TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
This repository contains all the code of the official implementation for the paper: TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking. The paper has been accepted to appear at COLING 2020. [slides] [poster]
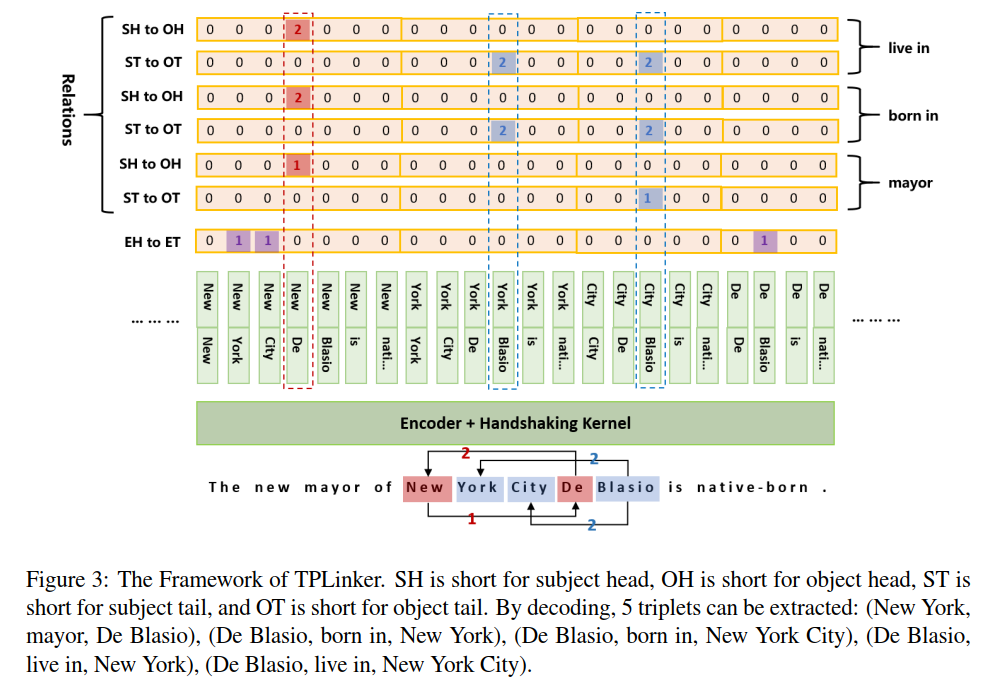
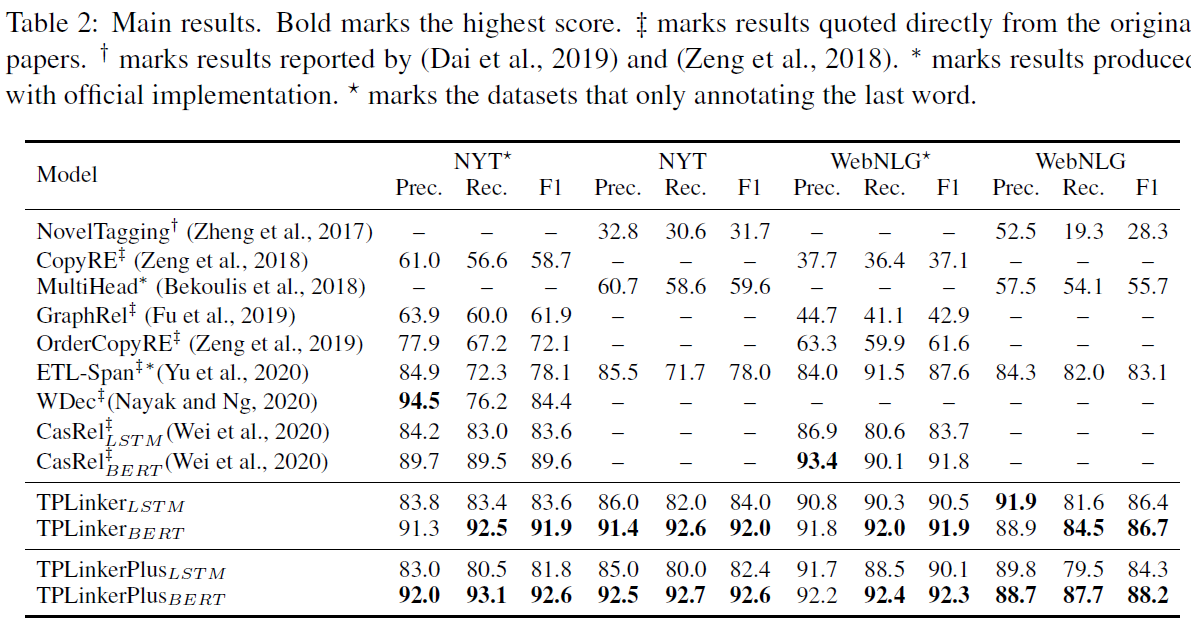
TPLinker is a joint extraction model resolved the issues of relation overlapping and nested entities, immune to the influence of exposure bias, and achieves SOTA performance on NYT (TPLinker: 91.9, TPlinkerPlus: 92.6 (+3.0)) and WebNLG (TPLinker: 91.9, TPlinkerPlus: 92.3 (+0.5)). Note that the details of TPLinkerPlus will be published in the extended paper, which is still in progress.
