devancn / blog Goto Github PK
View Code? Open in Web Editor NEW记录所学、所思、所悟、所行的地方
记录所学、所思、所悟、所行的地方

DOM 由 HTML 标签文本先进行分词然后利用栈的后进先出特点来生成一个 DOM 树
介绍 DOM 树生成之前先介绍一下 DOM 接口相关的信息,不同的 DOM 节点对应不同的 DOM 接口,如 head 与 body 节点接口继承关系
DOM 元素由标签和文本构成,而标签又分为 tagStart、tagEnd 。
<html>
<head>
<title>DOM解析</title>
</head>
</html><html> 时会根据 HTMLHtmlElement 对象实例化一个 html 节点并作为 document 节点的子节点,同时把 html push 到栈中<head> 时会根据 HTMLHeadElement 对象实例化一个 head 节点并作为 html 节点的子节点,同时把 head push 到栈中title 时会根据 HTMLTitleElement 对象实例化一个 title 节点并作为 title 节点的子节点,同时把 title push 到栈中DOM解析文本时使用 Text 对象实例化一个 文本节点并作为 title 节点的子节点,并不会 push 到栈中</title>时因为该标签为 tagEnd 所以会在栈中 pop 出一个元素 判断是否为 title TagStart,如果是则该节点生成完成在对字节流进行解析时如果遇到 script 标签,此时HTML解析器会暂停解析, javascript引擎会先执行 script 脚本再继续进行解析,因为 javascript 可能会对 DOM 进行添加、修改等操作。如果该 script 标签前面还有style标签,会先对 style 标签的文本解析时 CSSOM,因为 js 也可能会对 CSSOM 进行操作,常见的比如获取某个元素样式信息。如果 js 与 css 需要下载时,也会延长 DOM 的解析。不过渲染进程中有预解析线程会先扫描一下html文本中是否有需要加载的关键资源,有的花就会去下载,下载的过程中并不会阻塞DOM解析
把知识进行分解,按照关系进行分类整理
每个子节点的步骤具有明显的先后关系,顺序不能乱,子节点每个步骤都完成后会组合成父节点,如编译的四个步骤:
父节点描述一个事物,子节点描述这个事物的各个部分,如CSS规则:
把一个事物可以分成几个维度来看待,如JavaScript:
父类是一个集合,每个子类都是父类的一个子集。如CSS简单选择器,以下是常用的选择器:
讲如何使用 commitizen 之前,先介绍一下一些前置知识和项目中常用到的 npm 包
Git 钩子就是特定事件发生时 Git 自动运行的普通脚本,脚本不一定是 shell 脚本,任何解释执行的语言都可以作为运行的脚本,只要指定执行的解释程序就行 ,比如 Node 程序的脚本 开头声明为 #!/usr/bin/env node就可以执行。
在打开仓库的 .git/hooks目录中会看到下面这些文件:
applypatch-msg.sample pre-push.sample
commit-msg.sample pre-rebase.sample
post-update.sample prepare-commit-msg.sample
pre-applypatch.sample update.sample
pre-commit.sample
这里包含了大部分 Git 可用的钩子, 但是也 .sample 扩展名放置他们被执行,只要去掉 .sample扩展名就可以或者从新写一个以 Git Hook 为命名的脚本。
在了解了 Git Hook 基本概念后,我们可以基于 Git Hook 做一些代码校验,单元测试等等。但是发现 Git Hook 脚本是放在 .gi/hooks 这个目录中的, 也就是说它不会被 Git 所进行管理,这样在多人协作和维护就比较麻烦。 所以 husky 可以解决这个问题,现在 husky@5 是最新版本,但是目前大家用的基本都是 husky@4 的版本,如果想从4升级至5可以自行查看下husky官网操作步骤。下面是 husky@4 使用步骤:
npm i husky@4 -D在 package.json 中配置 hooks, 如在运行 git commit时输出 Hello Devan字符串
{
"husky": {
"hooks": {
"pre-commit": "echo \"Hello Devan\""
}
}
}从字面就能看出它的作用,没错!就是检查用户的 commit messages(提交说明),commit messages 也有一些约定规范,比如 Angular 的约定规范类型有: build、ci、chore、docs、feat、fix、perf、refactor、revert、style、test。commitlint的 commit message 规范是可扩展的,所以它需要开发者自定义一些 commit message 规范或者使用社区已经开源提供的约定规范。如下演示如何使用常用的约定规范 commit/config-conventional
