



A one-stop repository for new-comers in Machine Learning and A.I.
- Description
- Project structure
- Project roadmap
- Getting started
- Preview Notebooks
- Built with
- Contributing
- Authors
- License
- Acknowledgments
This repository has two projects -
- Classification based project on Cancer prediction
Cancer_prediction.ipynb - Regression based project on Stock price prediction
L&T_Stock_Price_prediction.ipynb
- Cancer Prediction
Machine learning is not new to cancer research. Artificial neural networks (ANNs) and decision trees (DTs) have been used in cancer detection and diagnosis for nearly 20 years.The fundamental goals of cancer prediction and prognosis are distinct from the goals of cancer detection and diagnosis.
- Stock price Prediction
Stock market prediction aims to determine the future movement of the stock value of a financial exchange. The accurate prediction of share price movement will lead to more profit investors can make.
- Cancer Prediction
The idea is to predict whether a cell is cancerous or non-cancerous based on different features of cell using different Machine learning algorithms or Deep learning techniques
- Stock Prediction
The idea is to predict the future stock pricing based on different dependencies of a stock using different Machine learning algorithms or Deep learning techniques
.
├── Classification
│ ├── Cancer_prediction.ipynb Jupyter notebook for Cancer prediction
│ ├── Datasets Dataset for Cancer prediction
│ │ ├── cancer_data.csv
│ │ └── dataset.txt
│ └── classification.txt Basic information about Classification
├── Regression
│ ├── Datasets Dataset for L&T stock price prediction
│ │ ├── LT.csv
│ │ └── dataset.txt
│ ├── L&T_Stock_Price_prediction.ipynb Jupyter notebook for Stock price prediction
│ └── regression.txt Basic information about Regression
├── LICENSE
├── code_of_conduct.md
├── contributing.md
└── readme.md
The project currently does the following things-
- Data cleaning
- Data preprocessing
- Already implemented a very few machine learning algorithms or deep learning techniques
Following things can be implemented -
- Data augmentation or manipulation
- Better data visualization
- Implementation of different Machine learning algorithms or deep learning techniques to achieve better prediction results
-
Very basic understanding of git and github:
- What are repositories (local - remote - upstream), issues, pull requests
- How to clone a repository, how to fork a repository, how to set upstreams
- Adding, committing, pulling, pushing changes to remote repositories
-
For EDA and Visualisation
- Basic syntax and working of
python.(This is a must) - Basic knowledge of
pandaslibrary. Reading this blog might help. - Basic knowledge of
matplotliblibrary. Reading this blog might help. - Basic knowledge of
seabornlibrary. Reading this blog might help. - Basic knowledge of
scikit learnlibrary. Reading this blog might help. - Basic knowledge of
tensorflowlibrary. Reading this blog might help.
However the code is well explained, so anyone knowing the basics of Python can get a idea of what's happenning and contribute to this.
- Basic syntax and working of
A step by step series of examples that tell you how to get a development env running.
There are two ways of running the code.
