ 链接起来)
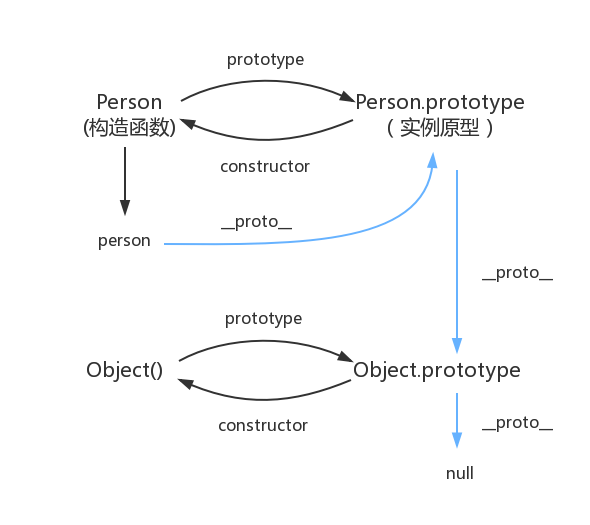
即,函数的 prototype 属性指向原型,原型链通过 __proto__ 链接起来
补充
constructor
看个例子:
function Person() {
}
const person = new Person()
console.log(person.constructor === Person) // true当获取 person.constructor 时,其实 person 中并没有 constructor 属性,当不能读取到 constructor 属性时,会从 person 的原型也就是 Person.prototype 中读取,正好原型中有该属性,所以:
person.constructor === Person.prototype.constructor === Person__proto__
关于 __proto__,绝大部分浏览器都支持这个非标准的方法访问原型,然而它并不存在于 Person.prototype 中。
实际上,它是来自于 Object.prototype ,与其说是一个属性,不如说是一个 getter/setter。
当使用 obj.__proto__ 时,可以理解成返回了 Object.getPrototypeOf(obj)。
关于继承
关于继承,前面我们讲到“每一个对象都会从原型‘继承’属性”,实际上,继承是一个十分具有迷惑性的说法,引用《你不知道的JavaScript》中的话,就是:
继承意味着复制操作,然而 JavaScript 默认并不会复制对象的属性,相反,JavaScript 只是在两个对象之间创建一个关联,这样,一个对象就可以通过委托访问另一个对象的属性和函数,所以与其叫继承,委托的说法反而更准确些。
定时器工作机制
从根本上讲,了解 JavaScript 计时器的工作原理很重要。很多时候,它们的行为不直观,因为它们处于单线程中。
定时器函数
我们首先看看我们可以访问的三个构造和操作计时器的函数。
-
var id = setTimeout(fn, delay)启动一个定时器,它将在延迟后调用指定的函数。该函数返回一个唯一的 ID,可以在以后取消计时器。
-
var id = setInterval(fn, delay)类似于 setTimeout,但该函数会不断的被调用(每次都有延迟)直到它被取消。
-
clearInterval(id),clearTimeout(id)接受计时器 ID(由上述任一函数返回)并停止发生计时器回调。
定时器内部如何工作
为了理解定时器内部如何工作,需要探索一个重要概念:定时器延迟的时间是不确定的。
由于浏览器中的所有 JavaScript 都在单个线程上执行,因此异步事件(例如鼠标单击和定时器)仅在执行进程中出现一个空位置时才运行。如下所示:
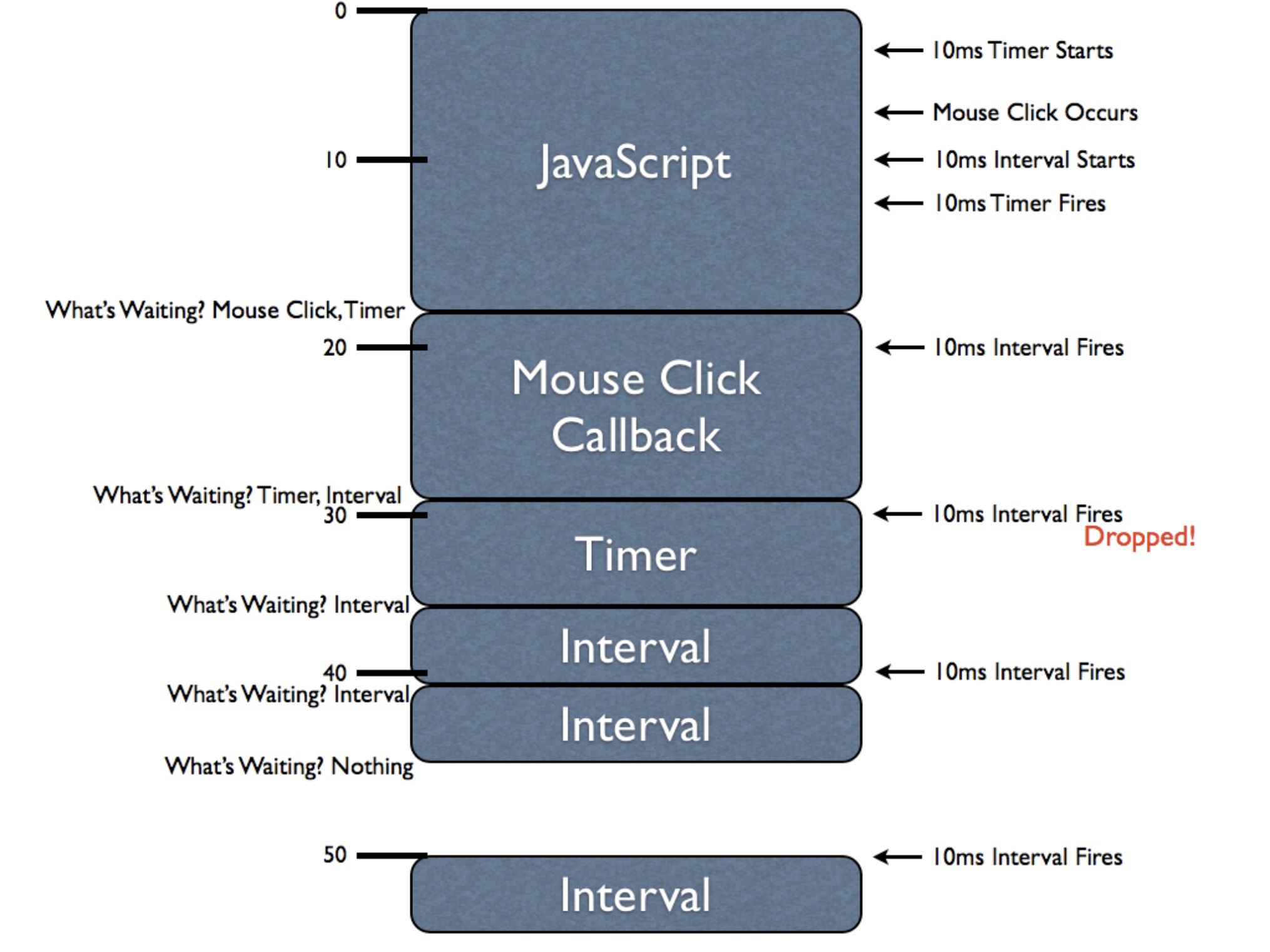
垂直方向表示时间,以毫秒为单位。蓝色框代表正在执行的 JavaScript 部分。例如,JavaScript 的第一个块执行大约 18 毫秒,鼠标单击块大约执行 11 毫秒,依此类推。
由于 JavaScript 一次只能执行一段代码(由于其单线程特性),因此这些代码块中的每一个都 阻塞 了其他异步事件的进程。这意味着当异步事件发生时(如鼠标点击、定时器触发或 XMLHttpRequest 完成),它会排队等待稍后执行(这种排队的实际发生方式肯定因浏览器而异,因此请考虑这一点)。
首先,在 JavaScript 的第一个块中,启动了两个定时器:一个 10mssetTimeout和一个 10ms setInterval。由于定时器启动的时间和地点,它实际上在我们完成第一个代码块之前触发。但是请注意,它不会立即执行(由于线程的原因,它无法执行此操作)。而是将延迟的回调函数排队以便在下一个可用时刻执行。
此外,在第一个 JavaScript 块中,我们看到鼠标单击发生。与此异步事件关联的 JavaScript 回调(我们永远不知道用户何时可以执行操作,因此被认为是异步的)无法立即执行,因此,与初始定时器一样,它会排队等待稍后执行。
在最初的 JavaScript 块执行完后,浏览器会立即问一个问题:等待执行的是什么?在这种情况下,鼠标单击处理程序和计时器回调都在等待。然后浏览器选择一个(鼠标点击回调)并立即执行它。计时器将等待下一个可能的时间,以便执行。
请注意,当鼠标单击处理程序正在执行时,第一个 interval 回调也执行。与定时器一样,interval 的回调会排队等待稍后执行。但是请注意,当 interval 再次触发时(当定时器处理程序正在执行时),这次处理程序执行被删除。如果在执行大块代码时将所有间隔回调排队,结果将是一堆间隔执行,它们之间没有延迟,完成后。相反,浏览器倾向于简单地等待,直到没有更多的间隔处理程序排队(对于有问题的间隔),然后再进行更多的排队。
事实上,我们可以看到,当第三个 interval 回调在 interval 本身正在执行时触发,就是这种情况。这向我们展示了一个重要的事实:Intervals 并不关心当前正在执行什么,它们会不分青红皂白地排队,即使这意味着会牺牲回调之间的时间。
最后,在第二个间隔回调执行完成后,我们可以看到 JavaScript 引擎没有任何东西可以执行。这意味着浏览器现在是等待新的异步事件发生。当间隔再次触发时,我们在 50ms 标记处得到这个。然而,这一次没有任何东西阻止它的执行,所以它会立即触发。
setTimeout 与 setInterval 的差异
让我们看一个例子,以更好地说明setTimeout和setInterval 之间的差异
setTimeout(function(){
/* Some long block of code... */
setTimeout(arguments.callee, 10)
}, 10)
setInterval(function(){
/* Some long block of code... */
}, 10)乍一看,这两段代码在功能上似乎是等效的,但实际上并非如此。值得注意的是,setTimeout代码在上一次回调执行后总是至少有 10 毫秒的延迟(它可能最终会更多,但绝不会更少),而setInterval无论最后一次回调何时执行,代码都会尝试每 10 毫秒执行一次回调。
总结
我们在这里学到了很多东西,让我们回顾一下:
- JavaScript 引擎只有一个线程,强制异步事件排队等待执行。
setTimeout并且setInterval在执行异步代码的方式上是非常不一样的。- 如果计时器被阻止立即执行,它将被延迟到下一个可能的执行点(这将比所需的延迟更长)。
- 如果间隔的执行时间足够长(长于指定的延迟),则它们可以无延迟地一个接一个的执行。
所有这些都是非常重要的知识。了解 JavaScript 引擎的工作原理,尤其是处理通常发生的大量异步事件时,可以为构建高级应用程序代码奠定良好的基础。
参考文章
继承
原型链继承
function Parent () {
this.name = 'kevin'
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child () {
}
Child.prototype = new Parent()
const child1 = new Child()
console.log(child1.getName()) // kevin存在两个问题:
