Text2Network is a python package to generate "semantic networks" from arbitrary text sources using a (deep neural) PyTorch transformer model (e.g. BERT). Details for this procedure are available in the following research paper: https://arxiv.org/abs/2110.04151
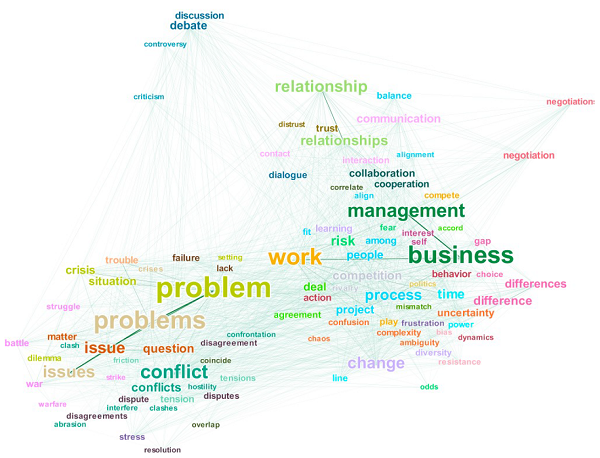
Text2Network allows you to understand direct and higher-order linguistic relationships in your texts. Since these relationships are extracted directly from a sophisticated transformer model, they are more powerful than prior approaches. For example, once a text is represented as network, you can query each potential relation between words conditional on a certain context, such as other words that may appear in a sentence. You can also aggregate across arbitrary time periods or text pieces. The network is constructed in such a way that each conditioning operation leads to proper probability measures that are directly interpretable without further nuisance parameters and refer, correctly, to the language use of the subset in question - be it a given context, or a subset of the corpus. Using network techniques, such as centralities, distances and community structures, you can then analyze global structure of language as used in the text corpus.
The semantic network also represents all the information about linugistic dependencies captured by the deep neural network. As such, it is useful to understand both the text source, as well as the model. Note, however, that this procedure is inferential and does not provide a good input for downstream tasks.
Text2Networks includes four python objects, one for preprocessing, one for training the language model, one for inference and one class that directly represents the semantic network and all operations on it.
The objects correspond to the four steps necessary to analyze a corpus:
-
Pre-processing: Texts are ingested, cleaned and saved in a hdfs database. Associated metadata is created, this notably includes a time variable and a number of freely chosen parameters.
-
Training of the DNN: The researcher determines which combination of parameters constitutes a unit of analysis (for example newspaper-year-issue) and passes this hierarchy to the trainer class, which trains the required number of DNN models. Please see the research paper why this is required to capture linguistic relations in the text corpus correctly.
-
Processing: Using the trained language models, the each word in the corpus is analyzed in its context. For each such occurrence, ties representing probabilistic relations are created. Here, we use a Neo4j graph database to save this network.
-
Analysis: The semantic_network class directly encapsulates the graph database and conditioning operations thereon. Networks created here can either be analyzed directly, or exported in gexf format.
If you start with a trained Transformer model (i.e. from Hugginface / PyTorch transformers) and do not seek to fine-tune it, only points (3) and (4) apply.
To run all elements correctly, the required python packages need to be installed. That is:
Generally: PyTorch (1.3.1) & Numpy Preprocessing: tables (hdf5) & nltk Processing: Transformers (2.1.1) & tensorboard Analysis: networkx & python-louvain & pandas
We are in the process of updating models to newer versions of PyTorch and Transformers. However, due to some interface changes, the code - and the supplied models - will not run with the latest versions.
If using anaconda, create a new environment and install
conda install pytorch==1.4.0 torchvision==0.5.0 cpuonly -c pytorch
conda install -c conda-forge transformers=2.1.1
conda install networkx pytables pandas nltk
conda install -c conda-forge tensorboardFinally, a Neo4j server should be running for processing. We are currently in the process of also allowing the extraction into a networkX graph. However, as this package was tested on large corpora of text, a Neo4J graph database is currently required.
You should be able to use any Neo4j instance, as we support the standard Bolt connector since it performance improved.
