在线评论的细粒度情感分析对于深刻理解商家和用户、挖掘用户情感等方面有至关重要的价值,并且在互联网行业有极其广泛的应用,主要用于个性化推荐、智能搜索、产品反馈、业务安全等。
使用 AI Challenger 2018 的细粒度用户评论情感分析数据集,共包含6大类20个细粒度要素的情感倾向。
数据集分为训练、验证、测试A与测试B四部分。数据集中的评价对象按照粒度不同划分为两个层次,层次一为粗粒度的评价对象,例如评论文本中涉及的服务、位置等要素;层次二为细粒度的情感对象,例如“服务”属性中的“服务人员态度”、“排队等候时间”等细粒度要素。评价对象的具体划分如下表所示。
| 层次一(The first layer) | 层次二(The second layer) |
|---|---|
| 位置(location) | 交通是否便利(traffic convenience) |
| 距离商圈远近(distance from business district) | |
| 是否容易寻找(easy to find) | |
| 服务(service) | 排队等候时间(wait time) |
| 服务人员态度(waiter’s attitude) | |
| 是否容易停车(parking convenience) | |
| 点菜/上菜速度(serving speed) | |
| 价格(price) | 价格水平(price level) |
| 性价比(cost-effective) | |
| 折扣力度(discount) | |
| 环境(environment) | 装修情况(decoration) |
| 嘈杂情况(noise) | |
| 就餐空间(space) | |
| 卫生情况(cleaness) | |
| 菜品(dish) | 分量(portion) |
| 口感(taste) | |
| 外观(look) | |
| 推荐程度(recommendation) | |
| 其他(others) | 本次消费感受(overall experience) |
| 再次消费的意愿(willing to consume again) |
每个细粒度要素的情感倾向有四种状态:正向、中性、负向、未提及。使用[1,0,-1,-2]四个值对情感倾向进行描述,情感倾向值及其含义对照表如下所示:
| 情感倾向值(Sentimental labels) | 1 | 0 | -1 | -2 |
|---|---|---|---|---|
| 含义(Meaning) | 正面情感(Positive) | 中性情感(Neutral) | 负面情感(Negative) | 情感倾向未提及(Not mentioned) |
数据标注示例如下:
“味道不错的面馆,性价比也相当之高,分量很足~女生吃小份,胃口小的,可能吃不完呢。环境在面馆来说算是好的,至少看上去堂子很亮,也比较干净,一般苍蝇馆子还是比不上这个卫生状况的。中午饭点的时候,人很多,人行道上也是要坐满的,隔壁的冒菜馆子,据说是一家,有时候也会开放出来坐吃面的人。“
| 层次一(The first layer) | 层次二(The second layer) | 标注 (Label) |
|---|---|---|
| 位置(location) | 交通是否便利(traffic convenience) | -2 |
| 距离商圈远近(distance from business district) | -2 | |
| 是否容易寻找(easy to find) | -2 | |
| 服务(service) | 排队等候时间(wait time) | -2 |
| 服务人员态度(waiter’s attitude) | -2 | |
| 是否容易停车(parking convenience) | -2 | |
| 点菜/上菜速度(serving speed) | -2 | |
| 价格(price) | 价格水平(price level) | -2 |
| 性价比(cost-effective) | 1 | |
| 折扣力度(discount) | -2 | |
