- Overview
- General
- Big O Complexity
- Data Structures
- Algorithms
- Sorting
- Searching
- Processes and Threads
- Languages
- Design Patterns
- Networking
- System Design
- Misc
- References
A handly refresher list for engineering code interviews.
- Ask clarifying questions (user story, constraints, edge cases)
- Break problem into components
- Identify bottlenecks, tradeoffs
- Talk out loud
- Whiteboard approach, code on laptop
- Naive solution, then optimize
- An important algorithm design technique is to use sorting as a basic building block, because many other problems become easy once a set of items is sorted
- Time/space complexity, resource (e.g. network) estimation
- Long stretches of silcence
- Panic (just an interview)
The measurement of processing time (number of algorithm steps) as an input size grows—not the objective performance of a program (e.g. constant time could be 1,000 years, exponential time for a small number of n may be fast).
Multiple complexities are reduced to just the largest (e.g. O(n^2) + O(n) + O(log n) has a complexity of just O(n^2)).
constant 1 < logarithmic log(n) < linear n < super-linear n*log(n) < quadratic n^2 < cubic n^3 < exponential 2^n < factorial n!
- All pairs:
O(n^2)(double-nested loop) - All triples:
O(n^3)(triple-nested loop) - All permutations:
n!(every combination) - All subsets:
2^n(at each element, fork and select + don't select) noverk(i.e.kitems from a set ofn):n!/(k!*(n-k)!)
An algorithm is considered "fast" if it can be run in polynomial O(n^k) time—although not always true in practice (e.g. O(n^20).
A problem can be considered P (solution found in polynomial), NP (solution verified in polynomial), NP-complete (family of NP problems with no P solution) and NP-hard (non-deterministic polynomial).
All about tradoffs—the right tool for the job.
- Arrays
[]- Good. Storing data (space-efficient), constant indexed lookups, iteration (elements adjacent in memory).
- Bad. Insertions/eletions in the middle, unknown number of elements (fixed-size), linear search (unsorted).
- Set
new Set()- Math set implented as an array (with all the pros and cons associated).
- Good. No duplicates.
- Bad. Unordered.
- Dynamic arrays
new ArrayList()- Good. Elastic array size.
- Bad. Time to grow array, slow insertions/deletions, linear search (unsorted).
- Linked lists
new LinkedList()- Can be single or doubly-linked (both directions).
- Good. Constant insert/delete, linear search, no overflow.
- Bad. Additional space for pointers, linear search (even if sorted).
- Stacks and queues
- Stacks are LIFO (Last In First Out), queues are FIFO (First In First Out). Implemented as a dynamic array or linked list.
- Good. Ordered data.
- Bad. Simplistic uses.
- Hash
{}- Collision can be handled by an array/list, or double-hashing. Implementations include set (no duplicates, allows null key), map (allows null keys and values) and table (synchronized, no null keys/values).
- Good. Constant lookup (depending on hash collisions), dictionaries.
- Bad. Unordered.
- Bloom filter
- Probabilistic data structure that allows a query on a set to return either "possibly in set" or "definitely not in set".
Graphs are compised of verticies (nodes), edges (connections), branches and leaves. Can be directed (one-way) or undirected (bi-directional). Trees are a simply a type of graph.
- Adjacency matrix—multi-dimensional array representing each node and its relationship to other nodes. Constant lookup, lots of space (especially if few edges).
- Adjacency list—objects pointing to each other. Harder to determine if an edge exists.
Self-balancing trees automatically balance the height of nodes to keep search operations logarithmic (based on node heights).
- Binary
- Each node has a maximum of 2 children.
- BST (Binary Search Tree)
- Ordered binary tree, time based on tree height (balanced), tree rotation on insert/delete. Good for searching
O(log N), range searches, in-order traversal, adjacent elements.
- Ordered binary tree, time based on tree height (balanced), tree rotation on insert/delete. Good for searching
- Red-Black
new TreeMap()- Painted nodes (red, black -- 1 bit extra per node) and rules to self-balance, rearranged and repainted on insert/delete.
- Splay
- Recently accessed elements moved closer to the root position for faster re-access (in real-world situations).
- AVL
- Better balanced than Red-Black for slower insert/delete, but faster search.
- Trie (Prefix)
- Strings as trees where edges represent one character and the path from root representing a string. Good for string searching (e.g. auto-completion).
- Ternary Search
- BST with up to 3 children (lo, eq, hi), more space-efficient but slower. Good for spell-checking and autocomplete.
- Patricia
- Radix
- Compressed (merge single-child nodes) version of Prefix.
- Suffix
- For locating substrings in linear time.
