algorithmica-org / algorithmica Goto Github PK
View Code? Open in Web Editor NEWA computer science textbook
Home Page: https://algorithmica.org/
A computer science textbook
Home Page: https://algorithmica.org/



























































































































































































https://en.algorithmica.org/hpc/cpu-cache/bandwidth/#frequency-scaling
**Unless** the dataset fits entirely in the cache, the relative performance of the two implementations may be different depending on the CPU clock rate because the RAM remains unaffected by it, while everything else does. Shouldn't this say If? The graph shows that clock rate doesn't matter when we reach RAM.
Not sure if the meaning of FLOPS has been extended in practice, or integer op throughput is tightly coupled to flops.
In this section, "higher" seem to mean "closest from CPU". As suggested by the pyramid picture and sentences like:
Modern CPUs have multiple layers of cache (L1, L2, often L3, and rarely even L4). The lowest layer is shared between cores and is usually scaled with their number (e.g., a 10-core CPU should have around 10M of L3 cache).
However, this logic seems to be reverted in the following?
When accessed, the contents of a cache line are emplaced onto the lowest cache layer and then gradually evicted to higher levels unless accessed again in time.
I cannot compile following example. If some complier flags are required, I think we should clarify that
gcc bench.c
bench.c:6:8: error: variably modified ‘a’ at file scope
6 | double a[n][n], b[n][n], c[n][n];
| ^
bench.c:6:8: error: variably modified ‘a’ at file scope
bench.c:6:17: error: variably modified ‘b’ at file scope
6 | double a[n][n], b[n][n], c[n][n];
| ^
bench.c:6:17: error: variably modified ‘b’ at file scope
bench.c:6:26: error: variably modified ‘c’ at file scope
6 | double a[n][n], b[n][n], c[n][n];
| ^
bench.c:6:26: error: variably modified ‘c’ at file scope
bench.c: In function ‘main’:
bench.c:23:21: error: expected expression before ‘float’
23 | float seconds = float(clock() - start) / CLOCKS_PER_SEC;
gcc --version
gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0
Since [0,1] is included in [0,infinity), even for floats, this statement cannot be true.
Hello! On this page:
https://en.algorithmica.org/hpc/architecture/functions/#calling-conventions
There is a section for calling conventions that has a link to a page about linkers on your website. This link is a 404
Link in question:
https://en.algorithmica.org/hpc/compilation/linking/
Differentiability is a very strong assumption. Although Newton’s method is widely used, there are so many optimization methods, that this statement seems improbable.
Hi,
I'm pretty sure I've found 3 misprints in the English SVGs on the AoS and SoA page.
https://github.com/algorithmica-org/algorithmica/blob/master/content/english/hpc/cpu-cache/img/aos-soa-padded-n.svg
array os structures -> array of structures
https://github.com/algorithmica-org/algorithmica/blob/master/content/english/hpc/cpu-cache/img/aos-soa-padded.svg
structure or arrays -> structure of arrays
https://github.com/algorithmica-org/algorithmica/blob/master/content/english/hpc/cpu-cache/img/aos-soa.svg
structure or arrays -> structure of arrays
I would fix them myself but when I opened the SVG files, I found out that all the text had been converted to paths so hopefully you guys can regenerate correct versions with matplotlib.
Also, I just wanted to say thanks for creating this free resource because I've learnt a lot from it. Wish you guys the best :)
https://github.com/algorithmica-org/algorithmica/blob/master/content/english/hpc/simd/masking.md claims that
// no branch:
for (int i = 0; i < N; i++)
s += (a[i] < 50) * a[i];
// also no branch:
for (int i = 0; i < N; i++)
s += (a[i] < 50 ? a[i] : 0);are both branchless, while I'm not sure about the first one, the 2nd one is definitely not branchless. (cond?true:false) is just syntactic sugar for if-then-else
The description of the insert sorting contains:
Когда это произойдет, это будет означать, что он будет больше всех элементов слева и меньше всех элементов префикса справа,
but the fragment of the algorithm contains the condition:
a[i - 1] < a[i], which is incorrect in terms of definition and sorts arrays in descending order.