| 环境(environment) | 装修情况(decoration) | 1 |
| 嘈杂情况(noise) | -2 | |
| 就餐空间(space) | -2 | |
| 卫生情况(cleaness) | 1 | |
| 菜品(dish) | 分量(portion) | 1 |
| 口感(taste) | 1 | |
| 外观(look) | -2 | |
| 推荐程度(recommendation) | -2 | |
| 其他(others) | 本次消费感受(overall experience) | 1 |
| 再次消费的意愿(willing to consume again) | -2 |
结果提交说明
选手需根据训练的模型对测试集的6大类20个的细粒度要素的情感倾向进行预测,提交预测结果,预测结果使用[-2,-1,0,1]四个值进行描述,返回的结果需保存为csv文件。格式如下:
| id | content | location_traffic_ convenience | location_distance_ from_business_district | location_easy _to_find | ...... |
|---|---|---|---|---|---|
| Give a label | Give a label | Give a label | ...... |
标注字段说明:
| location_traffic_ convenience | location_distance_from_ business_district | location_easy_ to_find | service_ wait_time |
|---|---|---|---|
| 位置-交通是否便利 | 位置-距离商圈远近 | 位置-是否容易寻找 | 服务-排队等候时间 |
| service_waiters_ attitude | service_parking_ convenience | service_serving_ speed | environment_noise |
| 服务-服务人员态度 | 服务-是否容易停车 | 服务-点菜/上菜速度 | 价格-价格水平 |
| price_cost_ effective | price_discount | environment_ decoration | environment_noise |
| 价格-性价比 | 价格-折扣力度 | 环境-装修情况 | 环境-嘈杂情况 |
| environment_space | environment_ cleaness | dish_portion | dish_taste |
| 环境-就餐空间 | 环境-卫生情况 | 菜品-分量 | 菜品-口感 |
| dish_look | dish_recommendation | others_overall_ experience | others_willing_to_ consume_again |
| 菜品-外观 | 菜品-推荐程度 | 其他-本次消费感受 | 其他-再次消费的意愿 |
-
多分类问题
每个小类都需要分成 正向、中性、负向、未提及 四种情感,所以其首先是个多分类问题。
-
多标签问题
站在样本角度看,每一个样本被打上了 20 个不同类别的情感标签,所以其也是一个多标签分类问题。
-
多任务学习
问题需要对 6大类20个小类 的细粒度要素情感倾向进行预测,发现每个大类下面的小类之间是相互有联系,并不是完全独立的,比如:大类 位置 下有 交通是否便利、距离商圈远近、是否容易寻找。所以使用迁移学习中的多任务学习或许可以改善分类效果。
某些类别的四种情感标签分布特别不均衡;最后一个大类 其他(本次消费感受、再次消费意愿),是对整体感受的描述,前边各个类评价正向的话,直觉这里也将会有更大概率正向。通过对样本数据统计分析后发现确实如此。
多标签问题,最一般的做法会把每一个类别标签训练一个分类器,好处是简单好理解,弊端是训练时间长,忽略了不同类别标签间的联系,更大量的类别标签无法处理,比如几百上千的类别标签就需要训练几百上千个模型,显然是不可能的。
