- High Availibility
- Scalability
- Elasticity
- Agility
- Disaster Recovery
- Capital Expenditure (CapEx)
- Operation Expenditure (OpEx)
- Consumption-based model
- Shared responsibility model
- Infrastructure-as-a-Service (IaaS)
- Platform-as-a-Service (PaaS)
- Serverless Computing
- Software-as-a-Service
- Identify a service type based on a use case
- Cloud computing
- Public Cloud
- Private Cloud
- Hybrid Cloud
- Comparision and contrast of the three types of cloud computing
- Scale Sets
- Regions and Region Pairs
- Availibility Zones
- Resource Groups
- Subscriptions
- Management Groups
- Azure Resource Manager
- Azure Resources
- Virtual Machines
- Azure App Services
- Azure Container Instances (ACI)
- Azure Kubernets Services (AKS)
- Windows Virtual Desktop
- Virtual Networks
- VPN Gateway
- Virtual Network Peering
- ExpressRoute
- Container (Blob) Storage
- Disk Storage
- File Storage
- Storage tiers
- Cosmos DB
- Azure SQL Database
- Azure Database for MySQL
- Azure Database for PostgresSQL
- SQL Managed Instance
- Azure Marketplace
- Internet of Things (IoT) Hub, IoT Central, Azure Sphere
- Azure Synapse Analytics, HDInsight, Azure Databricks
- Azure Machine Learning, Cognitive Services and Azure Bot Service
- Serverless computing solutions that include Azure Functions and Logic Apps
- Azure Devops, Github, Github Actions, Azure DevTest Labs
- Azure Portal
- Azure Powershell
- Azure CLI
- Cloud Shell
- Azure Mobile App
- Azure Advisor
- Azure Resource Manager (ARM)
- Azure Monitor
- Azure Service Health
- Azure Security Center, including policy compliance, securty alerts, secure score and resource hygiene
- Key Vault
- Azure Sentinel
- Azure Dedicated Host
- Concept of defense in depth
- Network Security Groups (NSG)
- Azure Firewall
- Azure DDoS protection
- Difference between authentication and authorization
- Azure Active Directory
- Conditional Acces, Multi-Factor Authentication (MFA) and Single Sign-On (SSO)
- Role-Based Acces Control (RBAC)
- Usage of resource
- Usage of tags
- Azure Policy
- Azure Blueprint
- Cloud Adoption Framework for Azure
- Microsoft core tenets of Security, Privacy and Compliance
- Purpose of Microsoft Privacy Statement, Product Terms sit and Data Protection Addendum (DPA)
- Purpose of the Trust Center
- Purpose of the Azure compliance documentation
- Azure Sovereign Regions (Azure Government cloud services and Azure China cloud services)
- Identify factors that can affect costs (resource types, services, locations, ingress and egress traffic)
- Identify factors that can reduce costs (reserved instances, reserved capacity, hybrid use benefit, spot pricing)
- Functionality and usage of the Pricing calculator and Total Cost of Ownershp (TCO) calculator
- Describe the purpose of an Azure Service Level Agreement (SLA)
- Identify action that can impact ans SLA (i.e. Availibility Zones)
- Describe the service lifecycle in Azure (Public Preview and General Availibility)
- Azure CycleCloud
- Azure Database Migration Service
- Azure Synapse Analytics
- Azure Sphere
- Azure Data Lake
- Azure Stream Analytics
- Azure Logic Apps
- Azure Event Hubs
- Azure Event Grid
< High Availibility
High Availibility
High availibility means VMs can spin up fast to help process requests, it refers to a set of technologies that minimize IT disruptions by providing business continuity of IT services through redundant, fault-tolerant, or failover-protected components inside the same data center. High availibility is a quality of computing infrastructure that allows it to continue functioning, even when some of its components fail. This is important for mission-critical sytem that cannot tolerate interruption in service, and any downtime can saude damage or result in financial loss.
Highly available system quarantee a certain percentage of uptime, for example, a system that has 99.9% uptime will be down only 0.1% of the time - 0.365 days or 8,76 hours per year. The number of "nines" is commonly used to indicate the degree of high availibility. For example, "five nines" indicates a system that is up 99.999% of the time.
The basic elements of high availibility The following three elements are essential to a highly available system:
- Redundancy: ensuring that any elements critical to system operations have an additional, redundant component that can take over in case of failure.
- Monitoring: collecting data from a running system and detecting when a component fails or stops responding
- Failover: a mechanism that can switch automatically from the currently active component to a redundant component, if monitoring shows a failure of the active component
< Scalability
Scalability
Scalability refers to Scaling Out or Scaling Up, Scalability is the ability to add or remove virtual machines, scaling out, or increase the resources on a single virtual machine, scaling up.
