More and more text data are becoming available these days to train Natural Language Processing models such as sentiment analysis, predictive keyboards and question-answering chatbots. If companies that deploy such models use data provided by users, they have a responsibility to take steps to ensure their users' privacy.
In this solution we demonstrate how one can use Differential Privacy to build accurate natural language processing models to meet business goals, while helping protect the privacy of the individuals in the data.
We will be using an algorithm, created by Amazon scientists, Feyisetan et al., that customers can use to better preserve the privacy of their users when analyzing large-scale text data.
You will need an AWS account to use this solution. Sign up for an account here.
To run this JumpStart 1P Solution and have the infrastructure deploy to your AWS account you will need to create an active SageMaker Studio instance (see Onboard to Amazon SageMaker Studio). When your Studio instance is Ready, use the instructions in SageMaker JumpStart to 1-Click Launch the solution.
The solution artifacts are included in this GitHub repository for reference.
Note: Solutions are available in most regions including us-west-2, and us-east-1.
Caution: Cloning this GitHub repository and running the code manually could lead to unexpected issues! Use the AWS CloudFormation template. You'll get an Amazon SageMaker Notebook instance that's been correctly setup and configured to access the other resources in the solution.
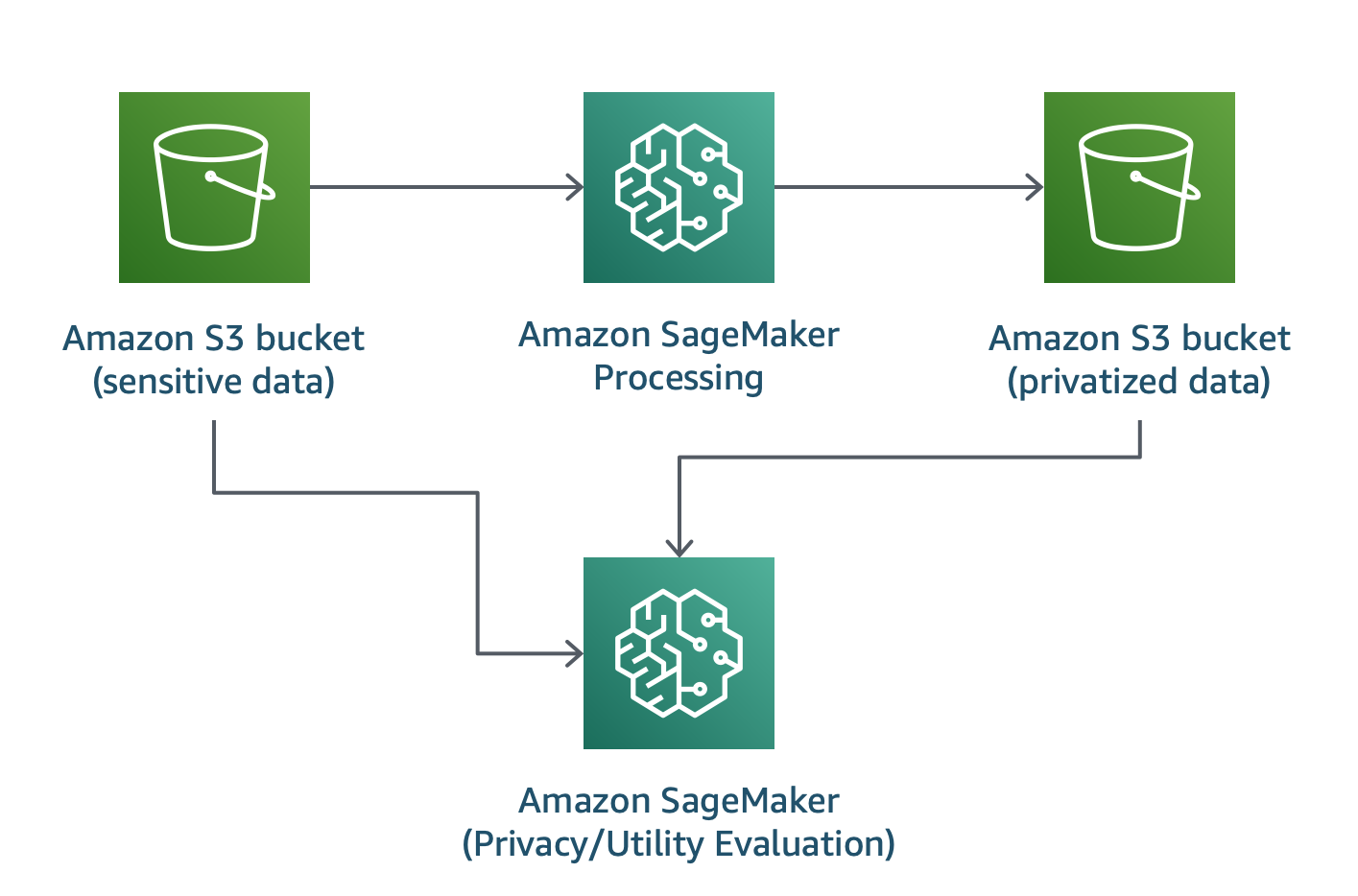
deployment/sagemaker-privacy-for-nlp.yaml: The CloudFormation template that is used to launch the solution.