I propose to change the font-family of the text to a more readable one on Windows systems. Or leave the old font, but as a fallback to a more readable font - for example Verdana (font-family: Verdana, crimson, serif;).
The existing solution in the form of "crimson" has some artifacts along the top line of the text.

It would also be great to slightly increase the font size of the text (font-size: 20px;)

In https://en.algorithmica.org/hpc/data-structures/segment-trees/:
int sum(int lq, int rq) {
if (rb <= lq && rb <= rq) // if we're fully inside the query, return the sum
return s;
if (rq <= lb || lq >= rb) // if we don't intersect with the query, return zero
return 0;
return l->sum(k) + r->sum(k);
}
should be (last line changed):
int sum(int lq, int rq) {
if (rb <= lq && rb <= rq) // if we're fully inside the query, return the sum
return s;
if (rq <= lb || lq >= rb) // if we don't intersect with the query, return zero
return 0;
return l->sum(lq, rq) + r->sum(lq, rq);
}
With real numbers, precisely addition and multiplication are associative and commutative. In contrast this is not the case for floating point numbers, and thus by extension not for the rounding error of these operations.
At least to me, this is quite unintuitive and an further explanation would be greatly appreciated.
Hello,
while it might be worth making the distinction between a programming languages and its implementation(s) or adding the garbage collection (protip: reference counting is also GC) distinction, this issue was prompted by reading the native/managed duality point immediately followed by the grouping of Python (cpython, I suppose) and JavaScript/Ruby (both being JiT compiled in their most popular and/or reference implementations) in the examples.
Even more confusingly, PyPy is mentioned a bit further.
Personally, when I have to use such categories, I use Interpreters, Bytecode compilers (aka VM) and Native compilers with JiT/AoT and GC/manual as possible additional differentiators.
