The Finnish research stations from monitoring programmes analysis framework
The Finnish research stations have collected metadata from several long-term environmental monitoring programmes.
The aim is that during the next 5 years all data from Kilpisjärvi, Lammi and Tvärminne stations will be opened according to FAIR principles?
Where would you start and what would be the most important steps / stages to achieve this goal?
Task: To develop a strategy for the establishment of Kilpisjärvi, Lammi and Tvärminne stations
over the next five years in accordance with FAIR principles
FAIR data is a term outlining best practice for preserving research data. The FAIR principles that are used in this project are presented in Figure 1:
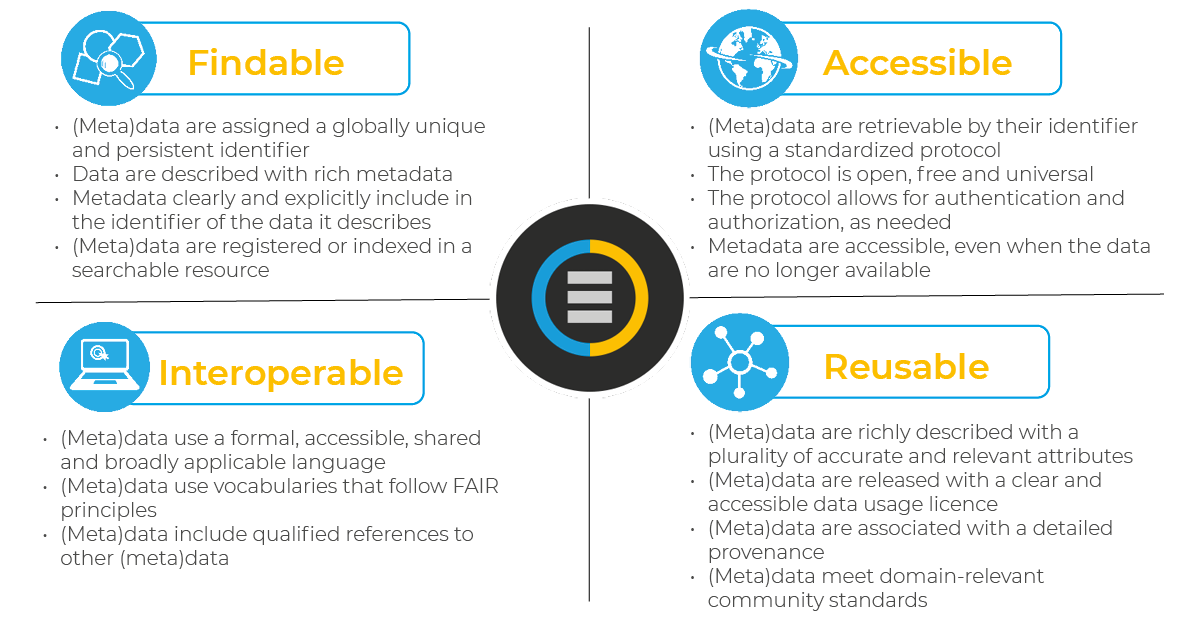
Figure 1. FAIR principles brief description (the picture was taken from 1, 26.04.2024)
Thus, four FAIR principles are distinguished (below are short descriptions of each principle summarizing the key message):
- Findability: For data to be findable there must be sufficient metadata and a unique and persistent identifier.
- Accessibility: metadata and data should be readable by humans and by machines, and it must reside in a trusted repository
- Interoperability: must share a common structure, and metadata must use recognized, formal terminologies for description
- Reusability: Data and collections must have clear usage licenses and clear provenance
This section presents the first version of the draft strategy that is proposed to be applied to the original metadata.
The aim: To develop a strategy for the establishment of Kilpisjärvi, Lammi and Tvärminne stations
over the next five years in accordance with FAIR principles.
In order to achieve the stated objective, the current document has been prepared and the following actions have been performed in the process of its preparation:
- Evaluate the current structure of metadata and datasets (Data Exploration).
- Propose changes to the structure based on the evaluation. Criterion - "Interoperability"
- Propose a plan to improve the "Accessibility" criterion by creating dataset distribution services (API, versioning, etc.).
- Create a plan to improve the "Findability" criterion. For this purpose, it is proposed to use a robust identifier system
- Propose a plan to improve the "Reusability" criterion through license preparation and data provenance
Each of the items is described in more detail below.
