| page_type | languages | name | description | products | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
sample |
|
Microsoft Cognitive Services Speech SDK Samples |
Learn how to use the Microsoft Cognitive Services Speech SDK to add speech-enabled features to your apps. |
|
This project hosts the samples for the Microsoft Cognitive Services Speech SDK. To find out more about the Microsoft Cognitive Services Speech SDK itself, please visit the SDK documentation site.
Please check here for release notes and older releases.
This repository hosts samples that help you to get started with several features of the SDK. In addition more complex scenarios are included to give you a head-start on using speech technology in your application.
We tested the samples with the latest released version of the SDK on Windows 10, Linux (on supported Linux distributions and target architectures), Android devices (API 23: Android 6.0 Marshmallow or higher), Mac x64 (OS version 10.14 or higher) and Mac M1 arm64 (OS version 11.0 or higher) and iOS 11.4 devices.
The SDK documentation has extensive sections about getting started, setting up the SDK, as well as the process to acquire the required subscription keys. You will need subscription keys to run the samples on your machines, you therefore should follow the instructions on these pages before continuing.
-
The easiest way to use these samples without using Git is to download the current version as a ZIP file.
- On Windows, before you unzip the archive, right-click it, select Properties, and then select Unblock.
- Be sure to unzip the entire archive, and not just individual samples.
-
Clone this sample repository using a Git client.
Note: the samples make use of the Microsoft Cognitive Services Speech SDK. By downloading the Microsoft Cognitive Services Speech SDK, you acknowledge its license, see Speech SDK license agreement.
Please see the description of each individual sample for instructions on how to build and run it.
-
Azure-Samples/Cognitive-Services-Voice-Assistant - Additional samples and tools to help you build an application that uses Speech SDK's DialogServiceConnector for voice communication with your Bot-Framework bot or Custom Command web application.
-
microsoft/cognitive-services-speech-sdk-js - JavaScript implementation of Speech SDK
-
Microsoft/cognitive-services-speech-sdk-go - Go implementation of Speech SDK
-
Azure-Samples/Speech-Service-Actions-Template - Template to create a repository to develop Azure Custom Speech models with built-in support for DevOps and common software engineering practices
The following quickstarts demonstrate how to perform one-shot speech recognition using a microphone. If you want to build them from scratch, please follow the quickstart or basics articles on our documentation page.
| Quickstart | Platform | Description |
|---|---|---|
| Quickstart C++ for Linux | Linux | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C++ for Windows | Windows | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C++ for macOS | macOS | |
| Quickstart C# .NET for Windows | Windows | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C# .NET Core | Windows, Linux, macOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C# UWP for Windows | Windows | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart C# Unity (Windows or Android) | Windows, Android | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart for Android | Android | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Java JRE | Windows, Linux, macOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart JavaScript | Web | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Node.js | Node.js | Demonstrates one-shot speech recognition from a file. |
| Quickstart Python | Windows, Linux, macOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Objective-C iOS | iOS | Demonstrates one-shot speech recognition from a file with recorded speech. |
| Quickstart Swift iOS | iOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Objective-C macOS | macOS | Demonstrates one-shot speech recognition from a microphone. |
| Quickstart Swift macOS | macOS | Demonstrates one-shot speech recognition from a microphone. |
The following quickstarts demonstrate how to perform one-shot speech translation using a microphone. If you want to build them from scratch, please follow the quickstart or basics articles on our documentation page.
| Quickstart | Platform | Description |
|---|---|---|
| Quickstart C++ for Windows | Windows | Demonstrates one-shot speech translation/transcription from a microphone. |
| Quickstart C# .NET Framework for Windows | Windows | Demonstrates one-shot speech translation/transcription from a microphone. |
| Quickstart C# .NET Core | Windows, Linux, macOS | Demonstrates one-shot speech translation/transcription from a microphone. |
| Quickstart C# UWP for Windows | Windows | Demonstrates one-shot speech translation/transcription from a microphone. |
| Quickstart Java JRE | Windows, Linux, macOS | Demonstrates one-shot speech translation/transcription from a microphone. |
The following quickstarts demonstrate how to perform one-shot speech synthesis to a speaker. If you want to build them from scratch, please follow the quickstart or basics articles on our documentation page.