PS: your work is amazing and very beginner friendly, I hope it'll help CS students smothered by theory and doing everything in Java/Python understand real world programming a bit more.
In https://github.com/algorithmica-org/algorithmica/blob/master/content/english/hpc/pipelining/hazards.md?plain=1#L15 you wrote:
The only way to resolve a hazard is to have a pipeline stall [...]
Though at least data hazards can often be resolved by using Scoreboarding or Tomasulo's algorithm, as you hint to later on in the text.
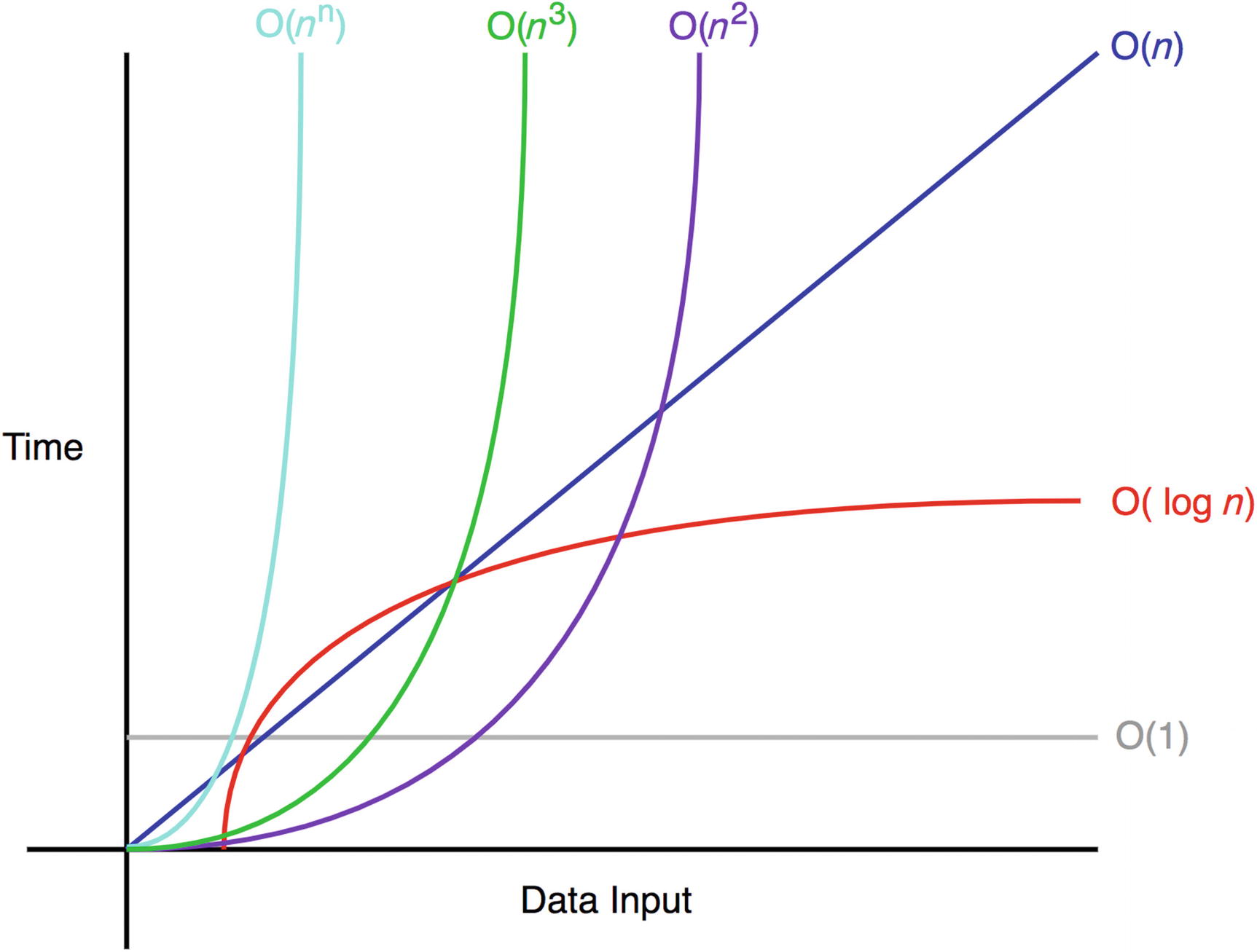
This picture can be confusing because the log curve is not starting at zero, and it becomes negative as the data input becomes small, which makes no sense. Maybe it's worth showing log(x+1) instead?
https://github.com/algorithmica-org/algorithmica/blob/master/content/english/hpc/arithmetic/float.md
Some comments explaining why we are shifting things around and what that does with one example would be very helpful. Or a link to some article/website that does that for common floating point operators.
Hello,
Not sure how you benchmarked the GCD code but on my laptop (with Intel(R) Core(TM) i7-10510U CPU @ 1.80GHz), std::gcd is significantly faster than the optimized binary GCD implementation. (Edit: I accidentally left my benchmark on a pathological test case instead... whoops.)
https://godbolt.org/z/3475szdz8
std::gcd 6.6 ms / 1048576 iterations = 6.294 nanoseconds
binary_gcd 23 ms / 1048576 iterations = 21.934 nanoseconds
Benchmark 1: ./std_gcd
Time (mean ± σ): 6.6 ms ± 0.7 ms [User: 6.2 ms, System: 0.6 ms]
Range (min … max): 6.1 ms … 9.3 ms 252 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet PC without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Benchmark 2: ./binary_gcd
Time (mean ± σ): 23.0 ms ± 1.7 ms [User: 22.6 ms, System: 0.6 ms]
Range (min … max): 22.3 ms … 30.4 ms 119 runs
Warning: Statistical outliers were detected. Consider re-running this benchmark on a quiet PC without any interferences from other programs. It might help to use the '--warmup' or '--prepare' options.