多任务学习,多个有联系的任务在特征提取阶段共享参数,只在最后几层单独做区分和输出。优点是考虑了不同任务间的联系,有联系的类别标签可以一块训练,对不均衡的样本数据有增强作用。
Seq2Seq,最新的研究把多标签的预测问题看成了一个序列到序列的学习,这样既考虑了标签之间的联系,又可以处理大量标签的问题,很新颖的思路。
所谓单模型,即单输入-多输出模型, 也可称之为多任务模型, 只接收一个输入,每个标签都对应一个输出。在这种架构下,由于不同的输出之间需要共享低层的网络层,因此不同的共享方式,会对模型的效率和分数产生不同的影响。
-
所有的输出共享相同的低层网络层
-
根据每个细粒度所属于的大类分组,同一组的输出共享相同的低层网络层, 不同组的输出之间不共享低层网络层。
试验对比下来,在训练和预测效率上,第一种策略优于第二种,但是在模型分数上,第二种策略往往要好于第一种。
所谓多模型,即单输入-单输出模型, 为每一个粒度各构建一个模型。为了方便,每个粒度都使用相同的模型架构,但分开训练。相较于单模型架构,这种方式建模相对简单,不涉及低层网络层的共享问题,调参难度相对小一些。在执行效率上,当模型比较简单时,单模型的效率要远好于多模型,但当模型比较复杂,参数量较多时, 单模型和多模型在执行效率上差距缩小的比较大。这里通过训练20个4-分类器,对于一个评论文本,每个分类器对其进行分析,最终20个分类器得到的结果汇总起来即为该模型对这条评论的结果。
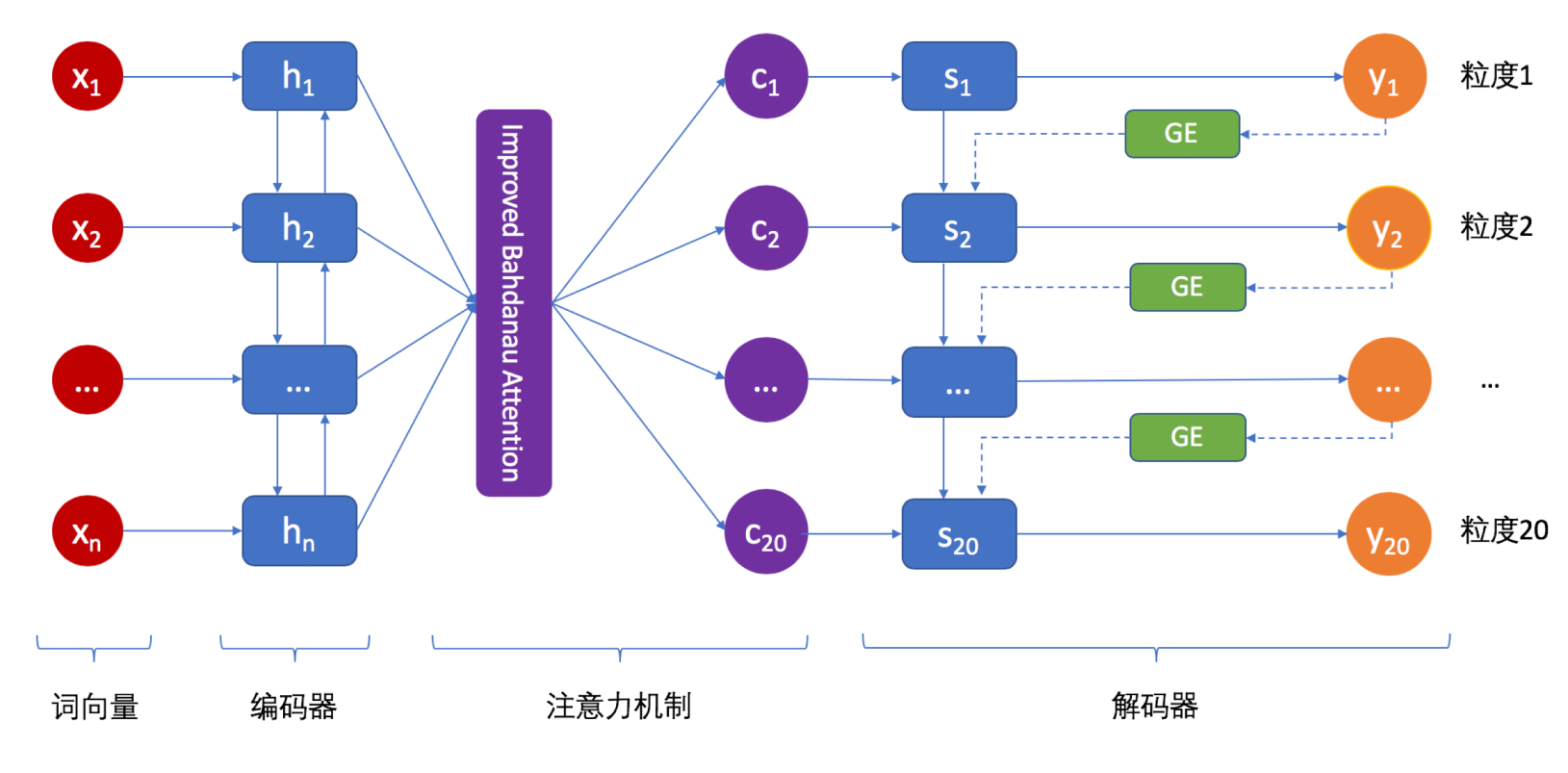
模型由参数共享的语句理解层和参数独立的情感辨别层
- 特征共享层:由1词向量层 + 1双向GRU组成
- 情感辨别层:由20 Capsule层 + 20全连接层组成
该模型的思路是加强处理任务(情感辨别)的能力
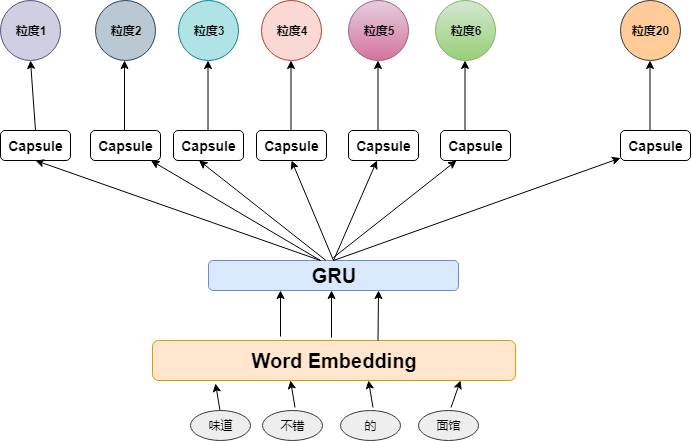
模型由参数共享的语句理解层和参数独立的情感辨别层
- 特征共享层:由1词向量层 + 1双向GRU组成
- 情感辨别层:由20 ResNet层 + 20全连接层组成
该模型的思路是加强处理任务(情感辨别)的能力
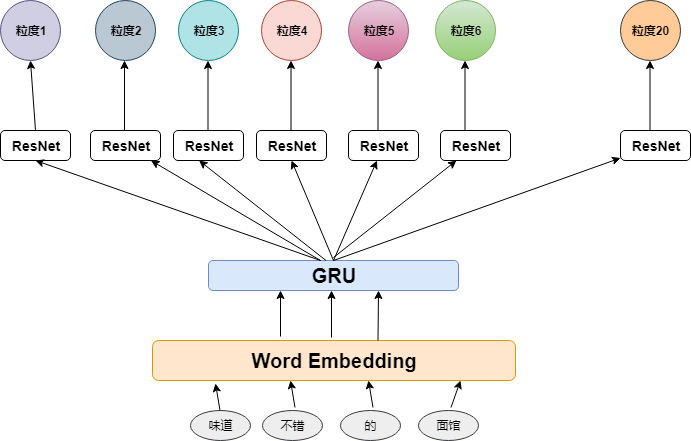
传统的基于神经网络的研究方法主要依赖于无监督训练的词向量,但这些词向量无法准确体现上下文语境关系;常用于处理情感分析问题的循环神经网络(RNN),模型参数众多,训练难度较大。为解决上述问题,这里用基于迁移学习的分层注意力神经网络(TLHANN)的情感分析算法。首先利用机器翻译任务训练一个用于在上下文中理解词语的编码器;然后,将这个编码器迁移到情感分析任务中,并将编码器输出的隐藏向量与无监督训练的词向量结合。在情感分析任务中,使用双向GRU,有效减少了参数个数,并引入了注意力机制提取重要信息。
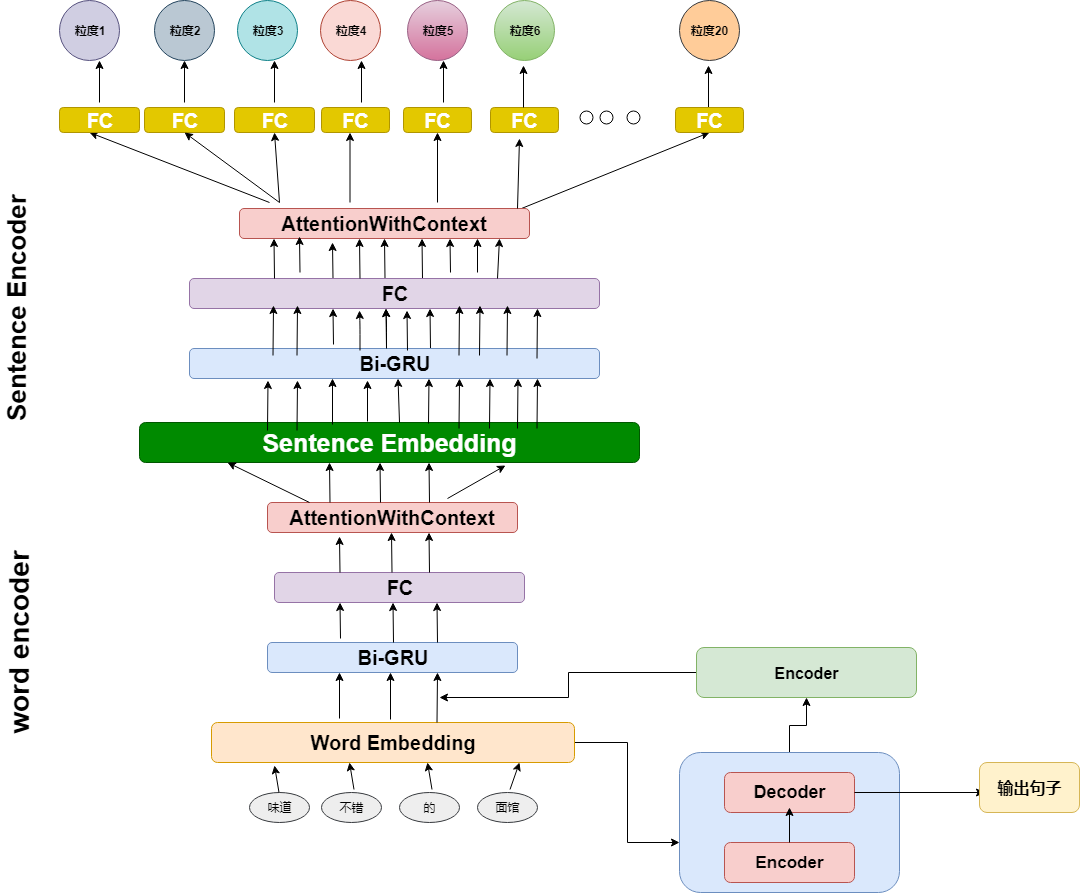
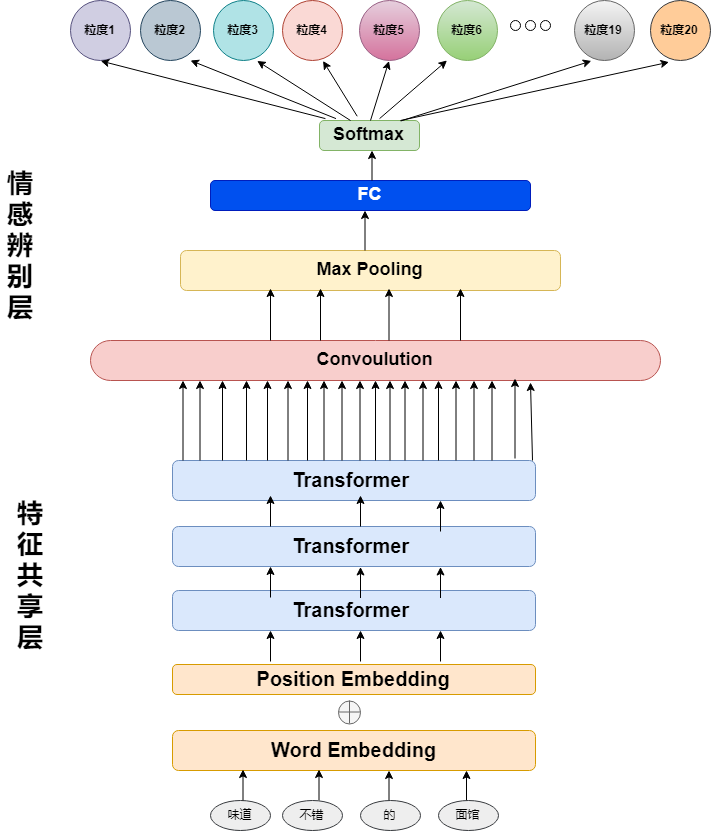
模型由参数共享的语句理解层和参数独立的情感辨别层
- 特征共享层:由1词向量层 + 1位置向量层(提供位置信息) + 3个Transformer Encoder 自注意力模块组成
- 情感辨别层:由1卷积层 + 1最大池化层 + 1全连接层组成
该模型的思路是模仿人处理该问题的行为:第一步理解语句(自注意力模块),第二步辨别情感(卷积+最大池化)
这里使用的是Encoder中的自注意力Transformer,自注意力Transformer Encoder对输入进行线性变换得到每个位置的query和(key, value)键值对,通过对query和key求点积来寻找与query最相关的key并对其结果使用softmax得到该键值对的权重。这个query的回答就是:sum(value * 对应权重),最后对这个query的回答进行维度缩(使用position-wise feed forword,即一维卷积,stride=1, 激活函数为relu),这样若有N个位置,得到N个query及其对应的回答
卷积层kernel的宽度为Transformer提取的Attention的维度大小,kernel的高度取10(即对临近的10个Attention进行卷积操作)。kernel的数量取64,最大池化的作用范围为整个feature map,即每个Kernel得到的feature map在经过最大池化后被提炼为一个值