安装 commitlint cli 和 conventional config 为开发依赖
npm i @commitlint/config-conventional @commitlint/cli -D在项目根目录添加 commitlint.config.js文件
{
extends: ['@commitlint/config-conventional']
}校验 commit message 是否符合 config-conventional 约定
npx commitlint --edit $1可以在用户输入提交信息之后被调用的钩子 message-msg来进行 commit 校验
"husky": {
"hooks": {
"commit-msg": "commitlint -e $HUSKY_GIT_PARAMS"
}
}这个也是从字面上也能看出它的作用。 git add files 是把工作目录中文件加入的 stage 缓存,lint-staged 就是对缓存中的文件进行一些比如使用 eslint 进行代码修复等操作。使用方式:
添加 lint-staged 为开发依赖
npm i lint-staged -D在 package.json 文件中添加配置
{
"lint-staged": {
"文件匹配规则": "shell 脚本"
}
}简单来说就是根据用户使用的commit messages规范以交互式的方式来格式化你的 commit messages。使用方式:
安装 commitizen 依赖
npm i commitizen --save-dev使用适配器 cz-conventional-changelog 来初始化提交给范类型
npx commitizen init cz-conventional-changelog --save-dev --save-exact在 package.json 配置规范
"config": {
"commitizen": {
"path": "cz-conventional-changelog"
}
}使用方式有以下几种方式
git cz - 需要用户全局安装 commitizen
npx cz - 本质是执行项目中 node_modules/.bin/cz shell 脚本,和 package.json 文件中:
"script": "cz"执行过程一致
使用 Git prepare-commit-msg钩子,每次调用 git commit命令是都会触发给钩子
"husky": {
"hooks": {
"prepare-commit-msg": "exec < /dev/tty && git cz --hook || true",
}
}以上只是简单初步了解,如果想要了解更多可以查看对应文档,实际个人觉得如果用了commitizen 就没必要再用 commitlint 。
https://github.com/commitizen/cz-cli
https://github.com/typicode/husky/tree/master
https://github.com/conventional-changelog/commitlint
https://www.conventionalcommits.org/en/v1.0.0-beta.2/#why-use-conventional-commits
用通俗易懂的方式说明 Typescript 中的协变与逆变。纯属个人理解,不保证内容正确性。
interface Parent {
name: string
}
interface Child {
name: string
age: number
}
let p:Parent = {
name: '张三'
}
let c:Child = {
name: '李四',
age: 18
}
p = c; // √
c = p; // × Property 'age' is missing in type 'Parent' but required in type 'Child'以上定义了父类 Parent 与子类 Child,并声明了变量 p 的类型为 Parent,变量 c 的类型为 Child。可以看到把变量 c 赋值给 p 的时候通过了 ts 的类型检查, 但是把 p 赋值给 c 的却不行。 ts 的类型只关注值的结构或者外形上能兼容即可。
变量 p 的类型为 Parent,意味着只要 p 的值的外形上只要存在 name 属性就可以。所以 ts 进行检查的时候没有问题。
变量 c 的类型为 Child,意味着只要 c 的值的外形上(可以理解成代码结构上)存在 name 与 age 属性就行。所以变量 c 赋值给 p 的时候是没有问题的,因为 c 的类型结构上也存在 p 所需要的 name,也叫类型兼容。反之 p 赋值给 c 就步行。 p 的类型没有 c 的类型所需要的 age 属性。
