Hi,大家好,这里会记录我平时学习过程中的积累,欢迎大家关注。
(译)Understanding javascript's 'undefined'
constructor, prototype, __proto__ 详解
webpack-dev-server使用方法,看完还不会的来找我~
Webpack dependencyTemplates 依赖模板
个人博客

































































































































Vue版本: 2.3.2
virtual-dom(后文简称vdom)的概念大规模的推广还是得益于react出现,virtual-dom也是react这个框架的非常重要的特性之一。相比于频繁的手动去操作dom而带来性能问题,vdom很好的将dom做了一层映射关系,进而将在我们本需要直接进行dom的一系列操作,映射到了操作vdom,而vdom上定义了关于真实dom的一些关键的信息,vdom完全是用js去实现,和宿主浏览器没有任何联系,此外得益于js的执行速度,将原本需要在真实dom进行的创建节点,删除节点,添加节点等一系列复杂的dom操作全部放到vdom中进行,这样就通过操作vdom来提高直接操作的dom的效率和性能。
Vue在2.0版本也引入了vdom。其vdom算法是基于snabbdom算法所做的修改。
在Vue的整个应用生命周期当中,每次需要更新视图的时候便会使用vdom。那么在Vue当中,vdom是如何和Vue这个框架融合在一起工作的呢?以及大家常常提到的vdom的diff算法又是怎样的呢?接下来就通过这篇文章简单的向大家介绍下Vue当中的vdom是如何去工作的。
首先,我们还是来看下Vue生命周期当中初始化的最后阶段:将vm实例挂载到dom上,源码在src/core/instance/init.js
Vue.prototype._init = function () {
...
vm.$mount(vm.$options.el)
...
} 实际上是调用了src/core/instance/lifecycle.js中的mountComponent方法,
mountComponent函数的定义是:
export function mountComponent (
vm: Component,
el: ?Element,
hydrating?: boolean
): Component {
// vm.$el为真实的node
vm.$el = el
// 如果vm上没有挂载render函数
if (!vm.$options.render) {
// 空节点
vm.$options.render = createEmptyVNode
}
// 钩子函数
callHook(vm, 'beforeMount')
let updateComponent
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
...
} else {
// updateComponent为监听函数, new Watcher(vm, updateComponent, noop)
updateComponent = () => {
// Vue.prototype._render 渲染函数
// vm._render() 返回一个VNode
// 更新dom
// vm._render()调用render函数,会返回一个VNode,在生成VNode的过程中,会动态计算getter,同时推入到dep里面
vm._update(vm._render(), hydrating)
}
}
// 新建一个_watcher对象
// vm实例上挂载的_watcher主要是为了更新DOM
// vm/expression/cb
vm._watcher = new Watcher(vm, updateComponent, noop)
hydrating = false
// manually mounted instance, call mounted on self
// mounted is called for render-created child components in its inserted hook
if (vm.$vnode == null) {
vm._isMounted = true
callHook(vm, 'mounted')
}
return vm
}注意上面的代码中定义了一个updateComponent函数,这个函数执行的时候内部会调用vm._update(vm._render(), hyddrating)方法,其中vm._render方法会返回一个新的vnode,(关于vm_render是如何生成vnode的建议大家看看vue的关于compile阶段的代码),然后传入vm._update方法后,就用这个新的vnode和老的vnode进行diff,最后完成dom的更新工作。那么updateComponent都是在什么时候去进行调用呢?
vm._watcher = new Watcher(vm, updateComponent, noop)实例化一个watcher,在求值的过程中this.value = this.lazy ? undefined : this.get(),会调用this.get()方法,因此在实例化的过程当中Dep.target会被设为这个watcher,通过调用vm._render()方法生成新的Vnode并进行diff的过程中完成了模板当中变量依赖收集工作。即这个watcher被添加到了在模板当中所绑定变量的依赖当中。一旦model中的响应式的数据发生了变化,这些响应式的数据所维护的dep数组便会调用dep.notify()方法完成所有依赖遍历执行的工作,这里面就包括了视图的更新即updateComponent方法,它是在mountComponent中的定义的。
updateComponent方法的定义是:
updateComponent = () => {
vm._update(vm._render(), hydrating)
}完成视图的更新工作事实上就是调用了vm._update方法,这个方法接收的第一个参数是刚生成的Vnode,调用的vm._update方法(src/core/instance/lifecycle.js)的定义是
Vue.prototype._update = function (vnode: VNode, hydrating?: boolean) {
const vm: Component = this
if (vm._isMounted) {
callHook(vm, 'beforeUpdate')
}
const prevEl = vm.$el
const prevVnode = vm._vnode
const prevActiveInstance = activeInstance
activeInstance = vm
// 新的vnode
vm._vnode = vnode
// Vue.prototype.__patch__ is injected in entry points
// based on the rendering backend used.
// 如果需要diff的prevVnode不存在,那么就用新的vnode创建一个真实dom节点
if (!prevVnode) {
// initial render
// 第一个参数为真实的node节点
vm.$el = vm.__patch__(
vm.$el, vnode, hydrating, false /* removeOnly */,
vm.$options._parentElm,
vm.$options._refElm
)
} else {
// updates
// 如果需要diff的prevVnode存在,那么首先对prevVnode和vnode进行diff,并将需要的更新的dom操作已patch的形式打到prevVnode上,并完成真实dom的更新工作
vm.$el = vm.__patch__(prevVnode, vnode)
}
activeInstance = prevActiveInstance
// update __vue__ reference
if (prevEl) {
prevEl.__vue__ = null
}
if (vm.$el) {
vm.$el.__vue__ = vm
}
// if parent is an HOC, update its $el as well
if (vm.$vnode && vm.$parent && vm.$vnode === vm.$parent._vnode) {
vm.$parent.$el = vm.$el
}
}在这个方法当中最为关键的就是vm.__patch__方法,这也是整个virtaul-dom当中最为核心的方法,主要完成了prevVnode和vnode的diff过程并根据需要操作的vdom节点打patch,最后生成新的真实dom节点并完成视图的更新工作。
接下来就让我们看下vm.__patch__里面到底发生了什么:
function patch (oldVnode, vnode, hydrating, removeOnly, parentElm, refElm) {
// 当oldVnode不存在时
if (isUndef(oldVnode)) {
// 创建新的节点
createElm(vnode, insertedVnodeQueue, parentElm, refElm)
} else {
const isRealElement = isDef(oldVnode.nodeType)
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// patch existing root node
// 对oldVnode和vnode进行diff,并对oldVnode打patch
patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly)
}
}
}在对oldVnode和vnode类型判断中有个sameVnode方法,这个方法决定了是否需要对oldVnode和vnode进行diff及patch的过程。
function sameVnode (a, b) {
return (
a.key === b.key &&
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
)
}sameVnode会对传入的2个vnode进行基本属性的比较,只有当基本属性相同的情况下才认为这个2个vnode只是局部发生了更新,然后才会对这2个vnode进行diff,如果2个vnode的基本属性存在不一致的情况,那么就会直接跳过diff的过程,进而依据vnode新建一个真实的dom,同时删除老的dom节点。
vnode基本属性的定义可以参见源码:src/vdom/vnode.js里面对于vnode的定义。
constructor (
tag?: string,
data?: VNodeData, // 关于这个节点的data值,包括attrs,style,hook等
children?: ?Array<VNode>, // 子vdom节点
text?: string, // 文本内容
elm?: Node, // 真实的dom节点
context?: Component, // 创建这个vdom的上下文
componentOptions?: VNodeComponentOptions
) {
this.tag = tag
this.data = data
this.children = children
this.text = text
this.elm = elm
this.ns = undefined
this.context = context
this.functionalContext = undefined
this.key = data && data.key
this.componentOptions = componentOptions
this.componentInstance = undefined
this.parent = undefined
this.raw = false
this.isStatic = false
this.isRootInsert = true
this.isComment = false
this.isCloned = false
this.isOnce = false
}
// DEPRECATED: alias for componentInstance for backwards compat.
/* istanbul ignore next */
get child (): Component | void {
return this.componentInstance
}
}每一个vnode都映射到一个真实的dom节点上。其中几个比较重要的属性:
tag 属性即这个vnode的标签属性data 属性包含了最后渲染成真实dom节点后,节点上的class,attribute,style以及绑定的事件children 属性是vnode的子节点text 属性是文本属性elm 属性为这个vnode对应的真实dom节点key 属性是vnode的标记,在diff过程中可以提高diff的效率,后文有讲解比如,我定义了一个vnode,它的数据结构是:
{
tag: 'div'
data: {
id: 'app',
class: 'page-box'
},
children: [
{
tag: 'p',
text: 'this is demo'
}
]
}最后渲染出的实际的dom结构就是:
<div id="app" class="page-box">
<p>this is demo</p>
</div>让我们再回到patch函数当中,在当oldVnode不存在的时候,这个时候是root节点初始化的过程,因此调用了createElm(vnode, insertedVnodeQueue, parentElm, refElm)方法去创建一个新的节点。而当oldVnode是vnode且sameVnode(oldVnode, vnode)2个节点的基本属性相同,那么就进入了2个节点的diff过程。
diff的过程主要是通过调用patchVnode(src/core/vdom/patch.js)方法进行的:
function patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly) {
...
}if (isDef(data) && isPatchable(vnode)) {
// cbs保存了hooks钩子函数: 'create', 'activate', 'update', 'remove', 'destroy'
// 取出cbs保存的update钩子函数,依次调用,更新attrs/style/class/events/directives/refs等属性
for (i = 0; i < cbs.update.length; ++i) cbs.update[i](oldVnode, vnode)
if (isDef(i = data.hook) && isDef(i = i.update)) i(oldVnode, vnode)
}更新真实dom节点的data属性,相当于对dom节点进行了预处理的操作
接下来:
...
const elm = vnode.elm = oldVnode.elm
const oldCh = oldVnode.children
const ch = vnode.children
// 如果vnode没有文本节点
if (isUndef(vnode.text)) {
// 如果oldVnode的children属性存在且vnode的属性也存在
if (isDef(oldCh) && isDef(ch)) {
// updateChildren,对子节点进行diff
if (oldCh !== ch) updateChildren(elm, oldCh, ch, insertedVnodeQueue, removeOnly)
} else if (isDef(ch)) {
// 如果oldVnode的text存在,那么首先清空text的内容
if (isDef(oldVnode.text)) nodeOps.setTextContent(elm, '')
// 然后将vnode的children添加进去
addVnodes(elm, null, ch, 0, ch.length - 1, insertedVnodeQueue)
} else if (isDef(oldCh)) {
// 删除elm下的oldchildren
removeVnodes(elm, oldCh, 0, oldCh.length - 1)
} else if (isDef(oldVnode.text)) {
// oldVnode有子节点,而vnode没有,那么就清空这个节点
nodeOps.setTextContent(elm, '')
}
} else if (oldVnode.text !== vnode.text) {
// 如果oldVnode和vnode文本属性不同,那么直接更新真是dom节点的文本元素
nodeOps.setTextContent(elm, vnode.text)
}这其中的diff过程中又分了好几种情况,oldCh为oldVnode的子节点,ch为Vnode的子节点:
oldVnode.text !== vnode.text,那么就会直接进行文本节点的替换;vnode没有文本节点的情况下,进入子节点的diff;oldCh和ch都存在且不相同的情况下,调用updateChildren对子节点进行diff;oldCh不存在,ch存在,首先清空oldVnode的文本节点,同时调用addVnodes方法将ch添加到elm真实dom节点当中;oldCh存在,ch不存在,则删除elm真实节点下的oldCh子节点;oldVnode有文本节点,而vnode没有,那么就清空这个文本节点。这里着重分析下updateChildren(src/core/vdom/patch.js)方法,它也是整个diff过程中最重要的环节:
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
// 为oldCh和newCh分别建立索引,为之后遍历的依据
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, elmToMove, refElm
// 直到oldCh或者newCh被遍历完后跳出循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue)
// 插入到老的开始节点的前面
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 如果以上条件都不满足,那么这个时候开始比较key值,首先建立key和index索引的对应关系
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key) ? oldKeyToIdx[newStartVnode.key] : null
// 如果idxInOld不存在
// 1. newStartVnode上存在这个key,但是oldKeyToIdx中不存在
// 2. newStartVnode上并没有设置key属性
if (isUndef(idxInOld)) { // New element
// 创建新的dom节点
// 插入到oldStartVnode.elm前面
// 参见createElm方法
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} else {
elmToMove = oldCh[idxInOld]
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && !elmToMove) {
warn(
'It seems there are duplicate keys that is causing an update error. ' +
'Make sure each v-for item has a unique key.'
)
// 将找到的key一致的oldVnode再和newStartVnode进行diff
if (sameVnode(elmToMove, newStartVnode)) {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue)
oldCh[idxInOld] = undefined
// 移动node节点
canMove && nodeOps.insertBefore(parentElm, newStartVnode.elm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} else {
// same key but different element. treat as new element
// 创建新的dom节点
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
}
}
}
}
// 如果最后遍历的oldStartIdx大于oldEndIdx的话
if (oldStartIdx > oldEndIdx) { // 如果是老的vdom先被遍历完
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
// 添加newVnode中剩余的节点到parentElm中
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) { // 如果是新的vdom先被遍历完,则删除oldVnode里面所有的节点
// 删除剩余的节点
removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx)
}
}在开始遍历diff前,首先给oldCh和newCh分别分配一个startIndex和endIndex来作为遍历的索引,当oldCh或者newCh遍历完后(遍历完的条件就是oldCh或者newCh的startIndex >= endIndex),就停止oldCh和newCh的diff过程。接下来通过实例来看下整个diff的过程(节点属性中不带key的情况):
首先从第一个节点开始比较,不管是oldCh还是newCh的起始或者终止节点都不存在sameVnode,同时节点属性中是不带key标记的,因此第一轮的diff完后,newCh的startVnode被添加到oldStartVnode的前面,同时newStartIndex前移一位;

第二轮的diff中,满足sameVnode(oldStartVnode, newStartVnode),因此对这2个vnode进行diff,最后将patch打到oldStartVnode上,同时oldStartVnode和newStartIndex都向前移动一位

第三轮的diff中,满足sameVnode(oldEndVnode, newStartVnode),那么首先对oldEndVnode和newStartVnode进行diff,并对oldEndVnode进行patch,并完成oldEndVnode移位的操作,最后newStartIndex前移一位,oldStartVnode后移一位;

第四轮的diff中,过程同步骤3;

第五轮的diff中,同过程1;
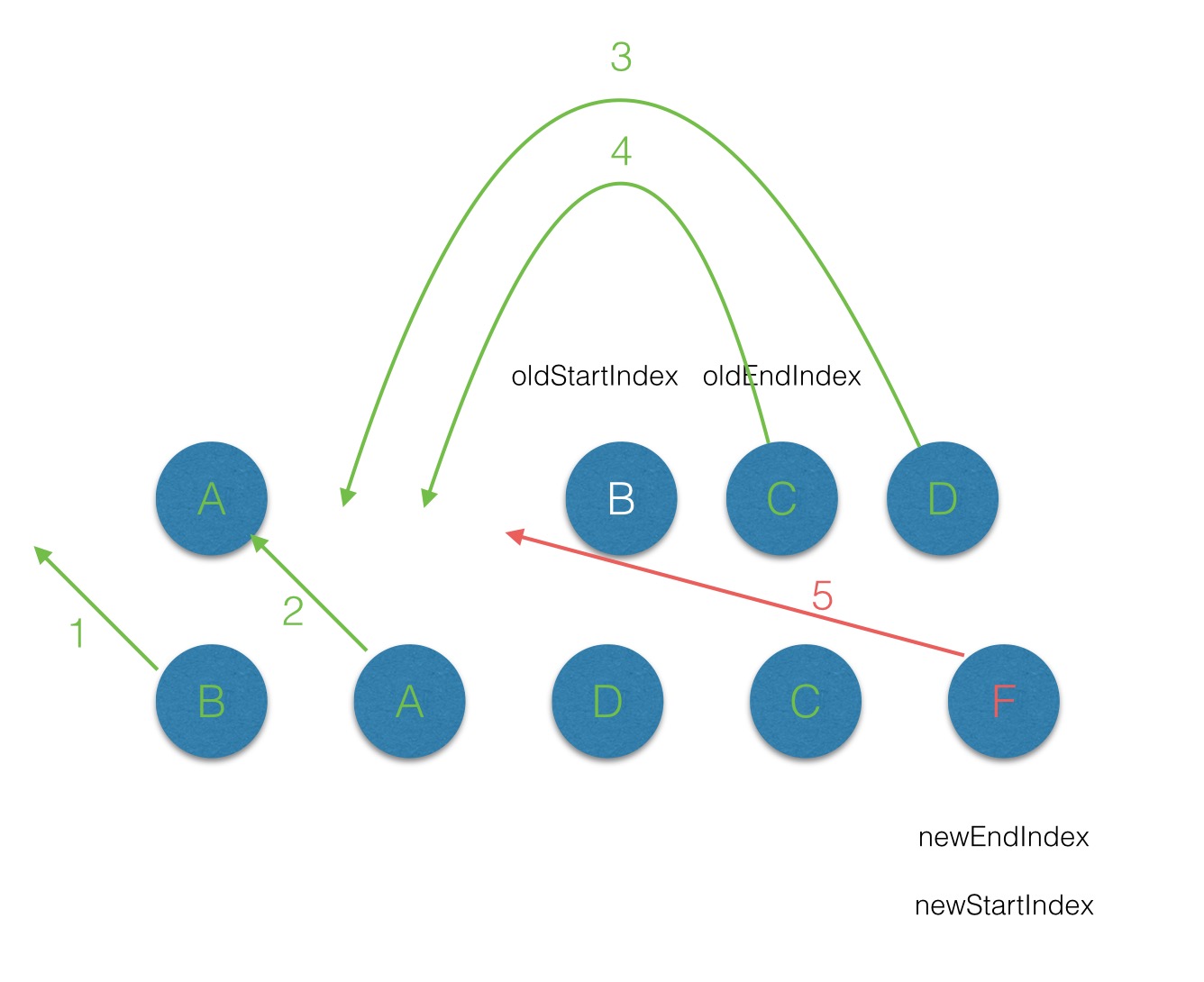
遍历的过程结束后,newStartIdx > newEndIdx,说明此时oldCh存在多余的节点,那么最后就需要将这些多余的节点删除。
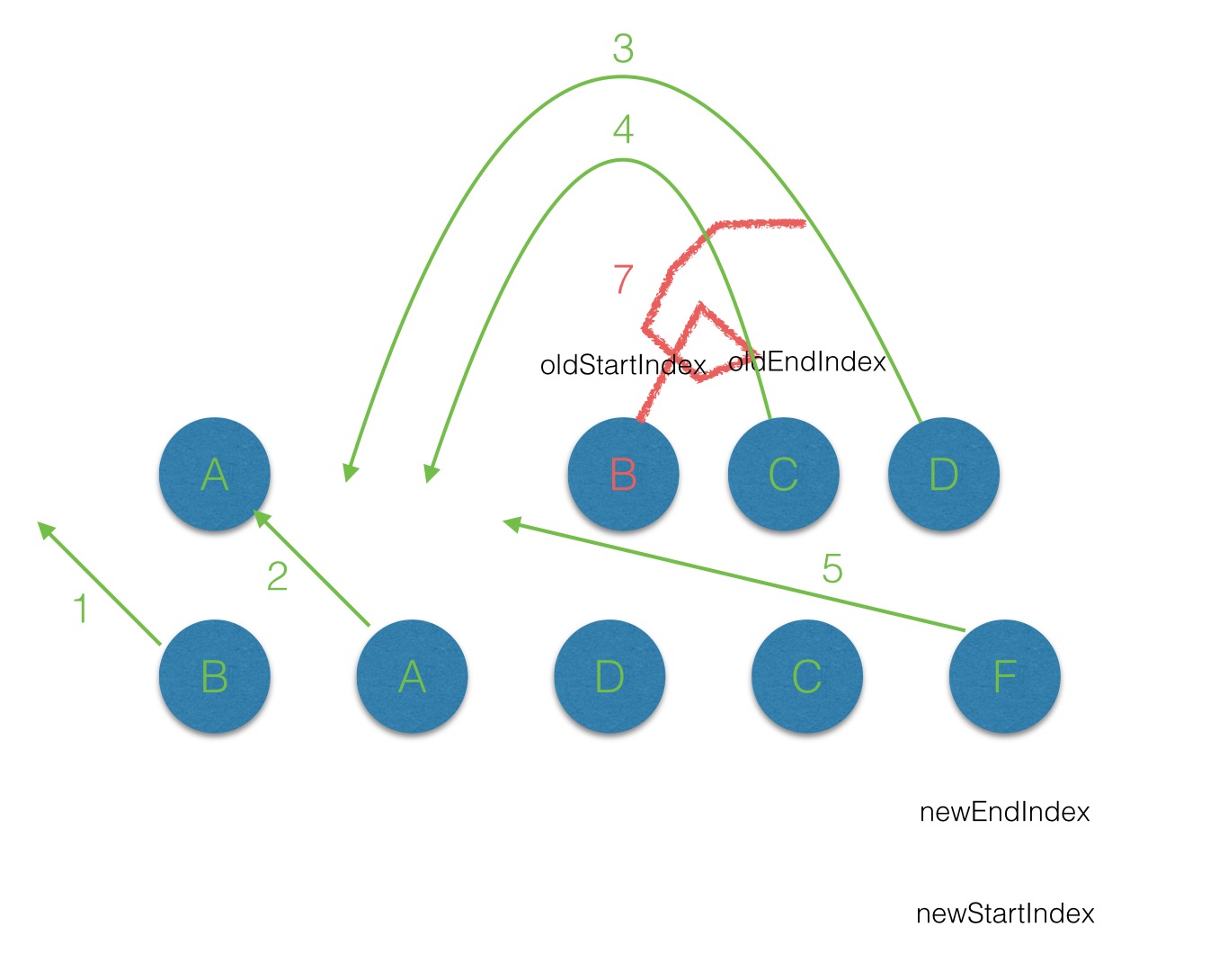
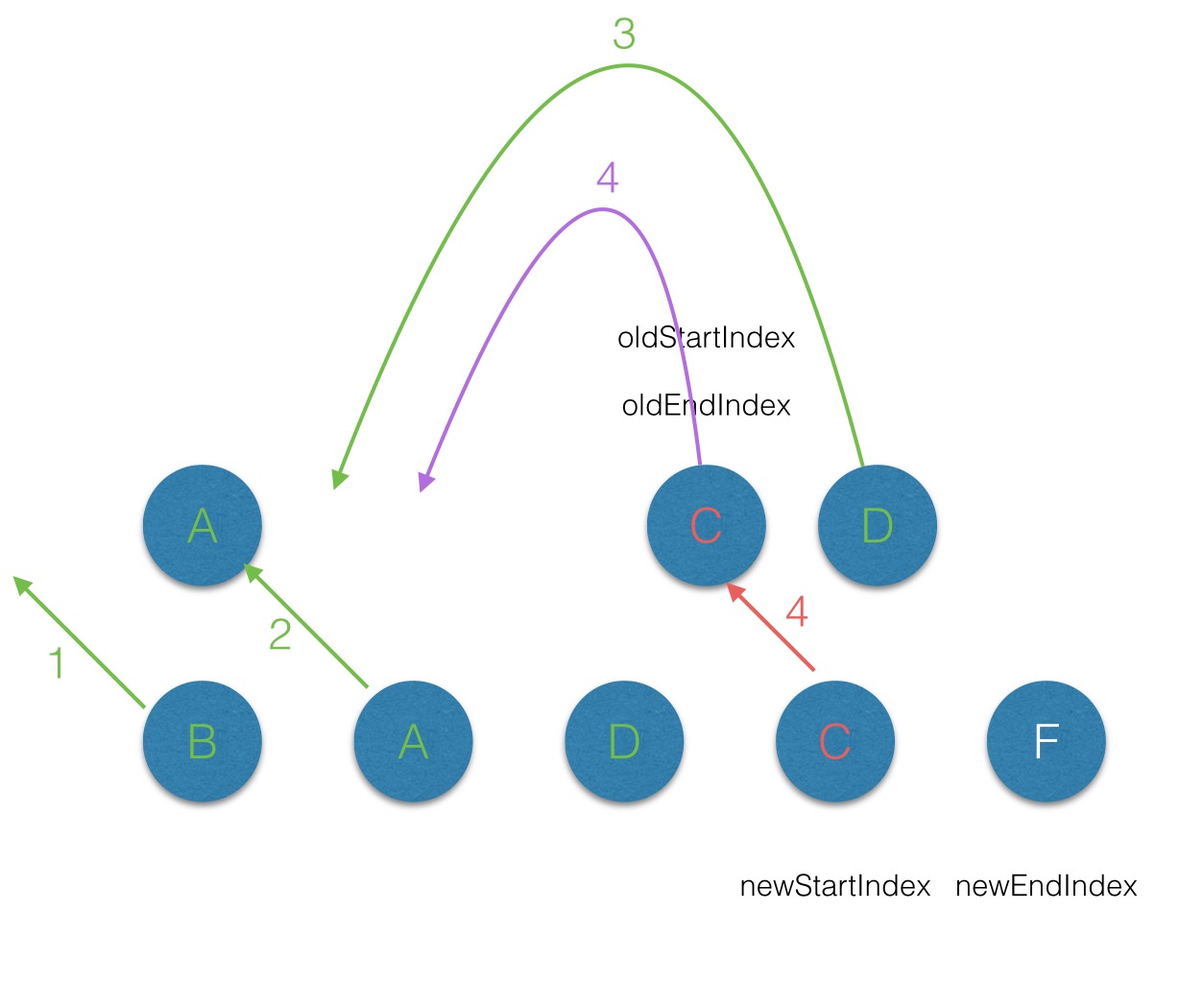
在vnode不带key的情况下,每一轮的diff过程当中都是起始和结束节点进行比较,直到oldCh或者newCh被遍历完。而当为vnode引入key属性后,在每一轮的diff过程中,当起始和结束节点都没有找到sameVnode时,首先对oldCh中进行key值与索引的映射:
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key) ? oldKeyToIdx[newStartVnode.key] : nullcreateKeyToOldIdx(src/core/vdom/patch.js)方法,用以将oldCh中的key属性作为键,而对应的节点的索引作为值。然后再判断在newStartVnode的属性中是否有key,且是否在oldKeyToIndx中找到对应的节点。
key,那么就将这个newStartVnode作为新的节点创建且插入到原有的root的子节点中:if (isUndef(idxInOld)) { // New element
// 创建新的dom节点
// 插入到oldStartVnode.elm前面
// 参见createElm方法
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} key,那么就取出oldCh中的存在这个key的vnode,然后再进行diff的过程: elmToMove = oldCh[idxInOld]
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && !elmToMove) {
// 将找到的key一致的oldVnode再和newStartVnode进行diff
if (sameVnode(elmToMove, newStartVnode)) {
patchVnode(elmToMove, newStartVnode, insertedVnodeQueue)
// 清空这个节点
oldCh[idxInOld] = undefined
// 移动node节点
canMove && nodeOps.insertBefore(parentElm, newStartVnode.elm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
} else {
// same key but different element. treat as new element
// 创建新的dom节点
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm)
newStartVnode = newCh[++newStartIdx]
}通过以上分析,给vdom上添加key属性后,遍历diff的过程中,当起始点, 结束点的搜寻及diff出现还是无法匹配的情况下时,就会用key来作为唯一标识,来进行diff,这样就可以提高diff效率。
带有Key属性的vnode的diff过程可见下图:
注意在第一轮的diff过后oldCh上的B节点被删除了,但是newCh上的B节点上elm属性保持对oldCh上B节点的elm引用。




最近的工作当中有个任务是做国际化。这篇文章也是做个简单的总结。
url进行区分,需要维护多份代码。IP去下发语言标识字段(前端根据下发的表示字段切换语言环境)useragent.lang浏览器环境语言进行设定lang字段去做语言标识,在页面渲染出来前,前端来决定使用的语言包。语言包是在本地编译的过程中就将语言包编译进了代码当中,没有采用异步加载的方式。vue-i18n这个插件来进行。插件提供了单复数,中文转英文的方法。a下文有对vue-i18n的源码进行分析。因为英文的阅读方向也是从左到右,因此语言展示的方向不予考虑。但是在一些阿拉伯地区国家的语言是从右到左进行阅读的。中文转英文后部分文案过长
图片
第三方插件(地图,SDK等)
a.中文转英文后肯定会遇到文案过长的情况。那么可能需要精简翻译,使文案保持在一定的可接受的长度范围内。但是大部分的情况都是文案在保持原意的情况下无法再进行精简。这时必须要前端来进行样式上的调整,那么可能还需要设计的同学参与进来,对一些文案过多出现折行的情况再单独做样式的定义。在细调样式这块,主要还是通过不同的语言标识去控制不同标签的class,来单独定义样式。

b. 此外,还有部分图片也是需要做调整,在C端中,大部分由产品方去输出内容,那么图片这块的话,还需要设计同学单独出图。c. 在第三方插件中这个环节当中,因为使用了腾讯地图插件,由于腾讯地图并未推出国内地图的英文版,所以整个页面的地图部分暂时无法做到国际化。由此联想到,你应用当中使用的其他一些第三方插件或者SDK。

