![]()





| The CubeFS Project holds bi-weekly community online meeting. To join or watch previous meeting notes and recordings, please see meeting schedule and meeting minutes. |

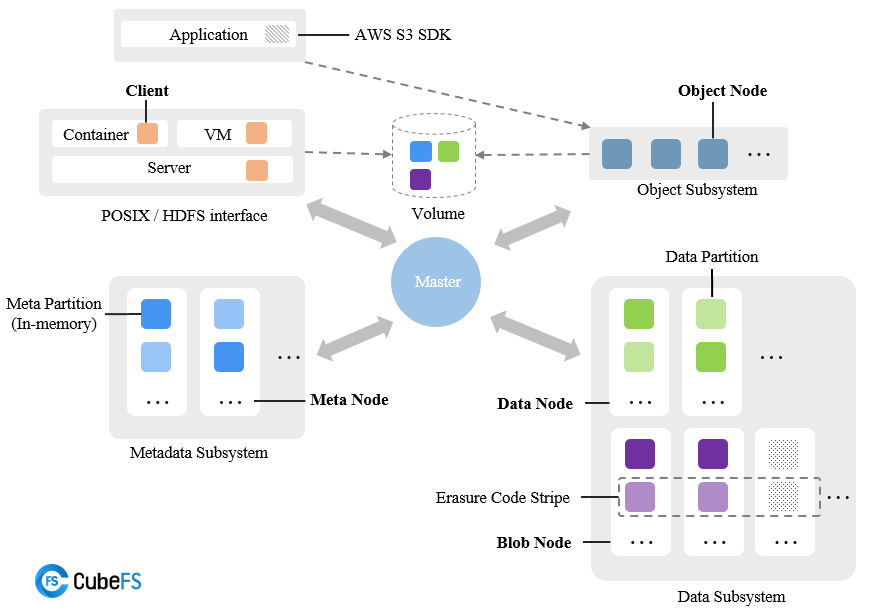
CubeFS ("储宝" in Chinese) is an open-source cloud-native file storage system, hosted by the Cloud Native Computing Foundation (CNCF) as an incubating project.
As an open-source distributed storage, CubeFS can serve as your datacenter filesystem, data lake storage infra, and private or hybrid cloud storage. In particular, CubeFS enables the separation of storage/compute architecture for databases and AI/ML applications.
Some key features of CubeFS include:
- Multiple access protocols such as POSIX, HDFS, S3, and its own REST API
- Highly scalable metadata service with strong consistency
- Performance optimization of large/small files and sequential/random writes
- Multi-tenancy support with better resource utilization and tenant isolation
- Hybrid cloud I/O acceleration through multi-level caching
- Flexible storage policies, high-performance replication or low-cost erasure coding
- English version: https://cubefs.io/docs/master/overview/introduction.html
- Chinese version: https://cubefs.io/zh/docs/master/overview/introduction.html
- Homepage: cubefs.io
- Mailing list: [email protected]
- Slack: cubefs.slack.com
- WeChat: detail see here
- Twitter: cubefs_storage
There is the list of users and success stories ADOPTERS.md.
Haifeng Liu, et al., CFS: A Distributed File System for Large Scale Container Platforms. SIGMOD‘19, June 30-July 5, 2019, Amsterdam, Netherlands.
For more information, please refer to https://dl.acm.org/citation.cfm?doid=3299869.3314046 and https://arxiv.org/abs/1911.03001
CubeFS is licensed under the Apache License, Version 2.0. For detail see LICENSE and NOTICE.
The master branch may be in an unstable or even broken state during development. Please use releases instead of the master branch in order to get a stable set of binaries.




























































































































