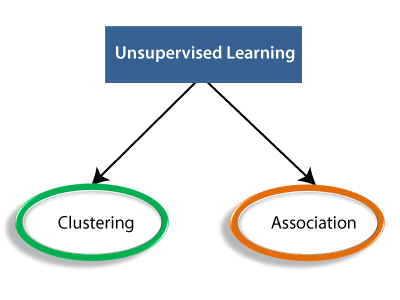
Unsupervised learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses. The most common unsupervised learning method is cluster analysis, which is used for exploratory data analysis to find hidden patterns or grouping in data.
In a supervised learning model, the algorithm learns on a labeled dataset, providing an answer key that the algorithm can use to evaluate its accuracy on training data. An unsupervised model, in contrast, provides unlabeled data that the algorithm tries to make sense of by extracting features and patterns on its own.


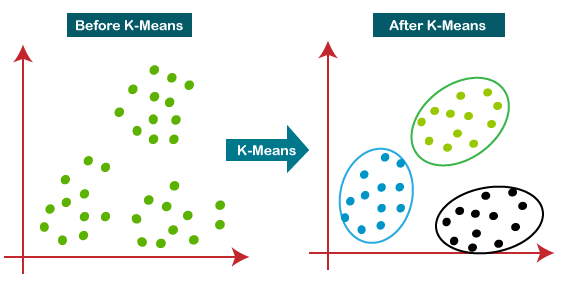
Grouping of similar data items together is known as clustering. This is mainly used for summarization of data.
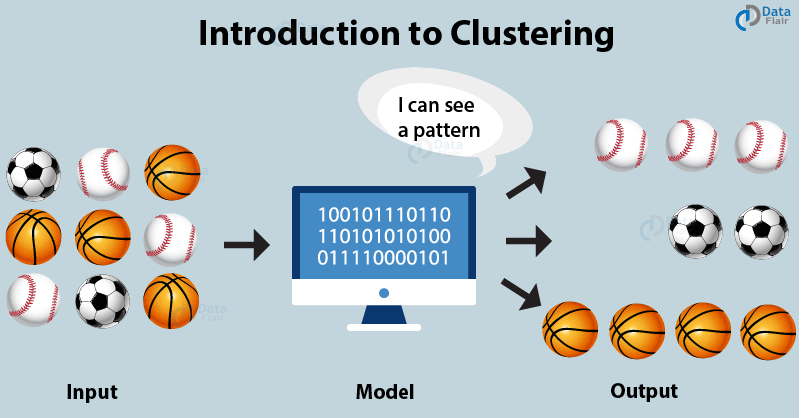

The process of grouping data basing on the information found is known as cluster analysis. The main goal of cluster analysis is that the objects within a group be similar to one another and different from the objects in other groups.
k- Means defines a prototype in terms of a centroid, which is usually the mean of a group of points and is applied to objects in a continuous n-dimensional data.
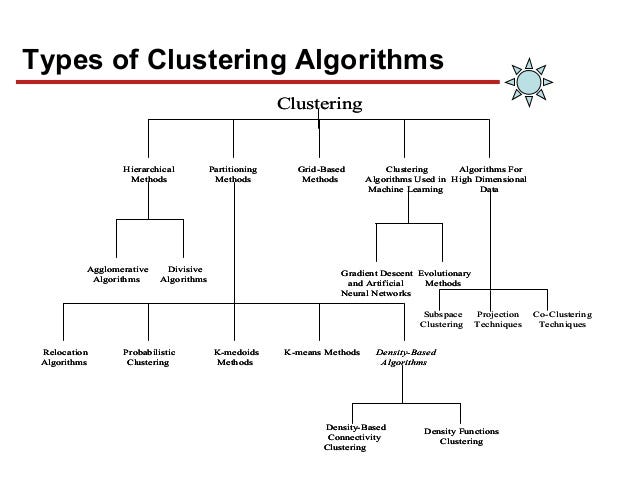
In this type of clustering, the set of clusters are nested clusters that are organized in the form of a tree known as dendrogram. Each node in the tree is the union of its children and root of the tree is the cluster containing all the objects.
There are two types of hierarchical clustering. They are:
- Agglomerative hierarchical clustering
- Divisive hierarchical clustering
Start with the points as individual clusters and at each step, merge the closest pair of clusters.
Start with one i.e.; group all data objects into a single cluster, at each step, split a cluster until only single cluster of individual points remains.
In machine learning problems there often involves tens of thousands of features for each training instance. This can be a problem as it makes our training extremely slow and prone to overfitting (refer to overfitting section). This problem is commonly referred to as the curse of dimensionality.
The main idea of principal component analysis (PCA) is to reduce the dimensionality of a data set consisting of many variables correlated with each other, either heavily or lightly, while retaining the variation present in the dataset, up to the maximum extent.
The same is done by transforming the variables to a new set of variables, which are known as the principal components (or simply, the PCs) and are orthogonal, ordered such that the retention of variation present in the original variables decreases as we move down in the order. So, in this way, the 1st principal component retains maximum variation that was present in the original components.
- Dimensionality: It is the number of random variables in a dataset or simply the number of features, or rather more simply, the number of columns present in your dataset.
- Correlation: It shows how strongly two variables are related to each other. The value of the same ranges for -1 to +1. Positive indicates that when one variable increases, the other increases as well, while negative indicates the other decreases on increasing the former.
- Eigenvectors: It is an eigenvector of a square matrix A, if Av is a
scalar multiple of v. Or simply.
Av = ƛv
Here, v is the eigenvector and ƛ is the eigenvalue associated with it.
- Covariance Matrix: This matrix consists of the covariances between the pairs of variables.The (i,j)th element is the covariance between i-th and j-th variable.
- Normalize the data
- Calculate the covariance matrix
- Calculate the eigenvalues and eigenvectors
- Choosing components and forming a feature vector
- Recasting data along Principal Components axes

Feature engineering is a process to convert the data into a form better understandable to machine learning algorithms.
In the sense, the outcome of Machine learning process is highly dependent on quality of input data.
- Indicator variable from thresholds
- Indicator variable from multiple features
- Sum of two features
- Date and time features
- Dealing with Geo locations
- Applying math formulas