货币及支付方式
时间的格式
在一些支付场景下,货币符号,单位及价格的转化等。不同国家地区在时间的格式显示上有差异。
翻译工作
map表的维护
当前翻译的工作流程是拆页面,每拆一个页面,FE同学整理好可能会出现的中文文案,再交由翻译的同学去完成翻译的工作。负责不同页面的同学维护着不同的map表,在当前的整体页面架构中,不同功能模块和页面被拆分出去交由不同的同学去做,那么通过跳页面的方式去暂时缓解map表的维护问题。如果哪一天页面需要收敛,这也是一个需要去考虑的问题。如果从整个项目的一开始就考虑到国际化的问题并采取相关的措施都能减轻后期的工作量及维护成本。同时以后一旦map表内容过多,是否需要考虑需要将map表进行异步加载。
// 入口main.js文件
import VueI18n from 'vue-i18n'
Vue.use(VueI18n) // 通过插件的形式挂载
const i18n = new VueI18n({
locale: CONFIG.lang, // 语言标识
messages: {
'zh-CN': require('./common/lang/zh'), // 中文语言包
'en-US': require('./common/lang/en') // 英文语言包
}
})
const app = new Vue({
i18n,
...App
}).$mout('#root')
// 单vue文件
<template>
<span>{{$t('你好')}}</span>
</template>Vue-i18n是以插件的形式配合Vue进行工作的。通过全局的mixin的方式将插件提供的方法挂载到Vue的实例上。
其中install.jsVue的挂载函数,主要是为了将mixin.js里面的提供的方法挂载到Vue实例当中:
import { warn } from './util'
import mixin from './mixin'
import Asset from './asset'
export let Vue
// 注入root Vue
export function install (_Vue) {
Vue = _Vue
const version = (Vue.version && Number(Vue.version.split('.')[0])) || -1
if (process.env.NODE_ENV !== 'production' && install.installed) {
warn('already installed.')
return
}
install.installed = true
if (process.env.NODE_ENV !== 'production' && version < 2) {
warn(`vue-i18n (${install.version}) need to use Vue 2.0 or later (Vue: ${Vue.version}).`)
return
}
// 通过mixin的方式,将插件提供的methods,钩子函数等注入到全局,之后每次创建的vue实例都用拥有这些methods或者钩子函数
Vue.mixin(mixin)
Asset(Vue)
}接下来就看下在Vue上混合了哪些methods或者钩子函数. 在mixin.js文件中:
/* @flow */
// VueI18n构造函数
import VueI18n from './index'
import { isPlainObject, warn } from './util'
// $i18n 是每创建一个Vue实例都会产生的实例对象
// 调用以下方法前都会判断实例上是否挂载了$i18n这个属性
// 最后实际调用的方法是插件内部定义的方法
export default {
// 这里混合了computed计算属性, 注意这里计算属性返回的都是函数,这样就可以在vue模板里面使用{{ $t('hello') }}, 或者其他方法当中使用 this.$t('hello')。这种函数接收参数的方式
computed: {
// 翻译函数, 调用的是VueI18n实例上提供的方法
$t () {
if (!this.$i18n) {
throw Error(`Failed in $t due to not find VueI18n instance`)
}
// add dependency tracking !!
const locale: string = this.$i18n.locale // 语言配置
const messages: Messages = this.$i18n.messages // 语言包
// 返回一个函数. 接受一个key值. 即在map文件中定义的key值, 在模板中进行使用 {{ $t('你好') }}
// ...args是传入的参数, 例如在模板中定义的一些替换符, 具体的支持的形式可翻阅文档https://kazupon.github.io/vue-i18n/formatting.html
return (key: string, ...args: any): string => {
return this.$i18n._t(key, locale, messages, this, ...args)
}
},
// tc方法可以单独定义组件内部语言设置选项, 如果没有定义组件内部语言,则还是使用global的配置
$tc () {
if (!this.$i18n) {
throw Error(`Failed in $tc due to not find VueI18n instance`)
}
// add dependency tracking !!
const locale: string = this.$i18n.locale
const messages: Messages = this.$i18n.messages
return (key: string, choice?: number, ...args: any): string => {
return this.$i18n._tc(key, locale, messages, this, choice, ...args)
}
},
// te方法
$te () {
if (!this.$i18n) {
throw Error(`Failed in $te due to not find VueI18n instance`)
}
// add dependency tracking !!
const locale: string = this.$i18n.locale
const messages: Messages = this.$i18n.messages
return (key: string, ...args: any): boolean => {
return this.$i18n._te(key, locale, messages, ...args)
}
}
},
// 钩子函数
// 被渲染前,在vue实例上添加$i18n属性
// 在根组件初始化的过程中:
/**
* new Vue({
* i18n // 这里是提供了自定义的属性 那么实例当中可以通过this.$option.i18n去访问这个属性
* // xxxx
* })
*/
beforeCreate () {
const options: any = this.$options
// 如果有i18n这个属性. 根实例化的时候传入了这个参数
if (options.i18n) {
if (options.i18n instanceof VueI18n) {
// 如果是VueI18n的实例,那么挂载在Vue实例的$i18n属性上
this.$i18n = options.i18n
// 如果是个object
} else if (isPlainObject(options.i18n)) { // 如果是一个pobj
// component local i18n
// 访问root vue实例。
if (this.$root && this.$root.$i18n && this.$root.$i18n instanceof VueI18n) {
options.i18n.root = this.$root.$i18n
}
this.$i18n = new VueI18n(options.i18n) // 创建属于component的local i18n
if (options.i18n.sync) {
this._localeWatcher = this.$i18n.watchLocale()
}
} else {
if (process.env.NODE_ENV !== 'production') {
warn(`Cannot be interpreted 'i18n' option.`)
}
}
} else if (this.$root && this.$root.$i18n && this.$root.$i18n instanceof VueI18n) {
// root i18n
// 如果子Vue实例没有传入$i18n方法,且root挂载了$i18n,那么子实例也会使用root i18n
this.$i18n = this.$root.$i18n
}
},
// 实例被销毁的回调函数
destroyed () {
if (this._localeWatcher) {
this.$i18n.unwatchLocale()
delete this._localeWatcher
}
// 组件销毁后,同时也销毁实例上的$i18n方法
this.$i18n = null
}
}这里注意下这几个方法的区别:
$tc这个方法可以用以返回翻译的复数字符串, 及一个key可以对应的翻译文本,通过|进行连接:
例如:
// main.js
new VueI18n({
messages: {
car: 'car | cars'
}
})
// template
<span>{{$tc('car', 1)}}</span> ===>>> <span>car</span>
<span>{{$tc('car', 2)}}</span> ===>>> <span>cars</span>$te这个方法用以判断需要翻译的key在你提供的语言包(messages)中是否存在.
接下来就看看VueI18n构造函数及原型上提供了哪些可以被实例继承的属性或者方法
/* @flow */
import { install, Vue } from './install'
import { warn, isNull, parseArgs, fetchChoice } from './util'
import BaseFormatter from './format' // 转化函数 封装了format, 里面包含了template模板替换的方法
import getPathValue from './path'
import type { PathValue } from './path'
// VueI18n构造函数
export default class VueI18n {
static install: () => void
static version: string
_vm: any
_formatter: Formatter
_root: ?I18n
_sync: ?boolean
_fallbackRoot: boolean
_fallbackLocale: string
_missing: ?MissingHandler
_exist: Function
_watcher: any
// 实例化参数配置
constructor (options: I18nOptions = {}) {
const locale: string = options.locale || 'en-US' // vue-i18n初始化的时候语言参数配置
const messages: Messages = options.messages || {} // 本地配置的所有语言环境都是挂载到了messages这个属性上
this._vm = null // ViewModel
this._fallbackLocale = options.fallbackLocale || 'en-US' // 缺省语言配置
this._formatter = options.formatter || new BaseFormatter() // 翻译函数
this._missing = options.missing
this._root = options.root || null
this._sync = options.sync || false
this._fallbackRoot = options.fallbackRoot || false
this._exist = (message: Object, key: string): boolean => {
if (!message || !key) { return false }
return !isNull(getPathValue(message, key))
}
this._resetVM({ locale, messages })
}
// VM
// 重置viewModel
_resetVM (data: { locale: string, messages: Messages }): void {
const silent = Vue.config.silent
Vue.config.silent = true
this._vm = new Vue({ data })
Vue.config.silent = silent
}
// 根实例的vm监听locale这个属性
watchLocale (): any {
if (!this._sync || !this._root) { return null }
const target: any = this._vm
// vm.$watch返回的是一个取消观察的函数,用来停止触发回调
this._watcher = this._root.vm.$watch('locale', (val) => {
target.$set(target, 'locale', val)
}, { immediate: true })
return this._watcher
}
// 停止触发vm.$watch观察函数
unwatchLocale (): boolean {
if (!this._sync || !this._watcher) { return false }
if (this._watcher) {
this._watcher()
delete this._watcher
}
return true
}
get vm (): any { return this._vm }
get messages (): Messages { return this._vm.$data.messages } // get 获取messages参数
set messages (messages: Messages): void { this._vm.$set(this._vm, 'messages', messages) } // set 设置messages参数
get locale (): string { return this._vm.$data.locale } // get 获取语言配置参数
set locale (locale: string): void { this._vm.$set(this._vm, 'locale', locale) } // set 重置语言配置参数
get fallbackLocale (): string { return this._fallbackLocale } // fallbackLocale 是什么?
set fallbackLocale (locale: string): void { this._fallbackLocale = locale }
get missing (): ?MissingHandler { return this._missing }
set missing (handler: MissingHandler): void { this._missing = handler }
get formatter (): Formatter { return this._formatter } // get 转换函数
set formatter (formatter: Formatter): void { this._formatter = formatter } // set 转换函数
_warnDefault (locale: string, key: string, result: ?any, vm: ?any): ?string {
if (!isNull(result)) { return result }
if (this.missing) {
this.missing.apply(null, [locale, key, vm])
} else {
if (process.env.NODE_ENV !== 'production') {
warn(
`Cannot translate the value of keypath '${key}'. ` +
'Use the value of keypath as default.'
)
}
}
return key
}
_isFallbackRoot (val: any): boolean {
return !val && !isNull(this._root) && this._fallbackRoot
}
// 插入函数
_interpolate (message: Messages, key: string, args: any): any {
if (!message) { return null }
// 获取key对应的字符串
let val: PathValue = getPathValue(message, key)
if (Array.isArray(val)) { return val }
if (isNull(val)) { val = message[key] }
if (isNull(val)) { return null }
if (typeof val !== 'string') {
warn(`Value of key '${key}' is not a string!`)
return null
}
// TODO ?? 这里的links是干什么的?
// Check for the existance of links within the translated string
if (val.indexOf('@:') >= 0) {
// Match all the links within the local
// We are going to replace each of
// them with its translation
const matches: any = val.match(/(@:[\w|.]+)/g)
for (const idx in matches) {
const link = matches[idx]
// Remove the leading @:
const linkPlaceholder = link.substr(2)
// Translate the link
const translatedstring = this._interpolate(message, linkPlaceholder, args)
// Replace the link with the translated string
val = val.replace(link, translatedstring)
}
}
// 如果没有传入需要替换的obj, 那么直接返回字符串, 否则调用this._format进行变量等的替换
return !args ? val : this._format(val, args) // 获取替换后的字符
}
_format (val: any, ...args: any): any {
return this._formatter.format(val, ...args)
}
// 翻译函数
_translate (messages: Messages, locale: string, fallback: string, key: string, args: any): any {
let res: any = null
/**
* messages[locale] 使用哪个语言包
* key 语言映射表的key
* args 映射替换关系
*/
res = this._interpolate(messages[locale], key, args)
if (!isNull(res)) { return res }
res = this._interpolate(messages[fallback], key, args)
if (!isNull(res)) {
if (process.env.NODE_ENV !== 'production') {
warn(`Fall back to translate the keypath '${key}' with '${fallback}' locale.`)
}
return res
} else {
return null
}
}
// 翻译的核心函数
/**
* 这里的方法传入的参数参照mixin.js里面的定义的方法
* key map的key值 (为接受的外部参数)
* _locale 语言配置选项: 'zh-CN' | 'en-US' (内部变量)
* messages 映射表 (内部变量)
* host为这个i18n的实例 (内部变量)
*
*/
_t (key: string, _locale: string, messages: Messages, host: any, ...args: any): any {
if (!key) { return '' }
// parseArgs函数用以返回传入的局部语言配置, 及映射表
const parsedArgs = parseArgs(...args) // 接收的参数{ locale, params(映射表) }
const locale = parsedArgs.locale || _locale // 语言配置
// 字符串替换
/**
* @params messages 语言包
* @params locale 语言配置
* @params fallbackLocale 缺省语言配置
* @params key 替换的key值
* @params parsedArgs.params 需要被替换的参数map表
*/
const ret: any = this._translate(messages, locale, this.fallbackLocale, key, parsedArgs.params)
if (this._isFallbackRoot(ret)) {
if (process.env.NODE_ENV !== 'production') {
warn(`Fall back to translate the keypath '${key}' with root locale.`)
}
if (!this._root) { throw Error('unexpected error') }
return this._root.t(key, ...args)
} else {
return this._warnDefault(locale, key, ret, host)
}
}
// 转化函数
t (key: string, ...args: any): string {
return this._t(key, this.locale, this.messages, null, ...args)
}
_tc (key: string, _locale: string, messages: Messages, host: any, choice?: number, ...args: any): any {
if (!key) { return '' }
if (choice !== undefined) {
return fetchChoice(this._t(key, _locale, messages, host, ...args), choice)
} else {
return this._t(key, _locale, messages, host, ...args)
}
}
tc (key: string, choice?: number, ...args: any): any {
return this._tc(key, this.locale, this.messages, null, choice, ...args)
}
_te (key: string, _locale: string, messages: Messages, ...args: any): boolean {
const locale = parseArgs(...args).locale || _locale
return this._exist(messages[locale], key)
}
te (key: string, ...args: any): boolean {
return this._te(key, this.locale, this.messages, ...args)
}
}
VueI18n.install = install
VueI18n.version = '__VERSION__'
// 如果是通过CDN或者外链的形式引入的Vue
if (typeof window !== 'undefined' && window.Vue) {
window.Vue.use(VueI18n)
}另外还有一个比较重要的库函数format.js:
/**
* String format template
* - Inspired:
* https://github.com/Matt-Esch/string-template/index.js
*/
// 变量的替换, 在字符串模板中写的站位符 {xxx} 进行替换
const RE_NARGS: RegExp = /(%|)\{([0-9a-zA-Z_]+)\}/g
/**
* template
*
* @param {String} string
* @param {Array} ...args
* @return {String}
*/
// 模板替换函数
export function template (str: string, ...args: any): string {
// 如果第一个参数是一个obj
if (args.length === 1 && typeof args[0] === 'object') {
args = args[0]
} else {
args = {}
}
if (!args || !args.hasOwnProperty) {
args = {}
}
// str.prototype.replace(substr/regexp, newSubStr/function) 第二个参数如果是个函数的话,每次匹配都会调用这个函数
// match 为匹配的子串
return str.replace(RE_NARGS, (match, prefix, i, index) => {
let result: string
// match是匹配到的字符串
// prefix ???
// i 括号中需要替换的字符换
// index是偏移量
// 字符串中如果出现{xxx}不需要被替换。那么应该写成{{xxx}}
if (str[index - 1] === '{' &&
str[index + match.length] === '}') {
return i
} else {
// 判断args obj是否包含这个key值
// 返回替换值, 或者被匹配上的字符串的值
result = hasOwn(args, i) ? args[i] : match
if (isNull(result)) {
return ''
}
return result
}
})
}本项目是使用vue作为前端框架,使用vue-i18n作为国际化的工具。
vue-i18n进行替换body上添加多语言的标识class属性SDK或插件的国际化推动前端通用国际化解决方案
前端技术日新月异,技术栈繁多。以前端框架来说有React, Vue, Angular等等,再配以webpack, gulp, Browserify, fis等等构建工具去满足日常的开发工作。同时在日常的工作当中,不同的项目使用的技术栈也会不一样。当需要对部分项目进行国际化改造时,由于技术栈的差异,这时你需要去寻找和当前项目使用的技术栈相匹配的国际化的插件工具。比如:
vue + vue-i18nangular + angular-translatereact + react-intljquery + jquery.i18n.property等等,同时可能有些页面没有使用框架,或者完全是没有进行工程化的静态前端页面。
为了减少由于不同技术栈所带来的学习相关国际化插件的成本及开发过程中可能遇到的国际化坑,在尝试着分析前端国际化所面临的主要问题及相关的解决方案后,我觉得是可以使用更加通用的技术方案去完成国际化的工作。
1.语言翻译
server端下发的动态数据)2.样式
3.map表维护
4.第三方服务
5.本地化
6.打包方案
在日常的开发过程当中,遇到的最多的需要国际化的场景是:语言翻译,样式,map表维护及打包方案。接下来针对这几块内容并结合日常的开发流程说明国际化的通用解决方案。
首先来看下当前开发环境可能用的技术栈:
1.使用了构建工具
webpackgulpfisbrowserify基于这些构建工具,使用:
VueAngularReactBackboneframework2.未使用构建工具
jquery或zepto等类库js其中在第一种开发流程当中,可用的国际化的工具可选方案较多:
从框架层面来看,各大框架都会有相对应的国际化插件,例如:vue-i18n, angular-translate, react-intl等,这些插件可以无缝接入当前的开发环节当中。优点是这些框架层面的国际化插件使用灵活,可以进行静态文案的翻译,动态文案的翻译。缺点就是开发过程中使用不同的框架还需要去学习相对应的插件,存在一定的学习成本,同时在业务代码中可能存在不同语言包判断逻辑。
从构建工具层面来看, webpack有相对应的i18n-webpack-plugin, gulp有gulp-static-i18n等相应的插件。这些插件的套路一般都是在你自定义map语言映射表,同时根据插件定义好的需要被编译的代码格式,然后在代码的编译阶段,通过字符串匹配的形式去完成静态文案的替换工作。这些插件仅仅解决了静态文案的问题,比如一些样式,图片替换,class属性,以及动态文案的翻译等工作并没有做。
事实上,这些插件在编译过程中对于样式,图片替换, class属性等替换工作是非常容易完成的,而动态文案的翻译因为缺少context,所以不会选择使用这些编译插件去完成动态文案的翻译工作。相反,将动态文案的翻译放到运行时去完成应该是更加靠谱的。
但是换个角度,抛开基于这些构建工具进行开发的框架来说,构建工具层面的国际化插件可以很好的抹平使用不同框架的差异,通过将国际化的过程从运行时转到编译时,在编译的过程中就完成大部分的国际化任务,降低学习相对应国际化插件的成本,同时在构建打包环节可实现定制化。不过也存在一定的缺点,就是这些构建工具层面的国际化插件只能完成一些基本的静态文案的翻译,因为缺少context,并不能很好的去完成动态文案的翻译工作,它比较适用于一些纯静态,偏展示性的网页。
在第二种开发流程当中,可使用的国际化工具较少,大多都会搭配jquery这些类库及相对应的jquery.i18n或i18next等插件去完成国际化。
综合不同的构建工具,开发框架及类库,针对不同的开发环境似乎是可以找到一个比较通用的国际化的方案的。
这个方案的大致思路就是:通过构建工具去完成样式, 图片替换, class属性等的替换工作,在业务代码中不会出现过多的因国际化而多出的变量名,同时使用一个通用的翻译函数去完成静态文案及动态文案的翻译工作,而不用使用不同框架提供的相应的国际化插件。简单点来说就是:
构建工具 + 一个通用的翻译函数去完成前端国际化首先,这个通用的语言翻译函数: di18n-translate。它所提供的功能就是静态和动态文案的翻译, 不依赖开发框架及构建工具。
npm install di18n-translate// 模块化写法
const LOCALE = 'en'
const DI18n = require('di18n-translate')
const di18n = new DI18n({
locale: LOCALE, // 语言环境
isReplace: false, // 是否开始运行时(适用于没有使用任何构建工具开发流程)
messages: { // 语言映射表
en: {
你好: 'Hello, {person}'
},
zh: {
你好: '你好, {person}'
}
}
})
di18n继承于一个翻译类,提供了2个方法`$t`, `$html`:
di18n.$t('你好', {person: 'xl'}) // 输出: Hello, xl
di18n.$html(htmlTemp) // 传入字符串拼接的dom, 返回匹配后的字符串,具体示例可见下文
// 外链形式
<script src="./lib/di18n-translate/index.js"></script>
<script>
const LOCALE = 'en'
const di18n = new DI18n({
locale: LOCALE,
isReplace: false,
messages: {
// 语言包
}
})
</script>这个时候你只需要将这个通用的翻译函数以适当的方式集成到你的开发框架当中去。
接下来会结合具体的不同场景去说明下相应的解决方案:
###使用MVVM类的framework
使用了MVVM类的framework时,可以借助framework帮你完成view层的渲染工作, 那么你可以在代码当中轻松的通过代码去控制class的内容, 以及不同语言环境下的图片替换工作.
例如vue, 示例(1):
main.js文件:
window.LOCALE = 'en'app.vue文件:
<template>
<p class="desc"
:class="locale" // locale这个变量去控制class的内容
:style="{backgroundImage: 'url(' + bgImg + ')'}" // bgImg去控制背景图片的路径
></p>
<img :src="imgSrc"> // imgSrc去控制图片路径
</template>
<script>
export default {
name: 'page',
data () {
return {
locale: LOCALE,
imgSrc: require(`./${LOCALE}/img/demo.png`),
bgImg: require(`./${LOCALE}/img/demo.png`)
}
}
}
</script>这个时候你再加入翻译函数,就可以满足大部分的国际化的场景了,现在在main.js中添加对翻译函数di18n-translate的引用:
main.js文件:
import Vue from 'vue'
window.LOCALE = 'en'
const DI18n = require('di18n-translate')
const di18n = new DI18n({
locale: LOCALE, // 语言环境
isReplace: false, // 是否进行替换(适用于没有使用任何构建工具开发流程)
messages: { // 语言映射表
en: {
你好: 'Hello, {person}'
},
zh: {
你好: '你好, {person}'
}
}
})
Vue.prototype.d18n = di18n翻译函数的基本使用, 当然你还可以使用其他的方式集成到你的开发环境当中去:
app.vue文件:
<template>
<p class="desc"
:class="locale" // locale这个变量去控制class的内容
:style="{backgroundImage: 'url(' + bgImg + ')'}" // bgImg去控制背景图片的路径
></p>
<img :src="imgSrc"> // imgSrc去控制图片路径
<p>{{title}}</p>
</template>
<script>
export default {
name: 'page',
data () {
return {
locale: LOCALE,
imgSrc: require(`./${LOCALE}/img/demo.png`),
bgImg: require(`./${LOCALE}/img/demo.png`),
title: this.di18n.$t('你好')
}
}
}
</script>使用mvvm framework进行国际化,上述方式应该是较为合适的,主要是借助了framework帮你完成view层的渲染工作, 然后再引入一个翻译函数去完成一些动态文案的翻译工作
这种国际化的方式算是运行时处理,不管是开发还是最终上线都只需要一份代码。
当然在使用mvvm framework的情况下也是可以不借助framework帮我们完成的view层的这部分的功能,而通过构建工具去完成, 这部分的套路可以参见下午的示例3
mvvm框架,使用了构建工具(如webpack/gulp/browserify/fis)国际化的方式和上面说的使用mvvm框架的方式一致,因为有模板引擎帮你完成了view层的渲染.所以对于样式,图片,class属性的处理可以和上述方式一致, 动态文案的翻译需引入翻译函数。
这种国际化的方式也算是运行时处理,开发和最终上线都只需要一份代码。
因为没用使用前端模板,便少了对于view层的处理。这个时候你的DOM结构可能是在html文件中一开始就定义好的了,也可能是借助于webpack这样能允许你使用模块化进行开发,通过js动态插入DOM的方式。
接下来我们先说说没有借助webpack这样允许你进行模块化开发的构建工具,DOM结构直接是在html文件中写死的项目。这种情况下你失去了对view层渲染能力。那么这种情况下有2种方式去处理这种情况。
第一种方式就是可以在你自己的代码中添加运行时的代码。大致的思路就是在DOM层面添加属性,这些属性及你需要翻译的map表所对应的key值:
示例(2):
html文件:
<div class="wrapper" i18n-class="${locale}">
<img i18n-img="/images/${locale}/test.png">
<input i18n-placeholder="你好">
<p i18n-content="你好"></p>
</div>运行时:
<script src="[PATH]/di18-translate/index.js"></script>
<script>
const LOCALE = 'en'
const di18n = new DI18n({
locale: LOCALE,
isReplace: true, // 开启运行时
messages: {
en: {
你好: 'Hello'
},
zh: {
你好: '你好'
}
}
})
</script>最后html会转化为:
<div class="wrapper en">
<img src="/images/en/test.png">
<input placeholder="Hello">
<p>Hello</p>
</div>第二种方式就是借助于构建工具在代码编译的环节就完成国际化的工作,以webpack为例:
示例(3):
html文件:
<div class="wrapper ${locale}">
<img src="/images/${locale}/test.png">
<p>$t('你好')</p>
</div>这个时候使用了一个webpack的preloader: locale-path-loader,它的作用就是在编译编译前,就通过webpack完成语言环境的配置工作,在你的业务代码中不会出现过多的关于语言环境变量以及很好的解决了运行时作为css的background的图片替换工作, 具体的locale-path-loader的文档请戳我
使用方法:
npm install locale-path-loaderwebpack 1.x 配置:
module.exports = {
....
preLoaders: [
{
test: /\.*$/,
exclude: /node_modules/,
loaders: [
'eslint',
'locale-path?outputDir=./src/common&locale=en&inline=true'
]
}
]
....
}webpack 2 配置:
module.exports = {
....
module: {
rules: [{
test: /\.*$/,
enforce: 'pre',
exclude: /node_modules/,
use: [{
loader: 'locale-path-loader',
options: {
locale: 'en',
outputDir: './src/common',
inline: true
}
}]
}]
}
....
}经过webpack的preloader处理后,被插入到页面中的DOM最后成为:
<div class="wrapper en">
<img src="/images/en/test.png">
<p>Hello</p>
</div>但是使用这种方案需要在最后的打包环节做下处理,因为通过preloader的处理,页面已经被翻译成相对应的语言版本了,所以需要通过构建工具以及改变preloader的参数去输出不同的语言版本文件。当然构建工具不止webpack这一种,不过这种方式处理的思路是一致的。
这种方式属于编译时处理,开发时只需要维护一份代码,但是最后输出的时候会输出不同语言包的代码。当然这个方案还需要服务端的支持,根据不同语言环境请求,返回相对应的入口文件。关于这里使用webpack搭配locale-path-loader进行分包的内容可参见vue-demo:
|--deploy
| |
| |---en
| | |--app.js
| | |--vendor.js
| | |--index.html
| |---zh
| | |--app.js
| | |--vendor.js
| | |--index.html
| |---jp
| | |--app.js
| | |--vendor.js
| | |--index.html
| |----lang.json接下来继续说下借助构建工具进行模块化开发的项目, 这些项目可能最后页面上的DOM都是通过js去动态插入到页面当中的。那么,很显然,可以在DOM被插入到页面前即可以完成静态文案翻译,样式, 图片替换, class属性等替换的工作。
示例(4):
html文件:
<div class="wrapper ${locale}">
<img src="/images/${locale}/test.png">
<p>$t('你好')</p>
</div>js文件:
let tpl = require('html!./index.html')
let wrapper = document.querySelector('.box-wrapper')
// di18n.$html方法即对你所加载的html字符串进行replace,最后相对应的语言版本
wrapper.innerHTML = di18n.$html(tpl)最后插入到的页面当中的DOM为:
<div class="wrapper en">
<img src="/images/en/test.png">
<p>Hello</p>
</div>这个时候动态翻译再借助引入的di18n上的$t方法
di18n.$t('你好')这种开发方式也属于运行时处理,开发和上线后只需要维护一份代码。
framework及构建工具的纯静态,偏展示性的网页这类网页的国际化,可以用上面提到的通过在代码中注入运行时来完成基本的国际化的工作, 具体内容可以参见**示例(2)**以及仓库中的html-demo文件夹。
建议将语言包单独新建文件维护,通过异步加载的方式去获取语言包.
最后需要感谢 @kenberkeley 同学,之前和他有过几次关于国际化的探讨,同时关于编译时这块的内容,他的有篇文章(请戳我)也给了我一些比较好的思路。
由于项目要兼容到IE9,因此将之前flex布局全部给换掉。今天leader让我看了kitecss这个css框架(里面的一些布局方式能比较好的兼容IE8+,里面有一些比较好的栅格布局,垂直居中等方案)。然后具体的学习了里面的一些css技巧和方法,总结如下:
##display:table
源码里面很多将父元素display属性设为display: table。这个时候再将子元素display属性设置为inline-block属性后,运用text-align属性即可进行水平居中,水平靠左,水平靠右。
##负margin
负margin的使用技巧和应用场景其实还是挺广泛的,比如使用float和负margin现实圣杯布局,双飞燕布局等等。
具体的使用技巧和参照文章:
由浅入深漫谈margin属性
不要告诉我你懂margin
我知道你不知道负margin
然后在kitecss里面的时候主要是运用在了栅格布局上面。
html结构:
<div class="kite kite--grid has-gutter">
<div class="kite__item is-4of12">
<div class="fixture">.is-4of12</div>
</div>
<div class="kite__item is-4of12">
<div class="fixture">.is-4of12</div>
</div>
<div class="kite__item is-4of12">
<div class="fixture">.is-4of12</div>
</div>
</div>
css:
.kite {
font-size: 0 !important;
}
.kite--grid.has-gutter {
display: block;
width: auto;
margin-left: -10px; //左基线向左移动10px
margin-right: -10px; //右基线向右移动10px
}
.kite_item {
box-sizing: border-box; //一定要使用border-box属性(自己不熟悉的自行google)
display: inline-block; //主要是为了好设置宽度
width: 33.3333%; //都是相对于父元素的33.3333%,即将父元素平均分成了3等份。
font-size: 1rem;
vertical-align: top; //元素在水平线上的对齐方式
padding-left: 10px; //左内边距10px
padding-right: 10px; //右内边距10px;
}看到图上左右2边的线条没,这其实就是父元素.kite--grid的左右边界
3个子元素的宽度都是33.333%,平均的3等份,但是设置padding-left和padding-right的值都为10px的时候,正好和左右负margin抵消,这样就是现实了3列等宽布局。
##垂直居中
html结构:
<div class="kite kite--position">
<div class="kit__item">
<div class="fixture">1</div>
</div>
</div>
css:
.kite--position {
display: block;
position: absolute;
top: 0; //使用绝对定位也可以实现自适应哦~
right: 0;
height: 150px;
text-align: center;//子元素的display属性为inline-block,因此可以实现水平居中
font-size: 0;
}
.kite--position::after{
display: inline-block;
content: '';
height: 100%;
vertical-align: middle;
}
.kite__item {
display: inline-block;
font-size: 1rem;
box-sizing: border-box;
}
.fixture {
border: 1px solid #489;
margin-bottom: 16px;
min-height: 48px;
background-color: rgba(108,200,220,0.75);
}css当中使用比较巧的是利用.kite--position的伪元素(content属性一定不能省,可以把值设为""),生成一个行内元素,其高度为100%,即为父元素的高度。同时,.kite--position的子元素也声明为行内元素,因此这个时候可以利用vertical-align属性进行垂直居中.
##width:auto
这个属性平时用的不多,看源码的时候看里面用的很普遍,它的用法和width:100%还是有点区别的。
比如遇到这种结构:
<div class="parent">
<div class="child">123123</div>
</div>
.parent {
position: absolute;
left: 50px;
top: 50px;
width: 200px;
height: 200px;
border: 1px solid #e3e3e3;
}
.child {
width: auto 或者 100%;
//可以设置不同margin和padding看下效果
border: 1px solid #e3e3e3;
}一般块级元素如果不添加float或者绝对定位或者设定宽度的话,它的宽度默认为100%.这个宽度仅仅是内容的宽度,如果你再设置padding或者margin值,会保持width不变,会出现盒模型伸长或者移动位置的情况。
width = 内容但是如果你设置为width: auto,它起到的作用实际上和申明box-sizing: border-box的一样。
width = 内容 + padding + border;你再怎么设置padding值和border值都是在width这个宽度里面进行设置。
可以到codepen上看看
codepen.io
loadSomething().then(function(something) {
loadAnotherthing().then(function(anthor) {
DoSomethingOnThem(something, anthor);
})
})你这样书写的原因是需要对2个promise的结果进行处理,由于then()接收的是上一个promise返回的结果,因此你无法通过链式写法将其连接起来。
To Fix:
q.all([loadSomething(), loadAnotherThing()])
.spread(function(something, another) {
DoSomethingOnThem(something, another);
})q.all()方法将会等待loadSomething和loadAnotherThing都被resolve后调用传入spread方法里面的回调。
##The Broken Chain(断掉的promise链)
先看一段代码:
function anAsyncCall() {
var promise = doSomethingAsync();
promise.then(function() {
somethingComplicated();
})
return promise;
}这种写法的问题是当somethingComplicated方法中抛出错误无法被捕获。Promise应当是链式的,每次调用then()方法后都会返回一个新的promise。普遍的写法是:最后调用catch()方法,这样在前面的一系列的promise操作当中,发生的任何error都会被捕获。
上面的代码中,当你最后返回的是第一个promise,而非这个promise调用then()方法后的结果,那么promise链也随即断掉。
To Fix:
function anAsyncCall() {
var promise = doSomethingAsync();
return promise.then(function() {
somethingComplicated()
});
}##The Collection Kerfuffle
当你有一个数组,数组里面的每个项目都需要进行异步的处理。因此你可能会通过递归去做某些事情:
function workMyCollection(arr) {
var resultArr = [];
function _recursive(idx) {
if (idx >= resultArr.length) return resultArr;
return doSomethingAsync(arr[idx]).then(function(res) {
resultArr.push(res);
return _recursive(idx + 1);
});
}
return _recursive(0);
}这段代码第一眼看上去有点难以理解啊。主要是的问题是如果不知道还有map或者reduce方法,那么你也不会知道有多少个项目需要被链接起来,这样就比较蛋疼了。
To Fix:
上面提到的q.all方法接受一个数组,这个数组里面都是promise,然后q.all方法等待所有这些promise全部被resolve后,得到一个数组,由之前的promise被resolve后的值组成。这个时候我们可以通过map方法去改进上面的代码:
function workMyCollection(arr) {
return q.all(arr.map(function(item) {
return doSomethingAsync(item);
}));
}上面的递归写法是串行处理的,但是通过q.all和map进行改写后变成并行处理,因此更加高效。
如果你确实需要promise串行处理,那么你可以使用reduce方法:
function workMyCollection(arr) {
return arr.reduce(function(promise, item) {
return promise.then(function(result) {
return doSomethingAsyncWithResult(item, result);
}, q());
});
}虽然不是很整洁,但是肯定有条理。
##The Ghost Promise
有个方法有时需要异步进行处理,有时可能不需要。这时也可以创建一个promise,去保证2种不同的处理方式的连贯性。
var promise ;
if(asyncCallNeeded) {
promise = doSomethingAsync();
} else {
promise = Q.resolve(42);
}
promise.then(function() {
doSomethingCool();
});还有一种更加整洁的写法,就是使用Q()方法去包裹一个普通值或者promise。
Q(asyncCallNeeded ? doSomethingAsync() : 42)
.then(function(value) {
dosomethingGood();
})
.catch(function(err) {
handleTheError();
});##The Overly Keen Error Handler
then()方法接收2个参数,fullfilled handler以及rejected handler:
somethingAync.then(function() {
return somethingElseAsync();
}, function(err) {
handleMyError(err);
})但是这种写法存在一个问题就是如果有错误在somethingElseAsync方法中抛出,那么这个错误是无法被error handler捕获的。
这个时候需要将error handler单独注册到then()方法中。
To Fix:
somethingAsync
.then(function() {
return somethingElseAsync()
})
.then(null, function(err) {
handleMyError(err);
});或者使用catch()方法:
somethingAsync()
.then(function() {
return somethingElseAsync();
})
.catch(function(err) {
handleMyError(err);
});这2种写法都为了保证在promise链式处理过程中出现错误能被捕获。
##The Forgotten Promise
你调用了一个方法并返回了一个promise。然而,你忘记了这个promise并且创建了一个你自己的:
var deferred = Q.defer();
doSomethingAsync().then(function(res) {
res = manipulateMeInSomeWay(res);
deferred.resolve(res);
}, function(err) {
deferred.reject(err);
});
return deferred.promise(;这里面存在着很多无用的代码,并且和Promise简洁的**正好相悖。
To Fix:
return doSomethingAsync().then(function(res) {
return manipulateMeInSomeWay(res);
});相关资料:
Render Function 这块的内容我觉得是 Mpx 设计上的一大亮点内容。Mpx 引入 Render Function 主要解决的问题是性能优化方向相关的,因为小程序的架构设计,逻辑层和渲染层是2个独立的。
这里直接引用 Mpx 有关 Render Function 对于性能优化相关开发工作的描述:
作为一个接管了小程序setData的数据响应开发框架,我们高度重视Mpx的渲染性能,通过小程序官方文档中提到的性能优化建议可以得知,setData对于小程序性能来说是重中之重,setData优化的方向主要有两个:
- 尽可能减少setData调用的频次
- 尽可能减少单次setData传输的数据
为了实现以上两个优化方向,我们做了以下几项工作:
将组件的静态模板编译为可执行的render函数,通过render函数收集模板数据依赖,只有当render函数中的依赖数据发生变化时才会触发小程序组件的setData,同时通过一个异步队列确保一个tick中最多只会进行一次setData,这个机制和Vue中的render机制非常类似,大大降低了setData的调用频次;
将模板编译render函数的过程中,我们还记录输出了模板中使用的数据路径,在每次需要setData时会根据这些数据路径与上一次的数据进行diff,仅将发生变化的数据通过数据路径的方式进行setData,这样确保了每次setData传输的数据量最低,同时避免了不必要的setData操作,进一步降低了setData的频次。
接下来我们看下 Mpx 是如何实现 Render Function 的。这里我们从一个简单的 demo 来说起:
<template>
<text>Computed reversed message: "{{ reversedMessage }}"</text>
<view>the c string {{ demoObj.a.b.c }}</view>
<view wx:class="{{ { active: isActive } }}"></view>
</template>
<script>
import { createComponent } from "@mpxjs/core";
createComponent({
data: {
isActive: true,
message: 'messages',
demoObj: {
a: {
b: {
c: 'c'
}
}
}
},
computed() {
reversedMessage() {
return this.message.split('').reverse().join('')
}
}
})
</script>.mpx 文件经过 loader 编译转换的过程中。对于 template 模块的处理和 vue 类似,首先将 template 转化为 AST,然后再将 AST 转化为 code 的过程中做相关转化的工作,最终得到我们需要的 template 模板代码。
在packages/webpack-plugin/lib/template-compiler.js模板处理 loader 当中:
let renderResult = bindThis(`global.currentInject = {
moduleId: ${JSON.stringify(options.moduleId)},
render: function () {
var __seen = [];
var renderData = {};
${compiler.genNode(ast)}return renderData;
}
};\n`, {
needCollect: true,
ignoreMap: meta.wxsModuleMap
})在 render 方法内部,创建 renderData 局部变量,调用compiler.genNode(ast)方法完成 Render Function 核心代码的生成工作,最终将这个 renderData 返回。例如在上面给出来的 demo 实例当中,通过compiler.genNode(ast)方法最终生成的代码为:
((mpxShow)||(mpxShow)===undefined?'':'display:none;');
if(( isActive )){
}
"Computed reversed message: \""+( reversedMessage )+"\"";
"the c string "+( demoObj.a.b.c );
(__injectHelper.transformClass("list", ( {active: isActive} )));TODO: compiler.genNode 方法的具体的流程实现思路
mpx 文件当中的 template 模块被初步处理成上面的代码后,可以看到这是一段可执行的 js 代码。那么这段 js 代码到底是用作何处呢?可以看到compiler.genNode方法是被包裹至bindThis方法当中的。即这段 js 代码还会被bindThis方法做进一步的处理。打开 bind-this.js 文件可以看到内部的实现其实就是一个 babel 的 transform plugin。在处理上面这段 js 代码的 AST 的过程中,通过这个插件对 js 代码做进一步的处理。最终这段 js 代码处理后的结果是:
TODO: Babel 插件的具体功效
/* mpx inject */ global.currentInject = {
moduleId: "2271575d",
render: function () {
var __seen = [];
var renderData = {};
(renderData["mpxShow"] = [this.mpxShow, "mpxShow"], this.mpxShow) || (renderData["mpxShow"] = [this.mpxShow, "mpxShow"], this.mpxShow) === undefined ? '' : 'display:none;';
"Computed reversed message: \"" + (renderData["reversedMessage"] = [this.reversedMessage, "reversedMessage"], this.reversedMessage) + "\"";
"the c string " + (renderData["demoObj.a.b.c"] = [this.demoObj.a.b.c, "demoObj"], this.__get(this.__get(this.__get(this.demoObj, "a"), "b"), "c"));
this.__get(__injectHelper, "transformClass")("list", { active: (renderData["isActive"] = [this.isActive, "isActive"], this.isActive) });
return renderData;
}
};bindThis 方法对于 js 代码的转化规则就是:
这里的 this 为 mpx 构造的一个代理对象,在你业务代码当中调用 createComponent/createPage 方法传入的配置项,例如 data,都会通过这个代理对象转化为响应式的数据。
需要注意的是不管哪种数据形式的改造,最终需要达到的效果就是确保在 Render Function 执行的过程当中,这些被模板使用到的数据能被正常的访问到,在访问的阶段中,这些被访问到的数据即被加入到 mpx 构建的整个响应式的系统当中。
只要在 template 当中使用到的 data 数据(包括衍生的 computed 数据),最终都会被 renderData 所记录,而记录的数据形式是例如:
renderData['xxx'] = [this.xxx, 'xxx'] // 数组的形式,第一项为这个数据实际的值,第二项为这个数据的 firstKey(主要用以数据 diff 的工作)以上就是 mpx 生成 Render Function 的整个过程。总结下 Render Function 所做的工作:
next-tick 算是 Vue 内部的一个核心的方法,它提供了一种异步执行任务的机制。它具体的源码在 src/core/util/next-tick.js 内部。
/* @flow */
/* globals MessageChannel */
import { noop } from 'shared/util'
import { handleError } from './error'
import { isIOS, isNative } from './env'
const callbacks = []
let pending = false
function flushCallbacks () {
pending = false
const copies = callbacks.slice(0)
callbacks.length = 0
for (let i = 0; i < copies.length; i++) {
copies[i]()
}
}
// Here we have async deferring wrappers using both microtasks and (macro) tasks.
// In < 2.4 we used microtasks everywhere, but there are some scenarios where
// microtasks have too high a priority and fire in between supposedly
// sequential events (e.g. #4521, #6690) or even between bubbling of the same
// event (#6566). However, using (macro) tasks everywhere also has subtle problems
// when state is changed right before repaint (e.g. #6813, out-in transitions).
// Here we use microtask by default, but expose a way to force (macro) task when
// needed (e.g. in event handlers attached by v-on).
let microTimerFunc
let macroTimerFunc
let useMacroTask = false
// Determine (macro) task defer implementation.
// Technically setImmediate should be the ideal choice, but it's only available
// in IE. The only polyfill that consistently queues the callback after all DOM
// events triggered in the same loop is by using MessageChannel.
/* istanbul ignore if */
if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
macroTimerFunc = () => {
setImmediate(flushCallbacks)
}
} else if (typeof MessageChannel !== 'undefined' && (
isNative(MessageChannel) ||
// PhantomJS
MessageChannel.toString() === '[object MessageChannelConstructor]'
)) {
const channel = new MessageChannel()
const port = channel.port2
channel.port1.onmessage = flushCallbacks
macroTimerFunc = () => {
port.postMessage(1)
}
} else {
/* istanbul ignore next */
macroTimerFunc = () => {
setTimeout(flushCallbacks, 0)
}
}
// Determine microtask defer implementation.
/* istanbul ignore next, $flow-disable-line */
if (typeof Promise !== 'undefined' && isNative(Promise)) {
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
// in problematic UIWebViews, Promise.then doesn't completely break, but
// it can get stuck in a weird state where callbacks are pushed into the
// microtask queue but the queue isn't being flushed, until the browser
// needs to do some other work, e.g. handle a timer. Therefore we can
// "force" the microtask queue to be flushed by adding an empty timer.
if (isIOS) setTimeout(noop)
}
} else {
// fallback to macro
microTimerFunc = macroTimerFunc
}
/**
* Wrap a function so that if any code inside triggers state change,
* the changes are queued using a (macro) task instead of a microtask.
*/
export function withMacroTask (fn: Function): Function {
return fn._withTask || (fn._withTask = function () {
useMacroTask = true
const res = fn.apply(null, arguments)
useMacroTask = false
return res
})
}
export function nextTick (cb?: Function, ctx?: Object) {
let _resolve
callbacks.push(() => {
if (cb) {
try {
cb.call(ctx)
} catch (e) {
handleError(e, ctx, 'nextTick') // 处理当 cb 执行过程中出现的报错
}
} else if (_resolve) {
_resolve(ctx)
}
})
if (!pending) {
pending = true
if (useMacroTask) {
macroTimerFunc()
} else {
microTimerFunc()
}
}
// $flow-disable-line
if (!cb && typeof Promise !== 'undefined') {
return new Promise(resolve => {
_resolve = resolve
})
}
}在 next-tick 内部分别定义了 microTimerFunc 和 macroTimerFunc,用以存储当前宿主环境所支持的 mircoTask 和 marcoTask。在 Vue 当中使用的 marcoTask 包含了 setImmediate/messageChannel/setTimeout,mircoTask 包含了 Promise。
Vue 在全局环境下提供了 Vue.nextTick 方法,在实例上提供了 $nextTick 方法以供调用。就拿全局对象上提供的 Vue.nextTick 方法来说,首先将传入的 cb 缓存至 callbacks 内部。然后根据 useMacroTask 来决定使用 macroTimerFunc 还是 microTimerFunc。在 nextTick 内部并没有直接执行传入的 cb,而是缓存至 callbacks 内部,在下一帧遍历 callbacks 内部缓存的所有 cb,这个时候这些 cb 都是同步去执行的。
特别是使用 microTimerFunc 的情况下,我们可以看到首先在函数外部定义一个被 resolved 的 promise。然后在函数体内部将 flushCallbacks 方法至于promise.then当中:
const p = Promise.resolve()
microTimerFunc = () => {
p.then(flushCallbacks)
}通过代码我们得知 flushCallbacks 方法内部是通过一个 for 循环去遍历执行 callbacks 内部缓存的所有的回调函数。这样就会将这些 callbacks 放到同一帧当中去执行。
webpack 子编译可以理解成创建了一个新的构建流程。webpack 内部的 compilation 的实例上提供了创建子编译流程的 API:createChildCompiler。
class Compilation {
...
/**
* This function allows you to run another instance of webpack inside of webpack however as
* a child with different settings and configurations (if desired) applied. It copies all hooks, plugins
* from parent (or top level compiler) and creates a child Compilation
*
* @param {string} name name of the child compiler
* @param {TODO} outputOptions // Need to convert config schema to types for this
* @param {Plugin[]} plugins webpack plugins that will be applied
* @returns {Compiler} creates a child Compiler instance
*/
createChildCompiler(name, outputOptions, plugins) {
const idx = this.childrenCounters[name] || 0;
this.childrenCounters[name] = idx + 1;
return this.compiler.createChildCompiler(
this, // 传入 compilation 对象
name,
idx,
outputOptions,
plugins
);
}
...
}那么这个子编译流程到底和父编译流程有哪些差异呢?
class Compiler {
...
createChildCompiler(
compilation,
compilerName,
compilerIndex,
outputOptions,
plugins
) {
const childCompiler = new Compiler(this.context); // 创建新的 compiler 对象,和父 compiler 拥有相同的 context 上下文路径
if (Array.isArray(plugins)) { // 如果在子编译的过程中需要相关插件的处理,那么就在创建子编译的阶段传入这些插件,需要注意的是在这个阶段执行这些插件的话,下面的有关 childCompiler 一些配置信息是拿不到的,因此可以先创建 childCompiler,然后由自己去手动的 apply 插件
for (const plugin of plugins) {
plugin.apply(childCompiler);
}
}
for (const name in this.hooks) {
if (
![
"make",
"compile",
"emit",
"afterEmit",
"invalid",
"done",
"thisCompilation"
].includes(name)
) {
if (childCompiler.hooks[name]) { // 子编译不会继承上面列出来的编译流程当中的钩子
childCompiler.hooks[name].taps = this.hooks[name].taps.slice();
}
}
}
// 接下来就是设置子编译 compiler 实例上的相关的属性或者方法
childCompiler.name = compilerName;
childCompiler.outputPath = this.outputPath;
childCompiler.inputFileSystem = this.inputFileSystem;
childCompiler.outputFileSystem = null;
childCompiler.resolverFactory = this.resolverFactory;
childCompiler.fileTimestamps = this.fileTimestamps;
childCompiler.contextTimestamps = this.contextTimestamps;
const relativeCompilerName = makePathsRelative(this.context, compilerName);
if (!this.records[relativeCompilerName]) {
this.records[relativeCompilerName] = [];
}
if (this.records[relativeCompilerName][compilerIndex]) {
childCompiler.records = this.records[relativeCompilerName][compilerIndex];
} else {
this.records[relativeCompilerName].push((childCompiler.records = {}));
}
childCompiler.options = Object.create(this.options); // options 配置继承于父编译 compiler 实例
childCompiler.options.output = Object.create(childCompiler.options.output);
for (const name in outputOptions) {
childCompiler.options.output[name] = outputOptions[name];
}
childCompiler.parentCompilation = compilation; // 建立父子编译之间的关系
// 触发 childCompiler hooks
compilation.hooks.childCompiler.call(
childCompiler,
compilerName,
compilerIndex
);
return childCompiler;
}
...
}通过代码我们发现在创建子编译 compiler 的过程中是过滤掉了make/compiler/emit/afterEmit等 hooks 的触发函数的,即子编译流程相对于父编译流程来说的话不具备完整的构建流程。例如在父编译的流程开始阶段会触发 hooks.make 钩子,这样完成入口文件的添加及开始相关的编译流程,而子编译要想完成编译文件的工作的话就需要你手动的在创建子编译的时候添加入口插件(例如 SingleEntryPlugin)。父编译阶段使用 compiler 实例上的 run 方法开始进行,而子编译阶段有一个独立的 runAsChild 方法用以开始编译,其中在 runAsChild 方法的 callback 中可以看到子编译阶段是没有单独的 emitAssets 的阶段的。在子编译阶段如果需要输出文件的话,是需要挂载到父编译的 compilation.assets 上的:
class Compiler {
...
runAsChild() {
this.compile((err, compilation) => {
...
this.parentCompilation.children.push(compilation)
for (const name of Object.keys(compilation.assets)) { // 将子编译需要输出的 chunk 文件挂载到父编译上,进而完成相关的 chunk 的输出工作
this.parentCompilation.assets[name] = compilation.assets[name];
}
...
})
}
...
}那么 childCompiler 子编译具体有哪些使用场景呢?在 webpack 官方的抽离 css chunk 的插件当中mini-css-extract-plugin就是使用到了 childCompiler 子编译去完成 css 的抽离工作,它主要体现了这个插件内部会提供了一个单独的 pitch loader,使用这个 pitch loader 进行样式模块(例如css/stylus/scss/less)的流程处理的拦截工作,在拦截的过程当中为每个样式模块都创建新的 childCompiler,这个 childCompiler 主要完成的工作就是专门针对这个样式模块进行编译相关的工作。可以想象的到就是每一个样式模块完成编译的工作后,都会生成一个 css chunk file。当然我们最终希望的是这些 css chunk file 最终能合并到一个 css chunk 文件当中,最后项目上线后,只需要加载少量的 css 文件。因此在 mini-css-extract-plugin 插件内部,每个样式模块通过子编译的流程后,是直接删除掉了 compilation.chunks 当中包含的所有的 file,即这些 css 模块最终不会被挂载到父编译的 assets 上,这样也不会为每个样式模块输出一个 css chunk file。这个插件等每个样式模块的子编译流程结束后,都会新建一个 css module,这个 css module 依赖类型为插件内部自己定义的,并且会作为当前正在编译的 module 依赖而被添加到当前模块当中。接下来,在父编译的 createChunkAssets 流程当中,分别触发 maniTemplate.hooks.renderManifest 和 chunkTemplate.hooks.renderManifest 的钩子的时候,会分别将 chunk 当中所包含的 css module 过滤出来,得到 css module 的集合,这样最终在输出文件的时候就会输出 css chunk 文件,这些 css chunk 文件当中就是分别包含了 css module 的集合而输出的。
PS:不过在你写插件或者 loader 的过程中,需要注意的一个地方就是一些 hooks,例如 thisCompilation 是不会被 childCompiler 继承的,因此如果有些插件注册的相关的 hooks 正好是这个,那么在你创建了 childCompiler 需要手动的调用这些插件的 apply 方法并传入 childCompiler,这样这些插件才能在 childCompiler 当中工作起来。这里也可以很明显的感受到在 compiler.js 当中触发 hooks.thisCompilation 和 hooks.compilation 2个钩子的区别。hooks.compilation 会被 childCompiler 继承,在 childCompiler 编译流程当中还会触发对应的钩子函数,而 hooks.thisCompilation 上绑定的钩子函数只适用于当前的 compiler 编译流程,如果是需要在其他的编译流程(childCompiler)当中使用的话,那么就需要手动的添加这些钩子。
主 compiler 在创建子编译的过程当中 compilation.createChildCompiler 会将主 compiler 上已经注册好的 hooks 一并在 childCompiler 上注册好。例如在主 compiler 上注册了 hooks.finishMake 的回调,那么在 childCompiler 编译流程当中,会触发这个 hooks.finishMake 所注册好的回调。
一个是钩子数量上有差异,另外就是 childCompiler 会复用主 compiler 上注册好的对应的 hooks。
Ruleset 类主要作用于过滤加载 module 时符合匹配条件规则的 loader。Ruleset 在内部会有一个默认的 module.defaultRules 配置,在真正加载 module 之前会和你在 webpack config 配置文件当中的自定义 module.rules 进行合并,然后转化成对应的匹配过滤器。
webpack 文档上对于 Ruleset 的说明太过于抽象,在文档上提到的条件,结果和嵌套规则并没有做很好的说明。本文会结合示例,源码来解释下这3点具体是指哪些内容。
首先我们来看下 module.defaultRules 配置是在 WebpackOptionsDefaulter.js 当中完成的,得到的结果是:
[ { type: 'javascript/auto', resolve: {} },
{ test: /\.mjs$/i,
type: 'javascript/esm',
resolve: { mainFields: [Array] } },
{ test: /\.json$/i, type: 'json' },
{ test: /\.wasm$/i, type: 'webassembly/experimental' }]这个数组最终会和你 webpack config 配置的 module.rules 进行 concat 合并成一个数组,并传入 Ruleset 的构造函数当中,得到 ruleset 实例:
// NormalModuleFactory.js
class NormalModuleFactory {
...
this.ruleset = new Ruleset(options.defaultRules.concat(options.rules))
...
}接下来我们来看下 Ruleset 构造函数里面到底进行了哪些处理:
class Ruleset {
constructor(rules) {
this.references = Object.create(null);
this.rules = RuleSet.normalizeRules(rules, this.references, "ref-");
}
// 序列化 rules 配置选项
static normalizeRules(rules, refs, ident) {
if (Array.isArray(rules)) {
return rules.map((rule, idx) => {
return RuleSet.normalizeRule(rule, refs, `${ident}-${idx}`);
});
} else if (rules) {
return [RuleSet.normalizeRule(rules, refs, ident)];
} else {
return [];
}
}
static normalizeRule(rule, refs, ident) {
...
}
}我们可以看到构造函数里面定义了 normalizeRules 静态方法,它的作用实际就是对传入的 rules 配置进行序列化(格式化)的处理为统一的格式,其中就包含了对于条件的序列化。在 module.defaultRules 和 webpack.config 里面有关 rules 的配置你可以理解为最原始的条件配置,这些配置通过 Ruleset 内部提供的方法格式化收敛为统一的过滤条件,最终匹配 loaders 时就是使用格式化过后的这些过滤条件。
有关 webpack.config 里面暴露出来供开发者使用的(常用的)条件配置主要有:
test/include/exclude 这3项我们平时使用较多的配置实际上是和 resouce 配置是等价的,2者只能存在其一,不能混用。其中test/include 用以匹配满足条件的 loader,而 exclude 用以排除满足条件 loader,resouceQuery 主要是用以在路径中带 query 参数的匹配规则,例如你的模块依赖路径为 xxx/xxx?type=demo, resolveQuery 的配置为 /type=demo/,那么便会符合对应的匹配规则。这些字段支持的数据类型有:
接下来我们看下 Ruleset 内部是如何将原始的配置进行格式的,以及最终格式化所输出的内容。
class RuleSet {
...
static normalizeRule(rule, refs, ident) {
...
if (rule.test || rule.include || rule.exclude) {
condition = {
test: rule.test,
include: rule.include,
exclude: rule.exclude
};
try {
newRule.resource = RuleSet.normalizeCondition(condition);
} catch (error) {
throw new Error(RuleSet.buildErrorMessage(condition, error));
}
}
if (rule.resource) {
checkResourceSource("resource");
try {
newRule.resource = RuleSet.normalizeCondition(rule.resource);
} catch (error) {
throw new Error(RuleSet.buildErrorMessage(rule.resource, error));
}
}
if (rule.resourceQuery) {
try {
newRule.resourceQuery = RuleSet.normalizeCondition(rule.resourceQuery);
} catch (error) {
throw new Error(RuleSet.buildErrorMessage(rule.resourceQuery, error));
}
}
if (rule.issuer) {
try {
newRule.issuer = RuleSet.normalizeCondition(rule.issuer);
} catch (error) {
throw new Error(RuleSet.buildErrorMessage(rule.issuer, error));
}
}
...
}
static normalizeCondition(condition) {
if (!condition) throw new Error("Expected condition but got falsy value");
// 如果配置数据类型为 string,那么直接使用 indexOf 作为路径匹配规则
if (typeof condition === "string") {
return str => str.indexOf(condition) === 0;
}
// 如果为 function 函数,那么使用这个开发者自己定义的 function 作为路径匹配规则
if (typeof condition === "function") {
return condition;
}
// 如果为正则表达式
if (condition instanceof RegExp) {
return condition.test.bind(condition);
}
// 如果为一个数组,那么分别处理数组当中的每一个元素,最终返回一个由 orMatcher 包装的函数,就是只要其中一个元素的匹配条件,那么就返回为 true
if (Array.isArray(condition)) {
const items = condition.map(c => RuleSet.normalizeCondition(c));
return orMatcher(items);
}
if (typeof condition !== "object") {
throw Error(
"Unexcepted " +
typeof condition +
" when condition was expected (" +
condition +
")"
);
}
// 匹配规则数组
const matchers = [];
// 如果为对象类型,那么最终会用一个 matchers 数组将这些条件收集起来
Object.keys(condition).forEach(key => {
const value = condition[key];
switch (key) {
case "or":
case "include":
case "test":
if (value) matchers.push(RuleSet.normalizeCondition(value));
break;
case "and":
if (value) {
const items = value.map(c => RuleSet.normalizeCondition(c));
matchers.push(andMatcher(items)); // andMatcher 必须在 items 里面都匹配
}
break;
case "not":
case "exclude":
if (value) {
const matcher = RuleSet.normalizeCondition(value);
matchers.push(notMatcher(matcher)); // notMatcher 必须在 matcher 之外
}
break;
default:
throw new Error("Unexcepted property " + key + " in condition");
}
});
if (matchers.length === 0) {
throw new Error("Excepted condition but got " + condition);
}
if (matchers.length === 1) {
return matchers[0];
}
return andMatcher(matchers);
}
...
}在 normalizeCondition 函数执行后始终返回的是一个函数,这个函数的用途就是接受模块的路径,然后使用你所定义的匹配使用去看是否满足对应的要求,如果满足那么会使用这个 loader,如果不满足那么便会过滤掉。
以上是对于 rule condition 条件的解释,接下来看下 rule 结果的相关解释。简单来讲就是我们使用 condition 来匹配我们需要的 rule 结果,condition 和 rule 是一一对应的关系,rule 结果就是最终我们需要加载这个模块需要使用的所有相关 loader 数组。我们首先来看下哪些配置字段和 rule 结果有强相关性:
这几个对应的配置写法有:
{
module: {
rules: [
{
test: /.vue$/,
loader: 'vue-loader'
},
{
test: /.scss$/,
use: [
'vue-style-loader',
'css-loader',
{
loader: 'sass-loader',
options: {
data: '$color: red;'
}
}
]
}
]
}
}在 RuleSet 构造函数内部使用静态方法 normalizeUse 方法来输出最终和 condition 对应的 rule 结果:
class RuleSet {
static normalizeUse(use, ident) {
if (typeof use === "function") {
return data => RuleSet.normalizeUse(use(data), ident);
}
if (Array.isArray(use)) {
return use
.map((item, idx) => RuleSet.normalizeUse(item, `${ident}-${idx}`))
.reduce((arr, items) => arr.concat(items), []);
}
return [RuleSet.normalizeUseItem(use, ident)];
}
static normalizeUseItemString(useItemString) {
const idx = useItemString.indexOf("?");
if (idx >= 0) {
return {
loader: useItemString.substr(0, idx),
options: useItemString.substr(idx + 1)
};
}
return {
loader: useItemString,
options: undefined
};
}
static normalizeUseItem(item, ident) {
if (typeof item === "string") {
return RuleSet.normalizeUseItemString(item);
}
const newItem = {};
if (item.options && item.query) {
throw new Error("Provided options and query in use");
}
if (!item.loader) {
throw new Error("No loader specified");
}
newItem.options = item.options || item.query;
if (typeof newItem.options === "object" && newItem.options) {
if (newItem.options.ident) {
newItem.ident = newItem.options.ident;
} else {
newItem.ident = ident;
}
}
const keys = Object.keys(item).filter(function(key) {
return !["options", "query"].includes(key);
});
for (const key of keys) {
newItem[key] = item[key];
}
return newItem;
}
}经过 normalizeUse 函数的格式化处理,最终的 rule 结果为一个数组,内部的 object 元素都包含 loader/options 等字段:
[{
loader: 'xxx-loader',
options: {
data: '$color red'
}
}, {
lodaer: 'xxx-loader',
options: 'a=b&c=d'
}]经过 RuleSet 内部的格式化的处理,最终输出的 rules 为:
rules: [
{
resource: [Function],
resourceQuery: [Function],
use: [{
loader: 'xxx-loader',
options: {
data: '$color red'
}
}]
},
{
resource: [Function],
resourceQuery: [Function],
use: [{
loader: 'xxx-loader',
options: 'a=b&c=d'
}]
}
]以上便是 RuleSet 构造函数实例化以及格式化 condition 及 rule 结果的过程。这个过程结束后,便可利用 ruleset 实例上的 exec 进行相关的匹配过滤工作。
在 webpack 正常的工作流当中,在加载对应的 module 之前首先需要知道加载这个模块具体使用哪些 loader,便是调用 ruleset 实例上的 exec 去过滤对应的 loader。
具体的使用方法为:
// NormalModuleFactory.js
this.ruleset.exec({
resource: resourcePath, // module 的路径
realResource:
matchResource !== undefined
? resource.replace(/\?.*/, "")
: resourcePath,
resourceQuery, // module 路径上所带的 query 参数
issuer: contextInfo.issuer, // 这个模块的发布者
compiler: contextInfo.compiler // 这个模块所使用的编译器选项
})
接下来我们看下 exec 方法内部具体的实现:
class RuleSet {
...
exec(data) {
const result = [];
this._run(
data,
{
rules: this.rules // 根据内置的 rules 和传入的 module.rule 合并后生成的 rules
},
result
);
return result;
}
_run(data, rule, result) {
// test conditions
// 一系列的匹配规则,只有通过这些匹配规则,才会将对应的 loaders 加入到数组中
if (rule.resource && !data.resource) return false;
if (rule.realResource && !data.realResource) return false;
if (rule.resourceQuery && !data.resourceQuery) return false;
if (rule.compiler && !data.compiler) return false;
if (rule.issuer && !data.issuer) return false;
if (rule.resource && !rule.resource(data.resource)) return false; // resource 匹配规则
if (rule.realResource && !rule.realResource(data.realResource))
return false;
if (data.issuer && rule.issuer && !rule.issuer(data.issuer)) return false;
if (
data.resourceQuery &&
rule.resourceQuery &&
!rule.resourceQuery(data.resourceQuery) // resourceQuery 的匹配规则
) {
return false;
}
if (data.compiler && rule.compiler && !rule.compiler(data.compiler)) {
return false;
}
// apply
const keys = Object.keys(rule).filter(key => {
return ![
"resource",
"realResource",
"resourceQuery",
"compiler",
"issuer",
"rules",
"oneOf",
"use",
"enforce"
].includes(key);
});
for (const key of keys) {
result.push({
type: key,
value: rule[key]
});
}
if (rule.use) {
const process = use => {
if (typeof use === "function") {
process(use(data));
} else if (Array.isArray(use)) {
use.forEach(process);
} else {
result.push({
type: "use",
value: use,
enforce: rule.enforce
});
}
};
process(rule.use);
}
if (rule.rules) {
for (let i = 0; i < rule.rules.length; i++) {
this._run(data, rule.rules[i], result);
}
}
if (rule.oneOf) {
for (let i = 0; i < rule.oneOf.length; i++) {
if (this._run(data, rule.oneOf[i], result)) break;
}
}
return true;
}
}过滤过程的实现应该是非常清晰的,就是递归的根据 ruleset 在实例化的时候创建的各种过滤条件(对应的不同的 Function),以及传入的不同字段(resouce/realsource/compiler/issuer/compiler),最终输出的数据格式即 webpack 文档上所说的结果为:
[{
type: 'use',
value: {
loader: 'vue-style-loader',
options: {}
},
enforce: undefined // 可选值还有 pre/post 分别为 pre-loader 和 post-loader
}, {
type: 'use',
value: {
loader: 'css-loader',
options: {}
},
enforce: undefined
}, {
type: 'use',
value: {
loader: 'sass-loader',
options: {
data: '$color red'
}
},
enforce: undefined
}]RuleSet 的使用主要包含了:
RuleSet 的实例化过程,即根据 webpack.module.rules 的配置及 webpack 内部的 rules 配置,将不同字段的不同数据类型,例如 string/RegExp/Function 等都转化为对应的过滤函数,因为 webpack 的 rules 为了满足不同的配置需求,设计的还是相对来说很灵活的,对于开发者而且可以使用灵活多样的配置形式,但是收敛到 ruleset 内部便统一转化为过滤函数的形式;
exec 方法过滤阶段便是根据传入的不同的配置规则来递归的进行匹配,最终输出被匹配到的 loaders 数组。
记录下webpack-dev-server的用法.
首先,我们来看看基本的webpack.config.js的写法
module.exports = {
entry: './src/js/index.js',
output: {
path: './dist/js',
filename: 'bundle.js'
}
}配置文件提供一个入口和一个出口,webpack根据这个来进行js的打包和编译工作。虽然webpack提供了webpack --watch的命令来动态监听文件的改变并实时打包,输出新bundle.js文件,这样文件多了之后打包速度会很慢,此外这样的打包的方式不能做到hot replace,即每次webpack编译之后,你还需要手动刷新浏览器。
webpack-dev-server其中部分功能就能克服上面的2个问题。webpack-dev-server主要是启动了一个使用express的Http服务器。它的作用主要是用来伺服资源文件。此外这个Http服务器和client使用了websocket通讯协议,原始文件作出改动后,webpack-dev-server会实时的编译,但是最后的编译的文件并没有输出到目标文件夹,即上面配置的:
output: {
path: './dist/js',
filename: 'bundle.js'
}注意:你启动webpack-dev-server后,你在目标文件夹中是看不到编译后的文件的,实时编译后的文件都保存到了内存当中。因此很多同学使用webpack-dev-server进行开发的时候都看不到编译后的文件
下面来结合webpack的文档和webpack-dev-server里部分源码来说明下如何使用:
##启动
启动webpack-dev-server有2种方式:
cmd lineNode.js API##配置
我主要讲解下cmd line的形式,Node.js API形式大家去看下官方文档。可通过npm script进行启动。我的目录结构是:
app
|__dist
| |__styles
| |__js
| |__bundle.js
| |__index.html
|__src
| |__styles
| |__js
| |__index.js
|__node_modules
|__package.json
|__webpack.config.js
###content-base
设定webpack-dev-server伺服的directory。如果不进行设定的话,默认是在当前目录下。
webpack-dev-server --content-base ./dist
这个时候还要注意的一点就是在webpack.config.js文件里面,如果配置了output的publicPath这个字段的值的话,在index.html文件里面也应该做出调整。因为webpack-dev-server伺服的文件是相对publicPath这个路径的。因此,如果你的webpack.config.js配置成这样的:
module.exports = {
entry: './src/js/index.js',
output: {
path: './dist/js',
filename: 'bundle.js',
publicPath: '/assets/'
}
}那么,在index.html文件当中引入的路径也发生相应的变化:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Demo</title>
</head>
<body>
<script src="assets/bundle.js"></script>
</body>
</html>如果在webpack.config.js里面没有配置output的publicPath的话,那么index.html最后引入的文件js文件路径应该是下面这样的。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Demo</title>
</head>
<body>
<script src="bundle.js"></script>
</body>
</html>##Automatic Refresh
webpack-dev-server支持2种自动刷新的方式:
这2种模式配置的方式和访问的路径稍微有点区别,最主要的区别还是Iframe mode是在网页中嵌入了一个iframe,将我们自己的应用注入到这个iframe当中去,因此每次你修改的文件后,都是这个iframe进行了reload。
通过查看webpack-dev-server的源码,lib路径下的Server.js文件,第38-48行,分别新建几个流,这几个流保存了client文件夹下的相关文件:
// Prepare live html page
var livePage = this.livePage = new StreamCache();
fs.createReadStream(path.join(__dirname, "..", "client", "live.html")).pipe(livePage);
// Prepare the live js file
var liveJs = new StreamCache();
fs.createReadStream(path.join(__dirname, "..", "client", "live.bundle.js")).pipe(liveJs);
// Prepare the inlined js file
var inlinedJs = new StreamCache();
fs.createReadStream(path.join(__dirname, "..", "client", "index.bundle.js")).pipe(inlinedJs); // Init express server
var app = this.app = new express();
// middleware for serving webpack bundle
this.middleware = webpackDevMiddleware(compiler, options);
app.get("/__webpack_dev_server__/live.bundle.js", function(req, res) {
res.setHeader("Content-Type", "application/javascript");
liveJs.pipe(res);
});
app.get("/webpack-dev-server.js", function(req, res) {
res.setHeader("Content-Type", "application/javascript");
inlinedJs.pipe(res);
});
app.get("/webpack-dev-server/*", function(req, res) {
res.setHeader("Content-Type", "text/html");
this.livePage.pipe(res);
}.bind(this));
当使用Iframe mode时,请求/webpack-dev-server/index.html路径时,会返回client/index.html文件,这个文件的内容就是:
<!DOCTYPE html><html><head><meta http-equiv="X-UA-Compatible" content="IE=edge"/><meta charset="utf-8"/><meta name="viewport" content="width=device-width, height=device-height, initial-scale=1.0, user-scalable=no, minimum-scale=1.0, maximum-scale=1.0"/><script type="text/javascript" charset="utf-8" src="/__webpack_dev_server__/live.bundle.js"></script></head><body></body></html>
这个页面会请求live.bundle.js,其中里面会新建一个Iframe,你的应用就被注入到了这个Iframe当中。同时live.bundle.js中含有socket.io的client代码,这样它就能和webpack-dev-server建立的http server进行websocket通讯了。并根据返回的信息完成相应的动作。
而Inline-mode,是webpack-dev-server会在你的webpack.config.js的入口配置文件中再添加一个入口,
module.exports = {
entry: {
app: [
'webpack-dev-server/client?http://localhost:8080/',
'./src/js/index.js'
]
},
output: {
path: './dist/js',
filename: 'bundle.js'
}
}
这样就完成了将inlinedJS打包进bundle.js里的功能,同时inlinedJS里面也包含了socket.io的client代码,可以和webpack-dev-server进行websocket通讯。
当然你也可以直接在你index.html引入这部分代码:
<script src="http://localhost:8080/webpack-dev-server.js"></script>
不过Iframe mode和Inline mode最后达到的效果都是一样的,都是监听文件的变化,然后再将编译后的文件推送到前端,完成页面的reload的。
###Iframe mode
Iframe mode下cmd line不需要添加其他的内容,浏览器访问的路径是:
localhost:8080/webpack-dev-server/index.html。
这个时候这个页面的header部分会出现整个reload消息的状态。当时改变源文件的时候,即可以完成自动编译打包,页面自动刷新的功能。
###Inline mode
使用inline mode的时候,cmd line需要写成:
webpack-dev-server --inline --content-base ./dist
这个时候访问的路径是:
localhost:8080/index.html
也能完成自动编译打包,页面自动刷新的功能。但是没有的header部分的reload消息的显示,不过在控制台中会显示reload的状态。
##Hot Module Replacement
开启Hot Module Replacement功能,在cmd line里面添加--hot
webpack-dev-server --hot --inline --content-base ./dist
##其他配置选项
--quiet 控制台中不输出打包的信息
--compress 开启gzip压缩
--progress 显示打包的进度
还有一切其他的配置信息可以查阅官方文档:
这是我的package.json的文件:
{
"name": "reptile",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"dev": "webpack-dev-server --devtool eval-source-map --progress --colors --hot --inline --content-base ./dist",
"build": "webpack --progress --colors"
},
"author": "",
"license": "ISC",
"devDependencies": {
"babel-core": "^6.13.2",
"babel-loader": "^6.2.5",
"babel-preset-es2015": "^6.13.2",
"babel-preset-react": "^6.11.1",
"css-loader": "^0.23.1",
"react": "^15.3.1",
"react-dom": "^15.3.1",
"style-loader": "^0.13.1",
"webpack": "^1.13.2",
"webpack-dev-server": "^1.14.1"
}
}
首先命令行:输入 npm install 所有依赖。然后输入npm run dev。在浏览器中打开localhost:8080/index.html,然后就可以愉快的开发咯。
##本地搭建API Server
如果你在本地还启动了一个api server,port为3000,这个server主要和你的前端应用进行数据交互。这个时候很显然会出现跨域的问题,那么这个时候,你前端应用的入口文件应当是用你自己启动的api server提供的。
var express = require('express');
var app = express();
app.get('/', function(req, res) {
res.send('xxx/xxx/index.html'); //这个地方填写dist/index.html的路径
})
此外webpack.config.js:
module.exports = {
entry: './src/js/index.js',
output: {
path: './dist/js',
filename: 'bundle.js',
publicPath: 'localhost:8080/dist'
},
devServer: {
'/get': {
targer: 'localhost:3000',
secure: false
}
}
}
将publicPath字段的内容配置为绝对路径。同时index.html文件中对js引用的路径也改为绝对路径
<script src="localhost:8080/dist/bundle.js"></script>
如果对web-dev-server还有其他问题的话,请留言告知。
另外2篇关于webpack的文章:
在我们使用 webpack 作为我们的构建工具来进行日常的业务开发过程中,我们可以借助 babel 这样的代码编译转化工具来使用 js 新版本所实现的特性,其中 ES Module 模块标准是 ES6 当中实现的,在一些低版本的浏览器当中肯定是没法直接使用 ES Module 的。所以我们需要借助 webpack 来完成相关的模块加载、执行等相关的工作,使得我们在源码当中写的遵照 ES Module 规范的代码能在低版本的浏览器当中运行。这篇文章主要就是来介绍下 webpack 自身为了达到这样一个目的从而实现的自己的一套模块系统。
我们首先来看个简单的例子:
// a.js
import { add } from './b'
add(1, 2)
import(/* webpackChunkName: "c" */ './c.js').then(del => del(3, 4)) // 异步加载 c 模块// b.js
export function add(n1, n2) {
return n1 + n2
}// c.js
export default function del(n1, n2) {
return n1 - n2
}webpack 输出到 dist 目标文件夹当中的代码可以这样分为这样3种:
其中 webpack runtime bootstrap 可以单独输出成一个 chunk,也可以使之包含于一个普通的 chunk 当中,这取决于你是否配置了相关的 chunk 优化策略,具体的内容参见webpack相关文档,在这里例子当中我们配置的是将 runtime bootstrap 单独打包输出一个 chunk。
其中在 runtime bootstrap 当中有个核心的方法:
/******/ // install a JSONP callback for chunk loading
/******/ function webpackJsonpCallback(data) {
/******/ var chunkIds = data[0];
/******/ var moreModules = data[1];
/******/ var executeModules = data[2];
/******/
/******/ // add "moreModules" to the modules object,
/******/ // then flag all "chunkIds" as loaded and fire callback
/******/ var moduleId, chunkId, i = 0, resolves = [];
/******/ for(;i < chunkIds.length; i++) {
/******/ chunkId = chunkIds[i];
/******/ if(installedChunks[chunkId]) {
/******/ resolves.push(installedChunks[chunkId][0]);
/******/ }
/******/ installedChunks[chunkId] = 0;
/******/ }
/******/ for(moduleId in moreModules) {
/******/ if(Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
/******/ modules[moduleId] = moreModules[moduleId];
/******/ }
/******/ }
/******/ if(parentJsonpFunction) parentJsonpFunction(data);
/******/
/******/ while(resolves.length) {
/******/ resolves.shift()();
/******/ }
/******/
/******/ // add entry modules from loaded chunk to deferred list
/******/ deferredModules.push.apply(deferredModules, executeModules || []);
/******/
/******/ // run deferred modules when all chunks ready
/******/ return checkDeferredModules();
/******/ };
/******/ // The require function
/******/ function __webpack_require__(moduleId) {
/******/
/******/ // Check if module is in cache
/******/ if(installedModules[moduleId]) {
/******/ return installedModules[moduleId].exports;
/******/ }
/******/ // Create a new module (and put it into the cache)
/******/ var module = installedModules[moduleId] = {
/******/ i: moduleId,
/******/ l: false,
/******/ exports: {}
/******/ };
/******/
/******/ // Execute the module function
/******/ modules[moduleId].call(module.exports, module, module.exports, __webpack_require__);
/******/
/******/ // Flag the module as loaded
/******/ module.l = true;
/******/
/******/ // Return the exports of the module
/******/ return module.exports;
/******/ }
/******/ // This file contains only the entry chunk.
/******/ // The chunk loading function for additional chunks
/******/ __webpack_require__.e = function requireEnsure(chunkId) {
...
/******/ };
...
/******/ var jsonpArray = window["webpackJsonp"] = window["webpackJsonp"] || [];
/******/ var oldJsonpFunction = jsonpArray.push.bind(jsonpArray);
/******/ jsonpArray.push = webpackJsonpCallback;
/******/ jsonpArray = jsonpArray.slice();
/******/ for(var i = 0; i < jsonpArray.length; i++) webpackJsonpCallback(jsonpArray[i]);
/******/ var parentJsonpFunction = oldJsonpFunction;__webpack_require__这个方法主要的功能就是首先判断 installedModules 上是否已经缓存了传入的 moduleId 对应的 module,如果有就直接返回这个 module.exports,即对应的 module 导出的内容。如果没有缓存过,那么首先初始化话一个新的 module 对象,并获取已经加载的 modules 上对应 moudleId 的 module 并执行(即实际每个模块的执行),传入module/module.exports/__webpack_require__这3个对象,这个 module 执行完之后就返回这个 module.exports 对象。
另外就是在 window 对象上定义了一个webpackJsonp数组对象。同时改写了这个数组的push方法为webpackJsonpCallback(这个方法的具体实现后面会讲)。
接下来我们就来看下不包含 runtime bootstrap 代码的 module 打包后是什么样的,我们看下需要异步加载的c.js最终打包出来的 chunk :
(window["webpackJsonp"] = window["webpackJsonp"] || []).push([[2],{
/***/ 2:
/***/ (function(module, __webpack_exports__, __webpack_require__) {
"use strict";
__webpack_require__.r(__webpack_exports__);
/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, "del", function() { return del; });
// import 'css-loader!./css-demo.css'
Promise.resolve(/* import() */).then(__webpack_require__.bind(null, 1)).then(function (add) {
return add(1, 2);
});
function del(a, b) {
return a - b;
}
/***/ })
}]);可以看到的是在 chunk 的最外层调用window["webpackJsonp"]上的push(即webpackJsonpCallback)方法,这个方法接收了一个数组参数,其中第一项为这个 chunk 的 chunkId,第二项为这个 chunk 所包含的所有 module。在webpackJsonpCallback方法内部主要完成的工作就是收集 moduleId/module 之间的映射关系并缓存(这个时候这个 module 还未被执行,只有调用__webpack_require__方法的时候才会执行这个 module),此外就是将在异步加载 module 时创建 promise 对象的 resolve 函数收集至一个 resolves 数组,然后一一推出并执行,即将那些异步加载的 promise 的状态进行 resolve,那么也就会执行这个 promise 通过 then 方法传入的回调函数。此外我们可以看到这个 chunk 当中只包含了一个 moduleId 为 2 的 module,这个 module 为一个匿名的函数,接受了3个参数,即上文当中提到的有关每个 module 执行时所接收的。再回到刚才的那个例子,通过import语法引入了其他的模块,同时使用export语法导出了对应的方法或者对象。那么这个 module 通过 webpack 处理后变为一个匿名函数,原本模块当中使用的import语法会通过__webpack_require__方法来引入其他模块,原模块使用的export语法通过__webpack_exports__语法来导出相关的对象或者方法。
基于 esm 规范实现的 hmr 不需要单独再去实现一套模块的系统,因此在整个流程当中比较重要的一个点就是如何去实现模块之间的依赖关系,hmr 的更新也是基于模块之间的依赖关系来进行工作的。
src/node/server/serverPluginHmr.ts
插件内部初始化一个 Websocket server;
watcher.on('change')绑定监听文件改动监听事件;
watcher.on('change', file => {
if (!(file.endsWith('.vue') || isCssRequest(file))) {
// everything except plain .css are considered HMR dependencies.
// plain css has its own HMR logic in ./serverPluginCss.ts.
handleJSReload()
}
})获取这个文件的所有 importers,初始化 hmrBoundaries,dirtyFiles;
walkImportChain 收集所有的 hmrBoundaries,dirtyFiles 以及判断 hasDeadEnd(这里的 hasDeadEnd 其实就是看依赖的模块间(除了 vue 文件外,可以理解为 vue 自动部署了相关 hmr 代码)是否部署了 import.meta.hot API);
如果 hasDeadEnd 则需要进行full-reload级别的更新;否则还是进行模块级别的热更新;
...
if (hasDeadEnd) {
send({
type: 'full-reload',
path: publicPath
})
console.log(chalk.green(`[vite] `) + `page reloaded.`)
} else {
const boundaries = [...hmrBoundaries]
const file =
boundaries.length === 1 ? boundaries[0] : `${boundaries.length} files`
console.log(
chalk.green(`[vite:hmr] `) +
`${file} hot updated due to change in ${relativeFile}.`
)
send({
type: 'multi',
updates: boundaries.map((boundary) => {
return {
type: boundary.endsWith('vue') ? 'vue-reload' : 'js-update', // 如果是 vue 文件那么是 vue-reload 类型的更新,如果是 js 文件,那么是 js-update 类型的更新
path: boundary,
changeSrcPath: publicPath,
timestamp
}
})
})
}
...src/node/server/serverPluginVue.ts
对于请求路径为 *.vue 文件的处理插件。
watcher.on('change')绑定监听文件改动的监听事件,当 *.vue 文件发生了变化后调用handleVueReload(file)方法进行处理;watcher.on('change', file => {
if (file.endsWith('.vue')) {
handleVueReload(file)
}
})parseSFC 并和之前编译缓存的 vue sfc 进行 diff;
如果 script block 的部分发生了变化,那么直接 sendReload(),script block 部分的 diff 也是优先级最高的;
const sendReload = () => {
send({
type: 'vue-reload',
path: publicPath,
changeSrcPath: publicPath,
timestamp
})
console.log(
chalk.green(`[vite:hmr] `) +
`${path.relative(root, filePath)} updated. (reload)`
)
}如果是 template block 的部分发生了变化,将needRerender标志位置为 true
如果css module发生了变化,或css variable发生了变化,或 css scope属性发生变化,那么直接 sendReload(),并退出当前的 handleVueReload 的流程;
如果仅是 style 样式的内容发生了变化,那么会通过 wss 发送 style-update 类型的更新消息
// only need to update styles if not reloading, since reload forces
// style updates as well.
nextStyles.forEach((_, i) => {
if (!prevStyles[i] || !isEqualBlock(prevStyles[i], nextStyles[i])) {
didUpdateStyle = true
const path = `${publicPath}?type=style&index=${i}`
send({
type: 'style-update',
path,
changeSrcPath: path,
timestamp
})
}
})
// stale styles always need to be removed
prevStyles.slice(nextStyles.length).forEach((_, i) => {
didUpdateStyle = true
send({
type: 'style-remove',
path: publicPath,
id: `${styleId}-${i + nextStyles.length}`
})
})vue-reload的操作流程。src/node/server/serverPluginModuleRewrite.ts
js module 路径的解析以及 module graph 依赖的生成:建立 importer 和 importee 之间的依赖关系。
export const moduleRewritePlugin: ServerPlugin = ({
root,
app,
watcher,
resolver
}) => {
app.use(async (ctx, next) => {
...
const importer = removeUnRelatedHmrQuery(
resolver.normalizePublicPath(ctx.url)
)
ctx.body = rewriteImports(
root,
content!,
importer,
resolver,
ctx.query.t
)
...
})
}es-module-lexer解析代码当中被引入的模块 imports;...
const prevImportees = importeeMap.get(importer)
const currentImportees = new Set<string>()
importeeMap.set(importer, currentImportees)
...
const importee = cleanUrl(resolved)
if (
importee !== importer &&
// no need to track hmr client or module dependencies
importee !== clientPublicPath
) {
currentImportees.add(importee)
ensureMapEntry(importerMap, importee).add(importer)
}
...
// src/node/server/serverPluginHmr
export function ensureMapEntry(map: HMRStateMap, key: string): Set<string> {
let entry = map.get(key)
if (!entry) {
entry = new Set<string>()
map.set(key, entry)
}
return entry
}src/client/client.ts
被注入到浏览器当中的 hmr 运行时的代码。用以和 serverPluginHmr 生成的 wss 建立连接。同时用以接收 wss push 过来的不同类型的更新代码策略。
依赖关系的建立:Webpack 在 browser 运行时记录,vite 在服务侧编译时记录;
Dirty Module Check 的流程:Webpack 在 browser 运行时进行,vite 在文件发生变更后再服务侧编译环节即进行。
Module 更新:Webpack 直接替换本地缓存的模块(即删除掉)。而 vite 是直接请求新的模块内容并使用新的模块。
Webpack 编译流程前置,vite 编译流程后置且按需编译;
Webpack 使用 JSONP 请求新的编译生成的模块。vite 直接使用 ESM import 动态加载发生变更的模块内容。读取 export 导出的内容。
vite 对于 vue 文件变更的 hmr 做了定制化的处理。
Readable Stream是对数据源的一种抽象。它提供了从数据源获取数据并缓存,以及将数据提供给数据消费者的能力。
接下来分别通过Readable Stream的2种模式来学习下可读流是如何获取数据以及将数据提供给消费者的。

