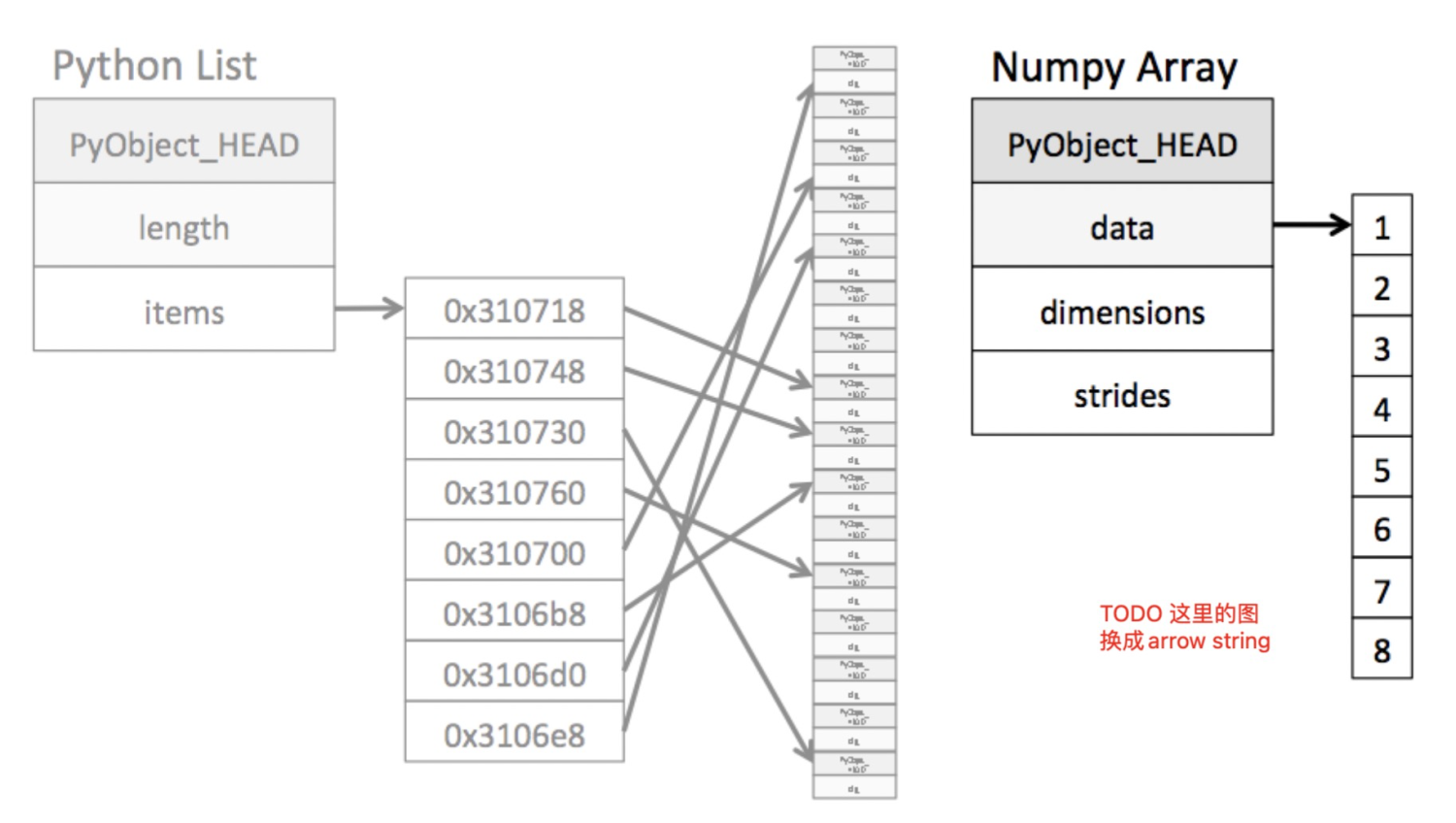
论文地址:https://www-cs.stanford.edu/~matei/papers/2022/sigmod_photon.pdf
摘要
Photon 是一个针对Lakehouse场景的向量化查询引擎。性能比云数据仓库好,同时本身也能够高效处理原始数据,以及支持Apache Spark API。对于某些work load性能提升十倍,以及新的100TB TPC-DS benchmark记录
设计选择:vectorization vs. code generation) 这个也可以参考论文:https://www.vldb.org/pvldb/vol11/p2209-kersten.pdf 这篇论文也在Photon的Reference里面提到了
1 介绍
Designing Photon required tackling two key challenges.
