cult-of-coders / grapher Goto Github PK
View Code? Open in Web Editor NEWGrapher: Meteor Collection Joins + Reactive GraphQL like queries
Home Page: https://atmospherejs.com/cultofcoders/grapher
License: MIT License
Grapher: Meteor Collection Joins + Reactive GraphQL like queries
Home Page: https://atmospherejs.com/cultofcoders/grapher
License: MIT License





































































































































Just create an "extend" and allow method with (parent, ...args)
you can do
query = createQuery({})
query.createExtension({
profile: {
firstName,
lastName
}
})
Deep merge objects.
Try to hack the system:
Test exposure more, at deeper levels, try to hack it.
Try to hack the aggregate pipeline. Analize the code first.
Hacking ideas:
users: {
$filters: { $or: { '_id': {$exists: true} } } // see if it bypasses our filters
comments: {
$filters: { $or: {'_id': {$exists: true} }; // check if sublinks of any kind can be filter bypassed
// this means one,many,one-meta,many-meta,resolver.
}
}
users: {
$limit: -1 // see what that does
comments: {
$options: {sort: [some-hack-to-the-pipeline], limit: [same]},
$filters: { $not: { userId: null } }
// try also to by pass via other logical operators $or $nor $not $and
}
}
When fetching direct metadata relations.
Store in "$metadata" field in the response the actual metadata they are assigned with in the parent.
$count: {
'users': 1,
'comments': {approved: true}
}
Store as
document.$count.users
$filter() function even if it's powerful it can sometimes be annoying
{
filters:{
status: '#status'
}
}
$status will be read as parameter.
Since you can specify any $filters in your request.
You should also deep-search it and remove those fields from $or and $and.
NOTE: this is a continuation of a thread on Meteor Forums.
Really cool project 😃
What are some ideas as to how one could make graph queries with Grapher? E.g. when doing such as 'affinity analysis' (a.k.a. 'market basket analysis' or building a 'recommendation engine').
Given a product in our store (graph of products and baskets)
What are the products most often purchased in the same cart as this product?
So we can add a 'recommended products' list to this product page
Given a person with a favorite books list (graph of books and reading lists)
What are the books most related to this persons reading interests?
So we can add a 'recommended reading' list to the user homepage.
Source: Extending market basket analysis with graph miningtechniques: A real case
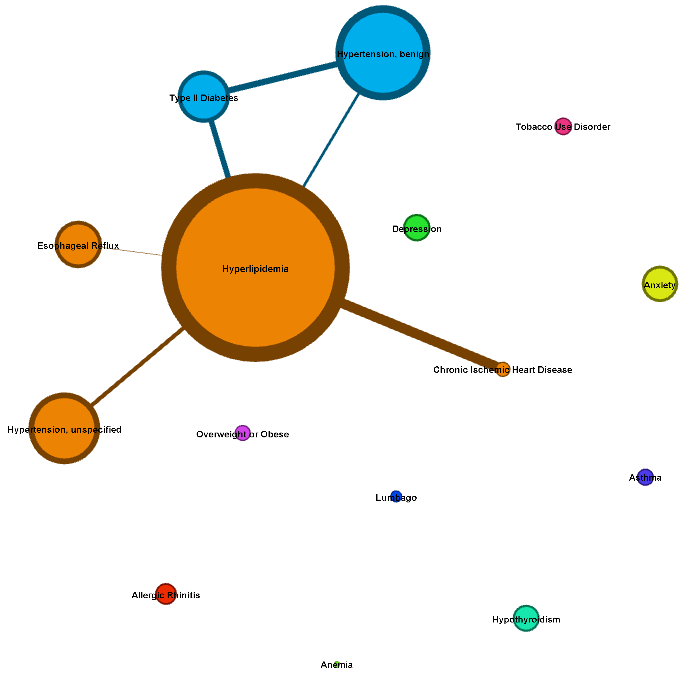
Given a patient diagnosis (graph of symptoms and diagnoses)
What are likely diseases/disorders that the patient may also experience?
So that we can plan proper treatment for the patient.
Patient population #1. Note how Chronic Heart Disease has a strong
co-occurrence rate with Hyperlipidemia, but actually occurs less
frequently overall than a number of different diagnoses.
Source: Revisiting the Analysis of Diagnoses in Populations
The following resources further explain the possibilities for using graph queries to perform 'market basket' analysis, build 'recommendation engines', etc.
make use of the _transform function.
Wow. I've just spent quite a bit of time building and refactoring something similar although far less ambitious that Grapher. I love how you have exposure working rather than named queries, but can see how it would get out of control in anything beyond a trivial app.