在flowing模式下,可读流自动从系统的底层读取数据,并通过EventEmitter接口的事件提供给消费者。如果不是开发者需要自己去实现可读流,大家可使用最为简单的readable.pipe()方法去消费数据。
接下来我们就通过一个简单的实例去具体分析下flowing模式下,可读流是如何工作的。
const { Readable } = require('stream')
let c = 97 - 1
// 实例化一个可读流
const rs = new Readable({
read () {
if (c >= 'z'.charCodeAt(0)) return rs.push(null)
setTimeout(() => {
// 向可读流中推送数据
rs.push(String.fromCharCode(++c))
}, 100)
}
})
// 将可读流的数据pipe到标准输出并打印出来
rs.pipe(process.stdout)
process.on('exit', () => {
console.error('\n_read() called ' + (c - 97) + ' times')
})首先我们先来看下Readable构造函数的实现:
function Readable(options) {
if (!(this instanceof Readable))
return new Readable(options);
// _readableState里面保存了关于可读流的不同阶段的状态值,下面会具体的分析
this._readableState = new ReadableState(options, this);
// legacy
this.readable = true;
if (options) {
// 重写内部的_read方法,用以自定义从数据源获取数据
if (typeof options.read === 'function')
this._read = options.read;
if (typeof options.destroy === 'function')
// 重写内部的_destory方法
this._destroy = options.destroy;
}
Stream.call(this);
}在我们创建可读流实例时,传入了一个read方法,用以自定义从数据源获取数据的方法,如果是开发者需要自己去实现可读流,那么这个方法一定需要去自定义,否则在程序的运行过程中会报错。ReadableState构造函数中定义了很多关于可读流的不同阶段的状态值:
function ReadableState(options, stream) {
options = options || {};
...
// object stream flag. Used to make read(n) ignore n and to
// make all the buffer merging and length checks go away
// 是否为对象模式,如果是的话,那么从缓冲区获得的数据为对象
this.objectMode = !!options.objectMode;
if (isDuplex)
this.objectMode = this.objectMode || !!options.readableObjectMode;
// the point at which it stops calling _read() to fill the buffer
// Note: 0 is a valid value, means "don't call _read preemptively ever"
// 高水位线,一旦buffer缓冲区的数据量大于hwm时,就会停止调用从数据源再获取数据
var hwm = options.highWaterMark;
var readableHwm = options.readableHighWaterMark;
var defaultHwm = this.objectMode ? 16 : 16 * 1024; // 默认值
if (hwm || hwm === 0)
this.highWaterMark = hwm;
else if (isDuplex && (readableHwm || readableHwm === 0))
this.highWaterMark = readableHwm;
else
this.highWaterMark = defaultHwm;
// cast to ints.
this.highWaterMark = Math.floor(this.highWaterMark);
// A linked list is used to store data chunks instead of an array because the
// linked list can remove elements from the beginning faster than
// array.shift()
// readable可读流内部的缓冲区
this.buffer = new BufferList();
// 缓冲区数据长度
this.length = 0;
this.pipes = null;
this.pipesCount = 0;
// flowing模式的初始值
this.flowing = null;
// 是否已将源数据全部读取完毕
this.ended = false;
// 是否触发了end事件
this.endEmitted = false;
// 是否正在从源数据处读取数据到缓冲区
this.reading = false;
// a flag to be able to tell if the event 'readable'/'data' is emitted
// immediately, or on a later tick. We set this to true at first, because
// any actions that shouldn't happen until "later" should generally also
// not happen before the first read call.
this.sync = true;
// whenever we return null, then we set a flag to say
// that we're awaiting a 'readable' event emission.
this.needReadable = false;
this.emittedReadable = false;
this.readableListening = false;
this.resumeScheduled = false;
// has it been destroyed
this.destroyed = false;
// Crypto is kind of old and crusty. Historically, its default string
// encoding is 'binary' so we have to make this configurable.
// Everything else in the universe uses 'utf8', though.
// 编码方式
this.defaultEncoding = options.defaultEncoding || 'utf8';
// 在pipe管道当中正在等待drain事件的写入流
// the number of writers that are awaiting a drain event in .pipe()s
this.awaitDrain = 0;
// if true, a maybeReadMore has been scheduled
this.readingMore = false;
this.decoder = null;
this.encoding = null;
if (options.encoding) {
if (!StringDecoder)
StringDecoder = require('string_decoder').StringDecoder;
this.decoder = new StringDecoder(options.encoding);
this.encoding = options.encoding;
}
}在上面的例子中,当实例化一个可读流rs后,调用可读流实例的pipe方法。这正式开始了可读流在flowing模式下从数据源开始获取数据,以及process.stdout对数据的消费。
Readable.prototype.pipe = function (dest, pipeOpts) {
var src = this
var state = this._readableState
...
// 可读流实例监听data,可读流会从数据源获取数据,同时数据被传递到了消费者
src.on('data', ondata)
function ondata (chunk) {
...
var ret = dest.write(chunk)
...
}
...
}Node提供的可读流有3种方式可以将初始态flowing = null的可读流转化为flowing = true:
data事件stream.resume()方法stream.pipe()方法事实上这3种方式都回归到了一种方式上:strean.resume(),通过调用这个方法,将可读流的模式改变为flowing态。继续回到上面的例子当中,在调用了rs.pipe()方法后,实际上内部是调用了src.on('data', ondata)监听data事件,那么我们就来看下这个方法当中做了哪些工作。
Readable.prototype.on = function (ev, fn) {
...
// 监听data事件
if (ev === 'data') {
// 可读流一开始的flowing状态是null
// Start flowing on next tick if stream isn't explicitly paused
if (this._readableState.flowing !== false)
this.resume();
} else if (ev === 'readable') {
...
}
return res;
}可读流监听data事件,并调用resume方法:
Readable.prototype.resume = function() {
var state = this._readableState;
if (!state.flowing) {
debug('resume');
// 置为flowing状态
state.flowing = true;
resume(this, state);
}
return this;
};
function resume(stream, state) {
if (!state.resumeScheduled) {
state.resumeScheduled = true;
process.nextTick(resume_, stream, state);
}
}
function resume_(stream, state) {
if (!state.reading) {
debug('resume read 0');
// 开始从数据源中获取数据
stream.read(0);
}
state.resumeScheduled = false;
// 如果是flowing状态的话,那么将awaitDrain置为0
state.awaitDrain = 0;
stream.emit('resume');
flow(stream);
if (state.flowing && !state.reading)
stream.read(0);
}resume方法会判断这个可读流是否处于flowing模式下,同时在内部调用stream.read(0)开始从数据源中获取数据(其中stream.read()方法根据所接受到的参数会有不同的行为):
TODO: 这个地方可说明stream.read(size)方法接收到的不同的参数
Readable.prototype.read = function (n) {
...
if (n === 0 &&
state.needReadable &&
(state.length >= state.highWaterMark || state.ended)) {
debug('read: emitReadable', state.length, state.ended);
// 如果缓存中没有数据且处于end状态
if (state.length === 0 && state.ended)
// 流状态结束
endReadable(this);
else
// 触发readable事件
emitReadable(this);
return null;
}
...
// 从缓存中可以读取的数据
n = howMuchToRead(n, state);
// 判断是否应该从数据源中获取数据
// if we need a readable event, then we need to do some reading.
var doRead = state.needReadable;
debug('need readable', doRead);
// if we currently have less than the highWaterMark, then also read some
// 如果buffer的长度为0或者buffer的长度减去需要读取的数据的长度 < hwm 的时候,那么这个时候还需要继续读取数据
// state.length - n 即表示当前buffer已有的数据长度减去需要读取的数据长度后,如果还小于hwm话,那么doRead仍然置为true
if (state.length === 0 || state.length - n < state.highWaterMark) {
// 继续read数据
doRead = true;
debug('length less than watermark', doRead);
}
// however, if we've ended, then there's no point, and if we're already
// reading, then it's unnecessary.
// 如果数据已经读取完毕,或者处于正在读取的状态,那么doRead置为false表明不需要读取数据
if (state.ended || state.reading) {
doRead = false;
debug('reading or ended', doRead);
} else if (doRead) {
debug('do read');
state.reading = true;
state.sync = true;
// if the length is currently zero, then we *need* a readable event.
// 如果当前缓冲区的长度为0,首先将needReadable置为true,那么再当缓冲区有数据的时候就触发readable事件
if (state.length === 0)
state.needReadable = true;
// call internal read method
// 从数据源获取数据,可能是同步也可能是异步的状态,这个取决于自定义_read方法的内部实现,可参见study里面的示例代码
this._read(state.highWaterMark);
state.sync = false;
// If _read pushed data synchronously, then `reading` will be false,
// and we need to re-evaluate how much data we can return to the user.
// 如果_read方法是同步,那么reading字段将会为false。这个时候需要重新计算有多少数据需要重新返回给消费者
if (!state.reading)
n = howMuchToRead(nOrig, state);
}
// ret为输出给消费者的数据
var ret;
if (n > 0)
ret = fromList(n, state);
else
ret = null;
if (ret === null) {
state.needReadable = true;
n = 0;
} else {
state.length -= n;
}
if (state.length === 0) {
// If we have nothing in the buffer, then we want to know
// as soon as we *do* get something into the buffer.
if (!state.ended)
state.needReadable = true;
// If we tried to read() past the EOF, then emit end on the next tick.
if (nOrig !== n && state.ended)
endReadable(this);
}
// 只要从数据源获取的数据不为null,即未EOF时,那么每次读取数据都会触发data事件
if (ret !== null)
this.emit('data', ret);
return ret;
}这个时候可读流从数据源开始获取数据,调用this._read(state.highWaterMark)方法,对应着例子当中实现的read()方法:
const rs = new Readable({
read () {
if (c >= 'z'.charCodeAt(0)) return rs.push(null)
setTimeout(() => {
// 向可读流中推送数据
rs.push(String.fromCharCode(++c))
}, 100)
}
})在read方法当中有一个非常中的方法需要开发者自己去调用,就是stream.push方法,这个方法即完成从数据源获取数据,并供消费者去调用。
Readable.prototype.push = function (chunk, encoding) {
....
// 对从数据源拿到的数据做处理
return readableAddChunk(this, chunk, encoding, false, skipChunkCheck);
}
function readableAddChunk (stream, chunk, encoding, addToFront, skipChunkCheck) {
...
// 是否添加数据到头部
if (addToFront) {
// 如果不能在写入数据
if (state.endEmitted)
stream.emit('error',
new errors.Error('ERR_STREAM_UNSHIFT_AFTER_END_EVENT'));
else
addChunk(stream, state, chunk, true);
} else if (state.ended) { // 已经EOF,但是仍然还在推送数据,这个时候会报错
stream.emit('error', new errors.Error('ERR_STREAM_PUSH_AFTER_EOF'));
} else {
// 完成一次读取后,立即将reading的状态置为false
state.reading = false;
if (state.decoder && !encoding) {
chunk = state.decoder.write(chunk);
if (state.objectMode || chunk.length !== 0)
// 添加数据到尾部
addChunk(stream, state, chunk, false);
else
maybeReadMore(stream, state);
} else {
// 添加数据到尾部
addChunk(stream, state, chunk, false);
}
}
...
return needMoreData(state);
}
// 根据stream的状态来对数据做处理
function addChunk(stream, state, chunk, addToFront) {
// flowing为readable stream的状态,length为buffer的长度
// flowing模式下且为异步读取数据的过程时,可读流的缓冲区并不保存数据,而是直接获取数据后触发data事件供消费者使用
if (state.flowing && state.length === 0 && !state.sync) {
// 对于flowing模式的Reabable,可读流自动从系统底层读取数据,直接触发data事件,且继续从数据源读取数据stream.read(0)
stream.emit('data', chunk);
// 继续从缓存池中获取数据
stream.read(0);
} else {
// update the buffer info.
// 数据的长度
state.length += state.objectMode ? 1 : chunk.length;
// 将数据添加到头部
if (addToFront)
state.buffer.unshift(chunk);
else
// 将数据添加到尾部
state.buffer.push(chunk);
// 触发readable事件,即通知缓存当中现在有数据可读
if (state.needReadable)
emitReadable(stream);
}
maybeReadMore(stream, state);
}在addChunk方法中完成对数据的处理,这里需要注意的就是,在flowing态下,数据被消耗的途径可能还不一样:
这2种情况到底使用哪一种还要看开发者的是同步还是异步的去调用push方法,对应着state.sync的状态值。
当push方法被异步调用时,即state.sync为false:这个时候对于从数据源获取到的数据是直接通过触发data事件以供消费者来使用,而不用存放到缓冲区。然后调用stream.read(0)方法重复读取数据并供消费者使用。
当push方法是同步时,即state.sync为true:这个时候从数据源获取数据后,就不是直接通过触发data事件来供消费者直接使用,而是首先上数据缓冲到可读流的缓冲区。这个时候你看代码可能会疑惑,将数据缓存起来后,那么在flowing模式下,是如何流动起来的呢?事实上在一开始调用resume_方法时:
function resume_() {
...
//
flow(stream);
if (state.flowing && !state.reading)
stream.read(0); // 继续从数据源获取数据
}
function flow(stream) {
...
// 如果处理flowing状态,那么调用stream.read()方法用以从stream的缓冲区中获取数据并供消费者来使用
while (state.flowing && stream.read() !== null);
}在flow方法内部调用stream.read()方法取出可读流缓冲区的数据供消费者使用,同时继续调用stream.read(0)来继续从数据源获取数据。
以上就是在flowing模式下,可读流是如何完成从数据源获取数据并提供给消费者使用的大致流程。
在pasued模式下,消费者如果要获取数据需要手动调用stream.read()方法去获取数据。
举个例子:
const { Readable } = require('stream')
let c = 97 - 1
const rs = new Readable({
highWaterMark: 3,
read () {
if (c >= 'f'.charCodeAt(0)) return rs.push(null)
setTimeout(() => {
rs.push(String.fromCharCode(++c))
}, 1000)
}
})
rs.setEncoding('utf8')
rs.on('readable', () => {
// console.log(rs._readableState.length)
console.log('get the data from readable: ', rs.read())
})通过监听readable事件,开始出发可读流从数据源获取数据。
Readable.prototype.on = function (env) {
if (env === 'data') {
...
} else if (env === 'readable') {
// 监听readable事件
const state = this._readableState;
if (!state.endEmitted && !state.readableListening) {
state.readableListening = state.needReadable = true;
state.emittedReadable = false;
if (!state.reading) {
process.nextTick(nReadingNextTick, this);
} else if (state.length) {
emitReadable(this);
}
}
}
}
function nReadingNextTick(self) {
debug('readable nexttick read 0');
// 开始从数据源获取数据
self.read(0);
}在nReadingNextTick当中调用self.read(0)方法后,后面的流程和上面分析的flowing模式的可读流从数据源获取数据的流程相似,最后都要调用addChunk方法,将数据获取到后推入可读流的缓冲区:
function addChunk(stream, state, chunk, addToFront) {
if (state.flowing && state.length === 0 && !state.sync) {
...
} else {
// update the buffer info.
// 数据的长度
state.length += state.objectMode ? 1 : chunk.length;
// 将数据添加到头部
if (addToFront)
state.buffer.unshift(chunk);
else
// 将数据添加到尾部
state.buffer.push(chunk);
// 触发readable事件,即通知缓存当中现在有数据可读
if (state.needReadable)
emitReadable(stream);
}
maybeReadMore(stream, state);
}一旦有数据被加入到了缓冲区,且needReadable(这个字段表示是否需要触发readable事件用以通知消费者来消费数据)为true,这个时候会触发readable告诉消费者有新的数据被push进了可读流的缓冲区。此外还会调用maybeReadMore方法,异步的从数据源获取更多的数据:
function maybeReadMore(stream, state) {
if (!state.readingMore) {
state.readingMore = true;
process.nextTick(maybeReadMore_, stream, state);
}
}
function maybeReadMore_(stream, state) {
var len = state.length;
// 在非flowing的模式下,且缓冲区的数据长度小于hwm
while (!state.reading && !state.flowing && !state.ended &&
state.length < state.highWaterMark) {
debug('maybeReadMore read 0');
stream.read(0);
// 获取不到数据后
if (len === state.length)
// didn't get any data, stop spinning.
break;
else
len = state.length;
}
state.readingMore = false;
}每当可读流有新的数据被推进缓冲区,触发readable事件后,消费者通过调用stream.read()方法来从可读流中获取数据。
当数据消费消费数据的速度慢于可写流提供给消费者的数据后会产生背压。
还是通过pipe管道来看:
Readable.prototype.pipe = function () {
...
// 监听drain事件
var ondrain = pipeOnDrain(src);
dest.on('drain', ondrain);
...
src.on('data', ondata)
function ondata () {
increasedAwaitDrain = false;
// 向writable中写入数据
var ret = dest.write(chunk);
if (false === ret && !increasedAwaitDrain) {
...
src.pause();
}
}
...
}
function pipeOnDrain(src) {
return function() {
var state = src._readableState;
debug('pipeOnDrain', state.awaitDrain);
// 减少pipes中awaitDrain的数量
if (state.awaitDrain)
state.awaitDrain--;
// 如果awaitDrain的数量为0,且readable上绑定了data事件时(EE.listenerCount返回绑定的事件回调数量)
if (state.awaitDrain === 0 && EE.listenerCount(src, 'data')) {
// 重新开启flowing模式
state.flowing = true;
flow(src);
}
};
}当dest.write(chunk)返回false的时候,即代表可读流给可写流提供的数据过快,这个时候调用src.pause方法,暂停flowing状态,同步也暂停可写流从数据源获取数据以及向可写流输入数据。这个时候只有当可写流触发drain事件时,会调用ondrain来恢复flowing,同时可读流继续向可写流输入数据。关于可写流的背压可参见关于Writable_stream的源码分析。
以上就是通过可读流的2种模式分析了下可读流的内部工作机制。当然还有一些细节处大家有兴趣的话可以阅读相关的源码。
在日常的开发过程当中,slot 插槽应该是用的较多的一个功能。Vue 的 slot 插槽可以让我们非常灵活的去完成对组件的拓展功能。接下来我们可以通过源码来看下 Vue 的 slot 插槽是如何去实现的。
Vue 提供了2种插槽类型:
首先来看一个简单的例子:
<div id="app">
<my-component>
<template name="demo">
<p>this is demo slot</p>
</template>
</my-component>
</div>
Vue.component('myComponent', {
template: '<div>this is my component <slot name="demo"></slot></div>'
})定义了一个 my-component 全局组件,这个组件内部包含了一个名字为 demo 的插槽。当页面开始渲染时,首先完成模板的编译功能,生成对应的 render 函数:
(function anonymous() {
with (this) {
return _c('div', {
attrs: {
"id": "app"
}
}, [_c('my-component', [_c('template', {
slot: "demo"
}, [_c('div', [_v("this is demo slot")])])], 2)], 1)
}
}
)并由这个 render 函数生成对应的 VNode,其中在生成自定义组件 my-component 的时候,有其对应的children VNode,即在模板当中的 template 节点。最终在生成的 my-component 的 VNode当中,在 componentOptions 属性当中存储了 VNode 子节点的信息。
function createComponent(
Ctor,
data,
context,
children,
tag
) {
...
var vnode = new VNode(
("vue-component-" + (Ctor.cid) + (name ? ("-" + name) : '')),
data, undefined, undefined, undefined, context,
{ Ctor: Ctor, propsData: propsData, listeners: listeners, tag: tag, children: children }, // VNode 构造函数接受的第7个参数为 componentOptions 即保存了有关 VNode 进行实例化成 Vue 实例所需要的信息
asyncFactory
);
...
}当整个 VNode 生成完毕后,开始递归将 VNode 渲染成真实的 DOM 节点,并挂载至文档对象中。在将 my-component 的 VNode 进行渲染的过程中:
function initRender(vm) {
...
var options = vm.$options;
var parentVnode = vm.$vnode = options._parentVnode; // the placeholder node in parent tree
var renderContext = parentVnode && parentVnode.context;
vm.$slots = resolveSlots(options._renderChildren, renderContext);
...
}
function resolveSlots (
children,
context
) {
var slots = {};
if (!children) {
return slots
}
for (var i = 0, l = children.length; i < l; i++) {
var child = children[i];
var data = child.data;
// remove slot attribute if the node is resolved as a Vue slot node
if (data && data.attrs && data.attrs.slot) {
delete data.attrs.slot;
}
// named slots should only be respected if the vnode was rendered in the
// same context.
if ((child.context === context || child.fnContext === context) &&
data && data.slot != null
) {
var name = data.slot; // 获取 slot 的名
var slot = (slots[name] || (slots[name] = []));
if (child.tag === 'template') { // 如果 tag 是 template 的 slot,那么就会取 template 的 children 作为 slot 的实际内容
slot.push.apply(slot, child.children || []);
} else {
slot.push(child);
}
} else {
// 设置 slots 的默认名为 default
(slots.default || (slots.default = [])).push(child);
}
}
// ignore slots that contains only whitespace
for (var name$1 in slots) {
if (slots[name$1].every(isWhitespace)) {
delete slots[name$1];
}
}
return slots
}在 initRender 函数当中,首先从 vm 实例上获取这个自定义组件模板当中嵌入的子节点(options._renderChildren),然后通过 resolveSlots 方法获取子节点对应的 slot,其中会根据这个 slot 是否有单独定义插槽名返回不同的插槽内容,比如说例子当中提供的为具名 demo 的插槽,所以最终返回的为具名插槽:
{
demo: [VNode]
}这里如果为非具名的插槽,那么会默认返回:
{
default: [VNode]
}同时在模板当中定义的 template 的标签,最终不会渲染到真实的 DOM 节点当中,而是取其子节点进行渲染。当执行完 initRender 方法后,vue 实例上已经有相关 slot 对应的节点信息,接下来开始完成 my-component 的渲染工作。
首先完成对应 my-component 的模板的编译工作,并生成对应的 render 函数:
(function anonymous() {
with (this) {
return _c('div', {
on: {
"click": test
}
}, [_v("this is my component "), _t("demo")], 2)
}
}
)render 函数执行后生成对应的 VNode,其中 _t("demo") 方法即完成 slot 的渲染工作:
// 获取 slot
function renderSlot (
name,
fallback,
props,
bindObject
) {
// 首先获取scopedSlot
var scopedSlotFn = this.$scopedSlots[name];
var nodes;
if (scopedSlotFn) { // scoped slot
props = props || {};
if (bindObject) {
if ("development" !== 'production' && !isObject(bindObject)) {
warn(
'slot v-bind without argument expects an Object',
this
);
}
props = extend(extend({}, bindObject), props);
}
nodes = scopedSlotFn(props) || fallback;
} else {
var slotNodes = this.$slots[name];
// warn duplicate slot usage
if (slotNodes) {
if ("development" !== 'production' && slotNodes._rendered) {
warn(
"Duplicate presence of slot \"" + name + "\" found in the same render tree " +
"- this will likely cause render errors.",
this
);
}
slotNodes._rendered = true;
}
nodes = slotNodes || fallback;
}
var target = props && props.slot;
if (target) {
return this.$createElement('template', { slot: target }, nodes)
} else {
return nodes
}
}在 renderSlot 方法中首先判断是否为 scopedSlot,如果不是那么便获取 vue 实例上 $slots 所对应的具名 slot 的 VNode 并返回。后面的流程便是走正常的组件渲染的过程。不过需要注意的是这里获取到的 VNode 实际上在父组件的作用域当中就已经生成好了,即 slot 的作用域属于父组件。
有时候我们希望插槽能在子组件的作用域中进行编译,这样自定义组件能获得更多的拓展功能。在讲作用域插槽前还是先看一个作用域插槽的相关例子:
<div id="app">
<my-component>
<template name="demo" slot-scope="slotProps">
<p>this is demo slot {{ slotProps.message }}</p>
</template>
</my-component>
</div>
Vue.component('myComponent', {
template: '<div>this is my component <slot name="demo" :message="message"></slot></div>',
data() {
return {
message: 'slot-demo'
}
}
})在 my-component 组件当中传递了一个 message 属性进去,然后在 slot 当中通过 slotProps.message 去获取从父组件传递到插槽内部的属性值。
首先在模板编译成 render 函数的生成 VNode 的过程当中:
(function anonymous() {
with (this) {
return _c('div', {
attrs: {
"id": "app"
}
}, [_c('my-component', {
scopedSlots: _u([{
key: "demo",
fn: function(slotProps) {
return [_c('div', [_v("this is demo slot " + _s(slotProps.message))])]
}
}])
})], 1)
}
}
)作用域插槽在模板的编译过程当中,并非直接编译成生成 VNode,并挂载至自定义组件 my-component 的 children 当中,而是缓存至 my-component 的 data.scopedSlots 属性中:
function resolveScopedSlots (
fns, // see flow/vnode
res
) {
res = res || {};
for (var i = 0; i < fns.length; i++) {
if (Array.isArray(fns[i])) {
resolveScopedSlots(fns[i], res);
} else {
res[fns[i].key] = fns[i].fn;
}
}
return res
}这个时候 slot 的 VNode 并没有生成,而是被一个函数包裹起来,缓存在 scopedSlots 属性上。接下来进行 my-component 组件的渲染,完成模板编译成 render 函数:
(function anonymous() {
with (this) {
return _c('div', {
on: {
"click": test
}
}, [_v("this is my component"), _t("demo", null, {
message: message
})], 2)
}
}
)调用 _t(即 renderSlot)方法来完成对具名的作用域插槽的渲染,这里需要注意的是传入了在 my-component 作用域当中定义的 message,再回到上面的 renderSlot 方法,在作用域插槽生成 VNode 的过程当中,即接收来自父组件传入的数据,所以在作用域插槽当中能通过 slotProps.message 访问到父组件上定义的 message 属性的值。当作用域插槽在父组件作用域内完成 VNode 的生成后,接下来仍然就是组件的递归渲染了,在这里就不赘述了。
以上通过源码分析了解了关于普通插槽和作用域插槽的不同在于,普通插槽是在自定义组件的父组件编译和生成 VNode 的时候便直接生成了自身的 VNode,因此其作用域处于自定义组件的父组件当中,而作用域插槽在自定义组件的父组件编译和生成 VNode 的时候并没有直接生成自身的 VNode,而是作为自定义组件 data.scopedSlots 属性缓存起来。当自定义组件自身开始编译渲染的时候,这时会取出对应的作用域插槽函数并执行生成对应的 VNode,这个时候所处的作用域为自定义组件内,因为作用域插槽可以获取自定义组件传递进来的数据。
最近将内部测试框架的底层库从mocha迁移到了AVA,迁移的原因之一是因为AVA提供了更好的流程控制。
我们从一个例子开始入手:
有A,B,C,D4个case,我要实现A -->> B -->> (C | D),A最先执行,B等待A执行完再执行,最后是(C | D)并发执行,使用ava提供的API来完成case就是:
const ava = require('ava')
ava.serial('A', async () => {
// do something
})
ava.serial('B', async () => {
// do something
})
ava('C', async () => {
// do something
})
ava('D', async () => {
// do something
})接下来我们就来具体看下AVA内部是如何实现流程控制的:
在AVA内实现了一个Sequence类:
class Sequence {
constructor (runnables) {
this.runnables = runnables
}
run() {
// do something
}
}这个Sequence类可以理解成集合的概念,这个集合内部包含的每一个元素可以是由一个case组成,也可以是由多个case组成。这个类的实例当中runnables属性(数组)保存了需要串行执行的case或case组。一个case可以当做一个组(runnables),多个case也可以当做一组,AVA用Sequence这个类来保证在runnables中保存的不同元素的顺序执行。
顺序执行了解后,我们再看下AVA内部实现的另外一个控制case并行执行的类:Concurrent:
class Concurrent {
constructor (runnables) {
this.runnables = runnables
}
run () {
// do something
}
}可以将Concurrent可以理解为组的概念,实例当中的runnables属性(数组)保存了这个组中所有待执行的case。这个Concurrent和上面提到的Sequence组都部署了run方法,用以runnables的执行,不同的地方在于,这个组内的case都是并行执行的。
具体到我们提供的实例当中:A -->> B -->> (C | D),AVA是如何从这2个类来实现他们之间的按序执行的呢?
在你定义case的时候:
ava.serial('A', async () => {
// do something
})
ava.serial('B', async () => {
// do something
})
ava('C', async () => {
// do something
})
ava('D', async () => {
// do something
})在ava内部便会维护一个serial数组用以保存顺序执行的case,concurrent数组用以保存并行执行的case:
const serial = ['A', 'B'];
const concurrent = ['C', 'D']然后用这2个数组,分别实例化一个Sequence和Concurrent实例:
const serialTests = new Sequence(serial)
const concurrentTests = new Concurrent(concurrent)这样保证了serialTests内部的case是顺序执行的,concurrentTests内部的case是并行执行的。但是如何保证这2个实例(serialTests和concurrentTests)之间的顺序执行呢?即serialTests内部case顺序执行完后,再进行concurrentTests的并行执行。
同样是使用Sequence这个类,实例化一个Sequence实例:
const allTests = new Sequence([serialTests, concurrentTests])之前我们就提到过Sequence实例的runnables属性中就维护了串行执行的case,所以在这里的具体体现就是,serialTests和concurrentTests之间是串行执行的,这也对应着:A -->> B -->> (C | D)。
接下来,我们就具体看下对应具体的流程实现:
allTests是所有这些case的集合,Sequence类上部署了run方法,因此调用:
allTests.run()开始case的执行。在Sequence类的run方法当中:
class Sequence {
constructor (runnables) {
this.runnables = runnables
}
run () {
// 首先获取runnables的迭代器对象,runnables数组保存了顺序执行的case
const iterator = this.runnables[Symbol.iterator]()
let activeRunnable
// 定义runNext方法,主要是用于保证case执行的顺序
// 因为ava支持同步和异步的case,这里也着重分析下异步case的执行顺序
const runNext = () => {
// 每次调用runNext方法都初始化一个新变量,用以保存异步case返回的promise
let promise
// 通过迭代器指针去遍历需要串行执行的case
for (let next = iterator.next(); !next.done; next = iterator.next()) {
// activeRunnable即每一个case或者是case的集合
activeRunnable = next.value
// 调用case的run方法,或者case集合的run方法,如果activeRunnable是一个case,那么就会执行这个case,而如果是case集合,调用run方法后,还是对应于sequence的run方法
// 因此在调用allTests.run()的时候,第一个activeRunnable就是'A',‘B’2个case的集合(sequence实例)。
const passedOrPromise = activeRunnable.run()
// passedOrPromise如果返回为false,即代表这个同步的case执行失败
if (!passedOrPromise) {
// do something
} else if (passedOrPromise !== true) { // !!!注意这里,如果passedOrPromise是个promise,那么会调用break来跳出这个for循环,进行到下面的步骤,这也是sequence类保证case顺序执行的关键。
promise = passedOrPromise
break;
}
}
if (!promise) {
return this.finish()
}
// !!!通过then方法,保证上一个promise被resolve后(即case执行完后),再进行后面的步骤,如果then接受passed参数为真,那么继续调用runNext()方法。再次调用runNext方法后,通过迭代器访问的数组:iterator迭代器的内部指针就不会从这个数组的一开始的起始位置开始访问,而是从上一次for循环结束的地方开始。这样也就保证了异步case的顺序执行
return promise.then(passed => {
if (!passed) {
// do something
}
return runNext()
})
}
return runNext()
}
}具体到我们提供的例子当中:
allTests这个Sequence实例的runnables属性保存了一个Sequence实例(A和B)和一个Concurrent实例(C和D)。
在调用allTests.run()后,在对allTesets的runnables的迭代器对象进行遍历的时候,首先调用包含A和B的Sequence实例的run方法,在run内部递归调用runNext方法,用以确保异步case的顺序执行。
具体的实现主要还是使用了Promise迭代链来完成异步任务的顺序执行:每次进行异步case时,这个异步的case会返回一个promise,这个时候停止迭代器对象的遍历,而是通过在promise的then方法中递归调用runNext(),来保证顺序执行。
return promise.then(passed => {
if (!passed) {
// do something
}
return runNext()
})当A和B组成的Sequence执行完成后,才会继续执行由C和D组成的Conccurent,接下来我们看下并发执行case的内部实现:同样在Concurrent类上也部署了run方法,用以开始需要并发执行的case:
class Concurrent {
constructor(runnables, bail) {
if (!Array.isArray(runnables)) {
throw new TypeError('Expected an array of runnables');
}
this.runnables = runnables;
}
run () {
// 所有的case是否通过
let allPassed = true;
let pending;
let rejectPending;
let resolvePending;
// 维护一个promise数组
const allPromises = [];
const handlePromise = promise => {
// 初始化一个pending的promise
if (!pending) {
pending = new Promise((resolve, reject) => {
rejectPending = reject;
resolvePending = resolve;
});
}
// 如果每个case都返回的是一个promise,那么首先调用then方法添加对于这个promise被resolve或者reject的处理函数,(这个添加被reject的处理,主要是用于下面Promise.all方法来处理所有被resolve的case)同时将这个promise推入到allPromises数组当中
allPromises.push(promise.then(passed => {
if (!passed) {
allPassed = false;
if (this.bail) {
// Stop if the test failed and bail mode is on.
resolvePending();
}
}
}, rejectPending));
};
// 通过for循环遍历runnables中保存的case。
for (const runnable of this.runnables) {
// 调用每个case的run方法
const passedOrPromise = runnable.run();
// 如果是同步的case,且执行失败了
if (!passedOrPromise) {
if (this.bail) {
// Stop if the test failed and bail mode is on.
return false;
}
allPassed = false;
} else if (passedOrPromise !== true) { // !!!如果返回的是一个promise
handlePromise(passedOrPromise);
}
}
if (pending) {
// 使用Promise.all去处理allPromises当中的promise。当所有的promise被resolve后才会调用resolvePending,因为resolvePending对应于pending这个promise的resolve方法,也就是pending这个promise也被resolve,最后调用pending的then方法中添加的对于promise被resolve的方法。
Promise.all(allPromises).then(resolvePending);
// 返回一个处于pending态的promise,但是它的then方法中添加了这个promise被resolve后的处理函数,即返回allPassed
return pending.then(() => allPassed);
}
// 如果是同步的测试
return allPassed;
}
}
}具体到我们的例子当中:Concurrent实例的runnables属性中保存了C和D2个case,调用实例的run方法后,C和D2个case即开始并发执行,不同于Sequence内部通过iterator遍历器来实现的case的顺序执行,Concurrent内部直接只用for循环来启动case的执行,然后通过维护一个promise数组,并调用Promise.all来处理promise数组的状态。
以上就是通过一个简单的例子介绍了AVA内部的流程控制模型。简单的总结下:
在AVA内部使用Promise来进行整个的流程控制(这里指的异步的case)。
串行:
Sequence类来保证case的串行执行,在需要串行运行的case当中,调用Sequence实例的runNext方法开始case的执行,通过获取case数组的iterator对象来手动对case(或case的集合)进行遍历执行,因为每个异步的case内部都返回了一个promise,这个时候会跳出对iterator的遍历,通过在这个promise的then方法中递归调用runNext方法,这样就保证了case的串行执行。
并行:
Concurrent类来保证case的并行执行,遇到需要并行运行的case时,同样是使用for循环,但是不是通过获取数组iterator迭代器对象去手动遍历,而是并发去执行,同时通过一个数组去收集这些并发执行的case返回的promise,最后通过Promise.all方法去处理这些未被resolve的promise,当然这里面也有一些小技巧,我在上面的分析中也指出了,这里不再赘述。
关于文中提到的Promise进行异步流程控制具体的应用,可以看下这2篇文章:
其中exec可用于在指定的shell当中执行命令。不同参数间使用空格隔开,可用于复杂的命令。
const { exec } = require('child_process')
exec('cat *.js bad_file | wc -l')exec方法用于异步创建一个新的子进程,可以接受一个callback。
exec('cat *.js bad_file | wc -l', (err, stdout, stderr) => {
console.log(stdout)
})传给回调的stdout和stderr参数会包含子进程的stdout和stderr的输出。
child_process.execFile(file[, args][, options][, callback])const { execFile } = require('child_process')
execFile('node', ['--version'], (err, stdout, stderr) => {
console.log(stdout)
})不是直接衍生一个shell。而是指定的可执行的文件直接创建一个新的进程。
child_process.fork(modulePath[, args][, options])创建一个新的node子进程。调用该方法后返回一个子进程的对象。通过fork方法创建出来的子进程可以和父进程通过内置的ipc通道进行通讯。
衍生的 Node.js 子进程与两者之间建立的 IPC 通信信道的异常是独立于父进程的。 每个进程都有自己的内存,使用自己的 V8 实例。 由于需要额外的资源分配,因此不推荐衍生大量的 Node.js 进程。
其中在options的配置信息当中:
父子进程间stdin/stdout/stderr之间的通讯。
如果置为true,那么子进程的标准输入输出都会被导流到父进程中:
parent.js
const { fork } = require('child_process')
const fd = fork('./sub.js')
fd.stdout.on('data', data => console.log(data))
sub.js
console.log('this is sub process')一般在子进程中如果有stdin的时候,可将stdin直接导入到父进程中,这样可进行tty和shell的交互。
如果置为false,那么子进程的标准输入输出都会继承父进程的。
关于这个的配置见下文。
child_process.spawn(command[, args][, options])上面说到的exec,execFile和fork创建新的子进程都是基于这个方法进行的封装。
调用这个方法返回子进程对象。
其中通过fork方法和spawn创建新的子进程时,在配置选项中有关于stdio的�字段:
这个字段主要用于父子进程间的管道配置。默认情况下,子进程的 stdin、 stdout 和 stderr 会重定向到 ChildProcess 对象上相应的 subprocess.stdin、 subprocess.stdout 和 subprocess.stderr 流。 这等同于将 options.stdio 设为 ['pipe', 'pipe', 'pipe']。
pipe - 等同于 [pipe, pipe, pipe] (默认)ignore - 等同于 [ignore, ignore, ignore]inherit - 等同于 [process.stdin, process.stdout, process.stderr] 或 [0,1,2]其中inherit即继承父进程的标准输入输出(和父进程共享)。
const { spawn } = require('child_process');
// 子进程使用父进程的 stdios
spawn('prg', [], { stdio: 'inherit' });
// 衍生的子进程只共享 stderr
spawn('prg', [], { stdio: ['pipe', 'pipe', process.stderr] });
// 打开一个额外的 fd=4,用于与程序交互
spawn('prg', [], { stdio: ['pipe', null, null, null, 'pipe'] });options 的合并应该说是 Vue 生命周期当中非常重要的一环。Vue 的组件实例化都是通过调用对应的构造函数完成相关实例化的工作。而在组件真正由 VNode 实例化成 vue 组件之前有关组件的相关定义都是挂载在组件的构造函数的 options 属性上。
我们定义一个全局的组件:
Vue.component('myComponent', {
template:
'<div @click="test">this is my component<slot name="demo" :message="message"></slot></div>',
props: {
obj: Object
},
data() {
return {
message: 'demo-slot'
}
},
methods: {
test() {
this.$emit('test')
}
},
components: {
child: {
template: '<p>hello</p>'
}
}
})Vue.component方法内部实际上是调用的 Vue.extend 方法,在这个方法内部完成这个组件的 options 的初始化的工作:
Vue.extend = function (extendOptions) {
...
var Super = this;
var SuperId = Super.cid;
...
var Sub = function VueComponent (options) {
this._init(options);
};
Sub.options = mergeOptions(
Super.options,
extendOptions
);
...
return Sub
}这个方法接收 extendOptions 参数即为组件的定义,然后在方法内部调用 mergeOptions 方法(这个方法内部到底做了哪些工作后面会讲)去完成对于根 Vue 构造函数上的 options 属性的合并,并将合并后的 options 属性赋值给子组件的构造函数 options 属性。这样便完成了组件 options 属性初始化的工作。通过Vue.component方法定义的全局组件,会在根 Vue 实例的 options 属性上挂载这个全局组件的构造函数。这也是为什么定义的全局组件如果要在组件当中使用时,可直接在模板当中进行书写,而不用在配置项里面去注册声明(这块的解释后面会讲)。
当组件真正进行实例化(new Vue)的阶段时,这里要分情况讨论了,首先让我们来看下根组件进行实例化:
Vue.prototype._init = function(options) {
...
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
initInternalComponent(vm, options)
} else {
// 在vm实例上挂载的 $options
vm.$options = mergeOptions(
resolveConstructorOptions(vm.constructor), // 获取构造函数上的options
options || {},
vm
)
}
...
}这里通过判断options._isComponent属性是进行内部子组件的实例化还是根组件的实例化。当是根组件的实例化的时候进入else的流程,调用mergeOptions方法完成 options 合并之前,首先调用 resolveConstructorOptions 方法获取构造函数上的 options 配置(这里不讨论单独通过 Vue.extend 方法完成继承的情况)。因为没有继承关系,所以这个方法最终还是返回这个构造函数上的 options 配置。第二个参数为外部传入的 options 配置,第三个参数为这个 vm 实例。最终将得到的 options 配置赋值给 vm 实例的 $options 属性上,并由这个 $options 属性去接着完成 vm 实例化。
接下来我们看下mergeOptions方法内部到底做了些什么工作。
/**
* Merge two option objects into a new one.
* Core utility used in both instantiation and inheritance.
*/
// mergeOptions Anchor
function mergeOptions(parent, child, vm) {
{
checkComponents(child)
}
if (typeof child === 'function') {
child = child.options // 获取子组件构造函数上的 options 属性
}
// 将子child的props属性统一设置为Object-based的类型
normalizeProps(child, vm)
normalizeInject(child, vm) // inject 属性
normalizeDirectives(child) // directive 指令属性
var extendsFrom = child.extends // extends 继承
if (extendsFrom) {
parent = mergeOptions(parent, extendsFrom, vm)
}
if (child.mixins) {
// 混入
for (var i = 0, l = child.mixins.length; i < l; i++) {
parent = mergeOptions(parent, child.mixins[i], vm)
}
}
var options = {}
var key
// 遍历父 options 的 key 值,并完成不同类型的 mergeField 操作
for (key in parent) {
mergeField(key)
}
for (key in child) {
if (!hasOwn(parent, key)) {
mergeField(key)
}
}
function mergeField(key) {
var strat = strats[key] || defaultStrat
// 合并父组件和子组件上的各种定义属性
options[key] = strat(parent[key], child[key], vm, key)
}
return options
}首先遍历构造函数上的 options 的 key,执行 mergeField 方法,然后遍历实例化组件的过程中传入的 options 的 key,并执行 mergeField 方法。其中 mergeField 方法内部就是关于 options 当中各个字段预设的合并策略。
会调用 defaultStrat 方法进行默认的合并策略:
var defaultStrat = function(parentVal, childVal) {
return childVal === undefined ? parentVal : childVal
}关于 el 和 propsData 属性的合并还有一些限制就是:只允许通过new Vue(Vue 为根构造函数)这种形式去实例化一个 Vue 的实例。子组件的实例化过程当中是不允许传入这 2 个字段的。
在实例化非组件实例时,并没有直接返回合并后的 data 的值,返回而是一个 mergedInstanceDataFn 函数:
function mergedInstanceDataFn() {
// instance merge
var instanceData =
typeof childVal === 'function' ? childVal.call(vm, vm) : childVal
var defaultData =
typeof parentVal === 'function' ? parentVal.call(vm, vm) : parentVal
if (instanceData) {
return mergeData(instanceData, defaultData)
} else {
return defaultData
}
}当实例化的阶段进入 initState 时,才会实际执行这个 mergedInstanceDataFn 函数,且是在传入的 vm 实例的作用域下执行的。然后通过 mergeData 方法将需要继承的 data 和 实例化传入的 data 进行合并。
function mergeHook (
parentVal,
childVal
) {
return childVal
? parentVal
? parentVal.concat(childVal)
: Array.isArray(childVal)
? childVal
: [childVal]
: parentVal
}
LIFECYCLE_HOOKS.forEach(function (hook) {
strats[hook] = mergeHook;
});会将每个生命周期的钩子函数都置为一个数组。
function mergeAssets (
parentVal,
childVal,
vm,
key
) {
var res = Object.create(parentVal || null);
if (childVal) {
"development" !== 'production' && assertObjectType(key, childVal, vm);
// 对实例进行拓展,将子 assets 属性和父 assets 属性建立引用关系
return extend(res, childVal)
} else {
return res
}
}
// components, filter, directives 的合并策略,通过原型继承来合并
ASSET_TYPES.forEach(function (type) {
strats[type + 's'] = mergeAssets;
});有关这三者的合并策略是通过原型继承的方式去实现的。
strats.watch = function (
parentVal,
childVal,
vm,
key
) {
...
/* istanbul ignore if */
if (!childVal) { return Object.create(parentVal || null) }
{
assertObjectType(key, childVal, vm);
}
if (!parentVal) { return childVal }
var ret = {};
extend(ret, parentVal);
for (var key$1 in childVal) {
var parent = ret[key$1];
var child = childVal[key$1];
if (parent && !Array.isArray(parent)) {
parent = [parent];
}
ret[key$1] = parent
? parent.concat(child)
: Array.isArray(child) ? child : [child];
}
return ret
};如果实例没有 watch,那么直接通过原型继承的方式返回构造函数上的 watch,如果构造函数上没有 watch,且实例有 watch,那么就直接返回实例的 watch。当两者都有的时候,那么需要将每个 key 对应的 watch 转化为数组,且先执行被继承来的 watch 函数。
strats.props =
strats.methods =
strats.inject =
strats.computed = function (
parentVal,
childVal,
vm,
key
) {
if (childVal && "development" !== 'production') {
assertObjectType(key, childVal, vm);
}
if (!parentVal) { return childVal }
var ret = Object.create(null);
extend(ret, parentVal);
if (childVal) { extend(ret, childVal); }
return ret
};有关这四者的合并策略即:如果没有需要继承值,那么直接返回实例传入的值,否则通过覆盖的形式去完成值的合并的过程。
在 mergeOptions 方法里面有个地方没有提到,就是关于 mixins 混入。mixins 可以算做我们去实现 HOC 的一种常用的手段。一个组件可以接受一个 mixins 数组。mergeOptions 方法首先会遍历 mixins 数组,依次将每个 mixin 混入到构造函数的 options 属性上,然后再完成和实例中传入的 options 的合并。在 Vue 的根构造函数上也提供了一个全局的 mixin 的方法Vue.mixin。这个全局的 mixin 方法会在 Vue 的根构造函数的 options 配置选项上混入你所传入的配置选项。
组件在创建 VNode 的过程中:
function createComponent (
Ctor,
data,
context, // 限制作用域
children,
tag
) {
if (isUndef(Ctor)) {
return
}
// Vue 的根构造函数
var baseCtor = context.$options._base;
// plain options object: turn it into a constructor
// 即局部组件的注册
if (isObject(Ctor)) {
Ctor = baseCtor.extend(Ctor);
}
// if at this stage it's not a constructor or an async component factory,
// reject.
if (typeof Ctor !== 'function') {
{
warn(("Invalid Component definition: " + (String(Ctor))), context);
}
return
}
...
// return a placeholder vnode
var name = Ctor.options.name || tag;
// 子vnode的id使用vue-component及对应的id来进行标识
var vnode = new VNode(
("vue-component-" + (Ctor.cid) + (name ? ("-" + name) : '')),
data, undefined, undefined, undefined, context,
// 这个参数为 componentOptions,即用于创建 componentInstance 实例
{ Ctor: Ctor, propsData: propsData, listeners: listeners, tag: tag, children: children },
asyncFactory
);
...
return vnode
}创建 VNode 之前,首先通过baseCtor.extend(Ctor)方法获取这个局部组件的构造函数,在这个方法内部会完成构造函数的 options 和这个局部组件配置 options 选项的合并工作,并将 options 属性挂载至这个局部组件的构造函数上。当进入到 VNode 实例化的过程中:
function createComponentInstanceForVnode (
vnode, // we know it's MountedComponentVNode but flow doesn't
parent, // activeInstance in lifecycle state
parentElm,
refElm
) {
var options = {
_isComponent: true, // 实例化一个内部的component的标识
parent: parent,
_parentVnode: vnode,
_parentElm: parentElm || null,
_refElm: refElm || null
};
...
return new vnode.componentOptions.Ctor(options)
}这个时候会调用Vue.prototype._init方法开始子组件的实例化:
Vue.prototype._init = function(options) {
...
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
initInternalComponent(vm, options)
} else {
// 在vm实例上挂载的 $options
vm.$options = mergeOptions(
resolveConstructorOptions(vm.constructor), // 获取构造函数上的options
options || {},
vm
)
}
...
}这时便会调用initInternalComponent方法去完成子组件的 options 合并:
function initInternalComponent (vm, options) {
// 将 constructor 构造函数上绑定的 options 属性转到 vm.$options 上。即在 component 通过 Vue.extend 方法生成构造函数所生成的最终的 options
var opts = vm.$options = Object.create(vm.constructor.options);
// doing this because it's faster than dynamic enumeration(动态列举?).
var parentVnode = options._parentVnode;
opts.parent = options.parent;
opts._parentVnode = parentVnode; // 这里的 parentVnode 即为需要创建 VNode 对应的实例的 VNode。也是在这里通过 parentVnode 将 VNode 和 vm 进行关联起来的,之后在 vm 实例化的过程当中,会将 parentVNode 绑定到 vm.$vnode 上
opts._parentElm = options._parentElm;
opts._refElm = options._refElm;
// 在创建 VNode 的时候传进来的 componentOptions 属性, 参见创建 VNode 时所调用的构造函数
var vnodeComponentOptions = parentVnode.componentOptions;
opts.propsData = vnodeComponentOptions.propsData; // props属性
opts._parentListeners = vnodeComponentOptions.listeners; // 获取父component传递下来的listeners
opts._renderChildren = vnodeComponentOptions.children;
opts._componentTag = vnodeComponentOptions.tag;
if (options.render) {
opts.render = options.render;
opts.staticRenderFns = options.staticRenderFns;
}
}在这个方法内部,通过原型继承的方法完成子组件实例的 $options 配置的初始化的过程。同时根据传入的 options 配置项去完成 VNode 在最终渲染前的配置工作。
在 Vue 进行实例化之前,组件 options 配置选项的继承始终是通过实例的构造函数去完成,构造函数的 options 合并是完成组件实例化的先行任务。
其中组件的实例化和直接通过new Vue去完成的实例化的 options 合并过程有有些区别。组件的实例化之前,会首先在 Vue.extend 方法内部调用mergeOptions去完成构造函数 options 的合并,开始实例化后(Vue.prototype._init方法),调用initInternalComponent方法,通过继承的方法初始化实例的 $options 选项。
而通过new Vue的方式直接完成实例化时,是在实例化开始后,调用mergeOptions方法去初始化实例的 $options 配置选项。
v-model是Vue内部实现的一个指令。它所提供的基本功能是在一些表单元素上实现数据的双向绑定。基本的使用方法就是:
<div id="app">
<input v-model="val">
</div>
new Vue({
el: '#app',
data () {
return {
val: 'default val'
}
},
watch: {
val (newVal) {
console.log(newVal)
}
}
})页面初次渲染完成后,input输入框的值为default val,当你改变input输入框的值的时候,你会发现控制台也打印出了输入框当中新的值。接下来我们就来看下v-model是如何完成数据的双向绑定的。
首先第一步,在这个vue实例化开始后,首先将data属性数据变成响应式的数据。接下来完成页面的渲染工作的时候,首先编译html模板:
(function() {
with (this) {
return _c('div', {
attrs: {
"id": "app"
}
}, [_c('input', {
directives: [{
name: "model",
rawName: "v-model",
value: (val),
expression: "val"
}],
attrs: { // 最终绑定到input的type属性上
"type": "text"
},
domProps: { // 最终绑定到input的value属性上,设定input的value初始值
"value": (val)
},
on: { // 最终会给input元素添加的dom事件
"input": function($event) {
if ($event.target.composing)
return;
val = $event.target.value // 响应input事件,同时获取到输入到Input输入框当中的值,并修改val的值
}
}
})])
}
}
)接下来我们深入细节的看下整个绑定的过程,以及在页面当中修改input输入框中的值后,如何使得模型数据也发生变化。
示例当中是在input元素上绑定的v-model指令,它是属于built in elements,因此不同于自定义component创建VNode过程中还需要进行获取props属性,自定义事件,初始化钩子函数等,而attrs,domProps,on属性最终都会绑定到dom元素上。
当调用_c方法完成后,即VNode都已经生成完毕,开始将VNode渲染成真实的dom节点并挂载到document中去:
function mountComponent (
vm,
el,
hydrating
) {
...
updateComponent = function ()
// vm._render首先构建完成vnode
// 然后调用vm._update方法,更vnode挂载到真实的DOM节点上
vm._update(vm._render(), hydrating);
};
...
new Watcher(vm, updateComponent, noop, null, true /* isRenderWatcher */);
...
}在页面初始化的阶段:
function createElm (
vnode,
insertedVnodeQueue,
parentElm, // 父节点
refElm,
nested,
ownerArray,
index
) {
...
var data = vnode.data; // 描述VNode属性的数据
var children = vnode.children; // VNode的子节点
var tag = vnode.tag; // VNode标签
// 实例化自定义component vnode
if (createComponent(vnode, insertedVnodeQueue, parentElm, refElm)) {
return
}
...
vnode.elm = vnode.ns
? nodeOps.createElementNS(vnode.ns, tag)
: nodeOps.createElement(tag, vnode);
setScope(vnode);
/* istanbul ignore if */
{
// 挂载子节点,vnode为父级vnode
createChildren(vnode, children, insertedVnodeQueue);
// 触发内部的create钩子函数
if (isDef(data)) {
invokeCreateHooks(vnode, insertedVnodeQueue);
}
// 将vnode生成的dom节点插入到真实的dom节点当中
insert(parentElm, vnode.elm, refElm);
}
...
}// TODO: 递归如何描述
在渲染VNode过程当中,如果是自定义的component VNode,那么首先完成component的vm实例化,接下来递归的对子节点进行实例化
注意当子 VNode 全部渲染成真实的 dom 节点,并挂载到父节点后,开始调用invokeCreateHooks方法,触发dom节点create阶段所包含的钩子函数来完成对dom节点添加attrs,domProps,dom事件等:(具体的可参见 createPatchFunction 方法中对于 create 阶段所有的回调函数的初始化)
function invokeCreateHooks (vnode, insertedVnodeQueue) {
for (var i$1 = 0; i$1 < cbs.create.length; ++i$1) {
cbs.create[i$1](emptyNode, vnode);
}
i = vnode.data.hook; // Reuse variable
if (isDef(i)) {
if (isDef(i.create)) { i.create(emptyNode, vnode); }
if (isDef(i.insert)) { insertedVnodeQueue.push(vnode); }
}
}在这里我们只关心和v-model相关的domProps和dom事件的钩子函数,首先来看下更新domProps的钩子函数:
function updateDOMProps (oldVnode, vnode) {
if (isUndef(oldVnode.data.domProps) && isUndef(vnode.data.domProps)) {
return
}
var key, cur;
var elm = vnode.elm;
var oldProps = oldVnode.data.domProps || {};
var props = vnode.data.domProps || {};
// clone observed objects, as the user probably wants to mutate it
if (isDef(props.__ob__)) {
props = vnode.data.domProps = extend({}, props);
}
for (key in oldProps) {
if (isUndef(props[key])) {
elm[key] = '';
}
}
for (key in props) {
cur = props[key];
...
// 如果是input的value属性
if (key === 'value') {
// store value as _value as well since
// non-string values will be stringified
elm._value = cur;
// avoid resetting cursor position when value is the same
var strCur = isUndef(cur) ? '' : String(cur);
if (shouldUpdateValue(elm, strCur)) {
// 更新dom对应的value值
elm.value = strCur;
}
} else {
elm[key] = cur;
}
}
}在dom初次创建的过程中,通过updateDOMProps方法完成dom的value的初始化。
接下来看下是如何绑定dom事件的:
// 更新dom绑定的事件
function updateDOMListeners (oldVnode, vnode) {
if (isUndef(oldVnode.data.on) && isUndef(vnode.data.on)) {
return
}
var on = vnode.data.on || {};
var oldOn = oldVnode.data.on || {};
// 设置全局的dom target$1对象
target$1 = vnode.elm;
normalizeEvents(on);
updateListeners(on, oldOn, add$1, remove$2, vnode.context);
target$1 = undefined;
}
// 注意add$1方法,它完成了向dom target$1绑定事件的功能。相应的remove$2方法是将对应的事件从dom节点上删除
function add$1 (
event,
handler,
once$$1,
capture,
passive
) {
handler = withMacroTask(handler);
if (once$$1) { handler = createOnceHandler(handler, event, capture); }
target$1.addEventListener(
event,
handler,
supportsPassive
? { capture: capture, passive: passive }
: capture
);
}在本例当中,即向input节点绑定input事件:
input.addEventListener('input', function ($event) {
if ($event.target.composing)
return;
val = $event.target.value
})当改变input输入框的内容时,触发input事件执行对应的回调函数,这个时候便会改变响应式数据val的值,即调用val的setter方法。因为之前在创建 input 的 VNode 的时候,val 收集到了这个 VNode 对应的 render watcher。所以当 val 的 setter 被触发的时候,会让 input 对应的 render watcher 重新执行,这样也就会触发这个 dom 节点的 diff 和渲染的工作。
// 创建VNode环节
// 渲染的环节
// 绑定dom
// TODO: 总体的的概述
// 如何绑定/更新domProps
// 绑定原生的dom事件
// 和dom相关的attrs、domProps、原生的dom事件、style等,都是在将vnode渲染成真实的dom元素后,并关在到父dom节点后完成的。
由于小程序的双线程的架构设计,逻辑层和视图层之间需要桥接 native bridge。如果要完成视图层的更新,那么逻辑层需要调用 setData 方法,数据经由 native bridge,再到渲染层,这个工程流程为:
小程序逻辑层调用宿主环境的 setData 方法;
逻辑层执行 JSON.stringify 将待传输数据转换成字符串并拼接到特定的JS脚本,并通过evaluateJavascript 执行脚本将数据传输到渲染层;
渲染层接收到后, WebView JS 线程会对脚本进行编译,得到待更新数据后进入渲染队列等待 WebView 线程空闲时进行页面渲染;
WebView 线程开始执行渲染时,待更新数据会合并到视图层保留的原始 data 数据,并将新数据套用在WXML片段中得到新的虚拟节点树。经过新虚拟节点树与当前节点树的 diff 对比,将差异部分更新到UI视图。同时,将新的节点树替换旧节点树,用于下一次重渲染。
而 setData 作为逻辑层和视图层之间通讯的核心接口,那么对于这个接口的使用遵照一些准则将有助于性能方面的提升。
Mpx 在这个方面所做的工作之一就是基于数据路径的 diff。这也是官方所推荐的 setData 的方式。每次响应式数据发生了变化,调用 setData 方法的时候确保传递的数据都为 diff 过后的最小数据集,这样来减少 setData 传输的数据。
接下来我们就来看下这个优化手段的具体实现思路,首先还是从一个简单的 demo 来看:
<script>
import { createComponent } from '@mpxjs/core'
createComponent({
data: {
obj: {
a: {
c: 1,
d: 2
}
}
}
onShow() {
setTimeout(() => {
this.obj.a = {
c: 1,
d: 'd'
}
}, 200)
}
})
</script>在示例 demo 当中,声明了一个 obj 对象(这个对象里面的内容在模块当中被使用到了)。然后经过 200ms 后,手动修改 obj.a 的值,因为对于 c 字段来说它的值没有发生改变,而 d 字段发生了改变。因此在 setData 方法当中也应该只更新 obj.a.d 的值,即:
this.setData('obj.a.d', 'd')因为 mpx 是整体接管了小程序当中有关调用 setData 方法并驱动视图更新的机制。所以当你在改变某些数据的时候,mpx 会帮你完成数据的 diff 工作,以保证每次调用 setData 方法时,传入的是最小的更新数据集。
这里也简单的分析下 mpx 是如何去实现这样的功能的。在上文的编译构建阶段有分析到 mpx 生成的 Render Function,这个 Render Function 每次执行的时候会返回一个 renderData,而这个 renderData 即用以接下来进行 setData 驱动视图渲染的原始数据。renderData 的数据组织形式是模板当中使用到的数据路径作为 key 键值,对应的值使用一个数组组织,数组第一项为数据的访问路径(可获取到对应渲染数据),第二项为数据路径的第一个键值,例如在 demo 示例当中的 renderData 数据如下:
renderData['obj.a.c'] = [this.obj.a.c, 'obj']
renderData['obj.a.d'] = [this.obj.a.d, 'obj']当页面第一次渲染,或者是响应式输出发生变化的时候,Render Function 都会被执行一次用以获取最新的 renderData 来进行接下来的页面渲染过程。
// src/core/proxy.js
class MPXProxy {
...
renderWithData(rawRenderData) { // rawRenderData 即为 Render Function 执行后获取的初始化 renderData
const renderData = preprocessRenderData(rawRenderData) // renderData 数据的预处理
if (!this.miniRenderData) { // 最小数据渲染集,页面/组件初次渲染的时候使用 miniRenderData 进行渲染,初次渲染的时候是没有数据需要进行 diff 的
this.miniRenderData = {}
for (let key in renderData) { // 遍历数据访问路径
if (renderData.hasOwnProperty(key)) {
let item = renderData[key]
let data = item[0]
let firstKey = item[1] // 某个字段 path 的第一个 key 值
if (this.localKeys.indexOf(firstKey) > -1) {
this.miniRenderData[key] = diffAndCloneA(data).clone
}
}
}
this.doRender(this.miniRenderData)
} else { // 非初次渲染使用 processRenderData 进行数据的处理,主要是需要进行数据的 diff 取值工作,并更新 miniRenderData 的值
this.doRender(this.processRenderData(renderData))
}
}
processRenderData(renderData) {
let result = {}
for (let key in renderData) {
if (renderData.hasOwnProperty(key)) {
let item = renderData[key]
let data = item[0]
let firstKey = item[1]
let { clone, diff } = diffAndCloneA(data, this.miniRenderData[key]) // 开始数据 diff
// firstKey 必须是为响应式数据的 key,且这个发生变化的 key 为 forceUpdateKey 或者是在 diff 阶段发现确实出现了 diff 的情况
if (this.localKeys.indexOf(firstKey) > -1 && (this.checkInForceUpdateKeys(key) || diff)) {
this.miniRenderData[key] = result[key] = clone
}
}
}
return result
}
...
}
// src/helper/utils.js
// 如果 renderData 里面即包含对某个 key 的访问,同时还有对这个 key 的子节点访问的话,那么需要剔除这个子节点
/**
* process renderData, remove sub node if visit parent node already
* @param {Object} renderData
* @return {Object} processedRenderData
*/
export function preprocessRenderData (renderData) {
// method for get key path array
const processKeyPathMap = (keyPathMap) => {
let keyPath = Object.keys(keyPathMap)
return keyPath.filter((keyA) => {
return keyPath.every((keyB) => {
if (keyA.startsWith(keyB) && keyA !== keyB) {
let nextChar = keyA[keyB.length]
if (nextChar === '.' || nextChar === '[') {
return false
}
}
return true
})
})
}
const processedRenderData = {}
const renderDataFinalKey = processKeyPathMap(renderData) // 获取最终需要被渲染的数据的 key
Object.keys(renderData).forEach(item => {
if (renderDataFinalKey.indexOf(item) > -1) {
processedRenderData[item] = renderData[item]
}
})
return processedRenderData
}其中在 processRenderData 方法内部调用了 diffAndCloneA 方法去完成数据的 diff 工作。在这个方法内部判断新、旧值是否发生变化,返回的 diff 字段即表示是否发生了变化,clone 为 diffAndCloneA 接受到的第一个数据的深拷贝值。
这里大致的描述下相关流程:
相关参阅文档:
Wxs 是小程序自己推出的一套脚本语言。官方文档给出的示例,wxs 模块必须要声明式的被 wxml 引用。和 js 在 jsCore 当中去运行不同的是 wxs 是在渲染线程当中去运行的。因此 wxs 的执行便少了一次从 jsCore 执行的线程和渲染线程的通讯,从这个角度来说是对代码执行效率和性能上的比较大的一个优化手段。
有关官方提到的有关 wxs 的运行效率的问题还有待论证:
“在 android 设备中,小程序里的 wxs 与 js 运行效率无差异,而在 ios 设备中,小程序里的 wxs 会比 js 快 2~20倍。”
因为 mpx 是对小程序做渐进增强,因此 wxs 的使用方式和原生的小程序保持一致。在你的.mpx文件当中的 template block 内通过路径直接去引入 wxs 模块即可使用:
<template>
<wxs src="../wxs/components/list.wxs" module="list">
<view>{{ list.FOO }}</view>
</template>
// wxs/components/list.wxs
const Foo = 'This is from list wxs module'
module.exports = {
Foo
}在 template 模块经过 template-compiler 处理的过程中。模板编译器 compiler 在解析模板的 AST 过程中会针对 wxs 标签缓存一份 wxs 模块的映射表:
{
meta: {
wxsModuleMap: {
list: '../wxs/components/list.wxs'
}
}
}当 compiler 对 template 模板解析完后,template-compiler 接下来就开始处理 wxs 模块相关的内容:
// template-compiler/index.js
module.exports = function (raw) {
...
const addDependency = dep => {
const resourceIdent = dep.getResourceIdentifier()
if (resourceIdent) {
const factory = compilation.dependencyFactories.get(dep.constructor)
if (factory === undefined) {
throw new Error(`No module factory available for dependency type: ${dep.constructor.name}`)
}
let innerMap = dependencies.get(factory)
if (innerMap === undefined) {
dependencies.set(factory, (innerMap = new Map()))
}
let list = innerMap.get(resourceIdent)
if (list === undefined) innerMap.set(resourceIdent, (list = []))
list.push(dep)
}
}
// 如果有 wxsModuleMap 即为 wxs module 依赖的话,那么下面会调用 compilation.addModuleDependencies 方法
// 将 wxsModule 作为 issuer 的依赖再次进行编译,最终也会被打包进输出的模块代码当中
// 需要注意的就是 wxs module 不仅要被注入到 bundle 里的 render 函数当中,同时也会通过 wxs-loader 处理,单独输出一份可运行的 wxs js 文件供 wxml 引入使用
for (let module in meta.wxsModuleMap) {
isSync = false
let src = meta.wxsModuleMap[module]
const expression = `require(${JSON.stringify(src)})`
const deps = []
// parser 为 js 的编译器
parser.parse(expression, {
current: { // 需要注意的是这里需要部署 addDependency 接口,因为通过 parse.parse 对代码进行编译的时候,会调用这个接口来获取 require(${JSON.stringify(src)}) 编译产生的依赖模块
addDependency: dep => {
dep.userRequest = module
deps.push(dep)
}
},
module: issuer
})
issuer.addVariable(module, expression, deps) // 给 issuer module 添加 variable 依赖
iterationOfArrayCallback(deps, addDependency)
}
// 如果没有 wxs module 的处理,那么 template-compiler 即为同步任务,否则为异步任务
if (isSync) {
return result
} else {
const callback = this.async()
const sortedDependencies = []
for (const pair1 of dependencies) {
for (const pair2 of pair1[1]) {
sortedDependencies.push({
factory: pair1[0],
dependencies: pair2[1]
})
}
}
// 调用 compilation.addModuleDependencies 方法,将 wxs module 作为 issuer module 的依赖加入到编译流程中
compilation.addModuleDependencies(
issuer,
sortedDependencies,
compilation.bail,
null,
true,
() => {
callback(null, result)
}
)
}
}Vue 数据根据异常处理机制主要是聊下关于 Vue 对于 Object 类型的响应式数据添加属性,以及对于 Array 类型数据变更的监测。由于Vue 是使用 Object.defineProperty 来做数据劫持,当被劫持的 key 所对应的 value 为基本类型时,那么每次对这个 key 的 value 做修改的时候,都会调用这个 key 所定义的 setter 函数,这样也就能触发相关的订阅者的更新。但是如果 key 所对应的 value 为引用类型,例如 plain object,这个时候如果你直接改变了引用类型的地址,那么会触发 key 对应的 setter 函数,使得相关的订阅者进行更新。但是如果你对 plain object 进行 增加/删除 属性的操作的话,这个时候是无法触发 key 所对应的 setter 函数的,那么也就无法更新相关的 watcher。如果遇到这种场景的话,那应该怎么处理呢?
Vue 提供了全局 Vue.set/Vue.del 和实例上的 vm.$set/vm.$del 方法去完成 plain object 属性的添加和删除:
function set (target, key, val) {
if ("development" !== 'production' &&
(isUndef(target) || isPrimitive(target))
) {
warn(("Cannot set reactive property on undefined, null, or primitive value: " + ((target))));
}
if (Array.isArray(target) && isValidArrayIndex(key)) {
target.length = Math.max(target.length, key);
target.splice(key, 1, val);
return val
}
if (key in target && !(key in Object.prototype)) {
target[key] = val;
return val
}
var ob = (target).__ob__;
if (target._isVue || (ob && ob.vmCount)) {
"development" !== 'production' && warn(
'Avoid adding reactive properties to a Vue instance or its root $data ' +
'at runtime - declare it upfront in the data option.'
);
return val
}
if (!ob) {
target[key] = val;
return val
}
defineReactive(ob.value, key, val);
ob.dep.notify();
return val
}<template>
<p>{{ obj.a }}</p>
<p>{{ obj.b }}</p>
</template>
<script>
export default {
data () {
return {
obj: {
a: 'text'
}
}
},
created () {
setTimeout(() => {
this.obj.b = 'textttt'
}, 1000)
}
}
</script>页面渲染出来后,obj.b的文本内容是无法显示出来的,具体的原因我上面也说了,这时如果在定时器内部调用:
this.$set(this.obj, b, 'textttt')那么1s后,页面可以渲染出 obj.b 的内容。这是因为在 set 方法内部,首先会获取 (target).__ob__ 属性,即这个 key 所对应的 plain object 的 observer 观察者,通过 defineReactive(ob.value, key, val)方法,将新传入的值变更为响应式的数据后调用 ob.dep.notify() 方法去遍历所有收集起来的观察者(watcher),并触发观察者的更新,如果这个 watcher 是 render watcher,那么就能完成视图的更新。那么在这个组件的生命周期中,这个 key 所对应的 observer 是在什么时候收集到 render watcher 的呢?
function defineReactive (
obj,
key,
val,
customSetter,
shallow
) {
var dep = new Dep(); // 每一个 key 所对应的 dep 依赖
...
// 递归的去将 object 的深层次数据变成响应式数据
var childOb = !shallow && observe(val); // 获取 key 对应的 value 值(如果是 object 类型,那么会返回一个对应的 observer)
Object.defineProperty(obj, key, {
enumerable: true,
configurable: true,
get: function reactiveGetter () {
var value = getter ? getter.call(obj) : val;
if (Dep.target) {
dep.depend();
if (childOb) { // 如果 key 对应的 value(如果是 object)的 observe,即将当前的 watcher 加入到这个 value 的依赖当中
childOb.dep.depend();
if (Array.isArray(value)) {
dependArray(value);
}
}
}
return value
},
set: function reactiveSetter (newVal) {
...
}
});
}事实上在组件初始化的 initData 阶段,将 data 变成响应式数据的过程中,对应到本实例就是将 obj 的值({ a: 'text' })变成响应式的过程中,首先获取 obj 的值(为 plain object)的 observer 观察者实例,然后形成一个闭包。当组件实例化进入 $mount 阶段将 VNode 转化为真实的 dom 时,会调用 obj 的 getter 函数,这个时候首先完成 obj 的依赖的添加,将 render watcher 添加到 obj 的 dep 数组当中,同时因为 obj 的值的 observer 存在,那么同时将这个 render watcher 添加到 observer 的 dep 依赖当中。这样就完成了依赖的收集,那么在实际使用过程中调用实例的 this.$set 方法去给 obj 添加属性,在这个方法内部会获取 obj 的值({ a: 'text' })的 __ob__ 属性,即 { a: 'text' } 的 observer,同时在 set 方法内部最终会调用 ob.dep.notify() 方法去通知所有 watcher 去完成更新。如果你要删除一个响应式数据上的 key,那么需要调用 Vue.del/vm.$del 方法去完成,相关的内容大家可以阅读对应的源码。
以上是 plain object 在数据更新时需要注意的情况。另外还需要注意的就是当你的响应式数据类型为数组的时候,如何正确的去处理数组项的变更,同时去完成页面的渲染。我们首先来看个例子:
这篇文章是通过lie.js的源码一起去了解下如何实现Promise相关的规范。
首先是Promise的核心的构造函数的实现。
function INTERNAL() {}
var REJECTED = ['REJECTED'];
var FULFILLED = ['FULFILLED'];
var PENDING = ['PENDING'];
var handlers = {}
function Promise (resolver) {
if (typeof resolver !== 'function') {
throw new TypeError('resolver must be a function');
}
this.state = PENDING;
this.queue = [];
this.outcome = void 0;
/* istanbul ignore else */
if (!process.browser) {
this.handled = UNHANDLED;
}
if (resolver !== INTERNAL) {
safelyResolveThenable(this, resolver);
}
}构造函数内部定义了几个promise实例的属性:
promise的状态值.有3种:rejected,fulfilled,pending
queue数组用以保存这个promise被resolve/rejected后需要异步执行的回调
这个promise实例的值
对于promise,我们一般的用法是:
// 构造函数当中接收2个参数,resolve/reject,需要注意的是这2个参数是promise内部定义的,用以改变这个promise的状态和值
const promise = new Promise((resolve, reject) => {
// 同步或者异步的去resolve一个值
resolve(1)
})给这个Promise构造函数内部传入的resolver由内部的方法safelyResolveThenable去执行:
function safelyResolveThenable(self, thenable) {
// Either fulfill, reject or reject with error
// 标志位,初始态的promise仅仅只能被resolve/reject一次
var called = false;
function onError(value) {
if (called) {
return;
}
called = true;
// reject这个promise
handlers.reject(self, value);
}
function onSuccess(value) {
if (called) {
return;
}
called = true;
// resolve这个promise
handlers.resolve(self, value);
}
// 用一个函数将resolver执行包裹一层
function tryToUnwrap() {
// 这个函数即由调用方传入的
thenable(onSuccess, onError);
}
// 用以捕获resolver在执行过程可能抛出的错误
var result = tryCatch(tryToUnwrap);
if (result.status === 'error') {
onError(result.value);
}
}
function tryCatch(func, value) {
var out = {};
try {
out.value = func(value);
out.status = 'success';
} catch (e) {
out.status = 'error';
out.value = e;
}
return out;
}在safelyResolveThenable方法中设定了一个called标志位,这是因为一旦一个promise的状态发生了改变,那么之后的状态不能再次被改变,举例:
new Promise((resolve, reject) => {
// 一旦状态发生改变,后面的reject/resolve方法不能起作用
resolve(1)
reject(new Error('error'))
resolve(2)
})如果给Promise构造函数传入callback在执行过程中没有报错,且被resolve的话,那么这个时候即调用的onSuccess方法,这个方法内部调用了handlers.resolve方法。
接下来我们看下这个方法的定义:
handlers.resolve = function (self, value) {
var result = tryCatch(getThen, value);
if (result.status === 'error') {
return handlers.reject(self, result.value);
}
// 判断这个value是否是个thenable对象
var thenable = result.value;
if (thenable) {
safelyResolveThenable(self, thenable);
} else {
// 将这个promise的state从 pending -> fulfilled
self.state = FULFILLED;
// 更改这个promise对应的值
self.outcome = value;
var i = -1;
var len = self.queue.length;
// 依次执行这个promise的queue队列里面每一项queueItem的callFulfilled方法
while (++i < len) {
self.queue[i].callFulfilled(value);
}
}
// 返回这个promise对象
return self;
}再回到我们上面举的这个例子:
const promise = new Promise(resolve => {
resolve(1)
})在这个例子当中,是同步去resolve这个promise,那么返回的这个promise实例的状态便为fulfilled,同时outcome的值也被设为1。
将这个例子拓展一下:
const promise = new Promise(resolve => {
resolve(1)
})
promise.then(function onFullfilled (value) {
console.log(value)
})在实例的then方法上传入一个onFullfilled回调执行上面的代码,最后在控制台输出1。
接下来我们看下Promise原型上then方法的定义:
Promise.prototype.then = function (onFulfilled, onRejected) {
if (typeof onFulfilled !== 'function' && this.state === FULFILLED ||
typeof onRejected !== 'function' && this.state === REJECTED) {
return this;
}
// 创建一个新的promise
var promise = new this.constructor(INTERNAL);
/* istanbul ignore else */
if (!process.browser) {
if (this.handled === UNHANDLED) {
this.handled = null;
}
}
// new Promise在内部resolve过程中如果是同步的
if (this.state !== PENDING) {
var resolver = this.state === FULFILLED ? onFulfilled : onRejected;
unwrap(promise, resolver, this.outcome);
} else { // 异步的resolve
// this.queue保存了对于promise
this.queue.push(new QueueItem(promise, onFulfilled, onRejected));
}
return promise;
};在then方法内部首先创建一个新的promise,接下来会根据这个promise的状态来进行不同的处理。
如果这个promise已经被resolve/reject了(即非pending态),那么会直接调用unwrap()方法来执行对应的回调函数;
如果这个promise还是处于pending态,那么需要实例化一个QueueItem,并推入到queue队列当中。
我们首先分析第一种情况,即调用then方法的时候,promise的状态已经被resolve/reject了,那么根据对应的state来取对应的回调函数,并调用unwrap函数(后面会详细讲解这个方法)。
function unwrap(promise, func, value) {
// 异步执行这个func
immediate(function () {
var returnValue;
try {
// 捕获onFulfilled函数在执行过程中的错误
returnValue = func(value);
} catch (e) {
return handlers.reject(promise, e);
}
// 不能返回自身promise
if (returnValue === promise) {
handlers.reject(promise, new TypeError('Cannot resolve promise with itself'));
} else {
handlers.resolve(promise, returnValue);
}
});
}在这个函数中,使用immediate方法统一的将func方法异步的执行。并将这个func执行的返回值传递到下一个promise的处理方法当中。
因此在上面给的例子当中,因为Promise的状态是被同步resolve的,那么接下来立即调用then方法,并执行传入的onFullfilled方法。
第二种情况,如果promise还是处于pending态,这个时候不是立即执行callback,首先实例化一个QueueItem,并缓存到这个promise的queue队列当中,延迟执行这个queue当中保存的回调函数。
function QueueItem(promise, onFulfilled, onRejected) {
// 首先保存这个promise
this.promise = promise;
// 如果onFulfilled是一个函数
if (typeof onFulfilled === 'function') {
this.onFulfilled = onFulfilled;
// 那么重新赋值callFulfilled函数
this.callFulfilled = this.otherCallFulfilled;
}
if (typeof onRejected === 'function') {
this.onRejected = onRejected;
this.callRejected = this.otherCallRejected;
}
}
// 如果onFulfilled是一个函数,那么就会覆盖callFulfilled方法
// 如果onFulfilled不是一个函数,那么就会直接调用handlers.resolve去递归处理promise
QueueItem.prototype.callFulfilled = function (value) {
handlers.resolve(this.promise, value);
};
QueueItem.prototype.otherCallFulfilled = function (value) {
unwrap(this.promise, this.onFulfilled, value);
};
QueueItem.prototype.callRejected = function (value) {
handlers.reject(this.promise, value);
};
QueueItem.prototype.otherCallRejected = function (value) {
unwrap(this.promise, this.onRejected, value);
};QueueItem构造函数接受3个参数:promise,onFullfilled,onRejected。
在then当中新创建的promise对象
上一个promise被resolve后需要调用的回调
上一个promise被reject后需要调用的回调函数
接下来我们看下第二种情况是在什么样的情况下去执行的:
const promise = new Promise(resolve => {
setTimeout(() => {
resolve(1)
}, 3000)
})
promise.then(data => console.log(data))在这个例子当中,当过了3s后在控制台输出1。在这个例子当中,因为promise内部是异步去resolve这个promise。在这个promise被resolve前,promise实例通过then方法向这个promise的queue队列中添加onFullfilled方法,这个queue中保存的方法会等到promise被resolve后才会被执行。当在实际的调用resolve(1)时,即promise这个时候才被resolve,那么便会调用handlers.resolve方法,并依次调用这个promise的queue队列当中保存的onFullfilled函数
可以看到在QueueItem函数内部,会对onFullfilled和onRejected的参数类型做判断,只有当它们是函数的时候,才会将这个方法进行一次缓存,同时使用otherCallFulfilled方法覆盖原有的callFulfilled方法。这也是大家经常会遇到的值穿透的问题,举个例子:
const promise = new Promise(resolve => {
setTimeout(() => {
resolve(2)
}, 2000)
})
promise
.then(3)
.then(console.log)最后在控制台打印出2,而非3。当上一个promise被resolve后,调用这个promise的queue当中缓存的queueItem上的callFulfilled方法,因为then方法接收的是数值类型,因此这个queueItem上的callFulfilled方法未被覆盖,因此这时所做的便是直接将这个queueItem中保存的promise进行resolve,同时将上一个promise的值传下去。可以这样理解,如果then方法第一个参数接收到的是个函数,那么就由这个函数处理上一个promise传递过来的值,如果不是函数,那么就像管道一样,先流过这个then方法,而将上一个值传递给下下个then方法接收到的函数去处理。
上面提到了关于unwrap这个函数,这个函数的作用就是统一的将then方法中接收到的onFullfilled参数异步的执行。主要是使用了immediate这个库。这里说明下为什么统一的要将onFullfilled方法进行异步话的处理呢。
首先,是要解决代码逻辑执行顺序的问题,首先来看一种情况:
const promise = new Promise(resolve => {
// 情况一:同步resolve
resolve(1)
// 情况二:异步resolve
setTimeout(() => {
resolve(2)
}, 1000)
})
promise.then(function onFullfilled() {
// do something
foo()
})
bar()这个promise可能会被同步的resolve,也有可能异步的resolve,这个时候如果onFullfilled方法设计成同步的执行的话,那么foo及bar的执行顺序便依赖promise是被同步or异步被resolve,但是如果统一将onFullfilled方法设计成异步的执行的话,那么bar方法始终在foo方法前执行,这样就保证了代码执行的顺序。
其次,是要解决同步回调stackoverflow的问题,具体的链接请戳我
我们看到lie.js的内部实现当中,每次在调用then方法的时候,内部都新创建了一个promise的对象并返回,这样也完成了promise的链式调用。即:
const Promise = require('lie')
const promise = new Promise(resolve => setTimeout(resolve, 3000))
promise.then(() => 'a').then(() => 'b').then(() => {})需要注意的是,在每个then方法内部创建的新的promise对象的state为pending态,outcome为null。可以将上面示例的promise打印到控制台,你会非常清晰的看到整个promise链的结构:
Promise {
state: [ 'PENDING' ],
queue:
[ QueueItem {
promise: {
state: ['PENDING'],
queue: [
QueueItem {
promise: {
state: ['PENDING'],
queue: [
QueueItem {
promise: {
state: ['PENDING'],
queue: [],
outcome: undefined
}
}
],
outcome: undefined,
handled: null
},
onFulfilled: [Function],
callFulfilled: [Function]
}
],
outcome: undefined,
handled: null
},
onFulfilled: [Function],
callFulfilled: [Function] } ],
outcome: undefined,
handled: null }实际这个promise链是一个嵌套的结构,一旦的最外部的promise的状态发生了改变,那么就会依次执行这个promise的queue队列里保存的queueItem的onFulfilled或者onRejected方法,并这样一直传递下去。因此这也是大家经常看到的promise链一旦开始,就会一直向下执行,没法在哪个promise的执行过程中中断。
不过刚才也提到了关于在then方法内部是创建的一个新的pending状态的promise,这个promise状态的改变完全是由上一个promise的状态决定的,如果上一个promise是被resolve的,那么这个promise同样是被resolve的(前提是在代码执行过程中没有报错),并这样传递下去,同样如果上一个promise是被rejected的,那么这个状态也会一直传递下去。如果有这样一种情况,在某个promise封装的请求中,如果响应的错误码不符合要求,不希望这个promise继续被resolve下去,同时想要单独的catch住这个响应的话,那么可以在then方法中直接返回一个被rejected的promise。这样在这个promise后面的then方法中创建的promise的state都会被rejected,同时这些promise所接受的fullfilled方法不再执行,如果有传入onRejected方法的话便会执行onRejected方法,最后一直传递到的catch方法中添加的onReject方法。
someRequest()
.then(res => {
if (res.error === 0) {
// do something
return res
} else {
return Promise.reject(res)
}
}).then(val => {
// do something
}).catch(err => {
// do something
})看完lie的源码后,觉得promise设计还是挺巧妙的,promise事实上就是一个状态机,不过状态值能发生一次转变,由于then方法内部每次都是创建了一个新的promise,这样也完成了promise的链式调用,同时then方法中的回调统一设计为异步执行也保证了代码逻辑执行顺序。
上周做一个关于移动端图片压缩上传的功能。期间踩了几个坑,在此总结下。
大体的思路是,部分API的兼容性请参照caniuse:
blob对象,或者是file对象,将图片转化为data uri的形式。canvas,在页面上新建一个画布,利用canvas提供的API,将图片画入这个画布当中。canvas.toDataURL(),进行图片的压缩,得到图片的data uri的值步骤1当中,在进行图片压缩前,还是对图片大小做了判断的,如果图片大小大于200KB时,是直接进行图片上传,不进行图片的压缩,如果图片的大小是大于200KB,则是先进行图片的压缩再上传:
<input type="file" id="choose" accept="image/*"> var fileChooser = document.getElementById("choose"),
maxSize = 200 * 1024; //200KB
fileChoose.change = function() {
var file = this.files[0], //读取文件
reader = new FileReader();
reader.onload = function() {
var result = this.result, //result为data url的形式
img = new Image(),
img.src = result;
if(result.length < maxSize) {
imgUpload(result); //图片直接上传
} else {
var data = compress(img); //图片首先进行压缩
imgUpload(data); //图片上传
}
}
reader.readAsDataURL(file);
}步骤2,3:
var canvas = document.createElement('canvas'),
ctx = canvas.getContext('2d');
function compress(img) {
canvas.width = img.width;
canvas.height = img.height;
//利用canvas进行绘图
//将原来图片的质量压缩到原先的0.2倍。
var data = canvas.toDataURL('image/jpeg', 0.2); //data url的形式
return data;
}在利用canvas进行绘图的过程中,IOS图片上传过程中,存在着这样的问题:
(使用了binaryajax.js),方便获取图片的exif信息,通过获取exif的信息来确定图片旋转的角度(使用了exif.js),然后再进行图片相应的旋转处理。解决方法请戳我IOS中,当图片的大小大于 2MB时,会出现图片压扁的情况,这个时候需要重置图片的比例。解决方法请戳我FileReader的bug: FileReader读取的图片转化为Base64时,字符串为空,具体的问题描述请戳我步骤4,文件上传有2种方式:
方式1可以通过xhr ajax或者xhr2 FormData进行提交。
方法2这里就有个大坑了。具体描述请戳我
简单点说就是:Blob对象是无法注入到FormData对象当中的。
当你拿到了图片的data uri数据后,将其转化为Blob数据类型
var ndata = compress(img);
ndata = window.atob(ndata); //将base64格式的数据进行解码
//新建一个buffer对象,用以存储图片数据
var buffer = new Uint8Array(ndata.length);
for(var i = 0; i < text.length; i++) {
buffer[i] = ndata.charCodeAt(i);
}
//将buffer对象转化为Blob数据类型
var blob = getBlob([buffer]);
var fd = new FormData(),
xhr = new XMLHttpRequest();
fd.append('file', blob);
xhr.open('post', url);
xhr.onreadystatechange = function() {
//do something
}
xhr.send(fd);在新建Blob对象中有需要进行兼容性的处理,特别是对于不支持FormData上传blob的andriod机的兼容性处理。具体的方法请戳我
主要实现的细节是通过重写HTTP请求。
在安卓机器中,部分4.x的机型, 在webview里面对file对象进行了阉割,比如你拿不到file.type的值。
Android4.4下<input type="file">由于系统WebView的openFileChooser接口更改,导致无法选择文件,从而导致无法上传文件. bug描述请戳我
每次调用 setData 方法都会完成一次从逻辑层 -> native bridge -> 视图层的通讯,并完成页面的更新。因此频繁的调用 setData 方法势必也会造成视图的多次渲染,用户的交互受阻。所以对于 setData 方法另外一个优化角度就是尽可能的减少 setData 的调用频次,将多个同步的 setData 操作合并到一次调用当中。接下来就来看下 mpx 在这方面是如何做优化的。
还是先来看一个简单的 demo:
<script>
import { createComponent } from '@mpxjs/core'
createComponent({
data: {
msg: 'hello',
obj: {
a: {
c: 1,
d: 2
}
}
}
watch: {
obj: {
handler() {
this.msg = 'world'
},
deep: true
}
},
onShow() {
setTimeout(() => {
this.obj.a = {
c: 1,
d: 'd'
}
}, 200)
}
})
</script>在示例 demo 当中,msg 和 obj 都作为模板依赖的数据,这个组件开始展示后的 200ms,更新 obj.a 的值,同时 obj 被 watch,当 obj 发生改变后,更新 msg 的值。这里的逻辑处理顺序是:
obj.a 变化 -> 将 renderWatch 加入到执行队列 -> 触发 obj watch -> 将 obj watch 加入到执行队列 -> 将执行队列放到下一帧执行 -> 按照 watch id 从小到大依次执行 watch.run -> setData 方法调用一次(即 renderWatch 回调),统一更新 obj.a 及 msg -> 视图重新渲染接下来就来具体看下这个流程:由于 obj 作为模板渲染的依赖数据,自然会被这个组件的 renderWatch 作为依赖而被收集。当 obj 的值发生变化后,首先触发 reaction 的回调,即 this.update() 方法,如果是个同步的 watch,那么立即调用 this.run() 方法,即 watcher 监听的回调方法,否则就通过 queueWatcher(this) 方法将这个 watcher 加入到执行队列:
// src/core/watcher.js
export default Watcher {
constructor (context, expr, callback, options) {
...
this.id = ++uid
this.reaction = new Reaction(`mpx-watcher-${this.id}`, () => {
this.update()
})
...
}
update () {
if (this.options.sync) {
this.run()
} else {
queueWatcher(this)
}
}
}而在 queueWatcher 方法中,lockTask 维护了一个异步锁,即将 flushQueue 当成微任务统一放到下一帧去执行。所以在 flushQueue 开始执行之前,还会有同步的代码将 watcher 加入到执行队列当中,当 flushQueue 开始执行的时候,依照 watcher.id 升序依次执行,这样去确保 renderWatcher 在执行前,其他所有的 watcher 回调都执行完了,即执行 renderWatcher 的回调的时候获取到的 renderData 都是最新的,然后再去进行 setData 的操作,完成页面的更新。
// src/core/queueWatcher.js
import { asyncLock } from '../helper/utils'
const queue = []
const idsMap = {}
let flushing = false
let curIndex = 0
const lockTask = asyncLock()
export default function queueWatcher (watcher) {
if (!watcher.id && typeof watcher === 'function') {
watcher = {
id: Infinity,
run: watcher
}
}
if (!idsMap[watcher.id] || watcher.id === Infinity) {
idsMap[watcher.id] = true
if (!flushing) {
queue.push(watcher)
} else {
let i = queue.length - 1
while (i > curIndex && watcher.id < queue[i].id) {
i--
}
queue.splice(i + 1, 0, watcher)
}
lockTask(flushQueue, resetQueue)
}
}
function flushQueue () {
flushing = true
queue.sort((a, b) => a.id - b.id)
for (curIndex = 0; curIndex < queue.length; curIndex++) {
const watcher = queue[curIndex]
idsMap[watcher.id] = null
watcher.destroyed || watcher.run()
}
resetQueue()
}
function resetQueue () {
flushing = false
curIndex = queue.length = 0
}本文主要解释在JS里面this关键字的指向问题(在浏览器环境下)。
首先,必须搞清楚在JS里面,函数的几种调用方式:
但是不管函数是按哪种方法来调用的,请记住一点:谁调用这个函数或方法,this关键字就指向谁。
接下来就分情况来讨论下这些不同的情况:
##普通函数调用
function person(){
this.name="xl";
console.log(this);
console.log(this.name);
}
person(); //输出 window xl
在这段代码中person函数作为普通函数调用,实际上person是作为全局对象window的一个方法来进行调用的,即window.person();
所以这个地方是window对象调用了person方法,那么person函数当中的this即指window,同时window还拥有了另外一个属性name,值为xl.
var name="xl";
function person(){
console.log(this.name);
}
person(); //输出 xl同样这个地方person作为window的方法来调用,在代码的一开始定义了一个全局变量name,值为xl,它相当于window的一个属性,即window.name="xl",又因为在调用person的时候this是指向window的,因此这里会输出xl.
##作为方法来调用
在上面的代码中,普通函数的调用即是作为window对象的方法进行调用。显然this关键字指向了window对象.
再来看下其他的形式
var name="XL";
var person={
name:"xl",
showName:function(){
console.log(this.name);
}
}
person.showName(); //输出 xl
//这里是person对象调用showName方法,很显然this关键字是指向person对象的,所以会输出name
var showNameA=person.showName;
showNameA(); //输出 XL
//这里将person.showName方法赋给showNameA变量,此时showNameA变量相当于window对象的一个属性,因此showNameA()执行的时候相当于window.showNameA(),即window对象调用showNameA这个方法,所以this关键字指向window再换种形式:
var personA={
name:"xl",
showName:function(){
console.log(this.name);
}
}
var personB={
name:"XL",
sayName:personA.showName
}
personB.sayName(); //输出 XL
//虽然showName方法是在personA这个对象中定义,但是调用的时候却是在personB这个对象中调用,因此this对象指向##作为构造函数来调用
function Person(name){
this.name=name;
}
var personA=Person("xl");
console.log(personA.name); // 输出 undefined
console.log(window.name);//输出 xl
//上面代码没有进行new操作,相当于window对象调用Person("xl")方法,那么this指向window对象,并进行赋值操作window.name="xl".
var personB=new Person("xl");
console.log(personB.name);// 输出 xl
//这部分代码的解释见下
###new操作符
//下面这段代码模拟了new操作符(实例化对象)的内部过程
function person(name){
var o={};
o.__proto__=Person.prototype; //原型继承
Person.call(o,name);
return o;
}
var personB=person("xl");
console.log(personB.name); // 输出 xl
在person里面首先创建一个空对象o,将o的**proto**指向Person.prototype完成对原型的属性和方法的继承
Person.call(o,name)这里即函数Person作为apply/call调用(具体内容下方),将Person对象里的this改为o,即完成了o.name=name操作
返回对象o。
因此person("xl")返回了一个继承了Person.prototype对象上的属性和方法,以及拥有name属性为"xl"的对象,并将它赋给变量personB.
所以console.log(personB.name)会输出"xl"
##call/apply方法的调用
在JS里函数也是对象,因此函数也有方法。从Function.prototype上继承到Function.prototype.call/Function.prototype.apply方法
call/apply方法最大的作用就是能改变this关键字的指向.
Obj.method.apply(AnotherObj,arguments);
var name="XL";
var Person={
name:"xl",
showName:function(){
console.log(this.name);
}
}
Person.showName.call(); //输出 "XL"
//这里call方法里面的第一个参数为空,默认指向window。
//虽然showName方法定义在Person对象里面,但是使用call方法后,将showName方法里面的this指向了window。因此最后会输出"XL"; funtion FruitA(n1,n2){
this.n1=n1;
this.n2=n2;
this.change=function(x,y){
this.n1=x;
this.n2=y;
}
}
var fruitA=new FruitA("cheery","banana");
var FruitB={
n1:"apple",
n2:"orange"
};
fruitA.change.call(FruitB,"pear","peach");
console.log(FruitB.n1); //输出 pear
console.log(FruitB.n2);// 输出 peachFruitB调用fruitA的change方法,将fruitA中的this绑定到对象FruitB上。
##Function.prototype.bind()方法
var name="XL";
function Person(name){
this.name=name;
this.sayName=function(){
setTimeout(function(){
console.log("my name is "+this.name);
},50)
}
}
var person=new Person("xl");
person.sayName() //输出 “my name is XL”;
//这里的setTimeout()定时函数,相当于window.setTimeout(),由window这个全局对象对调用,因此this的指向为window, 则this.name则为XL 那么如何才能输出"my name is xl"呢?
var name="XL";
function Person(name){
this.name=name;
this.sayName=function(){
setTimeout(function(){
console.log("my name is "+this.name);
}.bind(this),50) //注意这个地方使用的bind()方法,绑定setTimeout里面的匿名函数的this一直指向Person对象
}
}
var person=new Person("xl");
person.sayName(); //输出 “my name is xl”;这里setTimeout(function(){console.log(this.name)}.bind(this),50);,匿名函数使用bind(this)方法后创建了新的函数,这个新的函数不管在什么地方执行,this都指向的Person,而非window,因此最后的输出为"my name is xl"而不是"my name is XL"
另外几个需要注意的地方:
setTimeout/setInterval/匿名函数执行的时候,this默认指向window对象,除非手动改变this的指向。在《javascript高级程序设计》当中,写到:“超时调用的代码(setTimeout)都是在全局作用域中执行的,因此函数中的this的值,在非严格模式下是指向window对象,在严格模式下是指向undefined”。本文都是在非严格模式下的情况。
var name="XL";
function Person(){
this.name="xl";
this.showName=function(){
console.log(this.name);
}
setTimeout(this.showName,50);
}
var person=new Person(); //输出 "XL"
//在setTimeout(this.showName,50)语句中,会延时执行this.showName方法
//this.showName方法即构造函数Person()里面定义的方法。50ms后,执行this.showName方法,this.showName里面的this此时便指向了window对象。则会输出"XL";修改上面的代码:
var name="XL";
function Person(){
this.name="xl";
var that=this;
this.showName=function(){
console.log(that.name);
}
setTimeout(this.showName,50)
}
var person=new Person(); //输出 "xl"
//这里在Person函数当中将this赋值给that,即让that保存Person对象,因此在setTimeout(this.showName,50)执行过程当中,console.log(that.name)即会输出Person对象的属性"xl"匿名函数:
var name="XL";
var person={
name:"xl",
showName:function(){
console.log(this.name);
}
sayName:function(){
(function(callback){
callback();
})(this.showName)
}
}
person.sayName(); //输出 XL var name="XL";
var person={
name:"xl",
showName:function(){
console.log(this.name);
}
sayName:function(){
var that=this;
(function(callback){
callback();
})(that.showName)
}
}
person.sayName() ; //输出 "xl"
//匿名函数的执行同样在默认情况下this是指向window的,除非手动改变this的绑定对象##Eval函数
该函数执行的时候,this绑定到当前作用域的对象上
var name="XL";
var person={
name:"xl",
showName:function(){
eval("console.log(this.name)");
}
}
person.showName(); //输出 "xl"
var a=person.showName;
a(); //输出 "XL"##箭头函数
es6里面this指向固定化,始终指向外部对象,因为箭头函数没有this,因此它自身不能进行new实例化,同时也不能使用call, apply, bind等方法来改变this的指向
function Timer() {
this.seconds = 0;
setInterval( () => this.seconds ++, 1000);
}
var timer = new Timer();
setTimeout( () => console.log(timer.seconds), 3100);
// 3
在构造函数内部的setInterval()内的回调函数,this始终指向实例化的对象,并获取实例化对象的seconds的属性,每1s这个属性的值都会增加1。否则最后在3s后执行setTimeOut()函数执行后输出的是0
##参考资料
webpack 对于不同依赖模块的模板处理都有单独的依赖模块类型文件来进行处理。例如,在你写的源代码当中,使用的是ES Module,那么最终会由 HarmonyModulesPlugin 里面使用的依赖进行处理,再例如你写的源码中模块使用的是符合 CommonJS Module 规范,那么最终会有 CommonJsPlugin 里面使用的依赖进行处理。除此外,webpack 还对于其他类型的模块依赖语法也做了处理:
// WebpackOptionsApply.js
const LoaderPlugin = require("./dependencies/LoaderPlugin");
const CommonJsPlugin = require("./dependencies/CommonJsPlugin");
const HarmonyModulesPlugin = require("./dependencies/HarmonyModulesPlugin");
const SystemPlugin = require("./dependencies/SystemPlugin");
const ImportPlugin = require("./dependencies/ImportPlugin");
const AMDPlugin = require("./dependencies/AMDPlugin");
const RequireContextPlugin = require("./dependencies/RequireContextPlugin");
const RequireEnsurePlugin = require("./dependencies/RequireEnsurePlugin");
const RequireIncludePlugin = require("./dependencies/RequireIncludePlugin");
class WebpackOptionsApply extends OptionsApply {
constructor() {
super()
}
process(options, compiler) {
...
new HarmonyModulesPlugin(options.module).apply(compiler);
new AMDPlugin(options.module, options.amd || {}).apply(compiler);
new CommonJsPlugin(options.module).apply(compiler);
new LoaderPlugin().apply(compiler);
new RequireIncludePlugin().apply(compiler);
new RequireEnsurePlugin().apply(compiler);
new RequireContextPlugin(
options.resolve.modules,
options.resolve.extensions,
options.resolve.mainFiles
).apply(compiler);
new ImportPlugin(options.module).apply(compiler);
new SystemPlugin(options.module).apply(compiler);
...
}
}模块依赖语法的处理对于 webpack 生成最终的文件内容非常的重要。这些针对不同依赖加载语法的处理插件在 webpack 初始化创建 compiler 的时候就完成了加载及初始化过程。这里我们可以来看下模块遵循 ES Module 所使用的相关的依赖依赖模板的处理是如何进行的,即 HarmonyModulesPlugin 这个插件内部主要完成的工作。
// part 1: 引入的主要是 ES Module 当中使用的不同语法的依赖类型
const HarmonyCompatibilityDependency = require("./HarmonyCompatibilityDependency");
const HarmonyInitDependency = require("./HarmonyInitDependency");
const HarmonyImportSpecifierDependency = require("./HarmonyImportSpecifierDependency");
const HarmonyImportSideEffectDependency = require("./HarmonyImportSideEffectDependency");
const HarmonyExportHeaderDependency = require("./HarmonyExportHeaderDependency");
const HarmonyExportExpressionDependency = require("./HarmonyExportExpressionDependency");
const HarmonyExportSpecifierDependency = require("./HarmonyExportSpecifierDependency");
const HarmonyExportImportedSpecifierDependency = require("./HarmonyExportImportedSpecifierDependency");
const HarmonyAcceptDependency = require("./HarmonyAcceptDependency");
const HarmonyAcceptImportDependency = require("./HarmonyAcceptImportDependency");
const NullFactory = require("../NullFactory");
// part 2: 引入的主要是 ES Module 使用的不同的语法,在编译过程中需要挂载的 hooks,方便做依赖收集
const HarmonyDetectionParserPlugin = require("./HarmonyDetectionParserPlugin");
const HarmonyImportDependencyParserPlugin = require("./HarmonyImportDependencyParserPlugin");
const HarmonyExportDependencyParserPlugin = require("./HarmonyExportDependencyParserPlugin");
const HarmonyTopLevelThisParserPlugin = require("./HarmonyTopLevelThisParserPlugin");
class HarmonyModulesPlugin {
constructor(options) {
this.options = options;
}
apply(compiler) {
compiler.hooks.compilation.tap(
"HarmonyModulesPlugin",
(compilation, { normalModuleFactory }) => {
compilation.dependencyFactories.set(
HarmonyCompatibilityDependency,
new NullFactory()
);
// 设置对应的依赖渲染所需要的模板
compilation.dependencyTemplates.set(
HarmonyCompatibilityDependency,
new HarmonyCompatibilityDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyInitDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyInitDependency,
new HarmonyInitDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyImportSideEffectDependency,
normalModuleFactory
);
compilation.dependencyTemplates.set(
HarmonyImportSideEffectDependency,
new HarmonyImportSideEffectDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyImportSpecifierDependency,
normalModuleFactory
);
compilation.dependencyTemplates.set(
HarmonyImportSpecifierDependency,
new HarmonyImportSpecifierDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyExportHeaderDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyExportHeaderDependency,
new HarmonyExportHeaderDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyExportExpressionDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyExportExpressionDependency,
new HarmonyExportExpressionDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyExportSpecifierDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyExportSpecifierDependency,
new HarmonyExportSpecifierDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyExportImportedSpecifierDependency,
normalModuleFactory
);
compilation.dependencyTemplates.set(
HarmonyExportImportedSpecifierDependency,
new HarmonyExportImportedSpecifierDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyAcceptDependency,
new NullFactory()
);
compilation.dependencyTemplates.set(
HarmonyAcceptDependency,
new HarmonyAcceptDependency.Template()
);
compilation.dependencyFactories.set(
HarmonyAcceptImportDependency,
normalModuleFactory
);
compilation.dependencyTemplates.set(
HarmonyAcceptImportDependency,
new HarmonyAcceptImportDependency.Template()
);
const handler = (parser, parserOptions) => {
if (parserOptions.harmony !== undefined && !parserOptions.harmony)
return;
new HarmonyDetectionParserPlugin().apply(parser);
new HarmonyImportDependencyParserPlugin(this.options).apply(parser);
new HarmonyExportDependencyParserPlugin(this.options).apply(parser);
new HarmonyTopLevelThisParserPlugin().apply(parser);
};
normalModuleFactory.hooks.parser
.for("javascript/auto")
.tap("HarmonyModulesPlugin", handler);
normalModuleFactory.hooks.parser
.for("javascript/esm")
.tap("HarmonyModulesPlugin", handler);
}
);
}
}
module.exports = HarmonyModulesPlugin;在 HarmonyModulesPlugin 引入的文件当中主要是分为了2部分:
当 webpack 创建新的 compilation 对象后,便执行compiler.hooks.compilation注册的钩子内部的方法。其中主要完成了以下几项工作:
1.设置不同依赖类型的 moduleFactory,例如设置HarmonyImportSpecifierDependency依赖类型的 moduleFactory 为normalModuleFactory;
2.设置不同依赖类型的 dependencyTemplate,例如设置HarmonyImportSpecifierDependency依赖类型的模板为new HarmonyImportSpecifierDependency.Template()实例;
3.注册 normalModuleFactory.hooks.parser 钩子函数,每当新建一个 normalModule 时这个钩子函数都会被执行,即触发 handler 函数的执行。handler 函数内部去初始化各种 plugin,注册相关的 hooks。
我们首先来看下 handler 函数内部初始化的几个 plugin 里面注册的和 parser 编译相关的插件。
// HarmonyDetectionParserPlugin.js
const HarmonyCompatibilityDependency = require("./HarmonyCompatibilityDependency");
const HarmonyInitDependency = require("./HarmonyInitDependency");
module.exports = class HarmonyDetectionParserPlugin {
apply(parser) {
parser.hooks.program.tap("HarmonyDetectionParserPlugin", ast => {
const isStrictHarmony = parser.state.module.type === "javascript/esm";
const isHarmony =
isStrictHarmony ||
ast.body.some(statement => {
return /^(Import|Export).*Declaration$/.test(statement.type);
});
if (isHarmony) {
// 获取当前的正在编译的 module
const module = parser.state.module;
const compatDep = new HarmonyCompatibilityDependency(module);
compatDep.loc = {
start: {
line: -1,
column: 0
},
end: {
line: -1,
column: 0
},
index: -3
};
// 给这个 module 添加一个 compatDep 依赖
module.addDependency(compatDep);
const initDep = new HarmonyInitDependency(module);
initDep.loc = {
start: {
line: -1,
column: 0
},
end: {
line: -1,
column: 0
},
index: -2
};
// 给这个 module 添加一个 initDep 依赖
module.addDependency(initDep);
parser.state.harmonyParserScope = parser.state.harmonyParserScope || {};
parser.scope.isStrict = true;
// 初始化这个 module 最终被编译生成的 meta 元信息,
module.buildMeta.exportsType = "namespace";
module.buildInfo.strict = true;
module.buildInfo.exportsArgument = "__webpack_exports__";
if (isStrictHarmony) {
module.buildMeta.strictHarmonyModule = true;
module.buildInfo.moduleArgument = "__webpack_module__";
}
}
});
...
}
};在每个 module 开始编译的时候便会触发这个 plugin 上注册的 hooks。通过 AST 的节点类型来判断这个 module 是否是 ES Module,如果是的话,首先会实例化一个HarmonyCompatibilityDependency依赖的实例,并记录依赖需要替换的位置,然后将这个实例加入到 module 的依赖中,接下来实例化一个HarmonyInitDependency依赖的实例,并记录依赖需要替换的位置,然后将实例加入到 module 的依赖当中。然后会设定当前被 parser 处理的 module 最终被渲染时的一些构建信息,例如exportsArgument可能会使用__webpack_exports__,即这个模块输出挂载变量使用__webpack_exports__。
其中HarmonyCompatibilityDependency依赖的 Template 主要是:
HarmonyCompatibilityDependency.Template = class HarmonyExportDependencyTemplate {
apply(dep, source, runtime) {
const usedExports = dep.originModule.usedExports;
if (usedExports !== false && !Array.isArray(usedExports)) {
// 定义 module 的 export 类型
const content = runtime.defineEsModuleFlagStatement({
exportsArgument: dep.originModule.exportsArgument
});
source.insert(-10, content);
}
}
}调用 RuntimeTemplate 实例上提供的 defineEsModuleFlagStatement 方法在当前模块最终生成的代码内插入代码:
__webpack_require__.r(__webpack_exports__) // 用以在 __webpack_exports__ 上定义一个 __esModule 属性,用以标识当前 module 是一个 ES Module而在HarmonyInitDependency依赖的 Template 中主要完成的工作是:
HarmonyInitDependency.Template = class HarmonyInitDependencyTemplate {
apply(dep, source, runtime, dependencyTemplates) {
const module = dep.originModule;
const list = [];
// 遍历这个依赖的所属的 module 的所有依赖
for (const dependency of module.dependencies) {
// 获取不同依赖所使用的 template
const template = dependencyTemplates.get(dependency.constructor);
// 部分 template 并不是在 generator 调用 generate 方法立即执行相关模板依赖的替换工作的
// 而是将相关的操作置于 harmonyInit 函数当中,在这个会被加入到一个数组当中
if (
template &&
typeof template.harmonyInit === "function" &&
typeof template.getHarmonyInitOrder === "function"
) {
const order = template.getHarmonyInitOrder(dependency);
if (!isNaN(order)) {
list.push({
order,
listOrder: list.length,
dependency,
template
});
}
}
}
// 对模板依赖数组进行排序
list.sort((a, b) => {
const x = a.order - b.order;
if (x) return x;
return a.listOrder - b.listOrder;
});
// 依次执行模板依赖上的 harmonyInit 方法,这个时候开始相关模板的替换工作
for (const item of list) {
item.template.harmonyInit(
item.dependency,
source,
runtime,
dependencyTemplates
);
}
}
}接下来我们再来看 HarmonyModulesPlugin 插件里面初始化的第二个插件HarmonyImportDependencyParserPlugin,这个插件主要完成的工作是和 ES Module 当中使用 import 语法相关:
module.exports = class HarmonyImportDependencyParserPlugin {
constructor() {
...
}
apply(parser) {
...
parser.hooks.import.tap('HarmonyImportDependencyParserPlugin', (statement, source) => {
...
const sideEffectDep = new HarmonyImportSideEffectDependency({ ... })
parser.state.module.addDependency(sideEffectDep);
...
})
parser.hooks.importSpecifier.tap('HarmonyImportDependencyParserPlugin', (statement, source, id, name) => {
...
// 设置引入模块名的映射关系
parser.state.harmonySpecifier.set(name, {
source,
id,
sourceOrder: parser.state.lastHarmonyImportOrder
});
...
})
parser.hooks.expression
.for('imported var')
.tap('HarmonyImportDependencyParserPlugin', expr => {
...
const dep = new HarmonyImportSpecifierDependency({ ... });
parser.state.module.addDependency(dep);
...
})
parser.hooks.call
.for('imported var')
.tap('HarmonyImportDependencyParserPlugin', expr => {
...
const dep = new HarmonyImportSpecifierDependency({ ... })
parser.state.module.addDependency(dep);
...
})
}
}在这个插件里面主要是注册了在模块通过 parser 编译的过程中,遇到不同 tokens 触发的 hooks。例如hooks.importSpecifier主要是用于你通过import语法加载其他模块时所申明的变量名,会通过一个 map 结构记录这个变量名。当你在源代码中使用了这个变量名,例如作为一个函数去调用(对应触发hooks.call钩子),或者是作为一个表达式去访问(对应触发hooks.express钩子),那么它们都会新建一个HarmonyImportSpecifierDependency依赖的实例,并进入到当前被编译的 module 当中。
这个HarmonyImportSpecifierDependency模板依赖主要完成的工作就是:
HarmonyImportSpecifierDependency.Template = class HarmonyImportSpecifierDependencyTemplate extends HarmonyImportDependency.Template {
apply(dep, source, runtime) {
super.apply(dep, source, runtime);
const content = this.getContent(dep, runtime);
source.replace(dep.range[0], dep.range[1] - 1, content);
}
getContent(dep, runtime) {
const exportExpr = runtime.exportFromImport({
module: dep._module,
request: dep.request,
exportName: dep._id,
originModule: dep.originModule,
asiSafe: dep.shorthand,
isCall: dep.call,
callContext: !dep.directImport,
importVar: dep.getImportVar()
});
return dep.shorthand ? `${dep.name}: ${exportExpr}` : exportExpr;
}
};将源码中引入的其他模块的依赖变量名进行字符串的替换,具体可以查阅RuntimeTemplate.exportFromImport方法。
我们来看个例子:
// 在 parse 编译过程中,触发 hooks.importSpecifier 钩子,通过 map 记录对应变量名
import { add } from './add.js'
// 触发 hooks.call 钩子,给 module 加入 HarmonyImportSpecifierDependency 依赖
add(1, 2)
---
// 最终生成的代码为:
/* harmony import */ var _add__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(1);
Object(_b__WEBPACK_IMPORTED_MODULE_0__["add"])(1, 2);这个插件主要完成的是和 ES Module 当中使用 export 语法相关的工作:
module.exports = class HarmonyExportDependencyParserPlugin {
constructor(moduleOptions) {
this.strictExportPresence = moduleOptions.strictExportPresence;
}
apply(parser) {
parser.hooks.export.tap(
"HarmonyExportDependencyParserPlugin",
statement => {
...
const dep = new HarmonyExportHeaderDependency(...);
...
parser.state.current.addDependency(dep);
return true;
}
);
parser.hooks.exportImport.tap(
"HarmonyExportDependencyParserPlugin",
(statement, source) => {
...
const sideEffectDep = new HarmonyImportSideEffectDependency(...);
...
parser.state.current.addDependency(sideEffectDep);
return true;
}
);
parser.hooks.exportExpression.tap(
"HarmonyExportDependencyParserPlugin",
(statement, expr) => {
...
const dep = new HarmonyExportExpressionDependency(...);
...
parser.state.current.addDependency(dep);
return true;
}
);
parser.hooks.exportDeclaration.tap(
"HarmonyExportDependencyParserPlugin",
statement => {}
);
parser.hooks.exportSpecifier.tap(
"HarmonyExportDependencyParserPlugin",
(statement, id, name, idx) => {
...
if (rename === "imported var") {
const settings = parser.state.harmonySpecifier.get(id);
dep = new HarmonyExportImportedSpecifierDependency(...);
} else {
dep = new HarmonyExportSpecifierDependency(...);
}
parser.state.current.addDependency(dep);
return true;
}
);
parser.hooks.exportImportSpecifier.tap(
"HarmonyExportDependencyParserPlugin",
(statement, source, id, name, idx) => {
...
const dep = new HarmonyExportImportedSpecifierDependency(...);
...
parser.state.current.addDependency(dep);
return true;
}
);
}
};parse 在编译源码过程中,根据你使用的不同的 ES Module export 语法去触发不通过的 hooks,然后给当前编译的 module 加入对应的依赖 module。还是通过2个例子来看:
// export 一个 add 标识符,在 parse 环节会触发 hooks.exportSpecifier 钩子,会在当前 module 加入一个 HarmonyExportSpecifierDependency 依赖
export function add() {}
---
// 最终在输出文件当中输出的内容为
/* harmony export (binding) */ __webpack_require__.d(__webpack_exports__, "add", function() { return add; });
function add() {}// export 从 add.js 模块加载的 add 标识符,在 parse 环节会触发 hooks.exportImportSpecifier 钩子,会在当前 module 加入一个 HarmonyExportImportedSpecifierDependency 依赖
export { add } from './add'
---
// 最终在输出文件当中输出的内容为
/* harmony import */ var _add__WEBPACK_IMPORTED_MODULE_0__ = __webpack_require__(1);
/* harmony reexport (safe) */ __webpack_require__.d(__webpack_exports__, "add", function() { return _add__WEBPACK_IMPORTED_MODULE_0__["add"]; });具体替换的工作可以查阅HarmonyExportSpecifierDependency.Template和HarmonyExportImportedSpecifierDependency.Template提供的依赖模板函数。
本文为了解决以下问题:
__proto__(实际原型)和prototype(原型属性)不一样!!!constructor属性(原型对象中包含这个属性,实例当中也同样会继承这个属性)prototype属性(constructor.prototype原型对象)__proto__属性(实例指向原型对象的指针)首先弄清楚几个概念:
##什么是对象
若干属性的集合
##什么是原型?
原型是一个对象,其他对象可以通过它实现继承。
##哪些对象有原型?
所有的对象在默认情况下都有一个原型,因为原型本身也是对象,所以每个原型自身又有一个原型(只有一种例外,默认的对象原型在原型链的顶端)
##任何一个对象都可以成为原型
接下来就是最核心的内容:
constructor属性始终指向创建当前对象的构造函数。
var arr=[1,2,3];
console.log(arr.constructor); //输出 function Array(){}
var a={};
console.log(arr.constructor);//输出 function Object(){}
var bool=false;
console.log(bool.constructor);//输出 function Boolean(){}
var name="hello";
console.log(name.constructor);//输出 function String(){}
var sayName=function(){}
console.log(sayName.constrctor)// 输出 function Function(){}
//接下来通过构造函数创建instance
function A(){}
var a=new A();
console.log(a.constructor); //输出 function A(){}以上部分即解释了任何一个对象都有constructor属性,指向创建这个对象的构造函数
##prototype属性
注意:prototype是每个函数对象都具有的属性,被称为原型对象,而__proto__属性才是每个对象才有的属性。一旦原型对象被赋予属性和方法,那么由相应的构造函数创建的实例会继承prototype上的属性和方法
//constructor : A
//instance : a
function A(){}
var a=new A();
A.prototype.name="xl";
A.prototype.sayName=function(){
console.log(this.name);
}
console.log(a.name);// "xl"
a.sayName();// "xl"
//那么由constructor创建的instance会继承prototype上的属性和方法##constructor属性和prototype属性
每个函数都有prototype属性,而这个prototype的constructor属性会指向这个函数。
function Person(name){
this.name=name;
}
Person.prototype.sayName=function(){
console.log(this.name);
}
var person=new Person("xl");
console.log(person.constructor); //输出 function Person(){}
console.log(Person.prototype.constructor);//输出 function Person(){}
console.log(Person.constructor); //输出 function Function(){}如果我们重写(重新定义)这个Person.prototype属性,那么constructor属性的指向就会发生改变了。
Person.prototype={
sayName:function(){
console.log(this.name);
}
}
console.log(person.constructor==Person); //输出 false (这里为什么会输出false后面会讲)
console.log(Person.constructor==Person); //输出 false
console.log(Person.prototype.constructor);// 输出 function Object(){}
//这里为什么会输出function Object(){}
//还记得之前说过constructor属性始终指向创建这个对象的构造函数吗?
Person.prototype={
sayName:function(){
console.log(this.name);
}
}
//这里实际上是对原型对象的重写:
Person.prototype=new Object(){
sayName:function(){
console.log(this.name);
}
}
//看到了吧。现在Person.prototype.constructor属性实际上是指向Object的。
//那么我如何能将constructor属性再次指向Person呢?
Person.prototype.constructor=Person;接下来解释为什么,看下面的例子
function Person(name){
this.name = name;
}
var personOne=new Person("xl");
Person.prototype = {
sayName: function(){
console.log(this.name);
}
};
var personTwo = new Person('XL');
console.log(personOne.constructor == Person); //输出true
console.log(personTwo.constructor == Person); //输出false
//大家可能会对这个地方产生疑惑?为何会第二个会输出false,personTwo不也是由Person创建的吗?这个地方应该要输出true啊?
//这里就涉及到了JS里面的原型继承
//这个地方是因为person实例继承了Person.prototype原型对象的所有的方法和属性,包括constructor属性。当Person.prototype的constructor发生变化的时候,相应的person实例上的constructor属性也会发生变化。所以第二个会输出false;
//当然第一个是输出true,因为改变构造函数的prototype属性是在personOne被创建出来之后。接下解释__proto__和prototype属性
同样拿上面的代码来解释:
function Person(name){
this.name=name;
}
Person.prototype.sayName=function(){
console.log(this.name);
}
var person=new Person("xl");
person.sayName(); //输出 "xl"
//constructor : Person
//instance : person
//prototype : Person.prototype首先给构造函数的原型对象Person.prototype赋给sayName方法,由构造函数Person创建的实例person会继承原型对象上的sayName方法。
###为什么会继承原型对象的方法?
因为ECMAscript的发明者为了简化这门语言,同时又保持继承性,采用了链式继承的方法。
由constructor创建的每个instance都有个__proto__属性,它指向constructor.prototype。那么constrcutor.prototype上定义的属性和方法都会被instance所继承.
function Person(name){
this.name=name;
}
Person.prototype.sayName=function(){
console.log(this.name);
}
var personOne=new Person("a");
var personTwo=new Person("b");
personOne.sayName(); // 输出 "a"
personTwo.sayName(); //输出 "b"
console.log(personOne.__proto__==Person.prototype); // true
console.log(personTwo.__proto__==Person.prototype); // true
console.log(personOne.constructor==Person); //true
console.log(personTwo.constructor==Person); //true
console.log(Person.prototype.constructor==Person); //true
console.log(Person.constructor); //function Function(){}
console.log(Person.__proto__.__proto__); // Object{} 参考文章:
还没用express写过server,先把部分源码撸了一遍,各位大神求轻拍。
express入口文件在lib文件夹下的express.js,其向外界暴露了一些方法。
最主要的(express.js 第36-47行):
function createApplication() {
var app = function(req, res, next) {
app.handle(req, res, next); //各中间件的处理入口,handle方法通过mixin拓展于proto
};
mixin(app, EventEmitter.prototype, false);
mixin(app, proto, false);
app.request = { __proto__: req, app: app };
app.response = { __proto__: res, app: app };
app.init();
return app;
}
exports = module.exports = createApplication;
我们经常在自己的业务代码中这样写:
var express = require('express');
var app = express();
其实就是调用createApplication方法.这样就实例化了一个app。这个app比较特殊,通过mixin集成了一些其他的属性
mixin(app, EventEmitter.prototype, false); //拓展了事件发射器原型对象
mixin(app, proto, false); //拓展了application.js中的属性和方法
在我们业务代码实例化app的时候,调用了app.init()方法完成了一些初始化的配置。init()方法也是从application.js中继承的。
入口文件很清晰,主要是完成方法的暴露以及app的一些初始化操作。
接下来看下application.js中的部分代码逻辑:
第136-146行,延迟实例化一个_router
app.lazyrouter = function lazyrouter() {
if (!this._router) {
this._router = new Router({
caseSensitive: this.enabled('case sensitive routing'),
strict: this.enabled('strict routing')
});
this._router.use(query(this.get('query parser fn')));
this._router.use(middleware.init(this));
}
};
第157-174行,这是各个middleware的入口,
app.handle = function handle(req, res, callback) {
var router = this._router; //获取已经实例化得router
// final handler
var done = callback || finalhandler(req, res, {
env: this.get('env'),
onerror: logerror.bind(this)
});
// no routes
if (!router) {
debug('no routes defined on app');
done();
return;
}
router.handle(req, res, done); //当http过来时,对于request和response的处理从这个地方开始
};
第187-242行,app.use方法提供了应用级的middleware,但是事实上在214行,this.lazyrouter()新建一个route,第219-221行,然后根据app.use(fn)传入的参数挂载到了route.use()路由级中间件上了。app.use()是route.use的一个代理。
app.use = function use(fn) {
var offset = 0;
var path = '/';
// default path to '/'
// disambiguate app.use([fn])
if (typeof fn !== 'function') {
var arg = fn;
while (Array.isArray(arg) && arg.length !== 0) {
arg = arg[0];
}
// first arg is the path
if (typeof arg !== 'function') {
offset = 1;
path = fn;
}
}
var fns = flatten(slice.call(arguments, offset)); //铺平arguments
if (fns.length === 0) {
throw new TypeError('app.use() requires middleware functions');
}
// setup router
this.lazyrouter(); //如果没有route实例则新建一个
var router = this._router;
fns.forEach(function (fn) {
// non-express app //如果传入的不是express实例app
if (!fn || !fn.handle || !fn.set) {
return router.use(path, fn); //将中间件注入到router中
}
debug('.use app under %s', path);
fn.mountpath = path;
fn.parent = this;
// restore .app property on req and res
router.use(path, function mounted_app(req, res, next) {
var orig = req.app;
fn.handle(req, res, function (err) {
req.__proto__ = orig.request;
res.__proto__ = orig.response;
next(err);
});
});
// mounted an app
fn.emit('mount', this);
}, this);
return this;
};
第255-258行,代理到router实例的route()的方法中:
app.route = function route(path) {
this.lazyrouter();
return this._router.route(path);
};
router实例是通过router/index.js提供构造函数来创建的,在这个文件夹中第42-60行:
var proto = module.exports = function(options) {
var opts = options || {};
function router(req, res, next) {
router.handle(req, res, next); //handle方法继承于proto
}
// mixin Router class functions
router.__proto__ = proto;
router.params = {};
router._params = [];
router.caseSensitive = opts.caseSensitive;
router.mergeParams = opts.mergeParams;
router.strict = opts.strict;
router.stack = []; //初始化一个stack.这个stack中保存了注册的所有中间件
return router;
};
提供了一个router的构造函数,它的原型对象上,第136行提供了proto.handle方法,这个方法的作用就是接收来自http的req和res。
第413行,提供了proto.use方法,正如上面所说的app.use是route.use的代理,这个方法的特殊性就在任何的http请求都会经过在app.use上挂载的中间件,例如现在express4.x已经将很多中间件从自身移除,需要你重新通过npm去安装,然后在业务代码中进行引用,例如使用body-parser中间件:
var express = require('express');
var app = express();
var bodyParser = require('body-parser');
app.use(bodyParser.json());
这样每次http请求过来的时候首先会经过bodyParser.json()这个中间件,它提供了一个向req添加req.body = {}方法,并传向下一个中间件的作用。
同时在route.use内部,第439-458行,
for (var i = 0; i < callbacks.length; i++) {
var fn = callbacks[i];
if (typeof fn !== 'function') {
throw new TypeError('Router.use() requires middleware function but got a ' + gettype(fn));
}
// add the middleware
debug('use %s %s', path, fn.name || '<anonymous>');
var layer = new Layer(path, { //新建一个layer,layer上挂载了error_handler和request_handler
sensitive: this.caseSensitive,
strict: false,
end: false
}, fn);
layer.route = undefined;
this.stack.push(layer); //route自身会维护一个stack,将每个新建的layer都推入stack当中,这个layer实例最终会对匹配的path,作出error_handle或者request_handle。
}
第477行,proto.route方法提供了一个新建route的方法。
proto.route = function route(path) {
var route = new Route(path); //新建一个route,这个Route构建函数内部实现见./route.js,它里面提供了一个空的stack,用以
var layer = new Layer(path, { //新建一个layer,layer的作用见下面的讲解
sensitive: this.caseSensitive,
strict: this.strict,
end: true
}, route.dispatch.bind(route));
layer.route = route;
this.stack.push(layer); //新建一个route,这个route会维护自身的stack
return route;
};
var route = require('express').Router(),但是这个方法不同的地方
在于,它会自身维护一个stack,这个stack中有你在这个方法上面定义的所有中间件。同样,你可以通过这个route挂载对于不同路径的req, res的处理。
使用的方法:
var express = require('express');
var app = express();
var router = express.Router();
//没有挂载任何路径的中间件,通过该路由的每个请求都会执行该中间件
router.use(function(req, res, next) {
console.log('route.use');
})
router.get('/test', function(req, res, next) {
console.log('route.get');
});
//最后需要将这个router挂载到应用
app.use('/', router);
以上部分主要是整个express的中间件的挂载。总结一下:
app.use()挂载的中间件最终都代理到了router.use()方法下router.use()方法,新建一个layer,layer上保存了路径,默认为'/',及相应的处理方法,并存入这个app维护的stack中。var router = require('express').Router()新建的router路径级实例,同样可以挂载不同的中间件,不过最后需要将这个router路由注入到app应用当中:app.use('/', router);接下来讲下当http请求到来的时候,数据的流向: 在你定义中间件的过程中,因为是维护了一个app或者route实例,它们分别都有一个stack。这个stack是FIFO的,因此每当一个请求过来的时候,数据从最开始的定义的中间件开始,一直向下按顺序进行传递,因此你可以自己定义,当然,你需要调用next()方法。就比如Route.protoype.dispath方法
//将req, res分发给这个route
Route.prototype.dispatch = function dispatch(req, res, done) {
var idx = 0;
var stack = this.stack;
if (stack.length === 0) {
return done();
}
var method = req.method.toLowerCase();
if (method === 'head' && !this.methods['head']) {
method = 'get';
}
req.route = this;
next();
function next(err) {
if (err && err === 'route') {
return done();
}
var layer = stack[idx++];
if (!layer) {
return done(err);
}
if (layer.method && layer.method !== method) { //匹配传入的req请求方式,和layer的method进行对比
return next(err);
}
//调用layer.handle,用以错误处理或者request处理
if (err) {
layer.handle_error(err, req, res, next);
} else {
layer.handle_request(req, res, next);
}
}
};
最后,http请求的处理:
在app或者route实例中,自身有一个stack,这个stack就存放了在挂载中间时新建的layer,每个layer实例都保存了对应的路径,以及相应的error_handle和request_handle。
谢谢大家看到这里,欢迎大家斧正。
下一篇写写express路由的实现。
上篇文章主要讲了 loader 的配置,匹配相关的机制。这篇主要会讲当一个 module 被创建之后,使用 loader 去处理这个 module 内容的流程机制。首先我们来总体的看下整个的流程:

在 module 一开始构建的过程中,首先会创建一个 loaderContext 对象,它和这个 module 是一一对应的关系,而这个 module 所使用的所有 loaders 都会共享这个 loaderContext 对象,每个 loader 执行的时候上下文就是这个 loaderContext 对象,所以可以在我们写的 loader 里面通过 this 来访问。
// NormalModule.js
const { runLoaders } = require('loader-runner')
class NormalModule extends Module {
...
createLoaderContext(resolver, options, compilation, fs) {
const requestShortener = compilation.runtimeTemplate.requestShortener;
// 初始化 loaderContext 对象,这些初始字段的具体内容解释在文档上有具体的解释(https://webpack.docschina.org/api/loaders/#this-data)
const loaderContext = {
version: 2,
emitWarning: warning => {...},
emitError: error => {...},
exec: (code, filename) => {...},
resolve(context, request, callback) {...},
getResolve(options) {...},
emitFile: (name, content, sourceMap) => {...},
rootContext: options.context, // 项目的根路径
webpack: true,
sourceMap: !!this.useSourceMap,
_module: this,
_compilation: compilation,
_compiler: compilation.compiler,
fs: fs
};
// 触发 normalModuleLoader 的钩子函数
compilation.hooks.normalModuleLoader.call(loaderContext, this);
if (options.loader) {
Object.assign(loaderContext, options.loader);
}
return loaderContext;
}
doBuild(options, compilation, resolver, fs, callback) {
// 创建 loaderContext 上下文
const loaderContext = this.createLoaderContext(
resolver,
options,
compilation,
fs
)
runLoaders(
{
resource: this.resource, // 这个模块的路径
loaders: this.loaders, // 模块所使用的 loaders
context: loaderContext, // loaderContext 上下文
readResource: fs.readFile.bind(fs) // 读取文件的 node api
},
(err, result) => {
// do something
}
)
}
...
}当 loaderContext 初始化完成后,开始调用 runLoaders 方法,这个时候进入到了 loaders 的执行阶段。runLoaders 方法是由loader-runner这个独立的 npm 包提供的方法,那我们就一起来看下 runLoaders 方法内部是如何运行的。
首先根据传入的参数完成进一步的处理,同时对于 loaderContext 对象上的属性做进一步的拓展:
exports.runLoaders = function runLoaders(options, callback) {
// read options
var resource = options.resource || ""; // 模块的路径
var loaders = options.loaders || []; // 模块所需要使用的 loaders
var loaderContext = options.context || {}; // 在 normalModule 里面创建的 loaderContext
var readResource = options.readResource || readFile;
var splittedResource = resource && splitQuery(resource);
var resourcePath = splittedResource ? splittedResource[0] : undefined; // 模块实际路径
var resourceQuery = splittedResource ? splittedResource[1] : undefined; // 模块路径 query 参数
var contextDirectory = resourcePath ? dirname(resourcePath) : null; // 模块的父路径
// execution state
var requestCacheable = true;
var fileDependencies = [];
var contextDependencies = [];
// prepare loader objects
loaders = loaders.map(createLoaderObject); // 处理 loaders TODO:
// 拓展 loaderContext 的属性
loaderContext.context = contextDirectory;
loaderContext.loaderIndex = 0; // 当前正在执行的 loader 索引
loaderContext.loaders = loaders;
loaderContext.resourcePath = resourcePath;
loaderContext.resourceQuery = resourceQuery;
loaderContext.async = null; // 异步 loader
loaderContext.callback = null;
...
// 需要被构建的模块路径,将 loaderContext.resource -> getter/setter
// 例如 /abc/resource.js?rrr
Object.defineProperty(loaderContext, "resource", {
enumerable: true,
get: function() {
if(loaderContext.resourcePath === undefined)
return undefined;
return loaderContext.resourcePath + loaderContext.resourceQuery;
},
set: function(value) {
var splittedResource = value && splitQuery(value);
loaderContext.resourcePath = splittedResource ? splittedResource[0] : undefined;
loaderContext.resourceQuery = splittedResource ? splittedResource[1] : undefined;
}
});
// 构建这个 module 所有的 loader 及这个模块的 resouce 所组成的 request 字符串
// 例如:/abc/loader1.js?xyz!/abc/node_modules/loader2/index.js!/abc/resource.js?rrr
Object.defineProperty(loaderContext, "request", {
enumerable: true,
get: function() {
return loaderContext.loaders.map(function(o) {
return o.request;
}).concat(loaderContext.resource || "").join("!");
}
});
// 在执行 loader 提供的 pitch 函数阶段传入的参数之一,剩下还未被调用的 loader.pitch 所组成的 request 字符串
Object.defineProperty(loaderContext, "remainingRequest", {
enumerable: true,
get: function() {
if(loaderContext.loaderIndex >= loaderContext.loaders.length - 1 && !loaderContext.resource)
return "";
return loaderContext.loaders.slice(loaderContext.loaderIndex + 1).map(function(o) {
return o.request;
}).concat(loaderContext.resource || "").join("!");
}
});
// 在执行 loader 提供的 pitch 函数阶段传入的参数之一,包含当前 loader.pitch 所组成的 request 字符串
Object.defineProperty(loaderContext, "currentRequest", {
enumerable: true,
get: function() {
return loaderContext.loaders.slice(loaderContext.loaderIndex).map(function(o) {
return o.request;
}).concat(loaderContext.resource || "").join("!");
}
});
// 在执行 loader 提供的 pitch 函数阶段传入的参数之一,包含已经被执行的 loader.pitch 所组成的 request 字符串
Object.defineProperty(loaderContext, "previousRequest", {
enumerable: true,
get: function() {
return loaderContext.loaders.slice(0, loaderContext.loaderIndex).map(function(o) {
return o.request;
}).join("!");
}
});
// 获取当前正在执行的 loader 的query参数
// 如果这个 loader 配置了 options 对象的话,this.query 就指向这个 option 对象
// 如果 loader 中没有 options,而是以 query 字符串作为参数调用时,this.query 就是一个以 ? 开头的字符串
Object.defineProperty(loaderContext, "query", {
enumerable: true,
get: function() {
var entry = loaderContext.loaders[loaderContext.loaderIndex];
return entry.options && typeof entry.options === "object" ? entry.options : entry.query;
}
});
// 每个 loader 在 pitch 阶段和正常执行阶段都可以共享的 data 数据
Object.defineProperty(loaderContext, "data", {
enumerable: true,
get: function() {
return loaderContext.loaders[loaderContext.loaderIndex].data;
}
});
var processOptions = {
resourceBuffer: null, // module 的内容 buffer
readResource: readResource
};
// 开始执行每个 loader 上的 pitch 函数
iteratePitchingLoaders(processOptions, loaderContext, function(err, result) {
// do something...
});
}这里稍微总结下就是在 runLoaders 方法的初期会对相关参数进行初始化的操作,特别是将 loaderContext 上的部分属性改写为 getter/setter 函数,这样在不同的 loader 执行的阶段可以动态的获取一些参数。
接下来开始调用 iteratePitchingLoaders 方法执行每个 loader 上提供的 pitch 函数。大家写过 loader 的话应该都清楚,每个 loader 可以挂载一个 pitch 函数,每个 loader 提供的 pitch 方法和 loader 实际的执行顺序正好相反。这块的内容在 webpack 文档上也有详细的说明(请戳我)。
这些 pitch 函数并不是用来实际处理 module 的内容的,主要是可以利用 module 的 request,来做一些拦截处理的工作,从而达到在 loader 处理流程当中的一些定制化的处理需要,有关 pitch 函数具体的实战可以参见下一篇文档[Webpack 高手进阶-loader 实战] TODO:
function iteratePitchingLoaders() {
// abort after last loader
if(loaderContext.loaderIndex >= loaderContext.loaders.length)
return processResource(options, loaderContext, callback);
// 根据 loaderIndex 来获取当前需要执行的 loader
var currentLoaderObject = loaderContext.loaders[loaderContext.loaderIndex];
// iterate
// 如果被执行过,那么直接跳过这个 loader 的 pitch 函数
if(currentLoaderObject.pitchExecuted) {
loaderContext.loaderIndex++;
return iteratePitchingLoaders(options, loaderContext, callback);
}
// 加载 loader 模块
// load loader module
loadLoader(currentLoaderObject, function(err) {
// do something ...
});
}每次执行 pitch 函数前,首先根据 loaderIndex 来获取当前需要执行的 loader (currentLoaderObject),调用 loadLoader 函数来加载这个 loader,loadLoader 内部兼容了 SystemJS,ES Module,CommonJs 这些模块定义,最终会将 loader 提供的 pitch 方法和普通方法赋值到 currentLoaderObject 上:
// loadLoader.js
module.exports = function (loader, callback) {
...
var module = require(loader.path)
...
loader.normal = module
loader.pitch = module.pitch
loader.raw = module.raw
callback()
...
}当 loader 加载完后,开始执行 loadLoader 的回调:
loadLoader(currentLoaderObject, function(err) {
var fn = currentLoaderObject.pitch; // 获取 pitch 函数
currentLoaderObject.pitchExecuted = true;
if(!fn) return iteratePitchingLoaders(options, loaderContext, callback); // 如果这个 loader 没有提供 pitch 函数,那么直接跳过
// 开始执行 pitch 函数
runSyncOrAsync(
fn,
loaderContext, [loaderContext.remainingRequest, loaderContext.previousRequest, currentLoaderObject.data = {}],
function(err) {
if(err) return callback(err);
var args = Array.prototype.slice.call(arguments, 1);
// Determine whether to continue the pitching process based on
// argument values (as opposed to argument presence) in order
// to support synchronous and asynchronous usages.
// 根据是否有参数返回来判断是否向下继续进行 pitch 函数的执行
var hasArg = args.some(function(value) {
return value !== undefined;
});
if(hasArg) {
loaderContext.loaderIndex--;
iterateNormalLoaders(options, loaderContext, args, callback);
} else {
iteratePitchingLoaders(options, loaderContext, callback);
}
}
);
})这里出现了一个 runSyncOrAsync 方法,先按住不表,后文会讲,开始执行 pitch 函数,当 pitch 函数执行完后,执行传入的回调函数。我们看到回调函数里面会判断接收到的参数的个数,除了第一个 err 参数外,如果还有其他的参数(这些参数是pitch函数执行完后传入回调函数的),那么会直接进入 loader 的 normal 方法执行阶段,并且会直接跳过后面的 loader 执行阶段。如果 pitch 函数没有返回值的话,那么进入到下一个 loader 的 pitch 函数的执行阶段。让我们再回到 iteratePitchingLoaders 方法内部,当所有 loader 上面的 pitch 函数都执行完后,即 loaderIndex 索引值 >= loader 数组长度的时候:
function iteratePitchingLoaders () {
...
if(loaderContext.loaderIndex >= loaderContext.loaders.length)
return processResource(options, loaderContext, callback);
...
}
function processResource(options, loaderContext, callback) {
// set loader index to last loader
loaderContext.loaderIndex = loaderContext.loaders.length - 1;
var resourcePath = loaderContext.resourcePath;
if(resourcePath) {
loaderContext.addDependency(resourcePath); // 添加依赖
options.readResource(resourcePath, function(err, buffer) {
if(err) return callback(err);
options.resourceBuffer = buffer;
iterateNormalLoaders(options, loaderContext, [buffer], callback);
});
} else {
iterateNormalLoaders(options, loaderContext, [null], callback);
}
}在 processResouce 方法内部调用 node api readResouce 读取 module 对应路径的文本内容,调用 iterateNormalLoaders 方法,开始进入 loader normal 方法的执行阶段。
function iterateNormalLoaders () {
if(loaderContext.loaderIndex < 0)
return callback(null, args);
var currentLoaderObject = loaderContext.loaders[loaderContext.loaderIndex];
// iterate
if(currentLoaderObject.normalExecuted) {
loaderContext.loaderIndex--;
return iterateNormalLoaders(options, loaderContext, args, callback);
}
var fn = currentLoaderObject.normal;
currentLoaderObject.normalExecuted = true;
if(!fn) {
return iterateNormalLoaders(options, loaderContext, args, callback);
}
// buffer 和 utf8 string 之间的转化
convertArgs(args, currentLoaderObject.raw);
runSyncOrAsync(fn, loaderContext, args, function(err) {
if(err) return callback(err);
var args = Array.prototype.slice.call(arguments, 1);
iterateNormalLoaders(options, loaderContext, args, callback);
});
}在 iterateNormalLoaders 方法内部就是依照从右到左的顺序(正好与 pitch 方法执行顺序相反)依次执行每个 loader 上的 normal 方法。loader 不管是 pitch 方法还是 normal 方法的执行可为同步的,也可设为异步的(这里说下 normal 方法的)。一般如果你写的 loader 里面可能涉及到计算量较大的情况时,可将你的 loader 异步化,在你 loader 方法里面调用this.async方法,返回异步的回调函数,当你 loader 内部实际的内容执行完后,可调用这个异步的回调来进入下一个 loader 的执行。
module.exports = function (content) {
const callback = this.async()
someAsyncOperation(content, function(err, result) {
if (err) return callback(err);
callback(null, result);
});
}除了调用 this.async 来异步化 loader 之外,还有一种方式就是在你的 loader 里面去返回一个 promise,只有当这个 promise 被 resolve 之后,才会调用下一个 loader(具体实现机制见下文):
module.exports = function (content) {
return new Promise(resolve => {
someAsyncOpertion(content, function(err, result) {
if (err) resolve(err)
resolve(null, result)
})
})
}这里还有一个地方需要注意的就是,上下游 loader 之间的数据传递过程中,如果下游的 loader 接收到的参数为一个,那么可以在上一个 loader 执行结束后,如果是同步就直接 return 出去:
module.exports = function (content) {
// do something
return content
}如果是异步就直接调用异步回调传递下去(参见上面loader异步化)。如果下游 loader 接收的参数多余一个,那么上一个 loader 执行结束后,如果是同步那么就需要调用 loaderContext 提供的 callback 函数:
module.exports = function (content) {
// do something
this.callback(null, content, argA, argB)
}如果是异步的还是继续调用异步回调函数传递下去(参见上面loader异步化)。具体的执行机制涉及到上文还没讲到的 runSyncOrAsync 方法,它提供了上下游 loader 调用的接口:
function runSyncOrAsync(fn, context, args, callback) {
var isSync = true; // 是否为同步
var isDone = false;
var isError = false; // internal error
var reportedError = false;
// 给 loaderContext 上下文赋值 async 函数,用以将 loader 异步化,并返回异步回调
context.async = function async() {
if(isDone) {
if(reportedError) return; // ignore
throw new Error("async(): The callback was already called.");
}
isSync = false; // 同步标志位置为 false
return innerCallback;
};
// callback 的形式可以向下一个 loader 多个参数
var innerCallback = context.callback = function() {
if(isDone) {
if(reportedError) return; // ignore
throw new Error("callback(): The callback was already called.");
}
isDone = true;
isSync = false;
try {
callback.apply(null, arguments);
} catch(e) {
isError = true;
throw e;
}
};
try {
// 开始执行 loader
var result = (function LOADER_EXECUTION() {
return fn.apply(context, args);
}());
// 如果为同步的执行
if(isSync) {
isDone = true;
// 如果 loader 执行后没有返回值,执行 callback 开始下一个 loader 执行
if(result === undefined)
return callback();
// loader 返回值为一个 promise 函数,放到下一个 mircoTask 中执行下一个 loader。这也是 loader 异步化的一种方式
if(result && typeof result === "object" && typeof result.then === "function") {
return result.catch(callback).then(function(r) {
callback(null, r);
});
}
// 如果 loader 执行后有返回值,执行 callback 开始下一个 loader 执行
return callback(null, result);
}
} catch(e) {
// do something
}
}以上就是对于 module 在构建过程中 loader 执行流程的源码分析。可能平时在使用 webpack 过程了解相关的 loader 执行规则和策略,再配合这篇对于内部机制的分析,应该会对 webpack loader 的使用有更加深刻的印象。
hash 的生成过程是在 seal 阶段,当 chunk 和 module 建立起联系,module 被分配完 id 后开始进行。对应于 compilation 实例上的 createHash 方法:
最终生成的 hash 又分为好几种,例如代表本次 compilation 编译的 hash,每个 chunk 的 hash,每个 module 的 hash。所生成的这些 hash 主要都是基于文本实际内容去生成的。这里我们主要来看下平时用的较多的 chunkHash 是如何生成的。由于在 hash 生成的过程中会有很多相关的文本去影响最终的 hash 生成,这里主要是看下一些比较关键的影响 hash 生成的内容。
class Compilation {
createHash() {
const outputOptions = this.outputOptions; // output 配置
const hashFunction = outputOptions.hashFunction; // 所使用的 hash 函数,默认为 md5
const hashDigest = outputOptions.hashDigest; // 生成 hash 所使用的编码方法,默认为 hex
const hashDigestLength = outputOptions.hashDigestLength; // 最终输出的文件所使用的 hash 长度
const hash = createHash(hashFunction); // 本次 compilation 所使用的 hash
const chunks = this.chunks.slice();
...
// 遍历最终需要生成的 chunks
for (let i = 0; i < chunks.length; i++) {
const chunk = chunks[i];
// 为每个 chunk 新生成一个 chunkHash 生成函数
const chunkHash = createHash(hashFunction);
try {
if (outputOptions.hashSalt) {
chunkHash.update(outputOptions.hashSalt);
}
chunk.updateHash(chunkHash);
const template = chunk.hasRuntime()
? this.mainTemplate
: this.chunkTemplate;
template.updateHashForChunk(
chunkHash,
chunk,
this.moduleTemplates.javascript,
this.dependencyTemplates
);
// chunkhash 生成完毕
this.hooks.chunkHash.call(chunk, chunkHash);
chunk.hash = chunkHash.digest(hashDigest);
hash.update(chunk.hash);
chunk.renderedHash = chunk.hash.substr(0, hashDigestLength);
this.hooks.contentHash.call(chunk);
} catch (err) {
this.errors.push(new ChunkRenderError(chunk, "", err));
}
}
...
}
}遍历最终需要生成的 chunks,为每个 chunk 新生成一个 chunkHash 生成函数。调用 chunk.updateHash 方法:
class Chunk {
...
updateHash() {
hash.update(`${this.id} `);
hash.update(this.ids ? this.ids.join(",") : "");
hash.update(`${this.name || ""} `);
for (const m of this._modules) {
hash.update(m.hash);
}
}
...
}对这个 chunk 的 id / ids / name 以及这个 chunk 所包含的所有的 module 的 hash(chunk生成 hash 之前就已经生成好的) 进行 hash 计算。这个过程进行完后,根据这个 chunk 是否是入口 chunk 来调用对应的 updateHashForChunk 方法。这个方法结束后会暴露出一个 chunkHash 的钩子函数,并生成最终属于这个 chunk 的 hash 值。
工欲善其事必先利其器,在你开始了解 webpack 源码以前,首先需要了解下如果对 webpack 源码进行调试。因为笔者日常使用的是 VScode 作为我的编辑器,所以在这里我也是介绍下通过 VScode 来进行 webpack 的源码,或者是对 webpack 相关的 loader、plugin 进行调试。
我们的调试都是在 node 环境下进行的,不涉及到 browser,而 VScode 内部已经集成了 node debugger 环境,因此我们不需要安装其他的插件,直接进入到 debugger 配置阶段。