- B-Tree (Balanced)
- Works well for large data (too big for memory, stored on disk), used by databases, similar to Red-Black, nodes can have many children.
- Interval
- Red-Black tree that maintains a dynamic set of elements, each containing an interval.
- DAWG (Directed Acyclic Word Graph)
- Set of all substring, simplar to Suffix tree.
- Cartisean
- Retains the same order from top-to-bottom as left-to-right
- Heap
- Complete binary tree (all leaves filled except bottom layer), min or max value at root.
- Recursion
- See: recursion.
- Greedy
- Take the optimal solution at each step (even if worse overall). Good for shortest path in a graph (Dijkstra).
- Divide-and-Conquer
- Break into chunks, process (often recursively), and merge results.
- Lends to parallelization, requires more space, best when merging takes less time than solving sub-problems.
- DP (Dynamic Programming)
- Confusing name originating from its creator, Richard Bellman, wanting to obfuscate his research!
- Smart brute force guessing.
- Break a problem into sub-problems, store previous results (memoization, from taking "memos") to avoid re-calculating.
- Only useful for computing the same subproblem multiple times (e.g. nth Fibonacci). Find recursion in the problem, top-down memoization, bottom-up use of a table.
- Good for left-to-right problems (e.g. substrings), subset sum, 0-1 knapsack (n-choose-k), min path moving right-or-down, LCS (Longest Common Subsequence), LIS (Longest Increasing Subsequence).
Stable sort is one that retains order of equal values.
- Bubble
O(n^2)- Swap adjacent pairs.
- Selection
O(n^2)- Find the next minimum, swap, repeat.
- Insertion
O(n^2)- Sort next value, swap, repeat.
- Heap
O(n*log(n))- In-place selection sort using a heap data structure for constant access to target item. Slower than quicksort, but better worst.
- Shell
- Insertion sort of elements that are ideally far apart.
- Quick
O(n*log(n))- 2-3x faster than heap/merge, select pivot, sort left/right of pivot, recursion.
- Merge
O(n*log(n))- Split until single element, merge together in order.
- Tim
- Merge natural runs of data (common in the real world) to reduce number of comparisons.
- Cube
- Self-balancing multi-dimensional array! (created 2014)
- Distribution
O(n+k)- Split into buckets (e.g. 1-10, 11-20), sort. Requires roughly uniform data distribution to be effective.
- Counting
- For repeated elements within a known range, store the counts, then reconstruct. Good for finding mean/median/mode.
- Radix
O(n*k)- Alternative term for 'base' and Latin for 'root'. Count or bucket sort on one radix (least-significant bit, character, etc.) at a time.
- Binary
O(logn)- Must be sorted.
- Depth-First Search (DFS)
O(V + E)- Recursion (stack) over graphs. Good for topological sorting, finding cycles,
- Pre-order: root, left, right
- In-order: left, root, right
- Post-order: left, right, root
- Breadth-First Search (BFS)
O(V + E)- Queue over graphs. Good for shortest path, degrees of separation, GC scanning.
- Dijkstra (pronounced "die-sktra")
O(E + V*log(V))- Find shortest path between one node and ALL other nodes. Can't have negative weights.
- A*
- Extension of Dijkstra which achieves better time performance by using heuristics.
-
Process. Self-contained execution environment with it's own memory space (synonymous with programs or applications) containing 1-or-more threads.
-
Thread. Execution environment within a proces, shares process memory, fewer resources to spawn. Context switching between threads (of a single process, or multiple) running on CPUs cost time.
-
Stack. LIFO memory per thread execution, fast (simple access pattern).
-
Heap. Program memory, shared between threads.
-
Virtual Memory. Abstraction that virtualizes memory as a continuous address space.
-
Lock. Restricts mutation of object to a single thread (at any given time), slower.
-
Monitor. Cross-thread lock.
-
Mutex. Cross-process lock (i.e. system-wide) to syncronize access to a resource (e.g. CD drive).
-
Semaphore. Lock that allows N threads to access (i.e. pooling).
-
Deadlock. Threads lock a resource required by the other. Stalemate. Avoid by setting an order for locks (e.g. A then B).
-
Livelock. Threads infinitely repsond to the action of the other. Two people passing in a corridoor (each shifting left/right at the same time). Avoid by adding some randomness.
-
Starvation. Thread unable to access a resource.
-
Race Condition. Multiple threads mutating shared data at the same time, uncertain ordering of processing. Avoid with locks or timestamps.
- Imperitive
- Declarative (Functional a subcategory)
- Encapsulation—reusable, self-contained (sometimes "black-box") components of related state and behavior.