| Quickstart | Platform | Description |
|---|---|---|
| Quickstart C++ for Linux | Linux | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C++ for Windows | Windows | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C++ for macOS | macOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C# .NET for Windows | Windows | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C# UWP for Windows | Windows | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart C# .NET Core | Windows, Linux | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart for C# Unity (Windows or Android) | Windows, Android | Demonstrates one-shot speech synthesis to a synthesis result and then rendering to the default speaker. |
| Quickstart for Android | Android | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Java JRE | Windows, Linux, macOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Python | Windows, Linux, macOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Objective-C iOS | iOS | Demonstrates one-shot speech synthesis to a synthesis result and then rendering to the default speaker. |
| Quickstart Swift iOS | iOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Objective-C macOS | macOS | Demonstrates one-shot speech synthesis to the default speaker. |
| Quickstart Swift macOS | macOS | Demonstrates one-shot speech synthesis to the default speaker. |
The following quickstarts demonstrate how to create a custom Voice Assistant. The applications will connect to a previously authored bot configured to use the Direct Line Speech channel, send a voice request, and return a voice response activity (if configured). If you want to build these quickstarts from scratch, please follow the quickstart or basics articles on our documentation page.
See also Azure-Samples/Cognitive-Services-Voice-Assistant for full Voice Assistant samples and tools.
| Quickstart | Platform | Description |
|---|---|---|
| Quickstart Java JRE | Windows, Linux, macOS | Demonstrates speech recognition through the DialogServiceConnector and receiving activity responses. |
| Quickstart C# UWP for Windows | Windows | Demonstrates speech recognition through the DialogServiceConnector and receiving activity responses. |
The following samples demonstrate additional capabilities of the Speech SDK, such as additional modes of speech recognition as well as intent recognition and translation. Voice Assistant samples can be found in a separate GitHub repo.
| Sample | Platform | Description |
|---|---|---|
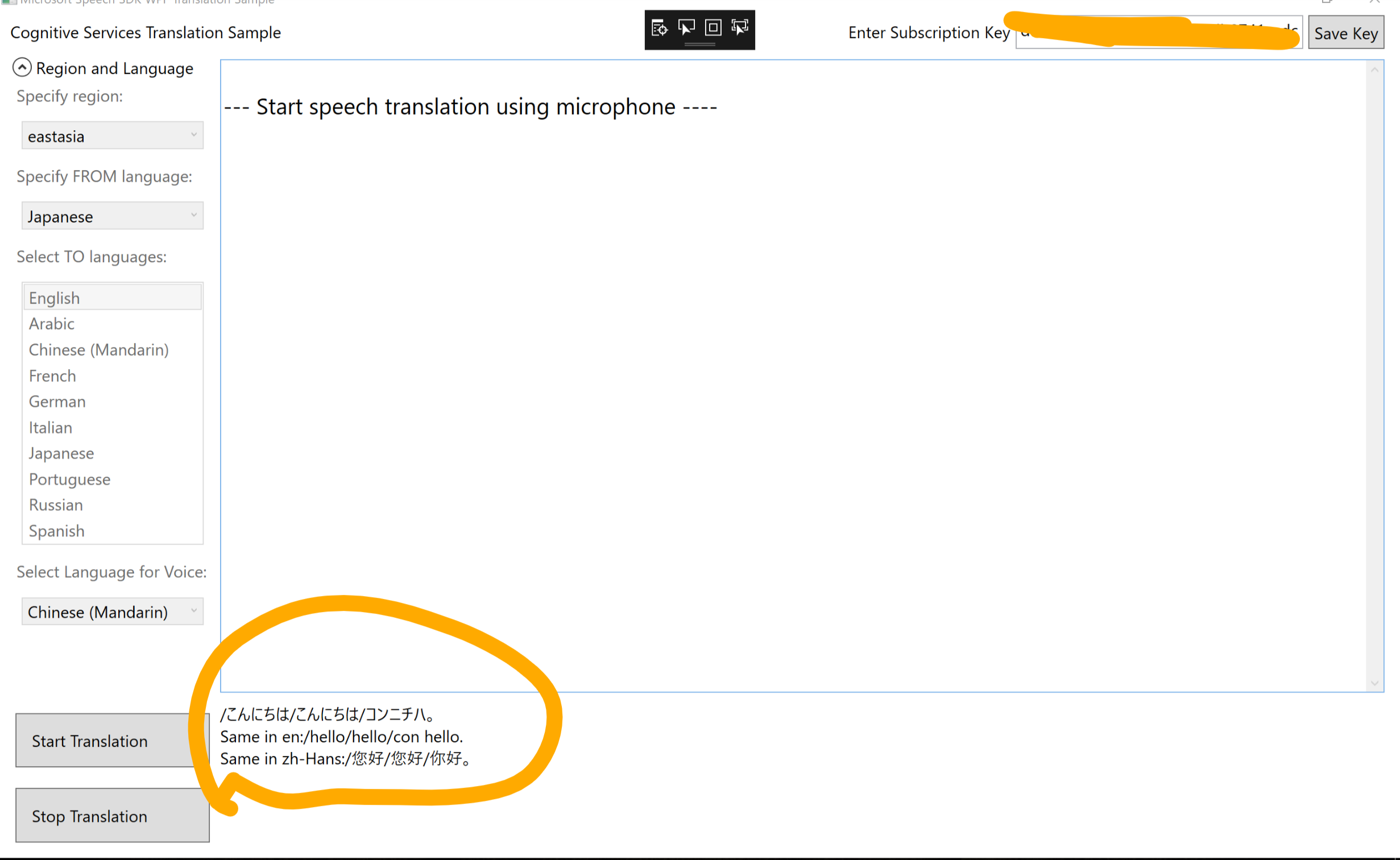
| C++ Console app for Windows | Windows | Demonstrates speech recognition, speech synthesis, intent recognition, conversation transcription and translation |
| C++ Speech Recognition from MP3/Opus file (Linux only) | Linux | Demonstrates speech recognition from an MP3/Opus file |
| C# Console app for .NET Framework on Windows | Windows | Demonstrates speech recognition, speech synthesis, intent recognition, and translation |
| C# Console app for .NET Core (Windows or Linux) | Windows, Linux, macOS | Demonstrates speech recognition, speech synthesis, intent recognition, and translation |