Based on the results of a detailed comparison of the metadata dataset columns of different stations, the following table was prepared:
Table 1. Observed issues per metadata dataset
| Column | Issue per Kilpisjärvi station | Issue per Lammi station | Issue per Tvärminne station |
|---|---|---|---|
| Name of the dataset | ✓ | ✓ | ✓ |
| Station | ✓ | ✓ | Presence nan |
| General description of data | Presence nan | Presence nan | Presence nan |
| Location | Presence nan | Presence nan | No data in the column |
| X | No data in the column | Presence nan | No data in the column |
| Y | No data in the column | Presence nan | No data in the column |
| Coordinate system | No data in the column | Presence nan | Presence nan |
| Environment type | ✓ | Presence nan | Presence nan |
| Other type | No data in the column | Environment type column intersection, presence nan | No data in the column |
| Measured variables | Duplicates due to long format | Duplicates due to long format | Duplicates due to long format |
| Unit | Presence nan and "???" | Presence nan | Presence nan |
| Spatial extent | Presence nan, not unified | Presence nan, not unified | Presence nan, not unified |
| Spatial resolution | Not unified | Not unified | Presence nan, not unified |
| Temporal extent | Presence nan, not unified | Presence nan, not unified | Presence nan, not unified |
| Starting year | ✓ | Presence nan, not unified | Presence nan, not unified |
| End year | Mixed types: integer and string | Mixed types: integer and string, presence nan | No data in the column |
| Temporal resolution | Presence nan | Presence nan, not unified | Presence nan |
| Data type | Presence nan | Presence nan | Presence nan |
| Format | Presence nan | Presence nan | Presence nan |
| Is the dataset well described | Expected to be bool | Expected to be bool | Presence nan |
| In what databases the dataset has been described | Presence nan | Presence nan | Presence nan |
| Is the dataset regurlarly shared somewhere | Presence nan | Presence nan | Presence nan |
| Is the data used in a publication | Presence nan | Presence nan | Presence nan, not unified |
| Where | Presence nan | No data in the column | No data in the column |
| Owner | Presence nan and "?" | Presence nan | Presence nan |
| Other notes | ✓ | ✓ | ✓ |
| Contact person | Presence nan | Presence nan | Presence nan |
| Institution | Presence nan | No data in the column | No data in the column |
| KBS, omat muistiinpanot | Presence nan | Not exist | Not exist |
| LBA notes | Not exist | Presence nan | Not exist |
Thus, a set of actions is required to improve the metadata structure.
Based on the results of the analysis of the table structure of the xlsx page of the file Kilpisjärvi, Lammi, Tvärminne it is proposed to perform the following actions, which will make the metadata structure more simple, understandable and comparable:
