什么是koa框架?
koa是一个基于node实现的一个新的web框架,它是由express框架的原班人马打造的。它的特点是优雅、简洁、表达力强、自由度高。它更express相比,它是一个更轻量的node框架,因为它所有功能都通过插件实现,这种插拔式的架构设计模式,很符合unix哲学。
koa框架现在更新到了2.x版本,本文从零开始,循序渐进,讲解koa2的框架源码结构和实现原理,展示和详解koa2框架源码中的几个最重要的概念,然后手把手教大家亲自实现一个简易的koa2框架,帮助大家学习和更深层次的理解koa2,看完本文以后,再去对照koa2的源码进行查看,相信你的思路将会非常的顺畅。
本文所用的框架是koa2,它跟koa1不同,koa1使用的是generator+co.js的执行方式,而koa2中使用了async/await,因此本文的代码和demo需要运行在node 8版本及其以上,如果读者的node版本较低,建议升级或者安装babel-cli,用其中的babel-node来运行本文涉及到的代码。
本文实现的轻量版koa的完整代码gitlab地址为:article_koa2
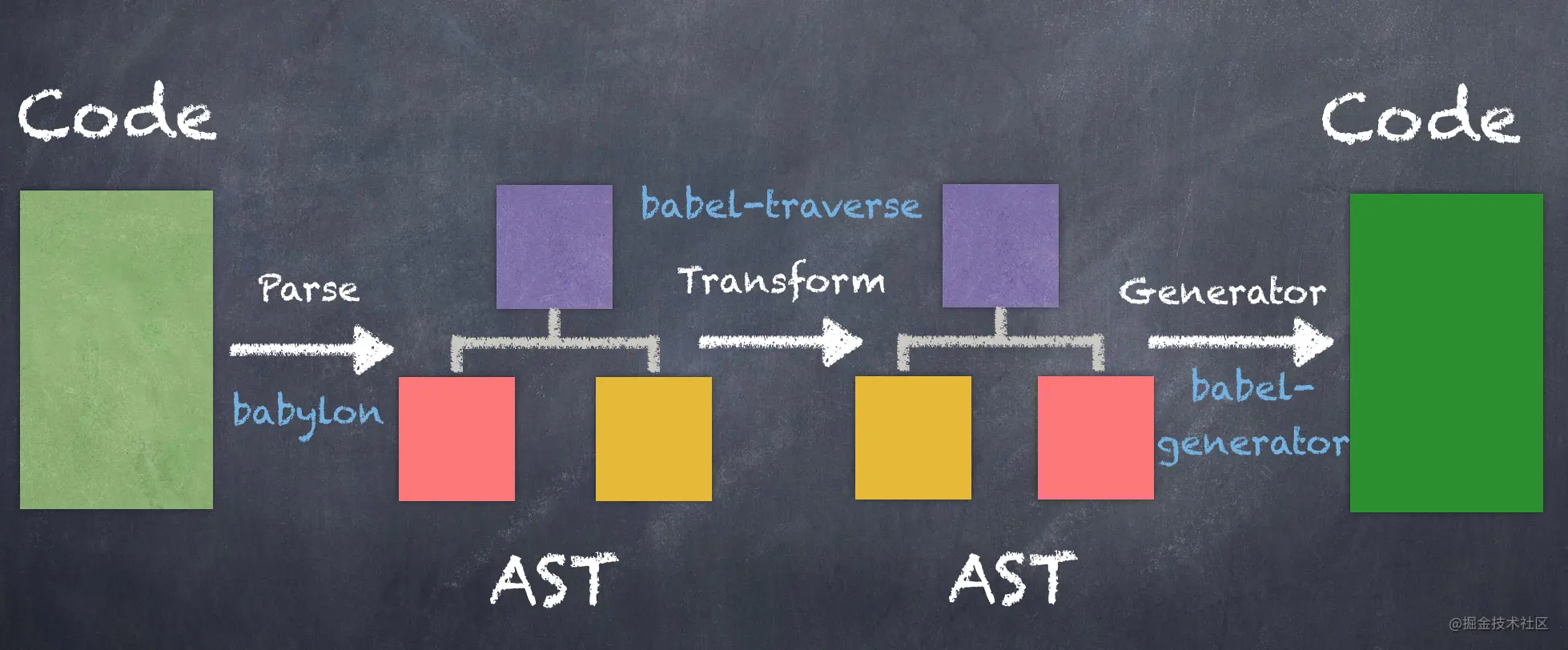
koa源码结构

上图是koa2的源码目录结构的lib文件夹,lib文件夹下放着四个koa2的核心文件:application.js、context.js、request.js、response.js。
application.js
application.js是koa的入口文件,它向外导出了创建class实例的构造函数,它继承了events,这样就会赋予框架事件监听和事件触发的能力。application还暴露了一些常用的api,比如toJSON、listen、use等等。
listen的实现原理其实就是对http.createServer进行了一个封装,重点是这个函数中传入的callback,它里面包含了中间件的合并,上下文的处理,对res的特殊处理。
use是收集中间件,将多个中间件放入一个缓存队列中,然后通过koa-compose这个插件进行递归组合调用这一些列的中间件。
context.js
这部分就是koa的应用上下文ctx,其实就一个简单的对象暴露,里面的重点在delegate,这个就是代理,这个就是为了开发者方便而设计的,比如我们要访问ctx.repsponse.status但是我们通过delegate,可以直接访问ctx.status访问到它。
request.js、response.js
这两部分就是对原生的res、req的一些操作了,大量使用es6的get和set的一些语法,去取headers或者设置headers、还有设置body等等,这些就不详细介绍了,有兴趣的读者可以自行看源码。
实现koa2的四大模块
上文简述了koa2源码的大体框架结构,接下来我们来实现一个koa2的框架,笔者认为理解和实现一个koa框架需要实现四个大模块,分别是:
- 封装node http server、创建Koa类构造函数
- 构造request、response、context对象
- 中间件机制和剥洋葱模型的实现
- 错误捕获和错误处理
- 下面我们就逐一分析和实现。
模块一:封装node http server和创建Koa类构造函数
阅读koa2的源码得知,实现koa的服务器应用和端口监听,其实就是基于node的原生代码进行了封装,如下图的代码就是通过node原生代码实现的服务器监听。
let http = require('http');
let server = http.createServer((req, res) => {
res.writeHead(200);
res.end('hello world');
});
server.listen(3000, () => {
console.log('listenning on 3000');
}); 我们需要将上面的node原生代码封装实现成koa的模式:
const http = require('http');
const Koa = require('koa');
const app = new Koa();
app.listen(3000); 实现koa的第一步就是对以上的这个过程进行封装,为此我们需要创建application.js实现一个Application类的构造函数
let http = require('http');
class Application {
constructor() {
this.callbackFunc;
}
listen(port) {
let server = http.createServer(this.callback());
