This repository is an application of the SiamMask object tracking and segmentation algorithm presented in the Fast Online Object Tracking and Segmentation: A Unifying Approach paper. We trained and validated the model against different test datasets, and applied it to recycling data.
The model has two stages of training:
- Rough tracking.
- Segmentation mask refinement.
In each stage, we trained the model on the supplied datasets and selected the best model for each. For rough tracking, the best model was the model that had the most amount of frames where the predicted bounding box overlapped with the ground-truth bounding box. The segmentation mask refinement model was selected based on the intersection-over-union (IOU) value. We applied this model to the DAVIS test dataset and the recycling data.
For general instructions on how to run the code, please go to https://github.com/foolwood/SiamMask. For this project, we have modified the code to run on BU's Shared Computing Cluster (SCC). The instructions below are specific to the SCC.
You need a machine with at least 1 GPU. We trained with 2 V100 GPUs. Testing is possible without a GPU, but it will not achieve real time performance.
On the SCC, load anaconda with
module load miniconda
Initialize the conda enviornment.
conda create -n siammask python=3.6
source activate siammask
pip install -r requirements.txt
bash make.sh
export PYTHONPATH=$PWD:$PYTHONPATH
For both first and second stage training, we use three datasets: Youtube-VOS, ImageNet-VID, and COCO datasets. Youtube-VOS is small. COCO and ImageNet-VID datasets are around 50 GB each. Each of these datasets contain many small files. It is IMPORTANT that you unzip these files in a LOCAL disk and then convert to .tar file for future use. On the SCC, use the scratch disk for this purpose.
Instructions for downloading each of the datasets can be found in the following three folders:
data/vid
data/coco
data/ytb_vos
modify experiments/siammask_base/config.json to point to the copy of the data you have locally (on the scratch disk).
You can use copy_data.sh to copy data from a file share. It is important to group files into one tar file when copying to and from a file share.
For the first stage of training, download a pre-trained res-net:
cd experiments
wget http://www.robots.ox.ac.uk/~qwang/resnet.model
ls | grep siam | xargs -I {} cp resnet.model {}
Use the following command to start the first stage of training:
experiments/siammask_base/
bash run.sh
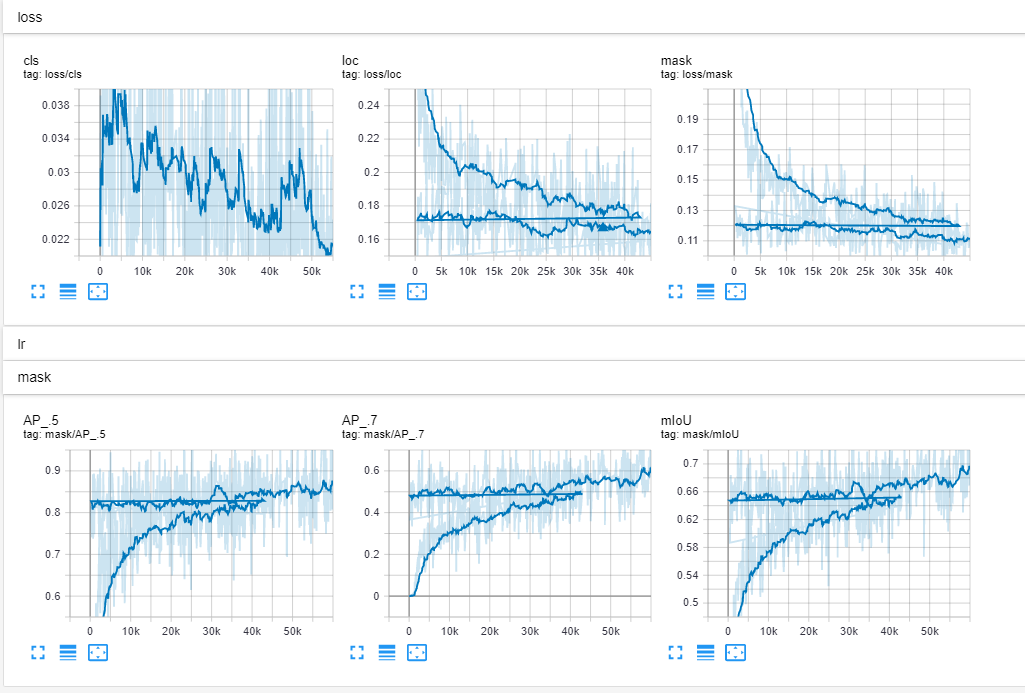
For us it took 10 hours to train 20 epochs on 2 V100 GPUs. However, it may not be necessary to train the model for more than ~10 epochs. Please see our validation plot for reference.
Tensor board files will appear in experiments/siammask_base/board. You should see plots that look like this (Note that our training was interrupted around epoch 9, so you see a discontinuity in the plots):
Download validation data using data/get_test_data.sh. We used VOT2018 data for validation of first stage model.
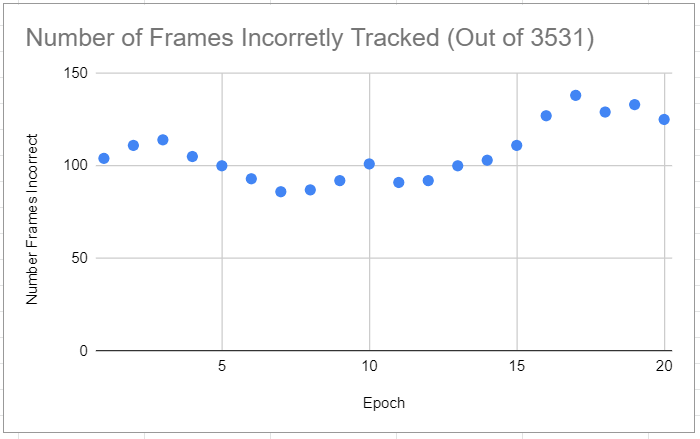
Modify and use the bash script experiments/siammask_base/test_all_mine.sh to validate the first stage models. This bash script generates statistics on how many frames of the validation videos where the predicted bounding box does not overlap with the ground-truth bounding box. Choose the model with the lowest number of frames lost.
Validation results:
The following image is a visualization of the ouputs of the Siammask model. The siammask model outputs some number of "region proposals". A region propopsal consists of a segmentation mask, the corresponding minimum bounding rectange, and a score. A subset of these proposed regions are shown in yellow in the image. The region proposal with the highest score is highlighted in green. In the first stage, we are only concerned about getting the region roughly correct; the second stage will fine-tune. This example should help you understand what is happening under-the-hood.