test/:Contains files that are used to automatically test the solution.source/sagemaker/:package/config.py: Stores and retrieves project configuration.utils.py: Utility functions for scripts and/or notebooks.container_build/container_build.py: Python code to trigger container builds through AWS CodeBuild.logs.py: Used to create logs for the container build.
data_privatization/container/: Contains the Docker container definition for running the privatization on one worker.data_privatization.py: The code used to apply the privatization mechanism.region-to-account.json: JSON mapping of AWS region to account used for the Amazon SageMaker Processing Apache Spark container.get_sm_account.py: Simple python script to read the JSON mapping
model/inference.py: Contains the inference code used to evaluate the trained models.requirements.txt: A file that defines the libraries needed to execute the privatization and inference using Amazon SageMaker Processing.train.py: Contains the code used to train a model using Torchtext in Amazon SageMaker Training.
1._Data_Privatization.ipynb: The first notebook, used to demonstrate and run the privatization mechanism.2._Model_Training.ipynb: The second notebook, used to train and compare two models trained on sensitive and privatized data, that were generated using the first notebook.requirements.txt: A file that defines the libraries needed to execute the notebooks.setup.py: Definition file of the package used in the solution.
Differential Privacy (DP) is a formalized notion of privacy that helps protect the privacy of individuals in a database against attackers who try to re-identify them. It was originally proposed by Dwork et al. and has since become the gold standard for privacy protection across both industry and academia. Amongst many other deployments, the 2020 US census is using differential privacy so that the data "from individuals and individual households remain confidential".
Specifically, a differentially private mechanism provides a probabilistic guarantee that given two datasets that only differ in the presence of a single individual in the datasets, the probability that the outcome of a query was produced from either dataset is roughly equal.
In other words, regardless of the response to a statistical query, an attacker cannot be certain that any single individual's data were used in the calculation of the result.
Differential Privacy (DP) is commonly achieved by introducing a carefully designed amount of noise into the results of statistical queries to a database. For example, a query to a database could be "what is the number of individuals with an income above $45,000 who reside in Seattle, WA".
Every time such a query is executed, a differentially private mechanism will inject some noise into the result and return the noisy result.
Machine Learning models work by learning to associate inputs to outputs from large data sources. If the data sources contain sensitive data, it may be possible to use the trained model to extract information about the individuals whose data were used to train the machine learning model.
Researchers have been able to perform membership inference attacks on black-box models, without having access to the data or model internals, by querying the public-facing API of a model. The researchers were able to reveal information about individuals' presence in sensitive datasets, such as a hospital discharge dataset, or infer whether a particular users' text data were used to train an NLP model.
These attacks illustrate the need to implement privacy measures when training a model on sensitive user data and deploying the trained model to a wide audience.
The algorithm we will use was designed by Amazon's scientists as "a way to protect privacy during large-scale analyses of textual data supplied by customers".
It uses a variant of differential privacy known as metric differential privacy that works in metric spaces, such as the space of word embeddings. The idea of metric DP originated in privacy research for location services. Given a query such as, "show me restaurants around my location" the purpose is to give useful results to the user, without revealing their exact location to the service. The idea is again to add carefully crafted noise to the exact location of the user, and return results for the new noisy location.
This algorithm takes this idea and adapts it to the space of word embeddings. Given an input word, we want to perturb the input in a way that preserves the meaning or semantics of the word, while providing privacy for the user. It will inject noise to the embedding vector of the original word, then pick another word close to the resulting noisy vector to replace the original.