- Scaling Out: A scale out operation is the equivalent of creating multiple copies of your website and adding a load balancer to distribute the demand between them. When you scale out a website in Windows Azure Web Sites there is no need to configure load balancing seperately since this is already provided by the platform.
- Scaling Up: A scale up operation is the Azure Web Sites cloud equivalent of moving your non-cloud website to a bigger physical server. So, scale up operations are useful to consider when your site is hitting a quota, signaling that you are outgrowing your existing mode or options. In addition, scaling up can be done on virtually any site without worrying about the implications of multi-instances data consistency. Two examples of scale up operations in Windows Azure webstes are:
- Changing the site mode: If you choose Standard mode, for example, your web site will have no quotas imposed on the CPU usage, and data egress will only be limited by the cost of data egress over the included 5 GB/month.
- Instance size in Standard mode: In Standard mode, Windows Azure Web Sites allows a choice of different instance sizes, Small, Medium, and Large. This is also analogous to moving to a bigger physical server with increasing numbers of cores and amounts of memory
< Elasticity
Elasticity
Elasticity is the ability to quickly increase or decrease computer processing and resources.
Elastic computing is the ability to quickly expand or decrease computer processing, memory, and storage resources to meet changing demands without worrying about capacity planning and engineering for peak usage. Typically controlled by system monitoring tools, elastic computing matches the amount of resources allocated to the amount of resources actually needed without disrupting operations. With cloud elasticity, a company avoids paying for unused capacity or idle resources and doesn’t have to worry about investing in the purchase or maintenance of additional resources and equipment.
While security and limited control are concerns to take into account when considering elastic cloud computing, it has many benefits. Elastic computing is more efficient than your typical IT infrastructure, is typically automated so it doesn’t have to rely on human administrators around the clock, and offers continuous availability of services by avoiding unnecessary slowdowns or service interruptions.
< Agility
Agility
Agility means the ability to rapidly develop, test, and launch software applications.
< Disaster Recovery
Disaster Recovery
A business continuity and disaster recovery (BCDR) strategy helps organizations secure data, applications, and workloads during planned or unplanned outages. To help organizations implement BCDR, Azure provides Azure Site Recovery (ASR). ASR ensures business continuity during outages by replicating applications and workloads from their primary location to a secondary site.
Azure Site Recovery (ASR) is a disaster recovery as a service (DRaaS) that can be used in both public cloud and hybrid cloud architectures. It lets you use Azure as an on-demand disaster recovery site, without needing to invest in disaster recovery equipment upfront. ASR creates replicas of computer systems which are synchronized through a near-real-time data replication process. It provides application-consistent snapshots, which make sure data is usable after a failover. ASR provides support for several migration and disaster recovery scenarios:
- Replicating physical servers from on-premises data centers and other cloud providers to Azure
- Replicating virtual machines (VMs) (both Windows and Linux) running on VMware or Microsoft Hyper-V infrastructure to Azure
- Replicating VMs (Windows only) from AWS to Azure
- Replicating VMs (both Windows and Linux) from Azure Stack, Azure’s hybrid cloud solution, to Azure
Azure Site Recovery continuously replicates Azure VMs to different regions, which serve as a secondary location. In case of an outage, organizations can use the secondary region to access their data and workloads - this is known as failover. Once the primary site works, normal operations can resume there - this is called failback.
Note: ASR is only supported between two regions in the same geographical cluster (for more details see the documentation). VMs you want to replicate must run one of the > supported operating systems (which include most popular versions of Windows and Linux).
Here are the components involved in this process:
- VMs in the source region - one or more Azure VMs running in the source region.
- Source VM storage - Azure VMs that are either managed or using unmanaged disks that are distributed across storage accounts.
- Source VM networks - you can place VMs in 1 or more virtual network (VNet) subnets located in the source region.
- Cache storage account - should be in the source network. VM changes are stored in this cache before they are sent to a target storage. This can help reduce impact on production applications. Azure advises to use only Standard cache storage accounts.
- Target resources - used during replication and when outages occur. Site Recovery sets up the target resources by default. It is also possible to create and customize the resources.
Site Recovery takes snapshots of VM disks. By default, the system takes crash-consistent snapshots of data. It is possible to define a frequency, and then Site Recovery will take app-consistent snapshots. The Site Recovery system uses snapshots to create recovery points, and then stores them according to the retention configurations pre-defined in the replication policy. Once a failure occurs, Site Recovery lets you restore a VM from a recovery point. This process helps ensure VMs start with no data loss or corruption. Depending on the snapshot taken, the process also helps make sure VM data remains consistent for the OS and the applications running on the VM.
