Authors: Dabi Ahn([email protected]), Kyubyong Park([email protected])
https://soundcloud.com/andabi/sets/voice-style-transfer-to-kate-winslet-with-deep-neural-networks
What if you could imitate a famous celebrity's voice or sing like a famous singer? This project started with a goal to convert someone's voice to a specific target voice. So called, it's voice style transfer. We worked on this project that aims to convert someone's voice to a famous English actress Kate Winslet's voice. We implemented a deep neural networks to achieve that and more than 2 hours of audio book sentences read by Kate Winslet are used as a dataset.

This is a many-to-one voice conversion system. The main significance of this work is that we could generate a target speaker's utterances without parallel data like <source's wav, target's wav>, <wav, text> or <wav, phone>, but only waveforms of the target speaker. (To make these parallel datasets needs a lot of effort.) All we need in this project is a number of waveforms of the target speaker's utterances and only a small set of <wav, phone> pairs from a number of anonymous speakers.
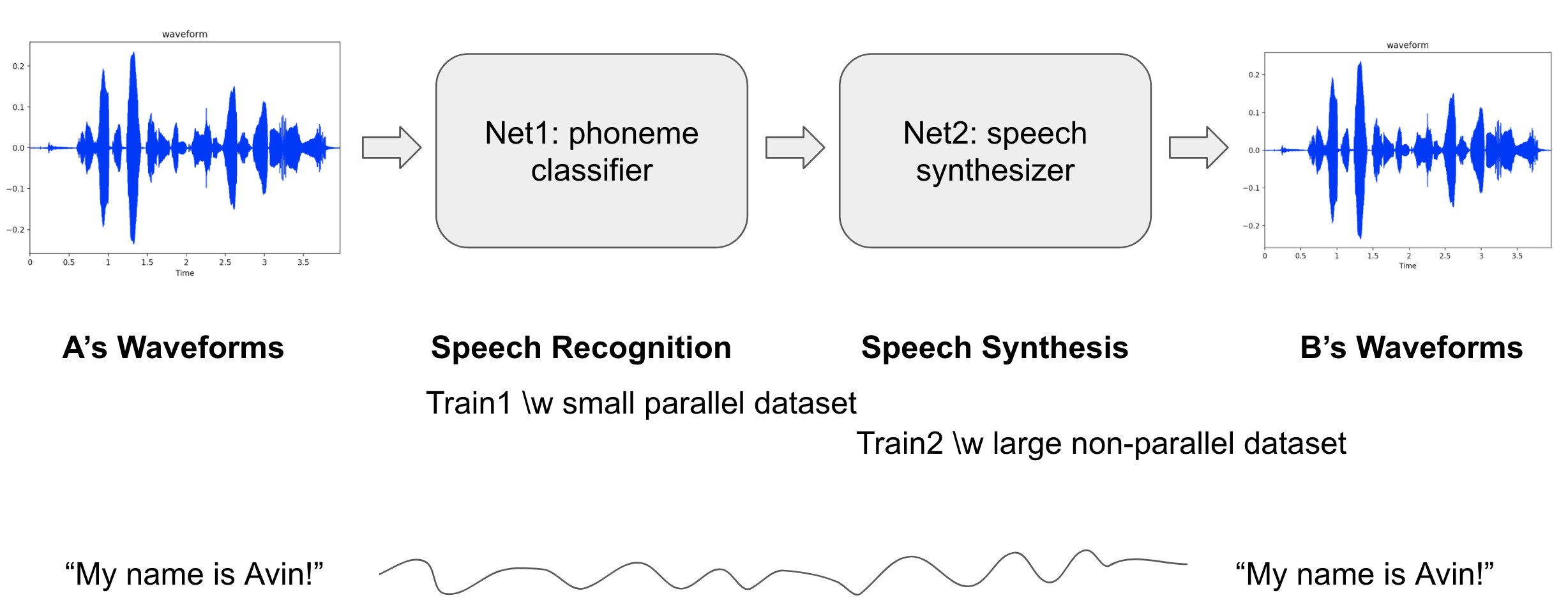
The model architecture consists of two modules:
- Net1(phoneme classification) classify someone's utterances to one of phoneme classes at every timestep.
- Phonemes are speaker-independent while waveforms are speaker-dependent.
- Net2(speech synthesis) synthesize speeches of the target speaker from the phones.
We applied CBHG(1-D convolution bank + highway network + bidirectional GRU) modules that are mentioned in Tacotron. CBHG is known to be good for capturing features from sequential data.
- Process: wav -> spectrogram -> mfccs -> phoneme dist.
- Net1 classifies spectrogram to phonemes that consists of 60 English phonemes at every timestep.
- For each timestep, the input is log magnitude spectrogram and the target is phoneme dist.
- Objective function is cross entropy loss.
- TIMIT dataset used.
- contains 630 speakers' utterances and corresponding phones that speaks similar sentences.
- Over 70% test accuracy
Net2 contains Net1 as a sub-network.
- Process: net1(wav -> spectrogram -> mfccs -> phoneme dist.) -> spectrogram -> wav
- Net2 synthesizes the target speaker's speeches.
- The input/target is a set of target speaker's utterances.
- Since Net1 is already trained in previous step, the remaining part only should be trained in this step.
- Loss is reconstruction error between input and target. (L2 distance)
- Datasets
- Target1(anonymous female): Arctic dataset (public)
- Target2(Kate Winslet): over 2 hours of audio book sentences read by her (private)
- Griffin-Lim reconstruction when reverting wav from spectrogram.
- python 2.7
- tensorflow >= 1.1
- numpy >= 1.11.1
- librosa == 0.5.1
- sample rate: 16,000Hz
- window length: 25ms
- hop length: 5ms
- Train phase: Net1 and Net2 should be trained sequentially.
- Train1(training Net1)
- Run
train1.pyto train andeval1.pyto test.
- Run
- Train2(training Net2)
- Run
train2.pyto train andeval2.pyto test.- Train2 should be trained after Train1 is done!
- Run
- Train1(training Net1)
- Convert phase: feed forward to Net2
- Run
convert.pyto get result samples. - Check Tensorboard's audio tab to listen the samples.
- Take a look at phoneme dist. visualization on Tensorboard's image tab.
- x-axis represents phoneme classes and y-axis represents timesteps
- the first class of x-axis means silence.
- Run

- Window length and hop length have to be small enough to be able to fit in only a phoneme.
- Obviously, sample rate, window length and hop length should be same in both Net1 and Net2.
- Before ISTFT(spectrogram to waveforms), emphasizing on the predicted spectrogram by applying power of 1.0~2.0 is helpful for removing noisy sound.
- It seems that to apply temperature to softmax in Net1 is not so meaningful.
- IMHO, the accuracy of Net1(phoneme classification) does not need to be so perfect.
- Net2 can reach to near optimal when Net1 accuracy is correct to some extent.
- "Phonetic posteriorgrams for many-to-one voice conversion without parallel data training", 2016 IEEE International Conference on Multimedia and Expo (ICME)
- "TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS", Submitted to Interspeech 2017























































































































































































