Summary
'./std_gcd' ran
3.35 ± 0.32 times faster than './binary_gcd'
Performance counter stats for './std_gcd':
11.17 msec task-clock:u # 0.969 CPUs utilized
0 context-switches:u # 0.000 /sec
0 cpu-migrations:u # 0.000 /sec
100 page-faults:u # 8.949 K/sec
30,609,505 cycles:u # 2.739 GHz
31,468,434 instructions:u # 1.03 insn per cycle
5,564,990 branches:u # 498.021 M/sec
8,829 branch-misses:u # 0.16% of all branches
0.011527144 seconds time elapsed
0.011597000 seconds user
0.000000000 seconds sys
Performance counter stats for './binary_gcd':
31.39 msec task-clock:u # 0.986 CPUs utilized
0 context-switches:u # 0.000 /sec
0 cpu-migrations:u # 0.000 /sec
98 page-faults:u # 3.122 K/sec
99,257,572 cycles:u # 3.162 GHz
235,231,331 instructions:u # 2.37 insn per cycle
18,247,030 branches:u # 581.359 M/sec
628,198 branch-misses:u # 3.44% of all branches
0.031830958 seconds time elapsed
0.031932000 seconds user
0.000000000 seconds sys
In this case, the Fenwick tree is not equivalent to a segment tree fo size
For numbers <2^64, not having factors <2^16 means that they have a roughly 1/2 chance of being prime. As such, it is worthwhile to perform a primality check. This can be done efficiently using Miller-Rabin with the bases (2, 325, 9375, 28178, 450775, 9780504, 1795265022) which have been proven to give the correct answer for all inputs <2^64. This can be done efficiently using Montgomery multiplication for the modular exponentiation, and runs in ~1us for prime inputs and ~350ns for composite inputs. This will have a somewhat notable affect on the time the algorithm takes, but makes it very easy to never give the wrong answer (which is somewhat messing with benchmarking since the cases where the current algorithm messes up tend to be the points that will take longer to factor anyway).
https://en.algorithmica.org/hpc/data-structures/s-tree/#b-tree-layout
The following criterion for B-tree keys is incomplete: "...each satisfying the property that all keys in the subtrees of the first i children are not greater than the i-th key in the parent node."
The criterion as written is met even if all keys in all subtrees are zero while all keys in the parent node are greater than zero.
What's missing is that the child keys must also be greater than (or not less than, depending on how one wants to define the B-tree) the 'previous' parent key. Or you might say that the keys in child node i must be between the parent keys i-1 and i. Or something like that. I can't think of a good wording right now...
The slowdown for randomized binary search versus the normal version is 2*log(2), about 1.386. Doesn't require much calculus in the end: the randomized time simplifies to twice the harmonic series, which has the well-known sum log(n) + O(1). Dividing by log2(n) causes the O(1) part to go to 0 (slowly), and log(n) / log2(n) is the constant log(2).
Flattening the recurrence, starting from your linear-time version:
# From random-binsearch.py
g[k] = (s[k - 1] * 2 / k / (k - 1) + 1) * k
= 2 * s[k - 1] / (k - 1) + k
s[k] = s[k - 1] + g[k]
# Substitute g
s[k] = s[k - 1] * (1 + 2 / (k - 1)) + k
= s[k - 1] * (k + 1) / (k - 1) + k
(s[k] / k) = s[k - 1] * (1 + 1 / k) / (k - 1) + 1
# Define r
r[k] = s[k] / k
r[k] = r[k - 1] * (1 + 1 / k) + 1
# Rewrite original g recurrence in f and r
f[k] * k = 2 * r[k - 1] + k
r[k - 1] = (f[k] - 1) * k / 2
# Substitute into r recurrence
(f[k + 1] - 1) * (k + 1) / 2 = (f[k] - 1) * k / 2 * (1 + 1 / k) + 1
= (f[k] - 1) * (k + 1) / 2 + 1
(f[k + 1] - 1) = (f[k] - 1) + 2 / (k + 1)
f[k + 1] = f[k] + 2 / (k + 1)
f[k] = f[k - 1] + 2 / kAnother, more complicated way to implement this whole sequence is to convert this sign bit into a mask and then use bitwise
andinstead of multiplication:((a[i] - 50) >> 31 - 1) & a[i].