server.listen(port);
}
use(fn) {
this.callbackFunc = fn;
}
callback() {
return (req, res) => {
this.callbackFunc(req, res);
};
}
}
module.exports = Application; 然后创建example.js,引入application.js,运行服务器实例启动监听代码:
let Koa = require('./application');
let app = new Koa();
app.use((req, res) => {
res.writeHead(200);
res.end('hello world');
});
app.listen(3000, () => {
console.log('listening on 3000');
}); 现在在浏览器输入localhost:3000即可看到浏览器里显示“hello world”。现在第一步我们已经完成了,对http server进行了简单的封装和创建了一个可以生成koa实例的类class,这个类里还实现了app.use用来注册中间件和注册回调函数,app.listen用来开启服务器实例并传入callback回调函数,第一模块主要是实现典型的koa风格和搭好了一个koa的简单的架子。接下来我们开始编写和讲解第二模块。
模块二:构造request、response、context对象
阅读koa2的源码得知,其中context.js、request.js、response.js三个文件分别是request、response、context三个模块的代码文件。context就是我们平时写koa代码时的ctx,它相当于一个全局的koa实例上下文this,它连接了request、response两个功能模块,并且暴露给koa的实例和中间件等回调函数的参数中,起到承上启下的作用。
request、response两个功能模块分别对node的原生request、response进行了一个功能的封装,使用了getter和setter属性,基于node的对象req/res对象封装koa的request/response对象。我们基于这个原理简单实现一下request.js、response.js,首先创建request.js文件,然后写入以下代码:
let url = require('url');
module.exports = {
get query() {
return url.parse(this.req.url, true).query;
}
}; 这样当你在koa实例里使用ctx.query的时候,就会返回url.parse(this.req.url, true).query的值。看源码可知,基于getter和setter,在request.js里还封装了header、url、origin、path等方法,都是对原生的request上用getter和setter进行了封装,笔者不再这里一一实现。
接下来我们实现response.js文件代码模块,它和request原理一样,也是基于getter和setter对原生response进行了封装,那我们接下来通过对常用的ctx.body和ctx.status这个两个语句当做例子简述一下如果实现koa的response的模块,我们首先创建好response.js文件,然后输入下面的代码:
module.exports = {
get body() {
return this._body;
},
set body(data) {
this._body = data;
},
get status() {
return this.res.statusCode;
},
set status(statusCode) {
if (typeof statusCode !== 'number') {
throw new Error('something wrong!');
}
this.res.statusCode = statusCode;
}
}; 以上代码实现了对koa的status的读取和设置,读取的时候返回的是基于原生的response对象的statusCode属性,而body的读取则是对this._body进行读写和操作。这里对body进行操作并没有使用原生的this.res.end,因为在我们编写koa代码的时候,会对body进行多次的读取和修改,所以真正返回浏览器信息的操作是在application.js里进行封装和操作。