For the second stage of training, we use the Youtube-VOS and COCO datasets. Edit the config.json file in experiements/siammask_sharp/config.json to point to the path of the datasets on your local disk.
Copy your best checkpoint from the first stage model to the experiments/siammask_sharp directory. The model in the second stage will be initialized with the weights from the first stage model. Run the following to train the second stage model. In our case, the accuracy of the model did not improve significantly on validation data after the first few epochs of training. Around 10 epochs of training should be sufficient.
cd experiments/siammask_sharp
bash run.sh checkpoint_e10.pth
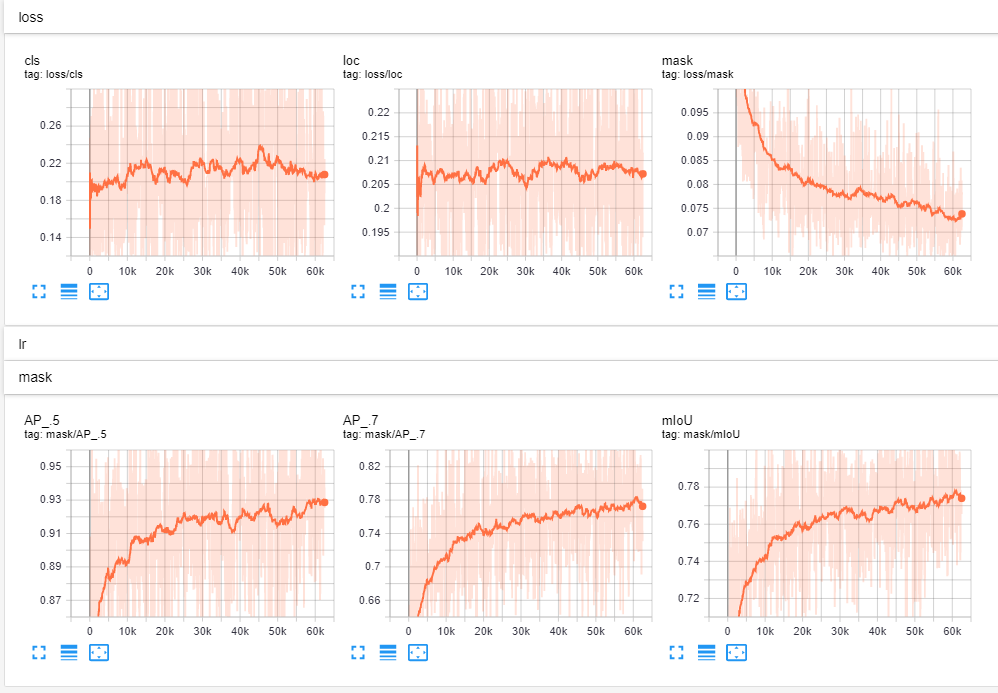
This stage of training only trains the mask branch of the siammask network, so only mask loss decreases over training iterations.
Tensor board files will appear in experiments/siammask_sharp/board. You should see plots that look like this (Note that only the mask loss decreases becuase stage 2 training is only concerned with improving segmentation mask):
After training, download the DAVIS 2016 or 2017 data. We used the DAVIS2017 training data for validation of the second stage model and the DAVIS2017 validation data for testing of the second stage model.
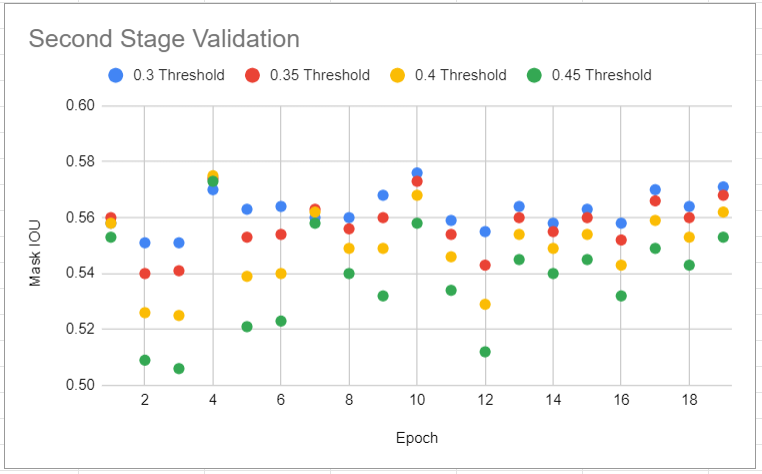
Use the script here: experiments/siammask_sharp/test_all_mine_1.sh to generate the IOU metrics for the second stage model checkpoints (for each segmentation mask threshold setting). Pick the model and threshold with the largest average IOU.
Validation results:
You can use the same bash script on the chosen model to generate results on the test data. Our results are included below and in the results directory.
Average IOU: 0.643 Standard Deviation: 0.182
All results are located in results folder.
The standard deviation seems relatively high. In some of the test cases the model performed very well, but in others it performed poorly.
(Note that there is a different measure of segmentation accuracy called F-measure. This measures the similarity of two contours. We do not report the F-measure results because we do not train the neural network to optimize for this metric. Therefore, the F-measure/contour accuracy is not as relevant to our project. Generally, you should expect our model to perform quite pourly with respect to contour accuracy due to loss of contour detail in the segmentation mask.)
Below are the results across the 30 different test videos of DAVIS2017 test set:

Generally, the Siammask model performs well under the following conditions:
- Only one instance of object being tracked (even if that object changes shape or orientation).





Generally, the Siammask model performs badly under the following conditions:
- Multiple instances of objects/animals/people being tracked.
- Too much detail in the segmentation (e.g. strings).
- Similar objects to the object being tracked are present in the scene.
- "ill-defined" segmentations. For example, if a person is wearing different colored shirt and pants, the model may only track the pants or the shirt becuase they are individually better segmentations. Or for exmaple, if the object has similar color and texture to the background, the model may fail to produce a good segmentation mask.
It is unclear whether the above failure cases can be attributed to the trainging data or the model architecture/parameters. The distribution of the DAVIS data is different from the distribution of the training data (There are very few training examples provided with the DAVIS data).
In order to improve the accuracy for these cases, we need more similar training data. We should also re-examine how the model produces a segmentation mask to address the loss of detail issue.


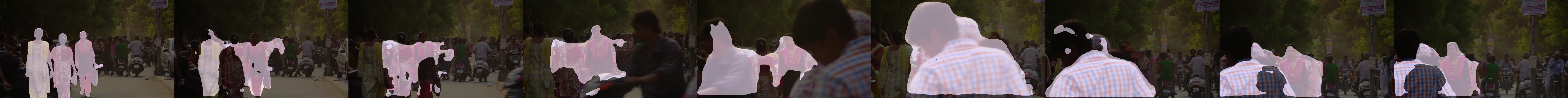


For the recycling data, there was no ground-truth to make a quantitative measurement against. Instead we looked at the segmentation results qualitatively. The model seems to perform decently, but the image blurring from the supplied video seems to negatively affect the tracking. Additionally, the objects in the video are cluttered and have similar texture, making accurate segmentation difficult.
To select an object to track, we used the supplied GUI object selector from the SiamMask repository.
In the following examples, the first image is given. The blue box outlines the object we want to track. We display the tracking result every ten frames. The red transparency mask represents the predicted tracking mask, and the green outline represents the minimum bounding box.
First two examples where our tracking/segmentation was bad:
(1) Tracking initialized with half of the piece of paper. When the piece of paper comes into full view, the model is still able to track it. However, after a few frames, the model loses track of the paper.


(2) In this example, out tracker is unable to distinguish between different pieces of crumpled paper.


Here are two examples where out model performs well:
(1) Tracking a crumbled piece of paper.


(2) Tracking a plastic bottle.


The recycling dataset was easy in the sense that the objects being tracked do not change shape or orientation throughout the video. However, the recycling dataset is challenging in the sense that (1) the frames are blurry, (2) the objects have irregular shapes, and (3) many similar instances of objects exist in the scene (such as crumpled pieces of paper). These factors contribute to unreliability of our model in this case.
Q. Wang, L. Zhang, L. Bertinetto, W. Hu and P. H. S. Torr, "Fast Online Object Tracking and Segmentation: A Unifying Approach," 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 1328-1338, doi: 10.1109/CVPR.2019.00142.
Q. Wang, L. Zhang, L. Bertinetto (2019) SiamMask [Source code]. https://github.com/foolwood/SiamMask