- Inheritance—defined behavior and characterstics between objects.
- Polymorphism—different objects that share the same in interface ("many forms") and can be used interchangeably.
- Single-responsiblity (classes do a single job)
- Open-closed (classes open for extension, closed for modification)
- Liskov substitution (every subclass/derived class should be substitutable for their base/parent class)
- Interface segregation (don't be forced to implement unused interfaces or interface methods)
- Dependency Inversion (depend on abstractions, not concrete implementations i.e. Dependency Injection)
- Factory
- Builder
- Singleton
- Adapter
- Facade
- Decorator
- Proxy
- Chain of responsibility
- Command
- Iterator
- Visitor
| Sr No | Layer | Data unit | Examples |
|---|---|---|---|
| 1 | Physical | bit | Ethernet, USB, Wi-Fi, Bluetooth, DSL |
| 2 | Data link | Frame | L2TP, PPP |
| 3 | Network | Packet | IPv4, IPv6 |
| 4 | Transport | Segment (Datagram) | TCP, UDP |
| 5 | Session | Data | HTTP, FTP, SMTP, DNS, IMAP, SSH, TLS |
| 6 | Presentation | Data | ASCII, JPEG |
| 7 | Application | Data | Chrome, Mail.app |
- IP (Inernet Protocol)
- Packet routing around connectivity problems (dropped packets), no delivery guarantee, multiple copies, multiple paths.
- TCP (Transmission Control Protocol)
- Built on top of IP, connection-based between computers, splits data into packets, guarantees arrival and ordering of packets, flow control.
- UDP (User Datagram Protocol)
- Thin layer on top of IP, minimizes delay at cost of 1-5% packet loss, no ordering guarantee, manual data splitting and flow control. Good for real-time data such as gaming and audio/video streaming.
- RPC (Remote Procedure Call)
- As if executed locally, communication layer abstracted away. Performant but tighter coupling and harder upgradability.
- REpresentational State Transfer (REST)
- Stateless, HATEOS, Graph API
- Scaling (vertical, horizontal, caching, load balancing, replication, partitioning, map-reduce, CDN -- push/pull, fan-out service, hash collisions)
- Concurrency, networking, real-world performance, availability, performance
- Web app: SEO (server-side rendering), progressive enhancement, graceful degredation, lazy loading, HTTP/2, tooling, responsive design
- Data replication (cluster of machines, redundancy, eventual consistency, geographic spread, file size, security, distributed)
- Rate limiting APIs (exponential backoff)
- Spelling suggestion (read dictionary, standardize lowercase/stripped, frequency count, find variants adding/removing/transposing characters, past/plural tenses, generate all variants, store, sort by score)
- Search engine (crawler, store content/metadata, index, query, ranking, re-index)
- Query types (single word, phrase), similar searches, context (georgraphy, time), tokenize query words and union results.
- Ranking. Weight words within a document, count and quality of linking documents (weighted graph with node containing sum)
- Design Twitter. Fan-out vs fan-in, push vs pull, Beirber effect, more reads than writes, Redis clusters, deliver messages in under 5sec.
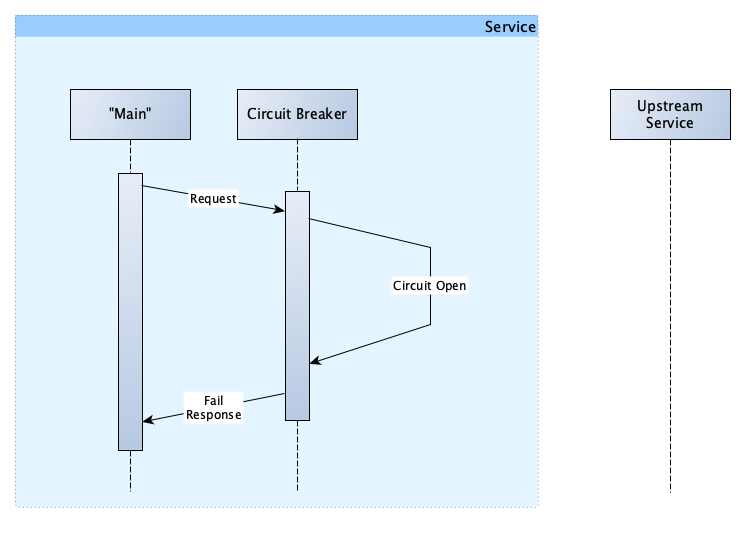
- Circuit breaker (temporarily protect upstream services from further 5xx requests if it fails by (https://engineering.grab.com/img/designing-resilient-systems-part-1/cb-circuit-open.png)["opening the circuit"] so it can recover). Potential fallback to other service providers.