The replication process performs several actions. First, the system installs the service extension of Site Recovery Mobility on the virtual machine. The extension can then register the virtual machine with Site Recovery. Then, the system starts continuously replicating the VM, immediately transferring disk writes to the Standard cache storage that was set up in the source location. During the next phase, Site Recovery starts processing cache data, sending it to replicated managed disks or to a storage account. When this is done, the system starts generating crash-consistent recovery points every 5 minutes. If the replication policy defined a process for app-consistent recovery points, these will be created too. The following diagram shows what happens when you enable replication. ASR starts replicating disk data to the target environment. However, virtual machines are not started yet.
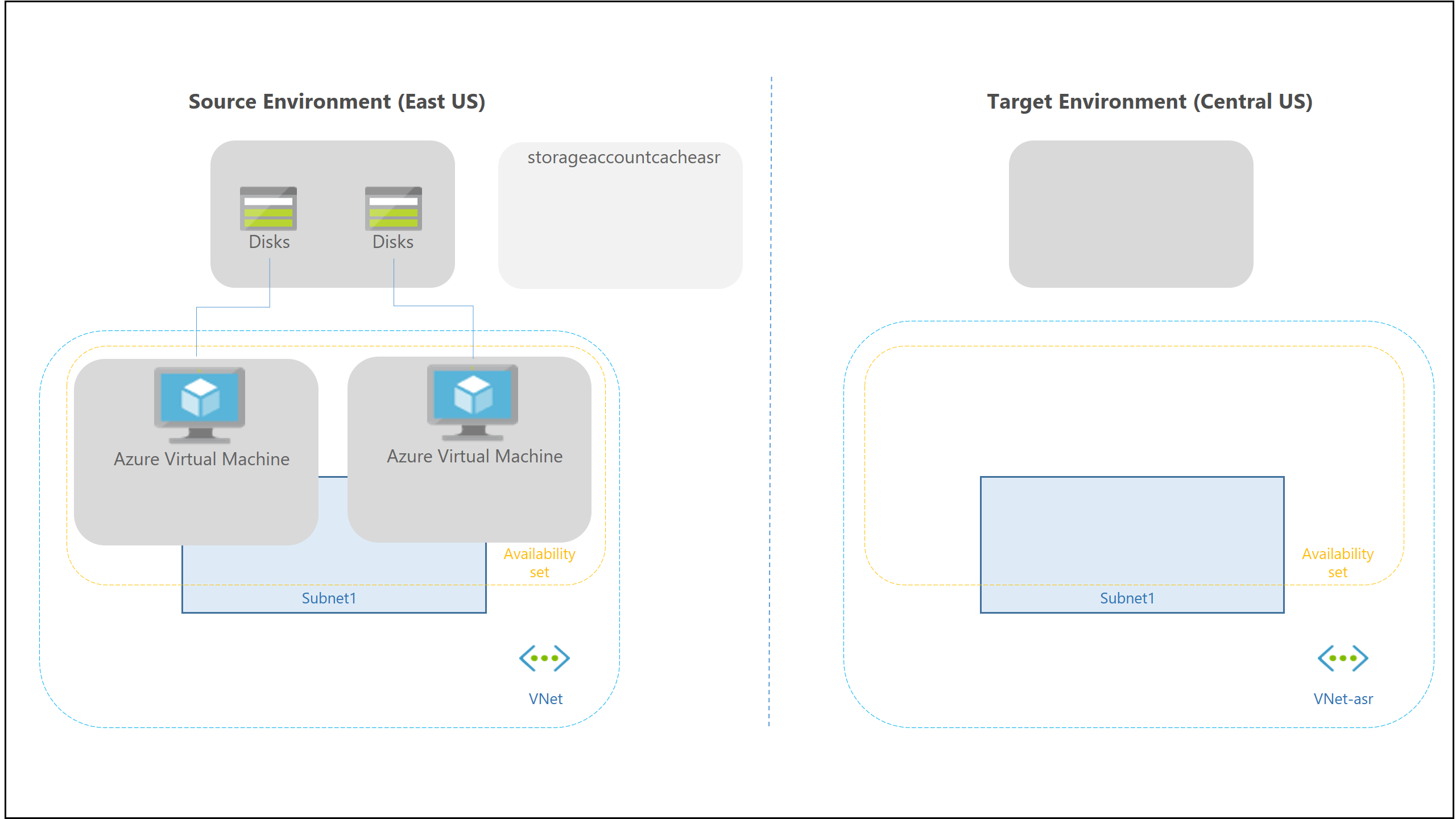
When you initiate a failover via ASR, VMs are created in the target region based on the virtual network, subnet, and availability set you defined, and the data previously replicated from the source environment.
