dpc10ster / rjafroc Goto Github PK
View Code? Open in Web Editor NEWArtificial Intelligence: Evaluating AI, optimizing AI
Artificial Intelligence: Evaluating AI, optimizing AI



















Hi,
Thank you for a wonderful package. I'm having issues with the below, and I'm not sure if it's just me not fully understanding what the package is doing, but when I do the following everything works as expected:
library(RJafroc)
g1 <- c(2, 3, 5, 6)
g2 <- c(0, 4, 7, 11)
d <- Df2RJafrocDataset(g1, g2, InputIsCountsTable = TRUE)
FitBinormalRoc(d)
#> $a
#> [1] 0.4173326
#>
#> $b
#> [1] 1.54108
#>
#> $zetas
#> zetaFwd1 zetaFwd2 zetaFwd3
#> -1.2324185 -0.3781095 0.2846961
#>
#> $AUC
#> [1] 0.5898541
#>
#> $StdAUC
#> [,1]
#> [1,] 0.1112752
#>
#> $NLLIni
#> [1] 45.46533
#>
#> $NLLFin
#> [1] 43.89465
#>
#> $ChisqrFitStats
#> $ChisqrFitStats$chisq
#> [1] NA
#>
#> $ChisqrFitStats$pVal
#> [1] NA
#>
#> $ChisqrFitStats$df
#> [1] NA
#>
#>
#> $covMat
#> a b zeta1 zeta2 zeta3
#> a 0.24601253 -0.03899557 0.08269791 0.11267253 0.12881384
#> b -0.03899557 0.42737122 0.10931400 0.05024462 -0.07684782
#> zeta1 0.08269791 0.10931400 0.16832791 0.07548285 0.03444080
#> zeta2 0.11267253 0.05024462 0.07548285 0.09238670 0.06247600
#> zeta3 0.12881384 -0.07684782 0.03444080 0.06247600 0.09822176
#>
#> $fittedPlotBut this is actually the exact opposite of what I want. When I try flipping the groups, however, I get an error with optim. I did a fair amount of digging into this and it seems to be coming from the internal ForwardValue function producing NaN, but can't fully understand why.
d2 <- Df2RJafrocDataset(g2, g1, InputIsCountsTable = TRUE)
FitBinormalRoc(d2)
#> Error in optim(par = c(aFwd = NaN, bFwd = 0.927966089318001, zetaFwd1 = -3.90053641225537, : non-finite value supplied by optimI would have expected that I would just get the inverse AUC. For example
library(tidyverse)
cumm_prop <- data.frame(index = seq_along(g1), g1, g2) %>%
pivot_longer(cols = -index) %>%
group_by(name) %>%
mutate(cs = cumsum(value),
prop = cs / sum(value)) %>%
select(index, name, prop) %>%
pivot_wider(names_from = name, values_from = prop)
ggplot(cumm_prop, aes(g1, g2)) +
geom_line() +
geom_abline(intercept = 0, slope = 1, color = "gray") +
xlim(0, 1)ggplot(cumm_prop, aes(g2, g1)) +
geom_line() +
geom_abline(intercept = 0, slope = 1, color = "gray") +
ylim(0, 1)Any help would be greatly appreciated. If you'd rather me post this issue on stack overflow or similar, I'd be happy to do that.
Created on 2020-04-14 by the reprex package (v0.3.0)
Xcode is generating a "significant" warning after recent MacOS upgrade to 12.6.1 (21G217) when I build Cpp code in this package. See commit message in 5cdb9f3. The warning is (you need to scroll horizontally to see the whole message):
Found the following significant warnings:
/Library/Frameworks/R.framework/Versions/4.2/Resources/library/Rcpp/include/Rcpp/internal/r_coerce.h:255:7: warning: 'sprintf' is deprecated: This function is provided for compatibility reasons only. Due to security concerns inherent in the design of sprintf(3), it is highly recommended that you use snprintf(3) instead. [-Wdeprecated-declarations]
See ‘/Users/Dev/GitHub/RJafroc.Rcheck/00install.out’ for details.
I do not use sprintf in my code; it appears to be called in a header file(s) that I have to include to compile my code. This warning does not occur in an iMac running an older version of OSX (Catalina) and Xcode.
It occurs only on Mac OS 12.6.1 which comes with Xcode 14.1.
Delete Xcode 14.1 in Applications folder
Restore older version (July 11, 2022) from TimeMachine (my fix assumes you are using TimeMachine).
Restored Version is: 13.4.1 (13F100)
pkgdown #122: Commit 94d4df1 pushed by dpc10ste
This was fixed by replacing existing pkgdown workflow file with one from here
No idea why previous version was failing. Would appreciate an explanation. @pwep
! error in pak subprocess
Caused by error:
! Could not solve package dependencies:
Backtrace:
Subprocess backtrace:
##stop("ROI paradigm not yet implemented")
ROI data is not yet implemented; it always returns FALSEThis is output with chk4 <- rhub::check(packagePath, platform = platforms[[1]][4]) :
E checking package dependencies (3.3s)
Package required but not available: ‘readxl’
Packages suggested but not available: 'testthat', 'kableExtra'
The suggested packages are required for a complete check.
Checking can be attempted without them by setting the environment
variable _R_CHECK_FORCE_SUGGESTS_ to a false value.
See section ‘The DESCRIPTION file’ in the ‘Writing R Extensions’
manual.
