Apache Spark is used on NOAA weather data from 2008-2012. Highest temperature is recorded. Performance analysis indicates speedup of about 3x on multiple nodes.
PySpark is used to map the data by isolating the air temperature recording. Then reduce is used to compare values to find the highest.
Testing is run on a single EOS machine as a baseline. By default, the Spark output provides timing of program execution; these numbers are recorded and graphed. Tests were run on a single node and on a twenty node cluster.
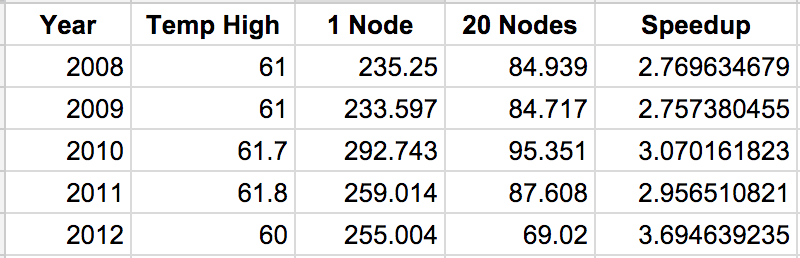
Spark is an effective platform for both data analysis on large data sets - with the ability to scale calculation up by adding machines to a cluster.