First, in the C language the minus operation has higher priority than the >> operation, hence that code is equivalent to ((a[i] - 50) >> 30) & a[i] and thus is not consistent with the assembly language code shown below.
Second, as mentioned in Section 4.4, the result of the >> operation on negative integer depends on the implementation, which is not specified in Section 3.3. Let us consider the following 2 cases:
Case 1. If the leftmost bit is extended: then ((a[i]-50)>>31) is -1 when a[i]<50 (ignoring underflow) and is 0 when a[i]>=50. Therefore there is no need of the -1 after 31 at all.
Case 2. If the leftmost bit is filled with 0: Then (a[i] - 50) >> 31 does get the sign bit of a[i]-50. In this case, (((a[i] - 50) >> 31) - 1) is 0 when a[i]<50 and is -1 when a[i]>=50. This is the reverse of what we want here: We want a '-1' when 'a[i]<50' and a '0' when 'a[i]>=50'.
To sum up, I think this part is pretty confusing and need to be fixed.
We need more assumptions. The English wikipedia article has an extensive description.
It's 10 bytes. In practice, it usually consumes 16 bytes in a struct due to alignment requirements; 12 only comes up on 32-bit systems.
In most browsers Alt + Left arrow and Alt + Right arrow are used to go back and forward in page history.
These hotkeys don't work on Algorithmica. They are mixed up with Left arrow and Right arrow (navigation between pages).
https://en.algorithmica.org/hpc/arithmetic/float/
At the very bottom there is [the next section](https://en.algorithmica.org/hpc/arithmetic/float/ieee-754.md).
But the link should be https://en.algorithmica.org/hpc/arithmetic/ieee-754/
The sentence reads a little weird to me. I’m not a native English speaker though.
https://en.algorithmica.org/hpc/external-memory/sorting/#:~:text=std%3A%3Apriority_queue%3C%20std%3A%3Apair%3Cint%2C%20int%3E%20%3E%20q%3B
Either change to std::priority_queue<std::pair<int, int>, std::vector<std::pair<int, int>>, std::greater<std::pair<int, int>>>, or store the additive inverse of the key in the heap, you can also create a struct that overloads the less-than operator.
Condition is a property of the problem at hand, stability is a property of an algorithm used to solve it. An algorithm solving a problem can be stable only if the underlying problem is well-conditioned. On the other hand, even if a problem is well conditioned, an algorithm solving it may be unstable (A classic example is matrix inversion). This is important because the remedy to bad conditioning is modifying the problem, whereas if your algorithm suffers from instability, it’s finding another algorithm.
It's probably worth mentioning on https://en.algorithmica.org/hpc/arithmetic/rsqrt/ that most modern processors have an rsqrtss intrinsic that mostly makes this obsolete.
The code on the line "a >>= az, b >>= bz;" is incorrect, it should be "a >>= shift, b >>= shift;"
Similarly, in the final version "b >>= bz;" is incorrect, it should be "b >>= shift;"
--Laci
PS: I wanted to submit a patch and pull request, but when I tried to submit the edited the page I got an error:
"Error while loading data from Github. This might be a temporary issue. Please try again later."
But it never worked in the course of 3 days... So I'm submitting the bug as an issue.
https://en.algorithmica.org/hpc/external-memory/locality/#dynamic-programming
The state can be updated in O(1) time per entry **if consider** either taking or not taking the. There should probably be a "we" in there, but I'm not sure.
Also, the code examples seem to interchange w and c. Unless I'm missing something, those should be the same variable. In addition, it's confusing to talk about a constant w and then later use k for that.
Recursive algorithms that can't tail-call optimized can still be implemented without recursion by using an auxiliary work list (essentially replacing the call stack with a dynamically allocated array). It would be useful to see some discussion of the tradeoffs inherent in that approach.
Not a very compelling reason to why changing rounding mode is preferable to changing precision.
To estimate the real running time of a program, you need to sum all latencies for its executed instructions and multiply it by the clock frequency, that is, the number of cycles a particular CPU does per second.
This would mean that a higher clock frequency would cause the program to take longer to run rather than be quicker. This should rather be sum of latencies divided by clock frequency. Dimensionally, cycles * (cycles/second) gives us cycles^2/second whereas cycles * (seconds/cycles) gives us seconds.