下面是类型是函数的情况,需要在 tsconfig.json 中 的 compilerOptions 中的 strictFunctionTypes 配置打开
let parent: (a:string) => void
let child: (a:string,b:string) => void;
parent = a => {
console.log(a)
}
child = (a, b) => {
console.log(a + b)
}
parent = child // × Type '(a: string, b: string) => void' is not assignable to type '(a: string) => void'
child = parent // √ 可以看到 parent 函数与 child 函数的区别就是 child 函数多一个参数。但是把 child 函数赋值给 parent 变量的时候,ts 类型校验不通过, parent 函数赋值给 child 变量确是没有问题。原因在于 child 函数需要两个参数,child 函数赋值给 parent 变量的时候, parent 就是 child 函数本身了,但是 parent 的类型声明中函数只有一个参数,就导致了类型声明和值的参数结构上存在不兼容。同理
parent 函数赋值给 child 变量可以是因为 parent 的类型函数只有一个变量,这相当于 child 变量的值是 parent 函数本事,child 的变量的类型函数的参数是两个,能兼容 parent 函数参数,所以是可以的。可以这么理解,child 函数类型声明需要两个参数,但实际的 child 变量的值的函数只有一个参数,这种情况下就算按照 child 类型声明的方式传递两个参数,child 的值的函数只需要一个参数,能兼容,也不会执行错误,所以是可以的。
两个例子其实都是说明只要实际执行的时候你赋值的变量的类型能兼容,运行不报错那 ts 类型检查就不会出问题。
再看另一种都是只有一个参数,类型不同的情况
interface Parent {
name: string;
}
interface Child {
name: string;
age: number
}
let a:(param: Parent) => void;
let b:(param: Child) => void;
a = param => {
console.log(param.name)
}
b = param => {
console.log(param.age + param.name)
}
a = b // × Type '(param: Child) => void' is not assignable to type '(param: Parent) => void'
b = a // √ b 赋值给 a 不行是因为 b 函数赋值给 a 变量之后相当于 a 变量的值是 b 指向的函数,该函数使用到了参数中的 age 和 name 属性,但是 b 的类型参数中只有一个 age。意味着你使用到这个 a 的函数的时候会按照 a 的类型传值。这样这个 a 函数就不安全意味着可能执行报错,因为没有传递这个 age 的属性。这种现象称为逆变。
逆变或者协变的本质都是保证 js 的代码正常运行, ts 只是给 js 添加了静态类型系统来保证 js 安全执行。个人感觉这种很理论的东西更让你难以理解。ts 中的类型的父与子与面向对象编程中的概念是没有关系的, ts 是用 值的形状来区分父与子,以就是说只要一个类型能兼容另一个类型,那它就是子类型。
之前在团队中做个一次 ppt 版的技术分享,这里用文字再整理一下,由于水平有限不保证内容的准确性。
环境记录与执行上下文有一点的联系,所以在介绍环境记录之前先看了解一下什么是执行上下文。执行上下文表示用来跟踪当前程序的执行状态。执行上下文之间使用栈这样的结构来维护上下文与上下文之间的关系,栈顶的上下文称为当前运行执行上下文(running execution context)。执行上下文有三种类型:
对上下文有个大概的了解后我们来看看上下文中包含哪些部分,以下内容整理自 ecma262 规范文档。
| Component | Purpose |
|---|---|
| code evaluation state | 程序执行状态 |
| Function | 如果是函数执行上下文,表示该函数代码 |
| Realm | 提供内置对象,如: Function、Object、String等 |
| ScriptOrModule | 如果是 Script Recort 或 Module Record,则表示该代码 |
| LexicalEnvironment | 用于解析 let、const 所声明的标识符 |
| VariableEnvironment | 用于解析 var 语句 或 函数声明 |