- Trade-offs: Performance vs scalability, availability vs consistency, usability vs security, latency vs throughput
- CAP Theorem (Consistency, Availability, Partition tolerance). CP and AP.
- Consistency (weak, eventual, strong)
- Availability (fail-over -- active/passive or active/active, replication)
- DNS (browser, DNS servers, propagation, NS, MX, A, CNAME, Route53)
- Load Balancer (SSL termination, sticky sessions, Layer4 routing, Layer7, stateless, reverse proxy unified interface)
- Microservices (service discovery / mesh, internal communication gRPC)
- Database (ACID, master/slave or master/master replication, federation, sharding, RDBMS, NoSQL, Graph, normalization, denormalization for read performance)
- Caching (client/browser, CDN, web server, database, application, TTL, invalidation, cache-aside, write-through, write-back, refresh-ahead)
- Async (message queues, task queues, back pressure)
- Security (encryption in transit and at rest, sanitize inputs, hash passwords, least priviledge, MFA, OWASP)
Heuristics are "rule of thumb" techniques for problem-solving.
& AND (both 1), | OR (either 1), ^ XOR (single 1), << left shift (multiply by 2^n.), >> right shift (divide by 2^n.
- ASCII (American Standard Code for Information Interchange). Basic set of 128 characters in 7 bits, with ANSI standards for characters 128-255 (the 1 extra bit) that differ between countries/languages.
- Unicode. Most used, 120,000 characters mapping to unique hex numbers (code points). Example:
A = 41 (U+0041). Encoded (to bytes) using UTF-8, which is compatible with ASCII.
Power Exact Value Approx Value Bytes
---------------------------------------------------------------
7 128
8 256
10 1024 1 thousand 1 KB
16 65,536 64 KB
20 1,048,576 1 million 1 MB
30 1,073,741,824 1 billion 1 GB
32 4,294,967,296 4 GB
40 1,099,511,627,776 1 trillion 1 TB
Latency Comparison Numbers
--------------------------
L1 cache reference 0.5 ns
Branch mispredict 5 ns
L2 cache reference 7 ns 14x L1 cache
Mutex lock/unlock 25 ns
Main memory reference 100 ns 20x L2 cache, 200x L1 cache
Compress 1K bytes with Zippy 10,000 ns 10 us
Send 1 KB bytes over 1 Gbps network 10,000 ns 10 us
Read 4 KB randomly from SSD* 150,000 ns 150 us ~1GB/sec SSD
Read 1 MB sequentially from memory 250,000 ns 250 us
Round trip within same datacenter 500,000 ns 500 us
Read 1 MB sequentially from SSD* 1,000,000 ns 1,000 us 1 ms ~1GB/sec SSD, 4X memory
Disk seek 10,000,000 ns 10,000 us 10 ms 20x datacenter roundtrip
Read 1 MB sequentially from 1 Gbps 10,000,000 ns 10,000 us 10 ms 40x memory, 10X SSD
Read 1 MB sequentially from disk 30,000,000 ns 30,000 us 30 ms 120x memory, 30X SSD
Send packet CA->Netherlands->CA 150,000,000 ns 150,000 us 150 ms
Notes
-----
1 ns = 10^-9 seconds
1 us = 10^-6 seconds = 1,000 ns
1 ms = 10^-3 seconds = 1,000 us = 1,000,000 ns
Handy metrics based on numbers above:
- Read sequentially from disk at 30 MB/s
- Read sequentially from 1 Gbps Ethernet at 100 MB/s
- Read sequentially from SSD at 1 GB/s
- Read sequentially from main memory at 4 GB/s
- 6-7 world-wide round trips per second
- 2,000 round trips per second within a data center
- Set theory, inite-state machines, regular expressions, matrix multiplication, bitwise operations, solving linear equations, important combinatorics concepts such as permutations, combinations, pigeonhole principle, processes/threads (OS, locks, mutex, semaphores, deadlock, livelock), data structures (e.g. linked-lists), distributed hash table, queues/schedulers, dynamic vs compiled, strongly vs weakly typed, functional vs imerative, parallelization (e.g. mapreduce)
- https://github.com/donnemartin/system-design-primer/blob/master/README.md (EXCELLENT system design primer)
- https://github.com/orrsella/soft-eng-interview-prep
- MIT introduction to algorithms (Youtube)
- https://techiedelight.quora.com/500-Data-Structures-and-Algorithms-interview-questions-and-their-solutions



%5B%22opening){kind=link}