Same error with chk4 <- rhub::check(packagePath, platform = platforms[[1]][5]) :
Email from an user cited inconsistent values of K (total number of cases) when using code with FOM = "HrSe" (or FOM = "HrSp"). Edited excerpts from email follow:
...issue with
RJafrocv2.1.2: functionStSignificanceTesting, withFOM = “HrSe”,method = ”DBM”andanalysisOption = "RRRC", calls functionUtilVarComponentsDBMwhereKis calculated using the length of the third dimension of the pseudo-value array, which in this case is the total number of diseased cases, i.e.,K = K2. This is correct as only diseased cases contribute to sensitivity. However, when calculating the statistics using functionDBMSummaryRRRC()thenK = K1+K2, i.e., the total number of cases, which is incorrect.
This bug affects all FOMs that depend on only diseased or only non-diseased cases, fortunately a rare usage of the software.
Here is the relevant history of the software:
There was a change in maintainer between version 0.0.1 and all subsequent versions. The first version was was coded by a excellent programmer (Xuetong Zhai). However his coding style was different from Dr. Chakraborty which was making it difficult for him to maintain and extend the code.
The StSignificanceTesting function was extensively recoded. To guard against errors creeping I inserted 'testthat' testing functions that compared the new values against the original values. The comparisons depended on the dataset, the figure of merit and the analysis method, see skeleton code below. Only the most commonly used FOMs were tested and unfortunately these did not include all FOMs that depend on only diseased or only non-diseased cases (these FOMs are not recommended by Dr. Chakraborty but some users still need them due to FDA imposed requirement).
Following the email the original code (which had a few remaining bugs) was corrected. The current code was also corrected to remove the discrepancy noted in the email and other bugs. Finally testthat function tests were included to check the consistency between the corrected original code and the current version. Here is the skeleton code showing the testing conditions:
dataset_arr <- c("dataset02", "dataset05")
FOM_arr <- c("Wilcoxon", "HrAuc", "wAFROC","AFROC", "wAFROC1","AFROC1",
"MaxLLF","MaxNLF","MaxNLFAllCases", "ExpTrnsfmSp", "HrSp", "HrSe")
...
...
analysisOption = "RRRC"
...
...
analysisOption = "FRRC"
...
...
analysisOption = "RRFC"
The two testing functions are (you need to fork the repository to see these functions):
~/GitHub/RJafroc/tests/testthat/test-OldVsNew-DBM.R for the DBM method
and
~/GitHub/RJafroc/tests/testthat/test-OldVsNew-OR.R for the OR method.
All corrections have been pushed to the master branch. The corrected old code is still there but is no longer visible in the HTML documentation. It is in the following file:
~/GitHub/RJafroc/R/StOldCode.R
A new CRAN submission is being prepared that will implement all bug-fixes. Anticipated submission date is approximately 9/30/2023. Until then users should download or fork the master branch.
I appreciate the sender of the email for the effort that went into detection of this bug and would encourage anyone to closely examine the code. All significant bug detections will be acknowledged.
The expect_known_output function produces a warning the first time a file is created. This is expected behaviour but fills the testthat output with multiple (and redundant) warnings. It should be possible to wrap the first call of expect_known_output with expect_warning.
Example:
test_that("DfBinDatasetAFROC", {
tmp <- tempfile()
expect_warning( # Expect a warning to be generated...
expect_known_output(
DfBinDataset(dataset05, opChType = "AFROC"),
tmp, print = TRUE),
"Creating reference output") # ...with a message matching this string
expect_known_output(
DfBinDataset(dataset05, opChType = "AFROC"),
tmp, print = TRUE)
})
Hello Professor, I think you are an expert in evaluation JAFROC, I have seen a lot of resources on your github. I would like to ask if you have the JAFROC that implement in Python version?, because nowadays many AI models are built in Python, which I'm working on, so it's very convenient if an algorithm like JAFROC can be used with Python. Do you plan on developing it with Python?
Thank you so much.
Four structural errors in test-significance-testing.R for the following combinations:
| Dataset | FOM | Method |
|---|---|---|
| dataset02 | Wilcoxon | DBMH |
| dataset02 | Wilcoxon | ORH |
| dataset05 | HrAuc | DBMH |
| dataset05 | HrAuc | ORH |
✖ | 7 4 | Significance testing excluding CAD [8.7 s]
────────────────────────────────────────────────────────────────────────────────
test-significance-testing.R:41: failure: SignificanceTestingAllCombinations
`ret1` not equal to `ret`.
Component "ciAvgRdrEachTrtRRRC": Component "StdErr": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtRRRC": Component "StdErr": target is numeric, current is array
Component "ciAvgRdrEachTrtRRRC": Component "DF": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtRRRC": Component "DF": target is numeric, current is array
Component "ciAvgRdrEachTrtFRRC": Component "StdErr": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtFRRC": Component "StdErr": target is numeric, current is array
Component "ciAvgRdrEachTrtFRRC": Component "DF": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtFRRC": Component "DF": target is numeric, current is array
Component "ciAvgRdrEachTrtRRFC": Component "StdErr": Attributes: < target is NULL, current is list >
...
Dataset = dataset02, FOM = Wilcoxon, method = DBMH
test-significance-testing.R:41: failure: SignificanceTestingAllCombinations
`ret1` not equal to `ret`.
Component "ciAvgRdrEachTrtRRRC": Component "StdErr": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtRRRC": Component "StdErr": target is numeric, current is array
Component "ciAvgRdrEachTrtRRRC": Component "DF": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtRRRC": Component "DF": target is numeric, current is array
Component "ciAvgRdrEachTrtFRRC": Component "StdErr": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtFRRC": Component "StdErr": target is numeric, current is array
Component "ciAvgRdrEachTrtFRRC": Component "DF": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtFRRC": Component "DF": target is numeric, current is array
Component "ciAvgRdrEachTrtRRFC": Component "StdErr": Attributes: < target is NULL, current is list >
...