- First, unlike a traditional data warehouse engine, Photon needed to perform well on raw, uncurated data, which can include highly irregular datasets, poor physical layout, and large fields, all with no useful clustering or data statistics.
- Second, we wanted Photon to support, and be semantically compatible with, the existing Apache Spark DataFrame API that is widely used for data lake workloads.
Challenge 1: Supporting raw, uncurated data.
Photon使用向量化的设计,主要有运行时自适应执行的好处:
Vectorized execution enabled us to support runtime adaptivity, wherein Photon discovers, maintains, and exploits micro-batch data characteristics with specialized code paths to adapt to the properties of Lakehouse datasets for optimal performance. For example, Photon runs optimized per-batch code for columns that rarely have NULL values, or mostly-ASCII string data.
Challenge 2: Supporting existing Spark APIs.
2 BACKGROUND
2.1 Databricks’ Lakehouse Architecture
- Data Lake Storage: decouples data storage from compute。Databricks accesses customer data using connectors
between a compute service and the data lake. The data itself is stored in open file formats such as Apache Parquet。
- Automatic Data Management: an open source ACID table storage layer over cloud object stores. Delta Lake enables warehouse-style features such as ACID transactions, time travel, audit logging, and fast metadata operations over tabular datasets. Delta Lake stores both its data and metadata as Parquet.
- Elastic Execution Layer:Spark + Photon
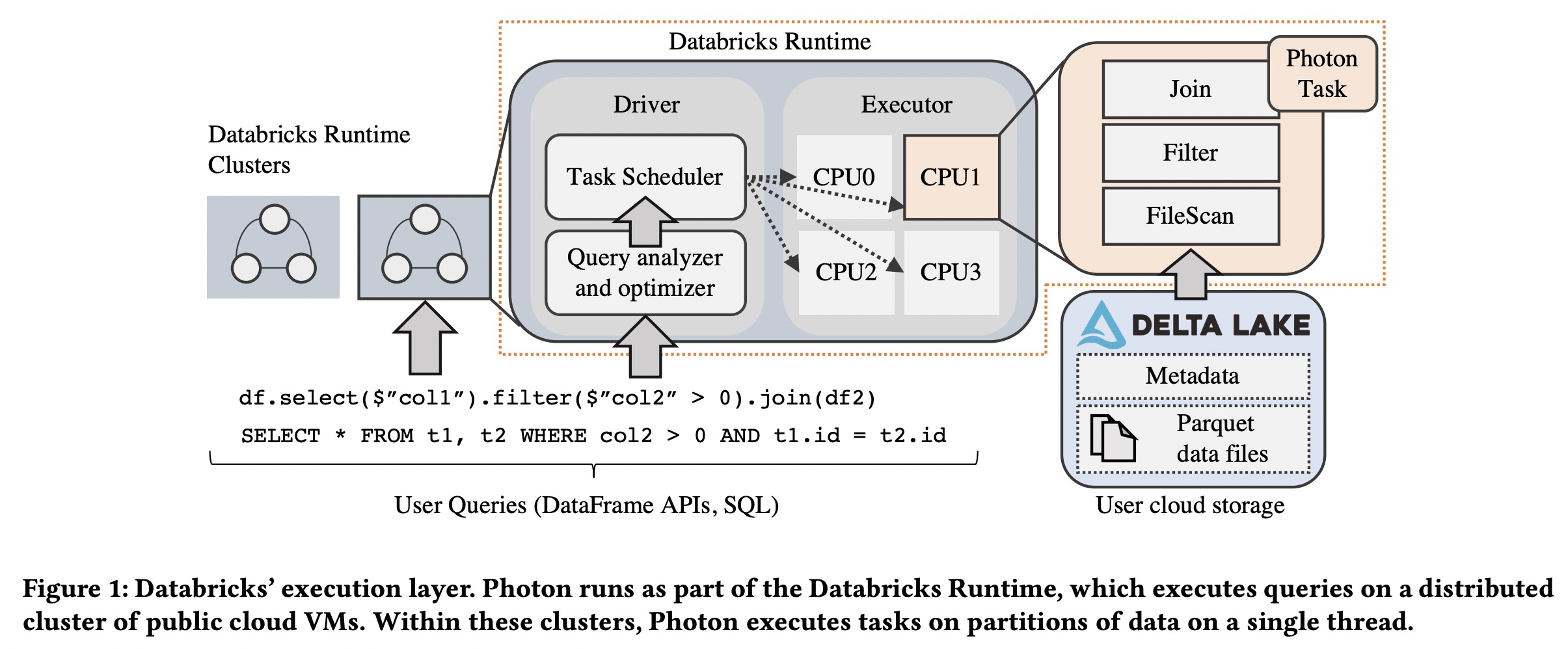
Photon fits into this execution layer by handling single-threaded query execution on each partition of the data processed.