VScode 会帮你在项目的根目录下初始化一个 .vscode/launch.json 文件,接下来就进行 debugger 相关的配置。
一些字段名:
例如在我的一个 vue 项目当中,webpack 被 vue-cli-service 封装到里面了,项目相关的一些构建的命令都需要通过 vue-cli-service 提供的 node bash (具体可参见通过 vue-cli 生成的项目中 package.json 配置的 npm script)进行启动,如果我想对项目进行编译构建实际上就是执行的vue-cli-service build命令。因此我需要进行的 lanuch.json 的配置就是:
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "launch",
"name": "vue-cli-service debug",
"program": "${workspaceFolder}/node_modules/.bin/vue-cli-service",
"args": ["build"]
}
]
}这些配置好了之后即可按 F5 开始进行 debugger 了。
webpack 的插件设计决定了不同模块之间的解耦和离散化。因此你在调试代码的过程中进行打断点、单步调试、单步跳过的时候经常就跳到了另外一个模块当中了,不过 VScode 提供的 debugger 功能非常的强大,有关运行时、上下文、变量等内容都可以非常清晰的看到。例如我比较喜欢在 VScode 的全局配置中将 Debug:Inline Values 打开(在 VScode 设置当中进行配置),这样会更加方便查阅相关信息。此外 VScode 还提供了 conditional breakpoints/inline breakpoints/log points 等等断点方便你进行调试,具体请查阅相关文档。
具体有关 VScode debugger 的一些使用方法和技巧,可查阅相关文档:
最近一直在用node.js写一些相关的工具,对于node.js的模块如何去加载,以及所遵循的模块加载规范的具体细节又是如何并不是了解。这篇文件也是看过node.js源码及部分文章总结而来:
在es2015标准以前,js并没有成熟的模块系统的规范。Node.js为了弥补这样一个缺陷,采用了CommonJS规范中所定义的模块规范,它包括:
1.require
require是一个函数,它接收一个模块的标识符,用以引用其他模块暴露出来的API。
2.module context
module context规定了一个模块当中,存在一个require变量,它遵从上面对于这个require函数的定义,一个exports对象,模块如果需要向外暴露API,即在一个exports的对象上添加属性。以及一个module object。
3.module Identifiers
module Identifiers定义了require函数所接受的参数规则,比如说必须是小驼峰命名的字符串,可以没有文件后缀名,.或者..表明文件路径是相对路径等等。
具体关于commonJS中定义的module规范,可以参见wiki文档
在我们的node.js程序当中,我们使用require这个看起来是全局(后面会解释为什么看起来是全局的)的方法去加载其他模块。
const util = require('./util')首先我们来看下关于这个方法,node.js内部是如何定义的:
Module.prototype.require = function () {
assert(path, 'missing path');
assert(typeof path === 'string', 'path must be a string');
// 实际上是调用Module._load方法
return Module._load(path, this, /* isMain */ false);
}
Module._load = function (request, parent, isMain) {
.....
// 获取文件名
var filename = Module._resolveFilename(request, parent, isMain);
// _cache缓存的模块
var cachedModule = Module._cache[filename];
if (cachedModule) {
updateChildren(parent, cachedModule, true);
return cachedModule.exports;
}
// 如果是nativeModule模块
if (NativeModule.nonInternalExists(filename)) {
debug('load native module %s', request);
return NativeModule.require(filename);
}
// Don't call updateChildren(), Module constructor already does.
// 初始化一个新的module
var module = new Module(filename, parent);
if (isMain) {
process.mainModule = module;
module.id = '.';
}
// 加载模块前,就将这个模块缓存起来。注意node.js的模块加载系统是如何避免循环依赖的
Module._cache[filename] = module;
// 加载module
tryModuleLoad(module, filename);
// 将module.exports导出的内容返回
return module.exports;
}Module._load方法是一个内部的方法,主要是:
接下来我们来看下node.js是如何根据传入的模块路径字符串来查找对应的模块的:
Module._resolveFilename = function (request, parent, isMain, options) {
if (NativeModule.nonInternalExists(request)) {
return request;
}
var paths;
if (typeof options === 'object' && options !== null &&
Array.isArray(options.paths)) {
...
} else {
// 获取模块的大致路径 [parentDir] | [id, [parentDir]]
paths = Module._resolveLookupPaths(request, parent, true);
}
// look up the filename first, since that's the cache key.
// node index.js
// request = index.js
// paths = ['/root/foo/bar/index.js', '/root/foo/bar']
var filename = Module._findPath(request, paths, isMain);
if (!filename) {
var err = new Error(`Cannot find module '${request}'`);
err.code = 'MODULE_NOT_FOUND';
throw err;
}
return filename;
}在这个方法内部,需要调用一个内部的方法:Module._resolveLookupPaths,这个方法会依据父模块的路径获取所有这个模块可能的路径:
Module._resolveLookupPaths = function (request, parent, newReturn) {
...
}这个方法内部有以下几种情况的处理:
node xxx启动的模块这个时候node.js会直接获取到你这个程序执行路径,并在这个方法当中返回
require(xxx)require一个存在于node_modules中的模块这个时候会对执行路径上所有可能存在node_modules的路径进行遍历一遍
require(./)require一个相对路径或者绝对路径的模块直接返回父路径
当拿到需要找寻的路径后,调用Module._findPath方法去查找对应的文件路径。
Module._findPath = function (request, paths, isMain) {
if (path.isAbsolute(request)) {
paths = [''];
} else if (!paths || paths.length === 0) {
return false;
}
// \x00 -> null,相当于空字符串
var cacheKey = request + '\x00' +
(paths.length === 1 ? paths[0] : paths.join('\x00'));
// 路径的缓存
var entry = Module._pathCache[cacheKey];
if (entry)
return entry;
var exts;
// 尾部是否带有/
var trailingSlash = request.length > 0 &&
request.charCodeAt(request.length - 1) === 47/*/*/;
// For each path
for (var i = 0; i < paths.length; i++) {
// Don't search further if path doesn't exist
const curPath = paths[i]; // 当前路径
if (curPath && stat(curPath) < 1) continue;
var basePath = path.resolve(curPath, request);
var filename;
// 调用internalModuleStat方法来判断文件类型
var rc = stat(basePath);
// 如果路径不以/结尾,那么可能是文件,也可能是文件夹
if (!trailingSlash) {
if (rc === 0) { // File. 文件
if (preserveSymlinks && !isMain) {
filename = path.resolve(basePath);
} else {
filename = toRealPath(basePath);
}
} else if (rc === 1) { // Directory. 当提供的路径是文件夹的情况下会去这个路径下找package.json中的main字段对应的模块的入口文件
if (exts === undefined)
// '.js' '.json' '.node' '.ms'
exts = Object.keys(Module._extensions);
// 获取pkg内部的main字段对应的值
filename = tryPackage(basePath, exts, isMain);
}
if (!filename) {
// try it with each of the extensions
if (exts === undefined)
exts = Object.keys(Module._extensions);
filename = tryExtensions(basePath, exts, isMain); // ${basePath}.(js|json|node)等文件后缀,看是否文件存在
}
}
// 如果路径以/结尾,那么就是文件夹
if (!filename && rc === 1) { // Directory.
if (exts === undefined)
exts = Object.keys(Module._extensions);
filename = tryPackage(basePath, exts, isMain) ||
// try it with each of the extensions at "index"
tryExtensions(path.resolve(basePath, 'index'), exts, isMain);
}
if (filename) {
// Warn once if '.' resolved outside the module dir
if (request === '.' && i > 0) {
if (!warned) {
warned = true;
process.emitWarning(
'warning: require(\'.\') resolved outside the package ' +
'directory. This functionality is deprecated and will be removed ' +
'soon.',
'DeprecationWarning', 'DEP0019');
}
}
// 缓存路径
Module._pathCache[cacheKey] = filename;
return filename;
}
}
return false;
}
function tryPackage(requestPath, exts, isMain) {
var pkg = readPackage(requestPath); // 获取package.json当中的main字段
if (!pkg) return false;
var filename = path.resolve(requestPath, pkg); // 解析路径
return tryFile(filename, isMain) || // 直接判断这个文件是否存在
tryExtensions(filename, exts, isMain) || // 判断这个分别以js,json,node等后缀结尾的文件是否存在
tryExtensions(path.resolve(filename, 'index'), exts, isMain); // 判断这个分别以 ${filename}/index.(js|json|node)等后缀结尾的文件是否存在
}梳理下上面查询模块时的一个策略:
require模块的时候,传入的字符串最后一个字符不是/时:如果是个文件,那么直接返回这个文件的路径
如果是个文件夹,那么会找个这个文件夹下是否有package.json文件,以及这个文件当中的main字段对应的路径(对应源码当中的方法为tryPackage):
.js,.json,.node,.ms后缀去加载对应文件index.js,index.json,index.node文件如果以上2个方法都没有找到对应文件路径,那么就对文件路径后添加分别添加.js,.json,.node,.ms后缀去加载对应的文件(对应源码当中的方法为tryExtensions)
require模块的时候,传入的字符串最后一个字符是/时,即require的是一个文件夹时:index.js,index.json,index.node等文件当找到文件的路径后就调用tryModuleLoad开始加载模块了,这个方法内部实际上是调用了模块实例的load方法:
Module.prototype.load = function () {
...
this.filename = filename;
// 定义module的paths。获取这个module路径上所有可能的node_modules路径
this.paths = Module._nodeModulePaths(path.dirname(filename));
var extension = path.extname(filename) || '.js';
if (!Module._extensions[extension]) extension = '.js';
// 开始load这个文件
Module._extensions[extension](this, filename);
this.loaded = true;
...
}调用Module._extension方法去加载不同格式的文件,就拿js文件来说:
Module._extensions['.js'] = function(module, filename) {
// 首先读取文件的文本内容
var content = fs.readFileSync(filename, 'utf8');
module._compile(internalModule.stripBOM(content), filename);
};内部调用了Module.prototype._compile这个方法:
Module.prototype._compile = function (content, filename)) {
content = internalModule.stripShebang(content);
// create wrapper function
// 将源码的文本包裹一层
var wrapper = Module.wrap(content);
// vm.runInThisContext在一个v8的虚拟机内部执行wrapper后的代码
var compiledWrapper = vm.runInThisContext(wrapper, {
filename: filename,
lineOffset: 0,
displayErrors: true
});
var inspectorWrapper = null;
if (process._breakFirstLine && process._eval == null) {
if (!resolvedArgv) {
// we enter the repl if we're not given a filename argument.
if (process.argv[1]) {
resolvedArgv = Module._resolveFilename(process.argv[1], null, false);
} else {
resolvedArgv = 'repl';
}
}
// Set breakpoint on module start
if (filename === resolvedArgv) {
delete process._breakFirstLine;
inspectorWrapper = process.binding('inspector').callAndPauseOnStart;
}
}
var dirname = path.dirname(filename);
// 构造require函数
var require = internalModule.makeRequireFunction(this);
var depth = internalModule.requireDepth;
if (depth === 0) stat.cache = new Map();
var result;
if (inspectorWrapper) {
result = inspectorWrapper(compiledWrapper, this.exports, this.exports,
require, this, filename, dirname);
} else {
// 开始执行这个函数
// 传入的参数依次是 module.exports / require / module / filename / dirname
result = compiledWrapper.call(this.exports, this.exports, require, this,
filename, dirname);
}
if (depth === 0) stat.cache = null;
return result;
}
Module.wrap = function(script) {
return Module.wrapper[0] + script + Module.wrapper[1];
};
Module.wrapper = [
'(function (exports, require, module, __filename, __dirname) { ',
'\n});'
];Module.wrap将源码包裹一层(遵循commonJS规范)vmv8虚拟机暴露出来的方法来构造一个新的函数通过源码发现,Module.wrapper在对源码文本进行包裹的时候,传入了5个参数:
是对于第三个参数module的exports属性的引用
这个require并非是Module.prototype.require方法,而是通过internalModule.makeRequireFunction重新构造出来的,这个方法内部还是依赖Module.prototype.require方法去加载模块的,同时还对这个require方法做了一些拓展。
module对象,如果需要向外暴露API供其他模块来使用,需要在module.exports属性上定义
当前文件的绝对路径
当前文件的父文件夹的绝对路径
特别注意第一个参数和第三参数的联系:第一参数是对于第三个参数的exports属性的引用。一旦将某个模块exports赋值给另外一个新的对象,那么就断开了exports属性和module.exports之间的引用关系,同时在其他模块当中也无法引用在当前模块中通过exports暴露出去的API,对于模块的引用始终是获取module.exports属性。
官方示例:
a.js
console.log('a 开始');
exports.done = false;
const b = require('./b.js');
console.log('在 a 中,b.done = %j', b.done);
exports.done = true;
console.log('a 结束');b.js
console.log('b 开始');
exports.done = false;
const a = require('./a.js');
console.log('在 b 中,a.done = %j', a.done);
exports.done = true;
console.log('b 结束');main.js
console.log('main 开始');
const a = require('./a.js');
const b = require('./b.js');
console.log('在 main 中,a.done=%j,b.done=%j', a.done, b.done);$ node main.js
main 开始
a 开始
b 开始
在 b 中,a.done = false
b 结束
在 a 中,b.done = true
a 结束
在 main 中,a.done=true,b.done=true在a模块加载时,需要加载b模块,但是在实际加载a模块之前,就已经将a模块进行的缓存,具体参见Module._load方法:
Module._cache[filename] = module;
tryModuleLoad(module, filename);因为在加载b模块的过程中再次去加载a模块的时候,这时是直接从缓存中获取a模块导出的API,此时exports.done的属性还是false,未被设置为true,只有当b模块被完全加载后,a模块exports属性才被设置为true。
Webpack 对于一个 module 所使用的 loader 对开发者提供了2种使用方式:
// webpack.config.js
module.exports = {
...
module: {
rules: [{
test: /.vue$/,
loader: 'vue-loader'
}, {
test: /.scss$/,
use: [
'vue-style-loader',
'css-loader',
{
loader: 'sass-loader',
options: {
data: '$color: red;'
}
}
]
}]
}
...
}// module
import a from 'raw-loader!../../utils.js'2种不同的配置形式,在 webpack 内部有着不同的解析方式。此外,不同的配置方式也决定了最终在实际加载 module 过程中不同 loader 之间相互的执行顺序等。
在讲 loader 的匹配过程之前,首先从整体上了解下 loader 在整个 webpack 的 workflow 过程中出现的时机。

在一个 module 构建过程中,首先根据 module 的依赖类型(例如 NormalModuleFactory)调用对应的构造函数来创建对应的模块。在创建模块的过程中(new NormalModuleFactory()),会根据开发者的 webpack.config 当中的 rules 以及 webpack 内置的 rules 规则实例化 ruleset 匹配实例,这个 ruleset 实例在 loader 的匹配过滤过程中非常的关键,具体的源码解析可参见Webpack Loader Ruleset 匹配规则解析。实例化 ruleset 后,还会注册2个钩子函数:
class NormalModuleFactory {
...
// 内部嵌套 resolver 的钩子,完成相关的解析后,创建这个 normalModule
this.hooks.factory.tap('NormalModuleFactory', () => (result, callback) => { ... })
// 在 hooks.factory 的钩子内部进行调用,实际的作用为解析构建一共 module 所需要的 loaders 及这个 module 的相关构建信息(例如获取 module 的 packge.json等)
this.hooks.resolver.tap('NormalModuleFactory', () => (result, callback) => { ... })
...
}当 NormalModuleFactory 实例化完成后,并在 compilation 内部调用这个实例的 create 方法开始真实开始创建这个 normalModule。首先调用hooks.factory获取对应的钩子函数,接下来就调用 resolver 钩子(hooks.resolver)进入到了 resolve 的阶段,在真正开始 resolve loader 之前,首先就是需要匹配过滤找到构建这个 module 所需要使用的所有的 loaders。首先进行的是对于 inline loaders 的处理:
// NormalModuleFactory.js
// 是否忽略 preLoader 以及 normalLoader
const noPreAutoLoaders = requestWithoutMatchResource.startsWith("-!");
// 是否忽略 normalLoader
const noAutoLoaders =
noPreAutoLoaders || requestWithoutMatchResource.startsWith("!");
// 忽略所有的 preLoader / normalLoader / postLoader
const noPrePostAutoLoaders = requestWithoutMatchResource.startsWith("!!");
// 首先解析出所需要的 loader,这种 loader 为内联的 loader
let elements = requestWithoutMatchResource
.replace(/^-?!+/, "")
.replace(/!!+/g, "!")
.split("!");
let resource = elements.pop(); // 获取资源的路径
elements = elements.map(identToLoaderRequest); // 获取每个loader及对应的options配置(将inline loader的写法变更为module.rule的写法)首先是根据模块的路径规则,例如模块的路径是以这些符号开头的 ! / -! / !! 来判断这个模块是否只是使用 inline loader,或者剔除掉 preLoader, postLoader 等规则:
! 忽略 webpack.config 配置当中符合规则的 normalLoader-! 忽略 webpack.config 配置当中符合规则的 preLoader/normalLoader!! 忽略 webpack.config 配置当中符合规则的 postLoader/preLoader/normalLoader这几个匹配规则主要适用于在 webpack.config 已经配置了对应模块使用的 loader,但是针对一些特殊的 module,你可能需要单独的定制化的 loader 去处理,而不是走常规的配置,因此可以使用这些规则来进行处理。
接下来将所有的 inline loader 转化为数组的形式,例如:
import 'style-loader!css-loader!stylus-loader?a=b!../../common.styl'最终 inline loader 统一格式输出为:
[{
loader: 'style-loader',
options: undefined
}, {
loader: 'css-lodaer',
options: undefined
}, {
loader: 'stylus-loader',
options: '?a=b'
}]对于 inline loader 的处理便是直接对其进行 resolve,获取对应 loader 的相关信息:
asyncLib.parallel([
callback =>
this.resolveRequestArray(
contextInfo,
context,
elements,
loaderResolver,
callback
),
callback => {
// 对这个 module 进行 resolve
...
callack(null, {
resouceResolveData, // 模块的基础信息,包含 descriptionFilePath / descriptionFileData 等(即 package.json 等信息)
resource // 模块的绝对路径
})
}
], (err, results) => {
const loaders = results[0] // 所有内联的 loaders
const resourceResolveData = results[1].resourceResolveData; // 获取模块的基本信息
resource = results[1].resource; // 模块的绝对路径
...
// 接下来就要开始根据引入模块的路径开始匹配对应的 loaders
let resourcePath =
matchResource !== undefined ? matchResource : resource;
let resourceQuery = "";
const queryIndex = resourcePath.indexOf("?");
if (queryIndex >= 0) {
resourceQuery = resourcePath.substr(queryIndex);
resourcePath = resourcePath.substr(0, queryIndex);
}
// 获取符合条件配置的 loader,具体的 ruleset 是如何匹配的请参见 ruleset 解析(https://github.com/CommanderXL/Biu-blog/issues/30)
const result = this.ruleSet.exec({
resource: resourcePath, // module 的绝对路径
realResource:
matchResource !== undefined
? resource.replace(/\?.*/, "")
: resourcePath,
resourceQuery, // module 路径上所带的 query 参数
issuer: contextInfo.issuer, // 所解析的 module 的发布者
compiler: contextInfo.compiler
});
// result 为最终根据 module 的路径及相关匹配规则过滤后得到的 loaders,为 webpack.config 进行配置的
// 输出的数据格式为:
/* [{
type: 'use',
value: {
loader: 'vue-style-loader',
options: {}
},
enforce: undefined // 可选值还有 pre/post 分别为 pre-loader 和 post-loader
}, {
type: 'use',
value: {
loader: 'css-loader',
options: {}
},
enforce: undefined
}, {
type: 'use',
value: {
loader: 'stylus-loader',
options: {
data: '$color red'
}
},
enforce: undefined
}] */
const settings = {};
const useLoadersPost = []; // post loader
const useLoaders = []; // normal loader
const useLoadersPre = []; // pre loader
for (const r of result) {
if (r.type === "use") {
// postLoader
if (r.enforce === "post" && !noPrePostAutoLoaders) {
useLoadersPost.push(r.value);
} else if (
r.enforce === "pre" &&
!noPreAutoLoaders &&
!noPrePostAutoLoaders
) {
// preLoader
useLoadersPre.push(r.value);
} else if (
!r.enforce &&
!noAutoLoaders &&
!noPrePostAutoLoaders
) {
// normal loader
useLoaders.push(r.value);
}
} else if (
typeof r.value === "object" &&
r.value !== null &&
typeof settings[r.type] === "object" &&
settings[r.type] !== null
) {
settings[r.type] = cachedMerge(settings[r.type], r.value);
} else {
settings[r.type] = r.value;
}
// 当获取到 webpack.config 当中配置的 loader 后,再根据 loader 的类型进行分组(enforce 配置类型)
// postLoader 存储到 useLoaders 内部
// preLoader 存储到 usePreLoaders 内部
// normalLoader 存储到 useLoaders 内部
// 这些分组最终会决定加载一个 module 时不同 loader 之间的调用顺序
// 当分组过程进行完之后,即开始 loader 模块的 resolve 过程
asyncLib.parallel([
[
// resolve postLoader
this.resolveRequestArray.bind(
this,
contextInfo,
this.context,
useLoadersPost,
loaderResolver
),
// resove normal loaders
this.resolveRequestArray.bind(
this,
contextInfo,
this.context,
useLoaders,
loaderResolver
),
// resolve preLoader
this.resolveRequestArray.bind(
this,
contextInfo,
this.context,
useLoadersPre,
loaderResolver
)
],
(err, results) => {
...
// results[0] -> postLoader
// results[1] -> normalLoader
// results[2] -> preLoader
// 这里将构建 module 需要的所有类型的 loaders 按照一定顺序组合起来,对应于:
// [postLoader, inlineLoader, normalLoader, preLoader]
// 最终 loader 所执行的顺序对应为: preLoader -> normalLoader -> inlineLoader -> postLoader
// 不同类型 loader 上的 pitch 方法执行的顺序为: postLoader.pitch -> inlineLoader.pitch -> normalLoader.pitch -> preLoader.pitch (具体loader内部执行的机制后文会单独讲解)
loaders = results[0].concat(loaders, results[1], results[2]);
process.nextTick(() => {
...
// 执行回调,创建 module
})
}
])
}
})简单总结下匹配的流程就是:
首先处理 inlineLoaders,对其进行解析,获取对应的 loader 模块的信息,接下来利用 ruleset 实例上的匹配过滤方法对 webpack.config 中配置的相关 loaders 进行匹配过滤,获取构建这个 module 所需要的配置的的 loaders,并进行解析,这个过程完成后,便进行所有 loaders 的拼装工作,并传入创建 module 的回调中。
声明文件即存放你声明的地方,声明包括命名空间、类型及值这三类。
在我们使用TS进行项目开发的时候会定义各种类型、变量、函数、对象等内容。这些内容有可能仅仅是作为项目内部来用,但是当你的项目是作为其他TS项目的依赖来使用的话,其他项目需要引用你的项目并调用相关模块或者方法进行开发。但是这些项目却不能很好的利用你内部的类型来做类型检查,所以你需要做的一项工作就是将相关的类型、变量、函数等给暴露出来,让其他项目在编译TS代码的时候,使用相关的类型去更好的做类型检查。简单点理解就是别人的TS项目在使用你所提供的TS项目时,别人的项目如果想做类型检查,那么就需要在你的项目当中通过声明文件将相关类型暴露出去。这就是声明文件最终的作用。
声明文件以.d.ts的后缀结尾。
如果某个文件遵循 ES Module/CommonJS/AMD 等模块书写规范的声明文件即为模块声明。如果这个文件没有出现相关模块规范的书写形式,而是仅仅有顶级的声明语句,那么这个文件即为全局声明文件。
全局声明文件里面的声明可以在其他任意的TS文件当中进行使用,而不用单独的导入。而模块声明如果需要被其他模块文件使用的话就需要进行相关的导入操作了。
当你使用 npm 包的形式去引入模块。
import foo from 'foo'node_modules/@types/foonode_modules/foo/index.d.tsnode_modules/foo/package.json 当中定义的typing或者types2个字段中的一个node_modules/foo/package.josn 当中定义的main入口文件相同文件名的声明文件,例如index.js / index.d.ts,如果typings或者types存在的话,是不会去找main入口当中同文件名的声明文件的此外,如果这个 npm 包没有提供声明文件,那么这个时候就需要自己去写声明文件。推荐大家在自己项目目录里面单独建一个types文件夹来存放相关的声明文件。但是依据上面的规则,TS是没法找到我们给这个 npm 包书写的声明文件的。所以需要通过tsconfig.json文件进行指定:
{
"compilerOptions": {
"baseUrl": "./", // 解析的基础目录
"paths": {
"*": ["types/*"]
}
}
}通过这样的配置后(具体有关baseUrl和paths字段的配置请参考文档),foo模块的声明文件除了会去node_modules目录下找,还会去当前项目的types/foo目录下去找:
projectRoot
├── src
│ └── index.ts
├── types
│ └── foo
│ └── index.d.ts
└── tsconfig.jsondeclare 关键字这个关键字就是告诉TS的编译系统,在这里我声明了一个类型、变量等内容,非常的语义化。它可以使用到TS的 runtime 代码当中:
// index.ts
declare class Foo {
constructor() {}
}
const foo = new Foo()最终declare关键字不会输出到编译后的文件当中的。在这里你不使用declare关键字也是没有问题的。
当然你也可以在声明文件当中使用declare关键字:
declare namespace Memo {
export class M {
constructor(str: string)
}
}在声明文件当中还是推荐使用declare关键字,这样语义化更好,也更加清晰。
import xxx = require('...')在网上找了一圈有关这个语法的说明,说是遵循 CommonJs 规范的 npm 包在书写声明文件的时候需要使用export = 这个语法去完成声明的导出。然后在你的业务代码中,如果需要引入这个 npm 包,就需要使用import xxx = require('...')这种TS独创的语法。
但是在我实际写代码的过程中(TS版本为3.x)发现,就算是遵循 CommonJs 规范的 npm 包,在书写声明文件的时候也是可以不用export =这种语法的,而可以使用 Es Module 的导出语法export,同时你的业务代码引入这个 npm 包的时候,也可以直接使用 Es Module 的导入语法import xxx from 'xxx',TS编译器也会加载对应的声明文件来完成类型检查。
有关这个问题我也查阅了相关的资料,都是指出 CommonJs 规范的模块在写声明文件的时候需要使用export =这样的语法来完成:
https://stackoverflow.com/questions/35706164/typescript-import-as-vs-import-require
microsoft/TypeScript#7185
https://tasaid.com/blog/2019022017450863.html
https://tasaid.com/blog/20171102225101.html#import-dao-ru-he-export-dao-chu
export as namespace xxx这个语法主要是为了解决一些库即可以通过模块的形式去引入,也可以通过<script>标签的形式全局引入(一般这些库的设计都是定义一个独有的全局变量,通过对这个全局变量进行拓展),即被称为UMD库。当你通过<script>标签这种形式引入的话,那么就需要一个声明文件进行一个全局的声明。为了解决这个问题,TS提供了export as namespace这个语法,可以将这个 namespace 名声明为全局的,其内部声明的其他的类型、函数、变量等都为这个 namespace 的子属性。
具体有关内容可参见文档
和其他语言相比,javascript中的对于undefined的理解还是有点让人困惑的。特别是试着理解ReferenceErrors错误("x is not defined")以及在编码过程中如何去避免这些错误总让人感到比较困惑。
这篇文章是我整理的关于这个知识点的内容。如果你对于javascript中的变量以及属性还不是很熟悉的话,你可以看看我之前写的文章
##undefined是什么?
在Javascript中,存在着Undefined(基本类型),undefined(值),以及defedined(变量)。
**Undefined(基本类型)**是js内置的基本类型之一(String, Number, Boolean, Null, Object)
**undefined(值)**是一个原始值,是未定义类型的基础值。任何未被赋值的属性值都可以假设为undefined。无返回值或者返回值为空的函数最后执行得到的值都未undefined。未设定的函数参数值也为undefined.
var a;
typeof a; // undefined
window.b;
typeof window.b; // undefined
var c = (function() {})();
typeof c; // undefined
var d = (function(e) {return e})();
typeof d; // undefined**undefined(变量)**是初始值为undefined的全局属性,既然它是个全局属性,那么我们也可以通过变量来获取它。例如我在这篇文章里面像这样将它作为一个变量来获取它。
typeof undefined; // undefined
var f = 2;
f = undefined; //重新将变量f赋值为变量undefined
typeof f; // undefined在ECMA3当中,它的值可以重新被赋值:
undefined = 'washing machine';
typeof undefined; // string
f = undefined;
typeof f; // string
f; // 'washing machine'不用说,将undefined重新赋值是一个比较糟糕的用法。事实上再ECMA5当中这种做法也是不被允许的。
##And then there's null?
大致上我们了解这两者之间的区别,但是还是需要重新复述一遍:undefined和null相比,undefined是一个原始值,它表示一个缺省值。undefined和null之间唯一相似的地方就是它们都能被通过类型转换成false。
##So what's a RefernceError?
一个ReferenceError表示编译器检测到一个无效的引用值。
在实际情况中,ReferenceError往往是在Javascript获取一个未被赋值的引用时被抛出。
注意下在不同浏览器中,ReferenceError现在的不同的语法错误提示信息。正如我们看到的,在不同浏览器中,错误信息并非特别的清楚明了。
alert(foo);
//FF/Chrome: foo is not defined
//IE: foo is undefined
//Safari: can't find variable foo##Still not clear ..."unresolvable reference"?
在ECMA标准中,一个引用值包含一个引用名称及一个基本值。
如果这个引用是一个属性,那么基础值及这个引用分别位于点号的两侧:
window.foo; // base value = window, reference name = foo;
a.b; //base value = a, reference name = b;
myObj['create']; //base value = myObj, reference name = create;
//Safari, Chrome, IE8+ only
Object.defineProperty(window, 'foo', {value: 'hello'});
//base value = window. reference name = foo;对于引用变量来说,基础值是当前执行上下文的变量对象。全局上线文的变量对象就是全局对象自己(浏览器当中是window)。任何一个函数上下文都有一个被称为活动对象的变量对象。(这个活动对象取决于调用这个函数的执行context)
var foo; //base value = window, reference name = foo;
function a() {
var b; // base value = <code>ActivationObject</code>, reference name = b;
}如果一个引用的基础值是undefined的话,那么这个引用就被认为unresolvable
因此,如果点号前面的值为undefined,那么这个属性引用就是unresolved。下面的这个例子就会抛出一个ReferenceError的错误,但是这并非是因为TypeError在此之前就被抛出。这是因为一个属性的基础值是属于CheckObjectCoercible,当试着将一个Undefined类型的转化为一个Object,那么这种情况下会抛出TypeError;
var foo;
foo.bar; //TypeError (base value, foo, is undefined)
bar.baz; //ReferenceError (bar is unresolvable)
undefined.foo //TypeError (base value is undefined)如果使用var关键字,那么将会确保变量对象始终有基础值,那么就不会出现引用变量unresolvable的情况。
当引用被定义的时候既不是属性值也不是变量的时候将会抛出一个ReferenceError:
foo; //ReferenceErrorJavascript检测到引用名foo没有明确的基础值,因此就会去寻找属性名为foo的变量对象。没有找到的话,就会认为引用名foo没有基础值并抛出ReferenceError的错误。
##But isn't foo just a undeclared variable?
技术上来说不是。尽管有时候我们觉得undeclared variable是有利用我们去排查bug。但是事实上如果一个变量未被声明的话也就不是一个变量。
##What about implicit globals?
未通过var关键字声明的标识符将会默认当做全局变量而被创建,但这只会在这些标识符被赋值的情况下才会生效。
function a() {
alert(foo); // ReferenceError
bar = [1, 2, 3]; // no error, bar is global
}
a();
bar; // [1, 2, 3]这确实让人有点困惑。如果Javascript检测到unresolvable的引用就直接抛出ReferenceErrors就更好了。(事实上在严格模式下javascript确实是这样做的)
#When do I need to code against ReferenceErrors?
如果你的代码写的很合理。我们发现在典型的用法中只有一种方式会遇到unresolvable reference: 当使用属性或者变量的句法不正确的时候。在大多数情况下,如果你能确保声明变量的时候使用var关键字时即可避免这种情况。在代码运行过程中唯一可能会遇到的情况就是引用的变量仅仅存在于部分浏览器或者第三方的代码当中。
一个比较好的例子就是console.在webkit浏览器中,console是内置的,console这个属性可以在任何地方获取到。Firefox中console属性取决于Firebug是否被安装以及被打开使用。IE7下没有console,IE8下的console属性仅存在于IE Developer Tools被启动的情况下。Opera明显是有console属性的,但是我从来没用使用过。
最后的结果就是,下面的代码在浏览器中运行时还是有可能会抛出ReferenceError的错误。
console.log(new Date());##How do I code against variables that may not exist?
一种方式就是去通过使用typeof关键字去嗅探一个unresolvable reference,避免抛出ReferenceError错误:
if (typeof console != 'undefined') {
console.log(new Date());
}然而这种方法对我来说太啰嗦了,更不用说合理了。我是比较反对使用typeof去进行类型检测的。
幸运的是还有另外一种方式:我们已经知道基础值被定义了,但是属性未被定义是不会抛出ReferenceError。console是全局对象的属性值,因此我们可以这样做:
window.console && console.log(new Date());事实上在全局环境下仅仅只需要检测变量是否存在(函数中也存在着执行上下文,你可以决定哪些变量可以存在于你的函数当中)。因此理论上至少你可以避免使用typeof来消除ReferenceError的情况。
在之前做一些前端国际化的项目的时候,因为业务不是很复杂,相关的需求一般都停留在文案的翻译上,即国际化多语言,基本上使用相关的 I18n 插件即可满足开发的需求。但是随着业务的迭代和需求复杂度的增加,这些 I18n 插件不一定能满足相关的需求开发,接下来就和大家具体聊下在做国际化项目的过程中所遇到的问题以及所做的思考。
因为团队的技术栈主要是基于 Vue,因此相关的解决方案也是基于 Vue 以及相关的国际化插件(vue-i18n)进行展开。
我们借助 vue-i18n 来完成相关国际化的工作。当项目比较简单,没有大量语言包文件的时候,将语言包直接打包进业务代码中是没有太大问题的。不过一旦语言包文件多起来,这个时候是可以考虑将语言包单独打包,减少业务代码体积,通过异步加载的方式去使用。此外,考虑到国际化语言包相对来说是非高频修改的内容,因此可以考虑将语言包进行缓存,每次页面渲染时优先从缓存中获取语言包来加快页面打开速度。
关于分包相关的工作可以借助 webpack 来自动完成分包及异步加载的工作。从 1.x 的版本开始,webpack 便提供了 require.ensure() 等相关 API 去完成语言包的分包的工作,不过那个时候 require.ensure() 必须要接受一个指定的路径,从 2.6.0 版本开始,webpack的 import 语法可以指定不同的模式解析动态导入,具体可以参见文档。因此结合 webpack 及 vue-i18n 提供的相关的 API 即可完成语言包的分包及异步加载语言包,同时在运行时完成语言的切换的工作。
示例代码:
文件目录结构:
src
|--components
|--pages
|--di18n-locales // 项目应用语言包
| |--zh-CN.js
| |--en-US.js
| |--pt-US.js
|--App.vue
|--main.jsmain.js:
import Vue from 'vue'
import VueI18n from 'vue-i18n'
import App from './App.vue'
Vue.use(VueI18n)
const i18n = new VueI18n({
locale: 'en',
messages: {}
})
function loadI18nMessages(lang) {
return import(`./di18n-locales/${lang}`).then(msg => {
i18n.setLocaleMessage(lang, msg.default)
i18n.locale = lang
return Promise.resolve()
})
}
loadI18nMessages('zh').then(() => {
new Vue({
el: '#app',
i18n,
render: h => h(App)
})
})以上首先解决了语言包的分包和异步加载的问题。
接下来聊下关于如果给语言包做缓存,以及相关的缓存机制,大致的思路是:
打开页面后,优先判断 localStorage 是否存在对应语言包文件,如果有的话,那么直接从 localStorage 中同步的获取语言包,然后完成页面的渲染,如果没有的话,那么需要异步从 CDN 获取语言包,并将语言包缓存到 localstorage 当中,然后完成页面的渲染.
当然在实现的过程中还需要考虑到以下的问题:
首先在代码编译的环节,通过 webpack 插件去完成每次编译后,语言包的版本 hash 值的收集工作,同时注入到业务代码当中。当页面打开,业务代码开始运行后,首先会判断业务代码中语言包的版本和 localStorage 中缓存的版本是否一致,如果一致则同步获取对应语言包文件,若不一致,则异步获取语言包
数据都是存储到 localStorage 当中的, localStorage 因为是按域名进行划分的,所以如果多个国际化项目部署在同一域名下,那么可按项目名进行 namespace 的划分,避免语言包/版本hash被覆盖。
以上是初期对于国际化项目做的一些简单的优化。总结一下就是:语言包单独打包成 chunk,并提供异步加载及 localStorage 存储的功能,加快下次页面打开速度。
随着项目的迭代和国际化项目的增多,越来越多的组件被单独抽离成组件库以供复用,其中部分组件也是需要支持国际化多语言。
其中关于这部分的内容,vue-i18n 现阶段也是支持组件国际化的,具体的用法请参加文档,大致的套路就是提供局部注册 vue-i18n 实例对象的能力,每当在子组件内部调用翻译函数$t,$tc等时,首先会获取子组件上实例化的 vue-i18n 对象,然后去做局部的语言 map 映射。
它所提供的方式仅仅限于语言包的局部 component 注册,在最终代码编译打包环节语言包最终也会被打包进业务代码当中,这也与我们初期对于国际化项目所做的优化目标不太兼容(当然如果你的 component 是异步组件的话是没问题的)。
为了在初期目标的基础上继续完善组件的国际化方案,这里我们试图将组件的语言包和组件进行解耦,即组件不需要单独引入多语言包,同时组件的语言包也可以通过异步的方式去加载。
这样在我们的预期范围内,可能会遇到如下几个问题:
首先在我们小组内部,后编译(关于后编译可以戳我)应该是我们技术栈的标配,因此我们的组件库最终也是通过源码的形式直接发布,项目应用当中通过按需引入+后编译的方式进行使用。
项目应用的多语言包组织应该问题不大,一般放置于一个独立的目录(di18n-locales)当中:
// 目录结构:
src
├── App.vue
├── di18n-locales
│ ├── en-US.js
│ └── zh-CN.js
└── main.js
// en-US.js
export default {
messages: {
'en-US': {
viper: 'viper',
sk: 'sk'
}
}
}
// zh-CN.js
export default {
messages: {
'zh-CN': {
viper: '冥界亚龙',
sk: '沙王'
}
}
}di18n-locales 目录下的每个语言包最终会单独打包成一个 chunk,所以这里我们考虑是否可以将组件库当中每个组件自己的语言包最终也和项目应用下的语言包打包在一起为一个 chunk:即项目应用的 en-US.js 和组件库当中所有被项目引用的组件对应的 en-US.js 打包在一起,其他语言包与此相同。这样做的目的是为了将组件库的语言包和组件进行解耦(与 vue-i18n 的方案正好相反),同时和项目应用的语言包进行统一的打包,以供异步加载。向着这样一个目的,我们在规划组件库的目录时,做了如下的约定:与每个组件同级也会有一个 di18n-locales(与项目应用的语言包目录保持一致,当然也支持可配)目录,这个目录下存放了每个组件对应的多语言包:
├── node_modules
| ├── @didi
| ├── common-biz-ui
| └── src
| └── components
| ├── coupon-list
| │ ├── coupon-list.vue
| │ └── di18n-locales
| │ ├── en.js // coupon-list组件对应的en语言包
| │ └── zh.js // coupon-list组件对应的zh语言包
| └── withdraw
| ├── withdraw.vue
| └── di18n-locales
| ├── en.js // withdraw组件对应的en语言包
| └── zh.js // withdraw组件对应的zh语言包
├── src
│ ├── App.vue
│ ├── di18n-locales
│ │ ├── en.js // 项目应用 en 语言包
│ │ └── zh.js // 项目应用 zh 语言包
│ └── main.js当你的项目应用当中使用了组件库当中的某个组件时:
// App.vue
<template>
...
</template>
<script>
import couponList from 'common-biz-ui/coupon-list'
export default {
components: {
couponList
}
}
</script>那么在不需要你手动引入语言包的情况下:
coupon-list 这个组件下的语言包?coupon-list 组件所使用的语言包打包进项目应用对应的语言包当中并输出一个 chunk?为此我们开发了一个 webpack 插件:di18n-webpack-plugin。用以解决以上2个问题,我们来看下这个插件的核心代码:
compilation.plugin('finish-modules', function(modules) {
...
for(const module of modules) {
const resource = module.resource || ''
if (that.context.test(resource)) {
const dirName = path.dirname(resource)
const localePath = path.join(dirName, 'di18n-locales')
if (fs.existsSync(localePath) && !di18nComponents[dirName]) {
di18nComponents[dirName] = {
cNameArr: [],
path: localePath
}
const files = fs.readdirSync(dirName)
files.forEach(file => {
if (path.extname(file) === '.vue') {
const baseName = path.basename(file, '.vue')
const componentPath = path.join(dirName, file)
const prefix = getComponentPrefix(componentPrefixMap, componentPath)
let componentName = ''
if (prefix) {
// transform to camelize style
componentName = `${camelize(prefix)}${baseName.charAt(0).toUpperCase()}${camelize(baseName.slice(1))}`
} else {
componentName = camelize(baseName)
}
// component name
di18nComponents[dirName].cNameArr.push(componentName)
}
})
...
}
}
})原理就是在 finish-modules 这个编译的阶段,所有的 module 都完成了编译,那么这个阶段便可以找到在项目应用当中到底使用了组件库当中的哪些组件,即组件对应的绝对路径,因为我们之前已经约定好了和组件同级的会有一个 di18n-locales 目录专门存放组件的多语言文件,所以对应的我们也能找到这个组件使用的语言包。最终通过这样一个钩子函数,以组件路径作为 key,完成相关的收集工作。这样上面的第一个问题便解决了。
接下来看下第二个问题。当我们通过 finish-modules 这个钩子拿到都有哪些组件被按需引入后,但是我们会遇到一个非常尴尬的问题,就是 finish-modules 这个阶段是在所有的 module 完成编译后触发的,这个阶段之后便进入了 seal 阶段,但是在 seal 阶段里面不会再去做有关模块编译的工作。
但是通过阅读 webpack 的源码,我们发现了在 compilation 上定义了一个 rebuildModule 的方法,从方法名上看应该是对一个 module 的进行重新编译,具体到方法的内部实现确实是调用了 compliation 对象上的 buildModule 方法去对一个 module 进行编译:
class Compilation extends Tapable {
constructor() {
...
}
...
rebuildModule() {
...
this.buildModule(module, false, module, null, err => {
...
})
}
...
}因为从一开始我们的目标就是组件库当中的多语言包和组件之间是相互解耦的,同时对于项目应用来说是无感知的,因此是需要 webpack 插件在编译的阶段去完成打包的工作的,所以针对上面第二个问题,我们尝试在 finish-modules 阶段完成后,拿到所有的被项目使用的组件的多语言包路径,然后自动完成将组件多语言包作为依赖添加至项目应用的语言包的源码当中,并通过 rebuildModule 方法重新对项目应用的语言包进行编译,这样便完成了将无感知的语言包作为依赖注入到项目应用的语言包当中。
webpack 的 buildModule 的流程是:

我们看到在 rebuild 的过程当中, webpack 会再次使用对应文件类型的 loader 去加载相关文件的源码到内存当中,因此我们可以在这个阶段完成依赖语言包的添加。我们来看下 di18n-webpack-plugin 插件的关于这块内容的核心代码:
compilation.plugin('build-module', function (module) {
if (!module.resource) {
return
}
// di18n rules
if (/src\/di18n-locales\//.test(module.resource) && module.createSource.name !== 'di18nCreateSource') {
...
if (!componentMsgs.length) {
return createSource.call(this, source, resourceBuffer, sourceMap)
}
let vars = []
const varReg = /export\s+default\s+([^{;]+)/
const exportDefaultVar = source.match(varReg)
source = `
${componentMsgs.map((item, index) => {
const varname = `di18n${index + 1}`
const { path, cNameStr } = item
vars.push({
varname,
cNameStr
})
return `import ${varname} from "${path}";`
}).join('')}
${
exportDefaultVar
? source.replace(varReg, function (_, m) {
return `
${m}.components = {
${getComponentMsgMap(vars)}
};
export default ${m}
`
})
: source.replace(/export\s+default\s*\{([^]+)\}/i, function (_, m) {
return `export default {${m},
components: {
${getComponentMsgMap(vars)}
}
}
`
})
}
`
resourceBuffer = new Buffer(source)
return createSource.call(this, source, resourceBuffer, sourceMap)
}
}
})原理就是利用 webpack 对 module 开始进行编译时暴露出来的 build-module 钩子,它的 callback 传参为当前正在编译的 module ,这个时候我们对 createSource 方法进行了一层代理,即在 createSource 方法调用前,我们通过改写项目应用语言包的源码来完成组件的语言包的引入。之后的流程还是交由 webpack 来进行处理,最终项目应用的每个语言包会单独打包成一个 chunk,且这个语言包中还将按需引入的组件的语言包一并打包进去了。
最终达到的效果就是:
// 原始的项目应用中文(zh.js)语言包
export default {
messages: {
zh: {
hello: '你好',
goodbye: '再见'
}
}
}通过 di18n-webpack-plugin 插件处理后的项目应用中文语言包:
// 将项目依赖的组件对应的语言包自动引入项目应用当中的语言包当中并完成编译输出为一个chunk
import bizCouponList from 'xxxx/xxxx/node_modules/xxx/src/components/coupon-list/di18n-locales/zh.js' // 组件语言包的路径为绝对路径
export default {
messages: {
zh: {
hello: '你好',
goodbye: '再见'
}
},
components: {
bizCouponList
}
}(在这里我们引入组件的语言包后,我们项目语言包中新增一个 components 字段,并将子组件的名字作为 key ,子组件的语言包作为 value ,挂载至 components 字段。)
上述过程即解决了之前提出来的几个问题:
现在我们通过 webpack 插件在编译环节已经帮我解决了项目语言包和组件语言包的组织,构建打包等问题。但是还有一个问题暂时还没解决,就是我们将组件语言包和组件进行解耦后,即不再按 vue-i18n 提供的多语言局部注册的方式,而是将组件的语言包收敛至项目应用下的语言包,那么如何才能完成组件的文案翻译工作呢?
我们都清楚 Vue 在创建子 component 的 VNode 过程当中,会给每个 VNode 创建一个唯一的 component name:
// src/core/vdom/create-component.js
export function createComponent() {
...
const vnode = new VNode(
`vue-component-${Ctor.cid}${name ? `-${name}` : ''}`,
data, undefined, undefined, undefined, context,
{ Ctor, propsData, listeners, tag, children },
asyncFactory
)
...
}在实际的使用过程当中,我们要求组件必须要有自己唯一命名。
vue-i18n 提供的策略是局部注册 vue-i18n 实例对象,每当在子组件内部调用翻译函数$t,$tc等时,首先会获取子组件上实例化的 vue-i18n 对象,然后去做局部的语言 map 映射。这个时候我们可以换一种思路,我们将子组件的语言包做了统一管理,不在子组件上注册 vue-i18n 实例,但是每次子组件调用$t,$tc等翻译函数的时候,这个时候我们从统一的语言包当中根据这个子组件的 component-name 来取得对应的语言包的内容,并完成翻译的工作。
在上面我们也提到了我们是如何管理项目应用及组件之间的语言包的组织的:我们引入组件的语言包后,我们项目语言包中新增一个 components 字段,并将子组件的名字作为 key,子组件的语言包作为 value,挂载至 components 字段。这样当子组件调用翻译函数的方法时,始终首先去项目应用的语言包当中的 components 字段中找到对应的组件名的 key,然后完成翻译的功能,如果没有找到,那么兜底使用项目应用对应字段的语言文案。
以上就是我们对于近期所做的一些国际化项目的思考,总结一下就是:
事实上上面所做的工作都是为了更多的减少相关功能对于官方提供的插件的依赖,提供一种较为抹平技术栈的通用解决方案。
可写流是对数据写入“目的地”的一种抽象,可作为可读流的一种消费者。数据源可能多种多样,如果使用了可写流来完成数据的消费,那么就有可写流的内部机制来控制数据在生产及消费过程中的各状态的扭转等。

首先来看下可写流内部几个比较关键的状态:
function WritableState(options, stream) {
options = options || {};
// Duplex streams are both readable and writable, but share
// the same options object.
// However, some cases require setting options to different
// values for the readable and the writable sides of the duplex stream.
// These options can be provided separately as readableXXX and writableXXX.
var isDuplex = stream instanceof Stream.Duplex;
// object stream flag to indicate whether or not this stream
// contains buffers or objects.
this.objectMode = !!options.objectMode;
if (isDuplex)
this.objectMode = this.objectMode || !!options.writableObjectMode;
// the point at which write() starts returning false
// Note: 0 is a valid value, means that we always return false if
// the entire buffer is not flushed immediately on write()
var hwm = options.highWaterMark;
var writableHwm = options.writableHighWaterMark;
var defaultHwm = this.objectMode ? 16 : 16 * 1024;
if (hwm || hwm === 0)
this.highWaterMark = hwm;
else if (isDuplex && (writableHwm || writableHwm === 0))
this.highWaterMark = writableHwm;
else
this.highWaterMark = defaultHwm;
// cast to ints.
this.highWaterMark = Math.floor(this.highWaterMark);
// if _final has been called
this.finalCalled = false;
// drain event flag.
this.needDrain = false;
// at the start of calling end()
this.ending = false;
// when end() has been called, and returned
this.ended = false;
// when 'finish' is emitted
this.finished = false;
// has it been destroyed
this.destroyed = false;
// should we decode strings into buffers before passing to _write?
// this is here so that some node-core streams can optimize string
// handling at a lower level.
var noDecode = options.decodeStrings === false;
this.decodeStrings = !noDecode;
// Crypto is kind of old and crusty. Historically, its default string
// encoding is 'binary' so we have to make this configurable.
// Everything else in the universe uses 'utf8', though.
this.defaultEncoding = options.defaultEncoding || 'utf8';
// not an actual buffer we keep track of, but a measurement
// of how much we're waiting to get pushed to some underlying
// socket or file.
// 不是真实buffer的长度,而是等待被写入文件或者socket等的数据的长度
this.length = 0;
// a flag to see when we're in the middle of a write.
this.writing = false;
// when true all writes will be buffered until .uncork() call
this.corked = 0;
// a flag to be able to tell if the onwrite cb is called immediately,
// or on a later tick. We set this to true at first, because any
// actions that shouldn't happen until "later" should generally also
// not happen before the first write call.
this.sync = true;
// a flag to know if we're processing previously buffered items, which
// may call the _write() callback in the same tick, so that we don't
// end up in an overlapped onwrite situation.
this.bufferProcessing = false;
// the callback that's passed to _write(chunk,cb)
// onwrite偏函数,stream始终作为一个参数
this.onwrite = onwrite.bind(undefined, stream);
// the callback that the user supplies to write(chunk,encoding,cb)
this.writecb = null;
// the amount that is being written when _write is called.
this.writelen = 0;
// 缓存池中的头结点
this.bufferedRequest = null;
// 缓存池中的尾结点
this.lastBufferedRequest = null;
// number of pending user-supplied write callbacks
// this must be 0 before 'finish' can be emitted
this.pendingcb = 0;
// emit prefinish if the only thing we're waiting for is _write cbs
// This is relevant for synchronous Transform streams
this.prefinished = false;
// True if the error was already emitted and should not be thrown again
this.errorEmitted = false;
// count buffered requests
this.bufferedRequestCount = 0;
// allocate the first CorkedRequest, there is always
// one allocated and free to use, and we maintain at most two
var corkReq = { next: null, entry: null, finish: undefined };
corkReq.finish = onCorkedFinish.bind(undefined, corkReq, this);
this.corkedRequestsFree = corkReq;
}在实现的可写流当中必须要定义一个write方法,在可写流内部,这个方法会被赋值给一个内部_write方法,主要是在数据被消费的时候调用:
const { Writable } = require('stream')
const ws = new Writable({
write (chunk, encoding, cb) {
// chunk 即要被消费的数据
// encoding为编码方式
// cb为内部实现的一个onwrite方法,上面说的状态定义里面有关于这个说明,主要是在完成一次消费后需要手动调用这个cb方法来扭转内部状态,下面会专门讲解这个方法
}
})可写流对开发者暴露了一个write方法,这个方法用于接收数据源的数据,同时来完成数据向消费者的传递或者是将数据暂存于缓冲区当中。
让我们来看下一个简单的例子:
function writeOneMillionTimes(writer, data, encoding, callback) {
let i = 1000000;
write();
function write() {
let ok = true;
do {
i--;
if (i === 0) {
// 最后 一次
writer.write(data, encoding, callback);
} else {
// 检查是否可以继续写入。
// 这里不要传递 callback, 因为写入还没有结束!
ok = writer.write(data, encoding);
}
} while (i > 0 && ok);
if (i > 0) {
// 不得不提前停下!
// 当 'drain' 事件触发后继续写入
writer.once('drain', write);
}
}
}
const { Writable } = require('stream')
const ws = new Writable({
write (chunk, encoding, cb) {
// do something to consume the chunk
}
})
writeOneMillionTimes(ws, 'aaaaaa', 'utf8', function () {
console.log('this is Writable')
})程序开始后,首先可写流调用writer.write方法,将数据data传入到可写流当中,然后可写流内部来判断将数据是直接提供给数据消费者还是暂时先存放到缓冲区。
Writable.prototype.write = function (data, encoding, callback) {
var state = this._writableState;
// 是否可向可写流当中继续写入数据
var ret = false;
var isBuf = !state.objectMode && Stream._isUint8Array(chunk);
// 转化成buffer
if (isBuf && Object.getPrototypeOf(chunk) !== Buffer.prototype) {
chunk = Stream._uint8ArrayToBuffer(chunk);
}
// 对于可选参数的处理
if (typeof encoding === 'function') {
cb = encoding;
encoding = null;
}
// 编码
if (isBuf)
encoding = 'buffer';
else if (!encoding)
encoding = state.defaultEncoding;
if (typeof cb !== 'function')
cb = nop;
// 如果已经停止了向数据消费者继续提供数据
if (state.ended)
writeAfterEnd(this, cb);
else if (isBuf || validChunk(this, state, chunk, cb)) {
state.pendingcb++;
// 是将数据直接提供给消费者还是暂时存放到缓冲区
ret = writeOrBuffer(this, state, isBuf, chunk, encoding, cb);
}
return ret;
}
function writeOrBuffer (stream, state, isBuf, chunk, encoding, cb) {
...
var len = state.objectMode ? 1 : chunk.length;
state.length += len;
var ret = state.length < state.highWaterMark;
// we must ensure that previous needDrain will not be reset to false.
// 如果state.length长度大于hwm,将needDrain置为true,需要触发drain事件,开发者通过监听这个事件可以重新恢复可写流对于数据源的获取
if (!ret)
state.needDrain = true;
// state.writing 代表现在可写流正处于将数据传递给消费者使用的状态
// 或 当前处于corked状态时,就将数据写入buffer缓冲区内
// writeable的buffer缓冲区也是链表结构
if (state.writing || state.corked) {
var last = state.lastBufferedRequest;
state.lastBufferedRequest = {
chunk,
encoding,
isBuf,
callback: cb,
next: null
};
if (last) {
last.next = state.lastBufferedRequest;
} else {
state.bufferedRequest = state.lastBufferedRequest;
}
state.bufferedRequestCount += 1;
} else {
// 将数据写入底层数据即传递给消费者
doWrite(stream, state, false, len, chunk, encoding, cb);
}
return ret;
}
function doWrite(stream, state, writev, len, chunk, encoding, cb) {
// chunk的数据长度
state.writelen = len;
// chunk传递给消费者后的回调函数
state.writecb = cb;
// 可写流正在将数据传递给消费者的状态
state.writing = true;
// 同步态
state.sync = true;
// 如果定义了writev批量写入数据数据的就调用此方法
if (writev)
stream._writev(chunk, state.onwrite);
else
// 这个方法即完成将数据传递给消费者,并传入onwrite回调,这个onwrite函数必须要调用来告知写数据是完成还是失败
// 这3个参数也对应着上面提到的在自定义实现可写流时需要定义的write方法所接受的3个参数
// 可写流向消费者提供数据是同步的,但是消费者拿到数据后同步可写流的状态可能是同步,也可能是异步的
stream._write(chunk, encoding, state.onwrite);
state.sync = false;
}在doWrite方法中调用了开发者定义的write方法来完成数据的消费,即stream._write(),同时也提到了关于当数据被消费完了后需要调用state.onwrite这个方法来同步可写流的状态。接下来就来看下这个方法的内部实现:
// 完成一次_write方法后,更新相关的state状态
function onwriteStateUpdate(state) {
state.writing = false; // 已经写完数据
state.writecb = null; // 回调
state.length -= state.writelen;
state.writelen = 0; // 需要被写入数据的长度
}
// 数据被写入底层资源后必须要调用这个callback,其中stream是被作为预设函数,可参数上面Writeable中关于onwrite的定义
function onwrite(stream, er) {
var state = stream._writableState;
var sync = state.sync;
var cb = state.writecb;
// 首先更新可写流的状态
onwriteStateUpdate(state);
if (er)
onwriteError(stream, state, sync, er, cb);
else {
// Check if we're actually ready to finish, but don't emit yet
// 检验是否要结束这个writeable的流
var finished = needFinish(state);
// 每次写完一次数据后都需要检验
// 如果finished代表可写流里面还保存着有数据,那么需要调用clearBuffer,将可写流的缓冲区的数据提供给消费者
if (!finished &&
!state.corked &&
!state.bufferProcessing &&
state.bufferedRequest) {
clearBuffer(stream, state);
}
// 始终是异步的调用afterWrite方法
if (sync) {
process.nextTick(afterWrite, stream, state, finished, cb);
} else {
afterWrite(stream, state, finished, cb);
}
}
}
function afterWrite(stream, state, finished, cb) {
if (!finished)
onwriteDrain(stream, state);
state.pendingcb--;
cb();
finishMaybe(stream, state);
}
// 是否要结束这个writeable的流,需要将内部缓冲区的数据全部写入底层资源池
function needFinish(state) {
return (state.ending &&
state.length === 0 &&
state.bufferedRequest === null &&
!state.finished &&
!state.writing);
}
// if there's something in the buffer waiting, then process it
// 内部递归调用doWrite方法来完成将数据从缓冲区传递给消费者
function clearBuffer(stream, state) {
// 这个字段代表正在处理缓冲区buffer
state.bufferProcessing = true;
var entry = state.bufferedRequest;
// 在定义了writev方法的情况下才可能调用,批量将数据传递给消费者
if (stream._writev && entry && entry.next) {
// Fast case, write everything using _writev()
...
} else {
// Slow case, write chunks one-by-one
// 一个一个将数据传递给消费者
while (entry) {
var chunk = entry.chunk;
var encoding = entry.encoding;
var cb = entry.callback;
var len = state.objectMode ? 1 : chunk.length;
// 继续将缓冲区的数据提供给消费者
doWrite(stream, state, false, len, chunk, encoding, cb);
entry = entry.next;
state.bufferedRequestCount--;
// if we didn't call the onwrite immediately, then
// it means that we need to wait until it does.
// also, that means that the chunk and cb are currently
// being processed, so move the buffer counter past them.
if (state.writing) {
break;
}
}
if (entry === null)
state.lastBufferedRequest = null;
}
state.bufferedRequest = entry;
// 缓冲区buffer已经处理完
state.bufferProcessing = false;
}每次调用onWrite方法时,首先都会调用onwriteStateUpdate方法来更新这个可写流的状态,具体见上面的方法定义。同时需要对这个可写流进行判断,是否要关闭这个可写流。同时还进行判断buffer是否还有可供消费者使用的数据。如果有那么就调用clearBuffer方法用以将缓冲区的数据提供给消费者来使用。
当数据源提供给可写流的数据过快的时候有可能出现背压的情况,这个时候数据源不再提供数据给可写流,是否出现背压的情况,可通过可写流的write方法的返回值来进行判断,如果返回的是false,那么就出现的了背压。
参见这个例子在实现的write方法中通过setTimeout来延迟一段时间调用onwrite方法,这个时候每次数据消费者都拿到了数据,但是因为这个地方延迟了更新可写流的状态,但是从数据源向可写流中还是同步的写入数据,因此可能会出现在可写流的缓冲区保存的数据大于hmw的情况。
在writeOrBuffer方法中有关于可写流缓冲区保存的数据长度和hwm的比较:
var ret = state.length < state.highWaterMark;
// we must ensure that previous needDrain will not be reset to false.
// 如果state.length长度大于hwm,将needDrain置为true,可能需要触发drain事件,
if (!ret)
state.needDrain = true;将needDrain置为true。出现背压后,数据源不再提供数据给可写流,这个时候只有等可写流将缓冲区的所有完成全部提供给消费者消耗,同时更新完可写流的状态后,会触发一个drain事件。
function onwrite(stream, er) {
...
if (er)
...
else {
...
if (sync) {
process.nextTick(afterWrite, stream, state, finished, cb);
} else {
afterWrite(stream, state, finished, cb);
}
}
}
function afterWrite(stream, state, finished, cb) {
if (!finished)
onwriteDrain(stream, state);
state.pendingcb--;
cb();
finishMaybe(stream, state);
}
// 缓冲区的数据已经全部提供给消费者,同时needDrain被置为了true 触发drain事件
function onwriteDrain(stream, state) {
if (state.length === 0 && state.needDrain) {
state.needDrain = false;
stream.emit('drain');
}
}这个时候如果你的程序提前定义的监听drain事件的方法,那么可以在回调里面再次调用可写流的write方法来让数据源继续提供数据给可写流。
在使用 webpack-dev-server 的过程中,如果指定了 hot 配置的话(使用 inline mode 的前提下), wds 会在内部更新 webpack 的相关配置,即将 HotModuleReplacementPlugin 加入到 webpack 的 plugins 当中。
在 HotModuleReplacementPlugin 执行的过程中主要是完成了以下几个工作:
normalModuleFactory.hooks.parser
.for("javascript/auto")
.tap("HotModuleReplacementPlugin", addParserPlugins);
normalModuleFactory.hooks.parser
.for("javascript/dynamic")
.tap("HotModuleReplacementPlugin", addParserPlugins);其中在 addParserPlugins 方法当中添加了具体有关 parser hook 的回调,有几个比较关键的 hook 单独拿出来说下:
parser.hooks.call
.for("module.hot.accept")
.tap("HotModuleReplacementPlugin")这个 hook 主要是在 parser 编译代码过程中遇到module.hot.accept的调用的时候会触发,主要的工作就是处理当前模块部署依赖模块的依赖分析,在编译阶段处理好依赖的路径替换等内容。
parser.hooks.call
.for("module.hot.decline")
.tap("HotModuleReplacementPlugin")这个 hook 同样是在 parser 编译代码过程中遇到module.hot.decline的调用的时候触发,所做的工作和上面的 hook 类似。
const mainTemplate = compilation.mainTemplate
mainTemplate.hooks.moduleRequire.tap(
"HotModuleReplacementPlugin",
(_, chunk, hash, varModuleId) => {
return `hotCreateRequire(${varModuleId})`;
})这个 hook 主要完成的工作是在生成 webpack bootstrap runtime 代码当中对加载 module 的 require function进行替换,变为hotCreateRequire(${varModuleId})的形式,这样做的目的其实就是对于 module 的加载做了一层代理,在加载 module 的过程当中建立起相关的依赖关系(需要注意的是这里的依赖关系并非是 webpack 在编译打包构建过程中的那个依赖关系,而是在 hmr 模式下代码执行阶段,一个 module 加载其他 module 时在 hotCreateRequire 内部会建立起相关的加载依赖关系,方便之后的修改代码之后进行的热更新操作),具体这块的分析可以参见下面的章节。
mainTemplate.hooks.bootstrap.tap(
"HotModuleReplacementPlugin",
(source, chunk, hash) => {
// 在生成 runtime 最终的代码前先通过 hooks.hotBootstrap 钩子生成相关的 hmr 代码然后再完成代码的拼接
source = mainTemplate.hooks.hotBootstrap.call(source, chunk, hash);
return Template.asString([
source,
"",
hotInitCode
.replace(/\$require\$/g, mainTemplate.requireFn)
.replace(/\$hash\$/g, JSON.stringify(hash))
.replace(/\$requestTimeout\$/g, requestTimeout)
.replace(
/\/\*foreachInstalledChunks\*\//g, // 通过一系列的占位字符串,在生成代码的阶段完成代码的替换工作
needChunkLoadingCode(chunk)
? "for(var chunkId in installedChunks)"
: `var chunkId = ${JSON.stringify(chunk.id)};`
)
]);
}
)在这个 hooks.bootstrap 当中所做的工作是在 mainTemplate 渲染 bootstrap runtime 的代码的过程中,对于hotInitCode代码进行字符串的匹配和替换工作。hotInitCode这部分的代码其实就是下面章节所要讲的HotModuleReplacement.runtime向 bootstrap runtime 代码里面注入的 hmr 运行时代码。
mainTemplate.hooks.moduleObj.tap(
"HotModuleReplacementPlugin",
(source, chunk, hash, varModuleId) => {
return Template.asString([
`${source},`,
`hot: hotCreateModule(${varModuleId}),`, // 这部分的内容即这个 hook 对相关内容的拓展
"parents: (hotCurrentParentsTemp = hotCurrentParents, hotCurrentParents = [], hotCurrentParentsTemp),",
"children: []"
]);
}
)在这个 hooks.moduleObj 当中所做的工作是对__webpack_require__这个函数体内部的 installedModules 缓存模块变量进行拓展。几个非常关键的点就是:
hot: hotCreateModule(${varModuleId}) 配置。这个 module.hot api 即对应这个 module 有关热更新的 api,可以看到这个部署 hot api 的工作是由 hotCreateModule 这个方法来完成的(这个方法是由 hmr runtime 代码提供的,下面的章节会讲)。最终和这个 module 所有有关热更新相关的接口都通过module.hot.*去访问。Webpack 内部提供了 HotModuleReplacement.runtime 即热更新运行时部分的代码。这部分的代码并不是通过通过添加 webpack.entry 入口文件的方式来注入这部分的代码,而是通过 mainTemplate 在渲染 boostrap runtime 代码的阶段完成代码的注入工作的(对应上面的 mainTemplate.hooks.boostrap 所做的工作)。
在这部分热更新运行时的代码当中所做的工作主要包含了以下几个点:
hotCreateRequire方法,用以对__webpack_require__模块引入方法进行代理,当一个模块依赖其他模块,并将其引入的时候,会建立起宿主模块和依赖模块之间的相互依赖关系,这个依赖关系也是作为之后某个模块发生更新后,寻找与其有依赖关系的模块的凭证。function hotCreateRequire(moduleId) {
var me = installedModules[moduleId];
if (!me) return $require$;
var fn = function(request) { // 这个是 hmr 模式下,对原来的 __webpack_require__ 引入模块的函数做的一层代理
// 通过 depModule.parents 和 module.children 来双向建立起 module 之间的依赖关系
if (me.hot.active) {
if (installedModules[request]) {
if (installedModules[request].parents.indexOf(moduleId) === -1) {
installedModules[request].parents.push(moduleId); // 建立 module 之间的依赖关系,在被引入的 module 的 module.parents 当中添加当前这个 moduleId
}
} else {
hotCurrentParents = [moduleId];
hotCurrentChildModule = request;
}
if (me.children.indexOf(request) === -1) {
me.children.push(request); // 在当前 module 的 module.children 属性当中添加被引入的 moduleId
}
} else {
console.warn(
"[HMR] unexpected require(" +
request +
") from disposed module " +
moduleId
);
hotCurrentParents = [];
}
return $require$(request); // 引入模块
};
...
return fn
}hotCreateModule方法,用以给每个 module 都部署热更新相关的 api:function hotCreateModule(moduleId) {
var hot = {
// private stuff
_acceptedDependencies: {},
_declinedDependencies: {},
_selfAccepted: false,
_selfDeclined: false,
_disposeHandlers: [],
_main: hotCurrentChildModule !== moduleId,
// Module API
active: true,
accept: function(dep, callback) {
if (dep === undefined) hot._selfAccepted = true; // 表示这个 module 可以进行 hmr
else if (typeof dep === "function") hot._selfAccepted = dep;
else if (typeof dep === "object") // 和其他 module 建立起热更新之间的关系
for (var i = 0; i < dep.length; i++)
hot._acceptedDependencies[dep[i]] = callback || function() {};
else hot._acceptedDependencies[dep] = callback || function() {};
},
decline: function(dep) {
if (dep === undefined) hot._selfDeclined = true; // 当前 module 不需要进行热更新
else if (typeof dep === "object") // 当其依赖的 module 发生更新后,并不会触发这个 module 的热更新
for (var i = 0; i < dep.length; i++)
hot._declinedDependencies[dep[i]] = true;
else hot._declinedDependencies[dep] = true;
},
dispose: function(callback) {
hot._disposeHandlers.push(callback);
},
addDisposeHandler: function(callback) {
hot._disposeHandlers.push(callback);
},
removeDisposeHandler: function(callback) {
var idx = hot._disposeHandlers.indexOf(callback);
if (idx >= 0) hot._disposeHandlers.splice(idx, 1);
},
// Management API
check: hotCheck,
apply: hotApply,
status: function(l) {
if (!l) return hotStatus;
hotStatusHandlers.push(l);
},
addStatusHandler: function(l) {
hotStatusHandlers.push(l);
},
removeStatusHandler: function(l) {
var idx = hotStatusHandlers.indexOf(l);
if (idx >= 0) hotStatusHandlers.splice(idx, 1);
},
//inherit from previous dispose call
data: hotCurrentModuleData[moduleId]
};
hotCurrentChildModule = undefined;
return hot;
}在 hotCreateModule 方法当中完成 module.hot.* 和热更新相关接口的定义。这些 api 也是暴露给用户部署热更新代码的接口。
其中hot.accept和hot.decline方法主要是用户来定义发生热更新的模块及其依赖是否需要热更新的相关策略。例如hot.accept方法用来决定当前模块所依赖的哪些模块发生更新的话,自身也需要完成一些更新相关的动作。而hot.decline方法用来决定当前模块依赖的模块发生更新后,来决定自身是否需要进行更新。
而hot.check和hot.apply两个方法其实是 webpack 内部使用的2个方法,其中hot.check方法:首先调用hotDownloadManifest方法,通过发送一个 Get 请求去 server 获取本次发生变更的相关内容。// TODO: 相关内容的具体格式和字段?
{
c: { // 发生更新的 chunk 集合
app: true
},
h: 'xxxxx' // 服务端本次生成的编译hash值,用来作为下次浏览器获取发生变更的 hash 值(相当于服务端下发的一个 token,浏览器拿着这个 token 去后端获取对应的内容)
}function hotCheck(apply) {
if (hotStatus !== "idle") {
throw new Error("check() is only allowed in idle status");
}
hotApplyOnUpdate = apply;
hotSetStatus("check"); // 更新 热更新 流程的内部状态
return hotDownloadManifest(hotRequestTimeout).then(function(update) {
if (!update) {
hotSetStatus("idle");
return null;
}
hotRequestedFilesMap = {};
hotWaitingFilesMap = {};
hotAvailableFilesMap = update.c; // 发生更新的 chunk 集合
hotUpdateNewHash = update.h; // server 下发的本次生成的编译 hash 值,作为下次浏览器获取发生变更的 hash 值
hotSetStatus("prepare");
var promise = new Promise(function(resolve, reject) {
hotDeferred = {
resolve: resolve,
reject: reject
};
});
hotUpdate = {};
/*foreachInstalledChunks*/ // 这段注释在渲染 bootstrap runtime 部分的代码的时候会通过字符串匹配给替换掉,最终替换后的代码执行就是对已经下载的 chunk 进行循环 hotEnsureUpdateChunk(chunkId)
// eslint-disable-next-line no-lone-blocks
{
/*globals chunkId */
hotEnsureUpdateChunk(chunkId); // hotEnsureUpdateChunk(lib/web/JsonpMainTemplate.runtime.js) 方法内部其实就是通过创建 script 标签,然后传入到文档当中完成发生更新的 chunk 的下载
}
if (
hotStatus === "prepare" &&
hotChunksLoading === 0 &&
hotWaitingFiles === 0
) {
hotUpdateDownloaded();
}
return promise;
});
}// TODO: 补一个 hot.check 执行的流程图
总结下hot.check方法执行的流程其实就是:
接下来看下被下载的更新的 chunk 具体内容:
webpackHotUpdate('app', {
'compiled/module1/path': (function() {
eval('...script...')
}),
'compiled/module2/path': (function() {
eval('...script...')
})
})可以看到的是返回的 chunk 内容是可以立即执行的函数:
function hotAddUpdateChunk(chunkId, moreModules) {
if (!hotAvailableFilesMap[chunkId] || !hotRequestedFilesMap[chunkId])
return;
hotRequestedFilesMap[chunkId] = false;
for (var moduleId in moreModules) {
if (Object.prototype.hasOwnProperty.call(moreModules, moduleId)) {
hotUpdate[moduleId] = moreModules[moduleId];
}
}
if (--hotWaitingFiles === 0 && hotChunksLoading === 0) {
hotUpdateDownloaded();
}
}对应所做的工作就是将需要更新的模块缓存至hotUpdate上,同时判断需要更新的 chunk 是否已经下载完了,如果全部下载完成那么执行hotUpdateDownloaded方法,其内部实际就是调用hotApply进行接下来进行细粒度的模块更新和替换的工作。
首先先讲下hotApply内部的执行流程:
hotUpdate需要更新的模块,找出和需要更新的模块有依赖关系的模块;function hotApply(options) {
function getAffectedStuff(updateModuleId) {
var outdatedModules = [updateModuleId]
var outdatedDependencies = {}
var queue = outdatedModules.slice().map(function (id) {
return {
chain: [id],
id: id
}
})
while (queue.length > 0) {
var queueItem = queue.pop()
var moduleId = queueItem.id
var chain = queueItem.chain
module = installedModules[moduleId] // installedModules 为在 bootstrap runtime 里面定义的已经被加载过的 module 集合,这里其实就是为了取到这个 module 自己定义部署的有关热更新的相关策略
if (!module || module.hot._selfAccepted) continue // 如果这个 module 不存在或者只接受自更新,那么直接略过接下来的代码处理
if (module.hot._selfDeclined) {
return {
type: 'self-declined',
chain: chain,
moduleId: moduleId
}
}
if (module.hot._main) {
return {
type: 'unaccepted',
chain: chain,
moduleId: moduleId
}
}
for (var i = 0; i < module.parents.length; i++) { // 遍历所有依赖这个模块的 module
var parentId = module.parents[i]
var parent = installedModules[parentId]
if (!parent) continue
if (parent.hot._declinedDependencies[moduleId]) { // 如果这个 parentModule 的 module.hot._declinedDependencies 里面设置了不受更新影响的 moduleId
return {
type: 'declined',
chain: chain.concat([parentId]),
moduleId: moduleId,
parentId: parentId
}
}
if (outdatedModules.indexOf(parentId) !== -1) continue
if (parent.hot._acceptedDependencies[moduleId]) { // 如果这个 parentModule 的 module.hot._acceptedDependencies 里面设置了其受更新影响的 moduleId
if (!outdatedDependencies[parentId])
outdatedDependencies[parentId] = []
addAllToSet(outdatedDependencies[parentId], [moduleId])
continue
}
// 如果这个 parentModule 没有部署任何相关热更新的**模块间依赖的更新策略**(不算_selfAccepted 和 _selfDeclined 状态),那么需要将这个 parentModule 加入到 outdatedModules 队列里面,同时更新 queue 来进行下一轮的遍历找出所有需要进行更新的 module
delete outdatedDependencies[parentId]
outdatedModules.push(parentId)
queue.push({
chain: chain.concat([parentId]),
id: parentId
})
}
}
return {
type: 'accepted',
moduleId: updateModuleId,
outdatedModules: outdatedModules, // 本次更新当中所有过期的 modules
outdatedDependencies: outdatedDependencies // 所有过期的依赖 modules
}
}
for (var id in hotUpdate) {
if (Object.prototype.hasOwnProperty.call(hotUpdate, id)) {
moduleId = toModuleId(id)
/** @type {TODO} */
var result
if (hotUpdate[id]) {
result = getAffectedStuff(moduleId)
} else {
result = {
type: 'disposed',
moduleId: id
}
}
/** @type {Error|false} */
var abortError = false
var doApply = false
var doDispose = false
var chainInfo = ''
if (result.chain) {
chainInfo = '\nUpdate propagation: ' + result.chain.join(' -> ')
}
switch (result.type) {
case 'self-declined':
if (options.onDeclined) options.onDeclined(result)
if (!options.ignoreDeclined)
abortError = new Error(
'Aborted because of self decline: ' +
result.moduleId +
chainInfo
)
break
case 'declined':
if (options.onDeclined) options.onDeclined(result)
if (!options.ignoreDeclined)
abortError = new Error(
'Aborted because of declined dependency: ' +
result.moduleId +
' in ' +
result.parentId +
chainInfo
)
break
case 'unaccepted':
if (options.onUnaccepted) options.onUnaccepted(result)
if (!options.ignoreUnaccepted)
abortError = new Error(
'Aborted because ' + moduleId + ' is not accepted' + chainInfo
)
break
case 'accepted':
if (options.onAccepted) options.onAccepted(result)
doApply = true
break
case 'disposed':
if (options.onDisposed) options.onDisposed(result)
doDispose = true
break
default:
throw new Error('Unexception type ' + result.type)
}
if (abortError) {
hotSetStatus('abort')
return Promise.reject(abortError)
}
if (doApply) {
appliedUpdate[moduleId] = hotUpdate[moduleId] // 需要更新的模块
addAllToSet(outdatedModules, result.outdatedModules) // 使用单独一个 outdatedModules 数组变量存放所有过期需要更新的 moduleId,其中 result.outdatedModules 是通过 getAffectedStuff 方法找到的当前遍历的 module 所依赖的过期的需要更新的模块
for (moduleId in result.outdatedDependencies) { // 使用单独的 outdatedDependencies 集合去存放相关依赖更新模块
if (
Object.prototype.hasOwnProperty.call(
result.outdatedDependencies,
moduleId
)
) {
if (!outdatedDependencies[moduleId])
outdatedDependencies[moduleId] = []
addAllToSet(
outdatedDependencies[moduleId],
result.outdatedDependencies[moduleId]
)
}
}
}
if (doDispose) {
addAllToSet(outdatedModules, [result.moduleId])
appliedUpdate[moduleId] = warnUnexpectedRequire
}
}
// Store self accepted outdated modules to require them later by the module system
// 在所有 outdatedModules 里面找到部署了 module.hot._selfAccepted 属性的模块。(部署了这个属性的模块会通过 webpack 的模块系统重新加载一次这个模块的新的内容来完成热更新)
var outdatedSelfAcceptedModules = []
for (i = 0; i < outdatedModules.length; i++) {
moduleId = outdatedModules[i]
if (
installedModules[moduleId] &&
installedModules[moduleId].hot._selfAccepted
)
outdatedSelfAcceptedModules.push({
module: moduleId,
errorHandler: installedModules[moduleId].hot._selfAccepted
})
}
// dispose phase TODO: 各个热更新阶段 hooks?
var idx
var queue = outdatedModules.slice()
while (queue.length > 0) {
moduleId = queue.pop()
module = installedModules[moduleId]
if (!module) continue
var data = {}
// Call dispose handlers
var disposeHandlers = module.hot._disposeHandlers
for (j = 0; j < disposeHandlers.length; j++) {
cb = disposeHandlers[j]
cb(data)
}
hotCurrentModuleData[moduleId] = data
// disable module (this disables requires from this module)
module.hot.active = false
// 从 installedModules 集合当中剔除掉过期的 module,即其他 module 引入这个被剔除掉的 module 的时候,其实是会重新执行这个 module,这也是为什么要从 installedModules 上剔除这个需要被更新的模块的原因
// remove module from cache
delete installedModules[moduleId]
// when disposing there is no need to call dispose handler
delete outdatedDependencies[moduleId]
// 将这个 module 所依赖的模块(module.children)当中剔除掉 module.children.parentModule,即解除模块之间的依赖关系
// remove "parents" references from all children
for (j = 0; j < module.children.length; j++) {
var child = installedModules[module.children[j]]
if (!child) continue
idx = child.parents.indexOf(moduleId)
if (idx >= 0) {
child.parents.splice(idx, 1)
}
}
}
// 这里同样是通过遍历 outdatedDependencies 里面需要更新的模块,需要注意的是 outdateDependencies 里面的 key 为被依赖的 module,这个 key 所对应的 value 数组里面存放的是发生了更新的 module。所以这是需要解除被依赖的 module 和这些发生更新了的 module 之间的引用依赖关系。
// remove outdated dependency from module children
var dependency
var moduleOutdatedDependencies
for (moduleId in outdatedDependencies) {
if (
Object.prototype.hasOwnProperty.call(outdatedDependencies, moduleId)
) {
module = installedModules[moduleId]
if (module) {
moduleOutdatedDependencies = outdatedDependencies[moduleId]
for (j = 0; j < moduleOutdatedDependencies.length; j++) {
dependency = moduleOutdatedDependencies[j]
idx = module.children.indexOf(dependency)
if (idx >= 0) module.children.splice(idx, 1)
}
}
}
}
// Not in "apply" phase
hotSetStatus('apply')
// 更新当前的热更新 hash 值(即通过 get 请求获取 server 下发的 hash 值)
hotCurrentHash = hotUpdateNewHash
// 遍历 appliedUpdate 发生更新的 module
// insert new code
for (moduleId in appliedUpdate) {
if (Object.prototype.hasOwnProperty.call(appliedUpdate, moduleId)) {
modules[moduleId] = appliedUpdate[moduleId] // HIGHLIGHT: 这里的 modules 变量为 bootstrap 代码里面接收到的所有的 modules 的集合,即在这里完成新老 module 的替换
}
}
// 执行那些在 module.hot.accept 上部署了依赖模块发生更新后的回调函数
// call accept handlers
var error = null
for (moduleId in outdatedDependencies) {
if (
Object.prototype.hasOwnProperty.call(outdatedDependencies, moduleId)
) {
module = installedModules[moduleId]
if (module) {
moduleOutdatedDependencies = outdatedDependencies[moduleId]
var callbacks = []
for (i = 0; i < moduleOutdatedDependencies.length; i++) {
dependency = moduleOutdatedDependencies[i]
cb = module.hot._acceptedDependencies[dependency]
if (cb) {
if (callbacks.indexOf(cb) !== -1) continue
callbacks.push(cb)
}
}
for (i = 0; i < callbacks.length; i++) {
cb = callbacks[i]
try {
cb(moduleOutdatedDependencies)
} catch (err) {
...
}
}
}
}
}
// 重新加载那些部署了 module.hot._selfAccepted 为 true 的 module,即这个 module 会被重新加载并执行一次,这样也就在 installedModules 上缓存了这个新的 module
// Load self accepted modules
for (i = 0; i < outdatedSelfAcceptedModules.length; i++) {
var item = outdatedSelfAcceptedModules[i]
moduleId = item.module
hotCurrentParents = [moduleId]
try {
$require$(moduleId) // $require$ 会在被最终渲染到 bootstrap runtime 当中被替换为 webpack require 加载模块的方法
} catch (err) {
if (typeof item.errorHandler === 'function') {
try {
item.errorHandler(err)
} catch (err2) {
...
}
} else {
...
}
}
hotSetStatus('idle')
return new Promise(function (resolve) {
resolve(outdatedModules)
})
}
}
}所以当一个模块发生变化后,依赖这个模块的 parentModule 有如下几种热更新执行的策略:
module.hot.accept()当依赖的模块发生更新后,这个模块需要通过重新加载去完成本模块的全量更新。
module.hot.accept(['xxx'], callback)当依赖的模块且为 xxx 模块发生更新后,这个模块会执行 callback 来完成相关的更新的动作。而不需要通过重新加载的方式去完成更新。
module.hot.decline()这个模块不管其依赖的模块是否发生了变化。这个模块都不会发生更新。
module.hot.decline(['xxx'])当依赖的模块为xxx发生更新的情况下,这个模块不会发生更新。当依赖的其他模块(除了xxx模块外)发生更新的话,那么最终还是会将本模块从缓存中删除。
这些热更新的 api 也是需要用户自己在代码当中进行部署的。就拿平时我们使用的 vue 来说,在本地开发阶段, vue sfc 经过 vue-loader 的编译处理后,会自动帮我们在组件代码当中当中注入和热更新相关的代码。
// vue-loader/lib/codegen/hotReload.js
const hotReloadAPIPath = JSON.stringify(require.resolve('vue-hot-reload-api'))
const genTemplateHotReloadCode = (id, request) => {
return `
module.hot.accept(${request}, function () {
api.rerender('${id}', {
render: render,
staticRenderFns: staticRenderFns
})
})
`.trim()
}
exports.genHotReloadCode = (id, functional, templateRequest) => {
return `
/* hot reload */
if (module.hot) {
var api = require(${hotReloadAPIPath})
api.install(require('vue'))
if (api.compatible) { // 判断使用的 vue 的版本是否支持热更新
module.hot.accept()
if (!api.isRecorded('${id}')) {
api.createRecord('${id}', component.options)
} else {
api.${functional ? 'rerender' : 'reload'}('${id}', component.options)
}
${templateRequest ? genTemplateHotReloadCode(id, templateRequest) : ''}
}
}
`.trim()
}vue-loader通过 genHotReloadCode 方法在处理 vue sfc 代码的时候完成热更新 api 的部署功能。这里大致讲下 vue component 进行热更新的流程:
$forceUpdate);<template>,<script>中的内容外会进行热更新外,在我们修改<style>样式内容的时候也有热更新的效果。这也是 vue component 在编译阶段在 vue style block 的代码当中部署了热更新代码的原因。具体更新策略可参见vue-style-loader相关资料:
最近遇到一个更新了 package,但是本地编译打包后没有更新代码的情况,先来复现下这个 case 的流程:
0.1.0版本的 package;0.2.0版本;0.1.0版本升级到0.2.0版本,并执行npm run deploy,代码经过 webpack 本地编译后发布到测试环境。但是测试环境的代码并不是最新的 package 的内容。但是在 node_modules 当中的 package 确实是最新的版本。这个问题其实在社区里面有很多同学已经遇到了:
TL;DR(流程分析较复杂,可一拉到底)
翻了那些 issue 后,基本知道了是由于 webpack 在编译代码过程中走到 cache-loader 然后命中了缓存,这个缓存是之前编译的老代码,既然命中了缓存,那么就不会再去编译新的代码,于是最终编译出来的代码并不是我们所期望的。所以这个时候 cd node_modules && rm -rf .cache && npm run deploy,就是进入到 node_modules 目录,将 cache-loader 缓存的代码全部清除掉,并重新执行部署的命令,这些编译出来的代码肯定是最新的。
既然知道了问题的所在,那么就开始着手去分析这个问题的来龙去脉。这里我也简单的介绍下 cache-loader 的 workflow 是怎么进行的:
node_modules/.cache 文件夹下的缓存的 json 文件(abc.json)。其中 cacheKey 的生成支持外部传入 cacheIdentifier 和 cacheDirectory 具体参见官方文档。// cache-loader 内部定义的默认的 cacheIdentifier 及 cacheDirectory
const defaults = {
cacheContext: '',
cacheDirectory: findCacheDir({ name: 'cache-loader' }) || os.tmpdir(),
cacheIdentifier: `cache-loader:${pkg.version} ${env}`,
cacheKey,
compare,
precision: 0,
read,
readOnly: false,
write
}
function cacheKey(options, request) {
const { cacheIdentifier, cacheDirectory } = options;
const hash = digest(`${cacheIdentifier}\n${request}`);
return path.join(cacheDirectory, `${hash}.json`);
}如果缓存文件(abc.json)当中记录的所有依赖以及这个文件都没发生变化,那么就会直接读取缓存当中的内容,并返回且跳过后面的 loader 的正常执行。一旦有依赖或者这个文件发生变化,那么就正常的走接下来的 loader 上部署的 pitch 方法,以及正常的 loader 处理文本文件的流程。
cache-loader 在决定是否使用缓存内容时是通过缓存内容当中记录的所有的依赖文件的 mtime 与对应文件最新的 mtime 做对比来看是否发生了变化,如果没有发生变化,即命中缓存,读取缓存内容并跳过后面的 loader 的处理,否则走正常的 loader 处理流程。
function pitch(remainingRequest, prevRequest, dataInput) {
...
// 根据 cacheKey 的标识获取对应的缓存文件内容
readFn(data.cacheKey, (readErr, cacheData) => {
async.each(
cacheData.dependencies.concat(cacheData.contextDependencies), // 遍历所有依赖文件路径
(dep, eachCallback) => {
// Applying reverse path transformation, in case they are relatives, when
// reading from cache
const contextDep = {
...dep,
path: pathWithCacheContext(options.cacheContext, dep.path),
};
// fs.stat 获取对应文件状态
FS.stat(contextDep.path, (statErr, stats) => {
if (statErr) {
eachCallback(statErr);
return;
}
// When we are under a readOnly config on cache-loader
// we don't want to emit any other error than a
// file stat error
if (readOnly) {
eachCallback();
return;
}
const compStats = stats;
const compDep = contextDep;
if (precision > 1) {
['atime', 'mtime', 'ctime', 'birthtime'].forEach((key) => {
const msKey = `${key}Ms`;
const ms = roundMs(stats[msKey], precision);
compStats[msKey] = ms;
compStats[key] = new Date(ms);
});
compDep.mtime = roundMs(dep.mtime, precision);
}
// 对比当前文件最新的 mtime 和缓存当中记录的 mtime 是否一致
// If the compare function returns false
// we not read from cache
if (compareFn(compStats, compDep) !== true) {
eachCallback(true);
return;
}
eachCallback();
});
},
(err) => {
if (err) {
data.startTime = Date.now();
callback();
return;
}
...
callback(null, ...cacheData.result);
}
);
})
}script block及template block在代码编译构建的流程当中都利用了 cache-loader 进行了缓存相关的配置工作。// @vue/cli-plugin-babel
module.export = (api, options) => {
...
api.chainWebpack(webpackConfig => {
const jsRule = webpackConfig.module
.rule('js')
.test(/\.m?jsx?$/)
.use('cache-loader')
.loader(require.resolve('cache-loader'))
.options(api.genCacheConfig('babel-loader', {
'@babel/core': require('@babel/core/package.json').version,
'@vue/babel-preset-app': require('@vue/babel-preset-app/package.json').version,
'babel-loader': require('babel-loader/package.json').version,
modern: !!process.env.VUE_CLI_MODERN_BUILD,
browserslist: api.service.pkg.browserslist
}, [
'babel.config.js',
'.browserslistrc'
]))
.end()
jsRule
.use('babel-loader')
.loader(require.resolve('babel-loader'))
})
...
}
// @vue/cli-serive/lib/config
module.exports = (api, options) => {
...
api.chainWebpack(webpackConfig => {
const vueLoaderCacheConfig = api.genCacheConfig('vue-loader', {
'vue-loader': require('vue-loader/package.json').version,
/* eslint-disable-next-line node/no-extraneous-require */
'@vue/component-compiler-utils': require('@vue/component-compiler-utils/package.json').version,
'vue-template-compiler': require('vue-template-compiler/package.json').version
})
webpackConfig.module
.rule('vue')
.test(/\.vue$/)
.use('cache-loader')
.loader(require.resolve('cache-loader'))
.options(vueLoaderCacheConfig)
.end()
.use('vue-loader')
.loader(require.resolve('vue-loader'))
.options(Object.assign({
compilerOptions: {
whitespace: 'condense'
}
}, vueLoaderCacheConfig))
...
})
}即:
script block来说经过babel-loader的处理后经由cache-loader,若之前没有进行缓存过,那么新建本地的缓存 json 文件,若命中了缓存,那么直接读取经过babel-loader处理后的 js 代码;template block来说经过vue-loader转化成 renderFunction 后经由cache-loader,若之前没有进行缓存过,那么新建本地的缓存 json 文件,若命中了缓存,那么直接读取 json 文件当中缓存的 renderFunction。上面对于 cache-loader 和 @vue/cli 内部工作原理的简单介绍。那么在文章一开始的时候提到的那个 case 具体是因为什么原因导致的呢?
事实上在npm 5.8+版本,npm 将发布的 package 当中包含的文件的 mtime 都统一置为了1985-10-26T08:15:00.000Z(可参见 issue-20439)。
A 同学(npm版本为6.4.1)发布了0.1.0的版本后,C 同学安装了0.1.0版本,本地构建后生成缓存文件记录的文件 mtime 为1985-10-26T08:15:00.000Z。B 同学(npm版本为6.2.1)发布了0.2.0,C 同学安装0.2.0版本,本地开始构建,但是经由 cache-loader 的过程当中,cache-loader 通过对比缓存文件记录的依赖的 mtime 和新安装的 package 的文件的 mtime,但是发现都是1985-10-26T08:15:00.000Z,这样也就命中了缓存,即直接获取上一次缓存文件当中所包含的内容,而不会对新安装的 package 的文件进行编译。
针对这个问题,@vue/cli 在19年4月的3.7.0版本(具体代码变更的内容请戳我)当中也做了相关的修复性的工作,主要是将:package-lock.json、yarn.lock、pnpm-lock.yaml,这些做版本控制文件也加入到了 hash 生成的策略当中:
// @vue/cli-service/lib/PluginAPI.js
class PluginAPI {
...
genCacheConfig(id, partialIdentifier, configFiles = []) {
...
if (!Array.isArray(configFiles)) {
configFiles = [configFiles]
}
configFiles = configFiles.concat([
'package-lock.json',
'yarn.lock',
'pnpm-lock.yaml'
])
const readConfig = file => {
const absolutePath = this.resolve(file)
if (!fs.existsSync(absolutePath)) {
return
}
if (absolutePath.endsWith('.js')) {
// should evaluate config scripts to reflect environment variable changes
try {
return JSON.stringify(require(absolutePath))
} catch (e) {
return fs.readFileSync(absolutePath, 'utf-8')
}
} else {
// console.log('the absolute path is:', fs.readFileSync(absolutePath, 'utf-8'))
return fs.readFileSync(absolutePath, 'utf-8')
}
}
// 获取版本控制文件的文本内容
for (const file of configFiles) {
const content = readConfig(file)
if (content) {
variables.configFiles = content.replace(/\r\n?/g, '\n')
break
}
}
// 将带有版本控制文件的内容加入到 hash 算法当中,生成新的 cacheIdentifier
// 并传入 cache-loader(缓存文件的 cacheKey 依据这个 cacheIdentifier 来生成,👆上文有说明)
const cacheIdentifier = hash(variables)
return { cacheDirectory, cacheIdentifier }
}
}这样来做的核心**就是:当你升级了某个 package 后,相应的版本控制文件也会对应的更新(例如 package-lock.json),那么再一次进行编译流程时,所生成的缓存文件的 cacheKey 就会是最新的,因为也就不会命中缓存,还是走正常的全流程的编译,最终打包出来的代码也就是最新的。
不过这次升级后,还是有同学在社区反馈命中缓存,代码没有更新的问题,而且出现的 case 是 package 当中需要走 babel-loader 的 js 会遇到命中缓存不更新的情况,但是 package 当中被项目代码引用的 vue 的 template 文件不会出现这种情况。后来我调试了下@vue/cli-service/lib/PluginAPI.js的代码,发现代码在读取多个配置文件的过程中,一旦获取到某个配置文件的内容后就不再读取后面的配置文件的内容了,这样也就导致就算package-lock.json发生了更新,但是因为在编译流程当中并未读取package-lock.json这个文件的最新的内容话,那么也就不会生成新的 cacheKey,仍然会出现命中缓存的问题:
// 针对需要走 babel-loader 流程的配置文件为:
['babel.config.js', '.browserslistrc', 'package-lock.json', 'yarn.lock', 'pnpm-lock.yaml']
// 针对需要缓存的 vue template 的配置文件为:
['package-lock.json', 'yarn.lock', 'pnpm-lock.yaml']
// @vue/cli-service/lib/PluginAPI.js
class PluginAPI {
...
genCacheConfig(id, partialIdentifier, configFiles = []) {
...
if (!Array.isArray(configFiles)) {
configFiles = [configFiles]
}
configFiles = configFiles.concat([
'package-lock.json',
'yarn.lock',
'pnpm-lock.yaml'
])
const readConfig = file => {
...
}
// 一旦获取到某个配置文件的内容后,就直接跳出了 for ... of 的循环
// 那么也就不会继续获取其他配置文件的内容,
// 所以对于处理 js 文件的流程来说,因为读取了 babel.config.js 的内容,那么也就不会再去获取更新后的 packge-lock.json 文件内容
// 但是对于处理 vue template 的流程来说,配置文件当中第一项就位 package-lock.json,这种情况下会获取最新的 package-lock.json 文件,所以对于 vue template 的不会出现升级了 package 内容,但是会因为命中缓存,导致编译代码不更新的情况。
for (const file of configFiles) {
const content = readConfig(file)
if (content) {
variables.configFiles = content.replace(/\r\n?/g, '\n')
break
}
}
const cacheIdentifier = hash(variables)
return { cacheDirectory, cacheIdentifier }
}
}不过就在前几天,@vue/cli 的作者也重新看了下这个有关 vue template 正常,但是对于 js 命中缓存的原因,并针对这个问题进行了修复(具体代码内容变更请戳我),这次的代码变更就是通过 map 循环(而非 for ... of 循环读取到内容后直接 break),这样去确保所有的配置文件都被获取得到:
variables.configFiles = configFiles.map(file => {
const content = readConfig(file)
return content && content.replace(/\r\n?/g, '\n')
}目前在@vue/[email protected]版本中已经进行了修复。
以上就是通过 @vue/cli 初始化的项目,在升级 package 的过程中,cache-loader 命中缓存,新一轮代码编译生成非最新代码问题的分析。
cache-loader 使用缓存文件(node_modules/.cache)记录了不同依赖文件的 mtime,并通过对比缓存记录的 mtime 和最新文件的 mtime 是否发生了变化来觉得是否使用缓存。由于[email protected]之后,每次新发布的 package 内部所包含的文件的 mtime 都被重置为1985-10-26T08:15:00.000Z,导致 cache-loader 这个对比 mtime 的策略失效。因为 @vue/cli-service 从3.7.0(19年4月)版本针对这个问题进行了第一次的修复,核心**就是将package-lock.json这样的版本控制文件的内容纳入到了生成缓存文件的 cacheKey 的 hash 算法当中,每次升级 package 后,package-lock.json也会随之变化,这样会生成新的 cacheKey,进而不会命中缓存策略,这样也就解开了由于 npm 重置 mtime 而带来的重复命中缓存的问题,但是3.7.0版本的修复是有bug的,主要就是有些项目当中package-lock.json(由项目结构决定)这样的版本控制文件根本就没有被读取,导致 cache-loader 生成的 cacheKey 依然没有变化。然后在前几天(2020年1月28日),@vue/cli 的作者重新针对这个问题进行优化,确保package-lock.json版本控制文件能被读取到,从而避免 cacheKey 不变的问题,于@vue/[email protected]版本中完全修复了重复命中缓存的问题。
这里比较有意思的一点就是这个问题的出现需要满足2个条件:
比如我一直使用的 node 版本为 8.11.0,对应的 npm 版本为 5.6.0,那么经由我去修改发布的所有 package 所包含的文件的 mtime 都是被修改的那一刻,其他人升级到我发布的版本后,是不会出现重复命中缓存的问题。
不过既然问题被梳理清楚后,那么本地编译的过程避免出现这个问题的解决方式:
node_module/.cache文件夹,例如将本地编译构建的npm script修改为rm -rf node_module/.cache && vue-cli-service build。(不过对于大型的项目来说,少了这部分的缓存内容的话,编译速度还是会受到一定的影响的。)[email protected] 是一个全新的 Vue 项目脚手架。不同于 1.x/2.x 基于模板的脚手架,[email protected] 采用了一套基于插件的架构,它将部分核心功能收敛至 CLI 内部,同时对开发者暴露可拓展的 API 以供开发者对 CLI 的功能进行灵活的拓展和配置。接下来我们就通过 [email protected] 的源码来看下这套插件架构是如何设计的。
整个插件系统当中包含2个重要的组成部分:
vue create创建一个新的项目;当你使用 vue create <project-name>创建一个新的 Vue 项目,你会发现生成的项目相较于 1.x/2.x 初始化一个项目时从远程拉取的模板发生了很大的变化,其中关于 webpack 相关的配置以及 npm script 都没有在模板里面直接暴露出来,而是提供了新的 npm script:
// package.json
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build",
"lint": "vue-cli-service lint"
}前 2 个脚本命令是项目本地安装的 @vue/cli-service 所提供的基于 webpack 及相关的插件进行封装的本地开发/构建的服务。@vue/cli-service 将 webpack 及相关插件提供的功能都收敛到 @vue/cli-service 内部来实现。
这 2 个命令对应于 node_modules/@vue/cli-service/lib/commands 下的 serve.js 和 build/index.js。
在 serve.js 和 build/index.js 的内部分别暴露了一个函数及一个 defaultModes 属性供外部来使用。事实上这两者都是作为 built-in(内置)插件来供 vue-cli-service 来使用的。
说到这里那么就来看看 @vue/cli-service 内部是如何搭建整个插件系统的。就拿执行npm run serve启动本地开发服务来说,首先来看下 @vue/cli-service 提供的 cli 启动入口服务(@vue/cli-service/bin/vue-cli-service.js):
TODO: 插入流程图
#!/usr/bin/env node
const semver = require('semver')
const { error } = require('@vue/cli-shared-utils')
const Service = require('../lib/Service') // 引入 Service 基类
const service = new Service(process.env.VUE_CLI_CONTEXT || process.cwd()) // 实例化 service
const rawArgv = process.argv.slice(2)
const args = require('minimist')(rawArgv)
const command = args._[0]
service.run(command, args, rawArgv).catch(err => { // 开始执行对应的 service 服务
error(err)
process.exit(1)
})看到这里你会发现在 bin 里面并未提供和本地开发 serve 相关的服务,事实上在项目当中本地安装的 @vue/cli-service 提供的不管是内置的还是插件提供的服务都是动态的去完成相关 CLI 服务的注册。
在 lib/Service.js 内部定义了一个核心的类 Service,它作为 @vue/cli 的运行时的服务而存在。在执行npm run serve后,首先完成 Service 的实例化工作:
class Service {
constructor(context) {
...
this.webpackChainFns = [] // 数组内部每项为一个fn
this.webpackRawConfigFns = [] // 数组内部每项为一个 fn 或 webpack 对象字面量配置项
this.devServerConfigFns = []
this.commands = {} // 缓存动态注册 CLI 命令
...
this.plugins = this.resolvePlugins(plugins, useBuiltIn) // 完成插件的加载
this.modes = this.plugins.reduce((modes, { apply: { defaultModes }}) => { // 缓存不同 CLI 命令执行时所对应的mode值
return Object.assign(modes, defaultModes)
}, {})
}
}在实例化 Service 的过程当中完成了两个比较重要的工作:
当 Service 实例化完成后,调用实例上的 run 方法来启动对应的 CLI 命令所提供的服务。
async run (name, args = {}, rawArgv = []) {
const mode = args.mode || (name === 'build' && args.watch ? 'development' : this.modes[name])
// load env variables, load user config, apply plugins
// 执行所有被加载进来的插件
this.init(mode)
...
const { fn } = command
return fn(args, rawArgv) // 开始执行对应的 cli 命令服务
}
init (mode = process.env.VUE_CLI_MODE) {
...
// 执行plugins
// apply plugins.
this.plugins.forEach(({ id, apply }) => {
// 传入一个实例化的PluginAPI实例,插件名作为插件的id标识,在插件内部完成注册 cli 命令服务和 webpack 配置的更新的工作
apply(new PluginAPI(id, this), this.projectOptions)
})
...
// apply webpack configs from project config file
if (this.projectOptions.chainWebpack) {
this.webpackChainFns.push(this.projectOptions.chainWebpack)
}
if (this.projectOptions.configureWebpack) {
this.webpackRawConfigFns.push(this.projectOptions.configureWebpack)
}
}接下来我们先看下 @vue/cli-service 当中的 Service 实例化的过程:通过 resolvePlugins 方法去完成插件的加载工作:
resolvePlugins(inlinePlugins, useBuiltIn) {
const idToPlugin = id => ({
id: id.replace(/^.\//, 'built-in:'),
apply: require(id) // 加载对应的插件
})
let plugins
// @vue/cli-service内部提供的插件
const builtInPlugins = [
'./commands/serve',
'./commands/build',
'./commands/inspect',
'./commands/help',
// config plugins are order sensitive
'./config/base',
'./config/css',
'./config/dev',
'./config/prod',
'./config/app'
].map(idToPlugin)
if (inlinePlugins) {
plugins = useBuiltIn !== false
? builtInPlugins.concat(inlinePlugins)
: inlinePlugins
} else {
// 加载项目当中使用的插件
const projectPlugins = Object.keys(this.pkg.devDependencies || {})
.concat(Object.keys(this.pkg.dependencies || {}))
.filter(isPlugin)
.map(idToPlugin)
plugins = builtInPlugins.concat(projectPlugins)
}
// Local plugins
if (this.pkg.vuePlugins && this.pkg.vuePlugins.service) {
const files = this.pkg.vuePlugins.service
if (!Array.isArray(files)) {
throw new Error(`Invalid type for option 'vuePlugins.service', expected 'array' but got ${typeof files}.`)
}
plugins = plugins.concat(files.map(file => ({
id: `local:${file}`,
apply: loadModule(file, this.pkgContext)
})))
}
return plugins
}在这个 resolvePlugins 方法当中,主要完成了对于 @vue/cli-service 内部提供的插件以及项目应用(package.json)当中需要使用的插件的加载,并将对应的插件进行缓存。在其提供的内部插件当中又分为两类:
'./commands/serve'
'./commands/build'
'./commands/inspect'
'./commands/help'这一类插件在内部动态注册新的 CLI 命令,开发者即可通过 npm script 的形式去启动对应的 CLI 命令服务。
'./config/base'
'./config/css'
'./config/dev'
'./config/prod'
'./config/app'这一类插件主要是完成 webpack 本地编译构建时的各种相关的配置。@vue/cli-service 将 webpack 的开发构建功能收敛到内部来完成。
插件加载完成,开始调用 service.run 方法,在这个方法内部开始执行所有被加载的插件:
this.plugins.forEach(({ id, apply }) => {
apply(new PluginAPI(id, this), this.projectOptions)
})在每个插件执行的过程中,接收到的第一个参数都是 PluginAPI 的实例,PluginAPI 也是整个 @vue/cli-service 服务当中一个核心的基类:
class PluginAPI {
constructor (id, service) {
this.id = id // 对应这个插件名
this.service = service // 对应 Service 类的实例(单例)
}
...
registerCommand (name, opts, fn) { // 注册自定义 cli 命令
if (typeof opts === 'function') {
fn = opts
opts = null
}
this.service.commands[name] = { fn, opts: opts || {}}
}
chainWebpack (fn) { // 缓存变更的 webpack 配置
this.service.webpackChainFns.push(fn)
}
configureWebpack (fn) { // 缓存变更的 webpack 配置
this.service.webpackRawConfigFns.push(fn)
}
...
}每个由 PluginAPI 实例化的 api 实例都提供了:
api.registerCommand)api.chainWebpack)api.configureWebpack),与api.chainWebpack提供的链式 api 操作 webpack 配置的方式不同,api.configureWebpack可接受raw式的配置形式,并通过 webpack-merge 对 webpack 配置进行合并。api.resolveWebpackConfig),调用之前通过 chainWebpack 和 configureWebpack 上完成的对于 webpack 配置的改造,并生成最终的 webpack 配置首先我们来看下 @vue/cli-service 提供的关于动态注册 CLI 服务的插件,拿 serve 服务(./commands/serve)来说:
// commands/serve
module.exports = (api, options) => {
api.registerCommand(
'serve',
{
description: 'start development server',
usage: 'vue-cli-service serve [options] [entry]',
options: {
'--open': `open browser on server start`,
'--copy': `copy url to clipboard on server start`,
'--mode': `specify env mode (default: development)`,
'--host': `specify host (default: ${defaults.host})`,
'--port': `specify port (default: ${defaults.port})`,
'--https': `use https (default: ${defaults.https})`,
'--public': `specify the public network URL for the HMR client`
}
},
async function serve(args) {
// do something
}
)
}./commands/serve 对外暴露一个函数,接收到的第一个参数 PluginAPI 的实例 api,并通过 api 提供的 registerCommand 方法来完成 CLI 命令(即 serve 服务)的注册。
再来看下 @vue/cli-service 内部提供的关于 webpack 配置的插件(./config/base):
module.exports = (api, options) => {
api.chainWebpack(webpackConfig => {
webpackConfig.module
.rule('vue')
.test(/\.vue$/)
.use('cache-loader')
.loader('cache-loader')
.options(vueLoaderCacheConfig)
.end()
.use('vue-loader')
.loader('vue-loader')
.options(
Object.assign(
{
compilerOptions: {
preserveWhitespace: false
}
},
vueLoaderCacheConfig
)
)
})
}这个插件完成了 webpack 的基本配置内容,例如 entry、output、加载不同文件类型的 loader 的配置。不同于之前使用的配置式的 webpack 使用方式,@vue/cli-service 默认使用 webpack-chain(链接请戳我) 来完成 webpack 配置的修改。这种方式也使得 webpack 的配置更加灵活,当你的项目迁移至 @vue/[email protected],使用的 webpack 插件也必须要使用 API 式的配置,同时插件不仅仅要提供插件自身的功能,同时也需要帮助调用方完成插件的注册等工作。
@vue/cli-service 将基于 webpack 的本地开发构建配置收敛至内部来实现,当你没有特殊的开发构建需求的时候,内部配置可以开箱即用,不用开发者去关心一些细节。当然在实际团队开发当中,内部配置肯定是无法满足的,得益于 @vue-cli@3.0 的插件构建设计,开发者不需要将内部的配置进行 Eject,而是直接使用 @vue/cli-service 暴露出来的 API 去完成对于特殊的开发构建需求。
以上介绍了 @vue/cli-service 插件系统当中几个核心的模块,即:
Service.js 提供服务的基类,它提供了 @vue/cli 生态当中本地开发构建时:插件加载(包括内部插件和项目应用插件)、插件的初始化,它的单例被所有的插件所共享,插件使用它的单例去完成 webpack 的更新。
PluginAPI.js 提供供插件使用的对象接口,它和插件是一一对应的关系。所有供 @vue/cli-service 使用的本地开发构建的插件接收的第一个参数都是 PluginAPI 的实例(api),插件使用这个实例去完成 CLI 命令的注册及对应服务的执行、webpack 配置的更新等。
以上就是 @vue/cli-service 插件系统简单的分析,感兴趣的同学可以深入阅读相关源码(链接请戳我)进行学习。
不同于之前 1.x/2.x 的 vue-cli 工具都是基于远程模板去完成项目的初始化的工作,它属于那种大而全的方式,当你需要完成自定义的脚手架工具时,你可能要对 vue-cli 进行源码级别的改造,或者是在远程模板里面帮开发者将所有的配置文件初始化完成好。而 @vue/[email protected] 主要是基于插件的 generator 去完成项目的初始化的工作,它将原来的大而全的模板拆解为现在基于插件系统的工作方式,每个插件完成自己所要对于项目应用的模板拓展工作。
@vue/cli 提供了终端里面的 vue 命令,例如:
vue create <project> 创建一个新的 vue 项目vue ui 打开 vue-cli 的可视化配置当你需要对 vue-cli 进行改造,自定义符合自己开发要求的脚手架的时候,那么你需要通过开发 vue-cli 插件来对 vue-cli 提供的服务进行拓展来满足相关的要求。vue-cli 插件始终包含一个 Service 插件作为其主要导出,且可选的包含一个 Generator 和一个 Prompt 文件。这里不细讲如何去开发一个 vue-cli 插件了,大家感兴趣的可以阅读vue-cli-plugin-eslint
这里主要是来看下 vue-cli 是如何设计整个插件系统以及整个插件系统是如何工作的。
@vue/[email protected] 提供的插件安装方式为一个 cli 服务:vue add <plugin>:
install a plugin and invoke its generator in an already created project
执行这条命令后,@vue/cli 会帮你完成插件的下载,安装以及执行插件所提供的 generator。整个流程的执行顺序可通过如下的流程图去概括:
TODO: 插入流程图
我们来看下具体的代码逻辑:
// @vue/cli/lib/add.js
async function add (pluginName, options = {}, context = process.cwd()) {
...
const packageManager = loadOptions().packageManager || (hasProjectYarn(context) ? 'yarn' : 'npm')
// 开始安装这个插件
await installPackage(context, packageManager, null, packageName)
log(`${chalk.green('✔')} Successfully installed plugin: ${chalk.cyan(packageName)}`)
log()
// 判断插件是否提供了 generator
const generatorPath = resolveModule(`${packageName}/generator`, context)
if (generatorPath) {
invoke(pluginName, options, context)
} else {
log(`Plugin ${packageName} does not have a generator to invoke`)
}
}首先 cli 内部会安装这个插件,并判断这个插件是否提供了 generator,若提供了那么去执行对应的 generator。
// @vue/cli/lib/invoke.js
async function invoke (pluginName, options = {}, context = process.cwd()) {
const pkg = getPkg(context)
...
// 从项目应用package.json中获取插件名
const id = findPlugin(pkg.devDependencies) || findPlugin(pkg.dependencies)
...
// 加载对应插件提供的generator方法
const pluginGenerator = loadModule(`${id}/generator`, context)
...
const plugin = {
id,
apply: pluginGenerator,
options
}
// 开始执行generator方法
await runGenerator(context, plugin, pkg)
}
async function runGenerator (context, plugin, pkg = getPkg(context)) {
...
// 实例化一个Generator实例
const generator = new Generator(context, {
pkg
plugins: [plugin], // 插件提供的generator方法
files: await readFiles(context), // 将项目当中的文件读取为字符串的形式保存到内存当中,被读取的文件规则具体见readFiles方法
completeCbs: createCompleteCbs,
invoking: true
})
...
// resolveFiles 将内存当中的所有缓存的 files 输出到文件当中
await generator.generate({
extractConfigFiles: true,
checkExisting: true
})
}和 @vue/cli-service 类似,在 @vue/cli 内部也有一个核心的类Generator,每个@vue/cli的插件对应一个Generator的实例。在实例化Generator方法的过程当中,完成插件提供的 generator 的执行。
// @vue/cli/lib/Generator.js
module.exports = class Generator {
constructor (context, {
pkg = {},
plugins = [],
completeCbs = [],
files = {},
invoking = false
} = {}) {
this.context = context
this.plugins = plugins
this.originalPkg = pkg
this.pkg = Object.assign({}, pkg)
this.imports = {}
this.rootOptions = {}
...
this.invoking = invoking
// for conflict resolution
this.depSources = {}
// virtual file tree
this.files = files
this.fileMiddlewares = []
this.postProcessFilesCbs = []
...
const cliService = plugins.find(p => p.id === '@vue/cli-service')
const rootOptions = cliService
? cliService.options
: inferRootOptions(pkg)
// apply generators from plugins
// 每个插件对应生成一个 GeneratorAPI 实例,并将实例 api 传入插件暴露出来的 generator 函数
plugins.forEach(({ id, apply, options }) => {
const api = new GeneratorAPI(id, this, options, rootOptions)
apply(api, options, rootOptions, invoking)
})
}
}和 @vue/cli-service 所使用的插件类似,@vue/cli 插件所提供的 generator 也是向外暴露一个函数,接收的第一个参数 api,然后通过该 api 提供的方法去完成应用的拓展工作。
开发者利用这个 api 实例去完成项目应用的拓展工作,这个 api 实例提供了:
api.extendPackage)api.render)api.onCreateComplete)import语法的方法(api.injectImports)例如 @vue/cli-plugin-eslint 插件的 generator 方法主要是完成了:vue-cli-service cli lint 服务命令的添加、相关 lint 标准库的依赖添加等工作:
module.exports = (api, { config, lintOn = [] }, _, invoking) => {
if (typeof lintOn === 'string') {
lintOn = lintOn.split(',')
}
const eslintConfig = require('./eslintOptions').config(api)
const pkg = {
scripts: {
lint: 'vue-cli-service lint'
},
eslintConfig,
devDependencies: {}
}
if (config === 'airbnb') {
eslintConfig.extends.push('@vue/airbnb')
Object.assign(pkg.devDependencies, {
'@vue/eslint-config-airbnb': '^3.0.0-rc.10'
})
} else if (config === 'standard') {
eslintConfig.extends.push('@vue/standard')
Object.assign(pkg.devDependencies, {
'@vue/eslint-config-standard': '^3.0.0-rc.10'
})
} else if (config === 'prettier') {
eslintConfig.extends.push('@vue/prettier')
Object.assign(pkg.devDependencies, {
'@vue/eslint-config-prettier': '^3.0.0-rc.10'
})
} else {
// default
eslintConfig.extends.push('eslint:recommended')
}
...
api.extendPackage(pkg)
...
// lint & fix after create to ensure files adhere to chosen config
if (config && config !== 'base') {
api.onCreateComplete(() => {
require('./lint')({ silent: true }, api)
})
}
}以上介绍了 @vue/cli 和插件系统相关的几个核心的模块,即:
add.js 提供了插件下载的 cli 命令服务和安装的功能;
invoke.js 完成插件所提供的 generator 方法的加载和执行,同时将项目当中的文件转化为字符串缓存到内存当中;
Generator.js 和插件进行桥接,@vue/cli 每次 add 一个插件时,都会实例化一个 Generator 实例与之对应;
GeneratorAPI.js 和插件一一对应,是 @vue/cli 暴露给插件的 api 对象,提供了很多项目应用的拓展工作。
以上是对 [email protected] 的插件系统当中两个主要部分:@vue/cli 和 @vue/cli-service 简析。
vue create <projectName>、vue add <pluginName>前者主要完成了对于插件的依赖管理,项目模板的拓展等,后者主要是提供了在运行时本地开发构建的服务,同时后者也作为 @vue/cli 整个插件系统当中的内部核心插件而存在。在插件系统内部也对核心功能进行了插件化的拆解,例如 @vue/cli-service 内置的基础 webpack 配置,npm script 命令等。二者使用约定式的方式向开发者提供插件的拓展能力,具体到如何开发 @vue/cli 的插件请戳我查阅相关文档
交叉类型操作符。主要用于将多种类型合并为一个类型
type TypeA = {
...
}
type TypeB = {
...
}
type TypeC = {
...
}
type A = TypeA & TypeB & TypeC用以获取一个类型的所有键值。最终得到的是一个联合类型的类型:
type Person = {
name: string,
age: number
}
type TypeA = keyof Person // TypeA 的类型即为字符串字面量联合类型 'name' | 'string'再比如一个例子:
const color = {
red: 'red',
blue: 'blue'
}
type Colors = keyof typeof color // 首先通过 typeof 类型操作符获取 color 变量的类型,然后通过 keyof 获取这个类型的所有键值,即字符串字面量联合类型 'red' | 'blue'
let color: Colors
color = 'red' // ok
color = 'blue' // ok
color = 'yellow' // Error 不能被赋值为 yellow用以获取变量的类型。因此这个操作符的后面接的始终是一个变量,且需要运用到类型定义当中。
type TypeA = {
name: string,
age: number
}
let person: TypeA = {
name: 'foo',
age: 18
}
type TypeB = typeof person // 通过 typeof 类型操作符去获取变量 person 的类型主要用以申明索引签名。
// 例1:
type Index = 'a' | 'b' | 'c'
type FromIndex = { [K in Index]?: number }
const good: FromIndex = { b: 1, c: 2 } // OK
const bad: FromIndex = { b: 1, c: 2, d: 3 } // Error. 不能添加 d 属性
// 例2:
type FromSomeIndex<K extends string> = { [key in K]: number } // 在这里使用泛型限制了 K 的类型为 string,因此可以作为索引签名再比如一些TS内置的映射类型当中:
type Readonly<T> = {
readonly [K in keyof T]: T[K] // 首先通过 keyof 操作符获取类型 T 上的字符串联合类型,然后通过 in 操作符遍历这个联合类型,并依次将联合类型当中每个值绑定到这个映射类型的属性上
}类型继承操作符。
U extends K ? X : Y 如果类型 U 能赋值给类型 K,那么最终的类型为 X,否则为 Y。
例如几个内置的TS条件类型:
type Exclude<T, U> = T extends U ? never: T
type Extract<T, U> = T extends U ? T : never
type NonNullable<T> = T extends null | undefined ? never : T需要注意的是,如果待检查的类型 U 为联合类型,那么最终为衍变成分布式的条件类型,U extends K ? X : Y,其中类型 U 为联合类型:A | B | C,那么最终会被解析为(A extends K ? X : Y) | (B extends K ? X : Y) | (C extends K ? X : Y)例如:
type BoxedValue<T> = { value: T }
type BoxedArray<T> = { array: T[] }
type Boxed<T> = T extends any[] ? BoxedArray<T[number]> : BoxedValue<T>
type b1 = Boxed<string> // BoxedValue<string>
type b2 = Boxed<number[]> // BoxedArray<number>
type b3 = Boxed<string | number[]> // BoxeValue<string> | BoxedArray<number>Es Module 和 CommonJS 规范都支持循环依赖。不过2个规范对于模块的加载和执行的策略不一样,所以在实际场景当中如果遇到了循环依赖的情况的话,
CommonJS 规范从加载策略来说是运行时加载,即代码执行到需要加载模块的那一行代码的时候,才会去加载并执行对应依赖的模块。举个例子:
foo.js和bar.js形成了一个循环依赖。这里可以看到foo.js导出变量书写的位置直接影响到了bar.js代码的执行。当bar.js开始执行的时候,如果在foo.js还未执行到exports.setFooParams导出这个方法的时候,在bar.js里面是访问不到对应方法的,这样程序执行的时候也就会报错。那么规避这种情况的一个处理方法就提前将exports.setFooParams方法置于文件的顶部,提前导出。
// foo.js
const { setBarParams } = require('./bar')
const params = {}
exports.setFooParams = function (obj) {
Object.assign(params, obj);
}
setBarParams({ a: 1 });
// bar.js
const { setFooParams } = require('./foo')
const params = {};
exports.setBarParams = function (obj) {
Object.assign(params, obj);
}
setFooParams({ b: 2 });Es Module 规范当中,规定使用 import 来导入模块,export 来导出模块的接口,导出的变量或方法为引用类型,这也是和 CommonJS 规范导出变量为值拷贝的不同点之一。Es Module 在代码的静态编译阶段就确定了模块之间的相互依赖关系,在 Es Module 执行的过程中,import 导入模块有提升的效果,即在一个文件当中,可能你的导入的其他模块的代码是在文件的下方,但是在实际执行的过程当中首先会执行 import 导入模块的代码的。因为这样的特性,在 Es Module 当中如果遇到了循环依赖的情况:
// a.js
console.log('this is a file')
import { setBParams } from './b'
var params = {}
export function setAParams(obj) {
Object.assign(params, obj)
}
setBParams({ a: 1 })
// b.js
var params = {}
import { setAParams } from './a'
export function setBParams(obj) {
Object.assign(params, obj)
}
console.log('this is b file')
setAParams({ b: 2 })开始执行a.js代码的时候,实际上会先执行b.js的代码,因此在b.js当中当执行到setAParams方法的时候,在a.js里面params变量仅仅完成了申明,还未走到赋值的阶段,因此会在setAParams调用的时候出现报错的情况(Object.assign方法接受的第一个参数类型不能为undefined或者null)。
一般在书写代码的过程中不会特别留心有关 ES Module 出现循环依赖的场景,不过随着项目的迭代和应用代码的增加,以及不同的开发人员参与到项目的开发迭代当中,如果对于模块之间的相互引用关系不清晰或者是在模块设计开发阶段没有做好合理的规划,在日后的开发过程中还是会比较容易出现这种循环依赖的场景。
接下来简单总结下最近在开发过程中遇到循环依赖这一问题以及针对这个问题如何解决的。
在我们日常的开发过程当中,将一些通用的功能抽离成 sdk 单独的去维护。sdk 内部的模块是以职责功能维度去进行划分的:
这里暂且将 Init、Login、Omega、Ajax 分别成为一级模块。然后每个一级模块内部可能还会进行相关子模块(二级模块)的拆解,例如目前:
Init 一级模块里面包含了:
Ajax 一级模块里包含了:
当然每个模块是有一级导出(index.js文件一般会集合不同的二级模块并将它们导出)的,不同模块之间有相互引用关系,例如 Ajax 模块可能会使用 Init 模块当中提供的一些公参。
随着 sdk 功能的迭代,目前这些一级模块的导出(index.js)所承担的职责越来越多:
这也为之后的模块的迭代拓展埋下的隐患。
比如这次需要增加一个global.js挂载相关全局对象的一个二级模块,从功能职责角度来说将它放到 Init 一级模块之下是合理的。不过在global.js里面是引入了Ajax的一级模块(index.js)的,这个Ajax一级模块所遇到的问题和我上面描述的一样:所承担的职责越来越多。在这个一级模块当中,引入了Init的一级模块来完成一些公参的初始化的工作。这样一来二去,也就遇到了循环依赖的问题,最终导致代码不是按我们的预期去执行。