I was reading on this page , and I wanted to go back to the home page, and I did hit on Algorithmica as shown in the photo below

which navigated me to the website: https://algorithmica.org/en/
showing the fellowing error:

I believe this is a simple fix, as the main english website is https://en.algorithmica.org instead of https://algorithmica.org/en
Although I can imagine which compiler you mean, it’s better to write it out.
https://github.com/algorithmica-org/algorithmica/blob/master/content/english/hpc/arithmetic/rsqrt.md
Above the graph, I think there's a typo: instead of L = 23, it should say L = 2^23. It would be nice to also mention that a multiplication by a power of two is equivalent to a left shift (hence where the I_x bit pattern comes from). The bias also comes out of nowhere: it should be briefly explained that IEEE exponents are shifted by 2^(e_x-1)-1. It's also be nice to have labels on the graph axes as I'm still not 100% sure what they mean. I believe vertical=binary representation while horizontal=float number.
In the intro to chapter 3, there is a link to https://en.algorithmica.org/hpc/pipelining/scheduling which gives a 404.
I see the scheduling page in the repo, but on the website that page does not appear in the sidebar.
On page https://ru.algorithmica.org/cs/modular/discrete-log/
math doesn't render
Hello. I suspect some information are missing from the page: https://en.algorithmica.org/hpc/architecture/assembly/
For comparison, here is what the summation loop looks like in AT&T asm
But there is no loop in the page, the example is *c = *a + *b.
Good luck, keep the good work! :)
EDIT: What I mean because it hasn't been explained before, the example is confusing as you don't know what the original code is supposed to do, and so, don't understand the AT&T assembly code.
EDIT2: OK, the for loop you are talking about is on the next page (loops and conditionals) and directly in assembly. Here is my suggestion: Stay on the original example in Assembly Language page (means *c = *a + *b) and provide a C example at the beginning of the "Loops and Conditionals" page. I think this would be more clear.
Keep the good work! :)
The development cost of Ariane 5 was approximately 6B€. Launch prices are around 180M€
"(a[i] - 50) >> 31" is equivalent to (a[i] < 50) for most possible values of a[i]... but not the ones in [-2^31, 50 - 2^31). So this is not a valid optimization unless the compiler can prove that all a[i] are not smaller than 50 - 2^31.
In https://en.algorithmica.org/hpc/arithmetic/float/:
due to the way floating-point arithmetic works, all integer numbers between -2^{53} and 2^{53} and results of computations involving them can be stored exactly,
That's not true for multiplication or division, or if there is overflow, e.g. adding 2^{53}-1 + 2^{53}. (Filing as a bug rather than a PR since I'm not sure how to suggest rewording it.)
The prose.io editor fails, saying "Error while loading data from Github. [...]"
The mul instruction looks like "mul reg/mem", has only one operand, should be changed to "mul ebx" or "imul eax, ebx".
You are contradicting yourself. On the one hand, you say switching to higher precision is not scalable, on the other hand, that’s what you recommend here.
A declarative, efficient, and flexible JavaScript library for building user interfaces.
🖖 Vue.js is a progressive, incrementally-adoptable JavaScript framework for building UI on the web.
TypeScript is a superset of JavaScript that compiles to clean JavaScript output.
An Open Source Machine Learning Framework for Everyone
The Web framework for perfectionists with deadlines.
A PHP framework for web artisans
Bring data to life with SVG, Canvas and HTML. 📊📈🎉
JavaScript (JS) is a lightweight interpreted programming language with first-class functions.
Some thing interesting about web. New door for the world.
A server is a program made to process requests and deliver data to clients.
Machine learning is a way of modeling and interpreting data that allows a piece of software to respond intelligently.
Some thing interesting about visualization, use data art
Some thing interesting about game, make everyone happy.
We are working to build community through open source technology. NB: members must have two-factor auth.
Open source projects and samples from Microsoft.
Google ❤️ Open Source for everyone.
Alibaba Open Source for everyone
Data-Driven Documents codes.
China tencent open source team.
{kind=link}
{kind=link}
{kind=link}