-
引用类型的属性会被多个实例共享,举个例子:
function Parent () { this.names = ['kevin', 'daisy'] } function Child () { } Parent.prototype.getName = function () { console.log(this.name) } Child.prototype = new Parent() const child1 = new Child() const child2 = new Child() child1.names.push('yayu') console.log(child1.names) // ["kevin", "daisy", "yayu"] console.log(child2.names) // ["kevin", "daisy", "yayu"]
为什么会存在这种问题呢?
其实,
Child.prototype = new Parent()相当于const p1 = new Parent(); Child.prototype = p1,可以改写为下面代码:function Parent () { this.names = ['kevin', 'daisy'] } function Child () { } Parent.prototype.getName = function () { console.log(this.name) } const p1 = new Parent() Child.prototype = p1 const child1 = new Child() console.log(child1)
我们在控制台打印实例 child1:
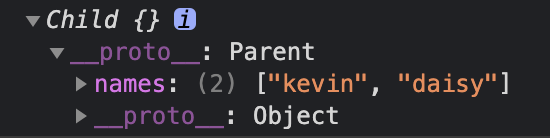
我们可以看到,
child1.__proto__ === p1,p1.__proto__ === Parent.prototype在原型与原型链一节中有讲到,函数的 prototype 属性指向了一个
对象,这个对象正是调用该构造函数而创建的实例的原型。所以这里 Parent.prototype 指向的也是一个对象,这个对象就是 p1 的原型。再展开来看:
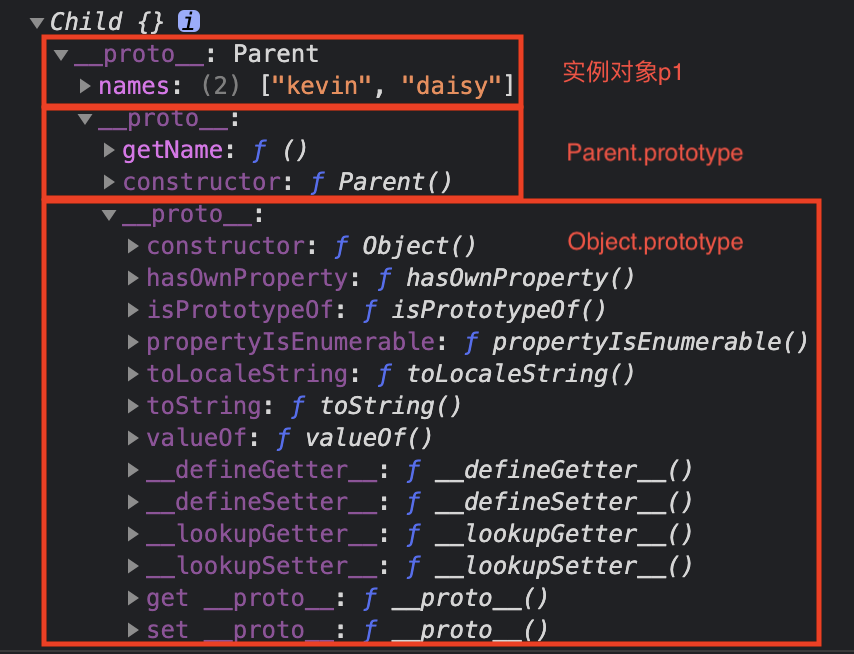
Parent.prototype.__proto__ === Object.prototype,p1 的原型的原型就是 Object.prototype 了。回到刚才的问题,即为什么会存在引用类型的属性被多个实例共享的呢?
因为这里实际上是
child1.__proto__ === p1,child1 继承的是 p1 这个对象,child1 继承的 names 属性也始终是 p1 对象中的那个 names(也就是继承的引用地址始终是同一个),所以其他实例 child2, child3 等等都会继承同一个 names。换种方式理解,使用 child1.names 时,在自身里找不到 names 这个属性,于是顺着原型链往上找,在 p1 对象中找到了 names 属性。使用 child2.names 时,在自身里找不到 names 这个属性,顺着原型链往上找也是在 p1 对象中找到了 names 属性,于是他们使用的是同一个 names 属性。
而如果是使用构造函数 new 出来的两个对象,它们里面的 names 属性的引用地址才会不同,如下:
function Parent () { this.names = ['kevin', 'daisy'] } const p1 = new Parent() const p2 = new Parent() p1.names.push('Coran') console.log(p1.names) // ['kevin', 'daisy', 'Coran'] console.log(p2.names) // ['kevin', 'daisy']
-
在创建 Child 的实例时,不能向 Parent 传参。
因为 Child 构造函数里面未使用
Parent.call(this, 参数)
借助构造函数实现继承
function Parent () {
this.names = ['kevin', 'daisy']
}
function Child () {
Parent.call(this)
}
const child1 = new Child()
const child2 = new Child()
child1.names.push('yayu')
console.log(child1.names) // ["kevin", "daisy", "yayu"]
console.log(child2.names) // ["kevin", "daisy"]优点:
-
避免了引用类型的属性被所有实例共享。
-
在创建 Child 的实例时,可以向 Parent 传参。
举个例子:
function Parent (name) { this.name = name } function Child (name) { Parent.call(this, name) } const child1 = new Child('kevin') const child2 = new Child('daisy') console.log(child1.name) // kevin console.log(child2.name) // daisy
缺点:
方法都需要在构造函数中定义,每次创建实例都会创建一遍方法。
因为,这种方式不能继承父类原型链上的属性,只能继承父类显式声明的属性。比如,通过
Parent.prototype.say给 Parent 新增一个 say 方法,那么 child1 不能继承。
组合继承
function Parent (name) {
this.name = name
this.colors = ['red', 'blue', 'green']
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child (name, age) {
Parent.call(this, name)
this.age = age
}
Child.prototype = new Parent()
Child.prototype.constructor = Child
const child1 = new Child('kevin', '18')
const child2 = new Child('daisy', '20')
child1.colors.push('black')
console.log(child1.name) // kevin
console.log(child1.age) // 18
console.log(child1.colors) // ["red", "blue", "green", "black"]
console.log(child2.name) // daisy
console.log(child2.age) // 20
console.log(child2.colors) // ["red", "blue", "green"]优点:融合了原型链继承和构造函数继承的优点,是 JavaScript 中最常用的继承模式。
使用 Parent.call(this) 解决了引用类型的属性被所有实例共享的问题
不过,为什么需要这一句呢?