Dataset = dataset02, FOM = Wilcoxon, method = ORH
test-significance-testing.R:41: failure: SignificanceTestingAllCombinations
`ret1` not equal to `ret`.
Component "ciAvgRdrEachTrtRRRC": Component "StdErr": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtRRRC": Component "StdErr": target is numeric, current is array
Component "ciAvgRdrEachTrtRRRC": Component "DF": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtRRRC": Component "DF": target is numeric, current is array
Component "ciAvgRdrEachTrtFRRC": Component "StdErr": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtFRRC": Component "StdErr": target is numeric, current is array
Component "ciAvgRdrEachTrtFRRC": Component "DF": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtFRRC": Component "DF": target is numeric, current is array
Component "ciAvgRdrEachTrtRRFC": Component "StdErr": Attributes: < target is NULL, current is list >
...
Dataset = dataset05, FOM = HrAuc, method = DBMH
test-significance-testing.R:41: failure: SignificanceTestingAllCombinations
`ret1` not equal to `ret`.
Component "ciAvgRdrEachTrtRRRC": Component "StdErr": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtRRRC": Component "StdErr": target is numeric, current is array
Component "ciAvgRdrEachTrtRRRC": Component "DF": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtRRRC": Component "DF": target is numeric, current is array
Component "ciAvgRdrEachTrtFRRC": Component "StdErr": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtFRRC": Component "StdErr": target is numeric, current is array
Component "ciAvgRdrEachTrtFRRC": Component "DF": Attributes: < target is NULL, current is list >
Component "ciAvgRdrEachTrtFRRC": Component "DF": target is numeric, current is array
Component "ciAvgRdrEachTrtRRFC": Component "StdErr": Attributes: < target is NULL, current is list >
...
Dataset = dataset05, FOM = HrAuc, method = ORH
────────────────────────────────────────────────────────────────────────────────
❯ devtools::check(run_dont_test = TRUE)
❯ checking installed package size ... NOTE
installed size is 6.1Mb
sub-directories of 1Mb or more:
doc 2.1Mb
sas 1.1Mb
0 errors ✔ | 1 warning ✖ | 1 note ✖
Can ignore for now, but eventually all vignettes need to be moved to RJafrocBook. Move all tests to non-CRAN version. Can SAS results be distilled to smaller files?
Other ideas: move datasets to a website; move SAS part to a website;
Sorry to raise this issue at this late hour ...
I am not sure that I am using this function correctly.
The first call to expect_know_output() writes the output (of the function being tested) to a temporary file and generates a message "Creating reference output" or something to that effect.
The second call generates new output and compares it to the contents of the temporary file.
In looking at the testthat package code it is clear that, on the first call, it checks if the temporary file already exists and if so it does not overwrite it. That would be a legitimate test as then one would be comparing newly generated output with previously saved "good output".
When run on Travis, the temporary file does not exist, so the code generates output and writes to the file and then compares the contents of the file to newly generated values, which are guaranteed to be identical. If so the test is meaningless.
The documentation of testthat states:
These expectations should be used in conjunction with git, as otherwise there is no way to revert to previous values. Git is particularly useful in conjunction with expect_known_output() as the diffs will show you exactly what has changed.
This implies the temporary file should be under Git control - which is definitely not the case on my machine. For example, a typical value for temple() is:
> tempfile()
[1] "/var/folders/d1/mx6dcbzx3v39r260458z2b200000gn/T//Rtmp7poTqc/file8ba9775dd8fe"
I have searched the web in vain for an example of how to use expect_know_output() with Git.
I can't believe that no one has commented on this. Am I barking up the wrong tree?
devtools::check()using log directory ‘/Users/Dev/Documents/GitHub/RJafroc.Rcheck’
using R version 3.6.0 (2019-04-26)
using platform: x86_64-apple-darwin15.6.0 (64-bit)
using session charset: UTF-8
using options ‘--no-manual --no-build-vignettes --as-cran’
checking for file ‘RJafroc/DESCRIPTION’ ... OK
checking extension type ... Package
this is package ‘RJafroc’ version ‘1.1.1.9000’
package encoding: UTF-8
checking package namespace information ... OK
checking package dependencies ... OK
checking if this is a source package ... OK
checking if there is a namespace ... OK
checking for executable files ... OK
checking for hidden files and directories ... OK
checking for portable file names ... OK
checking for sufficient/correct file permissions ... OK
checking whether package ‘RJafroc’ can be installed ... OK
checking installed package size ... OK
checking package directory ... OK
checking for future file timestamps ... OK
checking ‘build’ directory ... OK
checking DESCRIPTION meta-information ... OK
checking top-level files ... OK
checking for left-over files ... OK
checking index information ... OK
checking package subdirectories ... OK
checking R files for non-ASCII characters ... OK
checking R files for syntax errors ... OK
checking whether the package can be loaded ... OK
checking whether the package can be loaded with stated dependencies ... OK
checking whether the package can be unloaded cleanly ... OK
checking whether the namespace can be loaded with stated dependencies ... OK
checking whether the namespace can be unloaded cleanly ... OK
checking dependencies in R code ... OK
checking S3 generic/method consistency ... OK
checking replacement functions ... OK
checking foreign function calls ... OK
checking R code for possible problems ... OK
checking Rd files ... OK
checking Rd metadata ... OK
checking Rd line widths ... OK
checking Rd cross-references ... OK
checking for missing documentation entries ... OK
checking for code/documentation mismatches ... OK
checking Rd \usage sections ... OK
checking Rd contents ... OK
checking for unstated dependencies in examples ... OK
checking contents of ‘data’ directory ... OK
checking data for non-ASCII characters ... OK
checking data for ASCII and uncompressed saves ... OK
checking line endings in C/C++/Fortran sources/headers ... OK
checking pragmas in C/C++ headers and code ... OK
checking compilation flags used ... OK
checking compiled code ... OK
checking installed files from ‘inst/doc’ ... OK
checking files in ‘vignettes’ ... OK
checking examples ... OK
checking for unstated dependencies in ‘tests’ ... OK
checking tests ... ERROR
Running ‘testthat.R’
Running the tests in ‘tests/testthat.R’ failed.