Init(global.js 作为 Init 模块的子模块被引入,且被导出相关 API) <- global.js <- Ajax(Ajax 模块依赖 Init 模块提供的方法完成基础参数的初始化) <- Init
针对这个问题,首先确保 sdk 在接口和调用方式不变的前提下,进行进一步的功能模块的拆解和文件组织,最终所达到的效果就是:

这样在完成global.js的功能的时候,如果需要挂载 Ajax 模块提供的全局变量,那么global.js不再需要依赖 Ajax 的一级模块,直接引入对应的二级模块(instance.js)导出的实例即可。同时在 Ajax 模块当中原本依赖 Init 模块提供的公参也只需要从 Init 的二级模块(params.js)当中引入。这样也就解除了 Init <-> Ajax 一级模块之间的相互引用,因此他们之间的循环依赖也就被打破了。
在写代码的过程中一般不会特别去留心这种模块之间的相互依赖,特别是涉及到模块多,且 module graph 较为复杂的情况,在不经意之间也就会出现模块之间的循环依赖。不过需要留心的就是:
仅做导出,没有导入的(即不依赖其他模块,在 module graph 当中处于端点的模块,例如在图二当中的 params.js)模块是安全的。那些除了导出,还有导入的模块存在这种出现循环依赖的风险;
循环依赖的模块因为 Es Module 的执行机制,如果是同步代码执行,则会出现未获取到导出模块的接口情况,这样会出现代码执行不合符预期的情况(在文中一开始举的那个 Es Module 的例子)。如果是异步执行的代码,或者是需要被调用的方法例如事件响应等,则不会出现这个问题。所以说相互之间出现循环依赖的模块执行期间是否符合预期,还和模块里面的代码执行的时机有关;
如果循环依赖之间的模块执行不符合预期,那么就需要重新思考模块的设计和拆分是否合理。
其他拓展阅读:
前2篇文章主要通过源码分析了 loader 的配置,匹配和加载,执行等内容,这篇文章会通过具体的实例来学习下如何去实现一个 loader。
这里我们来看下 vue-loader(v15) 内部的相关内容,这里会讲解下有关 vue-loader 的大致处理流程,不会深入特别细节的地方。
git clone [email protected]:vuejs/vue-loader.git我们使用 vue-loader 官方仓库当中的 example 目录的内容作为整篇文章的示例。
首先我们都知道 vue-loader 配合 webpack 给我们开发 Vue 应用提供了非常大的便利性,允许我们在 SFC(single file component) 中去写我们的 template/script/style,同时 v15 版本的 vue-loader 还允许开发在 SFC 当中写 custom block。最终一个 Vue SFC 通过 vue-loader 的处理,会将 template/script/style/custom block 拆解为独立的 block,每个 block 还可以再交给对应的 loader 去做进一步的处理,例如你的 template 是使用 pug 来书写的,那么首先使用 vue-loader 获取一个 SFC 内部 pug 模板的内容,然后再交给 pug 相关的 loader 处理,可以说 vue-loader 对于 Vue SFC 来说是一个入口处理器。
在实际运用过程中,我们先来看下有关 Vue 的 webpack 配置:
const VueloaderPlugin = require('vue-loader/lib/plugin')
module.exports = {
...
module: {
rules: [
...
{
test: /\.vue$/,
loader: 'vue-loader'
}
]
}
plugins: [
new VueloaderPlugin()
]
...
}一个就是 module.rules 有关的配置,如果处理的 module 路径是以.vue形式结尾的,那么会交给 vue-loader 来处理,同时在 v15 版本必须要使用 vue-loader 内部提供的一个 plugin,它的职责是将你定义过的其它规则复制并应用到 .vue 文件里相应语言的块。例如,如果你有一条匹配 /\.js$/ 的规则,那么它会应用到 .vue 文件里的 <script> 块,说到这里我们就一起先来看看这个 plugin 里面到底做了哪些工作。
我们都清楚 webpack plugin 的装载过程是在整个 webpack 编译周期中初始阶段,我们先来看下 VueLoaderPlugin 内部源码的实现:
// vue-loader/lib/plugin.js
class VueLoaderPlugin {
apply() {
...
// use webpack's RuleSet utility to normalize user rules
const rawRules = compiler.options.module.rules
const { rules } = new RuleSet(rawRules)
// find the rule that applies to vue files
// 判断是否有给`.vue`或`.vue.html`进行 module.rule 的配置
let vueRuleIndex = rawRules.findIndex(createMatcher(`foo.vue`))
if (vueRuleIndex < 0) {
vueRuleIndex = rawRules.findIndex(createMatcher(`foo.vue.html`))
}
const vueRule = rules[vueRuleIndex]
...
// 判断对于`.vue`或`.vue.html`配置的 module.rule 是否有 vue-loader
// get the normlized "use" for vue files
const vueUse = vueRule.use
// get vue-loader options
const vueLoaderUseIndex = vueUse.findIndex(u => {
return /^vue-loader|(\/|\\|@)vue-loader/.test(u.loader)
})
...
// 创建 pitcher loader 的配置
const pitcher = {
loader: require.resolve('./loaders/pitcher'),
resourceQuery: query => {
const parsed = qs.parse(query.slice(1))
return parsed.vue != null
},
options: {
cacheDirectory: vueLoaderUse.options.cacheDirectory,
cacheIdentifier: vueLoaderUse.options.cacheIdentifier
}
}
// 拓展开发者的 module.rule 配置,加入 vue-loader 内部提供的 pitcher loader
// replace original rules
compiler.options.module.rules = [
pitcher,
...clonedRules,
...rules
]
}
}这个 plugin 主要完成了以下三部分的工作:
.vue或.vue.html进行 module.rule 的配置;.vue或.vue.html配置的 module.rule 是否有 vue-loader;我们看到有关 pitcher loader 的 rule 匹配条件是通过resourceQuery方法来进行判断的,即判断 module path 上的 query 参数是否存在 vue,例如:
// 这种类型的 module path 就会匹配上
'./source.vue?vue&type=template&id=27e4e96e&scoped=true&lang=pug&'如果存在的话,那么就需要将这个 loader 加入到构建这个 module 的 loaders 数组当中。以上就是 VueLoaderPlugin 所做的工作,其中涉及到拓展后的 module rule 里面加入的 pitcher loader 具体做的工作后文会分析。
接下来我们看下 vue-loader 的内部实现。首先来看下入口文件的相关内容:
// vue-loader/lib/index.js
...
const { parse } = require('@vue/component-compiler-utils')
function loadTemplateCompiler () {
try {
return require('vue-template-compiler')
} catch (e) {
throw new Error(
`[vue-loader] vue-template-compiler must be installed as a peer dependency, ` +
`or a compatible compiler implementation must be passed via options.`
)
}
}
module.exports = function(source) {
const loaderContext = this // 获取 loaderContext 对象
// 从 loaderContext 获取相关参数
const {
target, // webpack 构建目标,默认为 web
request, // module request 路径(由 path 和 query 组成)
minimize, // 构建模式
sourceMap, // 是否开启 sourceMap
rootContext, // 项目的根路径
resourcePath, // module 的 path 路径
resourceQuery // module 的 query 参数
} = loaderContext
// 接下来就是一系列对于参数和路径的处理
const rawQuery = resourceQuery.slice(1)
const inheritQuery = `&${rawQuery}`
const incomingQuery = qs.parse(rawQuery)
const options = loaderUtils.getOptions(loaderContext) || {}
...
// 开始解析 sfc,根据不同的 block 来拆解对应的内容
const descriptor = parse({
source,
compiler: options.compiler || loadTemplateCompiler(),
filename,
sourceRoot,
needMap: sourceMap
})
// 如果 query 参数上带了 block 的 type 类型,那么会直接返回对应 block 的内容
// 例如: foo.vue?vue&type=template,那么会直接返回 template 的文本内容
if (incomingQuery.type) {
return selectBlock(
descriptor,
loaderContext,
incomingQuery,
!!options.appendExtension
)
}
...
// template
let templateImport = `var render, staticRenderFns`
let templateRequest
if (descriptor.template) {
const src = descriptor.template.src || resourcePath
const idQuery = `&id=${id}`
const scopedQuery = hasScoped ? `&scoped=true` : ``
const attrsQuery = attrsToQuery(descriptor.template.attrs)
const query = `?vue&type=template${idQuery}${scopedQuery}${attrsQuery}${inheritQuery}`
const request = templateRequest = stringifyRequest(src + query)
templateImport = `import { render, staticRenderFns } from ${request}`
}
// script
let scriptImport = `var script = {}`
if (descriptor.script) {
const src = descriptor.script.src || resourcePath
const attrsQuery = attrsToQuery(descriptor.script.attrs, 'js')
const query = `?vue&type=script${attrsQuery}${inheritQuery}`
const request = stringifyRequest(src + query)
scriptImport = (
`import script from ${request}\n` +
`export * from ${request}` // support named exports
)
}
// styles
let stylesCode = ``
if (descriptor.styles.length) {
stylesCode = genStylesCode(
loaderContext,
descriptor.styles,
id,
resourcePath,
stringifyRequest,
needsHotReload,
isServer || isShadow // needs explicit injection?
)
}
let code = `
${templateImport}
${scriptImport}
${stylesCode}
/* normalize component */
import normalizer from ${stringifyRequest(`!${componentNormalizerPath}`)}
var component = normalizer(
script,
render,
staticRenderFns,
${hasFunctional ? `true` : `false`},
${/injectStyles/.test(stylesCode) ? `injectStyles` : `null`},
${hasScoped ? JSON.stringify(id) : `null`},
${isServer ? JSON.stringify(hash(request)) : `null`}
${isShadow ? `,true` : ``}
)
`.trim() + `\n`
if (descriptor.customBlocks && descriptor.customBlocks.length) {
code += genCustomBlocksCode(
descriptor.customBlocks,
resourcePath,
resourceQuery,
stringifyRequest
)
}
...
// Expose filename. This is used by the devtools and Vue runtime warnings.
code += `\ncomponent.options.__file = ${
isProduction
// For security reasons, only expose the file's basename in production.
? JSON.stringify(filename)
// Expose the file's full path in development, so that it can be opened
// from the devtools.
: JSON.stringify(rawShortFilePath.replace(/\\/g, '/'))
}`
code += `\nexport default component.exports`
return code
}以上就是 vue-loader 的入口文件(index.js)主要做的工作:对于 request 上不带 type 类型的 Vue SFC 进行 parse,获取每个 block 的相关内容,将不同类型的 block 组件的 Vue SFC 转化成 js module 字符串,具体的内容如下:
import { render, staticRenderFns } from "./source.vue?vue&type=template&id=27e4e96e&scoped=true&lang=pug&"
import script from "./source.vue?vue&type=script&lang=js&"
export * from "./source.vue?vue&type=script&lang=js&"
import style0 from "./source.vue?vue&type=style&index=0&id=27e4e96e&scoped=true&lang=css&"
/* normalize component */
import normalizer from "!../lib/runtime/componentNormalizer.js"
var component = normalizer(
script,
render,
staticRenderFns,
false,
null,
"27e4e96e",
null
)
/* custom blocks */
import block0 from "./source.vue?vue&type=custom&index=0&blockType=foo"
if (typeof block0 === 'function') block0(component)
// 省略了有关 hotReload 的代码
component.options.__file = "example/source.vue"
export default component.exports从生成的 js module 字符串来看:将由 source.vue 提供 render函数/staticRenderFns,js script,style样式,并交由 normalizer 进行统一的格式化,最终导出 component.exports。
这样 vue-loader 处理的第一个阶段结束了,vue-loader 在这一阶段将 Vue SFC 转化为 js module 后,接下来进入到第二阶段,将新生成的 js module 加入到 webpack 的编译环节,即对这个 js module 进行 AST 的解析以及相关依赖的收集过程,这里我用每个 request 去标记每个被收集的 module(这里只说明和 Vue SFC 相关的模块内容):
[
'./source.vue?vue&type=template&id=27e4e96e&scoped=true&lang=pug&',
'./source.vue?vue&type=script&lang=js&',
'./source.vue?vue&type=style&index=0&id=27e4e96e&scoped=true&lang=css&',
'./source.vue?vue&type=custom&index=0&blockType=foo'
]我们看到通过 vue-loader 处理到得到的 module path 上的 query 参数都带有 vue 字段。这里便涉及到了我们在文章开篇提到的 VueLoaderPlugin 加入的 pitcher loader。如果遇到了 query 参数上带有 vue 字段的 module path,那么就会把 pitcher loader 加入到处理这个 module 的 loaders 数组当中。因此这个 module 最终也会经过 pitcher loader 的处理。此外在 loader 的配置顺序上,pitcher loader 为第一个,因此在处理 Vue SFC 模块的时候,最先也是交由 pitcher loader 来处理。
事实上对一个 Vue SFC 处理的第二阶段就是刚才提到的,Vue SFC 会经由 pitcher loader 来做进一步的处理。那么我们就来看下 vue-loader 内部提供的 pitcher loader 主要是做了哪些工作呢:
// vue-loader/lib/loaders/pitcher.js
module.export = code => code
module.pitch = function () {
...
const query = qs.parse(this.resourceQuery.slice(1))
let loaders = this.loaders
// 剔除 eslint loader
// if this is a language block request, eslint-loader may get matched
// multiple times
if (query.type) {
// if this is an inline block, since the whole file itself is being linted,
// remove eslint-loader to avoid duplicate linting.
if (/\.vue$/.test(this.resourcePath)) {
loaders = loaders.filter(l => !isESLintLoader(l))
} else {
// This is a src import. Just make sure there's not more than 1 instance
// of eslint present.
loaders = dedupeESLintLoader(loaders)
}
}
// 剔除 pitcher loader 自身
// remove self
loaders = loaders.filter(isPitcher)
if (query.type === 'style') {
const cssLoaderIndex = loaders.findIndex(isCSSLoader)
if (cssLoaderIndex > -1) {
const afterLoaders = loaders.slice(0, cssLoaderIndex + 1)
const beforeLoaders = loaders.slice(cssLoaderIndex + 1)
const request = genRequest([
...afterLoaders,
stylePostLoaderPath,
...beforeLoaders
])
return `import mod from ${request}; export default mod; export * from ${request}`
}
}
if (query.type === 'template') {
const path = require('path')
const cacheLoader = cacheDirectory && cacheIdentifier
? [`cache-loader?${JSON.stringify({
// For some reason, webpack fails to generate consistent hash if we
// use absolute paths here, even though the path is only used in a
// comment. For now we have to ensure cacheDirectory is a relative path.
cacheDirectory: path.isAbsolute(cacheDirectory)
? path.relative(process.cwd(), cacheDirectory)
: cacheDirectory,
cacheIdentifier: hash(cacheIdentifier) + '-vue-loader-template'
})}`]
: []
const request = genRequest([
...cacheLoader,
templateLoaderPath + `??vue-loader-options`,
...loaders
])
// the template compiler uses esm exports
return `export * from ${request}`
}
// if a custom block has no other matching loader other than vue-loader itself,
// we should ignore it
if (query.type === `custom` &&
loaders.length === 1 &&
loaders[0].path === selfPath) {
return ``
}
// When the user defines a rule that has only resourceQuery but no test,
// both that rule and the cloned rule will match, resulting in duplicated
// loaders. Therefore it is necessary to perform a dedupe here.
const request = genRequest(loaders)
return `import mod from ${request}; export default mod; export * from ${request}`
}对于 style block 的处理,首先判断是否有 css-loader,如果有的话就重新生成一个新的 request,这个 request 包含了 vue-loader 内部提供的 stylePostLoader,并返回一个 js module,根据 pitch 函数的规则,pitcher loader 后面的 loader 都会被跳过,这个时候开始编译这个返回的 js module。相关的内容为:
import mod from "-!../node_modules/vue-style-loader/index.js!../node_modules/css-loader/index.js!../lib/loaders/stylePostLoader.js!../lib/index.js??vue-loader-options!./source.vue?vue&type=style&index=0&id=27e4e96e&scoped=true&lang=css&"
export default mod
export * from "-!../node_modules/vue-style-loader/index.js!../node_modules/css-loader/index.js!../lib/loaders/stylePostLoader.js!../lib/index.js??vue-loader-options!./source.vue?vue&type=style&index=0&id=27e4e96e&scoped=true&lang=css&" 对于 template block 的处理流程类似,生成一个新的 request,这个 request 包含了 vue-loader 内部提供的 templateLoader,并返回一个 js module,并跳过后面的 loader,然后开始编译返回的 js module。相关的内容为:
export * from "-!../lib/loaders/templateLoader.js??vue-loader-options!../node_modules/pug-plain-loader/index.js!../lib/index.js??vue-loader-options!./source.vue?vue&type=template&id=27e4e96e&scoped=true&lang=pug&"这样对于一个 Vue SFC 处理的第二阶段也就结束了,通过 pitcher loader 去拦截不同类型的 block,并返回新的 js module,跳过后面的 loader 的执行,同时在内部会剔除掉 pitcher loader,这样在进入到下一个处理阶段的时候,pitcher loader 不在使用的 loader 范围之内,因此下一阶段 Vue SFC 便不会经由 pitcher loader 来处理。
接下来进入到第三个阶段,编译返回的新的 js module,完成 AST 的解析和依赖收集工作,并开始处理不同类型的 block 的编译转换工作。就拿 Vue SFC 当中的 style / template block 来举例,
style block 会经过以下的流程处理:
source.vue?vue&type=style -> vue-loader(抽离 style block) -> stylePostLoader(处理作用域 scoped css) -> css-loader(处理相关资源引入路径) -> vue-style-loader(动态创建 style 标签插入 css)

template block 会经过以下的流程处理:
source.vue?vue&type=template -> vue-loader(抽离 template block ) -> pug-plain-loader(将 pug 模块转化为 html 字符串) -> templateLoader(编译 html 模板字符串,生成 render/staticRenderFns 函数并暴露出去)

