The solutuion is built with Python 3.6.1 and Pandas 0.20.2
The Final Solution is FindDealsCoveredByRenRe.py.
The input files are in Input folder.
The output files are in Output folder.
The test output files are in Output/Test folder.
-
The final solution FindDealsCoveredByRenRe used chunk in Pandas to handle large files. Other solutions could be using the library dask or sql lite.
-
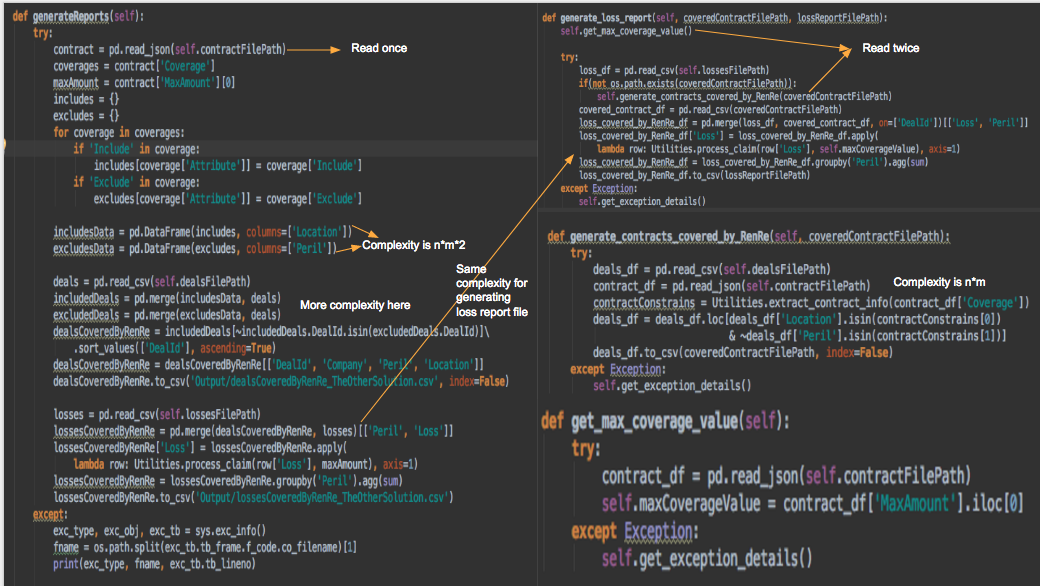
TheOtherSolutuion is my second thought after I finished the first one. After comparing the complexity, the solution FindDealsCoveredByRenRe is better than TheOtherSolutuion.
-
FindDealsCoveredByRenRe.py
is seperated by 4 parts so the functions can be reusable.
I work out this solutuion first. The Utilities.extract_contract_info returns includes and excludes lists. The lists are used to filter out the insurance covered by RenRe. Then the output file can be merged with the losses csv. -
TheOtherSolution.py
is one chunk, so the contract Json file is only read once. It reduced the reading time.
After finished the first solution I was thinking if I could make the contract json file as a csv file. The final result could be produced by merging the 3 csv files. The complexity could be reduced comparing with the solution FindDealsCoveredByRenRe.py However, pandas can not do filtering csv files without same indexes. So for creating the same data format, more complexity produced during the process.