Classifying MNIST digits without abstractifying the mathematical optimization involved in deep learning, diving into the meat of backpropagation.

Machine Learning uses mathematical optimization to minimize a loss, or measure of how bad the model is, where we then can descend the gradients of the parameters, called gradient descent. Finding the partial derivative, or rate of change, of a function with respect to its parameters is finding the gradient of those parameters.
Multilayer feedforward networks contain input neurons, hidden neurons, and output neurons, which can be expressed as single numbers. Each and every input neuron affects each hidden neuron in the second layer, and so on until the output layer.
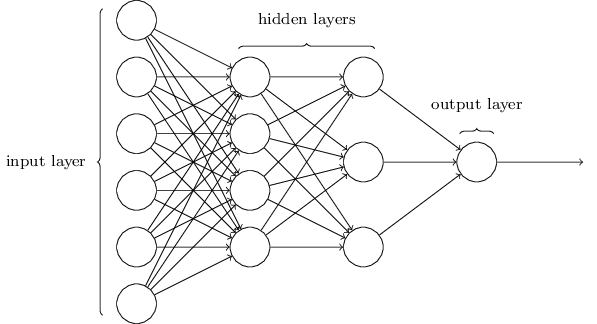
Each neuron is connected to a value in the next layer by a multiplier, or 'weight', and then added to a bias. This value, later expressed as 'z', is then sent through an activation function, such as sigmoid, to squish the value to the range of (0, 1), which is known as the activation. The activation of a neuron in any layer except for the input layer may be expressed as this:
where the superscript index is the layer, and the subscript index is of which neuron it is in a layer. However, this can be simplified significantly by expressing this as a series of matrix operations on an entire layer:
Deep neural networks are usually trained on mini-batches of data at a time, finding an optimal balance between training time and results, where multiple inputs are fed in and multiple outputs are expected. This can be done by simply adding more rows to the input matrix.
The goal of backpropagation is to adjust the weights and biases in order to optimally classify MNIST digits. We first have to have a measure of how bad the network performs, so that we can minimize it using gradient descent. An easy yet effective one to implement is the Mean Squared Error:
'Y' is the expected values, in our case that would be a vector of 0's except for the index that is the handwritten input digit, which will be a 1. Where L is the number of layers, so a superscript L would be the final activations, and is what the network predicts what the expected labels should be, computed through the layers of matrix operations.
To do this we must find the partial derivative with respect for each weight and bias, or gradients, using the chain rule. These are the calculated derivatives of a simple neural network with one input neuron, and one output neuron. Remember that 'z' is the pre-activation.
If we add another layer of one neuron to the input, how do we find the weight and bias gradient of the first layer? We have to find the gradient of the activation in the second layer, and use it in the chain rule the same way we used the derivative of our loss function.
When we add more neurons per layer, we can abstractify the backpropagation process in the same way we did with forward propagation: using matrix operations. The math does not change that much. Representing transpose matrices conflict with the superscript, so the layer it is in is now subscript.
Thanks to Online LaTeX Equations for a great equation editor, and 3Blue1Brown for the math!