Last 13 lines of output:
══ testthat results ══════════════════════════════════
OK: 50 SKIPPED: 0 WARNINGS: 0 FAILED: 10
Error: testthat unit tests failed
Execution halted
checking for unstated dependencies in vignettes ... OK
checking package vignettes in ‘inst/doc’ ... OK
checking running R code from vignettes ... NONE
checking re-building of vignette outputs ... SKIPPED
DONE
Status: 1 ERROR
This used to pass; now testthat fails for two test files, but only on Ubuntu:
test-PlotEmpiricalOperatingCharacteristics.R
test-predicted-plots.R
A user noted a discrepancy in the variance components reported by StSignificanceTesting().
Just updated Friday: This is on 8d0313c. The file is cran-comments.md. The branch is cran210.
I plan to submit to CRAN on Monday (7/25/22).
Currently ReaderID, ModalityID are allowed to be strings; this creates problems when using them as array indices, necessarily integers.
What to do?
Version 2.0.0
On new branch cran3
Merge process: developer -> master -> cran3
Removed tests and vignettes
Passes R CMD check on OS X
Hi Peter,
I am out of credits on Travis; I will need to be more careful in future on when to use the allowed credits.
I tried installing R and RStudio on my OSX based virtual machine running Windows 8 but they failed to run.
I think I will use the rhub website to periodically check the software. It should work for RJafroc but I am not sure about RJafrocBook.
Maybe I should get a Windows machine? Hate to step down from the Mac.
Any ideas?
PS: their prices are atrocious: $69 per month!
Hi
We preparing the next release of ggplot2 and our reverse dependency checks show that your package is failing with the new version. Looking into it we see that your package reaches into the internal structure of ggplot2 and those have changed in the new version.
You can install the release candidate of ggplot2 using devtools::install_github('tidyverse/[email protected]') to test this out.
We plan to submit ggplot2 by the end of October and hope you can have a fix ready before then
Kind regards
Thomas
Hi,
I am trying to import an excel sheet in which no control exists.
That means all cases include at least one lesion in each- all cases have lesion ID with 1 or more in "Truth" sheet.
DfReadDataFile does not work on this sheet and return error below:
Error in [<-(*tmp*, , , k2 + K1, (1:lesionVector[k2]) + 1, value = 1) :
subscript out of bounds
Could you help me to solve this problem?
File inst\cranSubmission\cranSubmission.R is same as in previous issue (rhub check failures 2 of xx on cran4a branch).
Code for this issue is on branch cran4b.
The difference is in file SsFrocNhRsmModel.R: currently the relevant lines are:
if (sum(lesDistr) != 1.0) {
errMsg <- ""
for (i in 1:length(lesDistr)) errMsg <- paste0(errMsg, sprintf("%10.5f", lesDistr[i]))
errMsg <- paste0("The lesion distribution vector must sum to unity:", errMsg)
stop(errMsg)
}
vs. previous code
chk1 <- abs(sum(lesDistr) - 1.0)
if (chk1 > 1e-5) {
errMsg <- ""
for (i in 1:length(lesDistr)) errMsg <- paste0(errMsg, sprintf("%10.5f", lesDistr[i]))
errMsg <- paste0(errMsg, sprintf(". Difference = %10.5e", chk1))
errMsg <- paste0("The lesion distribution vector must sum to unity:", errMsg)
stop(errMsg)
}
And here is the relevant output:
══ Failed tests ════════════════════════════════════════════════════════════════
── Error (test-SsSampleSizeFroc.R:21:3): Sample Size FROC ──────────────────────
Error in `SsFrocNhRsmModel(frocNhData, lesDistr = lesDistr)`: The lesion distribution vector must sum to unity: 0.70000 0.20000 0.10000
Backtrace:
▆
1. └─RJafroc::SsFrocNhRsmModel(frocNhData, lesDistr = lesDistr) at test-SsSampleSizeFroc.R:21:2
[ FAIL 1 | WARN 1 | SKIP 8 | PASS 1462 ]
Error: Test failures
Execution halted
✔ checking for unstated dependencies in vignettes
✔ checking package vignettes in ‘inst/doc’
─ checking running R code from vignettes
‘Ch19Vig1FrocSampleSize.Rmd’ using ‘UTF-8’... OK
‘Ch19Vig2FrocSampleSize.Rmd’ using ‘UTF-8’... OK
NONE
W checking re-building of vignette outputs (5s)
Error(s) in re-building vignettes:
...