We currently use a custom http connector, which is faster than the default interface. Sadly, the connector does not work for versions above 4.02. We are in the process of upgrading to a standard Bolt connector. You can choose the version of the database in the Neo4j Desktop App.
The .py files in the main folder of the repository show illustrate each step of the pipeline.
We use the standard python configuration parser to read an ini file.
from text2network.utils.file_helpers import check_create_folder
import configparser
# Load Configuration file
configuration_path='/config/config.ini'
config = configparser.ConfigParser()
config.read(check_create_folder(configuration_path))Inside the configuration file are a number of fields. It is essential to set the correct paths.
import_folder holds the txt data
pretrained_bert holds the pre-trained BERT Pytorch model, that is used for all divisions of the corpus.
trained_berts will store the fine-tuned BERT models.
processing_cache simply keeps track of which subcorpus has already been processed into the Neo4j Graph-
database holds the processed text in a hdf5 database.
log is the folder for the log.
Once text files are comfortably situated in a folder, the text can be pre-processed. Sentences that are too long are split, tags and other nuisance characters are deleted and so forth.
Most importantly, each sentence is saved in a database, together with its metadata. This always includes the following:
Year: A time variable integer. Typically, YYYY, but YYYYMMDD could be used.
Source: Name of the txt file
p1 through p4: Up to four parameters coming from the file name
run_index An index across all sentences in all text files.
seq_id An index across sentences within a given text file.
text The sentence, capped at a maximum length of characters.
Since each sentence is then saved as a row in the database, we can determine at a later stage how we seek to query and split the corpus into subcorpora (e.g. by year and parameter 1).
So initially, we need to use the configuration file to define the properties of the text we are going to use. In particular, we need to define what the file names mean. Two options for the file structure are possible:
First, the import folder could include sub-folders of years.
import_folder/
import_folder/year1/
------p1_p2_p3_p4.txt
------p1_p2_p3_p4.txt
(...)
import_folder/year2/
------p1_p2_p3_p4.txt
------p1_p2_p3_p4.txt
(...)
Alternatively, all txt files can also reside in a single folder.
import_folder/
------year1_p1_p2_p3_p4.txt
------year1_p1_p2_p3_p4.txt
------year2_p1_p2_p3_p4.txt
------year3_p1_p2_p3_p4.txt
(...)
Accordingly, we set the following parameters in the configuration file: split_symbol
is the symbol that splits between parameters (here "_"). number_params denotes the number
of parameters (here 4). If we had only two parameters, our text files might be
of the form p1_p2.txt and we would set that value to 2.
Finally, max_seq_length denotes the maximum length of a sentence.
char_mult is a multiplier that determines how many letters the average word can have.
The total sequence length in letters (symbols) is given by max_seq_length*char_mult.
Having a fixed-length format here is helpful for performance. Sequences can, of course, be shorter. Later components
will also re-split sentences if smaller batch sizes are desired. Setting the sequence size very high
ensures that no sentence will be unduly split, however this will increase file size.
We begin by instancing the preprocessing class. At this stage, we will also set up logging.
from src.classes.nw_preprocessor import nw_preprocessor
from text2network.preprocessing.nw_preprocessor import nw_preprocessor
from text2network.utils.file_helpers import check_create_folder, check_folder
from text2network.utils.logging_helpers import setup_logger
# Set up preprocessor
preprocessor = nw_preprocessor(config)
# Set up logging
preprocessor.setup_logger()Note that is is sufficient to pass the config, however the class also
takes optional parameters, if we want to overwrite the configuration file.
This is the standard behavior for all modules. So for example one could instead do:
preprocessor = nw_preprocessor(config, max_seq_length=50)Next, we can process the text files and create the database.
If our text files are split among multiple sub-folders, with years as folder names,
we call the preprocess_folders method
preprocessor.preprocess_folders(overwrite=True,excludelist=['checked', 'Error'])here, overwrite indicates that we wish to overwrite any existing database.
excludelist is a list of strings corresponding to any of the parameters
in the file name. Filenames including elements from this list are not processed.