Child.prototype.constructor = Child我们可以看上面原型链继承方式中的一个图片:
可以看到这里 child1 继承了对象 p1,但是 p1 中只有 __proto__,没有 constructor 属性来指向 Child 这个构造函数,那么这时如果打印 child1.constructor,那么在 child1 和 p1 中都找不到这个属性,就会到 Parent.prototype 中找,结果是找到了 Parent.prototype.constructor,也就是 Parent 构造函数,这显然是不对的。
child1 的构造函数应该是 Child 才对,所以我们需要在 p1 上增加一个 constructor 属性指向 Child,所以才有这一句 Child.prototype.constructor = Child。
我们再回过头来看原型与原型链一节中的原型链图解,上面的那句代码相当于添加了 Person.prototype.constructor === Person 这条链路,这时整个原型链才完整了:
寄生组合式继承
上面组合继承最大的缺点是会调用两次父构造函数。
一次是设置子类型实例的原型的时候:
Child.prototype = new Parent()一次在创建子类型实例的时候:
const child1 = new Child('kevin', '18')
// 这个时候执行了 Child 构造函数中的 Parent.call(this, name),所以在这里我们又调用了一次父构造函数所以,在这个例子中,如果我们打印 child1 对象,我们会发现 Child.prototype 和 child1 都有一个属性为colors,属性值为['red', 'blue', 'green']。且 Child.prototype 还有个 name 属性,为 undefined。
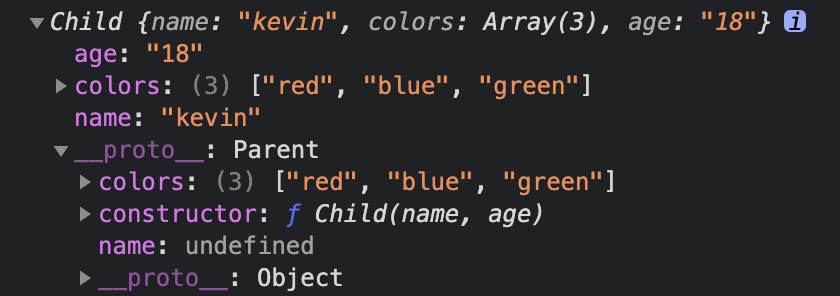
这些就是因为 Child.prototype = new Parent() 这句执行 new Parent() 时没传参数,所以会产生一个 colors 数组和一个未定义的 name 属性。
理论上 Child.prototype 上应该是没有这两个属性的,所以我们需要某种方法来避免 Child.prototype = new Parent() 这一句重复执行构造函数。
我们可以想想,Child.prototype = new Parent() 这一句的作用是什么呢?
换个角度来想,Parent.call(this)这句是能使我们继承显示声明的属性,但不能继承原型上的属性。所以 Child.prototype = new Parent() 这句的目的是能让我们继承原型上的属性,既然如此,我们可以换种方式实现这个目的,也就是间接的让 Child.prototype 访问到 Parent.prototype:
const F = function () {}
F.prototype = Parent.prototype
Child.prototype = new F()像上面这样写就可以间接的让 Child.prototype 访问到 Parent.prototype 了,由此我们还可以联想到 Object.create() 方法的模拟实现:
function createObj(o) {
function F () {}
F.prototype = o
return new F()
}将 Parent.prototype 传进去的话,就是:
function createObj(Parent.prorotype) {
function F () {}
F.prototype = Parent.prototype
return new F()
}所以我们可以借用 Object.create() 方法来简化一下,以下就是简化后的寄生组合式继承代码:
function Parent (name) {
this.name = name
this.colors = ['red', 'blue', 'green']
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child (name, age) {
Parent.call(this, name)
this.age = age
}
// 关键的三步
// var F = function () {}
// F.prototype = Parent.prototype
// Child.prototype = new F()
Child.prototype = Object.create(Parent.prototype)
Child.prototype.constructor = Child
const child1 = new Child('kevin', '18')
console.log(child1)最后打印出来的 child1 如图所示:
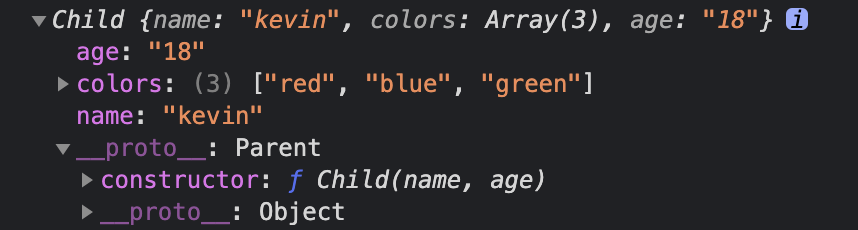
可见,Child.prorotype 中,已经没有了 name 和 colors 这两个属性,成功避免了重复执行两次父构造函数的问题。
引用《JavaScript高级程序设计》中对寄生组合式继承的夸赞就是:
这种方式的高效率体现它只调用了一次 Parent 构造函数,并且因此避免了在 Parent.prototype 上面创建不必要的、多余的属性。与此同时,原型链还能保持不变;因此,还能够正常使用 instanceof 和 isPrototypeOf。开发人员普遍认为寄生组合式继承是引用类型最理想的继承范式。
ES6 继承
class Parent {
constructor() {
this.name = 'Kevin'
}
}
class Child extends Parent {
constructor() {
super()
this.age = 13
}
}
const child1 = new Child()代码中:
- 类 Child 通过 extends 关键字继承类 Parent 的
原型对象上的属性 - 通过在类 Child 的 constructor 函数中执行 super() 函数,让类 Child 的实例继承类 Parent 的构造函数中定义的属性
super() 的作用类似构造函数中的 Parent.call(this),但它们是有区别的,下面会详述。
ES5继承与ES6继承的区别
我们以SubClass,SuperClass,instance为例
ES5中继承的实质是:(经典寄生组合式继承法)
- 先由子类(
SubClass)构造出实例对象this - 然后在子类的构造函数中,将父类(
SuperClass)的属性添加到this上,SuperClass.apply(this, arguments) - 子类原型(
SubClass.prototype)指向父类原型(SuperClass.prototype) - 所以
instance是子类(SubClass)构造出的(所以没有父类的[[Class]]关键标志) - 所以,
instance有SubClass和SuperClass的所有实例属性,以及可以通过原型链回溯,获取SubClass和SuperClass原型上的方法
ES6中继承的实质是:
- 先由父类(
SuperClass)构造出实例对象this,这也是为什么必须先调用父类的super()方法(子类没有自己的this对象,需先由父类构造) - 然后在子类的构造函数中,修改this(进行加工),譬如让它指向子类原型(
SubClass.prototype),这一步很关键,否则无法找到子类原型(注,子类构造中加工这一步的实际做法是推测出的,从最终效果来推测) - 然后同样,子类原型(
SubClass.prototype)指向父类原型(SuperClass.prototype) - 所以
instance是父类(SuperClass)构造出的(所以有着父类的[[Class]]关键标志) - 所以,
instance有SubClass和SuperClass的所有实例属性,以及可以通过原型链回溯,获取SubClass和SuperClass原型上的方法
所以,总的来说,ES5 与 ES6 继承的区别:
- 在 ES6 中类 Child 继承了类 Parent 的属性;在 ES5 中,构造函数 Child 没有继承构造函数 Parent 的属性。
- ES5 是先创建子类的实例对象 this,ES6 是先创建父类的实例对象 this。
ES6中在super中构建this的好处
因为 ES6 中允许我们继承内置的类,如 Date,Array,Error 等。
但如果 this 先被创建出来,再传给 Array 等系统内置类的构造函数,这些内置类的构造函数是不认这个 this 的。 所以需要先在 super 中构建出来,这样才能有着 super 中关键的[[Class]]标志,才能被允许调用。(否则就算继承了,也无法调用这些内置类的方法)
举个例子:
// ES5 继承
function MyArray() {
Array.call(this)
}
MyArray.prototype = Object.create(Array.prototype, {
constructor: { value: MyArray, writable: true, configurable: true }
})
// 相当于
// MyArray.prototype = Object.create(Array.prototype)
// MyArray.prototype.constructor = MyArray
const colors = new MyArray()
colors[0] = "red"
colors.length // 0
// 因为其无法获取 length 方法// ES6 继承
class MyArray extends Array {
constructor() {
super()
}
}
const arr = new MyArray()
arr[0] = 12
arr.length // 1
// 可以获取 length 方法设计模式原则与介绍
变与不变
能够决定一个前端工程师的本质的,不是那些瞬息万变的技术点,而是那些不变的东西。
什么是不变的东西?