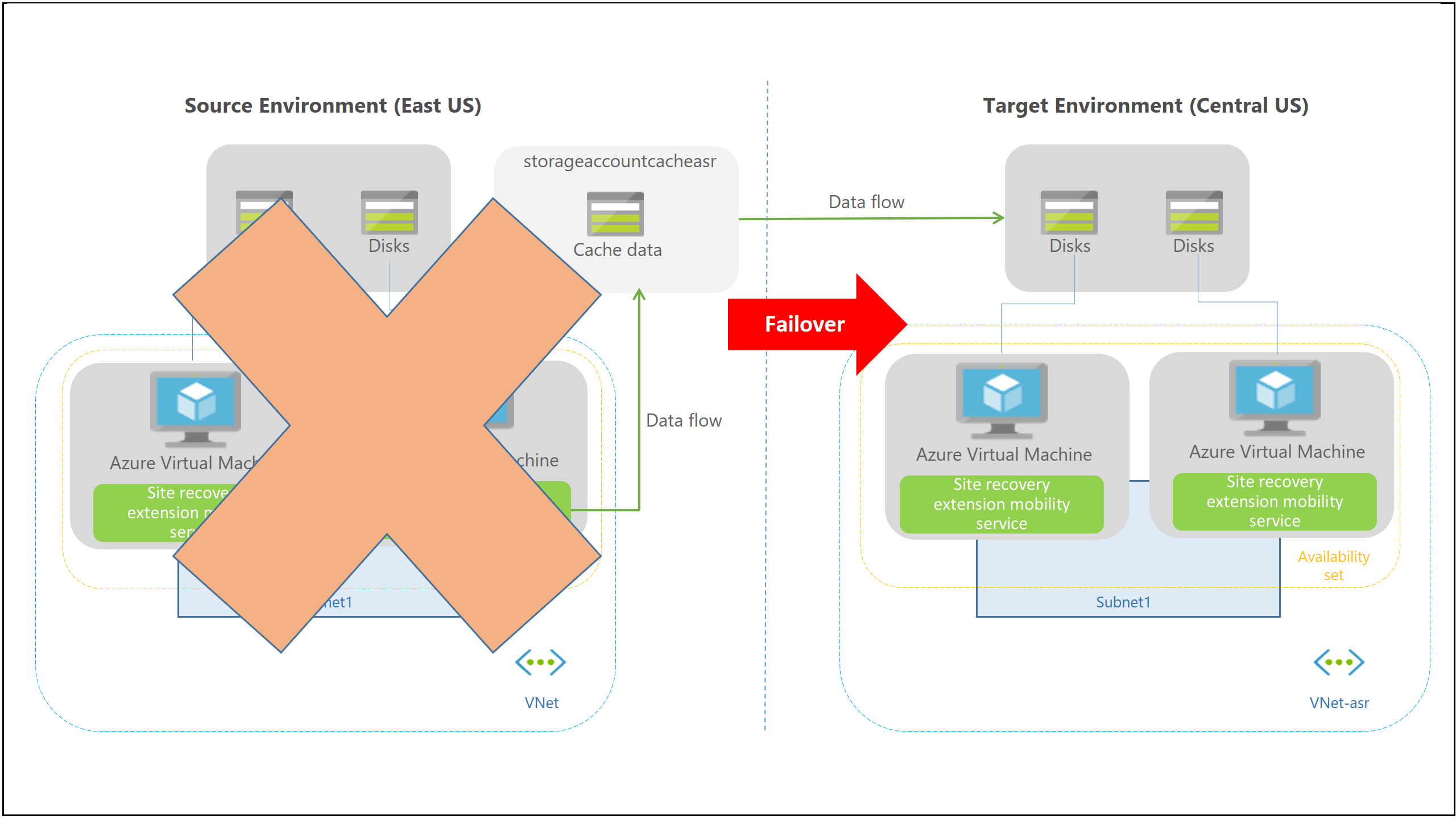
Azure Site Recovery can also be used to replicate physical servers deployed in an on-premises data center to the Azure cloud.
Here are the components involved in the process:
-
Azure subscription and network
Data replicated from physical machines is copied to disks within your Azure subscription. When you perform a failover, Azure VMs are created from data in those disks, within an Azure virtual network of your choice.
-
Process and configuration server
A replication gateway that receives data from local machines, applies caching, compression, and encryption, and copies to Azure storage. Also enables central management of the replication process. For large deployments, you may need several process servers, one for each group of machines.
-
Master target server
Also deployed on-premises, this server performs replication back to the on-premises data center during failback. As with process servers, several may be required for large deployments
-
Mobility service
Installed on each service you want to replicate to Azure. Microsoft recommends automatically installing the mobility service from the process server. You can also install it manually if needed.
