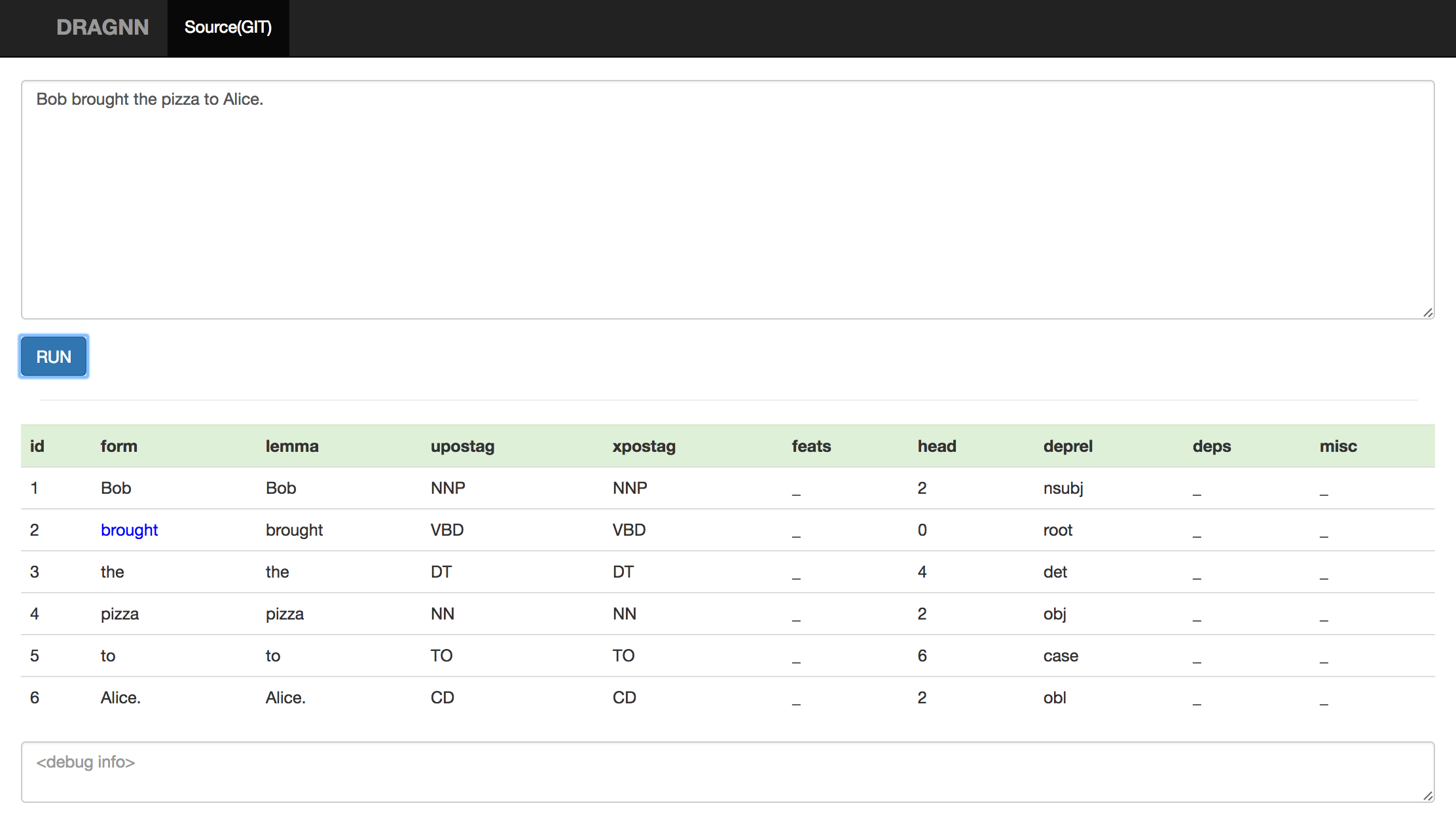
Hi there,
I've just finished to train a new model based on UD_Italian http://ufal.mff.cuni.cz/~zeman/soubory/ud-treebanks-conll2017.tgz corpus with Universal Dependencies release 2.0.
... everything fine but when I run the ./test.sh , the script do not find the models:
"File path is: %r" % (save_path, file_path))
ValueError: Restore called with invalid save path: '/opt/tensorflow/models/syntaxnet/work/models/tagger-params/model'. File path is: '/opt/tensorflow/models/syntaxnet/work/models/tagger-params/model'
here the complete log:
root@8d5f1d0de6eb:/opt/tensorflow/models/syntaxnet/work# echo "prova in Italiano" | ./test.sh
I syntaxnet/term_frequency_map.cc:103] Loaded 44 terms from /opt/tensorflow/models/syntaxnet/work/models/label-map.