--- re-building ‘Ch19Vig1FrocSampleSize.Rmd’ using rmarkdown
Quitting from lines 145-155 (Ch19Vig1FrocSampleSize.Rmd)
Error: processing vignette 'Ch19Vig1FrocSampleSize.Rmd' failed with diagnostics:
polygon edge not found
--- failed re-building ‘Ch19Vig1FrocSampleSize.Rmd’
--- re-building ‘Ch19Vig2FrocSampleSize.Rmd’ using rmarkdown
Quitting from lines 37-44 (Ch19Vig2FrocSampleSize.Rmd)
Error: processing vignette 'Ch19Vig2FrocSampleSize.Rmd' failed with diagnostics:
The lesion distribution vector must sum to unity: 0.70000 0.20000 0.10000
--- failed re-building ‘Ch19Vig2FrocSampleSize.Rmd’
SUMMARY: processing the following files failed:
‘Ch19Vig1FrocSampleSize.Rmd’ ‘Ch19Vig2FrocSampleSize.Rmd’
Error: Vignette re-building failed.
Execution halted
Cannot figure out why sum of 0.70000 0.20000 0.10000 is not unity.
Dev has indicated that openxlsx is due to be removed from CRAN in a few days (25th September). This has implications for packages dependent on it.
Alternative packages are:
xlsx depends on Java being installed, so is not preferred at this point.readxl and writexl appear to have no dependencies and look like a good fit.I'm going to try and rework the existing code to use readxl and writexl.
frocCr.xlsx
It looks like the results of StSignificanceTesting depends on the order of ModalityID in TP and FP sheets.
library("RJafroc")
library("readxl")
library("xlsx")
x <- DfReadDataFile(fileName = "frocCr.xlsx", newExcelFileFormat = TRUE)
ret <- StSignificanceTesting(x, FOM = "AFROC", method = "OR", analysisOption = "RRRC")
ret$RRRC$ciDiffTrt
truth <- read_xlsx("frocCr.xlsx", sheet = "TRUTH")
tp <- read_xlsx("frocCr.xlsx", sheet = "TP")
fp <- read_xlsx("frocCr.xlsx", sheet = "FP")
write.xlsx(as.data.frame(tp), file = "froc1.xlsx",
sheetName = "TP", append = FALSE, row.names = F, showNA = F)
write.xlsx(as.data.frame(fp), file = "froc1.xlsx",
sheetName="FP", append=TRUE, row.names = F)
write.xlsx(as.data.frame(truth), file = "froc1.xlsx",
sheetName="TRUTH", append=TRUE, row.names = F)
x <- DfReadDataFile(fileName = "froc1.xlsx", newExcelFileFormat = TRUE)
ret1 <- StSignificanceTesting(x, FOM = "AFROC", method = "OR", analysisOption = "RRRC")
#reorder tp and fp
tp <- tp %>% arrange(desc(tp))
fp <- fp %>% arrange(desc(fp))
head(tp)
head(fp)
write.xlsx(as.data.frame(tp), file = "froc1.xlsx",
sheetName = "TP", append = FALSE, row.names = F, showNA = F)
write.xlsx(as.data.frame(fp), file = "froc1.xlsx",
sheetName="FP", append=TRUE, row.names = F)
write.xlsx(as.data.frame(truth), file = "froc1.xlsx",
sheetName="TRUTH", append=TRUE, row.names = F)
x <- DfReadDataFile(fileName = "froc1.xlsx", newExcelFileFormat = TRUE)
ret2 <- StSignificanceTesting(x, FOM = "AFROC", method = "OR", analysisOption = "RRRC")
ret1$RRRC
ret2$RRRC

As you can see from the above screenshot, the trt1-trt0 and trt0-trt1 shows the same result. This is not intuitive and can be misleading with opposite inferences.
The following test creates a new tempfile of output, but does not repeat DfBinDatasetAFROC to compare.
RJafroc/tests/testthat/test-data-file.R
Lines 83 to 88 in 8c0602f
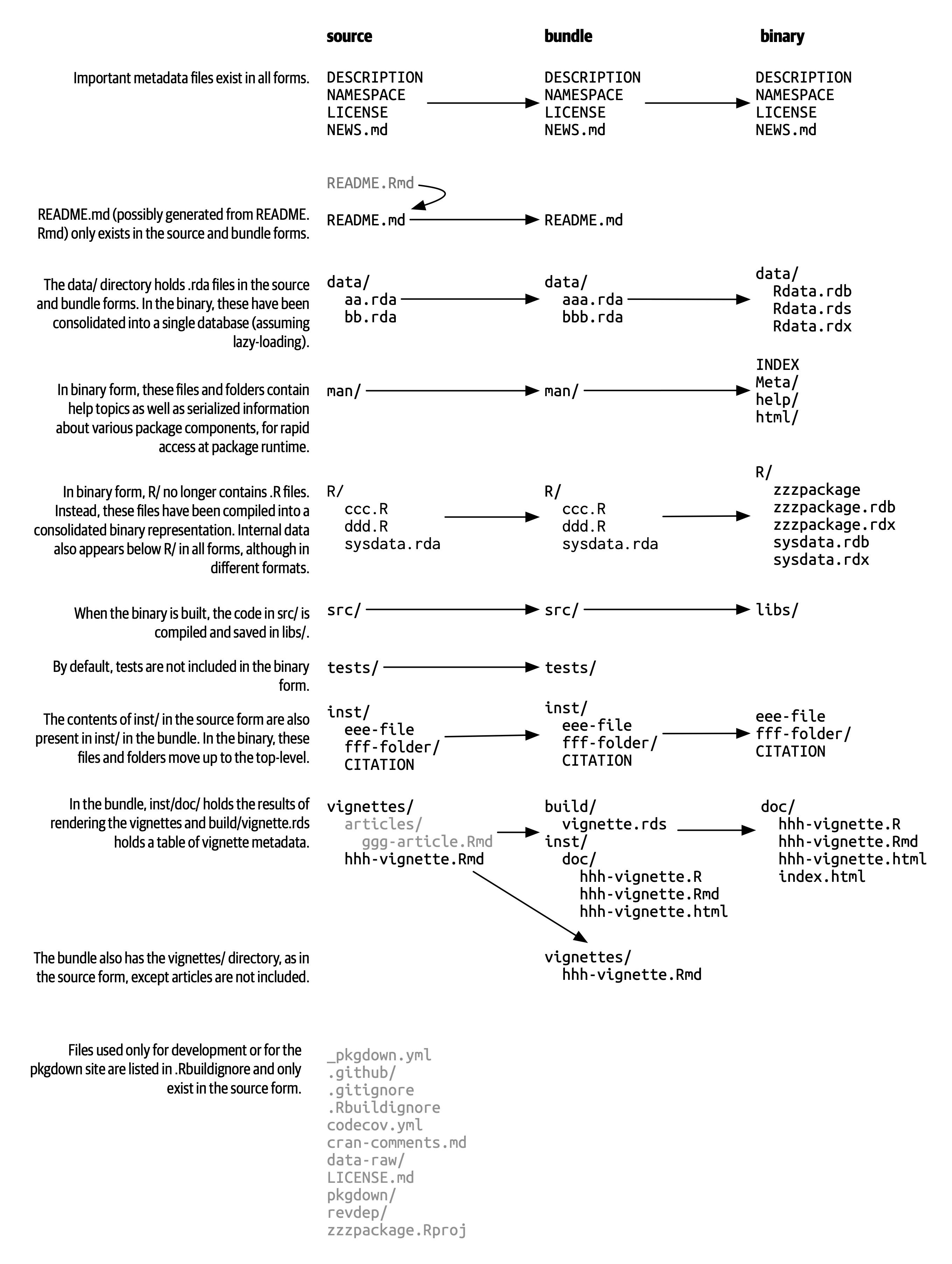
As mentioned in this card on the project board, a NOTE is generated about directory sizes when the package is checked or built.
The doc directory is automatically created and filled with the vignette output (see this image from http://r-pkgs.had.co.nz/package.html.
There might be scope to optimise the file size of images in vignettes/images using a tool called pngcrush.
Dear Peter, thanks for all your help. I am sorry if I wasted your time with the M1 platform before sidestepping it altogether. I am thinking of getting a M1 machine to replace my aging machine, and maybe I will then find out why the vignettes were creating problems.