If, instead, all files are in a single folder, we run
preprocessor.preprocess_files(overwrite=True,excludelist=['checked', 'Error'])Note that both functions also take a folder variable, if we want to not use the folder of the configuration file.
In this way, the pre-processing can also be done across many sources. Note, however, that the
file name of the txt file is essential and needs to follow the same convention:
Either folders with year names, or files starting with years, and then up to four parameters.
The module will try to take care of encodings and other matters. If the file can not be read, an error will be returned.
Once done, a db.h5 file will be created in the database folder, which includes all
individual sentences and their meta-data.
We will train one BERT model for each logical division of the corpus. This sub-division will be carried along all subsequent steps. So, processing a certain subdivision requires that a corresponding BERT model has been trained. Different divisions can be trained and saved, as they will be saved in distinct folders.
Subdivisions are specified via the split_hierarchy option in the configuration file.
It is a list of parameters by which to split the corpus and train the models. All parameters are always saved as meta-data, but we might want to aggregate across them when training BERT.
The simplest division is by year:
split_hierarchy=["year"]
This will train one BERT per year. However, we might also train one BERT per combination of year, p1 and p2, e.g.
split_hierarchy=["year","p1",p2"]
By setting this parameter, the trainer module can ascertain how many BERTs are required, and which sentences it should train on.
We do not wish to use word-pieces. The pre-trained BERT has word-pieces disabled. For that reason, the vocabulary needs to be amended. It is desirable, although not strictly necessary, to use the same vocabulary across all models. To keep this reasonable, set new_word_cutoff for large corpora. Only words that occur more often will be included in the vocabulary.
The training process creates first one shared vocabulary, resizes the BERT models and then trains them individually.
Each model is trained until either eval_loss_limit or loss_limit is reached, where the first denotes the loss across test sequences, whereas the second in the current batch during training. The configuration file also includes the usual model parameters, that should be set according to GPU size and corpus size.
To train all BERTs, we initialize the trainer and run the training. Again, attributes may be given via the config file or as individual parameters.
from text2network.training.bert_trainer import bert_trainer
trainer=bert_trainer(config)
trainer.train_berts()Having trained BERTs, we need to extract semantic networks. This involves running inference across the subdivisions of the corpus and saving network ties in the Neo4j database.
The processor class will set-up a network for you. The network is, of course, entirely empty at this stage. To fill it, we also create a processer that takes the network interface as input.
from text2network.processing.nw_processor import nw_processor
processor = nw_processor(config=config)Since all options are already specified in the configuration file, we can directly process our semantic networks.
processor.run_all_queries(delete_incomplete_times=True, delete_all=False)Where we can specify whether we would like to clean the graph database first - in order not to duplicate ties - or not.
Note that the processor remembers whether a BERT model has already been processed to completion. By specifying delete_incomplete, the processor will first clean the graph database of subdivisions that were not completed.
This is useful if the processing gets interrupted.
Conversely, delete_all cleans the graph entirely for a fresh start.
Once initialized, the semantic network class represents and interface to the Neo4j graph database. It acts similar to a networkx graph and can query individual nodes directly. For example, to return a networkx-compatible list of ties for the token "president", you can use
from text2network.classes.neo4jnw import neo4j_network
semantic_network=neo4j_network(config)
semantic_network['president']This will query the neo4j network directly.
If you are interested in analyzing more than a single node, it is a good idea to condition the graph. Conditioning the graph will query relevant ties from Neo4j and construct an in-memory networkx graph that is used until the deconditioning function is called. Conditioning the graph norms ensures that the probabilities implied by the network are correctly conditioned on context and time-frame.