使用opencc 将文件中的繁体转换成简体
opencc -i data/train/sentiment_analysis_trainingset.csv -o data/train/train_sc.csv -c t2s.json
opencc -i data/val/sentiment_analysis_validationset.csv -o data/val/val_sc.csv -c t2s.json
opencc -i data/test/a/sentiment_analysis_testa.csv -o data/test/a/a_sc.csv -c t2s.json
opencc -i data/test/b/sentiment_analysis_testb.csv -o data/test/b/b_sc.csv -c t2s.json
简体中文的词向量chinese word vectors 里的Word2vec / Skip-Gram with Negative Sampling,内容选择微博 (Word + Character + Ngram) 中文停用词使用此微博中文停用词库 (其中去除0-9)
分词使用的是jieba包, 主要先按词组拆分,如果词组不在词库(已去除停用词)中出现,再将该词组按字拆分, 因为考虑到项目为辨析情绪非翻译,考虑弱化语言结构,所以这里对未在词库中出现的新词不进行保留。
python preprocess_data.py --data_dir data/train
python preprocess_data.py --data_dir data/val
python preprocess_data.py -t --data_dir data/test/a
python preprocess_data.py -t --data_dir data/test/b
python main.py --model_dir output
python main.py -t --test_dir path/to/test/folder --model_dir output
对应文件: Preprocess_char.ipynb
使用的是char模型,所以不需要分词,用到的停用词也不多。比较粗暴,但是实测效果比 word level 好不少。
经过数据预处理,在 preprocess 文件夹下生成了 train_char.csv、test_char.csv、test_char.csv 三个文件。
比较简单,两层GRU之后接一个Attention层,起到加权平均的作用,然后和 avgpool、maxpool concat 到一块去,很直观的想法,kaggler的baseline。
import keras
from keras import Model
from keras.layers import *
from JoinAttLayer import Attention
class TextClassifier():
def model(self, embeddings_matrix, maxlen, word_index, num_class):
inp = Input(shape=(maxlen,))
encode = Bidirectional(CuDNNGRU(128, return_sequences=True))
encode2 = Bidirectional(CuDNNGRU(128, return_sequences=True))
attention = Attention(maxlen)
x_4 = Embedding(len(word_index) + 1,
embeddings_matrix.shape[1],
weights=[embeddings_matrix],
input_length=maxlen,
trainable=True)(inp)
x_3 = SpatialDropout1D(0.2)(x_4)
x_3 = encode(x_3)