There is another aesthetic issue that is bugging me; while the DESCRIPTION file does not raise any flags on testing, its Description field converts raggedly to pdf (you will notice two almost identical parts corresponding to this field in the pdf attached: a raggedly formatted part that comes from the DESCRIPTION file and a properly formatted part which comes from RJafroc-package.Rd; I used devtools::build_manual() to make the pdf);
The cryptic CRAN guidance left me confused:
The mandatory ‘Description’ field should give a comprehensive description of what the package does. One can use several (complete) sentences, but only one paragraph. It should be intelligible to all the intended readership (e.g. for a CRAN package to all CRAN users). It is good practice not to start with the package name, ‘This package’ or similar. As with the ‘Title’ field, double quotes should be used for quotations (including titles of books and articles), and single quotes for non-English usage, including names of other packages and external software. This field should also be used for explaining the package name if necessary. URLs should be enclosed in angle brackets, e.g. ‘https://www.r-project.org’: see also Specifying URLs.
What do they mean by paragraph? This is an electronic document with white spaces of different types. Could you take a look at it and tell me if it can be improved (the student Xuetong Zhai who created the first version of the package put everything in one huge line, which was almost impossible to read, but which passed CRAN).
The build fails only if the file NEWS.md is present in the project root.
As a temporary fix I have moved it to directory inst and renamed it to my_NEWS.md (if the renamed file is in the project root then I get the same failure as with the original file name).
Of course this means that the Changelog feature is no longer present in the project website.
After applying #7 (the fix for issue #6), tests can progress. I have not got all the way to the end of the test files yet, but test-StSignificanceTestingCad.R gnerates thousands of warnings.
With the RJafroc package loaded I run the test file using:
testthat::test_file("tests/testthat/test-StSignificanceTestingCad.R")
The first few test pass with warnings (coming from expect_known_output), but then these lines generate around 2000 warnings.
RJafroc/tests/testthat/test-StSignificanceTestingCad.R
Lines 36 to 39 in 3358e97
These warnings are all the same:
Warning in regularize.values(x, y, ties, missing(ties)) :
collapsing to unique 'x' values
Are these warnings OK to expect for this dataset? If so, the test could be done in two steps:
expect_warning() test for StSignificanceTestingCadVsRadiologists and saving the result to a variableexpect_known_output()So something like this:
expect_warning(pcl_singular <- StSignificanceTestingCadVsRadiologists (datasetCadLroc, FOM = "PCL", method = "singleModality"),
"collapsing to unique 'x' values")
expect_known_output(pcl_singular,tmp, print = TRUE, update = TRUE)
All n warnings from regularize.value, occurring within StSignificanceTestingCadVsRadiologists, can be accounted for, and the only warning created is the usual Creating reference output from the expect_known_output() function.
I'm getting a warning for lines 501-502 in test-StCompare2Iowa.R
Unlike other tests in this file, the test on line 501 is checking there is no equality - comparing the first 2 values of theirs and mine. The previous tests compare all values in theirs and mine.
RJafroc/tests/testthat/test-StCompare2Iowa.R
Line 501 in d9149e8
...with values 3:6 compared for equality on line 502.