< Capital Expenditure (CapEx)
Pros: With capital expenditures, you plan your expenses at the start of a project or budget period with a fixed cost. This is appealing when you need to predict the expenses before a project starts due to a limited budget. It is also beneficial in the longer run.
-
CapEx Computing Costs:
- Server costs All hardware components and the cost of supporting them are included here. While purchasing servers, one must ensure to design fault tolerance and redundancy, such as server clustering, redundant power supplies, and uninterruptible power supplies.
- Storage costs All storage hardware components and the cost of supporting it are included here. Note, based on the application and level of fault tolerance, centralized storage can be expensive.
- Network costs All on-premises hardware components, including cabling, switches, access points, and routers are included here. This also includes a wide area network (WAN) and Internet connections.
- Backup and archive costs This includes the cost to back up, copy, or archive data. Setting up a backup to or from the cloud might be considered. An upfront cost for the hardware and additional costs for backup maintenance and consumables like tapes are included here.
- Organization continuity and disaster recovery costs Together with server fault tolerance and redundancy, one must plan for recovery from a disaster and continue operating with a plan of creating a data recovery site. It could also include backup generators.
- Datacenter infrastructure costs The costs for electricity, floor space, cooling and building maintenance are included here
< Operational Expenditure (OpEx)
Pros: Demand and growth can be unpredictable and can outpace expectations, which is a challenge for the CapEx
- OpEx Cloud Computing Costs
- Leasing software and customized features Using a pay-per-use model require actively managing subscriptions to ensure users do not misuse the services, and that provisioned accounts are being utilized and not wasted. Resources that aren't in use will be de-provisioned by the Cloud service provider to minimize the costs
- Scaling charges based on usage/demand Cloud computing can bill in various way, such as the number of users of CPU usage time. Allocated RAM, I/O operations per second (IOPS), and storage space are also considered in Billing Categories. Plan for backup traffic and data recovery traffic to determine the bandwidth needed.
- Billing at the user or organization level The Azure subscription (pay-per-use) model is a computing billing method designed for both organizations and users. The organization or user is billed for the services used, on a recurring basis like we can scale, customize and provision computing resources, including software, storage and development platforms.
The cost of an Azure VM depends on various factors like its size, OS, and the region. Even though we create two VMs of the same size and OS they incur different charges if they are in a different region.
We will be charged for the OS, public IP, disk and other resources even if the VM has been stopped. In order to avoid paying for any non-functional resources, they should be deleted.
< Consumption based model
The common pricing options for Azure services are:
- Consumption-based price You are charged for only what you use. This model is also known as the Pay-As-You-Go rate.
- Fixed price You provision resources and are charged for those instances whether or not they are used.
A common way to estimate cost is by considering workloads on a peak throughput. Under consistently high utilization, consumption-based pricing can be less efficient for estimating baseline costs when compared to the equivalent provisioned pricing. PaaS and serverless technologies can help you understand the economy cutoff point for consumption-based pricing.
Observe the difference between cost models based on fixed, static provisioning of services, more variable costs based on autoscaling of serverless technologies
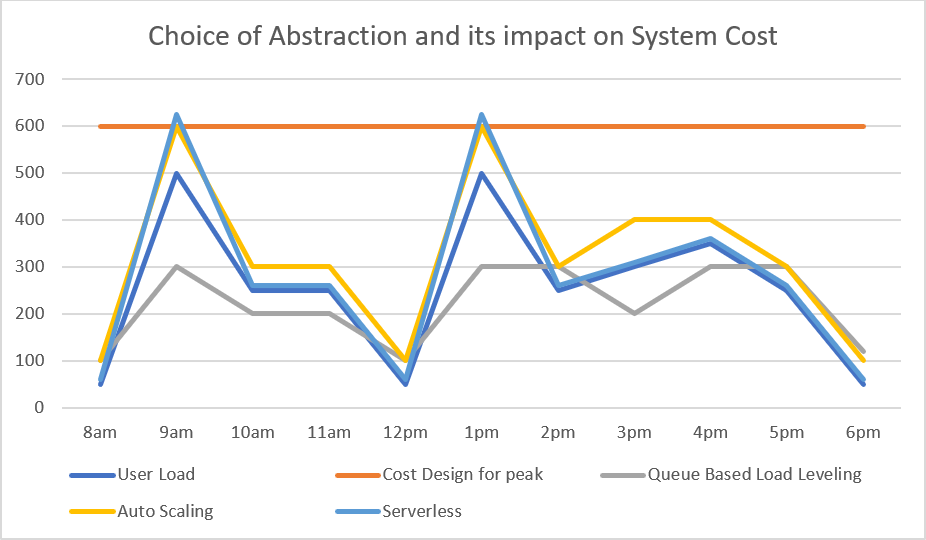
Start with a fixed minimum level of performance and then use architectural patterns (such as Queue Based Load Leveling) and autoscaling of services. With this approach the peaks can be smoothed out into a more consistent flow of compute and data. This approach should temporarily extend your burst performance when the service is under sustained load. If cost is an important factor but you need to maintain service availability under burst workload use the Throttling pattern to maintain quality of service under load.
