В результате выполнения данных проектов были освоенные практические навыки изчения данных при помощи машинного обучения и нейронных сетей, работа выполнялась при помощи дистрибутива языка программировани Python - Anaconda, который включает в себя бублиотеки для просто й работы по данной теме. Данное руководство ипрактические материалы помогут начинающим специалистам в области науки о данных освоить практические инстумены для работы с ними.
Наука о данных (англ. data science) — раздел информатики, изучающий проблемы анализа, обработки и представления данных в цифровой форме. Объединяет методы по обработке данных в условиях больших объёмов и высокого уровня параллелизма, статистические методы, методы интеллектуального анализа данных и приложения искусственного интеллекта для работы с данными, а также методы проектирования и разработки баз данных. Рассматривается как академическая дисциплина, а с начала 2010-х годов, во многом благодаря популяризации концепции «больших данных», — и как практическая межотраслевая сфера деятельности, притом специализация исследователя данных с начала 2010-х годов считается одной из самых привлекательных, высокооплачиваемых и перспективных профессий.
Машинное обучение (англ. machine learning) — класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение за счёт применения решений множества сходных задач. Для построения таких методов используются средства математической статистики, численных методов, математического анализа, методов оптимизации, теории вероятностей, теории графов, различные техники работы с данными в цифровой форме. Различают два типа обучения: Обучение по прецедентам, или индуктивное обучение, основано на выявлении эмпирических закономерностей в данных.
- Дедуктивное обучение предполагает формализацию знаний экспертов и их перенос в компьютер в виде базы знаний.
- Дедуктивное обучение принято относить к области экспертных систем, поэтому термины машинное обучение и обучение по прецедентам можно считать синонимами. Многие методы индуктивного обучения разрабатывались как альтернатива классическим статистическим подходам. Многие методы тесно связаны с извлечением информации (англ. information extraction, information retrieval), интеллектуальным анализом данных (data mining).
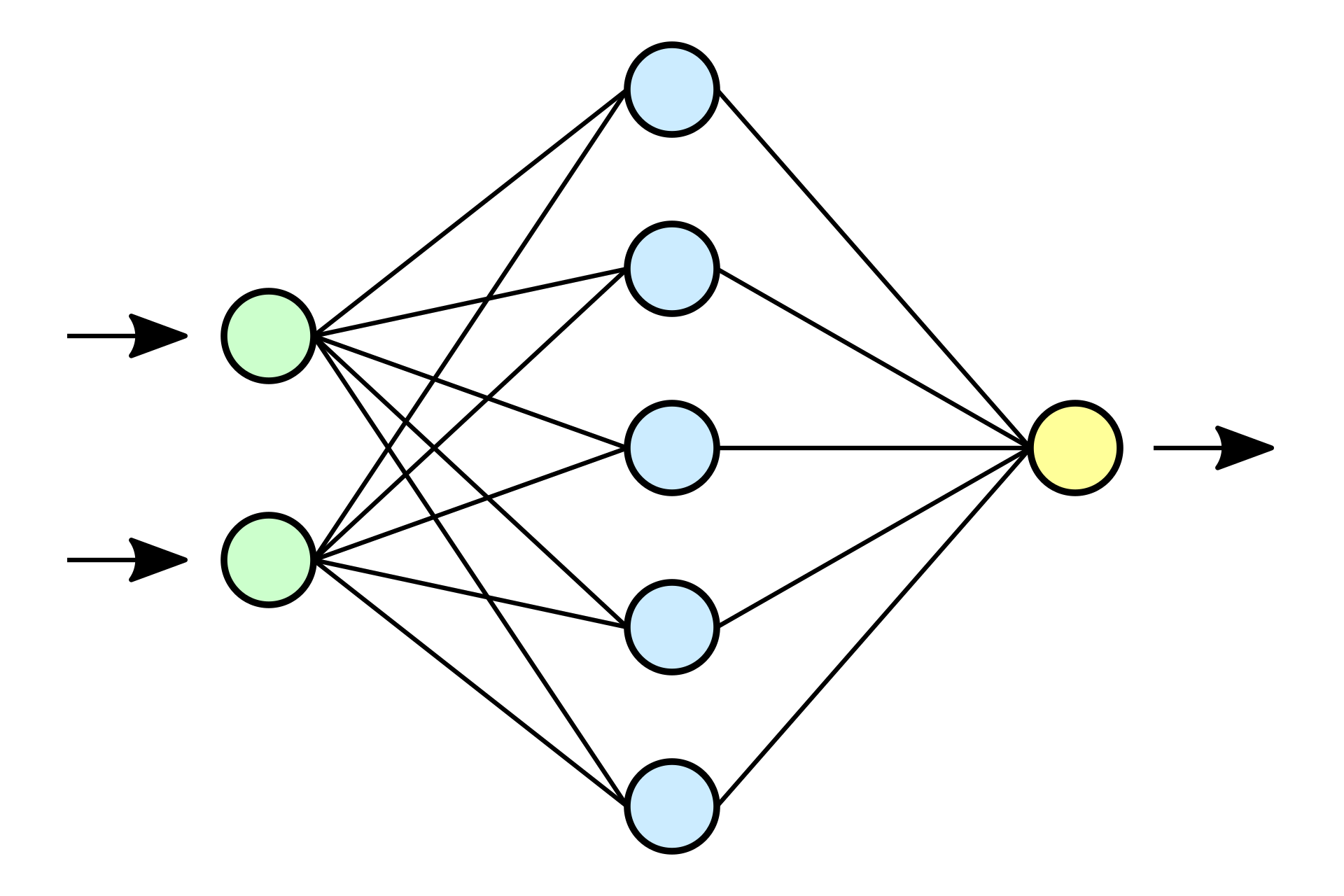