2.2 The Databricks Runtime
A query plan is a tree of SQL operators (e.g., Filter, Project, Shuffle) that maps to a list of stages. After query planning, the driver launches tasks to execute each stage of the query. Each task runs uses the in-memory execution engine to process data. Photon is an example of such an execution engine; it supersedes the previous engine based on Apache Spark SQL.
3 EXECUTION ENGINE DESIGN DECISIONS
3.1 Overview
- Photon使用C++实现,编译成共享库,通过JNI被java executor调用。 Photon runs as part of a single-threaded task in DBR, within an executor’s JVM process.
- Photon structures a SQL query as as tree of operators, where each operator uses a HasNext()/GetNext() API to pull batches of data from its child. 与Java算子交互也是通过JNI相互拉数据。
- Photon操作在列式数据格式上面,使用向量化执行进行加速,没有使用codegen
3.2 JVM vs. Native Execution
为什么采用C++实现?
- IO开销已经显著降低难以继续优化,CPU负载需要进一步优化:
- local NVMe SSD caching
- auto optimized shuffle(Spark AQE)
- Delta Lake提供的数据聚类等技术也可以通过 file pruning等方式跳过不必要的文件也可以进一步减少IO等待时间
- Lakehouse本身引入了对非标准数据较重的数据处理,比如大字符串,非结构化嵌套数据等。这也导致需要优化执行性能
- 而继续优化JVM执行引擎的性能非常困难:
- 需要大量JVM内核细节,确保JIT编译器生成最优代码(比如使用SIMD的循环)。在DataBricks里面只有搞过JVM内核的人才能更新生成Java代码相关的逻辑
- 缺少控制memory pipelining and custom SIMD kernels,也导致了性能天花板
- JVM在heap大于64GB时GC性能受到严重影响,而64GB在现代云环境里面是相当小的内存容量。这导致需要手动在JVM上面管理堆外内存。相比于native c++实现,这不容易实现也不好维护
- 另外Java代码生成也受到方法体大小涸代码缓存限制。比如超过8000个字节码的Java方法不会被编译,超过325个字节码的方法不会被内联。这些限制可能导致回退到Volcano-style的解释器执行模型,严重影响性能。比如对于超过100列的宽表,就经常面临这些限制。
3.3 Interpreted Vectorization vs. Code-Gen
高性能查询引擎一般两种设计:
- 向量化:clickhouse、MonetDB、X100。动态分发选择代码路径,按batch向量化执行摊还虚方法调用成本
- 代码生成:impala(LLVM)、spark sql(Catalyst+Janino+Java JIT)、HyPer(Rust实现)。通过整阶段代码生成绕过所有虚方法调用
Photon采用的是向量化技术,原因:
- Easier to develop and scale。代码生成更难开发和debug,运行时需要植入额外代码来帮助观察行为和debug
- Observability is easier。代码生成通过方法合并和内联消除了解释和函数调用开销,性能虽好,但引入了观察性问题。因为算子代码被融合成了一次处理一行的代码,因此给每个算子单独添加metrics比较困难。而向量化保留了算子之间抽象的边界,通过按批向量化执行摊还成本,保证了每个算子都可以低成本维护自己的metrics。
- Easier to adapt to changing data。Photon可以采集每批粒度上采集数据的特性,然后动态选择最佳codepath。这对于Lakehouse工作负载特别重要,因为传统的数仓约束和统计信息在Lakehouse查询case下可能并不存在,同时动态分派执行路径本身就已经是解释化执行的一部分了。代码生成要做同样的事情就需要提前生成所有分支的代码或者重编译部分查询,即使可行也会影响查询时间、启动时间、内存开销。