RJafroc/tests/testthat/test-StCompare2Iowa.R
Line 502 in d9149e8
My warning is:
Warning (test-StCompare2Iowa.R:502:3): StSignificanceTesting: Compare to Iowa Franken dataset
longer object length is not a multiple of shorter object length
Backtrace:
1. testthat::expect_equal(...)
at test-StCompare2Iowa.R:502:2
3. testthat:::compare.numeric(act$val, exp$val, ..., tolerance = tolerance)
5. base::all.equal.numeric(...)
This is coming from the scale argument. All values are being passed for in the scale, but only 2 values are compared for line 501, and 4 for line 502.
The fix is to pass only the values of interest in mine into the scale argument.
expect_error(expect_equal(theirs[1:2], mine[1:2], tolerance = 0.00001, scale = abs(mine[1:2])))
expect_equal(theirs[3:6], mine[3:6], tolerance = 0.00001, scale = abs(mine[3:6]))
I added a new test following my usual style: see test-SsSampleSizeFroc.R in the tests directory:
It fails on all but latest mac.
To prevent failures I had to include the skip_on_os() as shown below; any idea? something has changed in package testthat.
contextStr <- "Sample Size FROC"
context(contextStr)
test_that(contextStr, {
skip_on_os("windows")
skip_on_os("linux")
skip_on_os("solaris")
lesDistr <- c(0.7, 0.2, 0.1)
frocNhData <- DfExtractDataset(dataset04, trts = c(1,2))
fn <- paste0(test_path(), "/goodValues361/SsPower/FROC-dataset04", ".rds")
if (!file.exists(fn)) {
warning(paste0("File not found - generating new ",fn))
ret <- SsFrocNhRsmModel(frocNhData, lesDistr = lesDistr)
saveRDS(ret, file = fn)
}
x1 <- readRDS(fn)
x2 <-SsFrocNhRsmModel(frocNhData, lesDistr = lesDistr)
expect_equal(x1,x2)
})
Edit cran-comments.md file
Summarize results of cross-platform testing in Excel file
How to include Excel file in package?
Justify package size
Edit DESCRIPTION file: done, shortened considerably
Edit README.md
Edit NEWS.md
run devtools::build_site()
upload to GitHub so it can update the website
Submit to CRAN
Commit a8b4e62 produces these errors:
Error: Error: processing vignette 'Ch11Vig1SampleSize.Rmd' failed with diagnostics:
polygon edge not found
SUMMARY: processing the following files failed:
‘Ch11Vig1SampleSize.Rmd’ ‘Ch17Vig1PlotRsmOpCh.Rmd’
‘Ch19Vig1FrocSampleSize.Rmd’ ‘Ch20Vig1improperROCs.Rmd’
‘Ch20Vig2degenerateROCs.Rmd’ ‘Ch20Vig3proprocROCs.Rmd’
‘Ch20Vig5cbmPlots.Rmd’
I will be moving all vignettes to my online bookdown books, so these errors will disappear in future commits. I am leaving this, for the record, as a closed issue, in case it comes up again in future .
Hi,
Does/should T1-RRRC analysis in StSignificanceTestingCadVsRad work for the ROC only data, i.e. without FROC data? Looking at docs and chapter 39. of the book it seems that it should, but ROC-only data with T1-RRRC gives an error:
Error in t[i, j, , 1] : incorrect number of dimensions
This can be replicated e.g. by (1) loading the dataset09, (2) saving it as iMRMC -- ROC-only format, (3) loading said iMRMC file, (4) trying to do T1-RRRC significance test.
> s <- dataset09
> DfSaveDataFile(s, "sample.imrmc", format="iMRMC")
> s2 <- DfReadDataFile("sample.imrmc", format="iMRMC")
> StSignificanceTestingCadVsRad(s2, "Wilcoxon", method="1T-RRRC")
Error in t[i, j, , 1] : incorrect number of dimensionsT2-RRRC and T1-RRFC analyses work fine.
I am using this to mark code lines that bear further inspection and testing. As they pass testing, replace them with DPC
The error appears to be a warning.
I have uncommented the example at the top of test-compare-3fits.R, to run it, It is the example from the relevant testthat code. That example fails on my version, with the same error as others tests in this file.
test-compare-3fits.R:5: error: mtcarsExample - THIS WORKS
(converted from warning) Creating reference output
1: expect_known_output(mtcars[1:10, ], tmp, print = TRUE) at /home/peterphillips/repos/RJafroc/tests/testthat/test-compare-3fits.R:5
2: warning("Creating reference output", call. = FALSE)
3: .signalSimpleWarning("Creating reference output", base::quote(NULL))
4: withRestarts({
.Internal(.signalCondition(simpleWarning(msg, call), msg, call))
.Internal(.dfltWarn(msg, call))
}, muffleWarning = function() NULL)
5: withOneRestart(expr, restarts[[1L]])
6: doWithOneRestart(return(expr), restart)
The second line indicates that this is a warning, but it has been upgraded to an error.
I've found the testthat file that generates the warning. I am checking if a default in R has been updated to to escalate all warnings to errors.
Hi,
DfReadDataFile suggests that the package is capable of loading data in iMRMC format. However, attempting to load those datasets results in an error:
Error in ReadImrmc(fileName, sequentialNames) :
Cases' truth states must be 0 or 1.
This can be reproduced by using sample iMRMC file following format shown in the iMRMC documentation, e.g.