I syntaxnet/term_frequency_map.cc:103] Loaded 44 terms from /opt/tensorflow/models/syntaxnet/work/models/label-map.
I syntaxnet/embedding_feature_extractor.cc:35] Features: stack(3).word stack(2).word stack(1).word stack.word input.word input(1).word input(2).word input(3).word;input.digit input.hyphen;stack.suffix(length=2) input.suffix(length=2) input(1).suffix(length=2);stack.prefix(length=2) input.prefix(length=2) input(1).prefix(length=2)
I syntaxnet/embedding_feature_extractor.cc:36] Embedding names: words;other;suffix;prefix
I syntaxnet/embedding_feature_extractor.cc:37] Embedding dims: 64;4;8;8
I syntaxnet/embedding_feature_extractor.cc:35] Features: input.word input(1).word input(2).word input(3).word stack.word stack(1).word stack(2).word stack(3).word stack.child(1).word stack.child(1).sibling(-1).word stack.child(-1).word stack.child(-1).sibling(1).word stack(1).child(1).word stack(1).child(1).sibling(-1).word stack(1).child(-1).word stack(1).child(-1).sibling(1).word stack.child(2).word stack.child(-2).word stack(1).child(2).word stack(1).child(-2).word;input.tag input(1).tag input(2).tag input(3).tag stack.tag stack(1).tag stack(2).tag stack(3).tag stack.child(1).tag stack.child(1).sibling(-1).tag stack.child(-1).tag stack.child(-1).sibling(1).tag stack(1).child(1).tag stack(1).child(1).sibling(-1).tag stack(1).child(-1).tag stack(1).child(-1).sibling(1).tag stack.child(2).tag stack.child(-2).tag stack(1).child(2).tag stack(1).child(-2).tag;stack.child(1).label stack.child(1).sibling(-1).label stack.child(-1).label stack.child(-1).sibling(1).label stack(1).child(1).label stack(1).child(1).sibling(-1).label stack(1).child(-1).label stack(1).child(-1).sibling(1).label stack.child(2).label stack.child(-2).label stack(1).child(2).label stack(1).child(-2).label
I syntaxnet/embedding_feature_extractor.cc:36] Embedding names: words;tags;labels
I syntaxnet/embedding_feature_extractor.cc:37] Embedding dims: 64;32;32
I syntaxnet/term_frequency_map.cc:103] Loaded 27170 terms from /opt/tensorflow/models/syntaxnet/work/models/word-map.
I syntaxnet/term_frequency_map.cc:103] Loaded 27170 terms from /opt/tensorflow/models/syntaxnet/work/models/word-map.
I syntaxnet/term_frequency_map.cc:103] Loaded 39 terms from /opt/tensorflow/models/syntaxnet/work/models/tag-map.
I syntaxnet/term_frequency_map.cc:103] Loaded 39 terms from /opt/tensorflow/models/syntaxnet/work/models/tag-map.
INFO:tensorflow:Building training network with parameters: feature_sizes: [20 20 12] domain_sizes: [27173 42 47]
INFO:tensorflow:Building training network with parameters: feature_sizes: [8 2 3 3] domain_sizes: [27173 5 3319 4357]
Traceback (most recent call last):
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 161, in
tf.app.run()
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/platform/app.py", line 30, in run
sys.exit(main(sys.argv[:1] + flags_passthrough))
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 157, in main
Eval(sess)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 115, in Eval
parser.saver.restore(sess, FLAGS.model_path)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 1434, in restore
"File path is: %r" % (save_path, file_path))
ValueError: Restore called with invalid save path: '/opt/tensorflow/models/syntaxnet/work/models/tagger-params/model'. File path is: '/opt/tensorflow/models/syntaxnet/work/models/tagger-params/model'
Traceback (most recent call last):
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 161, in
tf.app.run()
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/platform/app.py", line 30, in run
sys.exit(main(sys.argv[:1] + flags_passthrough))
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 157, in main
Eval(sess)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 115, in Eval
parser.saver.restore(sess, FLAGS.model_path)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 1434, in restore
"File path is: %r" % (save_path, file_path))
ValueError: Restore called with invalid save path: '/opt/tensorflow/models/syntaxnet/work/models/parser-params/model'. File path is: '/opt/tensorflow/models/syntaxnet/work/models/parser-params/model'
INFO:tensorflow:Read 0 documents
so I tried to rename the models to let it found
/opt/tensorflow/models/syntaxnet/work/models/tagger-params/model.meta (the file I found in the directory) to -> /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model
/opt/tensorflow/models/syntaxnet/work/models/parser-params/model.meta (the file I found in the directory) to -> /opt/tensorflow/models/syntaxnet/work/models/parser-params/model
and then run again the ./test.sh
this time found the models but the error is different..
Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
here the complete log:
root@8d5f1d0de6eb:/opt/tensorflow/models/syntaxnet/work# echo "prova in Italiano" | ./test.sh
I syntaxnet/term_frequency_map.cc:103] Loaded 44 terms from /opt/tensorflow/models/syntaxnet/work/models/label-map.
I syntaxnet/term_frequency_map.cc:103] Loaded 44 terms from /opt/tensorflow/models/syntaxnet/work/models/label-map.
I syntaxnet/embedding_feature_extractor.cc:35] Features: input.word input(1).word input(2).word input(3).word stack.word stack(1).word stack(2).word stack(3).word stack.child(1).word stack.child(1).sibling(-1).word stack.child(-1).word stack.child(-1).sibling(1).word stack(1).child(1).word stack(1).child(1).sibling(-1).word stack(1).child(-1).word stack(1).child(-1).sibling(1).word stack.child(2).word stack.child(-2).word stack(1).child(2).word stack(1).child(-2).word;input.tag input(1).tag input(2).tag input(3).tag stack.tag stack(1).tag stack(2).tag stack(3).tag stack.child(1).tag stack.child(1).sibling(-1).tag stack.child(-1).tag stack.child(-1).sibling(1).tag stack(1).child(1).tag stack(1).child(1).sibling(-1).tag stack(1).child(-1).tag stack(1).child(-1).sibling(1).tag stack.child(2).tag stack.child(-2).tag stack(1).child(2).tag stack(1).child(-2).tag;stack.child(1).label stack.child(1).sibling(-1).label stack.child(-1).label stack.child(-1).sibling(1).label stack(1).child(1).label stack(1).child(1).sibling(-1).label stack(1).child(-1).label stack(1).child(-1).sibling(1).label stack.child(2).label stack.child(-2).label stack(1).child(2).label stack(1).child(-2).label
I syntaxnet/embedding_feature_extractor.cc:36] Embedding names: words;tags;labels
I syntaxnet/embedding_feature_extractor.cc:37] Embedding dims: 64;32;32
I syntaxnet/embedding_feature_extractor.cc:35] Features: stack(3).word stack(2).word stack(1).word stack.word input.word input(1).word input(2).word input(3).word;input.digit input.hyphen;stack.suffix(length=2) input.suffix(length=2) input(1).suffix(length=2);stack.prefix(length=2) input.prefix(length=2) input(1).prefix(length=2)
I syntaxnet/embedding_feature_extractor.cc:36] Embedding names: words;other;suffix;prefix
I syntaxnet/embedding_feature_extractor.cc:37] Embedding dims: 64;4;8;8
I syntaxnet/term_frequency_map.cc:103] Loaded 27170 terms from /opt/tensorflow/models/syntaxnet/work/models/word-map.
I syntaxnet/term_frequency_map.cc:103] Loaded 27170 terms from /opt/tensorflow/models/syntaxnet/work/models/word-map.
I syntaxnet/term_frequency_map.cc:103] Loaded 39 terms from /opt/tensorflow/models/syntaxnet/work/models/tag-map.
I syntaxnet/term_frequency_map.cc:103] Loaded 39 terms from /opt/tensorflow/models/syntaxnet/work/models/tag-map.
