Comments (30)
 ArturGudiev
commented on June 9, 2024
3
ArturGudiev
commented on June 9, 2024
3
Hi, I am also a native speaker of Ossetian. I want to participate in the project. My Pontoon username is arturgudiev
from common-voice.
 ftyers
commented on June 9, 2024
2
ftyers
commented on June 9, 2024
2
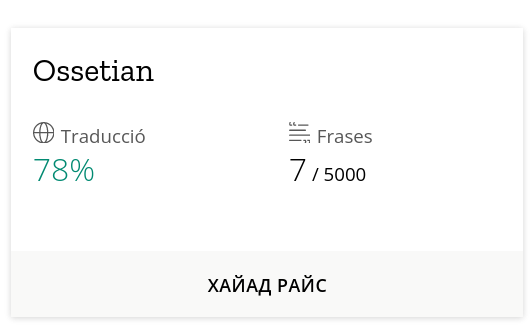
So far Ossetian only has 7 sentences contributed and approved. It will need 750 to launch.
from common-voice.
ftyers
commented on June 9, 2024
1
I've added Ossetian to Common Voice on Pontoon. If you could log in and suggest a translation, I will add you all as translators. Any questions, please feel free to contact us on Matrix.
from common-voice.
ftyers
commented on June 9, 2024
1
I've added @amikeco as a translator, if the other translators could also log in and make suggestions I will add them too. Also, there should be a manager for the locale, ideally it should be a native speaker.
In addition a next step will be to collect 750 public domain sentences in Ossetian for contributors to read out. I'm happy to provide advice on doing this. Please feel free to get in contact with me on Matrix.
from common-voice.
ftyers
commented on June 9, 2024
Dear @amikeco, thank you for your interest in Common Voice. Are you a native speaker of Ossetian or are you in contact with any members of the Ossetian-speaking community?
from common-voice.
 amikeco
commented on June 9, 2024
amikeco
commented on June 9, 2024
Dear @amikeco, thank you for your interest in Common Voice. Are you a native speaker of Ossetian or are you in contact with any members of the Ossetian-speaking community?
I am actually not a native speaker of the language, but I grew up in Ossetia, and I am almost fluent and have experience in translating interfaces (VK, telegram, Wikipedia) and other activities for the language (e. g. presenting it at language festivals, and keeping a popular site about the language).
Yes, I am in contact with the community, I think I can reach thousands of views with my announcements. I also can contact personally a dozen of speakers who may be interested in the activity like translating the interface, collecting the texts and reading them for the Common Voice initiative.
from common-voice.
ftyers
commented on June 9, 2024
That sounds fine! It would be good to have speakers involved in the translation. Could you invite them to make Pontoon accounts and post them here? Thanks!
from common-voice.
amikeco
commented on June 9, 2024
That sounds fine! It would be good to have speakers involved in the translation. Could you invite them to make Pontoon accounts and post them here? Thanks!
All right, going to do that.
from common-voice.
 chibrus
commented on June 9, 2024
chibrus
commented on June 9, 2024
I am a native speaker of Ossetian ( or Ossetic), I would like to take part in the project. My username at Pontoon is "chibupel".
from common-voice.
 theJosephGoodman
commented on June 9, 2024
theJosephGoodman
commented on June 9, 2024
Hi! Could you please add ossetian language. I am a native speaker of ossetic too. My Pontoon username is geor_lolaev. Right now I have free time, so I can help in translating
from common-voice.
amikeco
commented on June 9, 2024
I am a native speaker of Ossetian ( or Ossetic), I would like to take part in the project. My username at Pontoon is "chibupel".
Hi! Could you please add ossetian language. I am a native speaker of ossetic too. My Pontoon username is geor_lolaev. Right now I have free time, so I can help in translating
Thank you for your support for the idea.
from common-voice.
ftyers
commented on June 9, 2024
Thanks @ArturGudiev, could you please make a few suggestions and I will add you as a translator. :)
from common-voice.