x_3 = Dropout(0.2)(x_3)
x_3 = encode2(x_3)
x_3 = Dropout(0.2)(x_3)
avg_pool_3 = GlobalAveragePooling1D()(x_3)
max_pool_3 = GlobalMaxPooling1D()(x_3)
attention_3 = attention(x_3)
x = keras.layers.concatenate([avg_pool_3, max_pool_3, attention_3], name="fc")
x = Dense(num_class, activation="sigmoid")(x)
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08,amsgrad=True)
model = Model(inputs=inp, outputs=x)
model.compile(
loss='categorical_crossentropy',
optimizer=adam)
return model和第一个模型不同的地方在于,在RNN之后加了一层CNN对n-gram信息进行抓取。
import keras
from keras import Model
from keras.layers import *
from JoinAttLayer import Attention
class TextClassifier():
def model(self, embeddings_matrix, maxlen, word_index, num_class):
inp = Input(shape=(maxlen,))
encode = Bidirectional(CuDNNGRU(128, return_sequences=True))
encode2 = Bidirectional(CuDNNGRU(128, return_sequences=True))
attention = Attention(maxlen)
x_4 = Embedding(len(word_index) + 1,
embeddings_matrix.shape[1],
weights=[embeddings_matrix],
input_length=maxlen,
trainable=True)(inp)
x_3 = SpatialDropout1D(0.2)(x_4)
x_3 = encode(x_3)
x_3 = Dropout(0.2)(x_3)
x_3 = encode2(x_3)
x_3 = Dropout(0.2)(x_3)
x_3 = Conv1D(64, kernel_size=3, padding="valid", kernel_initializer="glorot_uniform")(x_3)
x_3 = Dropout(0.2)(x_3)
avg_pool_3 = GlobalAveragePooling1D()(x_3)
max_pool_3 = GlobalMaxPooling1D()(x_3)
attention_3 = attention(x_3)
x = keras.layers.concatenate([avg_pool_3, max_pool_3, attention_3])
x = Dense(num_class, activation="sigmoid")(x)
adam = keras.optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
model = Model(inputs=inp, outputs=x)
model.compile(
loss='categorical_crossentropy',
optimizer=adam
)
return model参考链接:先读懂CapsNet架构然后用TensorFlow实现:全面解析Hinton提出的Capsule
import keras
from keras import Model
from keras.layers import *