Нейро́нная сеть(также искусственная нейронная сеть, ИНС) — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма. Это понятие возникло при изучении процессов, протекающих в мозге, и при попытке смоделировать эти процессы. Первой такой попыткой были нейронные сети У. Маккалока и У. Питтса. После разработки алгоритмов обучения получаемые модели стали использовать в практических целях: в задачах прогнозирования, для распознавания образов, в задачах управления и др. ИНС представляет собой систему соединённых и взаимодействующих между собой простых процессоров (искусственных нейронов). Такие процессоры обычно довольно просты (особенно в сравнении с процессорами, используемыми в персональных компьютерах). Каждый процессор подобной сети имеет дело только с сигналами, которые он периодически получает, и сигналами, которые он периодически посылает другим процессорам. И, тем не менее, будучи соединёнными в достаточно большую сеть с управляемым взаимодействием, такие по отдельности простые процессоры вместе способны выполнять довольно сложные задачи.
Anaconda — дистрибутив языков программирования Python и R, включающий набор популярных свободных библиотек, объединённых проблематиками науки о данных и машинного обучения. Основная цель — поставка единым согласованным комплектом наиболее востребованных соответствующим кругом пользователей тематических модулей (таких как NumPy, SciPy, Astropy и других) с разрешением возникающих зависимостей и конфликтов, которые неизбежны при одиночной установке. По состоянию на 2019 год содержит более 1,5 тыс. модулей.
Алгоритм Naive Bayes, использует формулу Байеса для расчета вероятности. Название naive (наивный) происходит от наивного предположения, что все рассматриваемые переменные независимы друг от друга. В действительности это не всегда так, но на практике все же данный алгоритм находит применение. Вероятность того, что некоторый объект i1 относится к классу сr (т.е. у = сr), обозначим как Р(у = сr). Событие, соответствующее равенству независимых переменных определенным значениям, обозначим как Е, а вероятность его наступления Р(Е). Идея алгоритма заключается в расчете условной вероятности принадлежности объекта к определенному классу сr при равенстве его независимых переменных определенным значениям. Данный алгоритм можно применять для много классовой классификации данных как и в представленном задании. Использовался набор данных распознавания активности здоровых пожилых людей с помощью носимых датчиков без батареи, набор данных представляет собой аргументы в качестве которых представленны физические данные о поожении человека в пространстве и относительно считывающей антены, в качестве классов представлены действия пациентов при заданных данных.