-
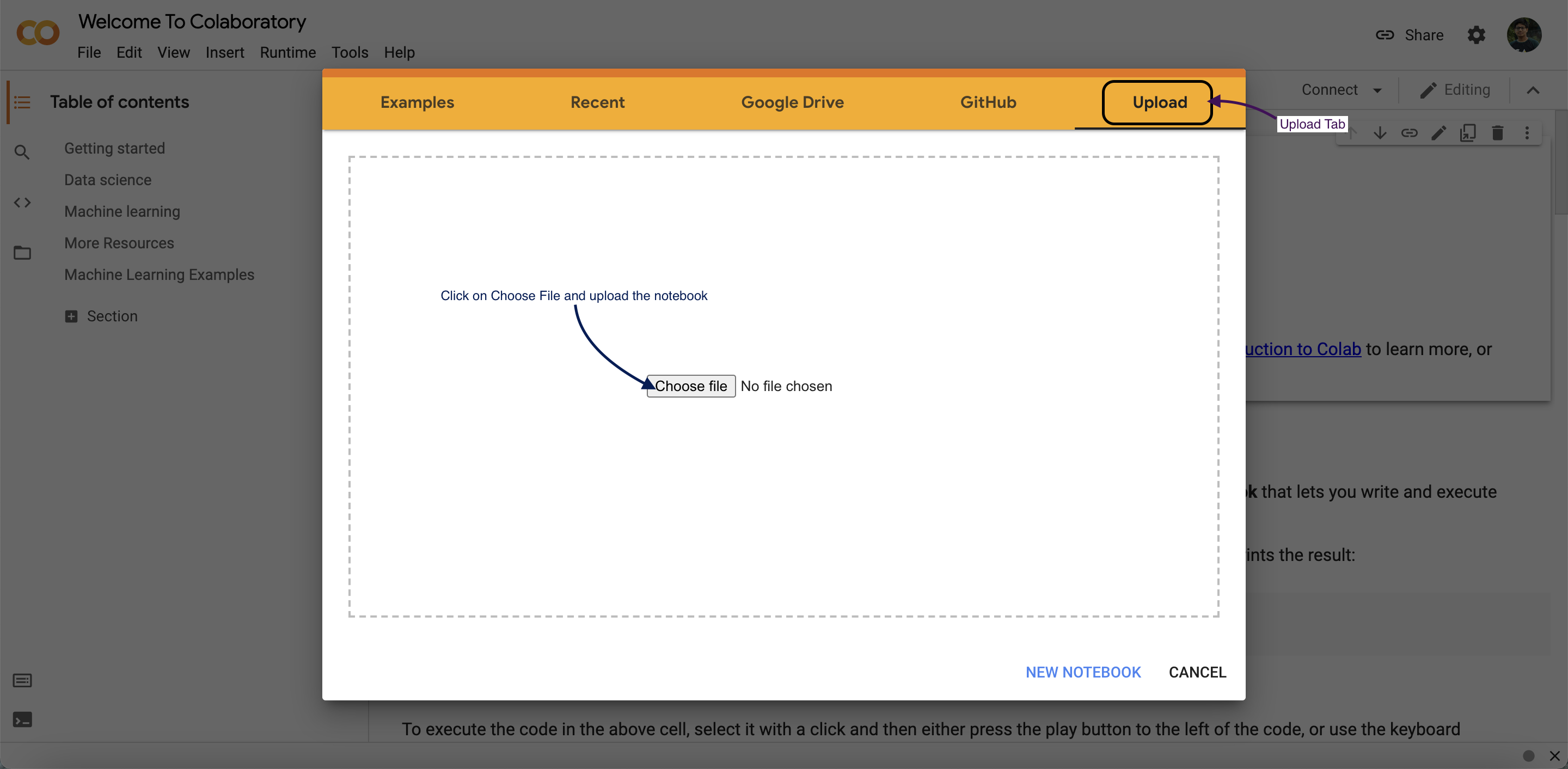
Running the code on web browser.(Google Colab) [Recommended]
- Head on to Google colab
- Then click on
Upload NotebookTab. - Upload the notebook that you got from this repo.