Stationcolumn: It is required to enter station identifiers into the table (for station Tvärminne) and prepare a separate document listing all possible identifiers for each station abbreviationGeneral description of datacolumn: Need to fill in the gaps for stations Kilpisjärvi, Lammi and TvärminneLocationcolumn: Need to fill in the gaps for stations Kilpisjärvi, Lammi and TvärminneX,YandCoordinate systemcolumns: it is proposed to indicate WGS84 coordinates everywhere instead of local metric systems (this will allow users to find a point more easily in both Google maps and other ones, as well as such coordinates are much easier to understand than multi-cypher coordinates from metric systems). Regardless of whether WGS84 will be used or not, it is necessary to keep the coordinates of all stations in one coordinate reference system and projectionEnvironment type,Other typecolumns: It is proposed to merge these columns and add a category such as “other” to theEnvironment typecolumnMeasured variablescolumn: to save space, consider presenting the table in long format instead of wide one (see Figure 1)
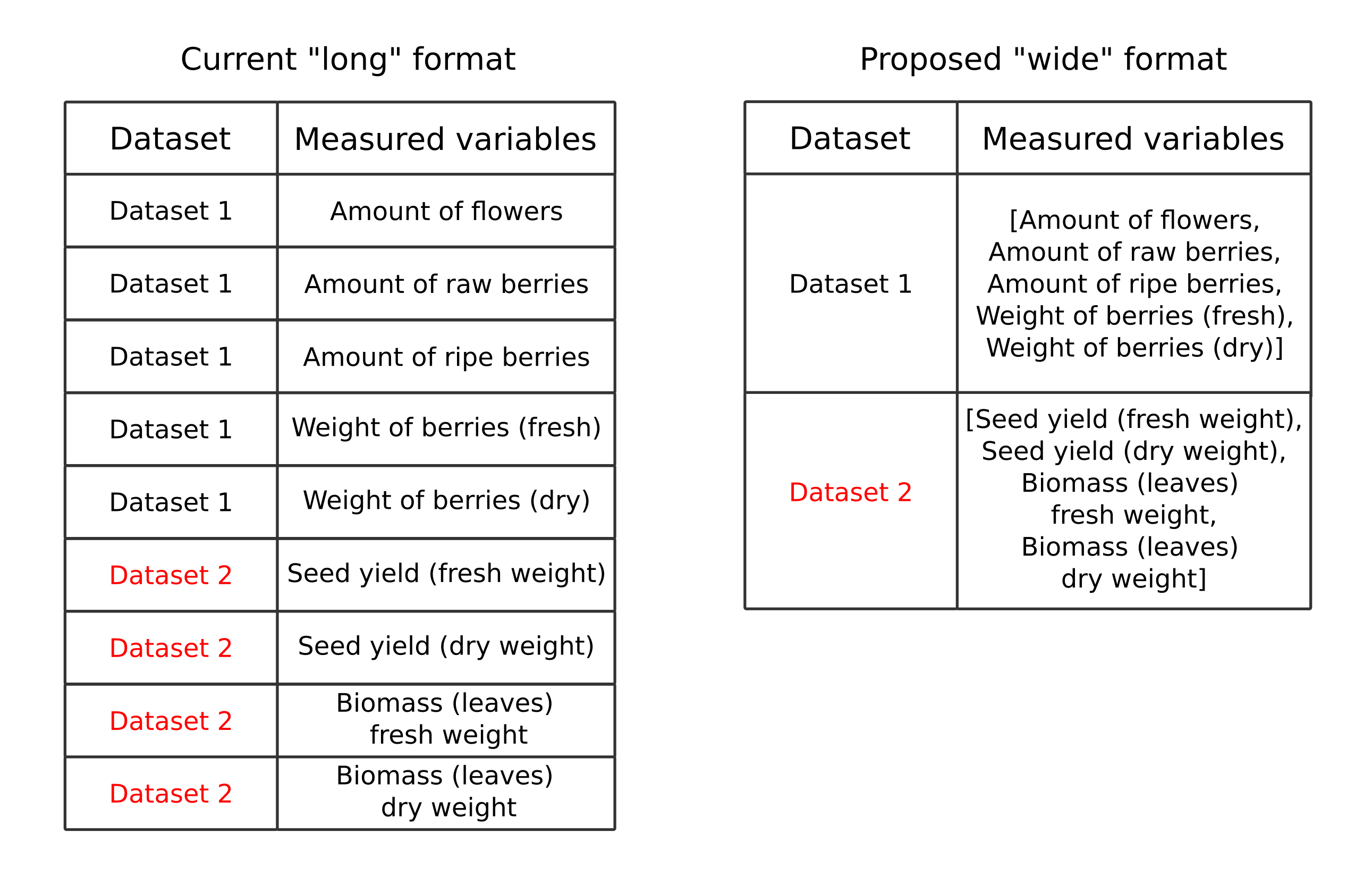
Figure 1. Wide format into long format for the column Measured variables transformation
Unitcolumn: Need to fill the gaps for stations Kilpisjärvi, Lammi and Tvärminne. If the value is dimensionless quantity, this must be specified explicitly. nan should not be in this columnSpatial extentcolumn: Need to fill the gaps for stations Kilpisjärvi, Lammi and Tvärminne. Unification needed. Perhaps the presence of this column is redundant and its role is already fulfilled by such fields as X, Y and Location. If we assume that the column is to be saved, then it makes sense to store spatial coverage in it using bounding box coordinates instead of places nameSpatial resolutioncolumn: Need to fill the gaps for station Tvärminne. It is necessary to unify, for example, to present all information in two possible variants: meters and centimeters.Temporal extentcolumn: Need to fill the gaps for stations Kilpisjärvi, Lammi and Tvärminne. Unification needed: some cells indicate the dates of monitoring, others the durationStarting yearcolumn: Need to fill the gaps for stations Kilpisjärvi, Lammi and Tvärminne. Unification needed: replace "noin 1970" with 1970 so only integers will be in the column, etc.End yearcolumn: Need to fill the gaps for stations Lammi and Tvärminne. Unification needed: it is better to avoid presence in one column integer values and "ongoing" stringTemporal resolutioncolumn: Need to fill the gaps for stations Kilpisjärvi, Lammi and Tvärminne. A unified system for specifying the discreteness of observations should be developedData typecolumn: Need to fill the gaps for stations Kilpisjärvi, Lammi and TvärminneFormatcolumn: Need to fill the gaps for stations Kilpisjärvi, Lammi and TvärminneIs the dataset well describedcolumn: Make the column take only two values: True or FalseIn what databases the dataset has been describedcolumn: Need to fill the gaps for stations Kilpisjärvi, Lammi and TvärminneIs the dataset regurlarly shared somewherecolumn: Make the column take only two values: True or FalseIs the data used in a publicationcolumn: Make the column take only two values: True or FalseWherecolumn: Each cell can have either None or a list with links to publications so that more than one can be specifiedOwnerand other column: Need to fill the gaps for stations Kilpisjärvi, Lammi and Tvärminne if required
General suggestions for improving interoperability:
- Allow datasets to be downloaded in multiple formats, or allow the user to interact with the data through a REST API. Possible examples: Parquet, CSV, Excel, JSON, GEOJSON, Geopackage, shapefile. Converters of tabular data to such formats can be reused in other data catalogs.