所谓“不变的东西”,说的就是这种驾驭技术的能力。
具体来说,它分为以下三个层次:
- 能用健壮的代码去解决具体的问题;
- 能用抽象的思维去应对复杂的系统;
- 能用工程化的**去规划更大规模的业务。
很多人缺乏的并不是这种高瞻远瞩的激情,而是我们前面提到的“不变能力”中最基本的那一点——用健壮的代码去解决具体的问题的能力。这个能力在软件工程领域所对标的经典知识体系,恰恰就是设计模式。
所以说,想要提升开发能力,先掌握设计模式。
设计模式原则与**
设计模式不是一堆空空如也、晦涩鸡肋的理论,它是一套现成的工具 —— 就好像你想要做饭的时候,会拿起厨具直接烹饪,而不会自己去铸一口锅、磨一把菜刀一样。
当我们解数学题目的时候,往往会用到很多公式/现成的解题方法。比如已知直角三角形两边长,求另一边,我们会直接用勾股定理(没有人会每求一次边长都自己推一遍勾股定理)。
SOLID设计原则
设计原则是设计模式的指导理论,它可以帮助我们规避不良的软件设计。SOLID 指代的五个基本原则分别是:
- 单一功能原则(Single Responsibility Principle)
- 开放封闭原则(Opened Closed Principle)
- 里式替换原则(Liskov Substitution Principle)
- 接口隔离原则(Interface Segregation Principle)
- 依赖反转原则(Dependency Inversion Principle)
在 JavaScript 设计模式中,主要用到的设计模式基本都围绕**“单一功能”和“开放封闭”**这两个原则来展开。
核心**--封装变化
设计模式出现的背景,是软件设计的复杂度日益飙升。软件设计越来越复杂的“罪魁祸首”,就是变化。
如果说我们写一个业务,这个业务是一潭死水,初始版本是 1.0,100 年后还是 1.0,不接受任何迭代和优化,那么这个业务几乎可以随便写。反正只要实现功能就行了,完全不需要考虑可维护性、可扩展性。但在实际开发中,不发生变化的代码可以说是不存在的。我们能做的只有将这个变化造成的影响最小化 —— 将变与不变分离,确保变化的部分灵活、不变的部分稳定。
这个过程,就叫**“封装变化”**;这样的代码,就是我们所谓的“健壮”的代码,它可以经得起变化的考验。而设计模式出现的意义,就是帮我们写出这样的代码。
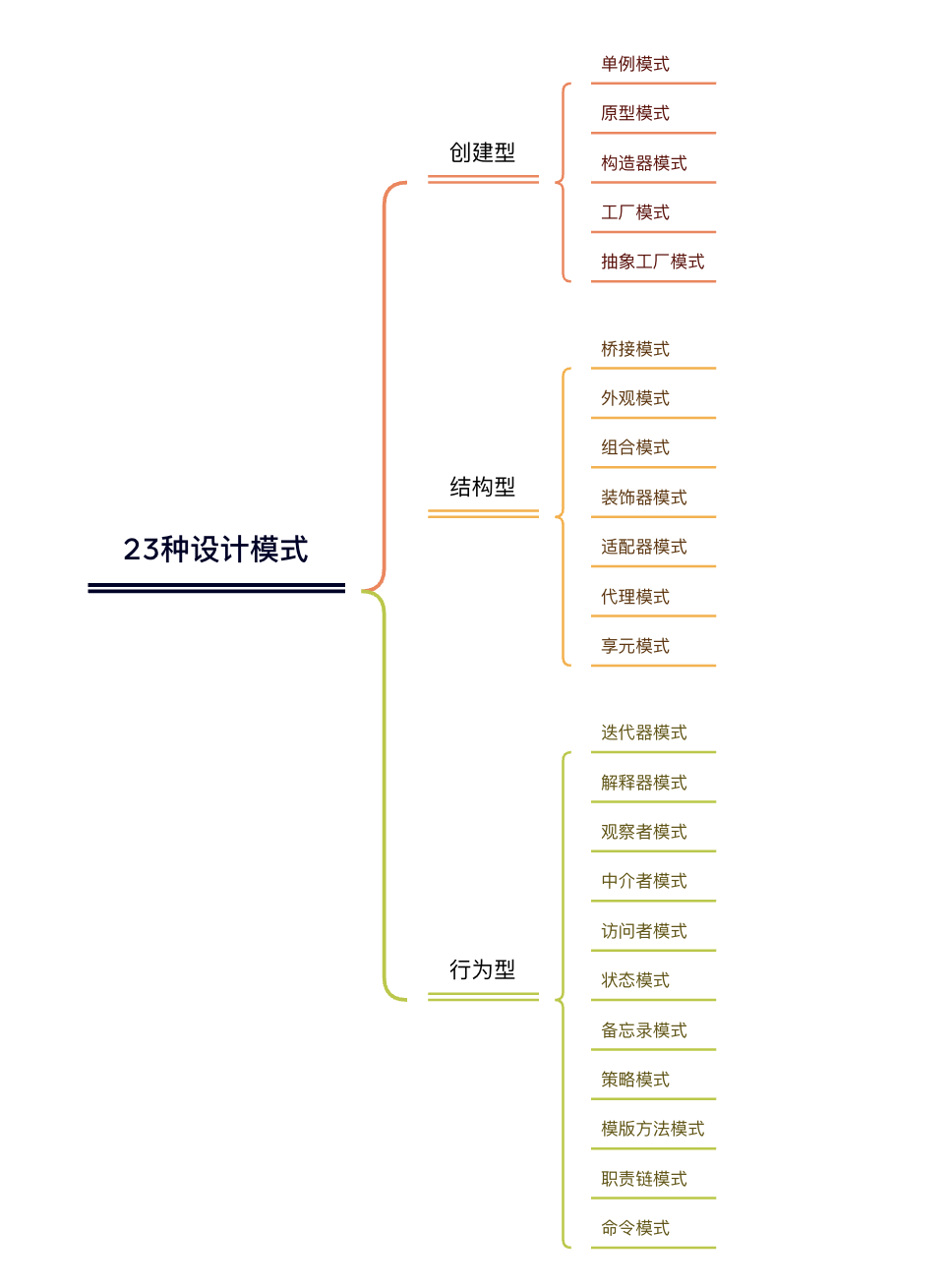
23种设计模式
二十年前 GOF 提出了最经典的23种设计模式,这23种设计模式可以按照“创建型”、“行为型”和“结构型”进行划分:
设计模式的核心**,就是“封装变化”。无论是创建型、结构型还是行为型,这些具体的设计模式都是在用自己的方式去封装不同类型的变化。
- 创建型模式封装了创建对象过程中的变化,比如工厂模式,它做的事情就是将创建对象的过程抽离;
- 结构型模式封装的是对象之间组合方式的变化,目的在于灵活地表达对象间的配合与依赖关系;
- 行为型模式则是将对象千变万化的行为进行抽离,确保我们能够更安全、更方便地对行为进行更改。
Koa2源码分析
原理
Koa.js 是基于中间件模式的 HTTP 服务框架,底层原理是离不开 Node.js 的 http 原生模块的
示例:
const http = require('http')
const PORT = 3001
// 控制器
const controller = {
index(req, res) {
res.end('This is index page')
},
home(req, res) {
res.end('This is home page')
},
_404(req, res) {
res.end('404 Not Found')
}
}
// 路由器
const router = (req, res) => {
if( req.url === '/' ) {
controller.index(req, res)
} else if( req.url.startsWith('/home') ) {
controller.home(req, res)
} else {
controller._404(req, res)
}
}
// 服务
const server = http.createServer(router)
server.listen(PORT, function() {
console.log(`the server is started at port ${PORT}`)
})Koa 文件目录
koa2 目录结构只有四个文件,搭起了整个 server 的框架。
koa 只是负责开头(接受请求)和结尾(响应请求),对请求的处理都是由中间件来实现。
├── lib
│ ├── application.js // 负责串联起 context request response 和中间件
│ ├── context.js // 一次请求的上下文
│ ├── request.js // koa 中的请求
│ └── response.js // koa 中的响应
└── package.json
application.js:负责串联起 context request response 和中间件
context.js:一次请求的上下文
request.js:koa 中的请求
response.js:koa 中的响应
new Koa()
Koa 实际上是一个 class,继承自 node 的 events 事件触发器。
new Koa() 时,大致实际执行了下列代码(简化版):
// lib/application.js
class Application extends Emitter {
constructor (options) {
super()
options = options || {}
this.proxy = options.proxy || false
this.subdomainOffset = options.subdomainOffset || 2
this.proxyIpHeader = options.proxyIpHeader || 'X-Forwarded-For'
this.maxIpsCount = options.maxIpsCount || 0
this.env = options.env || process.env.NODE_ENV || 'development'
if (options.keys) this.keys = options.keys
this.middleware = []
this.context = Object.create(context)
this.request = Object.create(request)
this.response = Object.create(response)
if (util.inspect.custom) {
this[util.inspect.custom] = this.inspect
}
}
listen () {
const fnMiddleware = compose(this.middleware)
const ctx = this.context
const handleResponse = () => respond(ctx)
const onerror = function() {
console.log('onerror')
}
fnMiddleware(ctx).then(handleResponse).catch(onerror)
}
use (fn) {
...