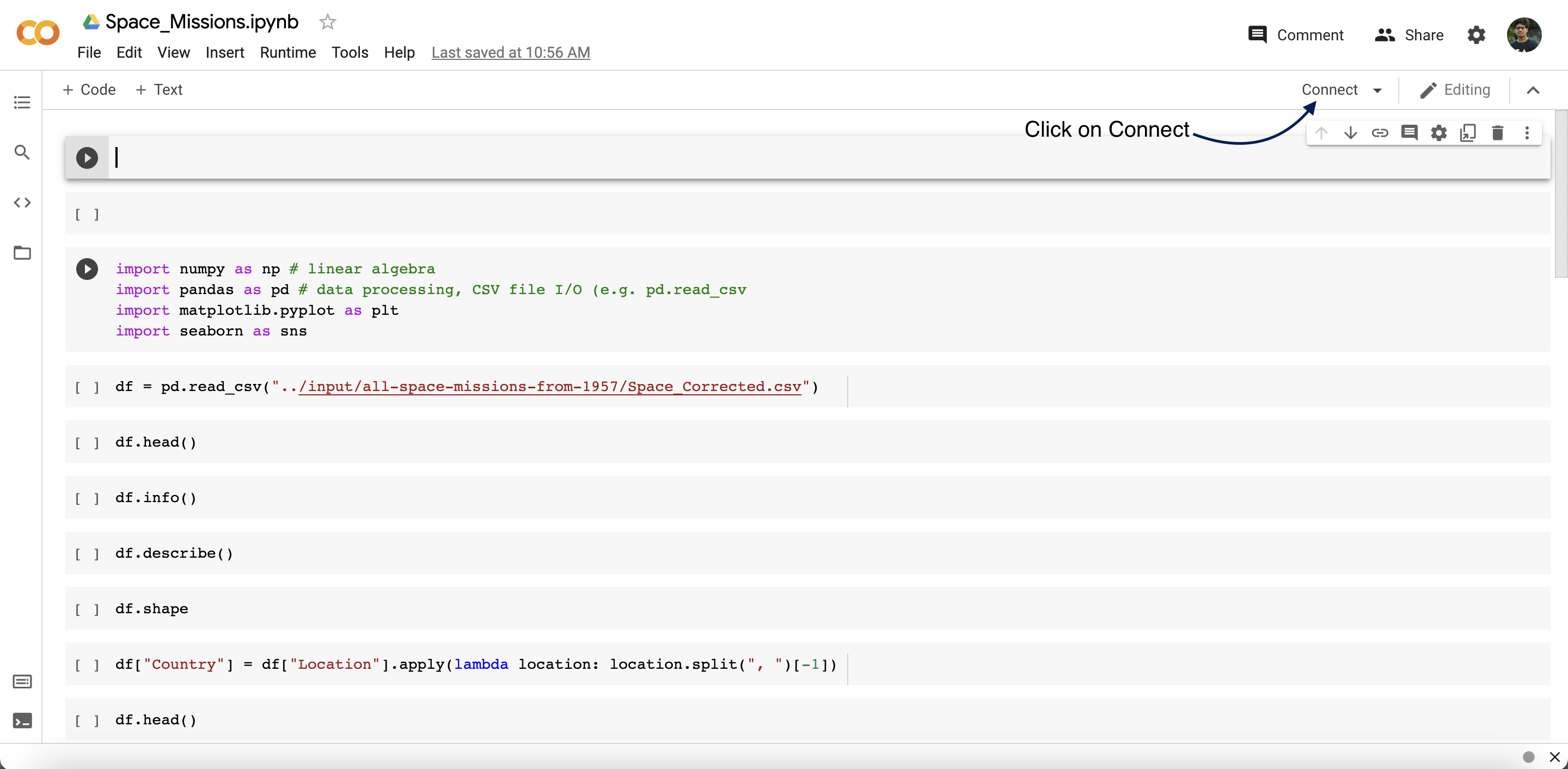
- Connect with the runtime.