ArturGudiev
commented on June 9, 2024
@ftyers What do you mean by suggestions? Should I translate something? Is it on Pontoon website?
from common-voice.
ArturGudiev
commented on June 9, 2024
@ftyers I got it. I've suggested several translations on Pontoon
from common-voice.
theJosephGoodman
commented on June 9, 2024
@ArturGudiev Салам. Tell me your telegram please
from common-voice.
ArturGudiev
commented on June 9, 2024
@theJosephGoodman Салам. It's arturgudiev

from common-voice.
amikeco
commented on June 9, 2024
There is an important correction: when we speak about the Ossetic/Ossetian version, we mean its bigger dialect known as Iron [ee-rohn]. The other dialect is known as Digoron, it has its own literary tradition, press, and even some people calling it a separate language, it may appear later with its own activists. Collecting both under one name seems not possible, since the differences are deeper than in reading same words differently.
I see in the list there are already many languages with narrowing descriptions, so it'd be nice to write ours as "Ossetic (Iron)", "Ossetian (Iron)", "Iron Ossetian" or in any other way that fits the project's tradition.
from common-voice.
ftyers
commented on June 9, 2024
It is the case for many languages on Common Voice (like Arabic, Portuguese, Armenian, Swahili, etc.) that have very different variants. Common Voice so far goes by ISO codes to distinguish languages that we support. We currently support variants for individual speakers (you can read about it here and we have a plan to support variants for text sentences too.
from common-voice.
amikeco
commented on June 9, 2024
It is the case for many languages on Common Voice (like Arabic, Portuguese, Armenian, Swahili, etc.) that have very different variants. Common Voice so far goes by ISO codes to distinguish languages that we support.
We have other levels of variation to call "variants", "subdialects" that are united by the writing system (there will be at least 4 in Iron Ossetic).
It's up to you how to present it so far: it could be code OS and name Ossetic, and when the Digor dialect (and literary norm) topic appears with the people ready to collect sentences and voices in it, we can come back to the discussion again.
from common-voice.
amikeco
commented on June 9, 2024
75% localization at Pontoon is ready.
from common-voice.
ArturGudiev
commented on June 9, 2024
It is the case for many languages on Common Voice (like Arabic, Portuguese, Armenian, Swahili, etc.) that have very different variants. Common Voice so far goes by ISO codes to distinguish languages that we support. We currently support variants for individual speakers (you can read about it here and we have a plan to support variants for text sentences too.
I see 2 Armenian languages in the lists (Armenian and Armenian Western). So Armenian Western is a different variant with its own dataset. The same would be suitable for Digoron Ossetian. It has its own grammar and vocabulary. Although there are similarities with Iron Ossetian the differences are significant. (by the way, Digoron Ossetian is also sometimes called Western Ossetian).

from common-voice.
ftyers
commented on June 9, 2024
There are not two variants of Armenian deployed in Common Voice, as you can read in this blogpost and see in the datasets. In addition, any region specific language codes are a result of legacy inclusions. We are planning to merge them when the technical capacity exists.
from common-voice.
amikeco
commented on June 9, 2024
https://commonvoice.mozilla.org/os/ is running now, thank you very much.
We will start new topics for other issues about it, right?
from common-voice.
ArturGudiev
commented on June 9, 2024
There is no button to contribute voice on os site. What is the reason? Should we add some os directory for that?
from common-voice.
amikeco
commented on June 9, 2024
Dear Francis,
Can we have an additional line of code somewhere in the Ossetic product? As Cyrillic Æ is poorly supported in fonts, people use the Latin code for it, Æ (absolutely identical visually, but other letter from the point of view of computers).
So either in the sentence collector or while packing the dataset, all Latin codes for Ææ should be changed to Cyrillic ones. Will it be possible?
Also the Main page of Common Voice uses some font that does not support Cyrillic letters, it is very obvious because of how Ossetic Æ's appear among the adjacent other letters:
https://commonvoice.mozilla.org/os
https://commonvoice.mozilla.org/os/review
from common-voice.