from JoinAttLayer import Attention
def squash(x, axis=-1):
# s_squared_norm is really small
# s_squared_norm = K.sum(K.square(x), axis, keepdims=True) + K.epsilon()
# scale = K.sqrt(s_squared_norm)/ (0.5 + s_squared_norm)
# return scale * x
s_squared_norm = K.sum(K.square(x), axis, keepdims=True)
scale = K.sqrt(s_squared_norm + K.epsilon())
return x / scale
# A Capsule Implement with Pure Keras
class Capsule(Layer):
def __init__(self, num_capsule, dim_capsule, routings=3, kernel_size=(9, 1), share_weights=True,
activation='default', **kwargs):
super(Capsule, self).__init__(**kwargs)
self.num_capsule = num_capsule
self.dim_capsule = dim_capsule
self.routings = routings
self.kernel_size = kernel_size
self.share_weights = share_weights
if activation == 'default':
self.activation = squash
else:
self.activation = Activation(activation)
def build(self, input_shape):
super(Capsule, self).build(input_shape)
input_dim_capsule = input_shape[-1]
if self.share_weights:
self.W = self.add_weight(name='capsule_kernel',
shape=(1, input_dim_capsule,
self.num_capsule * self.dim_capsule),
# shape=self.kernel_size,
initializer='glorot_uniform',
trainable=True)
else:
input_num_capsule = input_shape[-2]
self.W = self.add_weight(name='capsule_kernel',
shape=(input_num_capsule,
input_dim_capsule,
self.num_capsule * self.dim_capsule),
initializer='glorot_uniform',
trainable=True)
def call(self, u_vecs):
if self.share_weights:
u_hat_vecs = K.conv1d(u_vecs, self.W)
else:
u_hat_vecs = K.local_conv1d(u_vecs, self.W, [1], [1])
batch_size = K.shape(u_vecs)[0]
input_num_capsule = K.shape(u_vecs)[1]
u_hat_vecs = K.reshape(u_hat_vecs, (batch_size, input_num_capsule,
self.num_capsule, self.dim_capsule))
u_hat_vecs = K.permute_dimensions(u_hat_vecs, (0, 2, 1, 3))