| PrivateEnvironment | Identifies the PrivateEnvironment Record that holds Private Names created by ClassElements in the nearest containing class. null if there is no containing class. |
| Generator | 如果是生成器执行上下文,则表示该生成器代码 |
由于规范中对 PrivateEnvironment 的描述不是很理解,所以就把规范中的内容原样复制过来了,这部分推荐大家还是看规范文档好理解些,这里整理的内容是我所消化理解过的,不一定是正确的或者你不好理解的。
介绍完了执行上下文后,大家有没有看到执行上下文中的 LexicalEnvironment 和 VariableEnvironment。实际它们都是环境记录项,那现在我们来看一下什么环境记录。
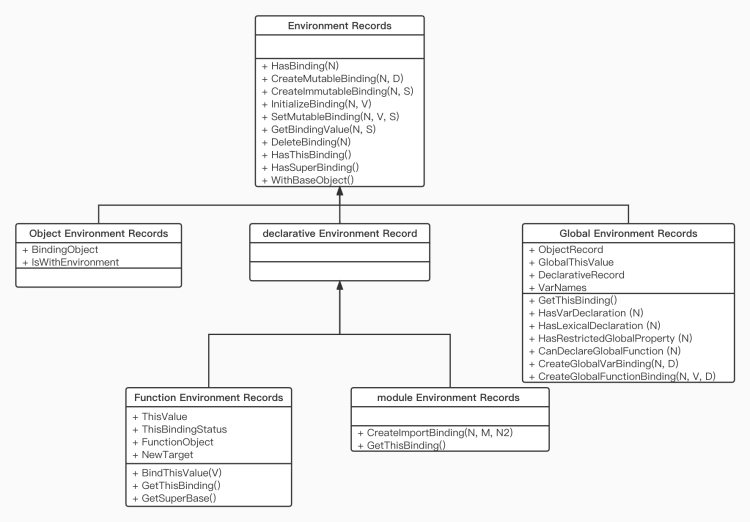
以上是我根据规范内容所整理的一个类图,可以看到环境记录逻辑上可以看成一个面向对象中的一种单继承结构。其中 Environment Records 作为 Object Environment Records、declarative Environment Records、Global Environment Records 的基类,子类根据自己的算法去实现抽象类中的抽象方法。
这里简单介绍一下每个方法的作用,具体的话需要看每个子类实现的算法,由于子类比较多这里就不整理了,文档中的算法步骤描述的也很清楚。
| 方法名 | 作用 |
|---|---|
| HasBinding(N) | 查看当前执行上下文中的环境记录项中是否存在标识符 N |
| CreateMutableBinding(N, D) | 创建一个标识符 N,D 表示可以在后续的操作中可以对该标识符进行删除 |
| CreateImmutableBinding(N, S) | 创建一个不可变的标识符 N,S 表示该上下文是否处于严格模式下,该标识符未初始化时进行访问会抛出一个异常 |
| InitializeBinding(N, V) | 初始化标识符 N 的值为 V |
| SetMutableBinding(N, V, S) | 设置环境记录中标识符 N 的值为 V,S 表示是否为严格模式,如果该标识符的值不能进行设置值时会抛出一个类型错误异常 |
| GetBindingValue(N, S) | 获取环境变量中标识符 N 的值,S 是否为严格模式,如果表示符为创建或者创建了未绑定则抛出引用错误异常 |
| DeleteBinding(N) | 删除环境记录中标识符 N |
| HasThisBinding() | 查看环境记录中是否存在 this 绑定 |
| HasSuperBinding() | 查看环境记录中是否存在 super 方法绑定 |
| WithBaseObject() | 如果当前环境记录为 Object Environment Records 时,表示绑定的对象 |
以上就是基类中的所有抽象方法,每个方法的具体算法步骤根据子类来定,比如 DeleteBinding(N) 方法只有当前环境记录为 Object Environment Records 时才有具体实现,别的子类直接返回 true。因为标识符本身是不能被删除的,只有对象的 key 才能被删除,Object Environment Records 表示我们使用 with 这样的语句才会创建对应的记录项,因为 with 中的标识符会与 with 的对象的 key 做一个关联绑定,当然 key 要符合规范文档中的标识符词法产生式(规则)。所以在 with 语句中我们可以对绑定的对象的 key 使用 delete 运算来达到 with 中的标识符删除。
标识符的查找是从当前运行的执行上下文的环境记录中解析的。因为像 let 或者 const 变量声明加上块(block)会产生新的词法作用域。环境记录中 LexicalEnvironment 也会用栈来维护这样的结构,如:
function foo(){
var a = 1
let b = 2
{
let b = 3
var c = 4
let d = 5
console.log(a)
console.log(b)
}
console.log(b)
console.log(c)
console.log(d)
}
foo()以上代码大家应该都能看得出输出的顺序是什么吧。那用图表示就是一下这种结构
可以看到 LexicalEnvironment 中存在两个一样的标识符 b,程序在解析该标识符的时候先从 LexicalEnvironment 中的栈顶去解析。所以标识符 b 的内容是 3 而不是 2。
上面例子中的标识符都是存在当前执行上下文中的,那如果当前上下文中环境记录不存在要访问的标识符怎么解析呢?
