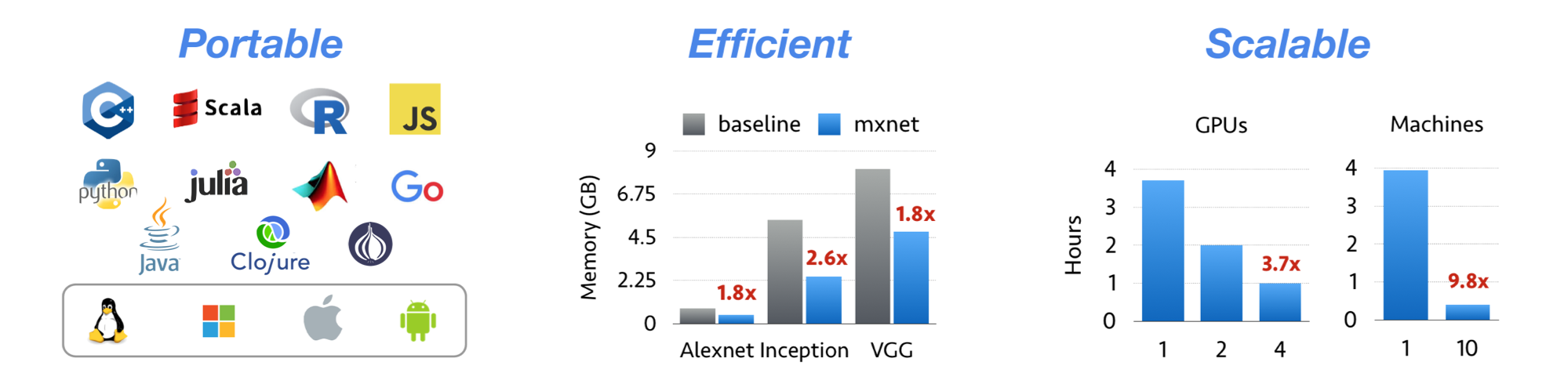










Apache MXNet is a deep learning framework designed for both efficiency and flexibility. It allows you to mix symbolic and imperative programming to maximize efficiency and productivity. At its core, MXNet contains a dynamic dependency scheduler that automatically parallelizes both symbolic and imperative operations on the fly. A graph optimization layer on top of that makes symbolic execution fast and memory efficient. MXNet is portable and lightweight, scalable to many GPUs and machines.
Apache MXNet is more than a deep learning project. It is a community on a mission of democratizing AI. It is a collection of blue prints and guidelines for building deep learning systems, and interesting insights of DL systems for hackers.
Licensed under an Apache-2.0 license.
| Branch | Build Status |
|---|---|
| master | |
| v1.x |
- NumPy-like programming interface, and is integrated with the new, easy-to-use Gluon 2.0 interface. NumPy users can easily adopt MXNet and start in deep learning.
- Automatic hybridization provides imperative programming with the performance of traditional symbolic programming.
- Lightweight, memory-efficient, and portable to smart devices through native cross-compilation support on ARM, and through ecosystem projects such as TVM, TensorRT, OpenVINO.
- Scales up to multi GPUs and distributed setting with auto parallelism through ps-lite, Horovod, and BytePS.
- Extensible backend that supports full customization, allowing integration with custom accelerator libraries and in-house hardware without the need to maintain a fork.
- Support for Python, Java, C++, R, Scala, Clojure, Go, Javascript, Perl, and Julia.
- Cloud-friendly and directly compatible with AWS and Azure.
- 1.9.1 Release - MXNet 1.9.1 Release.
- 1.8.0 Release - MXNet 1.8.0 Release.
- 1.7.0 Release - MXNet 1.7.0 Release.
- 1.6.0 Release - MXNet 1.6.0 Release.
- 1.5.1 Release - MXNet 1.5.1 Patch Release.
- 1.5.0 Release - MXNet 1.5.0 Release.
- 1.4.1 Release - MXNet 1.4.1 Patch Release.
- 1.4.0 Release - MXNet 1.4.0 Release.
- 1.3.1 Release - MXNet 1.3.1 Patch Release.
- 1.3.0 Release - MXNet 1.3.0 Release.
- 1.2.0 Release - MXNet 1.2.0 Release.
- 1.1.0 Release - MXNet 1.1.0 Release.
- 1.0.0 Release - MXNet 1.0.0 Release.
- 0.12.1 Release - MXNet 0.12.1 Patch Release.
- 0.12.0 Release - MXNet 0.12.0 Release.
- 0.11.0 Release - MXNet 0.11.0 Release.
- Apache Incubator - We are now an Apache Incubator project.
- 0.10.0 Release - MXNet 0.10.0 Release.
- 0.9.3 Release - First 0.9 official release.
- 0.9.1 Release (NNVM refactor) - NNVM branch is merged into master now. An official release will be made soon.
- 0.8.0 Release
- oneDNN for Faster CPU Performance
- MXNet Memory Monger, Training Deeper Nets with Sublinear Memory Cost
- Tutorial for NVidia GTC 2016
- MXNet.js: Javascript Package for Deep Learning in Browser (without server)
- Guide to Creating New Operators (Layers)
- Go binding for inference
| Channel | Purpose |
|---|---|
| Follow MXNet Development on Github | See what's going on in the MXNet project. |
| MXNet Confluence Wiki for Developers | MXNet developer wiki for information related to project development, maintained by contributors and developers. To request write access, send an email to send request to the dev list . |
| [email protected] mailing list | The "dev list". Discussions about the development of MXNet. To subscribe, send an email to [email protected] . |
| discuss.mxnet.io | Asking & answering MXNet usage questions. |
| Apache Slack #mxnet Channel | Connect with MXNet and other Apache developers. To join the MXNet slack channel send request to the dev list . |
| Follow MXNet on Social Media | Get updates about new features and events. |
Keep connected with the latest MXNet news and updates.
 Apache MXNet on Twitter
Apache MXNet on Twitter
 Contributor and user blogs about MXNet
Contributor and user blogs about MXNet
 Discuss MXNet on r/mxnet
Discuss MXNet on r/mxnet Apache MXNet YouTube channel
Apache MXNet YouTube channel Apache MXNet on LinkedIn
Apache MXNet on LinkedInMXNet emerged from a collaboration by the authors of cxxnet, minerva, and purine2. The project reflects what we have learned from the past projects. MXNet combines aspects of each of these projects to achieve flexibility, speed, and memory efficiency.
Tianqi Chen, Mu Li, Yutian Li, Min Lin, Naiyan Wang, Minjie Wang, Tianjun Xiao, Bing Xu, Chiyuan Zhang, and Zheng Zhang. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. In Neural Information Processing Systems, Workshop on Machine Learning Systems, 2015




































































































































































































































{kind=link}