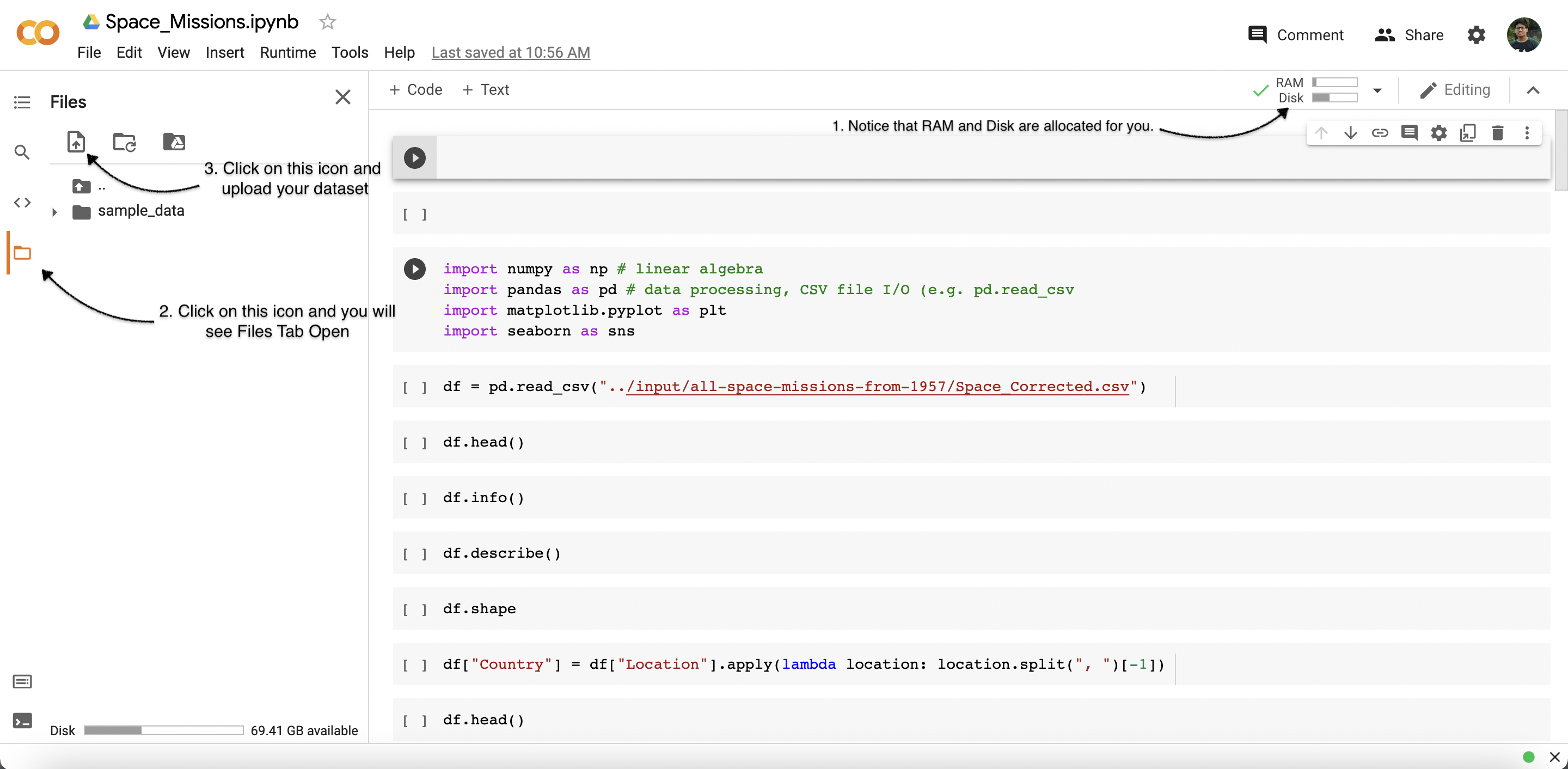
- Upload your dataset.
