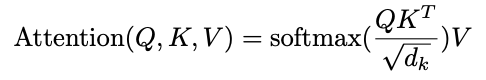BERT is designed to pre-train deep bidirectional representations from unlabelled text by jointly conditioning on both left and right context in all the layers. As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. BERT is trained on unlabelled dataset to achieve state of the art results on 11 individual NLP tasks. And all of this with little fine tuning.
Deeply Bidirectional means that BERT learns information from both the left and right side of a token's context during the training.
Let's try to understand the concept of left and right context in Deeply Bidirectional
- Sentence 1: They exchanged addresses and agreed to keep in touch.
- Sentence 2: People of India will be addressed by Prime Minister today.
If model is trained unidirectional and we try to predict the word "Address" from the above two sentences dataset, then the model will be making error in predicting either of them.

Before BERT, NLP community used features based on searching the key terms in the word corpus using Term Frequency.These vectors were used in mathematical and statistical models for classification and regression tasks. There was nothing much that could be done mathematically on term frequency to understand the syntax and semantics of the word in a sentence. Then arrived an era of word embedding. Here every word can be represented in their vector space and words having same meaning were close to each other in vector space. This started from Word2Vec and GloVe.
Consider an example:
- Sentence 1: Man is related to Woman
- Sentence 2: Then King is related to ...
Above sentence can be explained mathematically as: King - Man + Woman = Queen
And this can be achieved using word embeddings. Only issue with such word embeddings was with respect to the information they could store. Word2Vec could store only feedforward information, resulting in same vectors for similar words used in different context. Such words are known as Polysemy words. To handle polysemy words, prediction led to more complex and deeper LSTM models.
The revolutionary NLP architecture, which marked the era of transfer learning in NLP and also letting the model understand the syntax and semantics of a word, ELMo (Embeddings from Language Models) and ULMFit started the new trend. ELMo was then, the answer to the problem of Polysemy words- same words having different meanings based on the context .
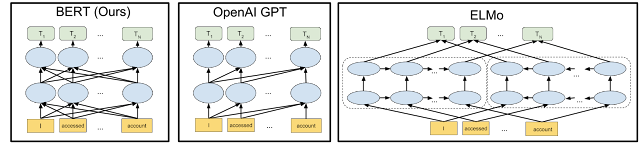
BERT is deeply bidirectional, OpenAI GPT is unidirectional, and ELMo is shallowly bidirectional.
ELMo used weighted sum of forward (context before the token/word) and backward (context after the token/word) pass generated, Intermediate Word vectors from two stacked biLM layers and raw vector generated from character convolutions to produce the final ELMo vector. This helped ELMo look at the past and future context, basically the whole sentence to generate the word vector, resulting in unique vector for Polysemy words.
The true power of transfer learning in NLP was unleashed after ULMFiT (Universal Language Model Fine-tuning). The concept revolved around having a Language Model (LM) trained on generic corpora. These LMs were based on same ideology what ImageNet helped to achieve transfer learning in Computer Vision. The stages in transfer learnng pretraining and Fine-tuning which is still followed started with ULMFiT. In pretraining stage the LMs will be trained to learn generic information over language corpora. While fine-tuning the pretrained model to a downstream task, we will train the model on task specific data. Only the last few layers will be trained from scratch. This will result in better accurracy as the initial layers had generic language understanding and last layers had task specific information. BERT is also based on the idea that fine-tuning a pre-trained language model can help the model achieve better results in the downstream tasks.
Following ELMo and UMLFiT on the same ground, came OpenAI GPT(Generative Pre-trained Transformers). OpenAI GPT was based on Transformer based network, as suggested in Google Brains research paper "Attention is all you need". They replaced the whole LSTM architecture with encoder decoder layer stack. GPT also emphasized the importance of the Transformer framework, which has a simpler architecture and can train faster than LSTM-based model. It is also able to learn complex patterns in the data by using the Attention mechanism. This started the breaktrough for NLP state of the art frameworks using Transformers which includes BERT.
BERT surpasses the unidirectionality constraints by using a “Masked Language Model (MLM)” pre-training objective. MLM randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary id of the masked word based only on its context. It enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformer. In addition to the MLM, BERT also uses a “ next sequence prediction” task that jointly pretrains text-pair representations.There are two steps involved in BERT:
- Pre-training: the model is trained on unlabelled data over different pre-training task.
- Fine-tuning: BERT model is first initialized with the pre-trained parameters and all of the parameters are fine-tuned using labelled data from the downstream task.
With the basic understanding of the above two steps, lets deep dive to understand BERT framework.