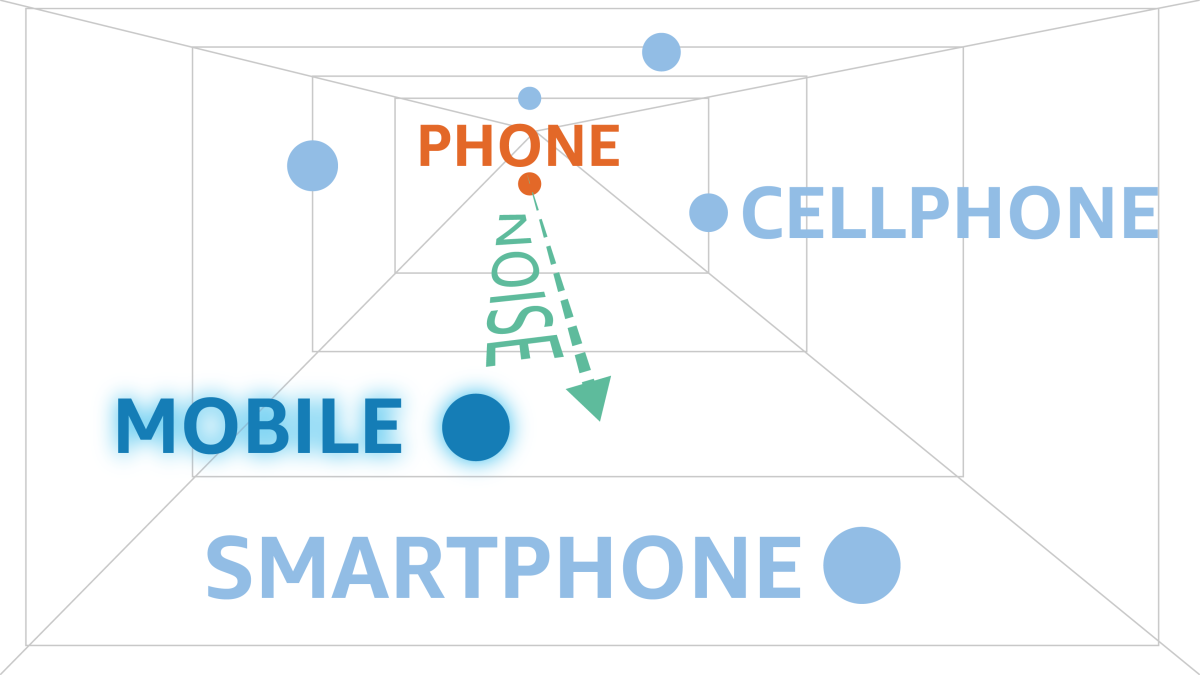
In the example above, the input word is "Phone". We inject noise to move away from the original word in the embedding space, and choose a new word whose position is closest to the new noisy vector, in this case "Mobile". This way we have preserved the meaning of the original word, while at the same time better protected the privacy of the individuals in the training dataset: if an attacker tries to reverse engineer a downstream model, they cannot be certain whether a specific word or sequence originated from an individual, or if it is the result of a perturbation.
- Feyisetan, Oluwaseyi, et al. "Privacy-and Utility-Preserving Textual Analysis via Calibrated Multivariate Perturbations." Proceedings of the 13th International Conference on Web Search and Data Mining. 2020. ArXiv Link.
- Blog post: Preserving privacy in analyses of textual data
This solution uses a subset of the Amazon Reviews - Polarity dataset, created by Xiang et al. [1] which itself is based on the Amazon Reviews Dataset by McAuley et al. [2]. The data are publicly available and hosted on the AWS Data Registry [3], on the behalf of fast.ai [4].
- Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 1 (NIPS’15). MIT Press, Cambridge, MA, USA, 649–657.
- J. McAuley and J. Leskovec. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM Conference on Recommender Systems, RecSys ’13, pages 165–172, New York, NY, USA, 2013. ACM.
- https://registry.opendata.aws/fast-ai-nlp/
- https://course.fast.ai/datasets#nlp
The solution also uses the pre-trained GloVe.6B vectors, created by Stanford NLP and released under the Open Data Commons Public Domain Dedication and License. The original publication is cited below:
Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. GloVe: Global Vectors for Word Representation. PDF Link
This project is licensed under the Amazon Software License.