现在我们已经实现了request.js、response.js,获取到了request、response对象和他们的封装的方法,然后我们开始实现context.js,context的作用就是将request、response对象挂载到ctx的上面,让koa实例和代码能方便的使用到request、response对象中的方法。现在我们创建context.js文件,输入如下代码:
let proto = {};
function delegateSet(property, name) {
proto.__defineSetter__(name, function (val) {
this[property][name] = val;
});
}
function delegateGet(property, name) {
proto.__defineGetter__(name, function () {
return this[property][name];
});
}
let requestSet = [];
let requestGet = ['query'];
let responseSet = ['body', 'status'];
let responseGet = responseSet;
requestSet.forEach(ele => {
delegateSet('request', ele);
});
requestGet.forEach(ele => {
delegateGet('request', ele);
});
responseSet.forEach(ele => {
delegateSet('response', ele);
});
responseGet.forEach(ele => {
delegateGet('response', ele);
});
module.exports = proto; context.js文件主要是对常用的request和response方法进行挂载和代理,通过context.query直接代理了context.request.query,context.body和context.status代理了context.response.body与context.response.status。而context.request,context.response则会在application.js中挂载。
本来可以用简单的setter和getter去设置每一个方法,但是由于context对象定义方法比较简单和规范,在koa源码里可以看到,koa源码用的是__defineSetter__和__defineSetter__来代替setter/getter每一个属性的读取设置,这样做主要是方便拓展和精简了写法,当我们需要代理更多的res和req的方法的时候,可以向context.js文件里面的数组对象里面添加对应的方法名和属性名即可。
目前为止,我们已经得到了request、response、context三个模块对象了,接下来就是将request、response所有方法挂载到context下,让context实现它的承上启下的作用,修改application.js文件,添加如下代码:
let http = require('http');
let context = require('./context');
let request = require('./request');
let response = require('./response');
createContext(req, res) {
let ctx = Object.create(this.context);
ctx.request = Object.create(this.request);
ctx.response = Object.create(this.response);
ctx.req = ctx.request.req = req;
ctx.res = ctx.response.res = res;
return ctx;
} 可以看到,我们添加了createContext这个方法,这个方法是关键,它通过Object.create创建了ctx,并将request和response挂载到了ctx上面,将原生的req和res挂载到了ctx的子属性上,往回看一下context/request/response.js文件,就能知道当时使用的this.res或者this.response之类的是从哪里来的了,原来是在这个createContext方法中挂载到了对应的实例上,构建了运行时上下文ctx之后,我们的app.use回调函数参数就都基于ctx了。
模块三:中间件机制和剥洋葱模型的实现