-
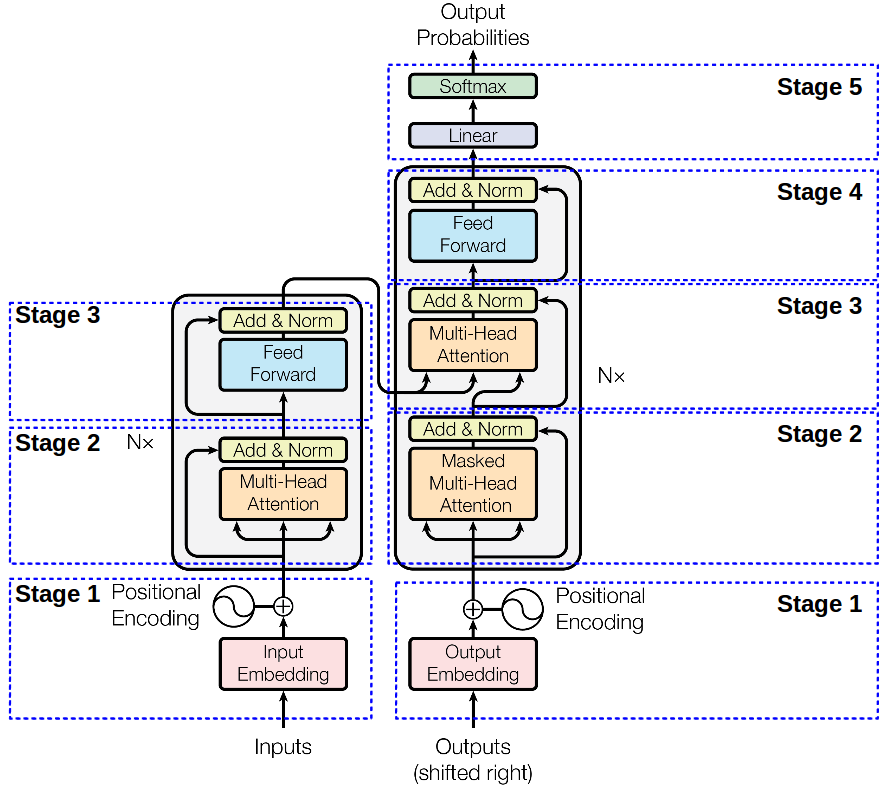
BERT Model architecture is a multi-layer bidirectional Transformer encoder-decoder structure.
-
Encoder: Encoder is composed of a stack of N=6 identical layers. Each layer has two sub layers. The first layer is a multi-head self-attention mechanism and the second is a position wise fully connected feed-forward network. There is a residual connection around each of the two sub layers followed by layer normalization.
-
Decoder: Decoder is also composed of N=6 identical layers. Decoder has additional one sub-layer over two sub-layers as present in encoder, which performs multi-head attention over the output of the encoder stack. Similar to encoder we have residual connection around every sub-layers followed by layer normalization.
-
Attention: Attention is a mechanism to know which word in the context better contributes to the current word. It is calculated using the dot product between query vector Q and key vector K. The output from attention head is the weighted sum of value vector V, where the weights assigned to each value is computed by a compatibility function of the Query with the corresponding Key. The general formula that sums up the whole process of attention calculation in BERT is:
where, Q is the matrix of queries, K and V matrix represent keys and values.
To fully understand the attention calculation with example, I would request you to go through the Analytics Vidya blog
-
-
BERT is pretrained using two unsupervised task:
- Masked Language Model: In order to train the bidirectional representation, BERT simply masks 15% of the input tokens at random and then predict those masked tokens. A downside is that it creates a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To deal with this situation, BERT not always replaces the masked words with actual [MASKED] token. The BERT training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, BERT replaces the i-th token with:
- the [MASK] token 80% of the time
- a random token 10% of the time
- the unchanged i-th token 10% of the time
- Next Sentence Prediction (NSP): In order to train a model that understands sentence relationships, we pre-train for a next sentence prediction task. If there are two sentences A and B, BERT trains on 50% of the time with B as the actual next sentence that follows A (labeled as isNext) and 50% of the time it is a random sentence from the corpus (labeled as NotNext).
- Masked Language Model: In order to train the bidirectional representation, BERT simply masks 15% of the input tokens at random and then predict those masked tokens. A downside is that it creates a mismatch between pre-training and fine-tuning, since the [MASK] token does not appear during fine-tuning. To deal with this situation, BERT not always replaces the masked words with actual [MASKED] token. The BERT training data generator chooses 15% of the token positions at random for prediction. If the i-th token is chosen, BERT replaces the i-th token with:
- The self-attention mechanism in the Transformer allows BERT to model any downstream task. BERT with self-attention encodes a concatenated text pair, which effectively includes bidirectional cross attention between two sentences. For each task, we simply plug in the task specific inputs and outputs into BERT and fine-tune all the parameters end to end. At the output the token representations are fed into an output layer for token level tasks, such as sequence tagging or question answering, and the [CLS] representation is fed into an output layer for classification, such as sentimental analysis or entailment.