INFO:tensorflow:Building training network with parameters: feature_sizes: [20 20 12] domain_sizes: [27173 42 47]
INFO:tensorflow:Building training network with parameters: feature_sizes: [8 2 3 3] domain_sizes: [27173 5 3319 4357]
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
Traceback (most recent call last):
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 161, in
tf.app.run()
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/platform/app.py", line 30, in run
sys.exit(main(sys.argv[:1] + flags_passthrough))
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 157, in main
Eval(sess)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 115, in Eval
parser.saver.restore(sess, FLAGS.model_path)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 1437, in restore
{self.saver_def.filename_tensor_name: save_path})
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/client/session.py", line 717, in run
run_metadata_ptr)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/client/session.py", line 915, in _run
feed_dict_string, options, run_metadata)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/client/session.py", line 965, in _do_run
target_list, options, run_metadata)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/client/session.py", line 985, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors.DataLossError: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
[[Node: save/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/cpu:0"](_recv_save/Const_0, save/RestoreV2/tensor_names, save/RestoreV2/shape_and_slices)]]
Caused by op u'save/RestoreV2', defined at:
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 161, in
tf.app.run()
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/platform/app.py", line 30, in run
sys.exit(main(sys.argv[:1] + flags_passthrough))
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 157, in main
Eval(sess)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 113, in Eval
parser.AddSaver(FLAGS.slim_model)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/graph_builder.py", line 568, in AddSaver
self.saver = tf.train.Saver(variables_to_save)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 1078, in init
self.build()
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 1107, in build
restore_sequentially=self._restore_sequentially)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 705, in build
restore_sequentially, reshape)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 442, in _AddRestoreOps
tensors = self.restore_op(filename_tensor, saveable, preferred_shard)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 281, in restore_op
[spec.tensor.dtype])[0])
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/ops/gen_io_ops.py", line 439, in restore_v2
dtypes=dtypes, name=name)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/framework/op_def_library.py", line 749, in apply_op
op_def=op_def)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/framework/ops.py", line 2386, in create_op
original_op=self._default_original_op, op_def=op_def)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/framework/ops.py", line 1298, in init
self._traceback = _extract_stack()
DataLossError (see above for traceback): Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/tagger-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
[[Node: save/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/cpu:0"](_recv_save/Const_0, save/RestoreV2/tensor_names, save/RestoreV2/shape_and_slices)]]
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/util/tensor_slice_reader.cc:95] Could not open /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
W external/org_tensorflow/tensorflow/core/framework/op_kernel.cc:968] Data loss: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
Traceback (most recent call last):
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 161, in
tf.app.run()
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/platform/app.py", line 30, in run
sys.exit(main(sys.argv[:1] + flags_passthrough))
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 157, in main
Eval(sess)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 115, in Eval
parser.saver.restore(sess, FLAGS.model_path)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 1437, in restore
{self.saver_def.filename_tensor_name: save_path})
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/client/session.py", line 717, in run
run_metadata_ptr)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/client/session.py", line 915, in _run
feed_dict_string, options, run_metadata)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/client/session.py", line 965, in _do_run
target_list, options, run_metadata)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/client/session.py", line 985, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors.DataLossError: Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
[[Node: save/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/cpu:0"](_recv_save/Const_0, save/RestoreV2/tensor_names, save/RestoreV2/shape_and_slices)]]
Caused by op u'save/RestoreV2', defined at:
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 161, in
tf.app.run()
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/platform/app.py", line 30, in run
sys.exit(main(sys.argv[:1] + flags_passthrough))
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 157, in main
Eval(sess)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/parser_eval.py", line 113, in Eval
parser.AddSaver(FLAGS.slim_model)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/main/syntaxnet/graph_builder.py", line 568, in AddSaver
self.saver = tf.train.Saver(variables_to_save)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 1078, in init
self.build()
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 1107, in build
restore_sequentially=self._restore_sequentially)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 705, in build
restore_sequentially, reshape)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 442, in _AddRestoreOps
tensors = self.restore_op(filename_tensor, saveable, preferred_shard)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/training/saver.py", line 281, in restore_op
[spec.tensor.dtype])[0])
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/ops/gen_io_ops.py", line 439, in restore_v2
dtypes=dtypes, name=name)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/framework/op_def_library.py", line 749, in apply_op
op_def=op_def)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/framework/ops.py", line 2386, in create_op
original_op=self._default_original_op, op_def=op_def)
File "/opt/tensorflow/models/syntaxnet/bazel-bin/syntaxnet/parser_eval.runfiles/org_tensorflow/tensorflow/python/framework/ops.py", line 1298, in init
self._traceback = _extract_stack()
DataLossError (see above for traceback): Unable to open table file /opt/tensorflow/models/syntaxnet/work/models/parser-params/model: Data loss: not an sstable (bad magic number): perhaps your file is in a different file format and you need to use a different restore operator?
[[Node: save/RestoreV2 = RestoreV2[dtypes=[DT_FLOAT], _device="/job:localhost/replica:0/task:0/cpu:0"](_recv_save/Const_0, save/RestoreV2/tensor_names, save/RestoreV2/shape_and_slices)]]
INFO:tensorflow:Read 0 documents`
Any clue?
Thank you so much!































































































































{kind=link}