What I ended up doing was defining 'views' on top of collections. These views provide similar firewalling and filtering based off the current user (what I call viewer). But by separating views from their collections I can have multiple views per collection. From the example at the top of your named query docs there could be a 'EndUser' view and a 'TeamMember' view. If these views were then used in links (rather than just Users) then you get around the problem as well as making your specification more closely match the domain.
Would that be appropriate for Grapher?
What I love about exposure is that so often what fields and links you want is a concern of the client, not the server. In the same way that the decision of reactive/publication or static/method is a client concern too. It would be great if exposure could get over this hurdle and become useful beyond trivial apps.
Tests.createQuery({$_id: ""})
Hypernova is the tool that lets us aggregate filters and assemble the data meaning we make predictable number of requests to db and reduce it dramatically.
Now, for subscription we use as a backbone: publish-composite meteor packages.
Try to see if there is a way to integrate Hypernova in it. Write performance tests.
But analyze it first it may not be needed because it depends on how the pub/sub meteor's system works.
The options for reactivity:
Implementation:
Allow options for remove and unset, to remove the referenced object from the db:
.remove([id1, id2], {'autoremove': true})
.unset({'autoremove': true})
Use the same cleaning option, but without actually removing storage field data, bc you need it to build the data graph from local collections.
The reason is that you may have Entity A, which has a link to Users.
When you expose Users you want only an ADMIN to have access to them, otherwise the logged in user, and for the logged in user some fields only.
When you want to get profile general info from a Comment link. Like comments -> author. Then you would need to do additional checks in Users exposure, because currently the exposures are linked.
This is why we are introducing Server-Side Queries. They are defined server-side. Secured optionally separately, and can be called by client like:
const query = createQuery('xxx', body)
query.expose('xxx', {
firewall(params, userId) {
}
})
Separate collection firewall from exposure firewall.
Collection.setFirewall(filters, options, userId) { ... }
Allow firewall to be set only once. Still allow firewall setting from the exposure.
Allow versatility in the exposure name.
Allow ability to have multiple exposures (entry points) for the same collection.
Collection.expose({
name: 'employees',
firewall(cleanedBody) { ... }
})
{
users: {
$leftJoin: ['posts'],
posts: {
}
}
}
Other naming candidates:
existsIf, mustHave, mustContain,
Given an exposure I have the ability to specify it's "body". This will not affect server-side requests.
{
body: {
field: 1,
linkSample1: 1, // the other exposure decides if it exists, if the other exposure has a body, the graph will be intersected
linkSample2: { // bypasses other exposures if they exist
profile: 1
}
}
}
When requesting data, the body of your request will be "intersected" with the body of this request.
Allow control over the current body of request.
body(userId) {
return { ... }
}
// using body makes restrictLinks, restrictedFields absolete, you are given a choice.
const userDocumentsLink = Users.getLink(this.userId, 'documents');
const documents = userDocumentsLink.get(callbackIfClient)
Like we do for direct links.
When I expose a collection I want to specify:
maxLimit - the maximum number of items I allow to retrieve.
maxDepth - how many levels deep do I allow the graph to go.
Collection.expose(...);
expose('collectionName'|Collection, firewall(Function) || {
firewall: Function,
maxLimit: X,
maxDepth: Y,
restrictFields: []
});
Firewall function can do, you may want to apply this depending on the username
this.config({
maxLimit, maxDepth, restrictFields
});
I want to configure the exposure settings globally:
expose.config({
maxLimit: X,
maxDepth: Y,
restrictFields: []
})
const Employees = new CollectionView("employees", { // name should not be used by other Mongo.Collection or NamedQuery
collection: Users,
filters: { roles: 'EMPLOYEE' }
})
You can perform .insert, .update, .upsert, .remove. But filters will be applied on each.
When you do .insert, perform a sift check on document to make sure it is correct and that it matches the filters.
You can expose CollectionViews and Link Them with other collections addLinks, you can expose them, they act like a normal Mongo.Collection.
Add them to the Documentation Exporter.
Two types of caching:
- memory for resolver and collections
https://www.npmjs.com/package/memory-cache
- database and memory for resolvers and collections
In memory for resolver + collection:
https://www.npmjs.com/package/memory-cache
In database for resolver + collection.
The reason for database for collection (which is already in mongodb) is 1. either you want a fairly smaller collection bc that one is to big and search is to slow, either you want something faster like redis.
Collection.cache({
key(collectionObject) { ... }
memory: {
maxLimit: x,
maxSize: x,
lifetime: X // this will have impact on reactivity
}
database: {
maxLimit: x,
maxSize: x,
lifetime: X
type: 'mongodb'|'main'|other'
// if other, you must select a DB Handler (implement abstract class for that)
// insert(filters, options) {} // update(filters, options) // remove
}
})
users: {
groups: {
$filters: { $meta: { isAdmin: true } }
}
}
For example if we have a query like
Collection A has 10 Collection B items
Collection B has 100 Collection C items
Collection D has 1000 Collection D items
When we try to fetch them all it goes really slow.
For about 2200 db requests it takes 2 seconds. That isn't so bad. But maybe we could minimize the database requests based somehow on previously fetched data ? A sort of caching mechanism. No Idea have to think about it.
You may want to use grapher to create an API endpoint using a server-side route.