# final u_hat_vecs.shape = [None, num_capsule, input_num_capsule, dim_capsule]
b = K.zeros_like(u_hat_vecs[:, :, :, 0]) # shape = [None, num_capsule, input_num_capsule]
for i in range(self.routings):
b = K.permute_dimensions(b, (0, 2, 1)) # shape = [None, input_num_capsule, num_capsule]
c = K.softmax(b)
c = K.permute_dimensions(c, (0, 2, 1))
b = K.permute_dimensions(b, (0, 2, 1))
outputs = self.activation(K.batch_dot(c, u_hat_vecs, [2, 2]))
if i < self.routings - 1:
b = K.batch_dot(outputs, u_hat_vecs, [2, 3])
return outputs
def compute_output_shape(self, input_shape):
return (None, self.num_capsule, self.dim_capsule)
class TextClassifier():
def model(self, embeddings_matrix, maxlen, word_index, num_class):
input1 = Input(shape=(maxlen,))
embed_layer = Embedding(len(word_index) + 1,
embeddings_matrix.shape[1],
input_length=maxlen,
weights=[embeddings_matrix],
trainable=True)(input1)
embed_layer = SpatialDropout1D(0.28)(embed_layer)
x = Bidirectional(
CuDNNGRU(128, return_sequences=True))(
embed_layer)
x = Activation('relu')(x)
x = Dropout(0.25)(x)
x = Bidirectional(
CuDNNGRU(128, return_sequences=True))(
x)
x = Activation('relu')(x)
x = Dropout(0.25)(x)
capsule = Capsule(num_capsule=10, dim_capsule=16, routings=5,
share_weights=True)(x)
# output_capsule = Lambda(lambda x: K.sqrt(K.sum(K.square(x), 2)))(capsule)
capsule = Flatten()(capsule)
capsule = Dropout(0.25)(capsule)
output = Dense(num_class, activation='sigmoid')(capsule)
model = Model(inputs=input1, outputs=output)
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=["categorical_accuracy"])
return model针对本赛题,分成20个模型分别来训练的话,其实 loss function 设置为 categorical crossentropy 或者 binary crossentropy 都可以。这两个损失函数的区别,categorical crossentropy 用来做多分类问题,binary crossentropy 用来做多标签分类问题。
需要注意的是,metric 的设置,如果我们在训练中设置 metric 的话,其实得到是每个 batch 的 f-score 值(非常不靠谱),所以我们需要在每个 epoch 结束之后去计算模型的 f-score 值,这样方便我们去掌握模型的训练情况。