Проект написан на python. Для его запуска необходимо установить вначале Anaconda. В проекте используется библиотека scikit-learn встроенная в Anaconda. Для полного понимания работы классов и методов двнной библиотеки можете посетить официальный сайт документации этой библиотеки: https://scikit-learn.org/stable/user_guide.html.
После необходимо использовать терминал для запуска jupyter notebook. Его лучше запускать из папки, в которой будет находиться ваш проект. Перейти в соответствующую папку можно с помощью команды cd. После чего пишем в командной строке jupyter notebook. Если все шаги выполнены верно, то в браузере откроется jupyter notebook, вы увидите список файлов из вашей рабочей папки (если она не пуста) и сможете создать новый notebook.
На первом шаге все множество I представляется как множество кластеров. На следующем шаге выбираются два наиболее близких друг к другу (например, ср и сq ) и объединяются в один общий кластер. Новое ножество, состоящее уже из т - 1 кластеров, будет. Повторяя процесс, получим последовательные множества кластеров,состоящие из (т - 2), (т - 3), (т - 4) и т. д. В конце процедуры получится кластер, состоящий из т объектов и совпадающий с первоначальным множеством I. На каждой итерации вместо пары самых близких кластеров образуется новый кластер. Расстояние от нового кластера до любого другого кластера вычисляется по расстояниям кластеров, которые образуют новый кластер. Эти расстояния к этому моменту уже должны быть известны. Для определения расстояния между кластерами можно выбрать разные способы. В зависимости от этого получают алгоритмы с различными свойствами.

Данные представленные в примере представляют собой базу данных клиенто в банка и их рахличные характеристике, предмет кластеризации, оформлял ли клиент банка срочный депозит (двоичный: «да», «нет»).
Проект написан на python. Для его запуска необходимо установить вначале Anaconda. В проекте используется библиотека scikit-learn встроенная в Anaconda. Для полного понимания работы классов и методов двнной библиотеки можете посетить официальный сайт документации этой библиотеки: https://scikit-learn.org/stable/user_guide.html.
После необходимо использовать терминал для запуска jupyter notebook. Его лучше запускать из папки, в которой будет находиться ваш проект. Перейти в соответствующую папку можно с помощью команды cd. После чего пишем в командной строке jupyter notebook. Если все шаги выполнены верно, то в браузере откроется jupyter notebook, вы увидите список файлов из вашей рабочей папки (если она не пуста) и сможете создать новый notebook.
Нейронная сеть — это громадный распределенный параллельный процессор, состоящий из элементарных единиц обработки информации, накапливающих экспериментальные знания и предоставляющих их для последующей обработки. На сегодня среди множества алгоритмов машинного обучения широкое применение получили нейронные сети (НС). Основное преимущество НС перед другими методами машинного обучения состоит в том, что они могут выявить достаточно глубокие, часто неочевидные закономерности в данных. Перед тем, как производить прогноз, алгоритм обучается на тренировочном наборе данных — обучающей выборке. Каждая строка такой выборки содержит:
- в полях, обозначенных как входные — множество входных параметров;
- в поле, обозначенном как выходное — соответствующее входным параметрам значение зависимой переменной. Технически обучение заключается в нахождении весов — коэффициентов связей между нейронами. В процессе обучения нейронная сеть способна выявлять сложные зависимости между входными параметрами и выходными, а также выполнять обобщение. Это значит, что в случае успешного обучения Нейросеть способна выдать верный результат на основании данных, которые отсутствовали в обучающей выборке, а также на неполных и/или «зашумленных», частично искажённых данных. Данные использовались те же что и при работе с кластеризацией.