That accepts JSON object bodies and returns JSON.
"GET", "http://example.com/api", { users: { emails: {} }
Return response as:
{
errors: [{type: 'xxx', message: 'xxx'}, ...]
data: {
users: []
}
}
This debug mode will store in an object all the actions, spent times on each important tasks. You can console.log(it) or send it over an API and process it how you wish.
This will make grapher live able to:
Grapher looks really nice! It reminds me of a better version of react-list-container, which we're currently using for Telescope.
We're thinking about migrating to Apollo/GraphQL though, in which case I would probably no longer maintain react-list-container. If that happens, would it be ok to point people to Grapher or somehow merge both projects? What do you think?
Accessible only from server.
import { extractDocuments } from 'meteor/cultofcoders:grapher';
jsObjectDocs = extractDocuments()
const ZendeskTickets = new ResolverCollection('uniqueNameToIdentifyAsString', {
resolve(filters, options, userId) {
// if filter is userId then return an object
},
extend: {
insert(ticket) {
}
}
onFail(e) {...}
cache: true // false // for each ticket request
})
ZendeskTickets.find(filters, options).fetch()
ZendeskTickets.expose({
firewall(filters, options, userId) {
})
})
ZendeskTickets.addLinks({
user: {
collection: ZendeskUsers // it can also be a resolver collection
type: 'one'
resolve(ticket) {
// API call to an Users API by ticket.userId
}
}
})
ZendeskUsers = new class extends Resolver {
resolve(filters, options) {
if (filters.id) {
// api call to return tickets with that userId
// always return an array, the caller decides if it's one or many.
}
return all users
}
ExtendWithAnyMethod(insert/update/remove) but not find
})
ZendeskUsers.addLinks({
tickets: {
type: 'many',
collection: ZendeskTickets // or string.
resolve(user) {
parent.id in userId in tickets find it.
// this function is responsible of returning "one" or many array
}
}
})
ZendeskUsers.expose({
name: 'zendesk_users'
firewall(filters, options, userId) {
}
})```
Currently there is no caching done by the grapher. For example:
If I take
posts: {
authors: {
authorFriends: {}
}
}
If I already have authorFriends, it should only try fetching the authors I need from the database.
$self means basically current logged in user.
If there is no $self. The query will not execute at all.
Bc you will have a lot of interactions with the current logged in user.
$self: {
friends: {
name: 1
}
}
I want to count the number of my children, not get the actual data.
Currently this can be solved by creating a resolver which does the actual counting for you. But resolver links are prone to performance bottlenecks.
posts: {
commentsCount: {
$counter: 1,
comments: {}
}
}
post = { }
I want based on userId to restrict/disallow certain links.
For example I may have users linked with comments, which are visible only by admin.
I have two ways of enforcing this:
allowLinks: ['comments'],
allowLinks(userId) {
if (!isAdmin(userId) {
return ['comments']
}
}
denyLinks: []
denyLinks()
Ability to add restrictions at link config level?
Users.addLinks({
'comments': {
allow(userId)
deny(userId)
}
});
Like createQuery. Export a addLinks method with the following API:
addLinks({
[collectionName]: [linkData],
})
Query
NamedQuery
This is for exposure body to allow things like
body(userId) {
return {
field: 1,
link(userId) {
return {
field: 1,
anotherLink(userId) {
.... and so on ...
}
}
}
}
}
After resolver collection + links. After API exposure libraries.
Ability to add as a link another grapher
addGraphers({
payments: {
uri: "https://api.grapher.com/",
doc() { ... }
// if http, authorize(req) {POST_DATA or HEADERS}
// if ddp authorize(ddpConnection) {}
}
});
addLinks({
users: {
payments: {
grapher: 'payments',
resolve(user) {
return {
{
payments: {
$filters: { user_id: user.paymentId }
}
}
}
}
}
}
})
If there is a doc give ability to integrate the documentation of each other. And createa "doc graph"
Users.expose({
body: {
profile: 1,
otherThings(userId) { ... }
}
})
Server-Side Only
Collection.getLink(forWhichObject, 'linkName').count()
The problem is that when you have a deep data graph:
{
users: {
posts: {
comments: {
}
}
}
}
You end-up subscribing to a bunch of things really.. because it is not as performant as a "static fetch" which uses hypernova module for assembly of filters and deassembly of data.
You may now want reactivity at user level, or at post level, maybe you want only 'comments'. OR maybe you want it for users and comments. You get the idea, because you may end up subscribing to a bunch of things where you don't need it. Or maybe you just want reactivity at certain fields. (why the heck not?)
I don't know if this is possible. But the idea is I want the ability to specify at which level and which fields I want reactivity. We also need to think what impact it has on the view layer, and how we beautifully integrate it there as well.
It can happen. Especially on resolver links that communicate with an API. That API might be down.
So what you can do is throw a Meteor.Error, or log it somewhere and allow it to fail.
The graph request will see that info as blank, but you do not depend on an untrusted link to retrieve your full graph data.
Add configuration to links:
onFail(exception) {
// log it or throw it as Meteor.Error or anything you want
}
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.