类似这样
def getClassification(arr):
arr = list(arr)
if arr.index(max(arr)) == 0:
return -2
elif arr.index(max(arr)) == 1:
return -1
elif arr.index(max(arr)) == 2:
return 0
else:
return 1
class Metrics(Callback):
def on_train_begin(self, logs={}):
self.val_f1s = []
self.val_recalls = []
self.val_precisions = []
def on_epoch_end(self, epoch, logs={}):
val_predict = list(map(getClassification, self.model.predict(self.validation_data[0])))
val_targ = list(map(getClassification, self.validation_data[1]))
_val_f1 = f1_score(val_targ, val_predict, average="macro")
_val_recall = recall_score(val_targ, val_predict, average="macro")
_val_precision = precision_score(val_targ, val_predict, average="macro")
self.val_f1s.append(_val_f1)
self.val_recalls.append(_val_recall)
self.val_precisions.append(_val_precision)
print(_val_f1, _val_precision, _val_recall)
print("max f1")
print(max(self.val_f1s))
return
early_stop,顾名思义,就是在训练模型的时候,当在验证集上效果不再提升的时候,就提前停止训练,节约时间。通过设置 patience 来调节。
这个 class weight 是我一直觉得比较玄学的地方,一般而言,当数据集样本不均衡的时候,通过设置正负样本权重,可以提高一些效果,但是在这道题目里面,我对4个类别分别设置了class_weight 之后,我发现效果竟然变得更差了。
参考:http://zangbo.me/2017/07/01/TensorFlow_6/、指数滑动平均(ExponentialMovingAverage)EMA - 年轻即出发, - CSDN博客
EMA 应该有不少同学听过,它被广泛的应用在深度学习的BN层中,RMSprop,adadelta,adam等梯度下降方法中。
它添加了训练参数的影子副本,并保持了其影子副本中训练参数的移动平均值操作。在每次训练之后调用此操作,更新移动平均值。
加了 EMA 之后,能够有效的防止参数更新过快,起到了一种类似 bagging 的作用吧。
在训练模型的时候,我们可以使用动态衰减的学习率,来避免模型停留在局部最优。
我个人的经验如下:
- 以默认学习率 (0.001) 将模型迭代足够多次,保留验证正确率最高的模型;
- 加载上一步最优模型,学习率降到 0.0001,继续训练模型,保留验证正确率最高的模型;
- 加载上一步最优模型,去掉正则化策略(dropout 等),学习率调为0.00001,训练至最优。
这个看似不重要,其实确实很重要的点。一开我以为 padding 的最大长度取整个评论平均的长度的2倍差不多就可以啦(对于char level 而言,max_length 取 400左右),但是会发现效果上不去,当时将 max_length 改为 1000 之后,macro f-score提示明显,我个人认为是在多分类问题中,那些长度很长的评论可能会有部分属于那些样本数很少的类别,padding过短会导致这些长评论无法被正确划分。