| Java Console app for JRE | Windows, Linux, macOS | Demonstrates speech recognition, speech synthesis, intent recognition, and translation |
| Python Console app | Windows, Linux, macOS | Demonstrates speech recognition, speech synthesis, intent recognition, and translation |
| Speech-to-text UWP sample | Windows | Demonstrates speech recognition |
| Text-to-speech UWP sample | Windows | Demonstrates speech synthesis |
| Speech recognition sample for Android | Android | Demonstrates speech and intent recognition |
| Speech recognition, synthesis, and translation sample for the browser, using JavaScript | Web | Demonstrates speech recognition, intent recognition, and translation |
| Speech recognition and translation sample using JavaScript and Node.js | Node.js | Demonstrates speech recognition, intent recognition, and translation |
| Speech recognition sample for iOS using a connection object | iOS | Demonstrates speech recognition |
| Extended speech recognition sample for iOS | iOS | Demonstrates speech recognition using streams etc. |
| Speech synthesis sample for iOS | iOS | Demonstrates speech synthesis using streams etc. |
| C# UWP DialogServiceConnector sample for Windows | Windows | Demonstrates speech recognition through the DialogServiceConnector and receiving activity responses. |
| C# Unity sample for Windows or Android | Windows, Android | Demonstrates speech recognition, intent recognition, and translation for Unity |
| C# Unity SpeechBotConnector sample for Windows or Android | Windows, Android | Demonstrates speech recognition through the SpeechBotConnector and receiving activity responses. |
| C#, C++ and Java DialogServiceConnector samples | Windows, Linux, Android | Additional samples and tools to help you build an application that uses Speech SDK's DialogServiceConnector for voice communication with your Bot-Framework Bot or Custom Command web application. |
Samples for using the Speech Service REST API (no Speech SDK installation required):
| Sample | Description |
|---|---|
| Batch transcription | Demonstrates usage of batch transcription from different programming languages |
| Batch synthesis | Demonstrates usage of batch synthesis from different programming languages |
| Custom voice | Demonstrates usage of custom voice from different programming languages |
| Tool | Platform | Description |
|---|---|---|
| Enumerate audio devices | C++, Windows | Shows how to get the Device ID of all connected microphones and loudspeakers. Device ID is required if you want to listen via non-default microphone (Speech Recognition), or play to a non-default loudspeaker (Text-To-Speech) using Speech SDK |
| Enumerate audio devices | C# .NET Framework, Windows | -"- |






![dependabot[bot] avatar](https://avatars.githubusercontent.com/in/29110?v=4 "dependabot[bot]")




















































































































































































































{kind=link}
{kind=link}