this.middleware.push(fn)
return this
}
}this.request 和 this.response 就是继承自文件 lib/request.js 和 lib/response.js 中的 request 和 response。 request 和 response 做的事情并不复杂,就是将 Node 原生的 http 的 req 和 res 再次做了封装,便于读取和设置,每个属性和方法的封装都不复杂,具体的属性和方法参考 koa 的官方文档。
至于 context,context 是一个 传递的纽带,每个中间件传递的就是 context,它承载了这次访问的所有内容,直到其被最终 response 掉。this.context 继承自文件 lib/context.js,就是一个普通的对象。context 还额外提供了 error 和 cookie 的处理,因为 app 是继承自 Emitter 只有它能订阅 onerror 事件,所以传递的 context 要包裹一个 app 来在中间件中传递(在下面的 createContext 函数中会出现)。
除了 respond 函数,我们可以看到,重点是在 listen 函数中的 compose 函数,详细看一下这个函数。
koa-compose
通过app.use() 添加了若干函数后,接下来要把它们串起来执行。这时就使用到了 compose 函数。
以下是 compose 函数的源码:
function compose (middleware) {
if (!Array.isArray(middleware)) throw new TypeError('Middleware stack must be an array!')
for (const fn of middleware) {
if (typeof fn !== 'function') throw new TypeError('Middleware must be composed of functions!')
}
/**
* @param {Object} context
* @return {Promise}
* @api public
*/
return function (context, next) {
// last called middleware #
let index = -1
return dispatch(0)
function dispatch (i) {
if (i <= index) return Promise.reject(new Error('next() called multiple times'))
index = i
let fn = middleware[i]
if (i === middleware.length) fn = next
if (!fn) return Promise.resolve()
try {
return Promise.resolve(fn(context, dispatch.bind(null, i + 1)));
} catch (err) {
return Promise.reject(err)
}
}
}
}传入一个数组,返回一个函数。然后发现 compose 其实就是类似这样的结构:
async function fn1 (ctx, next) {
console.log('action 001')
ctx.data.push(1)
await next()
console.log('action 006')
ctx.data.push(6)
}
async function fn2 (ctx, next) {
console.log('action 002')
ctx.data.push(2)
await next()
console.log('action 005')
ctx.data.push(5)
}
async function fn3 (ctx, next) {
console.log('action 003')
ctx.data.push(3)
await next()
console.log('action 004')
ctx.data.push(4)
}
const fnMiddleware = function (context) {
return Promise.resolve(
fn1 (context, function next (){
return Promise.resolve(
fn2 (context, function next (){
return Promise.resolve(
fn3 (context, function next (){
return Promise.resolve()
})
)
})
)
})
)
}
fnMiddleware(ctx).then(handleResponse).catch(onerror)在 fn1 中执行 await next() 时,即是执行 return Promise.resolve(fn2(context, function next(...))),然后再到 fn2, fn3 ...
最后一个中间件中有调用next函数,则返回Promise.resolve。如果没有,则不执行next函数。 这样就把所有中间件串联起来了。这也就是我们常说的洋葱模型。
这种把函数存储下来的方式,在很多源码中都有看到。比如
lodash源码的惰性求值,vuex也是把action等函数存储下,最后才去调用。
错误处理
koa 中文文档中的 错误处理 描述如下
错误事件侦听器可以用
app.on('error')指定。如果未指定错误侦听器,则使用默认错误侦听器。错误侦听器接收所有中间件链返回的错误,如果一个错误被捕获并且不再抛出,它将不会被传递给错误侦听器。如果没有指定错误事件侦听器,那么将使用app.onerror,除非error.expose为 true 或app.silent为 true 或error.status为 404,否则只简单记录错误。
我们可以自己在中间件中 try-catch 错误,若不 try-catch,错误则会分发到错误事件侦听器,而这个错误事件侦听器,我们可以自己用 app.on('error') 来定义,若未自己定义,则使用系统默认的错误事件侦听器,也就是下面讲到的 app.onerror() 函数。
错误事件侦听器的定义
执行 app.listen() 的时候:
// lib/application.js
listen (...args) {
debug('listen')
const server = http.createServer(this.callback())
return server.listen(...args)
}callback 函数如下所示:
// lib/application.js
callback () {
const fn = compose(this.middleware)
// listenerCount 返回正在监听的名为 error 的事件的监听器的数量,属于 node 自带的
if (!this.listenerCount('error')) this.on('error', this.onerror)
const handleRequest = (req, res) => {
const ctx = this.createContext(req, res)
return this.handleRequest(ctx, fn)
}
return handleRequest
}if (!this.listenerCount('error')) this.on('error', this.onerror) 这句表明,如果没有自定义的错误事件侦听器,则使用 onerror 函数来侦听错误。
onerror 函数如下所示:
// lib/application.js
onerror (err) {
if (!(err instanceof Error)) throw new TypeError(util.format('non-error thrown: %j', err))
if (404 == err.status || err.expose) return
if (this.silent) return
const msg = err.stack || err.toString()
console.error()
console.error(msg.replace(/^/gm, ' '))
console.error()
}onerror 函数是默认的错误事件侦听器(最外层的错误事件侦听器,全局错误事件侦听器),用来输出错误日志。官方文档中写道:
默认情况下,将错误输出到 stderr,除非
app.silent为true。 当err.status是404或err.expose是true时默认错误处理程序也不会输出错误。 要执行自定义错误处理逻辑,如集中式日志记录,您可以添加一个 “error” 事件侦听器。
每次请求时是如何捕获错误的
在每次请求时,会执行 this.createContext(req, res) 函数来初始化新的 ctx
// lib/application.js
createContext (req, res) {
const context = Object.create(this.context)
const request = context.request = Object.create(this.request)
const response = context.response = Object.create(this.response)
context.app = request.app = response.app = this
context.req = request.req = response.req = req
context.res = request.res = response.res = res
request.ctx = response.ctx = context
request.response = response
response.request = request
context.originalUrl = request.originalUrl = req.url
context.state = {}
return context
}为什么在构造函数中,this.context 是继承自 context.js 文件,这里在每次请求时又继承自 this.context 呢?