- Specialization is still possible. 代码生成可以通过公共子表达式消除和列裁剪较低开销,但通过为向量化执行在常见case(比如col >= left
and col <= right)创建特殊的融合算子,这类性能gap可以避免掉。由于避免了codegen的复杂性,开发工程师也有更多的时间来做这些优化。
3.4 Row vs. Column-Oriented Execution
Photon采用列存格式,而不是Spark SQL的行存格式。列存有几个特点:
- 更适合SIMD向量化指令。
- 通过让算子实现为紧密的循环,能够进行更加有效的数据流水线和数据预取优化。
- 同时在数据序列化和spill时也更加高效。
- 另外在Lakehouse里面主要文件格式是列存文件格式Parquet。列存格式可以跳过耗时的行列转换。
- 同时在列式格式当中还可以支持字典编码来减少内存开销,这对于String和其它变成数据特别有用,同时字符串在LakeHouse里面也很常见。
- 最终列式计算引擎计算结果写列存也更加容易。
不过Photon在某些场景里面还是会把列存转换为行存。比如在Hash表里面把数据缓存为行存结构。因为当执行hash表的key比较时,存储为列式格式需要大量随机访问列存,对缓存非常不友好。
3.5 Partial Rollout
用Photon执行部分查询,对于不支持的特性,优雅回退到Spark的JVM算子。
4 VECTORIZED EXECUTION IN PHOTON
4.1 Batched Columnar Data Layout
- column vector:单列持有单批值。column vector也持有一个byte vector,来表示每个值是否是NULL,同时也可以持有batch-level的元数据,比如string编码。(这块跟Arrow vector基本上是一样的)
- column batch:a collection of column vectors, and represents rows。这个跟Arrow的RecordBatch基本上一样的。但是column batch也持有一个position list来表示那些active的行。Arrow没有这个设计。
尽管将可以把active vs. inactive存储为一个byte vector,然后对SIMD更加友好。但这样在稀疏的batch上面也需要遍历所有行。实验表明在多数情况下只会使性能更差,即使是最简单的查询。另外数据在算子之间也是按照column batch进行传递的。每个算子从上游接收一个column batch,然后产出一个或者多个column batch。

4.2 Vectorized Execution Kernels
Photon的列式执行是构建在execution kernels之上的。execution kernels是高度优化的处理一个或者多个向量数据的循环的函数。Arrow Compute也采用了这种设计,实现了大量kernels函数。基本上Photon的所有操作比如expressions、hash table probing(TODO 进一步了解以及对比Arrow的hash table)、serialization以及runtime statistics
calculation都是实现为kernels。kernels多数情况下依赖编译器自动向量化,同时Photon也会在输入参数上提供一些RESTRICT标记提示编译器自动向量化。有时候Photon也会手写SIMD指令来实现向量化。通过C++模板将Kernels函数具化,以支持不同输入类型。每个Kernel函数接收Vectors以及column batch position list作为输入,然后产出一个vector作为输出。
下面是一个计算平方根的kernel示例:
template <bool kHasNulls, bool kAllRowsActive>
void SquareRootKernel(const int16_t* RESTRICT pos_list,
int num_rows, const double* RESTRICT input,
const int8_t* RESTRICT nulls, double* RESTRICT result) {
for (int i = 0; i < num_rows; i++) {
// branch compiles away since condition is
// compile-time constant.