目前为止我们已经成功实现了上下文context对象、 请求request对象和响应response对象模块,还差一个最重要的模块,就是koa的中间件模块,koa的中间件机制是一个剥洋葱式的模型,多个中间件通过use放进一个数组队列然后从外层开始执行,遇到next后进入队列中的下一个中间件,所有中间件执行完后开始回帧,执行队列中之前中间件中未执行的代码部分,这就是剥洋葱模型,koa的中间件机制。
koa的剥洋葱模型在koa1中使用的是generator + co.js去实现的,koa2则使用了async/await + Promise去实现的,接下来我们基于async/await + Promise去实现koa2中的中间件机制。首先,假设当koa的中间件机制已经做好了,那么它是能成功运行下面代码的:
let Koa = require('../src/application');
let app = new Koa();
app.use(async (ctx, next) => {
console.log(1);
await next();
console.log(6);
});
app.use(async (ctx, next) => {
console.log(2);
await next();
console.log(5);
});
app.use(async (ctx, next) => {
console.log(3);
ctx.body = "hello world";
console.log(4);
});
app.listen(3000, () => {
console.log('listenning on 3000');
});
```
运行成功后会在终端输出123456,那就能验证我们的koa的剥洋葱模型是正确的。接下来我们开始实现,修改application.js文件,添加如下代码:
```javascript
compose() {
return async ctx => {
function createNext(middleware, oldNext) {
return async () => {
await middleware(ctx, oldNext);
}
}
let len = this.middlewares.length;
let next = async () => {
return Promise.resolve();
};
for (let i = len - 1; i >= 0; i--) {
let currentMiddleware = this.middlewares[i];
next = createNext(currentMiddleware, next);
}
await next();
};
}
callback() {
return (req, res) => {
let ctx = this.createContext(req, res);
let respond = () => this.responseBody(ctx);
let onerror = (err) => this.onerror(err, ctx);
let fn = this.compose();
return fn(ctx);
};
}
```
koa通过use函数,把所有的中间件push到一个内部数组队列this.middlewares中,剥洋葱模型能让所有的中间件依次执行,每次执行完一个中间件,遇到next()就会将控制权传递到下一个中间件,下一个中间件的next参数,剥洋葱模型的最关键代码是compose这个函数:
```javascript
compose() {
return async ctx => {
function createNext(middleware, oldNext) {
return async () => {
await middleware(ctx, oldNext);
}
}
let len = this.middlewares.length;
let next = async () => {
return Promise.resolve();
};
for (let i = len - 1; i >= 0; i--) {
let currentMiddleware = this.middlewares[i];
next = createNext(currentMiddleware, next);
}
await next();
};
} createNext函数的作用就是将上一个中间件的next当做参数传给下一个中间件,并且将上下文ctx绑定当前中间件,当中间件执行完,调用next()的时候,其实就是去执行下一个中间件。
for (let i = len - 1; i >= 0; i--) {
let currentMiddleware = this.middlewares[i];