For example, to derive the 2-step ego network for the token "president", across a set of years, conditional on sentences with the context "USA" or "China", do
semantic_network.condition(years=[1992,2005], ego_nw_tokens="president", depth=2,weight_cutoff=0.05, context=['USA','China'])To release the conditioning
semantic_network.decondition()Several transformations are available and can be called directly on a conditioned network. For example
semantic_network.to_symmetric()
semantic_network.to_backout()In addition, we provide a host of analysis functions and formatting options. For example, printing the centralities of the terms "president","tyrant","man" and "woman" from a pandas dataframe can be accomplished in two lines:
centralities=semantic_network.centralities(focal_tokens=['president','tyrant','man', 'woman'], types=["PageRank"])
print(semantic_network.pd_format(centralities))where centralities computes centralities of different kind (here: PageRank) and semantic_network.pd_format transforms the output into a pandas DataFrame for easy printing and saving.
Semantic networks cluster hierarchically into linguistic components. This is usually where syntactic and grammatical boundaries appear. Text2Network offers several tools to derive these clusters. By default, louvain-clustering from the community package is used, however, you can add any callable.
Clusters are handled as dictionary container. They contain the relevant subgraph, names, measures (such as centralities) and metadata. By default, the cluster function takes care of handling these details. For example, to cluster the semantic network, call
clusters=semantic_network.cluster(levels=1)The clusters variable is a list of cluster containers, including the base graph amended by cluster identifiers for each node, as well as the subgraphs implied by the clustering algorithm.
You can automatically apply measures of choice on each cluster, which are saved as list of dictionaries in the cluster container
clusters=semantic_network.cluster(levels=1, to_measure=[proximity,centrality])
print(semantic_network.pd_format(clusters[0]['measures']))Clusters keep track of their level and parent cluster, such that hierarchies become apparent
levels=2
clusters=semantic_network.cluster(levels=levels)
for cl in clusters:
print("Name: {}, Level: {}, Parent: {}, Nodes: {}".format(cl['name'],cl['level'],cl['parent'],cl['graph'].nodes))Name: base, Level: 0, Parent: , Nodes: ['chancellor', 'president', 'king', 'tyrant', 'ceo', 'father', 'judge', 'delegate', 'manage', 'teach', 'rule', 'man', 'woman']
Name: base-0, Level: 1, Parent: base, Nodes: ['father', 'woman', 'king', 'chancellor', 'man', 'tyrant']
Name: base-1, Level: 1, Parent: base, Nodes: ['manage', 'president', 'teach', 'delegate', 'ceo']
Name: base-2, Level: 1, Parent: base, Nodes: ['rule', 'judge']
Name: base-0-0, Level: 2, Parent: base-0, Nodes: ['father', 'king', 'chancellor', 'tyrant']
Name: base-0-1, Level: 2, Parent: base-0, Nodes: ['man', 'woman']
Name: base-1-0, Level: 2, Parent: base-1, Nodes: ['manage', 'teach', 'delegate']
Name: base-1-1, Level: 2, Parent: base-1, Nodes: ['ceo', 'president']
Name: base-2-0, Level: 2, Parent: base-2, Nodes: ['rule', 'judge']
Of course, you can also apply clustering to networkx graphs yourself. For example, assume you have previously conditioned your network
semantic_network.condition(years=[1992,2005], weight_cutoff=0.05, context=['USA','China'])Then, you can package the graph into a cluster container
packaged_graph=return_cluster(semantic_network.graph,name="Test",parent="",level=0,measures=[],metadata={'years':[1992,2005], 'context':['USA','China']})and run the clustering function. This will return the base cluster, amended by measures and node identifiers, all well as a list of the subgraphs of the given clusters. In contrast to the cluster function of the semantic network class, the base cluster is returned as separate entity of a tuple.
base_cluster,subgraph_clusters=cluster_graph(packaged_graph, to_measure=[proximity, centrality],algorithm=louvain_cluster)Note that the cluster function of the semantic network can condition if necessary, such that the above is equivalent to
clusters=semantic_network.cluster(levels=1, name="Test", to_measure=[proximity,centrality], metadata={'years':[1992,2005], 'context':['USA','China']}, years=[1992,2005], weight_cutoff=0.05, context=['USA','China'])Many more analysis options are possible, and the network class provides an easy interface. See the analysis folder for further ideas.

![deepsource-autofix[bot] avatar](https://avatars.githubusercontent.com/in/57168?v=4 "deepsource-autofix[bot]")