Simulated iMRMC input
NR: 2
N0: 1
N1: 1
NM: 2
BEGIN DATA:
-1,1,0,1
-1,2,0,0
reader1,1,film,1.4
reader1,1,digital,1.9
reader2,1,film,-0.41
reader2,1,digital,0.68
reader1,2,film,1.4
reader1,2,digital,1.9
reader2,2,film,-0.41
reader2,2,digital,0.68
Note 1: I assume this might be related to updates to the iMRMC software. Link to the iMRMC website in current documentation is outdated
Note 2: This format also doesn't support case IDs that are non-integers. iMRMC documentation sample shows case ID as text, e.g. "case1". RJafroc gives a clear error message so it's not a problem but just wanted to give you a heads up.
the current version of rhub does not support several platforms that it previously did; for example, the previous version (about 2 years back) supported most of the platforms listed on this site. The current version of rhub only lists 5 platforms:
> rhub::platforms()
macos-highsierra-release:
macOS 10.13.6 High Sierra, R-release, brew
macos-highsierra-release-cran:
macOS 10.13.6 High Sierra, R-release, CRAN's setup
macos-m1-bigsur-release:
Apple Silicon (M1), macOS 11.6 Big Sur, R-release
solaris-x86-patched:
Oracle Solaris 10, x86, 32 bit, R-release
solaris-x86-patched-ods:
Oracle Solaris 10, x86, 32 bit, R release, Oracle Developer Studio 12.6
So how to check on these platforms; I have never used docker and dread the learning curve.
I am in the process of a CRAN submission. See inst\cranSubmission\cranSubmission.R below, which runs the checks on different platforms: here I focus on the checks run on the "macos-m1-bigsur-release" platform (other failures will be posted as separate issues). Code is on branch cran4a.
chk3 <- rhub::check(packagePath, platform = platforms[[1]][3])
Here is file inst\cranSubmission\cranSubmission.R:
library(devtools)
library(rhub)
library(RJafroc)
platforms <- rhub::platforms()
# > platforms[[1]]
# "macos-highsierra-release"
# "macos-highsierra-release-cran"
# "macos-m1-bigsur-release"
# "solaris-x86-patched"
# "solaris-x86-patched-ods"
packagePath <- "/Users/Dev/GitHub/RJafroc_2.1.0.tar.gz"
if (!file.exists(packagePath))
packagePath <- devtools::build()
# devtools::check_win_devel(packagePath) #OK
# devtools::check_win_release(packagePath) #OK
# devtools::check_win_oldrelease(packagePath) #OK
# devtools::revdep() # NONE
# chk1 <- rhub::check(packagePath, platform = platforms[[1]][1]) # OK
# chk2 <- rhub::check(packagePath, platform = platforms[[1]][2]) # OK
chk3 <- rhub::check(packagePath, platform = platforms[[1]][3]) # FAILS with message shown next
And here is the relevant output:
W checking re-building of vignette outputs (5s)
W checking re-building of vignette outputs (7.7s)
Error(s) in re-building vignettes:
...
--- re-building ‘Ch19Vig1FrocSampleSize.Rmd’ using rmarkdown
Quitting from lines 145-155 (Ch19Vig1FrocSampleSize.Rmd)
Error: processing vignette 'Ch19Vig1FrocSampleSize.Rmd' failed with diagnostics:
polygon edge not found
--- failed re-building ‘Ch19Vig1FrocSampleSize.Rmd’
--- re-building ‘Ch19Vig2FrocSampleSize.Rmd’ using rmarkdown
--- finished re-building ‘Ch19Vig2FrocSampleSize.Rmd’
SUMMARY: processing the following file failed:
‘Ch19Vig1FrocSampleSize.Rmd’
Error: Vignette re-building failed.
Execution halted
pkgdown and test-coverage are generating errors; not related to my code
Here are my codes:
library(RJafroc)
library(flextable)
library(gtsummary)
library(readxl)
library(dplyr)
library(magrittr)
frocCr_fp <- file.path('../out/Stage1_frocCr.xlsx')
x <- DfReadDataFile(frocCr_fp, newExcelFileFormat = TRUE)
ret_st <- StSignificanceTesting(x, FOM = "AFROC", method = "DBM")
# ret_fom <- UtilFigureOfMerit(x, FOM = "AFROC") # same as ret_st$FOMs$foms
ret_plt <- PlotEmpiricalOperatingCharacteristics(dataset = x, opChType = "AFROC")
ret_plt$Plot
# export tables to docx
ReaderID_df <- readxl::read_excel(ID_book_fp, sheet='ReaderID')
trt_rdr_foms <- ret_st$FOMs$foms
trt_rdr_foms$trt <- row.names(trt_rdr_foms)
trt_rdr_foms %<>% dplyr::select(trt, tidyr::everything())
table1 <- flextable::flextable(trt_rdr_foms)
ret_st$RRRC$FTests$p[1]
ciAvgRdrEachTrt <- ret_st$RRRC$ciAvgRdrEachTrt
ciAvgRdrEachTrt$trt <- row.names(ciAvgRdrEachTrt)
ciAvgRdrEachTrt %<>% dplyr::select(trt, tidyr::everything())
table2 <- flextable::flextable(ciAvgRdrEachTrt)
ciDiffTrt <- ret_st$RRRC$ciDiffTrt
ciDiffTrt$trt <- row.names(ciDiffTrt)
ciDiffTrt %<>% dplyr::select(trt, tidyr::everything())
table3 <- flextable::flextable(ciDiffTrt)
The output tables (1-3) are as below:

My question:
In the ModalityID variable, I assigned treatment A to be 0 and treatement B to be 1.
Therefore, my question is:
Are the trt1 and trt0 in table 1 and table 2 wrongly inverted?
Looking forward to your reply soon. Thank you very much.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.



{kind=link}