实际每个环境记录都有一个 OuterEnv 引用,该引用指向词法结构上或代码结构上的外层环境记录,最外层环境记录的 OuterEnv 引用指向 null,所以标识符的查找过程很像对象中属性的查找过程,只不过标识符查找到最外层还没找到的时候就会报引用错误。属性的查找如果找不到结果会 undefined。
实际我在理解这些内容之后让我了解到为什么基础数据类型为什么存在栈中,而引用类型数据存在堆中。上下文是用栈这种结构来进行维护,表示符又是存在于上下文中,栈这种结构的特点是具有连续性,物理内存中申请一块连续大的内存空间资源是比较宝贵的,哪怕内存空间足够大因为空间的不连续也容易导致内存申请失败。所以栈中的内存释放是在该上下文被校会的时候就会被释放掉。堆中的内存需要垃圾回收机制算法来释放对应的内存空间,所以堆的一个特点我理解的就是可以存放生命周期比较长的数据如闭包,可以存放比较占用空间资源的数据,比如对象,栈中只不过存储对象的引用。如果理解有误或者有什么错误的地方欢迎大家一起来讨论。
最近看了一下 ant-design 中的 tree 组件源码时发现 useEffect 中根据 props 来计算当前函数组件的 state 的,感到好奇,因为这样会导致应用重新绘制一次,这样才复杂场景下会对应用有一定的性能影响。为了验证自己猜想是否正确做了一下实践。这里的 React 是官方 16.12.0的源码。
import * as React from './react-source/packages/react'
import * as ReactDOM from './react-source/packages/react-dom'
const root = document.getElementById('root');
function Foo({number}) {
const [number2, setNumber2] = React.useState(0);
React.useEffect(() => {
setNumber2( number + 1)
}, [number])
return <div>
{number2 % 2 === 0 && <div>{number2}</div>}
<button onClick={() => setNumber2(number2 + 1)}>更新 number2</button>
</div>
}
function App() {
const [number1,setNumber1] = React.useState(1);
return <>
{number1 % 2 === 0 && <div>{number1}</div>}
<Foo number={number1}/>
<button onClick={() => setNumber1(number1 + 1)}>更新 number1</button>
</>
}
ReactDOM.render(<App/>, root)这里有两个组件, APP 函数组件有一个 number1 的 state,并作用 Foo 函数组件的 number props传递给子组件。Foo 子组件在 useEffect 中 依赖 number 的变化来更新该组件的 number2 state。
为了监听 root 节点变化的情况我使用了 MutationObserver API 来看看监听回调函数执行了多少次,所以在测试代码中增加了如下代码
const root = document.getElementById('root');
const observer = new MutationObserver(mutations => {
console.log(mutations)
} )
observer.observe(root, {
childList: true,