我们看到经过 vue-loader 处理时,会根据不同 module path 的类型(query 参数上的 type 字段)来抽离 SFC 当中不同类型的 block。这也是 vue-loader 内部定义的相关规则:
// vue-loader/lib/index.js
const qs = require('querystring')
const selectBlock = require('./select')
...
module.exports = function (source) {
...
const rawQuery = resourceQuery.slice(1)
const inheritQuery = `&${rawQuery}`
const incomingQuery = qs.parse(rawQuery)
...
const descriptor = parse({
source,
compiler: options.compiler || loadTemplateCompiler(),
filename,
sourceRoot,
needMap: sourceMap
})
// if the query has a type field, this is a language block request
// e.g. foo.vue?type=template&id=xxxxx
// and we will return early
if (incomingQuery.type) {
return selectBlock(
descriptor,
loaderContext,
incomingQuery,
!!options.appendExtension
)
}
...
}当 module path 上的 query 参数带有 type 字段,那么会直接调用 selectBlock 方法去获取 type 对应类型的 block 内容,跳过 vue-loader 后面的处理流程(这也是与 vue-loader 第一次处理这个 module时流程不一样的地方),并进入到下一个 loader 的处理流程中,selectBlock 方法内部主要就是根据不同的 type 类型(template/script/style/custom),来获取 descriptor 上对应类型的 content 内容并传入到下一个 loader 处理:
module.exports = function selectBlock (
descriptor,
loaderContext,
query,
appendExtension
) {
// template
if (query.type === `template`) {
if (appendExtension) {
loaderContext.resourcePath += '.' + (descriptor.template.lang || 'html')
}
loaderContext.callback(
null,
descriptor.template.content,
descriptor.template.map
)
return
}
// script
if (query.type === `script`) {
if (appendExtension) {
loaderContext.resourcePath += '.' + (descriptor.script.lang || 'js')
}
loaderContext.callback(
null,
descriptor.script.content,
descriptor.script.map
)
return
}
// styles
if (query.type === `style` && query.index != null) {
const style = descriptor.styles[query.index]
if (appendExtension) {
loaderContext.resourcePath += '.' + (style.lang || 'css')
}
loaderContext.callback(
null,
style.content,
style.map
)
return
}
// custom
if (query.type === 'custom' && query.index != null) {
const block = descriptor.customBlocks[query.index]
loaderContext.callback(
null,
block.content,
block.map
)
return
}
}通过 vue-loader 的源码我们看到一个 Vue SFC 在整个编译构建环节是怎么样一步一步处理的,这也是得益于 webpack 给开发这提供了这样一种 loader 的机制,使得开发者通过这样一种方式去对项目源码做对应的转换工作以满足相关的开发需求。结合之前的2篇有关 webpack loader 源码的分析,大家应该对 loader 有了更加深入的理解,也希望大家活学活用,利用 loader 机制去完成更多贴合实际需求的开发工作。
Vue version: 2.5.16
Vue的组件系统是Vue最为核心的功能之一。它也是构建大型的复杂的web应用的基础能力。接下来就通过这篇文章去分析下Vue组件系统是如何工作的。这篇文章主要是讲组件系统的渲染。
在组件的注册使用过程当中,有2种使用方式:
Vue.component('component-name', {
// options
})通过全局方式注册的组件,可在模板根实例下使用。
var Parent = {
template: '<div>A custom component!<child></child></div>',
components: {
child: {
template: '<p>This is child component</p>'
}
}
}
new Vue({
// ...
components: {
'parent-component': Parent
}
})通过局部注册方式注册的child组件只能在parent组件内部使用。
首先,我们来看下全局组件:
Vue.component方法提供了全局注册组件的能力,这也是Vue在初始化的过程中,通过内部的initGlobalAPI方法,在Vue这个全局唯一个根constructor上挂载的一个方法。
function initGlobalAPI (Vue) {
...
initAssetRegisters(Vue);
...
}
// ASSET_TYPES -> ['component', 'directive', 'filter']
function initAssetRegisters (Vue) {
/**
* Create asset registration methods.
*/
ASSET_TYPES.forEach(function (type) {
Vue[type] = function (
id,
definition
) {
if (!definition) {
return this.options[type + 's'][id]
} else {
...
if (type === 'component' && isPlainObject(definition)) {
definition.name = definition.name || id;
definition = this.options._base.extend(definition);
}
...
// 在 Vue.options 的 components 属性上挂载组件的 constructor
this.options[type + 's'][id] = definition;
return definition
}
};
});
}通过Vue.component方法注册的组件最终还是调用的Vue.extend方法来完成子组件对父组件的一系列的继承的初始化的工作。主要是将根 Vue 构造函数上的 options 配置和组件定义所传入的 options 进行合并,对组件,同时在根constructor的options属性上挂载这个全局子组件的constructor。Vue.extend方法在整个Vue组件系统中算是一个建立起父子组件之间联系的作用。
Vue.extend = function (extendOptions) {
extendOptions = extendOptions || {};
var Super = this;
var SuperId = Super.cid;
// 给extendOptions设置_Ctor属性
var cachedCtors = extendOptions._Ctor || (extendOptions._Ctor = {});
if (cachedCtors[SuperId]) {
return cachedCtors[SuperId]
}
var name = extendOptions.name || Super.options.name;
...
// 子组件实例的初始化函数
var Sub = function VueComponent (options) {
this._init(options);
};
Sub.prototype = Object.create(Super.prototype);
Sub.prototype.constructor = Sub;
Sub.cid = cid++;
// 完成options合并的工作,同时建立起子组件options和Super options的原型链
Sub.options = mergeOptions(
Super.options,
extendOptions
);
Sub['super'] = Super;
...
// allow further extension/mixin/plugin usage
Sub.extend = Super.extend;
Sub.mixin = Super.mixin;
Sub.use = Super.use;
// create asset registers, so extended classes
// can have their private assets too.
ASSET_TYPES.forEach(function (type) {
Sub[type] = Super[type];
});
// enable recursive self-lookup
if (name) {
Sub.options.components[name] = Sub;
}
// keep a reference to the super options at extension time.
// later at instantiation we can check if Super's options have
// been updated.
Sub.superOptions = Super.options;
Sub.extendOptions = extendOptions;
Sub.sealedOptions = extend({}, Sub.options);
// cache constructor
cachedCtors[SuperId] = Sub;
return Sub
};大家可以看到在Vue.extend方法内部,实际上就是创建了一个VueComponent的constructor,同时还需完成这个构造函数和根constructor方法、原型链的继承工作,其中有一点关于options配置属性合并的工作。
...
Sub.options = mergeOptions(
Super.options,
extendOptions
)
...// TODO: 讲解下options合并的过程
调用mergeOptions方法,将根constructor(superCtor)的options属性和子constructor的options(subCtor)属性进行一次合并。就拿components属性来说,最终的结果就是subCtor.options.components.prototype = superCtor.options.components,同时通过mixin,使得subCtor.options.components可直接访问全局组件和局部组件。
这样调用Vue.component方法后完成全局组件的注册。Vue的局部组件和全局组件注册的方法还不太一样,首先在注册的阶段,局部组件并非和全局组件一样在代码初始化的阶段就完成了全局组件的注册,局部组件是在父组件在实例化的过程中动态的进行注册的(后面的内容会讲到这个地方)。
当全局组件在注册完毕后,开始根实例化的过程。(这篇文章主要将组件渲染过程,所以其他关于Vue的部分内容会略去不展开)
从一个实例开始:
// 模板
<div id="app">
<my-component></my-component>
<p>{{appVal}}</p>
</div>
// script
Vue.component('my-component', {
template: '<div>this is my component<child></child></div>',
components: {
'child': {
template: '<p>hello</p>'
}
}
})
new Vue({
el: '#app',
data () {
appVal: 'this is app val'
}
})首先进行根实例化,从Vue.prototype._init方法开始:
Vue.prototype._init = function () {
var vm = this
...
initRender(vm)
...
if (vm.$options.el) {
vm.$mount(vm.$options.el)
}
}在这个内部,通过调用initRender方法给实例挂载生成vnode节点的方法:
function initRender () {
...
// 在内部render函数执行生成vnode的时候调用
vm._c = function (a, b, c, d) { return createElement(vm, a, b, c, d, false); };
...
// 供开发者调用的生成vnode的方法
vm.$createElement = function (a, b, c, d) { return createElement(vm, a, b, c, d, true); };
...
}接下来根据是否有el配置选项来将vue component挂载到真实dom节点上。
// public mount method
Vue.prototype.$mount = function (
el,
hydrating
) {
el = el && inBrowser ? query(el) : undefined;
return mountComponent(this, el, hydrating)
};
var mount = Vue.prototype.$mount;
Vue.prototype.$mount = function (
el,
hydrating
) {
el = el && query(el);
var options = this.$options;
// resolve template/el and convert to render function
if (!options.render) {
var template = options.template;
if (template) {
if (typeof template === 'string') {
if (template.charAt(0) === '#') {
template = idToTemplate(template);
/* istanbul ignore if */
if ("development" !== 'production' && !template) {
warn(
("Template element not found or is empty: " + (options.template)),
this
);
}
}
} else if (template.nodeType) {
template = template.innerHTML;
} else {
{
warn('invalid template option:' + template, this);
}
return this
}
} else if (el) {
// 获取真实dom元素的字符串内容
template = getOuterHTML(el);
}
if (template) {
// 获取到模板的字符串内容后,调用compileToFunctions方法将模板字符编译成render函数
// 需要注意的是编译的时候只编译模板下的字符串,并不能直接编译当前模板的子组件的模板内容
var ref = compileToFunctions(template, {
shouldDecodeNewlines: shouldDecodeNewlines,
shouldDecodeNewlinesForHref: shouldDecodeNewlinesForHref,
delimiters: options.delimiters,
comments: options.comments
}, this);
// 生成render函数
var render = ref.render;
var staticRenderFns = ref.staticRenderFns;
options.render = render; // 挂载render函数
options.staticRenderFns = staticRenderFns; // 挂载staticRenderFns函数
}
}
return mount.call(this, el, hydrating)
}在上面的实例当中,Vue的编译系统会将html模板内容转化为render函数:
// html模板
<div id="app">
<my-component></my-component>
<p>{{appVal}}</p>
</div>
// render函数
(function() {
with(this){
return _c('div', // 标签tag
{
attrs:{"id":"app"} // 属性值
},
[ // children节点
_c('my-component'),
_v(" "),
_c('p',[_v(_s(appVal))])
], 1)}
})完成模板编译,生成render函数后,接下来调用mountComponent方法:
!!! 前方高能:
function mountComponent (
vm,
el,
hydrating
) {
vm.$el = el;
if (!vm.$options.render) {
...
}
// 挂载前
callHook(vm, 'beforeMount');
var updateComponent;
/* istanbul ignore if */
if ("development" !== 'production' && config.performance && mark) {
...
} else {
updateComponent = function () {
// vm._render首先构建完成vnode
// 然后调用vm._update方法,更vnode挂载到真实的DOM节点上
vm._update(vm._render(), hydrating);
};
}
// we set this to vm._watcher inside the watcher's constructor
// since the watcher's initial patch may call $forceUpdate (e.g. inside child
// component's mounted hook), which relies on vm._watcher being already defined
new Watcher(vm, updateComponent, noop, null, true /* isRenderWatcher */);
hydrating = false;
// manually mounted instance, call mounted on self
// mounted is called for render-created child components in its inserted hook
if (vm.$vnode == null) {
vm._isMounted = true;
callHook(vm, 'mounted');
}
return vm
}在mountComponent方法内部首先定义updateComponent方法,这个方法内部首先会调用vm._render,将模板编译后生成的渲染函数转化成vnode,然后再调用vm._update完成真实dom的更新,新实例化一个watcher,开始进行页面的渲染工作。
首先来看下vm._render是如何将渲染函数转化成vnode的:
Vue.prototype._render = function () {
var vm = this;
var ref = vm.$options;
var render = ref.render; // 获取render函数
var _parentVnode = ref._parentVnode;
...
// set parent vnode. this allows render functions to have access
// to the data on the placeholder node.
vm.$vnode = _parentVnode;
// render self
var vnode;
try {
// 开始调用render函数,用以生成vnode
vnode = render.call(vm._renderProxy, vm.$createElement);
} catch (e) {
handleError(e, vm, "render");
// return error render result,
// or previous vnode to prevent render error causing blank component
...
}
// return empty vnode in case the render function errored out
if (!(vnode instanceof VNode)) {
...
vnode = createEmptyVNode();
}
// set parent
vnode.parent = _parentVnode;
return vnode
};
}在上面已经提到了关于最后关于编译生成的render函数:
// render函数
(function() {
with(this){
return _c('div', // 标签tag
{
attrs:{"id":"app"} // 属性值
},
[ // children节点
_c('my-component'),
_v(" "),
_c('p',[_v(_s(appVal))])
], 1)}
})在实际的执行过程当中,首先完成children节点的vnode的生成工作。这里首先生成my-component子组件的vnode,我们来看下vm._c方法,这个方法内部最终是调用_createElement方法来生成vnode:
function _createElement (
context,
tag,
data,
children,
normalizationType
) {
...
// support single function children as default scoped slot
if (Array.isArray(children) &&
typeof children[0] === 'function'
) {
data = data || {};
data.scopedSlots = { default: children[0] };
children.length = 0;
}
if (normalizationType === ALWAYS_NORMALIZE) {
children = normalizeChildren(children);
} else if (normalizationType === SIMPLE_NORMALIZE) {
children = simpleNormalizeChildren(children);
}
var vnode, ns;
if (typeof tag === 'string') {
var Ctor;
ns = (context.$vnode && context.$vnode.ns) || config.getTagNamespace(tag);
if (config.isReservedTag(tag)) {
// platform built-in elements
// 如果是内置的元素,那么直接创建VNode
vnode = new VNode(
config.parsePlatformTagName(tag), data, children,
undefined, undefined, context
);
} else if (isDef(Ctor = resolveAsset(context.$options, 'components', tag))) {
// component
// 如果是自己自定义标签元素,那么需要通过createComponent完成VNode的创建工作
// 首先resolveAsset从$options属性上获取components定义
// 需要注意的是全局注册的component,最终得到的Ctor为一个function
// 而局部注册的component,最终得到的Ctor为一个plain Object
vnode = createComponent(Ctor, data, context, children, tag);
} else {
// unknown or unlisted namespaced elements
// check at runtime because it may get assigned a namespace when its
// parent normalizes children
vnode = new VNode(
tag, data, children,
undefined, undefined, context
);
}
} else {
// direct component options / constructor
vnode = createComponent(tag, data, context, children);
}
if (Array.isArray(vnode)) {
return vnode
} else if (isDef(vnode)) {
if (isDef(ns)) { applyNS(vnode, ns); }
if (isDef(data)) { registerDeepBindings(data); }
return vnode
} else {
return createEmptyVNode()
}
}
function createComponent (
Ctor,
data,
context,
children,
tag
) {
if (isUndef(Ctor)) {
return
}
// Vue构造函数
var baseCtor = context.$options._base;
// plain options object: turn it into a constructor
// 如果组件的定义是一个plain object,那么就需要通过使用Vue.extend方法将它转化为一个constructor
// 即完成局部组件的注册
if (isObject(Ctor)) {
Ctor = baseCtor.extend(Ctor);
}
...
if (isUndef(Ctor.cid)) {
...
}
data = data || {};
// resolve constructor options in case global mixins are applied after
// component constructor creation
// 获取Ctor构造函数上的options属性
resolveConstructorOptions(Ctor);
// extract props
var propsData = extractPropsFromVNodeData(data, Ctor, tag);
// functional component
if (isTrue(Ctor.options.functional)) {
return createFunctionalComponent(Ctor, propsData, data, context, children)
}
...
if (isTrue(Ctor.options.abstract)) {
...
}
// install component management hooks onto the placeholder node
// 给component初始化挂载钩子函数,只有自定义的component才有,built-in的没有
installComponentHooks(data);
// return a placeholder vnode
var name = Ctor.options.name || tag;
// 子vnode的id使用vue-component及对应的id来进行标识
var vnode = new VNode(
("vue-component-" + (Ctor.cid) + (name ? ("-" + name) : '')),
data, undefined, undefined, undefined, context,
{ Ctor: Ctor, propsData: propsData, listeners: listeners, tag: tag, children: children },
asyncFactory
);
/* istanbul ignore if */
return vnode
}因此上面提到的render函数,最终生成一个vnode
VNode {
...
children: [VNode, VNode, VNode],
tag: 'div',
elm: div#app(dom元素),
data: {
attrs: {
id: '#app'
}
},
context: Vue
...
}当根节点的VNode生成完毕后,让我们再回到mountComponent方法内部:
updateComponent = function () {
// vm._render首先构建完成vnode
// 然后调用vm._update方法,更vnode挂载到真实的DOM节点上
vm._update(vm._render(), hydrating);
};当vm._render函数生成完vnode后,执行vm._update(vnode),将vnode渲染为真实的DOM节点:
Vue.prototype._update = function (vnode, hydrating) {
var vm = this;
if (vm._isMounted) {
callHook(vm, 'beforeUpdate');
}
var prevEl = vm.$el;
var prevVnode = vm._vnode;
var prevActiveInstance = activeInstance;
activeInstance = vm;
vm._vnode = vnode;
// Vue.prototype.__patch__ is injected in entry points
// based on the rendering backend used.
if (!prevVnode) {
// initial render
// 页面初始化渲染
vm.$el = vm.__patch__(
vm.$el, vnode, hydrating, false /* removeOnly */,
vm.$options._parentElm,
vm.$options._refElm
);
// no need for the ref nodes after initial patch
// this prevents keeping a detached DOM tree in memory (#5851)
vm.$options._parentElm = vm.$options._refElm = null;
} else {
// updates
// 更新
vm.$el = vm.__patch__(prevVnode, vnode);
}
...
}当页面进行首次渲染的时候:
vm.$el = vm.__patch__(
vm.$el, vnode, hydrating, false /* removeOnly */,
vm.$options._parentElm,
vm.$options._refElm
)可查阅关于patch的方法:
function patch (oldVnode, vnode, hydrating, removeOnly, parentElm, refElm) {
...
if (isUndef(oldVnode)) {
...
} else {
// 是否是真实的dom节点
var isRealElement = isDef(oldVnode.nodeType);
if (!isRealElement && sameVnode(oldVnode, vnode)) {
// patch existing root node
patchVnode(oldVnode, vnode, insertedVnodeQueue, removeOnly);
} else {
...
// replacing existing element
var oldElm = oldVnode.elm;
var parentElm$1 = nodeOps.parentNode(oldElm);
// create new node
createElm(
vnode,
insertedVnodeQueue,
// extremely rare edge case: do not insert if old element is in a
// leaving transition. Only happens when combining transition +
// keep-alive + HOCs. (#4590)
oldElm._leaveCb ? null : parentElm$1,
nodeOps.nextSibling(oldElm)
);
}
}
}
function createElm (
vnode,
insertedVnodeQueue,
parentElm, // 父节点
refElm,
nested,
ownerArray,
index
) {
vnode.isRootInsert = !nested; // for transition enter check
// 实例化customer component,而非built in component
// 和上面提到的_createElement方法不同的是,那个方法是会创建新的vnode,这里是将vnode实例化成一个vue component。
if (createComponent(vnode, insertedVnodeQueue, parentElm, refElm)) {
return
}
// anchor
var data = vnode.data;
var children = vnode.children;
var tag = vnode.tag;
if (isDef(tag)) {
...
// 创建真实的DOM节点
vnode.elm = vnode.ns
? nodeOps.createElementNS(vnode.ns, tag)
: nodeOps.createElement(tag, vnode);
setScope(vnode);
/* istanbul ignore if */
{
// 挂载根节点之前首先递归遍历children vnode,将children vnode渲染成真实的dom节点,并挂载到传入的vnode所创建的DOM节点下
createChildren(vnode, children, insertedVnodeQueue);
if (isDef(data)) {
invokeCreateHooks(vnode, insertedVnodeQueue);
}
console.log('parentEle: ', parentElm)
console.log('vnode.elm', vnode.elm)
// 将vnode生成的dom节点插入到真实的dom节点当中
insert(parentElm, vnode.elm, refElm);
}
if ("development" !== 'production' && data && data.pre) {
creatingElmInVPre--;
}
} else if (isTrue(vnode.isComment)) {
vnode.elm = nodeOps.createComment(vnode.text);
insert(parentElm, vnode.elm, refElm);
} else {
vnode.elm = nodeOps.createTextNode(vnode.text);
insert(parentElm, vnode.elm, refElm);
}
}再让我们看下上面说的产生的根VNode节点:
VNode {
...
children: [VNode, VNode, VNode],
tag: 'div',
elm: div#app(dom元素),
data: {
attrs: {
id: '#app'
}
},
context: Vue
...
}这个根VNode有3个VNode子节点,这个时候开始调用createChildren方法递归的完成子VNode的实例化,以及将VNode渲染成真实的DOM节点,并插入到父节点当中。
function createChildren (vnode, children, insertedVnodeQueue) {
if (Array.isArray(children)) {
{
checkDuplicateKeys(children);
}
for (var i = 0; i < children.length; ++i) {
// 调用createElm方法完成vnode的实例化以及渲染成真实的DOM节点
createElm(children[i], insertedVnodeQueue, vnode.elm, null, true, children, i);
}
} else if (isPrimitive(vnode.text)) {
nodeOps.appendChild(vnode.elm, nodeOps.createTextNode(String(vnode.text)));
}
}小程序也是通过数据去驱动视图的渲染,需要手动的调用setData去完成这样一个动作。同时小程序的视图层也提供了用户交互的响应事件系统,在 js 代码中可以去注册相关的事件回调并在回调中去更改相关数据的值。Mpx 使用 Mobx 作为响应式数据工具并引入到小程序当中,使得小程序也有一套完成的响应式的系统,让小程序的开发有了更好的体验。
还是从组件的角度开始分析 mpx 的整个响应式的系统。每次通过createComponent方法去创建一个新的组件,这个方法将原生的小程序创造组件的方法Component做了一层代理,例如在 attched 的生命周期钩子函数内部会注入一个 mixin:
// attached 生命周期钩子 mixin
attached() {
// 提供代理对象需要的api
transformApiForProxy(this, currentInject)
// 缓存options
this.$rawOptions = rawOptions // 原始的,没有剔除 customKeys 的 options 配置
// 创建proxy对象
const mpxProxy = new MPXProxy(rawOptions, this) // 将当前实例代理到 MPXProxy 这个代理对象上面去
this.$mpxProxy = mpxProxy // 在小程序实例上绑定 $mpxProxy 的实例
// 组件监听视图数据更新, attached之后才能拿到properties
this.$mpxProxy.created()
}在这个方法内部首先调用transformApiForProxy方法对组件实例上下文this做一层代理工作,在 context 上下文上去重置小程序的 setData 方法,同时拓展 context 相关的属性内容:
function transformApiForProxy (context, currentInject) {
const rawSetData = context.setData.bind(context) // setData 绑定对应的 context 上下文
Object.defineProperties(context, {
setData: { // 重置 context 的 setData 方法
get () {
return this.$mpxProxy.setData.bind(this.$mpxProxy)
},
configurable: true
},
__getInitialData: {
get () {
return () => context.data
},
configurable: false
},
__render: { // 小程序原生的 setData 方法
get () {
return rawSetData
},
configurable: false
}
})
// context 绑定注入的render函数
if (currentInject) {
if (currentInject.render) { // 编译过程中生成的 render 函数
Object.defineProperties(context, {
__injectedRender: {
get () {
return currentInject.render.bind(context)
},
configurable: false
}
})
}
if (currentInject.getRefsData) {
Object.defineProperties(context, {
__getRefsData: {
get () {
return currentInject.getRefsData
},
configurable: false
}
})
}
}
}接下来实例化一个 mpxProxy 实例并挂载至 context 上下文的 $mpxProxy 属性上,并调用 mpxProxy 的 created 方法完成这个代理对象的初始化的工作。在 created 方法内部主要是完成了以下的几个工作:
$watch,$forceUpdate,$updated,$nextTick等方法,这样在你的业务代码当中即可直接访问实例上部署好的这些方法;这里我们具体的来看下 initRender 方法内部是如何进行工作的:
export default class MPXProxy {
...
initRender() {
let renderWatcher
let renderExcutedFailed = false
if (this.target.__injectedRender) { // webpack 注入的有关这个 page/component 的 renderFunction
renderWatcher = watch(this.target, () => {
if (renderExcutedFailed) {
this.render()
} else {
try {
return this.target.__injectedRender() // 执行 renderFunction,获取渲染所需的响应式数据
} catch(e) {
...
}
}
}, {
handler: (ret) => {
if (!renderExcutedFailed) {
this.renderWithData(ret) // 渲染页面
}
},
immediate: true,
forceCallback: true
})
}
}
...
}在 initRender 方法内部非常清楚的看到,首先判断这个 page/component 是否具有 renderFunction,如果有的话那么就直接实例化一个 renderWatcher:
export default class Watcher {
constructor (context, expr, callback, options) {
this.destroyed = false
this.get = () => {
return type(expr) === 'String' ? getByPath(context, expr) : expr()
}
const callbackType = type(callback)
if (callbackType === 'Object') {
options = callback
callback = null
} else if (callbackType === 'String') {
callback = context[callback]
}
this.callback = typeof callback === 'function' ? action(callback.bind(context)) : null
this.options = options || {}
this.id = ++uid
// 创建一个新的 reaction
this.reaction = new Reaction(`mpx-watcher-${this.id}`, () => {
this.update()
})
// 在调用 getValue 函数的时候,实际上是调用 reaction.track 方法,这个方法内部会自动执行 effect 函数,即执行 this.update() 方法,这样便会出发一次模板当中的 render 函数来完成依赖的收集
const value = this.getValue()
if (this.options.immediateAsync) { // 放置到一个队列里面去执行
queueWatcher(this)
} else { // 立即执行 callback
this.value = value
if (this.options.immediate) {
this.callback && this.callback(this.value)
}
}
}
getValue () {
let value
this.reaction.track(() => {
value = this.get() // 获取注入的 render 函数执行后返回的 renderData 的值,在执行 render 函数的过程中,就会访问响应式数据的值
if (this.options.deep) {
const valueType = type(value)
// 某些情况下,最外层是非isObservable 对象,比如同时观察多个属性时
if (!isObservable(value) && (valueType === 'Array' || valueType === 'Object')) {
if (valueType === 'Array') {
value = value.map(item => toJS(item, false))
} else {
const newValue = {}
Object.keys(value).forEach(key => {
newValue[key] = toJS(value[key], false)
})
value = newValue
}
} else {
value = toJS(value, false)
}
} else if (isObservableArray(value)) {
value.peek()
} else if (isObservableObject(value)) {
keys(value)
}
})
return value
}
update () {
if (this.options.sync) {
this.run()
} else {
queueWatcher(this)
}
}
run () {
const immediateAsync = !this.hasOwnProperty('value')
const oldValue = this.value
this.value = this.getValue() // 重新获取新的 renderData 的值
if (immediateAsync || this.value !== oldValue || isObject(this.value) || this.options.forceCallback) {
if (this.callback) {
immediateAsync ? this.callback(this.value) : this.callback(this.value, oldValue)
}
}
}
destroy () {
this.destroyed = true
this.reaction.getDisposer()()
}
}Watcher 观察者核心实现的工作流程就是:
this.update()方法来完成页面的重新渲染。mpx 在构建这个响应式的系统当中,主要有2个大的环节,其一为在构建编译的过程中,将 template 模块转化为 renderFunction,提供了渲染模板时所需响应式数据的访问机制,并将 renderFunction 注入到运行时代码当中,其二就是在运行环节,mpx 通过构建一个小程序实例的代理对象,将小程序实例上的数据访问全部代理至 MPXProxy 实例上,而 MPXProxy 实例即 mpx 基于 Mobx 去构建的一套响应式数据对象,首先将 data 数据转化为响应式数据,其次提供了 computed 计算属性,watch 方法等一系列增强的拓展属性/方法,虽然在你的业务代码当中 page/component 实例 this 都是小程序提供的,但是最终经过代理机制,实际上访问的是 MPXProxy 所提供的增强功能,所以 mpx 也是通过这样一个代理对象去接管了小程序的实例。需要特别指出的是,mpx 将小程序官方提供的 setData 方法同样收敛至内部,这也是响应式系统提供的基础能力,即开发者只需要关注业务开发,而有关小程序渲染运行在 mpx 内部去帮你完成。
不同于 Vue 借助 webpack 是将 Vue 单文件最终打包成单独的 js chunk 文件。而小程序的规范是每个页面/组件需要对应的 wxml/js/wxss/json 4个文件。因为 mpx 使用单文件的方式去组织代码,所以在编译环节所需要做的工作之一就是将 mpx 单文件当中不同 block 的内容拆解到对应文件类型当中。在动态入口编译的小节里面我们了解到 mpx 会分析每个 mpx 文件的引用依赖,从而去给这个文件创建一个 entry 依赖(SingleEntryPlugin)并加入到 webpack 的编译流程当中。我们还是继续看下 mpx loader 对于 mpx 单文件初步编译转化后的内容:
/* script */
export * from "!!babel-loader!../../node_modules/@mpxjs/webpack-plugin/lib/selector?type=script&index=0!./list.mpx"
/* styles */
require("!!../../node_modules/@mpxjs/webpack-plugin/lib/extractor?type=styles&index=0!../../node_modules/@mpxjs/webpack-plugin/lib/wxss/loader?root=&importLoaders=1&extract=true!../../node_modules/@mpxjs/webpack-plugin/lib/style-compiler/index?{\"id\":\"2271575d\",\"scoped\":false,\"sourceMap\":false,\"transRpx\":{\"mode\":\"only\",\"comment\":\"use rpx\",\"include\":\"/Users/XRene/demo/mpx-demo-source/src\"}}!stylus-loader!../../node_modules/@mpxjs/webpack-plugin/lib/selector?type=styles&index=0!./list.mpx")
/* json */
require("!!../../node_modules/@mpxjs/webpack-plugin/lib/extractor?type=json&index=0!../../node_modules/@mpxjs/webpack-plugin/lib/json-compiler/index?root=!../../node_modules/@mpxjs/webpack-plugin/lib/selector?type=json&index=0!./list.mpx")
/* template */
require("!!../../node_modules/@mpxjs/webpack-plugin/lib/extractor?type=template&index=0!../../node_modules/@mpxjs/webpack-plugin/lib/wxml/wxml-loader?root=!../../node_modules/@mpxjs/webpack-plugin/lib/template-compiler/index?{\"usingComponents\":[],\"hasScoped\":false,\"isNative\":false,\"moduleId\":\"2271575d\"}!../../node_modules/@mpxjs/webpack-plugin/lib/selector?type=template&index=0!./list.mpx")接下来可以看下 styles/json/template 这3个 block 的处理流程是什么样。
首先来看下 json block 的处理流程:list.mpx -> json-compiler -> extractor。第一个阶段 list.mpx 文件经由 json-compiler 的处理流程在前面的章节已经讲过,主要就是分析依赖增加动态入口的编译过程。当所有的依赖分析完后,调用 json-compiler loader 的异步回调函数:
// lib/json-compiler/index.js
module.exports = function (content) {
...
const nativeCallback = this.async()
...
let callbacked = false
const callback = (err, processOutput) => {
checkEntryDeps(() => {
callbacked = true
if (err) return nativeCallback(err)
let output = `var json = ${JSON.stringify(json, null, 2)};\n`
if (processOutput) output = processOutput(output)
output += `module.exports = JSON.stringify(json, null, 2);\n`
nativeCallback(null, output)
})
}
}这里我们可以看到经由 json-compiler 处理后,通过nativeCallback方法传入下一个 loader 的文本内容形如:
var json = {
"usingComponents": {
"list": "/components/list397512ea/list"
}
}
module.exports = JSON.stringify(json, null, 2)即这段文本内容会传递到下一个 loader 内部进行处理,即 extractor。接下来我们来看下 extractor 里面主要是实现了哪些功能:
// lib/extractor.js
module.exports = function (content) {
...
const contentLoader = normalize.lib('content-loader')
let request = `!!${contentLoader}?${JSON.stringify(options)}!${this.resource}` // 构建一个新的 resource,且这个 resource 只需要经过 content-loader
let resultSource = defaultResultSource
const childFilename = 'extractor-filename'
const outputOptions = {
filename: childFilename
}
// 创建一个 child compiler
const childCompiler = mainCompilation.createChildCompiler(request, outputOptions, [
new NodeTemplatePlugin(outputOptions),
new LibraryTemplatePlugin(null, 'commonjs2'), // 最终输出的 chunk 内容遵循 commonjs 规范的可执行的模块代码 module.exports = (function(modules) {})([modules])
new NodeTargetPlugin(),
new SingleEntryPlugin(this.context, request, resourcePath),
new LimitChunkCountPlugin({ maxChunks: 1 })
])
...
childCompiler.hooks.thisCompilation.tap('MpxWebpackPlugin ', (compilation) => {
// 创建 loaderContext 时触发的 hook,在这个 hook 触发的时候,将原本从 json-compiler 传递过来的 content 内容挂载至 loaderContext.__mpx__ 属性上面以供接下来的 content -loader 来进行使用
compilation.hooks.normalModuleLoader.tap('MpxWebpackPlugin', (loaderContext, module) => {
// 传递编译结果,子编译器进入content-loader后直接输出
loaderContext.__mpx__ = {
content,
fileDependencies: this.getDependencies(),
contextDependencies: this.getContextDependencies()
}
})
})
let source
childCompiler.hooks.afterCompile.tapAsync('MpxWebpackPlugin', (compilation, callback) => {
// 这里 afterCompile 产出的 assets 的代码当中是包含 webpack runtime bootstrap 的代码,不过需要注意的是这个 source 模块的产出形式
// 因为使用了 new LibraryTemplatePlugin(null, 'commonjs2') 等插件。所以产出的 source 是可以在 node 环境下执行的 module
// 因为在 loaderContext 上部署了 exec 方法,即可以直接执行 commonjs 规范的 module 代码,这样就最终完成了 mpx 单文件当中不同模块的抽离工作
source = compilation.assets[childFilename] && compilation.assets[childFilename].source()
// Remove all chunk assets
compilation.chunks.forEach((chunk) => {
chunk.files.forEach((file) => {
delete compilation.assets[file]
})
})
callback()
})
childCompiler.runAsChild((err, entries, compilation) => {
...
try {
// exec 是 loaderContext 上提供的一个方法,在其内部会构建原生的 node.js module,并执行这个 module 的代码
// 执行这个 module 代码后获取的内容就是通过 module.exports 导出的内容
let text = this.exec(source, request)
if (Array.isArray(text)) {
text = text.map((item) => {
return item[1]
}).join('\n')
}
let extracted = extract(text, options.type, resourcePath, +options.index, selfResourcePath)
if (extracted) {
resultSource = `module.exports = __webpack_public_path__ + ${JSON.stringify(extracted)};`
}
} catch (err) {
return nativeCallback(err)
}
if (resultSource) {
nativeCallback(null, resultSource)
} else {
nativeCallback()
}
})
}稍微总结下上面的处理流程:
module.exports导出的内容。所以上面的示例 demo 最终会输出一个 json 文件,里面包含的内容即为:
{
"usingComponents": {
"list": "/components/list397512ea/list"
}
}本文旨在解释闭包里的微观世界。
内容包含:值类型、作用域、闭包
JS当中所有的function都是闭包,一般说来,嵌套的function的闭包性更强。这也是我们平时接触和研究比较多的地方。
在进入本文的核心部分以前,首先来理解几个概念:
值类型
声明一个值类型变量,编译器会在栈上分配一个空间,这个空间对应着该值的类型变量,空间存储的就是这个变量的值。存储在栈(stack)中的简单数据段,也就是说,它们的值直接存储在变量访问的位置。
引用类型
引用类型的实例分配在堆(heap)上,新建一个引用类型的实例,得到的变量值对应的是该实例的内存分配地址。存储在堆(heap)中的对象,也就是说,存储在变量中的值是一个指针(point),其指向存储对象的位置。
//值类型
var a="xl";
var b=a;
a="XL";
console.log(b); //输出 "xl"
//引用类型
var a={name:"xl"};
var b=a;
a.name="XL";
console.log(b.name);//输出 "XL"区别就是值类型变量是可以直接访问栈(stack)中的值:
接下来的内容就是关于闭包的微观世界
function a(){
var i=0;
function b(){
console.log(++i);
}
return b;
}
var c=a(); //函数a执行后返回函数b,并将函数b赋给c
c();//输出 1本来这个地方变量i是定义在函数a中,并不能被函数a的外部所访问,但是这个地方因为在a中定义了一个函数b,函数b中有对变量i的引用,因此当b被a返回后,变量c获得了对函数a中函数b的引用,因此i不会被GC回收,而是存在内存当中。
当在一个函数a里面定义另外一个函数b,函数b有对函数a中变量的引用,当函数a执行并返回函数b,将b赋给变量c时,这样就存在相互之间的引用关系,并形成了大家经常见到的闭包
我们进一步的分析:这一部分的内容包含了作用域和作用域链部分的内容.
依然拿上面的例子来分析:
当定义函数a的时候,js解释器会将函数a的**作用域链(scope chain)**设置为定义a时所在的“环境”,如果a是一个全局函数,那么scope chain中只有window对象。
当执行函数a的时候,a会进入相应的执行环境(excution context).
在创建执行环境的过程中,首先会为a添加scope属性,即a的作用域,其值就为第一步的scope chain.即a.scope=a的作用域链。
然后执行环境会创建一个活动对象(call object).活动对象也是一个拥有属性的对象。但它不具有原型而且不能直接通过javascript代码访问。创建完活动对象后,把活动对象添加到a的作用域的最顶端,此时a的作用域链包含2个对象:a的活动对象和window对象。
下一步是在活动对象上添加一个arguments属性,它保存着调用a时所传递的参数。最后把所有函数a的形参以及定义的内部函数b添加到a的活动对象上。在这一步中,完成了函数b的定义,正如第一步,函数b的作用域链被设置为b被定义时所处的环境,即a的作用域
到此,整个函数a从定义到执行的过程就完成了。此时a返回函数b的引用给c,又函数b的作用域链包含了对函数a的活动对象的引用,也就是说b可以访问到a中定义的所有变量和函数。函数b被c引用,函数b又依赖函数的a,因此函数a在返回的时候不会被gc收回。
当函数b执行的时候,同样会按上述步骤一样。执行时b的作用域里包含了3个对象:{b的活动对象}、{a的活动对象}、{window对象}
下面用2张图来表示整个过程:
图一展示了函数a定义过程是如何创建作用域链的
图二展示了函数a执行过程产生的活动对象(call object)
在这其中有个非常重要的内容就是函数的作用域是在定义函数的时候就已经确定,而不是在执行的时候确定。
具体内容参见:鸟哥:Javascript作用域和作用域链
再来看看我们在平时经常遇到的一段代码:
HTML部分:
<div id="example">
<span>1</span>
<span>2</span>
<span>3</span>
</div>
JS:
var spanArr=document.getElementById("example").getElementsByTagName("span");
for(var i=0;i<3;i++){
spanArr[i].onclick=function(){
console.log(i);
}
}
//不管点击哪个<span>都会输出3
//这是因为在内部的匿名函数中i是对于外部的i的引用。当for循环结束以后,i的值变为了3.那么匿名函数相应获得的引用值夜都变为了3.所以最后不管点击哪个<span>最后都会输出3.
//所以遇到这种情况的时候一般处理方法是
1.将变量i保存在每个span对象上。
for(var i=0;i<3;i++){
spanArr[i].i=i;
spanArr[i].onclick=function(){
console.log(i);
}
}
2.加一层闭包
for(var i=0;i<3;i++){
(function(i){
spanArr[i].onclick=function(){
console.log(i);
}
})(i)
}
//当然还有其他的方法,这里不多述。参考文章:
不同于 web 规范,我们都知道小程序每个 page/component 需要被最终在 webview 上渲染出来的内容是需要包含这几个独立的文件的:js/json/wxml/wxss。为了提升小程序的开发体验,mpx 参考 vue 的 SFC(single file component)的设计思路,采用单文件的代码组织方式进行开发。既然采用这种方式去组织代码的话,那么模板、逻辑代码、json配置文件、style样式等都放到了同一个文件当中。那么 mpx 需要做的一个工作就是如何将 SFC 在代码编译后拆分为 js/json/wxml/wxss 以满足小程序技术规范。熟悉 vue 生态的同学都知道,vue-loader 里面就做了这样一个编译转化工作。具体有关 vue-loader 的工作流程可以参见我写的文章。
这里会遇到这样一个问题,就是在 vue 当中,如果你要引入一个页面/组件的话,直接通过import语法去引入对应的 vue 文件即可。但是在小程序的标准规范里面,它有自己一套组件系统,即如果你在某个页面/组件里面想要使用另外一个组件,那么需要在你的 json 配置文件当中去声明usingComponents这个字段,对应的值为这个组件的路径。
在 vue 里面 import 一个 vue 文件,那么这个文件会被当做一个 dependency 去加入到 webpack 的编译流程当中。但是 mpx 是保持小程序原有的功能,去进行功能的增强。因此一个 mpx 文件当中如果需要引入其他页面/组件,那么就是遵照小程序的组件规范需要在usingComponents定义好组件名:路径即可,mpx 提供的 webpack 插件来完成确定依赖关系,同时将被引入的页面/组件加入到编译构建的环节当中。
TODO: webpack-plugin 和 loader 的附属关系的实现
接下来就来看下具体的实现,mpx webpack-plugin 暴露出来的插件上也提供了静态方法去使用 loader。这个 loader 的作用和 vue-loader 的作用类似,首先就是拿到 mpx 原始的文件后转化一个 js 文本的文件。例如一个 list.mpx 文件里面有关 json 的配置会被编译为:
require("!!../../node_modules/@mpxjs/webpack-plugin/lib/extractor?type=json&index=0!../../node_modules/@mpxjs/webpack-plugin/lib/json-compiler/index?root=!../../node_modules/@mpxjs/webpack-plugin/lib/selector?type=json&index=0!./list.mpx")这样可以清楚的看到 list.mpx 这个文件首先 selector(抽离list.mpx当中有关 json 的配置,并传入到 json-compiler 当中) --->>> json-compiler(对 json 配置进行处理,添加动态入口等) --->>> extractor(利用 child compiler 单独生成 json 配置文件)
其中动态添加入口的处理流程是在 json-compiler 当中去完成的。例如在你的 page/home.mpx 文件当中的 json 配置中使用了 局部组件 components/list.mpx:
<script type="application/json">
{
"usingComponents": {
"list": "../components/list"
}
}
</script>在 json-compiler 当中:
...
const addEntrySafely = (resource, name, callback) => {
// 如果loader已经回调,就不再添加entry
if (callbacked) return callback()
// 使用 webpack 提供的 SingleEntryPlugin 插件创建一个单文件的入口依赖(即这个 component)
const dep = SingleEntryPlugin.createDependency(resource, name)
entryDeps.add(dep)
// compilation.addEntry 方法开始将这个需要被编译的 component 作为依赖添加到 webpack 的构建流程当中
// 这里可以看到的是整个动态添加入口文件的过程是深度优先的
this._compilation.addEntry(this._compiler.context, dep, name, (err, module) => {
entryDeps.delete(dep)
checkEntryDeps()
callback(err, module)
})
}
const processComponent = (component, context, rewritePath, componentPath, callback) => {
...
// 调用 loaderContext 上提供的 resolve 方法去解析这个 component path 完整的路径,以及这个 component 所属的 package 相关的信息(例如 package.json 等)
this.resolve(context, component, (err, rawResult, info) => {
...
componentPath = componentPath || path.join(subPackageRoot, 'components', componentName + hash(result), componentName)
...
// component path 解析完之后,调用 addEntrySafely 开始在 webpack 构建流程中动态添加入口
addEntrySafely(rawResult, componentPath, callback)
})
}
if (isApp) {
...
} else {
if (json.usingComponents) {
// async.forEachOf 流程控制依次调用 processComponent 方法
async.forEachOf(json.usingComponents, (component, name, callback) => {
processComponent(component, this.context, (path) => {
json.usingComponents[name] = path
}, undefined, callback)
}, callback)
}
...
}
...这里需要解释说明下有关 webpack 提供的 SingleEntryPlugin 插件。这个插件是 webpack 提供的一个内置插件,当这个插件被挂载到 webpack 的编译流程的过程中是,会绑定compiler.hooks.make.tapAsynchook,当这个 hook 触发后会调用这个插件上的 SingleEntryPlugin.createDependency 静态方法去创建一个入口依赖,然后调用compilation.addEntry将这个依赖加入到编译的流程当中,这个是单入口文件的编译流程的最开始的一个步骤(具体可以参见 Webpack SingleEntryPlugin 源码)。
Mpx 正是利用了 webpack 提供的这样一种能力,在遵照小程序的自定义组件的规范的前提下,解析 mpx json 配置文件的过程中,手动的调用 SingleEntryPlugin 相关的方法去完成动态入口的添加工作。这样也就串联起了所有的 mpx 文件的编译工作。
在Vue中,父子组件基本的通讯方式就是父组件通过props属性将数据传递给子组件,这种数据的流向是单向的,当父props属性发生了改变,子组件所接收到的对应的属性值也会发生改变,但是反过来却不是这样的。子组件通过event自定义事件的触发来通知父组件自身内部所发生的变化。
还是从一个实例出发:
// 模板
<div id="app">
<child-component :message="val"></child-component>
</div>
// js
Vue.component('child-component', {
props: ['message']
template: '<div>this is child component, I have {{message}}</div>',
})
new Vue({
el: '#app',
data() {
return {
val: 'parent val'
}
},
mounted () {
setTimeout(() => {
this.val = 'parent val which has been changed after 2s'
}, 2000)
}
})最终页面渲染出的内容为:
this is child component, I have parent val
2s后文案变更为:
this child component, I hava parent val which has been changed after 2s接下来我们就来看下父子组件是如何通过props属性来完成数据的传递的。
首先根组件开始实例化,完成一系列的初始化的内容。首先将val转化为响应式的数据,并调用Vue.prototype.$mount方法完成vnode的生成,真实dom元素的挂载等功能:
Vue.prototype._init = function (options) {
...
initState(vm)
...
if (vm.$options.el) {
vm.$mount(vm.$options.el);
}
...
}Vue.prototype.$mount方法内部:
Vue.prototype.$mount = function (
el,
hydrating
) {
el = el && inBrowser ? query(el) : undefined;
return mountComponent(this, el, hydrating)
};
var mount = Vue.prototype.$mount;
Vue.prototype.$mount = function (
el,
hydrating
) {
el = el && query(el);
var options = this.$options;
// resolve template/el and convert to render function
if (!options.render) {
var template = options.template;
if (template) {
...
} else if (el) {
template = getOuterHTML(el);
}
if (template) {
...
var ref = compileToFunctions(template, {
shouldDecodeNewlines: shouldDecodeNewlines,
shouldDecodeNewlinesForHref: shouldDecodeNewlinesForHref,
delimiters: options.delimiters,
comments: options.comments
}, this);
// 生成render函数
var render = ref.render;
var staticRenderFns = ref.staticRenderFns;
options.render = render;
options.staticRenderFns = staticRenderFns;
}
}
return mount.call(this, el, hydrating)
};
function mountComponent (
vm,
el,
hydrating
) {
vm.$el = el;
if (!vm.$options.render) {
...
}
// 挂载前
callHook(vm, 'beforeMount');
var updateComponent;
/* istanbul ignore if */
if ("development" !== 'production' && config.performance && mark) {
...
} else {
updateComponent = function () {
vm._update(vm._render(), hydrating);
};
}
new Watcher(vm, updateComponent, noop, null, true /* isRenderWatcher */);
hydrating = false;
// manually mounted instance, call mounted on self
// mounted is called for render-created child components in its inserted hook
if (vm.$vnode == null) {
vm._isMounted = true;
callHook(vm, 'mounted');
}
return vm
}完成模板的编译,同时生成render函数,这个render函数在实际实行生成vnode时,会将作用域绑定到对应的vm实例的作用域下,即在创建vnode的环节当中,始终访问的是当前这个vm实例,子vnode创建时是没法直接访问到父组件中定义的数据的。除非通过props属性来完成数据由父组件向子组件的传递。
;(function() {
with (this) {
return _c(
'div',
{
attrs: {
id: 'app'
}
},
[
_c('my-component', {
attrs: {
message: val
}
})
],
1
)
}
})完成模板的编译生成render函数后,调用_c方法,对应访问vue实例的_c方法,开始创建对应的vnode,注意这里val变量,即vue实例上data属性定义的val,在创建对应的vnode前,实例已经调用initState方法将val转化为响应式的数据。因此在创建vnode过程中,访问val即访问它的getter。
在访问过程中Dep.target已经被设定为当前vue实例的watcher(具体见mountComponent方法内部创建watcher对象),因此会将当前的watcher加入到val的dep当中。这样便完成了val的依赖收集的工作。
在创建VNode时,又分为:
built in VNode)component VNode)其中内置标签的VNode的没有需要特别说明的地方,就是调用VNode的构造函数完成创建过程。
但是在创建自定义标签元素的VNode时,完成一些重要的操作(因为本文是讲解 props 传递,所以挑出和 props 相关的部分):
function createComponent () {
...
// 注意这个方法。它完成了从父组件对应的props字段获取值的作用,具体到本例子,就是获取到了message字段的值
// 这样就完成了props从父组件传递到子组件的功能
var propsData = extractPropsFromVNodeData(data, Ctor, tag);
...
// 给component初始化挂载钩子函数,在VNode实例化成vue component会调相关的钩子函数
installComponentHooks(data);
...
// 创建VNode
var vnode = new VNode(
("vue-component-" + (Ctor.cid) + (name ? ("-" + name) : '')),
data, undefined, undefined, undefined, context,
{ Ctor: Ctor, propsData: propsData, listeners: listeners, tag: tag, children: children },
asyncFactory
);
return vnode
}在createComponent创建VNode的过程中需要注意的是:Vue的父子组件传递props属性的时候都是在子组件上直接写自定义的dom attrs:
<div id="app">
<child-component :message="val"></child-component>
</div>但是在模板编译后,统一将dom节点(不管是built in的节点还是自定义component节点)上的属性转化为attrs对象(见代码片段 111),在创建VNode过程中调用了extractPropsFromVNodeData这个方法完成从attrs对象上获取到这个component所需要的props属性,获取完成后还会将attrs对象上对应的key值删除。因此这个key值对应的是要传入子component的数据,而非原生dom属性,最终由VNode生成真实dom的时候是不需要这些自定义数据的,因此需要删除。
当然如果你在子组件中传入了props数据,但是在子组件中没有定义相关的props属性,那么这个 props 属性最终会渲染到子组件的真实的dom元素上,不过控制台也会出现报错:
> [Vue warn]: Property or method "message" is not defined on the instance but referenced during render. Make sure that this property is reactive, either in the data option, or for class-based components, by initializing the property当完成了my-component的VNode创建后,开始创建它的父VNode,即根VNode。
(function() {
with (this) {
return _c('div', {
attrs: {
"id": "app"
}
}, <my-component-vnode>, 1)
}
}
)vm._render()方法调用完成后,即所有的VNode都创建完成,开始递归将VNode渲染成真实的dom节点,同时挂载到document当中(见上方调用的mountComponent内部vm.update(vm._render()))。
Vue.prototype._update = function (vnode, hydrating) {
var vm = this;
if (vm._isMounted) {
// 触发beforeUpdate钩子函数
callHook(vm, 'beforeUpdate');
}
var prevEl = vm.$el;
var prevVnode = vm._vnode;
var prevActiveInstance = activeInstance;
activeInstance = vm;
vm._vnode = vnode;
// 第一次渲染
if (!prevVnode) {
// initial render
// 初始化render
vm.$el = vm.__patch__(
vm.$el, vnode, hydrating, false /* removeOnly */,
vm.$options._parentElm,
vm.$options._refElm
);
...
} else {
// updates
// 将prevVnode和vnode进行patch操作并更新
vm.$el = vm.__patch__(prevVnode, vnode);
}
...
}在将VNode递归渲染成真实的dom节点过程当中:
对于**自定义标签元素(即组件)**的渲染,首先完成组件vue实例的初始化。又重复到上文一开始的Vue.prototype._init方法。在实例化my-component组件的过程中,还是通过调用initState方法,将定义的props属性中的message属性转化为响应式的数据。� 在此之前,my-component组件上的message属性已经被初始化为从父组件传递过来的值。因此在页面初次渲染的时候,my-component通过定义的props属性从父组件上获取到的值为parent val(上面的例子中定义的)
这样便完成了父组件通过props属性向子组件传递数据。
在子组件生成 VNode 的过程中会对应创建 render watcher,通过 props 从父组件传递给子组件的数据是在父作用域下获取得到的。因此,props 的 Dep 中会将这个 watcher 作为依赖添加进去。那么当父组件中的数据发生了改变,便会调用这个响应式数据Dep.notify()方法去通知相关的订阅者去完成更新,其中就包括子组件的 render watcher。
那么在子组件需要和父组件进行通讯的时候,所使用的events事件又是如何实现的呢?
// 模板
<div id="app">
<child-component @foo="bar"></child-component>
</div>
// js
Vue.component('child-component', {
props: ['message']
template: '<div @click="foo">this is child component, I have {{message}}</div>',
methods: {
foo () {
this.$emit('foo', 'this is child component')
}
}
})
new Vue({
el: '#app',
data() {
return {
val: 'parent val'
}
},
methods: {
foo (val) {
console.log(val)
}
}
})当点击<child-component>时,会在控制台输出this is child component。那我们来看下整个过程是如何进行的:
首先在模板编译的过程:
;(function() {
with (this) {
return _c(
'div',
{
attrs: {
id: 'app'
}
},
[
_c('my-component', {
staticClass: 'my-component',
attrs: {
message: val
},
on: {
test: test
}
})
],
1
)
}
})在创建my-component的component VNode过程中,通过传入data数据上定义的on属性。这个时候test访问的还是在父组件上定义的test方法。
//
function createComponent (
Ctor,
data,
context,
children,
tag
) {
...
// extract listeners, since these needs to be treated as
// child component listeners instead of DOM listeners
// 获取父 component 作用域中定义的 listeners。这个 listeners 会作为 componentOptions 的属性传递进 VNode 当中
// 注意这个地方和 DOM listeners 的区别。DOM listeners是使用的浏览器原生的事件系统
var listeners = data.on;
...
// install component management hooks onto the placeholder node
installComponentHooks(data);
// return a placeholder vnode
var name = Ctor.options.name || tag;
// 将从父 component 作用作用域定义的 listeners 作为 VNode 的 componentOptions 传入 VNode 的构造函数内部
var vnode = new VNode(
("vue-component-" + (Ctor.cid) + (name ? ("-" + name) : '')),
data, undefined, undefined, undefined, context,
{ Ctor: Ctor, propsData: propsData, listeners: listeners, tag: tag, children: children },
asyncFactory
);
/* istanbul ignore if */
return vnode
}接下来在将这个VNode实例成vue component的时候:
Vue.prototype._init = function (options) {
var vm = this;
// 实例化子vue component
if (options && options._isComponent) {
// optimize internal component instantiation
// since dynamic options merging is pretty slow, and none of the
// internal component options needs special treatment.
// 从VNode的componentOptions属性上获取关于这个vue component定义的属性
initInternalComponent(vm, options);
} else {
...
}
// expose real self
vm._self = vm;
initLifecycle(vm);
// 初始化vm的上绑定的自定义事件
initEvents(vm);
...
};
// 实例化vue component自定义事件
function initEvents (vm) {
vm._events = Object.create(null);
vm._hasHookEvent = false;
// init parent attached events
// 获取从父组件上传递过来的自定义事件
var listeners = vm.$options._parentListeners;
if (listeners) {
updateComponentListeners(vm, listeners);
}
}
function updateComponentListeners (
vm,
listeners,
oldListeners
) {
// 设置全局target对象
target = vm;
updateListeners(listeners, oldListeners || {}, add, remove$1, vm);
target = undefined;
}
// 给全局target对象挂载自定义事件
function add (event, fn, once) {
if (once) {
target.$once(event, fn);
} else {
target.$on(event, fn);
}
}在将VNode实例化过程当中,调用initEvents方法,获取在这个VNode上绑定的从父组件传递下来的方法,并缓存至对应事件的回调函数数组当中。当你在子组件当中去$emit对应的事件的时候,便会执行对应的回调函数。这里父子间的event事件机制实际上是利用了发布订阅的设计模式。
这个是有关父子组件自定义事件的机制。这里也顺带讲下 Vue 是如何绑定原生 DOM 事件的。
在代码片段 xxx 当中,生成 VNode 的环节当中,会将 nativeOn 赋值给data.on(data 上保存了将 VNode 渲染成真实 DOM 节点的数据)。当开始渲染真实 DOM 元素的时候:
function createElm () {
...
if (isDef(data)) {
invokeCreateHooks(vnode, insertedVnodeQueue)
}
...
}
function invokeCreateHooks (vnode, insertedVnodeQueue) {
for (var i$1 = 0; i$1 < cbs.create.length; ++i$1) {
cbs.create[i$1](emptyNode, vnode);
}
i = vnode.data.hook; // Reuse variable
if (isDef(i)) {
if (isDef(i.create)) { i.create(emptyNode, vnode); }
if (isDef(i.insert)) {
insertedVnodeQueue.push(vnode);
}
}
}当 data 有值的时候,那么就开始执行 DOM 相关属性更新的工作。即执行在 cbs 上有关 create 阶段所有的回调函数,其中包括:
var platformModules = [
attrs, // attrs 属性
klass, // class
events, // 原生 dom 事件
domProps,
style,
transition
]其中我们来看下有关 events,即原生 dom 事件是如何绑定到 DOM 元素上的。
var events = {
create: updateDOMListeners,
update: updateDOMListeners
}
function updateDOMListeners (oldVnode, vnode) {
if (isUndef(oldVnode.data.on) && isUndef(vnode.data.on)) {
return
}
var on = vnode.data.on || {};
var oldOn = oldVnode.data.on || {};
target$1 = vnode.elm; // 真实的 dom 节点
normalizeEvents(on);
updateListeners(on, oldOn, add$1, remove$2, vnode.context);
target$1 = undefined;
}
function add$1 (
event,
handler,
once$$1,
capture,
passive
) {
handler = withMacroTask(handler); // 强制放到 marcoTask 当中去执行
if (once$$1) { handler = createOnceHandler(handler, event, capture); }
target$1.addEventListener(
event,
handler,
supportsPassive
? { capture: capture, passive: passive }
: capture
);
}
function remove$2 (
event,
handler,
capture,
_target
) {
(_target || target$1).removeEventListener(
event,
handler._withTask || handler,
capture
);
}在初次渲染DOM节点的时候,传入的 oldVNode 为一个空的 VNode,即拿这个空的 VNode 和即将要渲染的 VNode 进行原生DOM事件的 diff 工作。在updateDOMListeners方法当中还是继续调用updateListeners方法去进行事件的绑定,这个时候绑定事件的函数使用的是add$1,即调用DOM提供的addEventListener方法去完成原生DOM事件的绑定工作。在这里我们也可以看出去 Vue 提供的事件修饰符在这里进行配置生效。这样便完成了原生的DOM事件的绑定。
在 2.3.0+ 版本,Vue 提供了一种可以对 props 进行数据双向绑定的语法糖。基本的使用方法为:
事实上是 Vue 在将模板编译成渲染函数时,会将带有.sync标识符的 props 自动添加一个自定义的事件update:message事件:
{
...
on: {
'update:message': function ($event) {
message = $event
}
}
...
}那么当你在子组件当中去调用update:message方法的时候,并传入值的时候即会更新 message 的值。这个 message 的值即在父组件当中的数据。这样便完成了数据的双向绑定。
// vm._update(vm._render())
// patch
// prepatch 方法
// updateChildComponent 完成 props 等属性的 setter 操作 _props是在实例初始化过程中定义的一个内部属性,同时调用defineReactive方法完成将响应式数据存放到_props属性上。在VNode的patch过程中,如果有属性发生了变化,那么会调用这个属性的setter方法完成值的变更操作,继而完成视图的更新。当然了,如果组件在定义的过程,没有定义props属性,那么在实例初始化的过程中,_props属性也不会被创建。只有组件上定义过props属性,在初始化的过程中才会定义这个内部属性。
这篇文章主要是通过源码去探索下 webpack 是如何通过在编译环节创建的 module graph 来生成对应的 chunk graph。
首先来了解一些概念及其相互之间的关系:
我们都知道 webpack 打包构建时会根据你的具体业务代码和 webpack 相关配置来决定输出的最终文件,具体的文件的名和文件数量也与此相关。而这些文件就被称为 chunk。例如在你的业务当中使用了异步分包的 API:
import('./foo.js').then(bar => bar())在最终输出的文件当中,foo.js会被单独输出一个 chunk 文件。
又或者在你的 webpack 配置当中,进行了有关 optimization 优化 chunk 生成的配置:
module.exports = {
optimization: {
runtimeChunk: {
name: 'runtime-chunk'
}
}
}最终 webpack 会将 webpack runtime chunk 单独抽离成一个 chunk 后再输出成一个名为runtime-chunk.js的文件。
而这些生成的 chunk 文件当中即是由相关的 module 模块所构成的。
接下来我们就看下 webpack 在工作流当中是如何生成 chunk 的,首先我们先来看下示例:
// a.js (webpack config 入口文件)
import add from './b.js'
add(1, 2)
import('./c').then(del => del(1, 2))
-----
// b.js
import mod from './d.js'
export default function add(n1, n2) {
return n1 + n2
}
mod(100, 11)
-----
// c.js
import mod from './d.js'
mod(100, 11)
import('./b.js').then(add => add(1, 2))
export default function del(n1, n2) {
return n1 - n2
}
-----
// d.js
export default function mod(n1, n2) {
return n1 % n2
}webpack 相关的配置:
// webpack.config.js
module.exports = {
entry: {
app: 'a.js'
},
output: {
filename: '[name].[chunkhash].js',
chunkFilename: '[name].bundle.[chunkhash:8].js',
publicPath: '/'
},
optimization: {
runtimeChunk: {
name: 'bundle'
}
},
}其中 a.js 为 webpack config 当中配置的 entry 入口文件,a.js 依赖 b.js/c.js,而 b.js 依赖 d.js,c.js 依赖 d.js/b.js。最终通过 webpack 编译后,将会生成3个 chunk 文件,其中:
接下来我们就通过源码来看下 webpack 内部是通过什么样的策略去完成 chunk 的生成的。
在 webpack 的工作流程当中,当所有的 module 都被编译完成后,进入到 seal 阶段会开始生成 chunk 的相关的工作:
// compilation.js
class Compilation {
...
seal () {
...
this.hooks.beforeChunks.call();
// 根据 addEntry 方法中收集到入口文件组成的 _preparedEntrypoints 数组
for (const preparedEntrypoint of this._preparedEntrypoints) {
const module = preparedEntrypoint.module;
const name = preparedEntrypoint.name;
const chunk = this.addChunk(name); // 入口 chunk 且为 runtimeChunk
const entrypoint = new Entrypoint(name); // 每一个 entryPoint 就是一个 chunkGroup
entrypoint.setRuntimeChunk(chunk); // 设置 runtime chunk
entrypoint.addOrigin(null, name, preparedEntrypoint.request);
this.namedChunkGroups.set(name, entrypoint); // 设置 chunkGroups 的内容
this.entrypoints.set(name, entrypoint);
this.chunkGroups.push(entrypoint);
// 建立起 chunkGroup 和 chunk 之间的关系
GraphHelpers.connectChunkGroupAndChunk(entrypoint, chunk);
// 建立起 chunk 和 module 之间的关系
GraphHelpers.connectChunkAndModule(chunk, module);
chunk.entryModule = module;
chunk.name = name;
this.assignDepth(module);
}
this.processDependenciesBlocksForChunkGroups(this.chunkGroups.slice());
// 对 module 进行排序
this.sortModules(this.modules);
// 创建完 chunk 之后的 hook
this.hooks.afterChunks.call(this.chunks);
//
this.hooks.optimize.call();
while (
this.hooks.optimizeModulesBasic.call(this.modules) ||
this.hooks.optimizeModules.call(this.modules) ||
this.hooks.optimizeModulesAdvanced.call(this.modules)
) {
/* empty */
}
// 优化 module 之后的 hook
this.hooks.afterOptimizeModules.call(this.modules);
while (
this.hooks.optimizeChunksBasic.call(this.chunks, this.chunkGroups) ||
this.hooks.optimizeChunks.call(this.chunks, this.chunkGroups) ||
// 主要涉及到 webpack config 当中的有关 optimization 配置的相关内容
this.hooks.optimizeChunksAdvanced.call(this.chunks, this.chunkGroups)
) {
/* empty */
}
// 优化 chunk 之后的 hook
this.hooks.afterOptimizeChunks.call(this.chunks, this.chunkGroups);
...
}
...
}在这个过程当中首先遍历 webpack config 当中配置的入口 module,每个入口 module 都会通过addChunk方法去创建一个 chunk,而这个新建的 chunk 为一个空的 chunk,即不包含任何与之相关联的 module。之后实例化一个 entryPoint,而这个 entryPoint 为一个 chunkGroup,每个 chunkGroup 可以包含多的 chunk,同时内部会有个比较特殊的 runtimeChunk(当 webpack 最终编译完成后包含的 webpack runtime 代码最终会注入到 runtimeChunk 当中)。到此仅仅是分别创建了 chunk 以及 chunkGroup,接下来便调用GraphHelpers模块提供的connectChunkGroupAndChunk及connectChunkAndModule方法来建立起 chunkGroup 和 chunk 之间的联系,以及 chunk 和 入口 module 之间(这里还未涉及到依赖 module)的联系:
// GraphHelpers.js
/**
* @param {ChunkGroup} chunkGroup the ChunkGroup to connect
* @param {Chunk} chunk chunk to tie to ChunkGroup
* @returns {void}
*/
GraphHelpers.connectChunkGroupAndChunk = (chunkGroup, chunk) => {
if (chunkGroup.pushChunk(chunk)) {
chunk.addGroup(chunkGroup);
}
};
/**
* @param {Chunk} chunk Chunk to connect to Module
* @param {Module} module Module to connect to Chunk
* @returns {void}
*/
GraphHelpers.connectChunkAndModule = (chunk, module) => {
if (module.addChunk(chunk)) {
chunk.addModule(module);
}
};例如在示例当中,入口 module 只配置了一个,那么在处理 entryPoints 阶段时会生成一个 chunkGroup 以及一个 chunk,这个 chunk 目前仅仅只包含了入口 module。我们都知道 webpack 输出的 chunk 当中都会包含与之相关的 module,在编译环节进行到上面这一步仅仅建立起了 chunk 和入口 module 之间的联系,那么 chunk 是如何与其他的 module 也建立起联系呢?接下来我们就看下 webpack 在生成 chunk 的过程当中是如何与其依赖的 module 进行关联的。
与此相关的便是 compilation 实例提供的processDependenciesBlocksForChunkGroups方法。这个方法内部细节较为复杂,它包含了两个核心的处理流程:
在第一个步骤中,首先对这次 compliation 收集到的 modules 进行一次遍历,在遍历 module 的过程中,会对这个 module 的 dependencies 依赖进行处理,获取这个 module 的依赖模块,同时还会处理这个 module 的 blocks(即在你的代码通过异步 API 加载的模块),每个异步 block 都会被加入到遍历的过程当中,被当做一个 module 来处理。因此在这次遍历的过程结束后会建立起基本的 module graph,包含普通的 module 及异步 module(block),最终存储到一个 map 表(blockInfoMap)当中:
const iteratorBlockPrepare = b => {
blockInfoBlocks.push(b);
// 将 block 加入到 blockQueue 当中,从而进入到下一次的遍历过程当中
blockQueue.push(b);
};
// 这次 compilation 包含的所有的 module
for (const modules of this.modules) {
blockQueue = [module];
currentModule = module;
while (blockQueue.length > 0) {
block = blockQueue.pop(); // 当前正在被遍历的 module
blockInfoModules = new Set(); // module 依赖的同步的 module
blockInfoBlocks = []; // module 依赖的异步 module(block)
if (block.variables) {
iterationBlockVariable(block.variables, iteratorDependency);
}
// 在 blockInfoModules 数据集(set)当中添加 dependencies 中的普通 module
if (block.dependencies) {
iterationOfArrayCallback(block.dependencies, iteratorDependency);
}
// 在 blockInfoBlocks 和 blockQueue 数组当中添加异步 module(block),这样这些被加入到 blockQueue当中的
// module 也会进入到遍历的环节,去获取异步 module(block)的依赖
if (block.blocks) {
iterationOfArrayCallback(block.blocks, iteratorBlockPrepare);
}
const blockInfo = {
modules: Array.from(blockInfoModules),
blocks: blockInfoBlocks
};
// blockInfoMap 上保存了每个 module 依赖的同步 module 及 异步 blocks
blockInfoMap.set(block, blockInfo);
}
}在我们的实例当中生成的 module graph 即为:

当基础的 module graph (即blockInfoMap)生成后,接下来开始根据 module graph 去生成 basic chunk graph。刚开始仍然是数据的处理,将传入的 entryPoint(chunkGroup) 转化为一个新的 queue,queue 数组当中每一项包含了:
在我们提供的示例当中,因为是单入口的,因此这里 queue 初始化后只有一项。
{
action: ENTER_MODULE,
block: a.js,
module: a.js,
chunk,
chunkGroup: entryPoint
}接下来进入到 queue 的遍历环节,通过源码我们发现对于 queue 的处理进行了2次遍历的操作(内层和外层),具体为什么会需要进行2次遍历操作后文会说明。首先我们来看下内层的遍历操作,首先根据 action 的类型进入到对应的处理流程当中:
首先进入到 ENTRY_MODULE 的阶段,会在 queue 中新增一个 action 为 LEAVE_MODULE 的项会在后面遍历的流程当中使用,当 ENTRY_MODULE 的阶段进行完后,立即进入到了 PROCESS_BLOCK 阶段:
在这个阶段当中根据 module graph 依赖图保存的模块映射 blockInfoMap 获取这个 module(称为A) 的同步依赖 modules 及异步依赖 blocks。
接下来遍历 modules 当中的包含的 module(称为B),判断当前这个 module(A) 所属的 chunk 当中是否包含了其依赖 modules 当中的 module(B),如果不包含的话,那么会在 queue 当中加入新的项,新加入的项目的 action 为 ADD_AND_ENTER_MODULE,即这个新增项在下次遍历的时候,首先会进入到 ADD_AND_ENTER_MODULE 阶段。
当新项被 push 至 queue 当中后,即这个 module 依赖的还未被处理的 module(A) 被加入到 queue当中后,接下来开始调用iteratorBlock方法来处理这个 module(A) 依赖的所有的异步 blocks,在这个方法内部主要完成的工作是:
调用addChunkInGroup为这个异步的 block 新建一个 chunk 以及 chunkGroup,同时调用 GraphHelpers 模块提供的 connectChunkGroupAndChunk 建立起这个新建的 chunk 和 chunkGroup 之间的联系。这里新建的 chunk 也就是在你的代码当中使用异步API 加载模块时,webpack 最终会单独给这个模块输出一个 chunk,但是此时这个 chunk 为一个空的 chunk,没有加入任何依赖的 module;
建立起当前 module 所属的 chunkGroup 和 block 以及这个 block 所属的 chunkGroup 之间的依赖关系,并存储至 chunkDependencies map 表中,这个 map 表主要用于后面优化 chunk graph;
向 queueDelayed 中添加一个 action 类型为 PROCESS_BLOCK,module 为当前所属的 module,block 为当前 module 依赖的异步模块,chunk(chunkGroup 当中的第一个 chunk) 及 chunkGroup 都是处理异步模块生成的新项,而这里向 queueDelayed 数据集当中添加的新项主要就是用于 queue 的外层遍历。
在 ENTRY_MODULE 阶段即完成了将 entry module 的依赖 module 加入到 queue 当中,这个阶段结束后即进入到了 queue 内层第二轮的遍历的环节:
在对 queue 的内层遍历过程当中,我们主要关注 queue 当中每项 action 类型为 ADD_AND_ENTER_MODULE 的项,在进行实际的处理时,进入到 ADD_AND_ENTER_MODULE 阶段,这个阶段完成的主要工作就是判断 chunk 所依赖的 module 是否已经添加到 chunk 内部(chunk.addModule方法),如果没有的话,那么便会将 module 加入到 chunk,并进入到 ENTRY_MODULE 阶段,进入到后面的流程(见上文),如果已经添加过了,那么则会跳过这次遍历。
当对 queue 这一轮的内层的遍历完成后(每一轮的内层遍历都对应于同一个 chunkGroup,即每一轮内层的遍历都是对这个 chunkGroup 当中所包含的所有的 module 进行处理),开始进入到外层的遍历当中,即对 queueDelayed 数据集进行处理。
以上是在processDependenciesBlocksForChunkGroups方法内部对于 module graph 和 chunk graph 的初步处理,最终的结果就是根据 module graph 建立起了 chunk graph,将原本空的 chunk 里面加入其对应的 module 依赖。
entryPoint 包含了 a, b, d 3个 module,而 a 的异步依赖模块 c 以及 c 的同步依赖模块 d 同属于新创建的 chunkGroup2,chunkGroup2 中只有一个 chunk,而 c 的异步模块 b 属于新创建的 chunkGroup3。

// 创建异步的 block
// For each async Block in graph
/**
* @param {AsyncDependenciesBlock} b iterating over each Async DepBlock
* @returns {void}
*/
const iteratorBlock = b => {
// 1. We create a chunk for this Block
// but only once (blockChunkGroups map)
let c = blockChunkGroups.get(b);
if (c === undefined) {
c = this.namedChunkGroups.get(b.chunkName);
if (c && c.isInitial()) {
this.errors.push(
new AsyncDependencyToInitialChunkError(b.chunkName, module, b.loc)
);
c = chunkGroup;
} else {
// 通过 addChunkInGroup 方法创建新的 chunkGroup 及 chunk,并返回这个 chunkGroup
c = this.addChunkInGroup(
b.groupOptions || b.chunkName,
module, // 这个 block 所属的 module
b.loc,
b.request
);
chunkGroupCounters.set(c, { index: 0, index2: 0 });
blockChunkGroups.set(b, c);
allCreatedChunkGroups.add(c);
}
} else {
// TODO webpack 5 remove addOptions check
if (c.addOptions) c.addOptions(b.groupOptions);
c.addOrigin(module, b.loc, b.request);
}
// 2. We store the Block+Chunk mapping as dependency for the chunk
let deps = chunkDependencies.get(chunkGroup);
if (!deps) chunkDependencies.set(chunkGroup, (deps = []));
// 当前 chunkGroup 所依赖的 block 及 chunkGroup
deps.push({
block: b,
chunkGroup: c,
couldBeFiltered: true
});
// 异步的 block 使用创建的新的 chunkGroup
// 3. We enqueue the DependenciesBlock for traversal
queueDelayed.push({
action: PROCESS_BLOCK,
block: b,
module: module,
chunk: c.chunks[0], // 获取新创建的 chunkGroup 当中的第一个 chunk,即 block 需要被加入的 chunk
chunkGroup: c // 异步 block 使用新创建的 chunkGroup
});
};
...
const ADD_AND_ENTER_MODULE = 0;
const ENTER_MODULE = 1;
const PROCESS_BLOCK = 2;
const LEAVE_MODULE = 3;
...
const chunkGroupToQueueItem = chunkGroup => ({
action: ENTER_MODULE,
block: chunkGroup.chunks[0].entryModule,
module: chunkGroup.chunks[0].entryModule,
chunk: chunkGroup.chunks[0],
chunkGroup
});
let queue = inputChunkGroups.map(chunkGroupToQueueItem).reverse()
while (queue.length) { // 外层 queue 遍历
while (queue.length) { // 内层 queue 遍历
const queueItem = queue.pop();
module = queueItem.module;
block = queueItem.block;
chunk = queueItem.chunk;
chunkGroup = queueItem.chunkGroup;
switch (queueItem.action) {
case ADD_AND_ENTER_MODULE: {
// 添加 module 至 chunk 当中
// We connect Module and Chunk when not already done
if (chunk.addModule(module)) {
module.addChunk(chunk);
} else {
// already connected, skip it
break;
}
}
// fallthrough
case ENTER_MODULE: {
...
queue.push({
action: LEAVE_MODULE,
block,
module,
chunk,
chunkGroup
});
}
// fallthrough
case PROCESS_BLOCK: {
// get prepared block info
const blockInfo = blockInfoMap.get(block);
// Traverse all referenced modules
for (let i = blockInfo.modules.length - 1; i >= 0; i--) {
const refModule = blockInfo.modules[i];
if (chunk.containsModule(refModule)) {
// skip early if already connected
continue;
}
// enqueue the add and enter to enter in the correct order
// this is relevant with circular dependencies
queue.push({
action: ADD_AND_ENTER_MODULE,
block: refModule, // 依赖 module
module: refModule, // 依赖 module
chunk, // module 所属的 chunk
chunkGroup // module 所属的 chunkGroup
});
}
// 开始创建异步的 chunk
// Traverse all Blocks
iterationOfArrayCallback(blockInfo.blocks, iteratorBlock);
if (blockInfo.blocks.length > 0 && module !== block) {
blocksWithNestedBlocks.add(block);
}
break;
}
case LEAVE_MODULE: {
...
break;
}
}
}
const tempQueue = queue;
queue = queueDelayed.reverse();
queueDelayed = tempQueue;
}接下来进入到第二个步骤,遍历 chunk graph,通过和依赖的 module 之间的使用关系来建立起不同 chunkGroup 之间的父子关系,同时剔除一些没有建立起联系的 chunk。
首先还是完成一些数据的初始化工作,chunkGroupInfoMap 存放了不同 chunkGroup 相关信息:
/** @type {Map<ChunkGroup, ChunkGroupInfo>} */
const chunkGroupInfoMap = new Map();
/** @type {Queue<ChunkGroup>} */
const queue2 = new Queue(inputChunkGroups);
for (const chunkGroup of inputChunkGroups) {
chunkGroupInfoMap.set(chunkGroup, {
minAvailableModules: undefined,
availableModulesToBeMerged: [new Set()]
});
}获取在第一阶段的 chunkDependencies 当中缓存的 chunkGroup 的 deps 数组依赖,chunkDependencies 中保存了不同 chunkGroup 所依赖的异步 block,以及同这个 block 一同创建的 chunkGroup(目前二者仅仅是存于一个 map 结构当中,还未建立起 chunkGroup 和 block 之间的依赖关系)。
如果 deps 数据不存在或者长度为0,那么会跳过遍历 deps 当中的 chunkGroup 流程,否则会为这个 chunkGroup 创建一个新的 available module 数据集 newAvailableModules,开始遍历这个 chunkGroup 当中所有的 chunk 所包含的 module,并加入到 newAvailableModules 这一数据集当中。并开始遍历这个 chunkGroup 的 deps 数组依赖,这个阶段主要完成的工作就是:
connectDependenciesBlockAndChunkGroup建立起 deps 依赖中的异步 block 和 chunkGroup 的依赖关系;connectChunkGroupParentAndChild建立起 chunkGroup 和 deps 依赖中的 chunkGroup 之间的依赖关系 (这个依赖关系也决定了在 webpack 编译完成后输出的文件当中是否会有 deps 依赖中的 chunkGroup 所包含的 chunk);那么在我们给出的示例当中,经过在上面提到的这些步骤,第一阶段处理 entryPoint(chunkGroup),以及其包含的所有的 module,在处理过程中发现这个 entryPoint 依赖异步 block c,它包含在了 blocksWithNestedBlocks 数据集当中,依据对应的过滤规则,是需要继续遍历异步 block c 所在的 chunkGroup2。接下来在处理 chunkGroup2 的过程当中,它依赖 chunkGroup3,且这个 chunkGroup3 包含异步 block d,因为在第一阶段处理 entryPoint 过程中完成了一轮 module 集的收集,其中就包含了同步的 module d,这里可以想象得到的是同步的 module d 和异步 block d 最终只可能输出一个,且同步的 module d 要比异步的 block d 的优先级更高。因此最终模块 d 的代码会以同步的 module d 的形式被输出到 entryPoint 所包含的 chunk 当中,这样包含异步 block d 的 chunkGroup3 也就相应的不会再被输出,即会被从 chunk graph 当中剔除掉。
最终会生成的 chunk 依赖图为:

/**
* Helper function to check if all modules of a chunk are available
*
* @param {ChunkGroup} chunkGroup the chunkGroup to scan
* @param {Set<Module>} availableModules the comparitor set
* @returns {boolean} return true if all modules of a chunk are available
*/
// 判断chunkGroup当中是否已经包含了所有的 availableModules
const areModulesAvailable = (chunkGroup, availableModules) => {
for (const chunk of chunkGroup.chunks) {
for (const module of chunk.modulesIterable) {
// 如果在 availableModules 存在没有的 module,那么返回 false
if (!availableModules.has(module)) return false;
}
}
return true;
};
// For each edge in the basic chunk graph
/**
* @param {TODO} dep the dependency used for filtering
* @returns {boolean} used to filter "edges" (aka Dependencies) that were pointing
* to modules that are already available. Also filters circular dependencies in the chunks graph
*/
const filterFn = dep => {
const depChunkGroup = dep.chunkGroup;
if (!dep.couldBeFiltered) return true;
if (blocksWithNestedBlocks.has(dep.block)) return true;
if (areModulesAvailable(depChunkGroup, newAvailableModules)) {
return false; // break, all modules are already available
}
dep.couldBeFiltered = false;
return true;
};
/** @type {Map<ChunkGroup, ChunkGroupInfo>} */
const chunkGroupInfoMap = new Map();
/** @type {Queue<ChunkGroup>} */
const queue2 = new Queue(inputChunkGroups);
for (const chunkGroup of inputChunkGroups) {
chunkGroupInfoMap.set(chunkGroup, {
minAvailableModules: undefined,
availableModulesToBeMerged: [new Set()]
});
}
...
while (queue2.length) {
chunkGroup = queue2.dequeue();
const info = chunkGroupInfoMap.get(chunkGroup);
const availableModulesToBeMerged = info.availableModulesToBeMerged;
let minAvailableModules = info.minAvailableModules;
// 1. Get minimal available modules
// It doesn't make sense to traverse a chunk again with more available modules.
// This step calculates the minimal available modules and skips traversal when
// the list didn't shrink.
availableModulesToBeMerged.sort(bySetSize);
let changed = false;
for (const availableModules of availableModulesToBeMerged) {
if (minAvailableModules === undefined) {
minAvailableModules = new Set(availableModules);
info.minAvailableModules = minAvailableModules;
changed = true;
} else {
for (const m of minAvailableModules) {
if (!availableModules.has(m)) {
minAvailableModules.delete(m);
changed = true;
}
}
}
}
availableModulesToBeMerged.length = 0;
if (!changed) continue;
// 获取这个 chunkGroup 的 deps 数组,包含异步的 block 及 对应的 chunkGroup
// 2. Get the edges at this point of the graph
const deps = chunkDependencies.get(chunkGroup);
if (!deps) continue;
if (deps.length === 0) continue;
// 根据之前的 minAvailableModules 创建一个新的 newAvailableModules 数据集
// 即之前所有遍历过的 chunk 当中的 module 都会保存到这个数据集当中,不停的累加
// 3. Create a new Set of available modules at this points
newAvailableModules = new Set(minAvailableModules);
for (const chunk of chunkGroup.chunks) {
for (const m of chunk.modulesIterable) { // 这个 chunk 当中所包含的 module
newAvailableModules.add(m);
}
}
// 边界条件,及异步的 block 所在的 chunkGroup
// 4. Foreach remaining edge
const nextChunkGroups = new Set();
// 异步 block 依赖
for (let i = 0; i < deps.length; i++) {
const dep = deps[i];
// Filter inline, rather than creating a new array from `.filter()`
if (!filterFn(dep)) {
continue;
}
// 这个 block 所属的 chunkGroup,在 iteratorBlock 方法内部创建的
const depChunkGroup = dep.chunkGroup;
const depBlock = dep.block;
// 开始建立 block 和 chunkGroup 之间的关系
// 在为 block 创建新的 chunk 时,仅仅建立起了 chunkGroup 和 chunk 之间的关系,
// 5. Connect block with chunk
GraphHelpers.connectDependenciesBlockAndChunkGroup(
depBlock,
depChunkGroup
);
// 建立起新创建的 chunkGroup 和此前的 chunkGroup 之间的相互联系
// 6. Connect chunk with parent
GraphHelpers.connectChunkGroupParentAndChild(chunkGroup, depChunkGroup);
nextChunkGroups.add(depChunkGroup);
}
// 7. Enqueue further traversal
for (const nextChunkGroup of nextChunkGroups) {
...
// As queue deduplicates enqueued items this makes sure that a ChunkGroup
// is not enqueued twice
queue2.enqueue(nextChunkGroup);
}
}
...以上就是通过源码分析了 webpack 是如何构建 module graph,以及是如何通过 module graph 去生成 chunk graph 的,当你读完这篇文章后应该就大致了解了在你每次构建完成后,你的项目应用中目标输出文件夹出现的不同的 chunk 文件是经过哪些过程而产生的。
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.