ArturGudiev
commented on June 9, 2024
There are not two variants of Armenian deployed in Common Voice, as you can read in this blogpost and see in the datasets. In addition, any region specific language codes are a result of legacy inclusions. We are planning to merge them when the technical capacity exists.
There are essential differences in grammar, vocabulary, and pronunciation between the Iron and Digor languages. One object can have different words in Iron and Digor, correspondingly. You either need to provide 2 variants for every phrase (Iron and Digor) or create two separate datasets.
In Ossetia, books are printed in either Iron or Digor. Foreign books can have two translations (Iron and Digor). I still think it's better to create two different interfaces for the Iron and Digor languages. Otherwise, datasets will be mixed, which can result in lower quality speech recognition.
from common-voice.
ftyers
commented on June 9, 2024
Why do you think it would result in lower quality speech recognition? If ASR systems can be improved by adding data from unrelated languages, why not from related languages or variants of the same language? Anyway, in any case, this GitHub issue is not the place for this discussion, it would be better to take it to Discourse, and please feel free to link it here.
from common-voice.
ArturGudiev
commented on June 9, 2024
Why do you think it would result in lower quality speech recognition? If ASR systems can be improved by adding data from unrelated languages, why not from related languages or variants of the same language? Anyway, in any case, this GitHub issue is not the place for this discussion, it would be better to take it to Discourse, and please feel free to link it here.
Sure, thanks. We can continue the discussion there.
from common-voice.
ArturGudiev
commented on June 9, 2024
So far Ossetian only has 7 sentences contributed and approved. It will need 750 to launch.
Now there are 757 sentences in Ossetian. Should the voice recording option appear automatically? I don't see it right now.

from common-voice.
ftyers
commented on June 9, 2024
It should appear at the next release, so within 1-2 weeks.
from common-voice.
Related Issues (20)
- LOCALIZATION REQUEST: Laz Language HOT 1
- [FR] Also give option to invalidate reported sentences. HOT 7
- [BUG] CV maintenance info not translated HOT 1
- [BUG] 3 ways of logging in CV website only 1 to log out HOT 1
- [BUG] After 5 validated clips in (en) contributor gets an award every time HOT 1
- Move language goals to translations HOT 1
- [BUG] Log in not possible - Callback URL mismatch (android13) HOT 3
- Deletions, on a fixed location HOT 6
- Last updated note for the stats page HOT 3
- [FR] Add text-corpus related statistics to the panel HOT 1
- [BUG] Incorrect display of statistics at CV website for Catalan language HOT 1
- Datasets with only validated data
- LOCALIZATION REQUEST: HOT 1
- The interface can be made faster HOT 2
- LOCALIZATION REQUEST: for Pular Guinée HOT 9
- Downloading the Latest Datasets for All Languages on Linux HOT 1
- Adding new language: Sindhi HOT 3
- LOCALIZATION REQUEST: HOT 3
- [BUG] CV cancel message in german validation not fully translated (de)(android14) HOT 2
- [BUG] Run out of Basque sentences to validate HOT 3
Recommend Projects
-
 React
React
A declarative, efficient, and flexible JavaScript library for building user interfaces.
-
Vue.js
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
-
 Typescript
Typescript
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
-
TensorFlow
An Open Source Machine Learning Framework for Everyone
-
Django
The Web framework for perfectionists with deadlines.
-
 Laravel
Laravel
A PHP framework for web artisans
-
D3
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
-
Recommend Topics
-
javascript
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
-
web
Some thing interesting about web. New door for the world.
-
server
A server is a program made to process requests and deliver data to clients.
-
Machine learning
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
-
Visualization
Some thing interesting about visualization, use data art
-
Game
Some thing interesting about game, make everyone happy.
Recommend Org
-
Facebook
We are working to build community through open source technology. NB: members must have two-factor auth.
-
Microsoft
Open source projects and samples from Microsoft.
-
Google
Google ❤️ Open Source for everyone.
-
Alibaba
Alibaba Open Source for everyone
-
D3
Data-Driven Documents codes.
-
Tencent
China tencent open source team.
from common-voice.