Проект написан на python. Для его запуска необходимо установить вначале Anaconda. В проекте используется библиотеки tensorflow и keras встроенные в Anaconda. Для полного понимания работы классов и методов двнной библиотеки можете посетить официальный сайты документации этоих библиотек:
После необходимо использовать терминал для запуска jupyter notebook. Его лучше запускать из папки, в которой будет находиться ваш проект. Перейти в соответствующую папку можно с помощью команды cd. После чего пишем в командной строке jupyter notebook. Если все шаги выполнены верно, то в браузере откроется jupyter notebook, вы увидите список файлов из вашей рабочей папки (если она не пуста) и сможете создать новый notebook. Однако обучение и тестирование моделей нейронных сетей затратная задача по ресурсам компьютера. Если вы не обладаете достаточно мощными комплектующими, рекомендуется использовать Google Colab - colab позволяет любому писать и выполнять произвольный код Python через браузер и особенно хорошо подходит для машинного обучения, анализа данных и образования. При этом будут использованы более производительные сервера Google для вычислений, что позволи обучать и тестировать модели бистрее.
Временной ряд представляет собой последовательность наблюдений за изменениями во времени значений параметров некоторого объекта или процесса. Строго говоря, каждый процесс непрерывен во времени, то есть некоторые значения параметров этого процесса существуют в любой момент времени. Но для задач анализа не нужно знать значения параметров объектов в любой момент времени. Интерес представляют временные отсчеты – значения, зафиксированные в некоторые, обычно равноотстоящие моменты времени. Отсчеты могут браться через различные промежутки: через минуту, час, день, неделю, месяц или год – в зависимости от того, насколько детально должен быть проанализирован процесс. В задачах анализа временных рядов мы имеем дело с дискретным временем, когда каждое наблюдение за параметром образуют временной отсчет. Глубокие нейронные сети в настоящее время становятся одним из самых популярных методов машинного обучения. Они показывают лучшие результаты по сравнению с альтернативными методами в таких областях, как распознавание речи, обработка естественного языка, компьютерное зрение, медицинская информатика и др. В рекуррентных же сетях связи между нейронами могут идти не только от нижнего слоя к верхнему, но и от нейрона к «самому себе», точнее, к предыдущему значению самого этого нейрона или других нейронов того же слоя. Именно это позволяет отразить зависимость переменной от своих значений в разные моменты времени: нейрон обучается использовать не только текущий вход и то, что с ним сделали нейроны предыдущих уровней, но и то, что происходило с ним самим и, возможно, другими нейронами на предыдущих входах. Структура LSTM тоже напоминает такую же, как на рисунке 5 цепочку, но модули выглядят и взаимодействуют иначе. Ключевой компонент LSTM – это состояние ячейки. Состояние ячейки участвует в нескольких линейных преобразованиях. LSTM может удалять информацию из состояния ячейки.

Для тестирования и обучения модели были использованны биржевые котировки цен валют с сайта https://www.finam.ru .
Проект написан на python. Для его запуска необходимо установить вначале Anaconda. В проекте используется библиотеки tensorflow и keras встроенные в Anaconda. Для полного понимания работы классов и методов двнной библиотеки можете посетить официальный сайты документации этоих библиотек:
После необходимо использовать терминал для запуска jupyter notebook. Его лучше запускать из папки, в которой будет находиться ваш проект. Перейти в соответствующую папку можно с помощью команды cd. После чего пишем в командной строке jupyter notebook. Если все шаги выполнены верно, то в браузере откроется jupyter notebook, вы увидите список файлов из вашей рабочей папки (если она не пуста) и сможете создать новый notebook. Однако обучение и тестирование моделей нейронных сетей затратная задача по ресурсам компьютера. Если вы не обладаете достаточно мощными комплектующими, рекомендуется использовать Google Colab - colab позволяет любому писать и выполнять произвольный код Python через браузер и особенно хорошо подходит для машинного обучения, анализа данных и образования. При этом будут использованы более производительные сервера Google для вычислений, что позволи обучать и тестировать модели бистрее.