Compare and contrast the options and understand how to provision workloads that can potentially switch between the two models. The model will be a tradeoff between scalability and predictability. Ideally in the architecture, blend the two aspects.
< Infrastructure As A Service (IaaS)
Infrastructure as a Service
Infrastructure as a service (IaaS) is a type of cloud computing service that offers essential compute, storage, and networking resources on demand, on a pay-as-you-go basis. IaaS is one of the four types of cloud services, along with software as a service (SaaS), platform as a service (PaaS), and serverless.
Migrating your organization's infrastructure to an IaaS solution helps you reduce maintenance of on-premises data centers, save money on hardware costs, and gain real-time business insights. IaaS solutions give you the flexibility to scale your IT resources up and down with demand. They also help you quickly provision new applications and increase the reliability of your underlying infrastructure.
IaaS lets you bypass the cost and complexity of buying and managing physical servers and datacenter infrastructure. Each resource is offered as a separate service component, and you only pay for a particular resource for as long as you need it. A cloud computing service provider like Azure manages the infrastructure, while you purchase, install, configure, and manage your own software—including operating systems, middleware, and applications.

< Platform As A Service (IaaS)
Platform as a Service
Platform as a service (PaaS) is a complete development and deployment environment in the cloud, with resources that enable you to deliver everything from simple cloud-based apps to sophisticated, cloud-enabled enterprise applications. You purchase the resources you need from a cloud service provider on a pay-as-you-go basis and access them over a secure Internet connection.
Like IaaS, PaaS includes infrastructure—servers, storage, and networking—but also middleware, development tools, business intelligence (BI) services, database management systems, and more. PaaS is designed to support the complete web application lifecycle: building, testing, deploying, managing, and updating.
PaaS allows you to avoid the expense and complexity of buying and managing software licenses, the underlying application infrastructure and middleware, container orchestrators such as Kubernetes, or the development tools and other resources. You manage the applications and services you develop, and the cloud service provider typically manages everything else.

< Serverless Computing
Serverless Computing
Serverless computing enables developers to build applications faster by eliminating the need for them to manage infrastructure. With serverless applications, the cloud service provider automatically provisions, scales, and manages the infrastructure required to run the code.
In understanding the definition of serverless computing, it’s important to note that servers are still running the code. The serverless name comes from the fact that the tasks associated with infrastructure provisioning and management are invisible to the developer. This approach enables developers to increase their focus on the business logic and deliver more value to the core of the business. Serverless computing helps teams increase their productivity and bring products to market faster, and it allows organizations to better optimize resources and stay focused on innovation.
< Software as a Service
Software as a Service (SaaS)
Software as a service (SaaS) allows users to connect to and use cloud-based apps over the Internet. Common examples are email, calendaring, and office tools (such as Microsoft Office 365).
SaaS provides a complete software solution that you purchase on a pay-as-you-go basis from a cloud service provider. You rent the use of an app for your organization, and your users connect to it over the Internet, usually with a web browser. All of the underlying infrastructure, middleware, app software, and app data are located in the service provider’s data center. The service provider manages the hardware and software, and with the appropriate service agreement, will ensure the availability and the security of the app and your data as well. SaaS allows your organization to get quickly up and running with an app at minimal upfront cost.
Common SaaS scenarios
If you’ve used a web-based email service such as Outlook, Hotmail, or Yahoo! Mail, then you’ve already used a form of SaaS. With these services, you log into your account over the Internet, often from a web browser. The email software is located on the service provider’s network, and your messages are stored there as well. You can access your email and stored messages from a web browser on any computer or Internet-connected device.
The previous examples are free services for personal use. For organizational use, you can rent productivity apps, such as email, collaboration, and calendaring; and sophisticated business applications such as customer relationship management (CRM), enterprise resource planning (ERP), and document management. You pay for the use of these apps by subscription or according to the level of use.
-
Gain access to sophisticated applications. To provide SaaS apps to users, you don’t need to purchase, install, update, or maintain any hardware, middleware, or software. SaaS makes even sophisticated enterprise applications, such as ERP and CRM, affordable for organizations that lack the resources to buy, deploy, and manage the required infrastructure and software themselves.
-
Pay only for what you use. You also save money because the SaaS service automatically scales up and down according to the level of usage.
