

The fastest delimited reader for R, 1.04 GB/sec.
But that’s impossible! How can it be so fast?
vroom doesn’t stop to actually read all of your data, it simply indexes where each record is located so it can be read later. The vectors returned use the Altrep framework to lazily load the data on-demand when it is accessed, so you only pay for what you use.
vroom also uses multiple threads for indexing and materializing non-character columns, to further improve performance.
| package | version | time (sec) | speedup | throughput |
|---|---|---|---|---|
| vroom | 0.0.0.9000 | 1.60 | 67.42 | 1.04 GB |
| data.table | 1.12.0 | 19.75 | 5.47 | 84.38 MB |
| readr | 1.3.1 | 26.61 | 4.06 | 62.64 MB |
| read.delim | 3.5.1 | 108.13 | 1.00 | 15.42 MB |
vroom has nearly all of the parsing features of readr for delimited files, including
- delimiter guessing*
- custom delimiters (including multi-byte* and unicode* delimiters)
- specification of column types (including type guessing)
- numeric types (double, integer, number)
- logical types
- datetime types (datetime, date, time)
- categorical types (characters, factors)
- skipping headers, comments and blank lines
- quoted fields
- double and backslashed escapes
- whitespace trimming
- windows newlines
- reading from multiple files or connections*
* these are additional features only in vroom.
However vroom does not currently support embedded newlines in headers or fields.
Install the development version from GitHub with:
# install.packages("devtools")
devtools::install_github("jimhester/vroom")vroom uses the same interface as readr to specify column types.
vroom::vroom("mtcars.tsv",
col_types = list(cyl = "i", gear = "f",hp = "i", disp = "_",
drat = "_", vs = "l", am = "l", carb = "i")
)
#> # A tibble: 32 x 10
#> model mpg cyl hp wt qsec vs am gear carb
#> <chr> <dbl> <int> <int> <dbl> <dbl> <lgl> <lgl> <fct> <int>
#> 1 Mazda RX4 21 6 110 2.62 16.5 FALSE TRUE 4 4
#> 2 Mazda RX4 Wag 21 6 110 2.88 17.0 FALSE TRUE 4 4
#> 3 Datsun 710 22.8 4 93 2.32 18.6 TRUE TRUE 4 1
#> # … with 29 more rowsvroom natively supports reading from multiple files (or even multiple connections!).
First we will create some files to read by splitting the nycflights dataset by airline.
library(nycflights13)
purrr::iwalk(
split(flights, flights$carrier),
~ readr::write_tsv(.x, glue::glue("flights_{.y}.tsv"))
)Then we can efficiently read them into one tibble by passing the filenames directly to vroom.
files <- fs::dir_ls(glob = "flights*tsv")
files
#> flights_9E.tsv flights_AA.tsv flights_AS.tsv flights_B6.tsv flights_DL.tsv
#> flights_EV.tsv flights_F9.tsv flights_FL.tsv flights_HA.tsv flights_MQ.tsv
#> flights_OO.tsv flights_UA.tsv flights_US.tsv flights_VX.tsv flights_WN.tsv
#> flights_YV.tsv
vroom::vroom(files)
#> # A tibble: 336,776 x 19
#> year month day dep_time sched_dep_time dep_delay arr_time
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2013 1 1 810 810 0 1048
#> 2 2013 1 1 1451 1500 -9 1634
#> 3 2013 1 1 1452 1455 -3 1637
#> # … with 3.368e+05 more rows, and 12 more variables: sched_arr_time <dbl>,
#> # arr_delay <dbl>, carrier <chr>, flight <dbl>, tailnum <chr>,
#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
#> # minute <dbl>, time_hour <dttm>The speed quoted above is from a dataset with 14,776,615 rows and 11 columns, see the benchmark article for full details of the dataset and bench/ for the code used to retrieve the data and perform the benchmarks.
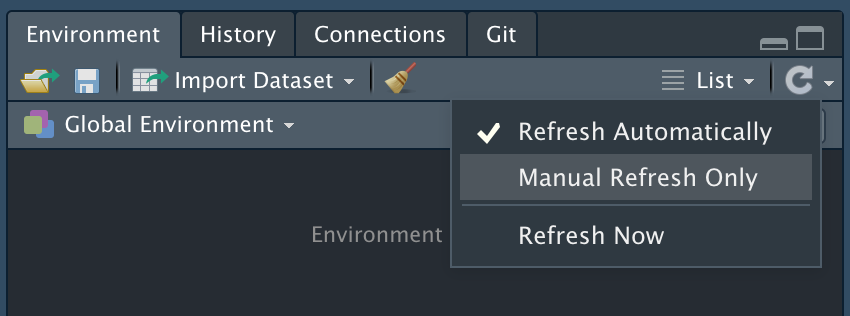
RStudio’s environment pane auto-refresh behavior calls object.size()
which for Altrep objects can be extremely slow. This was fixed in
rstudio#4210 and
rstudio#4292, so it is
recommended you use a daily version if
you are trying to use vroom inside RStudio. For older versions a
workaround is to use the ‘Manual Refresh Only’ option in the environment
pane.
- Gabe Becker, Luke Tierney and Tomas Kalibera for implementing and maintaining the Altrep framework
- Romain François, whose Altrepisode package and related blog-posts were a great guide for creating new Altrep objects in C++.
- Matt Dowle and the rest of the
Rdatatable team,
data.table::fread()is blazing fast and great motivation!