next = createNext(currentMiddleware, next);
} 上面这段代码其实就是一个链式反向递归模型的实现,i是从最大数开始循环的,将中间件从最后一个开始封装,每一次都是将自己的执行函数封装成next当做上一个中间件的next参数,这样当循环到第一个中间件的时候,只需要执行一次next(),就能链式的递归调用所有中间件,这个就是koa剥洋葱的核心代码机制。
到这里我们总结一下上面所有剥洋葱模型代码的流程,通过use传进来的中间件是一个回调函数,回调函数的参数是ctx上下文和next,next其实就是控制权的交接棒,next的作用是停止运行当前中间件,将控制权交给下一个中间件,执行下一个中间件的next()之前的代码,当下一个中间件运行的代码遇到了next(),又会将代码执行权交给下下个中间件,当执行到最后一个中间件的时候,控制权发生反转,开始回头去执行之前所有中间件中剩下未执行的代码,这整个流程有点像一个伪递归,当最终所有中间件全部执行完后,会返回一个Promise对象,因为我们的compose函数返回的是一个async的函数,async函数执行完后会返回一个Promise,这样我们就能将所有的中间件异步执行同步化,通过then就可以执行响应函数和错误处理函数。
当中间件机制代码写好了以后,运行我们的上面的例子,已经能输出123456了,至此,我们的koa的基本框架已经基本做好了,不过一个框架不能只实现功能,为了框架和服务器实例的健壮,还需要加上错误处理机制。
模块四:错误捕获和错误处理
要实现一个基础框架,错误处理和捕获必不可少,一个健壮的框架,必须保证在发生错误的时候,能够捕获到错误和抛出的异常,并反馈出来,将错误信息发送到监控系统上进行反馈,目前我们实现的简易koa框架还没有能实现这一点,我们接下加上错误处理和捕获的机制。
throw new Error('oooops'); 基于现在的框架,如果中间件代码中出现如上错误异常抛出,是捕获不到错误的,这时候我们看一下application.js中的callback函数的return返回代码,如下:
return fn(ctx).then(respond);
可以看到,fn是中间件的执行函数,每一个中间件代码都是由async包裹着的,而且中间件的执行函数compose返回的也是一个async函数,我们根据es7的规范知道,async返回的是一个promise的对象实例,我们如果想要捕获promise的错误,只需要使用promise的catch方法,就可以把所有的中间件的异常全部捕获到,修改后callback的返回代码如下:
return fn(ctx).then(respond).catch(onerror);
现在我们已经实现了中间件的错误异常捕获,但是我们还缺少框架层发生错误的捕获机制,我们希望我们的服务器实例能有错误事件的监听机制,通过on的监听函数就能订阅和监听框架层面上的错误,实现这个机制不难,使用nodejs原生events模块即可,events模块给我们提供了事件监听on函数和事件触发emit行为函数,一个发射事件,一个负责接收事件,我们只需要将koa的构造函数继承events模块即可,构造后的伪代码如下:
let EventEmitter = require('events');
class Application extends EventEmitter {} 继承了events模块后,当我们创建koa实例的时候,加上on监听函数,代码如下:
let app = new Koa();
app.on('error', err => {
console.log('error happends: ', err.stack);
}); 这样我们就实现了框架层面上的错误的捕获和监听机制了。总结一下,错误处理和捕获,分中间件的错误处理捕获和框架层的错误处理捕获,中间件的错误处理用promise的catch,框架层面的错误处理用nodejs的原生模块events,这样我们就可以把一个服务器实例上的所有的错误异常全部捕获到了。至此,我们就完整实现了一个轻量版的koa框架了。
结尾
目前为止,我们已经实现了一个轻量版的koa框架了,我们实现了封装node http server、创建Koa类构造函数、构造request、response、context对象、中间件机制和剥洋葱模型的实现、错误捕获和错误处理这四个大模块,理解了这个轻量版koa的实现原理,再去看koa2的源码,你就会发现一切都豁然开朗,koa2的源码无非就是在这个轻量版基础上加了很多工具函数和细节的处理,限于篇幅笔者就不再一一介绍了。
本文实现的轻量版koa的完整代码gitlab地址为:article_koa2