-
Use free client software. Users can run most SaaS apps directly from their web browser without needing to download and install any software, although some apps require plugins. This means that you don’t need to purchase and install special software for your users.
-
Mobilize your workforce easily. SaaS makes it easy to “mobilize” your workforce because users can access SaaS apps and data from any Internet-connected computer or mobile device. You don’t need to worry about developing apps to run on different types of computers and devices because the service provider has already done so. In addition, you don’t need to bring special expertise onboard to manage the security issues inherent in mobile computing. A carefully chosen service provider will ensure the security of your data, regardless of the type of device consuming it.
-
Access app data from anywhere. With data stored in the cloud, users can access their information from any Internet-connected computer or mobile device. And when app data is stored in the cloud, no data is lost if a user’s computer or device fails.
< Shared responsibility in the cloud
Shared Responsiblity Model
As you consider and evaluate public cloud services, it’s critical to understand the shared responsibility model and which security tasks are handled by the cloud provider and which tasks are handled by you. The workload responsibilities vary depending on whether the workload is hosted on Software as a Service (SaaS), Platform as a Service (PaaS), Infrastructure as a Service (IaaS), or in an on-premises datacenter.
In an on-premises datacenter, you own the whole stack. As you move to the cloud some responsibilities transfer to Microsoft. The following diagram illustrates the areas of responsibility between you and Microsoft, according to the type of deployment of your stack.
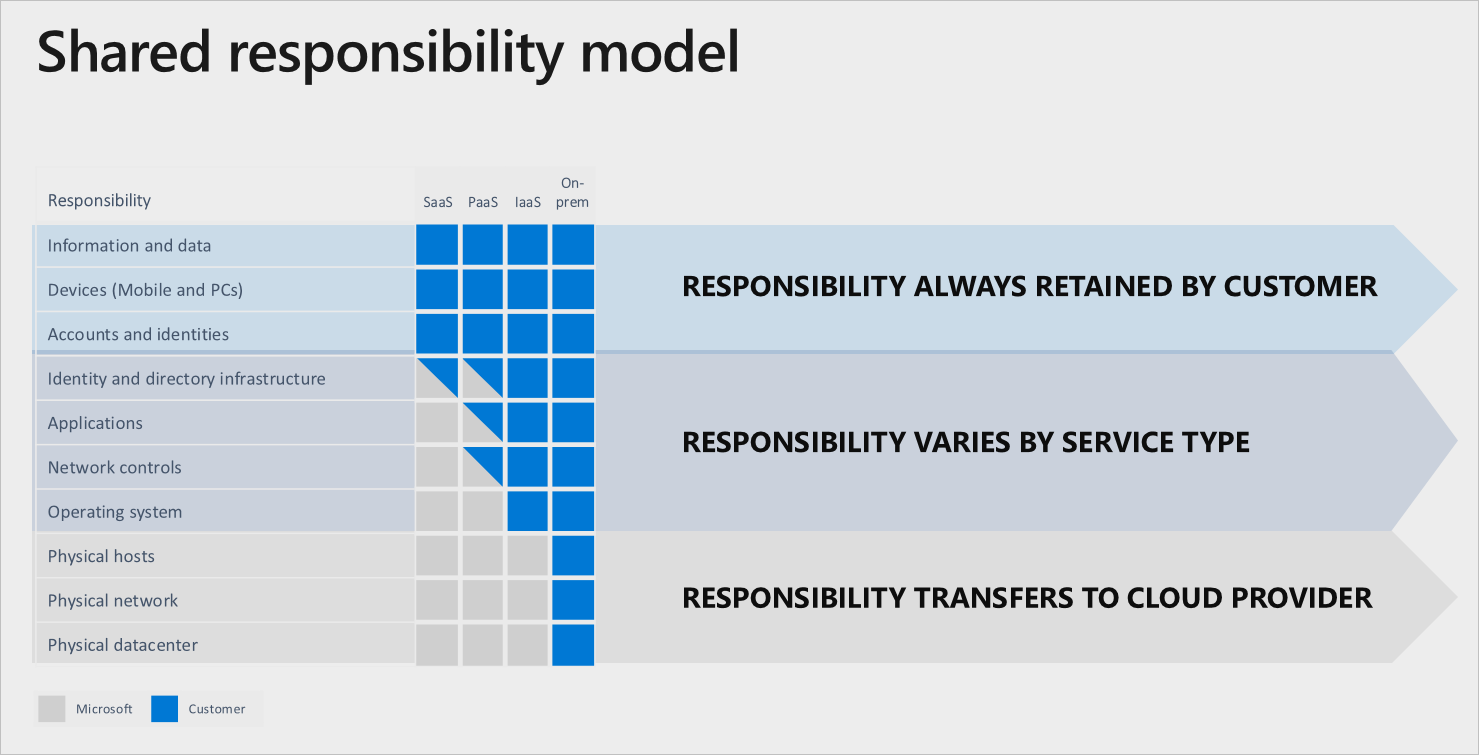
For all cloud deployment types, you own your data and identities. You are responsible for protecting the security of your data and identities, on-premises resources, and the cloud components you control (which varies by service type).