int row_idx = kAllRowsActive ? i : pos_list[i];
if (!kHasNulls || !nulls[row_idx]) {
result[row_idx] = sqrt(input[row_idx]);
}
}
}4.3 Filters and Conditionals
- Filters: 通过修改column batch的position list实现。一个filtering表达式接收column vectors作为输入,返回一个position list作为输入,然后产出一个vector作为输出。
- Conditionals(待讨论):对于CASE WHEN场景,对于每个CASE分支,在kernel调用内部修改position list保证只让一些行active。然后多个CASE分支,每个都返回单独的position list。在一个position list里面inactive的row可能在别的position list里面是active的,因此不能修改inactive的行。
4.4 Vectorized Hash Table
Photon’s hash table是一个vectorized实现,主要分为三步:
- 首先使用hashing kernel给一批key计算hash
- 接下来probe kernel使用hash值加载hash table entries的指针,注意hash table entries的存储为行而不是列的
- 最终将hash table entries跟查询的key进行column-by-column的比较,然后为不匹配的行产出一个position list。不匹配的行通过调整bucket index继续probing hash table(Photon用的是quadratic probing)。
其实就是把Hash表的实现并行化了一下,把hash计算,bucket查找,
这块跟Arrow Compute的Swiss Table很像:https://github.com/apache/arrow/blob/master/cpp/src/arrow/compute/exec/doc/key_map.md .个人感觉Arrow的Swiss Table是一个更优的设计
4.5 Vector Memory Management
Photon使用了一个自己写的buffer pool来管理内存,buffer pool会cache分配,同时使用最近使用的内存来分配内存。这样可以将热点内存用于每个input batch的重复分配。因为query算子在执行期间固定,因此如果输入batch是固定长度类型,处理单个input batch的vector分配数量就也是固定的。
变长数据(e.g., buffers for strings)是使用一个append-only pool单独管理的,Photon会在处理新的batch前释放这个buffer pool。这个pool使用的内存是通过一个全局的memory tracker来记录的,这样引擎就可以在遇到很大的字符串时调小batch size。
对于超过单个batch生命周期的内存分配比如聚合和join,这些内存是被一个外部的内存管理器单独追踪的。这种细粒度的内存管理比Spark SQL更加能够健壮处理大输入记录。
4.6 Adaptive Execution
在LakeHouse场景里面,要处理的数据大部分都缺少元数据、统计信息,而且大部分数据本身也不标准。因此很难在执行计划阶段选择出最优的执行计划。因此Photon提供了batch-level的自适应执行能力,即在运行时对一个batch的数据构建元数据,然后使用该元数据来优化execution kernel的选择。
主要的自适应能力包括两部分:
— 每个batch是否有Null值。没有空值的话可以移除分支。
- 每个batch是否有inactive的行。没有inactive行的话可以避免position list的indirection,这也会促进SIMD
其它情况下也会进行一些case by case的优化:
- 所有字符串都是ASCII时可以使用定长的Vector;
- 运行时压缩稀疏的batch
- 自适应的Shuffle编码等,通过寻找Shuffle Key的pattern,从而使用更加高效的编码
5 INTEGRATION WITH DATABRICKS RUNTIME
Photon目前主要是作为Spark的native算子集成到spark的,因此Photon是Spark和Spark共享集群资源
5.1 Converting Spark Plans to Photon Plans
Spark SQL的执行计划转到Photon的执行计划,是通过给Spark的catalyst优化器增加一组规则来把部分执行计划节点换成Photon来实现的。

添加的规则首先从自底向上从file scan开始遍历,把每个Photon支持的节点替换成Photon。如果某个节点Photon不支持,就插入一个转换节点把Photon列式数据转换成Spark SQL的行存数据。同时也在file scan和第一个Photon之间插入一个适配器节点来把file scan的数据转换成Photon的列式存储。因为file scan一般读取的parquet的列式数据,因此这一步一般是Zero-Copy的。
