
This is the official implementation of the following CVPR 2021 paper:
Learning To Count Everything
Viresh Ranjan, Udbhav Sharma, Thu Nguyen and Minh Hoai
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021.
Link to arxiv preprint: https://arxiv.org/pdf/2104.08391.pdf
Short presentation video
Images can be downloaded from here: https://drive.google.com/file/d/1ymDYrGs9DSRicfZbSCDiOu0ikGDh5k6S/view?usp=sharing
Precomputed density maps can be found here: https://archive.org/details/FSC147-GT
Place the unzipped image directory and density map directory inside the data directory.
conda create -n fscount python=3.7 -y
conda activate fscount
python -m pip install matplotlib opencv-python notebook tqdm
conda install pytorch==1.4.0 torchvision==0.5.0 cudatoolkit=10.0 -c pytorch
Provide the input image and also provide the bounding boxes of exemplar objects using a text file:
python demo.py --input-image orange.jpg --bbox-file orange_box_ex.txt Use our provided interface to specify the bounding boxes for exemplar objects
python demo.py --input-image orange.jpgWe are providing our pretrained FamNet model, and the evaluation code can be used without the training.
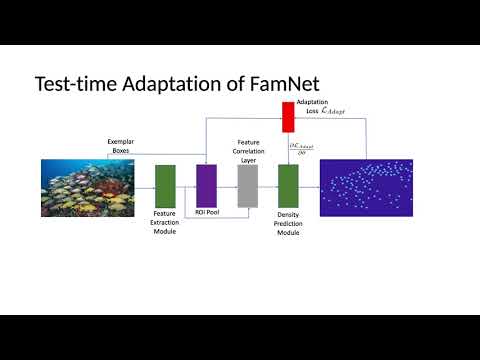
python test.py --data_path /PATH/TO/YOUR/FSC147/DATASET/ --test_split valpython test.py --data_path /PATH/TO/YOUR/FSC147/DATASET/ --test_split val --adaptpython train.py --gpu 0If you find the code useful, please cite:
@inproceedings{m_Ranjan-etal-CVPR21,
author = {Viresh Ranjan and Udbhav Sharma and Thu Nguyen and Minh Hoai},
title = {Learning To Count Everything},
year = {2021},
booktitle = {Proceedings of the {IEEE/CVF} Conference on Computer Vision and Pattern Recognition (CVPR)},
}
































































































