Regardless of the type of deployment, the following responsibilities are always retained by you:
- Data
- Endpoints
- Account
- Access management
The cloud offers significant advantages for solving long standing information security challenges. In an on-premises environment, organizations likely have unmet responsibilities and limited resources available to invest in security, which creates an environment where attackers are able to exploit vulnerabilities at all layers.
The following diagram shows a traditional approach where many security responsibilities are unmet due to limited resources. In the cloud-enabled approach, you are able to shift day to day security responsibilities to your cloud provider and reallocate your resources.

In the cloud-enabled approach, you are also able to leverage cloud-based security capabilities for more effectiveness and use cloud intelligence to improve your threat detection and response time. By shifting responsibilities to the cloud provider, organizations can get more security coverage, which enables them to reallocate security resources and budget to other business priorities.
< Azure Cycle Cloud
Azure Cycle Cloud
Azure CycleCloud is the simplest way to manage HPC (High Performance Computing) workloads.
< Azure Database Migration
Azure Database Migration
Azure Database Migration Service is a tool that helps you simplify, guide, and automate your database migration to Azure. Easily migrate your data, schema, and objects from multiple sources to the cloud at scale.
< Azure Synapse Analytics
Azure Synapse Analytics
Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing, and big data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated resources—at scale. Azure Synapse brings these worlds together with a unified experience to ingest, explore, prepare, manage, and serve data for immediate BI and machine learning needs.
< Azure Sphere
< Azure Data Lake
Azure Data Lake
Azure Data Lake includes all the capabilities required to make it easy for developers, data scientists, and analysts to store data of any size, shape, and speed, and do all types of processing and analytics across platforms and languages. It removes the complexities of ingesting and storing all of your data while making it faster to get up and running with batch, streaming, and interactive analytics. Azure Data Lake works with existing IT investments for identity, management, and security for simplified data management and governance. It also integrates seamlessly with operational stores and data warehouses so you can extend current data applications. We’ve drawn on the experience of working with enterprise customers and running some of the largest scale processing and analytics in the world for Microsoft businesses like Office 365, Xbox Live, Azure, Windows, Bing, and Skype. Azure Data Lake solves many of the productivity and scalability challenges that prevent you from maximizing the value of your data assets with a service that’s ready to meet your current and future business needs.
< Azure Stream Analytics
Azure Stream Analytics
Azure Stream Analytics, the easy-to-use, real-time analytics service that is designed for mission-critical workloads. Build an end-to-end serverless streaming pipeline with just a few clicks. Go from zero to production in minutes using SQL—easily extensible with custom code and built-in machine learning capabilities for more advanced scenarios. Run your most demanding workloads with the confidence of a financially backed SLA.
< Azure Logic Apps
Azure Logic Apps
Azure Logic Apps is a leading integration platform as a service (iPaaS) built on a containerized runtime. Deploy and run Logic Apps anywhere to increase scale and portability while automating business-critical workflows anywhere.
< Azure Event Hubs
Azure Event Hubs
Event Hubs is a fully managed, real-time data ingestion service that’s simple, trusted, and scalable. Stream millions of events per second from any source to build dynamic data pipelines and immediately respond to business challenges. Keep processing data during emergencies using the geo-disaster recovery and geo-replication features.
Integrate seamlessly with other Azure services to unlock valuable insights. Allow existing Apache Kafka clients and applications to talk to Event Hubs without any code changes—you get a managed Kafka experience without having to manage your own clusters. Experience real-time data ingestion and microbatching on the same stream.
< Azure Event Grid
Azure Event Grid allows you to easily build applications with event-based architectures. First, select the Azure resource you would like to subscribe to, and then give the event handler or WebHook endpoint to send the event to. Event Grid has built-in support for events coming from Azure services, like storage blobs and resource groups. Event Grid also has support for your own events, using custom topics.
You can use filters to route specific events to different endpoints, multicast to multiple endpoints, and make sure your events are reliably delivered.
Azure Event Grid is deployed to maximize availability by natively spreading across multiple fault domains in every region, and across availability zones (in regions that support them). For a list of regions that are supported by Event Grid.

This image shows how Event Grid connects sources and handlers, and isn't a comprehensive list of supported integrations. For a list of all supported event sources, see the following section.