subtree: true
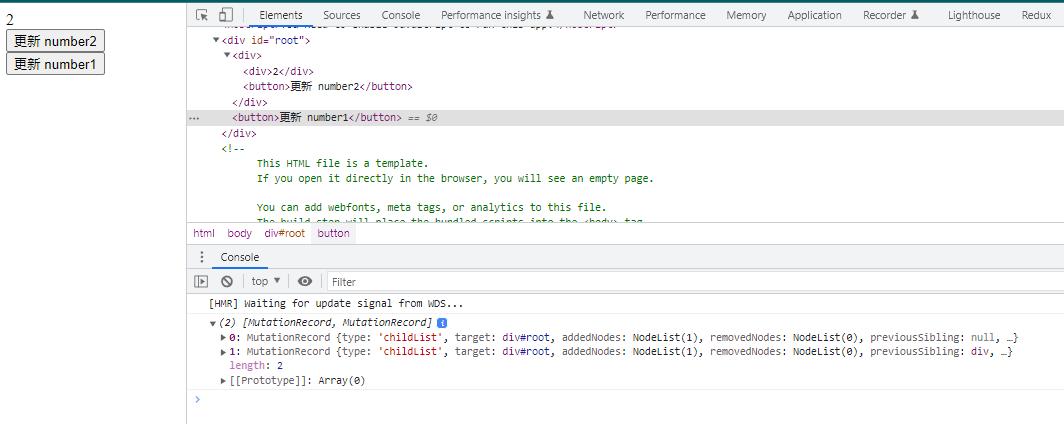
})来看一下第一渲染时界面输出的效果
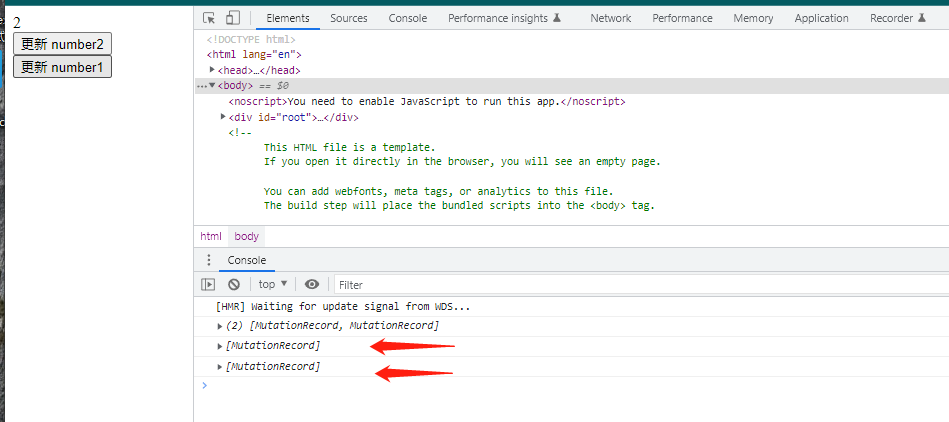
可以看到 MutationObserver 回调被执行了两次, mutations 中有两项新增记录,对应 root 的新增两个子节点。现在再看看我点【更新number1】按钮之后的结果
可以看到 MutationObserver 这个回调被执行了两次,也就是但这个按钮的时候页面绘制了两次。
import * as React from './react-source/packages/react'
import * as ReactDOM from './react-source/packages/react-dom'
const root = document.getElementById('root');
const observer = new MutationObserver(mutations => {
console.log(mutations)
} )
observer.observe(root, {
childList: true,
subtree: true
})
function Foo({number2,setNumber2}) {
return <div>
{number2 % 2 === 0 && <div>{number2}</div>}
<button onClick={() => setNumber2(number2 + 1)}>更新 number2</button>
</div>
}
function App() {
const [number1,setNumber1] = React.useState(1);
/**
* 这里例子可能不太好,因为但从这里例子来看 number 没必要再调用
* useState,实际项目应用场景中有的比较复杂的逻辑,状态之间有关联是
* 比较常见的
*/
const [number2, setNumber2] = React.useState(0);
return <>
{number1 % 2 === 0 && <div>{number1}</div>}
<Foo number2={number2} setNumber2={setNumber2}/>
<button onClick={() => {
let newNumber1 = number1 + 1
setNumber1(newNumber1)
setNumber2(newNumber1 + 1)
}}>更新 number1</button>
</>
}
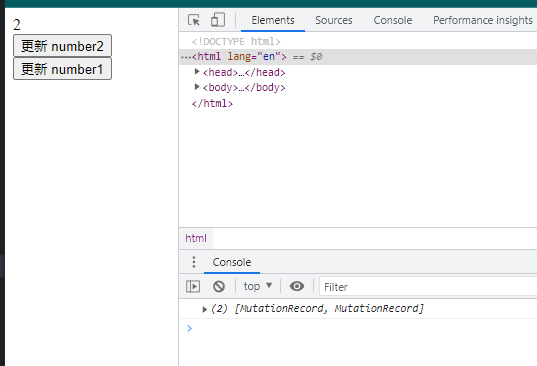
ReactDOM.render(<App/>, root)优化有的代码就是把 Foo 状态提升到父组件中,然后把状态以及更新函数传给子组件就行。这样我们再来看一下点击【更新number1】之后的效果图
可以看看到这次 MutationObserver 的回调只被执行了一次。
项目中还是尽量减少应用的重复绘制次数,不然会影响用户的交互体验,最差的情况可能还会看到每次绘制的中间状态,视觉上给人一种很卡的感觉。虽然性能提升上去了,但是代码的可维护性变差了,这种的就看你怎么平衡了,如果性能如果能接受的话,个人还是感觉代码的可维护性重要些。实践的时候还发现了一个 MutationObserver 的一个问题,就是我对 DOM 节点的文本进行修改的时候,MutationObserver 的回调居然没有执行让我有些意外。
关于样式的相关概念介绍
使用产生式来表达样式规则语法
style-rule ::=
selectors-list {
properties-list
}