5.2 Executing Photon Plans
在一个Photon task里面,executor首先把local执行计划的Photon部分序列化成Protobuf格式,然后通过JNI传递给Photon C++ library,Photon再把它反序列化和转换成Photon内部的执行计划。执行计划跟Spark很像,每个算子都有HasNext()/GetNext()接口,数据是从末端节点(parent)向开始节点(child)按照column batche的粒度拉取的方式进行流转。
对于数据交换部分,Photon会复合Spark Shuffle协议的文件,然后把Shuffle文件的元数据传递给Spark来执行Shuffle的网络IO过程。然后在接收端(新的stage)Photon会从Shuffle里面读取对应的分区。
Adapter node to read Scan data:Photon本地执行计划的叶子节点始终是adapter节点。scan node把数据首先读取到OffHeapColumnVector,然后把Photon存储数据和NULL的Vector指向OffHeapColumnVector对应的address即可,整个过程zero-Copy。
Transition node to pass Photon data to Spark
Photon plan的最后一个节点是一个过渡节点,负责把列式数据转换为Spark SQL需要的行存格式。因为最开始读数据就是列式,因此Photon只做了一次行列转换。而Spark SQL本身也会在最开始读数据时执行一次转换,因此Photon并没有引入额外开销。后续Photon可能会考虑在中间节点引入Photon算子,这将引入额外的行列转换开销,需要进行tradeoff。
5.3 Unified Memory Management
因为Photon是作为Spark Task在Spark Executor里面运行的,因此Photon和Spark Executor共享所有集群资源,两者必须有一致的资源视图。因此Photon hook了Spark的内存管理器。主要是通过将内存保留和内存分配分开来实现的,这块跟Arrow Java的内存管理就非常像,不确定是不是参考了Arrow。
内存reservations会向Spark请求内存,这可能会导致Spill,这时Spark会要求使用内存的算子(memory consumer)释放内存。Spark和Photon算子都可以请求和释放内存。Spilling设计为动态,主要是因为通常不知道每个算子将消费多少数据和内存,尤其是在UDF时。
Spill策略跟Spark一样,将内存消费者按分配的内存从低到高排序,然后将第一个满足要spill大小的算子进行spill,这样可以最小化spill的数量和数据。
在保留内存后,Photon就可以分配内存了,分配内存是纯local的操作,而不是从Spark的内存池划一块内存出来,Spark只是负责统计内存。这样Spill算子执行将分为两个阶段:保留阶段请求内存,可能会导致别的算子spill让出内存;分配阶段产出中间计算结果。这对于Lakehouse很关键,因为查询经常超过可用内存。
5.4 Managing On-heap vs. Off-heap memory
Spark集群的每个Executor都配置了一个静态的off-heap大小,Spark内存管理器负责这块内存的管理,每个内存消费者需要确保自己只使用分配的内存,过度使用可能导致OOM。但只提供内存并不足够,由于JVM通常只在堆内存使用较高时才触发老年代GC,而Photon使用的内存都是堆外内存,因此GC很少发生。当Photon依赖heap内存时就可能出现问题,比如在执行broadcast hash join时候需要把数据从Photon堆外内存拷贝到堆内存。但是这个临时的内存使用并不会被频繁GC,因此当其它Spark JVM算子分配大块内存时可能导致Java OutOfMemory。Photon通过添加一个监听器在查询结束时清理Photon状态避免了双份内存占用的问题。
5.5 Interaction with Other SQL Features
Photon算子实现了导出统计信息(shuffle文件大小,输出数据行数等)的接口,这些信息可以提供给AQE在stage边界进行重分区和执行计划调整。
Photon也和Spark的metric系统做了集成,可以通过Spark UI查看metrics。
5.6 Ensuring Semantics Consistency
因为相同的query表达式可以同时运行在Photon和Spark里面,因此两者的行为必须保持一致。Java和C++的integer-to-floating转换在某些情况下行为不一致,以及时区数据库的版本不一致都可能导致返回不同的结果。因此Photon增加了三类测试捞保证行为的一致性:
- Unit tests: 直接对SQL表达式进行测试。C++层实现了一个表达式测试框架,同时也和Spark的表达式测试case进行了集成。
- End-to-end tests: 提交使用Photon和Spark的查询,然后比较结果
- Fuzz tests: 随机生成输入数据和Query,然后同时使用Photon和Spark执行并比较结果
6 EXPERIMENTAL EVALUATION