这样的好处是你可以为你的 app 设定一个类似模板的 context,这样一来每个请求的 context 在继承时就会有一些预设的方法或属性,this.request 和 this.response 也同理。
紧接着,会执行 this.handleRequest() 函数,传入 ctx 和中间件函数 fnMiddleware。
// lib/application.js
handleRequest(ctx, fnMiddleware) {
const res = ctx.res
// 默认状态码设置为 404
res.statusCode = 404
const onerror = err => ctx.onerror(err)
const handleResponse = () => respond(ctx)
onFinished(res, onerror)
return fnMiddleware(ctx).then(handleResponse).catch(onerror)
}可以看到,中间件中抛出的错误会 catch 到 ctx.onerror() 函数中,然后 ctx.onerror() 函数中则会通过 this.app.emit('error', err, this) 来分发 error 事件,最后在最外层的 app.on('error', app.onerror) 被捕获。
整个流程
koa 中一次 http 请求的流程示意图如下:
运行中有一个很重要和基本的概念就是:HTTP 请求是幂等的。
一次和多次请求某一个资源应该具有同样的副作用,也就是说每个 HTTP 请求都会有一套全新的 context,request,response。
可以看到,若未抛出错误,则最终进入到 respond 函数中:
// lib/application.js
function respond (ctx) {
// allow bypassing koa
if (false === ctx.respond) return
if (!ctx.writable) return
const res = ctx.res
let body = ctx.body
const code = ctx.status
// ignore body
if (statuses.empty[code]) {
// strip headers
ctx.body = null
return res.end()
}
if ('HEAD' === ctx.method) {
if (!res.headersSent && !ctx.response.has('Content-Length')) {
const { length } = ctx.response
if (Number.isInteger(length)) ctx.length = length
}
return res.end()
}
// status body
if (null == body) {
if (ctx.req.httpVersionMajor >= 2) {
body = String(code)
} else {
body = ctx.message || String(code)
}
if (!res.headersSent) {
ctx.type = 'text'
ctx.length = Buffer.byteLength(body)
}
return res.end(body)
}
// responses
if (Buffer.isBuffer(body)) return res.end(body)
if ('string' == typeof body) return res.end(body)
if (body instanceof Stream) return body.pipe(res)
// body: json
body = JSON.stringify(body)
if (!res.headersSent) {
ctx.length = Buffer.byteLength(body)
}
res.end(body)
}Koa2 与 Koa1 的对比
Koa 中文文档中的 从 Koa v1.x 迁移到 v2.x 描述了 Koa2 与 Koa1 的区别。
在 Koa1 中,使用 yield next 进入下一个中间件;在 koa2 中,中间件使用 async 函数,直接使用 await next() 进入下一个中间件。
在 Koa1 中,主要是使用 generator 函数实现中间件,然后在 callback() 函数中用 co.wrap 来将其转换。
Koa2 中,则是使用 koa-compose 将中间件使用Promise串联起来。Koa2 中也兼容 generator 函数实现中间件的方式。从源码中可以看到 app.use时有一层判断,判断是否是generator函数,如果是则用koa-convert暴露的方法convert来转换重新赋值,再存入middleware,后续再使用。
// lib/applicant.js
class Koa extends Emitter {
use (fn) {
if (typeof fn !== 'function') throw new TypeError('middleware must be a function!')
if (isGeneratorFunction(fn)) {
deprecate('Support for generators will be removed in v3. ' +
'See the documentation for examples of how to convert old middleware ' +
'https://github.com/koajs/koa/blob/master/docs/migration.md')
fn = convert(fn)
}
debug('use %s', fn._name || fn.name || '-')
this.middleware.push(fn)
return this
}
}koa-convert 源码挺多,核心代码其实是这样:
function convert(){
return function (ctx, next) {
return co.call(ctx, mw.call(ctx, createGenerator(next)))
}
function * createGenerator (next) {
return yield next()
}
}最后还是通过co来转换的。
Koa 与 Express 的对比
功能实用上具体参考 Koa与Express
框架设计
命令式与声明式
从范式上来看,视图层框架通常分为命令式和声明式。
命令式:关注过程,自然语言描述能够与代码产生一一对应的关系,代码本身描述的是“做事的过程”。
const div = document.querySelector('#app') // 获取div
div.innerText = 'hello world' // 设置文本内容
div.addEventListener('click', () => { alert('ok') }) // 绑定点击事件声明式:更加关注结果,我们提供的是一个“结果”,而怎样去实现这个“结果”,我们并不关心。
<div @click="() => alert('ok')">hello world</div>因此,我们知道,Vue.js的内部实现一定是命令式的,而暴露给用户的却更加声明式。
性能与可维护性
声明式代码的性能不优于命令式的代码
假设现在我们要将div标签的文本修改为hello vue3
用命令式代码可以直接实现
div.textContent = 'hello vue3'现在思考一下,还有没有其他办法比上面这句代码的性能更好?答案是“没有”
理论上,命令式代码可以做到极致的性能优化,因为我们明确的知道哪些发生了变更,只做必要的修改就行了。
但是,声明式代码不一定能做到这一点,因为它描述的是结果:
<!-- 之前:-->
<div>hello world</div>
<!-- 之后:-->
<div>hello vue3</div>对于框架来说,为了实现最优的更新性能,它需要找到前后的差异并只更新变化的地方,但是最终完成这次更新的代码仍然是:
div.textContent = 'hello vue3'如果我们把直接修改的性能消耗定义为A,把找出差异的性能消耗定义为B,那么有:
命令式代码的更新性能消耗 = A
声明式代码的更新性能消耗 = B + A
因此,最理想的情况是,当找出差异的性能消耗为0时,声明式代码与命令式代码的性能相同,但是无法做到超越。
既然性能方面命令式代码是更好的选择,那么为什么vue.js要选择声明式的设计方案呢?
原因就在于声明式代码的可维护性更强。
在采用命令式代码开发的时候,我们需要维护实现目标的整个过程,包括要手动完成DOM元素的创建、更新、删除等工作。而声明式代码展示的就是我们要的结果,看上去更加直观,至于实现的过程,并不需要我们关心,vue.js都帮我们封装好了。
这体现了在框架设计上要做出的关于可维护性与性能之间的权衡。在采用声明式提升可维护性的同时,性能就会有一定的损失,框架设计者要做的就是:在保持可维护性的同时,让性能损失最小化。
虚拟DOM的性能
前面讲到,如果我们能够最小化找出差异的性能消耗,就可以让声明式代码的性能无限接近命令式代码的性能。
而所谓的虚拟DOM,就是为了最小化找出差异的性能消耗而出现的。
我们知道,采用虚拟DOM的更新技术的性能理论上不可能比原生JS操作DOM更高。这里所说的原生JS实际上指的是类似document.createElement之类的DOM操作方法,并不包括 innerHTML,因为它比较特殊,需要单独讨论。
接下来我们来比较一下,使用innerHTML来操作页面 和 虚拟DOM,这两个性能如何。
创建页面
对于innerHTML来说,为了创建页面,我们需要构造一段HTML字符串:
const html = `
<div><span>...</span></div>
`接着将该字符串赋值给DOM元素的innerHTML属性:
div.innerHTML = html然而这句话远没有看上去那么简单,为了渲染出页面,我们需要把字符串解析成DOM树,这是一个DOM层面的计算,涉及DOM的运算远比JS层面的计算性能差。
所以,性能公式为:innerHTML创建页面的性能 = HTML字符串拼接的计算量 + innerHTML的DOM计算量
对于虚拟DOM,创建页面的过程分为两步:
- 创建JS对象,这个对象可以理解为真实DOM的描述
- 递归的遍历虚拟DOM树并创建真实DOM
所以,性能公式为:虚拟DOM创建页面的性能 = 创建JS对象的计算量 + 创建真实DOM的计算量
可见,在创建页面时,无论是纯JS层面的计算,还是DOM层面的计算,其实两者差距不大
更新页面
我们通过下面表格来对比:
| 虚拟DOM | innerHTML | |
|---|---|---|
| 纯JS运算 | 创建新的JS对象 + diff | 渲染HTML字符串 |
| DOM运算 | 必要的DOM更新 | 销毁所有旧DOM + 新建所有新DOM |
可以发现,在更新页面时,虚拟DOM在JS层面的运算要多出一个diff的性能消耗,然而它毕竟也是JS层面的运算,所以不会产生数量级的差异。但innerHTML在DOM层面的运算需要全量的更新,销毁再重建,这时虚拟DOM的优势就体现出来了。
另外,当更新页面时,无论页面多大,都只会更新变化的内容,而对于innerHTML来说,页面越大,就意味着更新时的性能消耗越大。
| 虚拟DOM | innerHTML |
|---|---|
| 性能因素 | 与数据变化量相关 |
性能比较
粗略的比较一下innerHTML、虚拟DOM、原生JS(createElement等方法)在更新页面时的性能:
性能:innerHTML < 虚拟DOM < 原生JS
| innerHTML | 虚拟DOM | 原生JS |
|---|---|---|
| 心智负担中等 | 心智负担小 | 心智负担大 |
| 性能差 | 性能不错 | 性能高 |
| 可维护性强 | 可维护性差 |
可以看到,因为虚拟DOM是声明式的,因此心智负担小,可维护性强,性能虽然比不上极致优化的原生JS,但是在保证心智负担和可维护性的前提下相当不错。
至此,我们有必要思考一下:有没有办法做到,既声明式的描述UI,又具备原生JS的性能呢?我们在之后的章节继续讨论。
运行时和编译时
当设计一个框架的时候,我们有三种选择:
- 纯运行时的
- 运行时 + 编译时的
- 纯编译时的
至于选择哪种,这需要我们根据目标框架的特征,以及对框架的期望,做出合适的决策。
纯运行时
假设我们设计了一个框架,它提供一个Render函数,用户可以为该函数提供一个树型结构的数据对象,然后Render函数会根据该对象递归的将数据渲染成DOM元素,我们规定树型结构的数据对象如下:
const obj = {
tag: 'div',
children: [
{ tag: 'span', children: 'hello world' }
]
}Render函数的实现:
function Render (obj, root) {
const el = document.createElement(obj, tag)
if (typeof obj.children === 'string') {
const text = document.createTextNode(obj.children)
el.appendChild(text)
} else if (obj.children) {
// 数组,递归调用Render,使用el作为root参数
obj.children.forEach(child => Render(child, el))
}
// 将元素添加到root
root.appendChild(el)
}有了这个函数,用户就可以这样使用它:
const obj = {
tag: 'div',
children: [
{ tag: 'span', children: 'hello world' }
]
}
// 渲染到body下
Render(obj, document.body)在浏览器中运行上述代码,就可以看到我们预期的内容。
这就是纯运行时的框架,可以发现,用户在使用它渲染内容时,直接为Render函数提供了一个树型结构的数据对象。这里面不涉及任何额外的步骤,用户也不需要学习额外的知识。
运行时 + 编译时
如果有一天,你的用户抱怨说:“手写树型结构的数据对象太麻烦了,而且不直观,能不能支持用类似于HTML标签的方式描述树型结构的数据对象呢?”