I am looking for a Ph.D. position! My research insterests are NLP and knowledge graph. If you have any helpful info, please contact me! Thank you very much!
- 2020.11.01: Fixed bugs and added comments in BuildData.ipynb and build_data_config.yaml; TPLinkerPlus can support entity classification now, see build data for the data format; Updated the datasets (added
entity_listfor TPLinkerPlus).


Our experiments are conducted on Python 3.6 and Pytorch 1.4. The main requirements are:
- tqdm
- glove-python-binary==0.2.0
- transformers==2.10.0
- wandb # for logging the results
- yaml
In the root directory, run
pip install -e .Get and preprocess NYT* and WebNLG* following CasRel (note: named NYT and WebNLG by CasRel).
Take NYT* as an example, rename train_triples.json and dev_triples.json to train_data.json and valid_data.json and move them to ori_data/nyt_star, put all test*.json under ori_data/nyt_star/test_data. The same process goes for WebNLG*.
Get raw NYT from CopyRE, rename raw_train.json and raw_valid.json to train_data.json and valid_data.json and move them to ori_data/nyt, rename raw_test.json to test_data.json and put it under ori_data/nyt/test_data.
Get WebNLG from ETL-Span, rename train.json and dev.json to train_data.json and valid_data.json and move them to ori_data/webnlg, rename test.json to test_data.json and put it under ori_data/webnlg/test_data.
If you are bother to prepare data on your own, you could download our preprocessed datasets.
Build data by preprocess/BuildData.ipynb.
Set configuration in preprocess/build_data_config.yaml.
In the configuration file, set exp_name corresponding to the directory name, set ori_data_format corresponding to the source project name of the data.
e.g. To build NYT*, set exp_name to nyt_star and set ori_data_format to casrel. See build_data_config.yaml for more details.
If you want to run on other datasets, transform them into the normal format for TPLinker, then set exp_name to <your folder name> and set ori_data_format to tplinker:
[{
"id": <text_id>,
"text": <text>,
"relation_list": [{
"subject": <subject>,
"subj_char_span": <character level span of the subject>, # e.g [3, 10] This key is optional. If no this key, set "add_char_span" to true in "build_data_config.yaml" when you build the data
"object": <object>,
"obj_char_span": <character level span of the object>, # optional
"predicate": <predicate>,
}],
"entity_list": [{ # This key is optional, only for TPLinkerPlus. If no this key, BuildData.ipynb will auto genrate a entity list based on the relation list.
"text": <entity>,
"type": <entity_type>,
"char_span": <character level span of the object>, # This key relys on subj_char_span and obj_char_span in relation_list, if you do not have, set "add_char_span" to true in "build_data_config.yaml".
}],
}]Download BERT-BASE-CASED and put it under ../pretrained_models. Pretrain word embeddings by preprocess/Pretrain_Word_Embedding.ipynb and put models under ../pretrained_emb.
If you are bother to train word embeddings by yourself, use our's directly.
Set configuration in tplinker/config.py as follows:
common["exp_name"] = nyt_star # webnlg_star, nyt, webnlg
common["device_num"] = 0 # 1, 2, 3 ...
common["encoder"] = "BERT" # BiLSTM
train_config["hyper_parameters"]["batch_size"] = 24 # 6 for webnlg and webnlg_star
train_config["hyper_parameters"]["match_pattern"] = "only_head_text" # "only_head_text" for webnlg_star and nyt_star; "whole_text" for webnlg and nyt.
# if the encoder is set to BiLSTM
bilstm_config["pretrained_word_embedding_path"] = ""../pretrained_word_emb/glove_300_nyt.emb""
# Leave the rest as defaultStart training
cd tplinker
python train.py
TPLinker
Just follow the paper
TPLinkerPlus
# NYT*/NYT
# The best F1: 0.931/0.934 (on validation set), 0.926/0.926 (on test set)
T_mult: 1
batch_size: 24
epochs: 250
log_interval: 10
lr: 0.00001
max_seq_len: 100
rewarm_epoch_num: 2
scheduler: CAWR
seed: 2333
shaking_type: cln
sliding_len: 20
tok_pair_sample_rate: 1
# WebNLG*/WebNLG
# The best F1: 0.934/0.889 (on validation set), 0.923/0.882 (on test set)
T_mult: 1
batch_size: 6
epochs: 250
log_interval: 10
lr: 0.00001
max_seq_len: 100
rewarm_epoch_num: 2
scheduler: CAWR
seed: 2333
shaking_type: cln
sliding_len: 20
tok_pair_sample_rate: 1
Note: Adjusting the learning rate and add epochs may help achieve better performance. It would be helpful to change scheduler, cause it is slow to converge by CAWR. If you get a better performance, it would be very nice of you to share the super parameters by an issue!
Set configuration in tplinker/config.py as follows:
eval_config["model_state_dict_dir"] = "./wandb" # if use wandb, set "./wandb"; if you use default logger, set "./default_log_dir"
eval_config["run_ids"] = ["46qer3r9", ] # If you use default logger, run id is shown in the output and recorded in the log (see train_config["log_path"]); If you use wandb, it is logged on the platform, check the details of the running projects.
eval_config["last_k_model"] = 1 # only use the last k models in to output results
# Leave the rest as the same as the trainingStart evaluation by running tplinker/Evaluation.ipynb