selectors-list ::=
selector[:pseudo-class] [::pseudo-element]
[, selectors-list]
properties-list ::=
[property : value] [; properties-list]
样式规则示例
strong {
color: red;
}
div.menu-bar li:hover > ul {
display: block;
}简单选择器使用特定的分割符号(*、.、# ...)
=号与value也可以不写,表示选中带有attr的属性选择器复合选择器有简单选择器组成,简单选择器之间不能有空可,所表达的含义为与的关系,如
<style>
/*选择同时带有class为a和b的元素*/
.a.b {
color: skyblue;
}
</style>
<div class="a b">123</div>使用,号分割多个选择器集合起来的一个列表,不与参与选择器优先级的运算
选择器列表 A,B
指定同时选择 A和B元素。这是一种选择多个匹配元素的分组方法
组合选择器是两个或多个简单选择器之间建立关系的选择器,例如“A是B的子代”或“A与B相邻”,选择器之间使用特定的符号来链接,如+、~、 空格、>
相邻兄弟选择器 A + B
指A和B选择的元素具有相同的父元素,并且B选择的元素在水平方向上紧随A选择的元素
<style>
/*文本为2的所在元素的颜色为skyblue*/
.a + .b {
color: skyblue;
}
</style>
<div class="a">1</div>
<div class="b">2</div>
<div class="b">3</div>普通兄弟选择器 A ~ B
指由A和B选择的元素共享相同的父元素,并指定A选择的元素在B选择的元素之前,但不一定紧接在B之前
<style>
/*文本为3和4的所在元素的颜色为skyblue*/
.a~.b {
color: skyblue;
}
</style>
<div class="a">1</div>
<div class="c">2</div>
<div class="b">3</div>
<div class="b">4</div>子选择器 A > B
指B选择的元素是A选择的元素的直接子元素
后代选择器 A B
指B选择的元素是A选择的元素的后代,不一定是直接子代
伪类选择器使用:表示,用来操作用户交互或浏览器机制所带来的状态改变
伪元素选择器使用::或:表示,伪元素它的作用会在当前DOM树种新增一个元素,该元素不存在html代码标签中
简单选择器的计算
把选择器分为四级 [内联,ID,类|属性,标签],计算的是组合选择器(复杂选择器)的优先级,如:
复杂选择器#id div.a#id的优先级计算方式为,[0个内联样式,2个ID选择器,1个class选择器,1个标签选择器],优先级的比较方式是两个这样的四元组从左往右一一对应进行对比,直到比较出谁大则停止比较,则谁的优先级就高;
div#a.b .c[id=x]统计的结果为[0,1,3,1],0个内联,1个id(#a),2个class(.b与.c)加上1个属性[id=x],1个标签a
<style>
#a:not(#b) {
color: red;
}
/*这里的优先级与上面一直都是[0,2,0,0],上面的:not不参与优先级计算,根据后面样式覆盖前面样式的规则,所以最终颜色为 green,不参与优先级计算的还有*号*/
#x #a {
color: green;
}
</style>
<div id="x" class="b">
<div class="c d" id="a">Devan</div>
</div>A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.