为了满足用户的需求,我们可以引入编译的手段,把HTML标签编译成树型结构的数据对象,这样不就可以继续使用Render函数了吗?
例如
<div>
<span>hello world</span>
</div>编译成
const obj = {
tag: 'div',
children: [
{ tag: 'span', children: 'hello world' }
]
}为此,我们编写了一个叫做compiler的程序,它的作用就是把HTML字符串编译成树型结构的数据对象,于是交付给用户去用了,用户可以这样使用:
const html = `
<div><span>hello world</span></div>
`
// 编译得到HTML树型结构的数据对象
const obj = compiler(html)
// 进行渲染
Render(obj, document.body)这时我们的框架就变成了一个运行时 + 编译时的框架。
纯编译时
运行时编译的框架,是代码运行的时候才开始编译,而这会产生一定的性能开销。因此我们也可以在构建的时候就执行compiler程序将用户提供的内容编译好,等到运行时就无需编译了,这对性能是非常友好的。
同时,既然编译器可以把HTML字符串编译成数据对象,那么肯定也能直接编译成命令式的代码
例如
<div>
<span>hello world</span>
</div>编译成
const div = document.createElement('div')
const span = document.createElement('span')
span.innerText = 'hello world'
div.appendChild(span)
document.body.appendChild(div)这样我们只需要一个compiler函数就可以了,连Render都不需要了。其实这就变成了一个纯编译时的框架,因为我们不支持任何运行时的内容。用户的代码通过编译器编译后才能运行。
优势比较
这几个方案各有利弊。
首先是纯运行时的框架,由于它没有编译过程,因此我们没办法分析用户提供的内容。
但如果加入编译步骤,那就大不一样了,我们可以分析用户提供的内容,看看哪些内容未来可能会改变,哪些内容永远不会改变,这样我们就可以在编译的时候提取这些信息,然后将其传递给Render函数,Render函数得到这些信息之后就可以做进一步的优化了。
假如我们的框架是纯编译时的,那么它也可以分析用户提供的内容。由于不需要任何运行时,而是直接编译成可执行的JS代码,因此性能可能会更好,但是这种做法有损灵活性,即用户提供的内容必须编译后才能用。
Vue.js 3 仍然保持了运行时 + 编译时的架构,在保持灵活性的基础上能够尽可能的去优化。
等后面讲解编译优化相关的内容时,你会看到Vue.js 3在保留运行时的情况下,其性能甚至不输纯编译时的框架。
浏览器缓存(HTTP缓存)
DNS 缓存
什么是 DNS
全称 Domain Name System,即域名系统。
万维网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。DNS协议运行在UDP协议之上,使用端口号53。
DNS 解析
通过域名,最终得到该域名所对应的IP地址的过程叫做域名解析(或主机名解析)。
www.dnscache.com (域名) - DNS解析 -> 11.222.33.444 (IP地址)
DNS 缓存
有 DNS 的地方,就有缓存。浏览器、操作系统、Local DNS、根域名服务器,它们都会对DNS结果做一定程度的缓存。
DNS 查询过程如下:
- 首先搜索浏览器自身的 DNS 缓存,如果存在,则域名解析到此完成。
- 如果浏览器自身的缓存里面没有找到对应的条目,那么会尝试读取操作系统的 hosts 文件看是否存在对应的映射关系,如果存在,则域名解析到此完成。
- 如果本地 hosts 文件不存在映射关系,则查找本地 DNS 服务器(ISP 服务器,或者自己手动设置的 DNS 服务器),如果存在,域名到此解析完成。
- 如果本地 DNS 服务器还没找到的话,它就会向根服务器发出请求,进行递归查询。
CDN 缓存
什么是 CDN
全称 Content Delivery Network,即内容分发网络。
摘录一个形象的比喻,来理解 CDN 是什么。
10年前,还没有火车票代售点一说,12306.cn更是无从说起。那时候火车票还只能在火车站的售票大厅购买,而我所在的小县城并不通火车,火车票都要去市里的火车站购买,而从我家到县城再到市里,来回就是4个小时车程,简直就是浪费生命。后来就好了,小县城里出现了火车票代售点,甚至乡镇上也有了代售点,可以直接在代售点购买火车票,方便了不少,全市人民再也不用在一个点苦逼的排队买票了。
简单的理解 CDN 就是这些代售点(缓存服务器)的承包商,他为买票者提供了便利,帮助他们在最近的地方(最近的 CDN 节点)用最短的时间(最短的请求时间)买到票(拿到资源),这样去火车站售票大厅排队的人也就少了。也就减轻了售票大厅的压力(起到分流作用,减轻服务器负载压力)。
用户在浏览网站的时候,CDN 会选择一个离用户最近的 CDN 边缘节点来响应用户的请求,这样海南移动用户的请求就不会千里迢迢跑到北京电信机房的服务器(假设源站部署在北京电信机房)上了。
CDN 缓存
关于 CDN 缓存,在浏览器本地缓存失效后,浏览器会向 CDN 边缘节点发起请求。类似浏览器缓存,CDN边缘节点也存在着一套缓存机制。CDN 边缘节点缓存策略因服务商不同而不同,但一般都会遵循 http 标准协议,通过http响应头中的 Cache-control: max-age 的字段来设置 CDN 边缘节点数据缓存时间。
当浏览器向 CDN 节点请求数据时,CDN 节点会判断缓存数据是否过期,若缓存数据并没有过期,则直接将缓存数据返回给客户端。否则,CDN节点就会向服务器发出回源请求,从服务器拉取最新数据,更新本地缓存,并将最新数据返回给客户端。 CDN服务商一般会提供基于文件后缀、目录多个维度来指定 CDN 缓存时间,为用户提供更精细化的缓存管理。
CDN 优势
- CDN 节点解决了跨运营商和跨地域访问的问题,访问延时大大降低。
- 大部分请求在 CDN 边缘节点完成,CDN 起到了分流作用,减轻了源服务器的负载。
浏览器缓存
什么是浏览器缓存
简单来说,浏览器缓存其实就是浏览器保存通过 HTTP 获取的所有资源,是浏览器将网络资源存储在本地的一种行为。
缓存的资源去哪了?