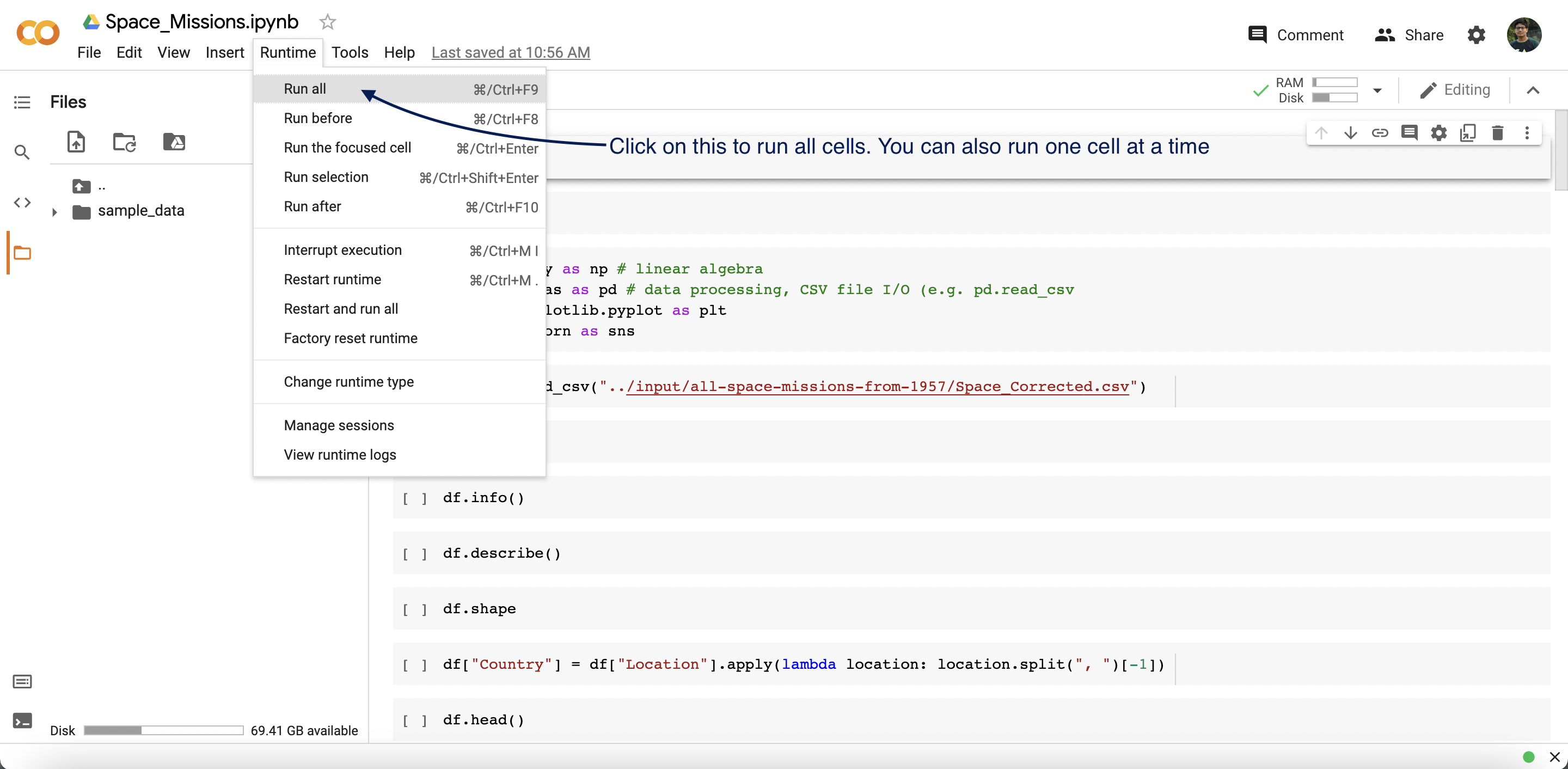
- Then Click on
Run All. - Start Editing.
-
You can also run the code locally in your computer by installing Anaconda.
- Install Anaconda. Follow these steps to install Anaconda on your computer
- Install jupyter notebook using
conda. Follow these steps to install jupyter notebook. - Make sure to install
pandas,matplotlib,seabornandscikit-learnto run the notebook. - Start Editing.
Notebook will be opened in Google Colab
- Head to here for the
Cancer_predictionpreview - Head to here for the
L&T_Stock_Price_predictionpreview
Please read contributing.md for details on our code of conduct, and the process for submitting pull requests to us.
This project is licensed under the MIT License - see the LICENSE file for details.