All proposed changes are planned to be implemented in a step-by-step collaboration with representatives of the institutions that own the datasets that are described in this metadata.
Example of the station Kilpisjärvi sample with applied changes: https://docs.google.com/spreadsheets/d/1_a6_xrBO5CZ2aykT4Y5Dj_eqIYBIUGOE/edit?usp=sharing&ouid=117425651530373612251&rtpof=true&sd=true
To make data accessible in the modern digital world, it is proposed to build a datahub ecosystem where data can be accessed using two modes:
- Manual downloading of datasets in desired format;
- Data request via REST API
Implementation of both ways of interaction requires implementation and deployment of the backend service. An example of
such a service implemented using the technology stack Python, Docker, heroku platform: API environmental monitoring service
Service versioning should be prepared for researchers and engineers. For example, when providing API access to a data platform, both semantic versioning of datasets, as well as the API of the service. Then, when changing the data structure, using old references and methods, researchers will be able to get the same datasets.
The following examples of data platforms can be used as references:
- http://dataportal.saeri.org/ - Falklands islands data catalog
- https://geo.ca/home/ - Canada’s open geospatial information
Persistent identifiers are required for Findability. Ensuring the availability of such identifiers is proposed through the use of DOIs. This will also allow such data to be easily used and cited in scientific publications.
Example of data platforms that uses DOI generation:
- https://techdocs.gbif.org/en/ - Global Biodiversity Information Facility (GBIF)
- https://doi.org/10.15468/dl.f487j5 - GBIF.org (20 October 2023) GBIF Occurrence Download
The following systems are used to search for datasets (in addition to standard search engines like Google, Bing, etc.):
Therefore, it is planned to prepare datasets in such a way that they are easily accessible also using these platforms.
The final processing activities should be the preparation of license documents and verification that the data have a clear provenance. To ensure Reusability, it is also necessary to describe in detail the structure of the datasets provided. This can be done by means of a single web page (as a simplified example) - see environmental-monitoring description page
The findings of the study were:
- Strategy for the construction of an environmental monitoring scientific data distribution system for Kilpisjärvi, Lammi and Tvärminne stations according to FAIR principles;
- Recommendations for improving the station metadata structure and a sample with applied changes;
- Prototype web page providing information on how to retrieve data on selected stations and with which licenses;
- Prototype of a web service that allows using REST API to get meta-information about stations. On the basis of this backend service it will be possible to customize the systems for downloading datasets and metadata for them.
- CCDC FAIR data principles
- Open and FAIR data sharing policy related to writing
- Common Data Elements: Standardizing Data Collection. Data Definition of FAIR Data
Document was prepared by Mikhail Sarafanov 28.04.2024
Current module deployed on Heroku using the following instructions:
Deploy FastAPI on Heroku using Docker Container
heroku login
Launch docker daemon and then
heroku container:login
heroku container:push web --app environmental-monitoring
heroku container:release web --app environmental-monitoring
Swagger UI available via URL: https://environmental-monitoring-82bc1f9868c5.herokuapp.com/
login:universitypassword:university
For local launch there is a need to start launch.py