你可能会有疑问,浏览器存储了资源,那它把资源存储在哪里呢?存储在以下两个部分
-
memory cache
MemoryCache 顾名思义,就是将资源缓存到内存中,等待下次访问时不需要重新下载资源,而直接从内存中获取。Webkit 早已支持 memoryCache。 目前 Webkit 资源分成两类,一类是主资源,比如 HTML 页面,或者下载项,一类是派生资源,比如HTML 页面中内嵌的图片或者脚本链接,分别对应代码中两个类:MainResourceLoader 和 SubresourceLoader。虽然 Webkit支持 memoryCache,但是也只是针对派生资源,它对应的类为 CachedResource,用于保存原始数据(比如CSS,JS等),以及解码过的图片数据。
-
disk cache
DiskCache 顾名思义,就是将资源缓存到磁盘中,等待下次访问时不需要重新下载资源,而直接从磁盘中获取,它的直接操作对象为 CurlCacheManager。
-
以下是他们的对比
memory cache disk cache 相同点 只能存储一些派生类资源文件 只能存储一些派生类资源文件 不同点 退出进程时数据会被清除 退出进程时数据不会被清除 存储资源 一般脚本、字体、图片会存在内存当中 一般非脚本会存在内存当中,如css等 因为CSS文件加载一次就可渲染出来,我们不会频繁读取它,所以它不适合缓存到内存中,但是js之类的脚本却随时可能会执行,如果脚本在磁盘当中,我们在执行脚本的时候需要从磁盘取到内存中来,这样IO开销就很大了,有可能导致浏览器失去响应。
三级缓存原理(访问缓存优先级)
- 先在内存中查找,如果有,直接加载。
- 如果内存中不存在,则在硬盘中查找,如果有直接加载。
- 如果硬盘中也没有,那么就进行网络请求。
- 请求获取的资源缓存到硬盘和内存。
浏览器缓存的分类
- 强缓存
- 协商缓存
浏览器再向服务器请求资源时,首先判断是否命中强缓存,再判断是否命中协商缓存。
浏览器缓存的优点
- 减少了冗余的数据传输
- 减少了服务器的负担,大大提升了网站的性能
- 加快了客户端加载网页的速度
强缓存
浏览器在加载资源时,会先根据本地缓存资源的 header 中的信息判断是否命中强缓存,如果命中则直接使用缓存中的资源不会再向服务器发送请求。
这里的 header 中的信息指的是 expires 和 cache-control
Expires
该字段是 http1.0 时的规范,它的值为一个绝对时间的 GMT 格式的时间字符串,比如 Expires:Mon,18 Oct 2066 23:59:59 GMT。这个时间代表着这个资源的失效时间,在此时间之前,即命中缓存。这种方式有一个明显的缺点,由于失效时间是一个绝对时间,所以当服务器与客户端时间偏差较大时,就会导致缓存混乱。
Cache-Control
Cache-Control 是 http1.1 时出现的 header 信息,主要是利用该字段的 max-age 值来进行判断,它是一个相对时间,例如 Cache-Control:max-age=3600,代表着资源的有效期是 3600 秒。cache-control 除了该字段外,还有下面几个比较常见的属性:
Cache-Control请求头常见属性
| 字段(单位秒) | 说明 |
|---|---|
| max-age=300 | 拒绝接受长于300秒的资源,为0时表示获取最新资源 |
| max-stale=100 | 缓存过期之后的100秒内,依然拿来用 |
| min-fresh=50 | 缓存到期时间还剩余50秒开始,就不给拿了,不新鲜了 |
| no-cache | 协商缓存验证 |
| no-store | 不使用缓存 |
| only-if-chached | 只使用缓存,没有就报504错误 |
| no-transform | 不得对资源进行转换或转变。Content-Encoding, Content-Range, Content-Type等HTTP头不能由代理修改。然并卵 |
Cache-Control响应头常见属性
| 字段(单位秒) | 说明 |
|---|---|
| max-age=300 | 缓存有效期300秒 |
| s-maxage=500 | 有效期500秒,优先级高于max-age,适用于共享缓存(如CDN) |
| public | 可以被任何终端缓存,包括代理服务器、CDN等 |
| private | 只能被用户的浏览器终端缓存(私有缓存) |
| no-cache | 需要和服务端确认资源是否发生变化,没有变化则使用缓存 |
| no-store | 不缓存 |
| no-transform | 与上面请求指令中的一样 |
| must-revalidate | 客户端缓存过期了就向源服务器验证 |
| proxy-revalidate | 代理缓存过期了就去源服务器重新获取 |
协商缓存
协商缓存就是强缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程。
资源标识分为两种:
Last-Modified / If-Modified-Since
Last-Modified 是服务器响应请求时,返回该资源文件在服务器最后被修改的时间。
If-Modified-Since 则是客户端再次发起该请求时,携带上次请求返回的 Last-Modified 值,通过此字段值告诉服务器该资源上次请求返回的最后被修改时间。服务器收到该请求,发现请求头含有 If-Modified-Since 字段,则会根据 If-Modified-Since 的字段值与该资源在服务器的最后被修改时间做对比,若服务器的资源最后被修改时间大于 If-Modified-Since 的字段值,则重新返回资源,状态码为 200;否则则返回 304,代表资源无更新,可继续使用缓存文件。
Etag / If-None-Match
Etag是服务器响应请求时,返回当前资源文件的一个唯一标识(由服务器生成)。
If-None-Match 是客户端再次发起该请求时,携带上次请求返回的唯一标识 Etag 值,通过此字段值告诉服务器该资源上次请求返回的唯一标识值。服务器收到该请求后,发现该请求头中含有 If-None-Match,则会根据 If-None-Match 的字段值与该资源在服务器的 Etag 值做对比,一致则返回 304,代表资源无更新,继续使用缓存文件;不一致则重新返回资源文件,状态码为200。
Etag / If-None-Match 优先级高于 Last-Modified / If-Modified-Since,同时存在则只有Etag / If-None-Match生效。通常使用Etag,因为其更精确些,而 Last-Modified 只能精确到秒
整个流程
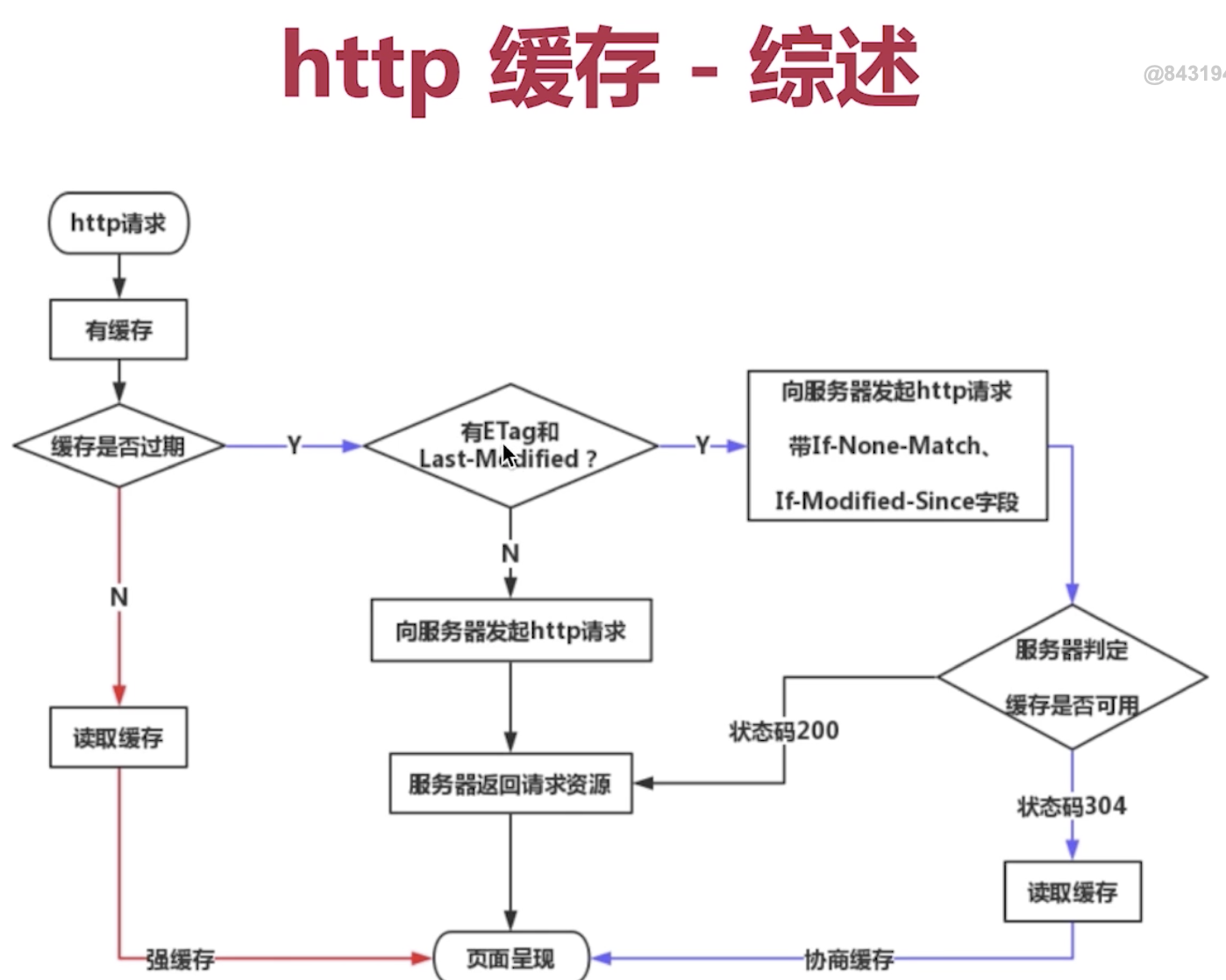
正常操作:强缓存有效,协商缓存有效
手动刷新(F5):强缓存失效,协商缓存有效
强制刷新(ctrl + F5):强缓存失效,协商缓存失效
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.